ほとんどの企業にとって、増え続ける大量
の生データから有益な情報を導き出すこ
とは、今なお大きな課題として残されてい
ます。なぜなら、重要なチャンスの発見に
つながる関係性や知見は、膨大なデータ
の中に埋もれていることが多いからです。
どの顧客が、いつ、どのような製品を購入
するか? どの顧客が離れていこうとしてい
るか? また、その顧客を引き止めるために
何をしたらよいか? 収益を確保するため
には、どのような価格設定を行うべきか?
機械の保守スケジュールや稼働状況は、
部品が故障するまでの時間にどう影響し
ているのか?
激しい競争が繰り広げられる今日の市場
で競争優位を保つためには、膨大なデー
タから重要な情報を引き出すことができ
るパワフルで高度な分析ソリューションが
不可欠です。それによって、これまで気づ
かなかったパターンを発見することができ、
意思決定者は具体的な行動に結びつく戦
略を立案できるようになります。ビジネス
プロセスにデータマイニングを取り入れた
企業は、変化の激しい市場でも競争力を
維持していくことができるでしょう。
残念ながら、適切なプロセスや適切なツー
ルなしに大量のデータを掘り起こすことは、
手に負えない非効率な作業です。データ
マイニング手法を活用して情報の調査・分
析を行うための新たなアプローチやテク
ニックは、急速な進化を遂げています。ま
た、ひとつの分析手法がひとつのデータ・
コレクションに対してうまく機能していると
しても、市場や競争環境の変化に応じて新
たなデータソースを加えた場合や、新しい
ビジネス課題に対応しようとした場合に、
うまく機能しない可能性もあります。
そのため、幅広い分析ツールを用意して
異なるモデルを作成し、それらのモデルを
横並びで比較することによって、どのデー
タマイニングのアプローチが「最適」であ
るかを判断することが重要です。限定的な
機能しか備えていない(例えば回帰法だけ、
あるいは決定木分析だけしか使用できな
い)作業環境では、限られた結果や予測的
価値しかもたらさないモデルになってしま
うでしょう。
あらゆる業界において、具体的な行動に
結びつく分析情報が求められるようになっ
てきており、データマイニングの担当者は、
より適切なモデルをより短時間で、より多
く作成しなければならないというプレッ
シャーに直面しています。安全かつ拡張可
能な方法で分析(アナリティクス)を取り入
れることができれば、業務や業種に固有の
ビジネス課題を解決する上で広く役立つ
でしょう。また、確かな成果を上げるため
には組織全体の協力体制が必要ですが、
それには、多種多様なニーズに対応でき
る強力で多目的なデータマイニングのソ
リューションが不可欠です。
SAS
®Enterprise Miner
™のアーキテクチャ
はこうした目的に最適化されており、デー
タマイニングの担当者は高精度な予測モ
デルや記述モデルを作成する作業に、より
多くの時間を割くことができます。作成し
たモデルは組織全体で共有し、分析情報を
関係者に配布したり、業務プロセスに適用
したりすることが可能です。SAS Analytics
は、SAS が提供する戦略的情報基盤の重
要なコンポーネントです。既存システムの
価値を高め、企業全体にわたって一貫性
のあるビューを確立し、不確定要素を減ら
して正確な予測を可能にすることで、市場
における競争優位の獲得を支援します。
主な利点
•
直観的に重要な関係性を理解し、
短期間でモデルを構築
SAS Enterprise Miner は直観的で使い
やすいグラフィカル・ユーザー・インター
フェイス(GUI)を備えているため、統計
分析の担当者は、モデリング・サイクル
のどの時点においても情報を簡単に扱
うことができます。統計分析の担当者と
業務の責任者の両方が、理解しやすい
視覚的な方法でデータマイニング・プロ
セスを共有できるため、非常に難しい課
SAS
®ENTERPRISE MINER
™7.1
データマイニング・プロセスを効率化し、
膨大なデータから高精度な記述/予測モデルを作成
主な機能
SAS のデータマイニング・ソリューショ ンSAS Enterprise Minerは、企業に蓄積 されている膨大なデータから傾向や相 関を見つけ出す作業を支援します。デー タマイニングのプロセスを効率化し、高 精度の予測モデルや記述モデルの作成 と管理を行います。先進的な企業は SAS の予測分析およびデータマイニン グ・ソフトウェアを使用して、不正の発見、 リスクの最小化、リソース需要の予測、 設備資産のダウンタイムの削減、マーケ ティング・キャンペーン反応率の向上、顧 客離反防止などに役立てています。
ビジネスメリット
SAS は業界で最も包括的な予測分析お よびデータマイニング機能のセットを提 供しています。ユーザーは、複雑なデー タを分析して隠された意味を見出し、有 益な洞察を導き出し、確信を持って行動 することで、事実にもとづく意思決定を 行えるようになります。対象ユーザー
増え続ける大量のデータを分析して理 解することで、ビジネスや研究における 重要課題を特定および解決し、十分な情 報にもとづいて意思決定を行う必要が あるデータマイニング担当者、統計専門 スタッフ、マーケティング・アナリスト、 データベース・マーケティング担当者、リ スク分析担当者、不正捜査官、エンジニ ア、科学者、ビジネス分析担当者などを 対象として開発されています。FACT SHEET
グ &ドロップ方式のインターフェイスを採
用しているため、経験を積んだ統計の専門
スタッフも、経験の少ないビジネス・アナリ
ストも容易に活用できます。また、データ
マイニングを成功させるために欠かすこ
とのできない高度な分析アルゴリズムが
組まれています。SAS のデータマイニング
のプロセスは、SEMMAと呼ばれる5 つの
ステップ(サンプリング、探索、加工、モデリ
ング、評価)から成り立っています。各ステッ
プでは、データマイニングのプロジェクト
を進める上で重要な一連の作業を実行し
ます。SEMMA のメニューシステムに沿っ
てノード開発の作業を進めるだけで、高度
な統計手法を適用し、最も顕著な変数を特
定し、エクスプレッション・ビルダーを用い
てデータ要素を変換し、結果を予測するた
めのモデルを作成し、結果の精度を評価し、
最終的には予測数値とともに点数化され
たデータセットを生成して、業務アプリケー
ションに展開できるようになっています。
ビジネスユーザーが自力で、
素早く簡単にモデルを作成
SAS Rapid Predictive Modelerでは、デー
タマイニング作業のワークフローに沿って、
データの変換、変数の選択、さまざまなア
ルゴリズムの適用、モデルの評価などの各
ステップが自動的に案内されるため、ビジ
ネスユーザー自身が幅広いビジネス課題
について予測モデルを素早く作成できま
す。SAS Rapid Predictive Modeler は、
SAS
®Enterprise Guide
®またはSAS
Add-In for Microsoft Office(Microsoft Excel
のみに対応)のタスクとして実行され、
SAS Enterprise Miner 内の定義済みモ
デリング・ステップを使用します。ビジネ
スユー ザ ーが SAS Rapid Predictive
Modeler で作成したモデルを、分析担当者
が SAS Enterprise Miner を使用して強化
およびカスタマイズするという形で、共同
作業することも可能です。
定番および最新のモデリング手法を
バランスよく搭載
SAS Enterprise Miner は、決定木分析、バ
ギングおよびブースティング、時系列デー
タマイニング、サポート・ベクター・マシン
(SVM)、ニューラル・ネットワーク、記憶ベー
ス推論(MBR)、階層的クラスタリング、線
形およびロジスティック回帰分析、アソシ
エーション分析、シーケンス分析、Web パ
の機能では、モデル化された結果に予
測変数がどのように関与しているかを
理解できます。
•
モデル展開の容易化と、
スコアリング・プロセスの高速化
SAS Enterprise Miner では、新しいデー
タをスコアリングする際の単調なプロ
セスが自動化されます。モデル開発の
全段階のための完全なスコアリング・
コードをSAS、C、Java、PMML 言語で自
動的に出力してくれます。自動作成さ
れたスコアリング・コードは SAS 内のさ
まざまなリアルタイム環境やバッチ環
境に展開でき、Web 上への展開やビジ
ネスプロセスへの組み込み、リレーショ
ナル・データベースへの直接展開(In-Database 処理)なども可能です。以上
のような機能により、ユーザーは時間を
節約しながら正確な結果を導き出し、大
きな価値につながる意思決定を下すこ
とができるようになります。
ソリューション概要
SAS Enterprise Miner は、最新かつ分散
型のクライアント/サーバー型のシステ
ムです。データマイニングのプロセスを容
易に拡張・強化できるようにするため、SAS
が提供するデータ統合、分析・予測、レポー
ティングといったテクノロジーともスムー
ズに連携するように設計されています。
すべてのデータを統合し、
完全なビューを提供
データマイニングが最も効果を発揮する
のは、Web やコールセンター、アンケート
結果、顧客からのフィードバック、時系列
データや取引データを処理する販売シス
テムなど、企業内のさまざまな情報ソース
からデータを集めて活用することを目指
す情報統合戦略の一部として利用した場
合です。SAS のテキストマイニング(SAS
Text Miner)も併用すれば、構造化データ
と非構造化データの両方を統合型の予測
モデリングに取り込むことが可能になるた
め、より広範なデータ分析に対応できるよ
うになります。
使いやすい
GUI
SAS Enterprise Miner が提供するデータ
マイニング機能は、使い勝手のよい、
ドラッ
題でも協力して解決することができます。
ポイント・アンド・クリック方式で操作で
きる対話型の環境は、発見と視覚的な
探索の作業に最適化されています。テー
ブルとグラフィックスが動的に結びつけ
られるため、さまざまな関係性を簡単に
理解できます。
•
多彩なデータマイニング機能で、
優れたモデルを効率的に量産
SAS Enterprise Miner が提供する直観
的 なプロセスフロー・ダイアグラム
(PFD)を利用すれば、統計の専門家や
データマイニング担当者は、従来よりも
はるかに短い時間で多くのモデルを作
成できます。プロセスフロー・ダイアグ
ラムは、最良の結果が出るように、デー
タマイニング・プロセス全体を効率よく
マッピングします。
•
セルフサービス型の自動化により、
誰もが迅速かつ容易に洞察を導き出し、
的確な意思決定を実現
SAS Rapid Predictive Modeler タスク
を活用すると、ビジネス・アナリストや各
分野の専門家は、統計の専門知識が限
られていても、一般的なビジネスシナリ
オ用の予測モデルを自動的に作成し、
その結果を踏まえて素早く行動するこ
とができます。分析結果は理解しやすい
チャートで表示されるため、意思決定の
質も向上します。
•
予測精度の向上により、
適切な意思決定にもとづいて
常にベストな行動がとれるように支援
モデルに革新的なアルゴリズムを採用
し、業種固有の手法も組み入れたことで、
予測の安定性と精度がさらに向上して
います。また、予測結果は、視覚的なモ
デル評価機能や、検証用の指標を用い
て簡単に確認・検証できます。異なる手
法で作成したモデルから得られた予測
結果や評価統計値を左右に並べて表示
し、簡単に比較・検討することも可能で
す。分析結果として得られたダイアグラ
ムは、自動的に文書化を行えるテンプ
レートとして利用できます。部分的な変
更も簡単に行えるため、新たな課題解
決の際に一からモデルを作り直す必要
はありません。また、モデルのプロファ
イリング機能もサポートしています。こ
ス分析など、予測モデルや記述モデルの
ための一連のアルゴリズムをバランスよく
実装し、非常に高度で奥深い分析機能を
提供しています。幅広い分析アルゴリズム
を備えており、勾配ブースティング、部分
最小二乗法(PLS)、サポート・ベクター・マ
シン(SVM)といった最新の分析手法も利
用できます。
データの準備や要約、探索を行うための
洗練されたツール群
対象データの準備は、データマイニングの
プロセスの中で最も時間のかかるところ
ですが、SAS Enterprise Miner では、欠落
値の最適な解決、異常値のフィルタリング、
ルール作成を行うための、対話操作型の
データ準備ウィザードが利用できます。ま
た、データファイルのインポート、変数の
追加、マージ、切り捨てなどを行う基本的
なデータ準備ツールも完備。さらに、記述
統計のための広範な機能や、対話操作型
のデータ探索ツールにより、統計分析に詳
しくないビジネスユーザーでも、動的にリ
ンクした大量データを調査し、多次元プロッ
トを検証できます。これにより、特定のビ
ジネス課題に適した質の高いデータマイ
ニングを、幅広いユーザー層が活用できる
ようになります。
ビジネスの視点にもとづくモデルの比較、
レポーティング、管理
リフトカーブや ROI(投資対効果)の観点
から複数のモデルを比較できる評価機能
により、データマイニングの担当者と各ビ
ジネス分野の専門家がデータマイニング
の結果について話し合うなど、有意義なコ
ラボレーションの機会が増えます。さまざ
まなアルゴリズムを活用して作ったモデル
は、必要に応じていつでも、高度に視覚化
された評価(アセスメント)用のインター
フェイスを使って評価することができます。
また革新的なカットオフ・ノードによって事
後確率を評価し、目の前のビジネス課題を
解決する最善の行動が何かを明確化する
ことも可能です。
従来型および
In-Database
型の
スコアリング・プロセスにより、
結果を迅速に提供
新しいデータを業務環境に導入する際は、
そのデータにモデルを適用するためのス
コアリングが常に必要となります。このプ
ロセスには手間がかかり、特にコードの書
き直しや変換を手作業で行う場合は非常
に面倒で、モデルの導入が遅れたり、多額
の損失を生むエラーにつながったりするリ
スクもあります。スコアリング用のコード
は、最終的な予測モデルに至るまでのプロ
セス全体(データの前処理の全ステップを
含む)を反映したものでなければなりませ
ん。SAS Enterprise Miner では、SASプロ
グラミング言語、C、Java、PMML でスコア
リング用のコードが自動的に生成されます。
完成したコードは、SAS 内のさまざまな環
境にリアルタイムもしくはバッチで展開で
きるだけでなく、Web上への展開や、リレー
ショナル・データベース内での直接展開も
可能です。スコアリング・アクセラレータ
(Teradata、IBM DB2、Netezza で利用可
能)と組み合わせれば、SAS Enterprise
Miner のモデルをデータベース固有のス
コアリング機能として発行し、データベー
ス内で直接実行することもできます。また、
SAS Enterprise Miner から得られた結果
をSAS Marketing Automation、SAS Model
Manager、SAS Real-Time Decision
Manager といった SAS のビジネス・ソ
リューションに渡すことで、データマイニン
グの結果をリアルタイムの業務環境で活
用することも可能です。
オープンで拡張性のある設計、
高度な柔軟性
SAS Enterprise Miner の環境はカスタマ
イズに対応しており、ツールの追加や、パー
ソナライズした SAS コードの取り込みが
可能です。SAS Enterprise Miner の環境
外で作られた既存の SAS モデルも、構文
の記述を完全に維持した状態で、プロセス
フロー環境に簡単に統合できます。拡張
ノードには、トレーニング・コードやスコア
リング・コードの作成に役立つ対話型のエ
ディタ機能が備わっています。ユーザーは、
ログや出力リストを見ながら、その場でコー
ドを編集し、サブミットできます。デフォル
トの選択リストを、SAS のコードや XML ロ
ジックで書かれたカスタム開発のツールで
拡張することも可能です。これを活用すれ
ば、データマイニングの担当者は SAS の
あらゆる機能を利用できるようになります。
グリッド対応可能な
ハイパフォーマンスのワークベンチ
革新的な Java クライアントと SAS サー
バーを採用したアーキテクチャにより、こ
れまでに例のない柔軟性が実現していま
す。単一ユーザー向けのシステムから大
規模なエンタープライズ・ソリューションま
で、さまざまなシステムを効率的に構成で
きます。堅牢なサーバーが安定したパ
フォーマンスを提供し続けるため、エンド
ユーザーがオフィスから自宅、あるいはリ
モートサイトに移動した場合でも、データ
マイニングのプロジェクトやサービスへの
アクセスを失うことはありません。データ
の並べ替えや要約、変数選択や回帰モデ
ルなど、処理負荷の高いタスクの多くはマ
ルチスレッド処理に対応しており、グリッ
ド・コンピューティングによる並行処理や
負荷分散、あるいはバッチプロセスのスケ
ジューリングが可能です。
大規模な利用にも適した
最新の分散型データマイニング・システム
SAS Enterprise Miner は、シンクライアン
トの Webポータルだけで展開できるため、
クライアント側のメンテナンスを最小限に
抑えながら、多数のユーザーで使用するこ
とができます。あるいは、スタンドアロー
ンの PC 上に構成して使用することも可能
です。SAS Enterprise Miner は Windows
サーバーとUNIX プラットフォームに対応
しており、大規模なデータマイニングのプ
ロジェクトを実行する企業にとっても、最
適な選択肢となります。SAS Enterprise
Miner のバッチ処理機能を活用すれば、社
内のコンピューティング負荷がピークとな
る時間帯を外して、大規模なトレーニング
やスコアリングを実行するようにスケジュー
リングできます。分析全体をカバーしたレ
ポートの作成・配信も容易に行うことがで
き、社内での記録や社外への報告に利用
できます。また、モデルを組み合わせたパッ
ケージを作り、SAS Metadata Serverに登
録して集中管理することが可能で、SAS
Model Manager、SAS Data Integration
Studio (SAS Enterprise Data Integration
ServerとSAS Data Integration Server の
コンポーネント)、SAS Enterprise Guide
から利用できます。これにより、データマ
イニング担当者、業務マネージャー、デー
タ担当マネージャーが SAS Business
Analytics の基盤を介して、組織全体にわ
たる大規模なモデル・ポートフォリオを効
果的に管理できます。
主な機能
直感的なインターフェイス • プロセスフロー・ダイアグラム(PFD)を 作成するための使いやすいGUI: • より多くの高度なモデルを、より短時 間で作成 • Web経由で提供可能 • SASプログラミング環境へのアクセス • XMLダイアグラム交換機能 • ダイアグラムをテンプレートとして別 のプロジェクトやユーザーが再利用 • バッチ処理: • GUIの全機能をカプセル化 • SASマクロがベース • トレーニングおよびスコアリングのプ ロセスを独自アプリケーションに組み 込み 拡張性のあるプロセッシング • サーバーベースのプロセッシング • In-Memory処理 • 非同期でのモデル・トレーニング • 処理をクリーンに停止可能 • グリッド・コンピューティング: • マイニング・プロセスをクラスター内 に分散 • トレーニングとスコアリングのタスク をスケジューリング • 負荷分散とリソース割当 • 並列処理 – 複数のツールやダイアグラ ムを同時に実行 • マルチスレッド処理に対応した予測アル ゴリズム • すべてのストレージをサーバー上に配置 データのアクセスと管理 • 構造化/非構造化データソースへのアク セスと統合(予測変数候補として、時系列 データ、マーケット・バスケット、Webパス、 調査データを含む) • Microsoft Excel、カンマ区切りファイル、 SAS、JMP®、その他の一般的なファイル 形式に簡単にアクセスできるFile Import ノード • Rとの統合によるモデルのタイプと比較 の拡張: • JMP Pro内でRのメソッドを使用 • 特殊な特性を持つ変数のサポート • テーブルのリストの高速な検索・表示や、 対話型のグラフ・コンポーネントを用いた プロット作成など、機能が拡張された Explorerウィンドウ• SAS Library ExplorerおよびLibrary Assignmentウィザード
• Drop Variablesノード
• Merge Dataノード
• Appendノード
図1. SAS Enterprise MinerのGUIでは、プロセスフロー・ダイアグラム(PFD)が自己文書化型のテンプ レートとして機能。テンプレートの更新、新しい問題への適用、モデル作成者や他のアナリストとの共有も容 易です。
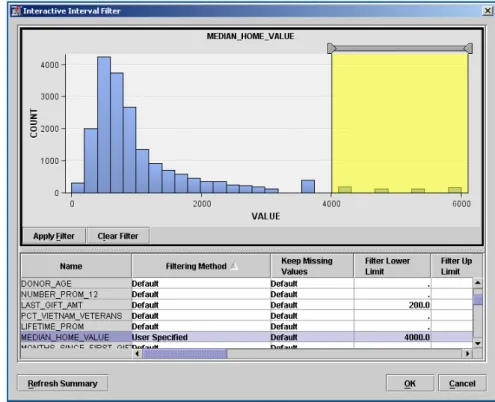
図2. Filterノードで、フィルタの極値を対話操作でフィルタリング。色の付いた領域は、保持する可変範囲を 示しています。
• 異常値のフィルタリング: • 各種の分布しきい値を適用して極端 な区間値を除外 • 発生回数がn回未満の階級値を結合 • 階級値と数値を対話操作でフィルタリ ング • ロール、計測レベル、順序などの列メタ データを変更できるMetadataノード
• SAS Metadata Serverを通じてSAS Data Integration Studio、SAS Enterprise Guide、SAS Add-In for Microsoft Officeと統合: • マイニング用のトレーニング・テーブ ルを構築 • スコアリング・コードを展開 サンプリング • 単純無作為 • 層化抽出 • 加重 • クラスター • 系統抽出 • 最初のN個 • 希少事象サンプリング • Teradata 13での層化および事象レベ ル・サンプリング データのパーティション化 • トレーニング、バリデーション、検定用デー タセットの作成 • 提示されたデータを使用してモデルの良 好な普遍性を確保 • クラス・ターゲットによるデフォルトの層化 • 任意のクラス変数によるバランスのとれ たパーティション化 • SASテーブルまたはビューの出力 変換 • 単純:対数、常用対数、平方根、逆数、平 方、指数、標準化 • ビニング:ターゲットとの関係を明らかに するためのバケット化、分位数、最適化に よるビニング • 最適なべき乗:正規性の最大化、ターゲッ トとの相関の最大化、ターゲット・レベル とのスプレッドの同等化 • 相互作用エディタ:多項およびn次元の 相互作用を定義 • 対話操作による変換の定義: • エクスプレッション・ビルダーまたは SASコードエディタを用いて、独自の 変換を定義 • 新しい変数の分布を元の変数と比較 • グローバル変換コードを事前定義して再 利用 図3. Transform Variablesノードで、対話型のエクスプレッション・ビルダーを使用してカスタム変換を作成 図4. 対話操作で変数をビン化して、ターゲットとの関係性を最大化したり、ビジネスポリシーに準拠させるこ とが可能。ビンを対話操作で分割または結合し、グループ化の定義を保存して再利用できます。
グラフ/可視化 • バッチプロットと対話操作型プロット:散布、行列、ボックス、星座、等高線、ニードル、格子、密度、多 次元(以上プロット)、3-D、円、面、棒(以上グラフ)、ヒストグラム • セグメント・プロファイル・プロット: • クラスタリングやモデリング・ツールで作成されたデータのセグメントを対話操作でプロファイル化 • プロファイルとグループ間の相違を決定付ける変数を簡単に特定
• 使いやすいGraphics ExplorerウィザードとGraphics Exploreノード:
• タイトルと脚注の作成
• WHERE句の適用
• 複数のカラースキームを選択可能
• 軸の拡大・縮小が容易
• SAS Enterprise Minerの標準の結果の元になっているデータを表示し、カスタマイズされた グラフィックスを作成 • プロットとテーブルを対話操作でリンクさせ、ブラッシングやバンディングなどのタスクをサポート • 簡単な操作でデータとプロットをコピーし、別のアプリケーションに貼り付け、またはBMPファイル として保存 • 対話操作型のグラフをノードのResultsウィンドウ内に自動保存 • グラフ作成機能(Graph Builder): • 変数をテンプレートにドラッグ&ドロップする対話操作でグラフを作成。変数をグラフ上にドラッ グすると、瞬時にフィードバックが表示される • 複数のグループ化レベルをすべてひとつのプロット内で視覚的に比較 • 統計情報をグラフィックスと動的にリンクさせることで、関係性を容易に特定 クラスタリングと自己組織化マップ • クラスタリング: • 最適なクラスターをユーザー定義または自動選択 • クラス変数を分析コードに組み込むための複数の戦略 • 欠損値を処理 • 変数セグメント・プロファイル・プロットにより、各クラスター内での入力や他の要因の分布状況 を表示 • 決定木プロファイルにより、入力を使用してクラスターのメンバーシップを予測 • PMMLによるスコアリング・コード 対話操作による変数ビニング • 分位数またはバケット • ジニ係数の選択 • 欠損値を個別のグループとして処理 • クラス分け詳細の微細化と粗大化 • ビンをターゲット別にプロファイル化 • 対話操作によるグループ変更 • ビニング定義の保存
Rules Builder
ノード • アドホック・データにもとづくルールおよ びポリシーを作成 • 結果変数の値と結果に至るパスを対話操 作で定義 データの置換 • 中心性の計測(Measures of centrality) • 分布ベース • 代理ルールを伴うツリー分析による置き 換え • 中間ミディアム・スペーシング (Mid-medium spacing) • 堅牢なM推定量 (Robust M-estimators) • デフォルト定数 • 置換エディタ: • クラス変数に対して新しい値を指定 • 未知の値に対して置換値を割当 • 極端な区間値を対話操作で置換しき い値に制限 記述統計 • 単変量による統計とプロット: • 間隔変数: n、平均、中央値、最小、 最 大、標準偏差、拡縮偏差(scaled deviation)、欠損率(percent missing)• クラス変数:カテゴリー数、件数、モー ド、モード率(percent mode)、欠損率 (percent missing) • 分布プロット • クラス・ターゲットの各レベルへの統 計ブレイクダウン • 二変量による統計とプロット: • ピアソンおよびスピアマンの順位相関 プロット • 連続入力をnビンにビニングするオプ ションを伴う、順位付きのカイ二乗プ ロット • 変動係数プロット • 対数価値による変数選択 • その他の対話操作型プロット: • ターゲットにとっての価値にもとづい て入力をランク付けする変数価値プ ロット • ターゲットおよび/またはセグメント 変数にまたがるクラス変数分布 • 拡縮平均偏差プロット(Scaled mean deviation plots) 図5. さまざまなプロットを対話的に操作してデータを探索。Graphics Exploreノードの実行結果に、対話 操作型のグラフが自動的に保存されます。
• 自己組織化マップ(SOM): • Nadaraya-Watsonまたはローカル 線形スムージングを用いたバッチSOM • Kohonenネットワーク • 他の変数の分布をマップ上にオーバー レイ • 欠損値を処理 マーケット・バスケット分析 • アソシエーションとシーケンスの発見: • 信頼度によって順序付けされるルール のグリッドプロット • リフト、信頼度、予想信頼度、ルール支 持度にもとづく統計ラインプロット • 与えられた対象範囲と信頼度に関する 頻度値の統計ヒストグラム • 予想信頼度と実際の信頼度を比較す る散布プロット • ルール記述テーブル • ルールのネットワーク・プロット • リフト、信頼度、支持度、チェーン長などの 指標にもとづき、対話操作でルールをサ ブセット化 • ルールを他の入力とシームレスに統合す ることで、予測モデリングを高度化 • 階層的アソシエーション: • 複数のレベルでルールを導出 • 次元入力テーブル向けに親子関係の マッピングを指定
Web
パス分析 • クリックストリーム・データから最も頻繁 にナビゲートされたパスを特定する、拡 張性と効率性に優れたマイニング • 任意のタイプのシーケンスデータから、連 続する頻度が高いサブシーケンスを発掘 次元削減 • 変数選択: • カイ二乗またはR2の選択基準にもと づき、ターゲットに無関係な変数を 除去 • 変数の階層構造を除去 • 欠損値が多い変数を除去 • レベル数が多いクラス変数を削減 • 連続入力をビニングして非線形の関 係を特定 • 相互作用を検出 • 最小角度回帰(LARS)の変数選択: • AIC、SBC、Mallows C(p)、クロス・バ リデーション、その他の選択基準 • プロットの種類:パラメータ予測、係 数パス、反復プロット、スコア・ランキン グ、その他• 一般化によるLASSO(Least Absolute Shrinkage and Selection Operator) のサポート • クラス入力とターゲット、連続変数の サポート • スコアリング・コードの生成 • 主成分: • 相関と共分散行列から固有値と固有ベクトルを計算 • プロットの種類:主成分係数、主成分行列、固有値、対数固有値、累積比例固有値(Cumulative Proportional Eigenvalue) • 保持する成分の数を対話操作で選択 • 選択した主成分を予測モデリング手法を使用して発掘 図6. マーケット・バスケットのプロファイル表示。リフト、信頼度、支持度、チェーン長などの指標にもとづき、 対話操作でルールをサブセット化できます。 図7. LARSを使用して、重要な予測変数を事前選択。
• 変数のクラスタリング: • 変数を分解クラスターまたは階層的ク ラスターに分割 • 固有値または主成分の学習 • クラス変数をサポート • クラスターのデンドログラム(樹形図) • 選択した変数テーブルでクラスターと 相関統計を使用 • クラスター・ネットワークとR二乗プ ロット • 選択した変数をユーザーが対話操作 で無効化 • 時系列マイニング: • 複数の累積手法と変換を使用し、トラ ンザクション・データを時系列化して 削減 • 季節、傾向、時間領域、季節分解など の分析手法 • 削減された時系列を、クラスタリングと 予測モデリングの手法を使用して発掘
SAS Code
ノード • 複雑なデータ準備および変換のタスクで も、SASコードで簡単に記述 • 他のSAS製品からプロシジャを取り込み • カスタムモデルの開発• SAS Enterprise Miner拡張ノードの 作成 • スコアリング・コードのロジック強化 • 使いやすいプログラム開発インターフェ イス: • データソースや変数などを参照するマ クロ変数 • 対話操作型のコードエディタとサブ ミット • トレーニング、スコアリング、レポーティ ング用のコードを個別に管理
• SAS OutputおよびSAS LOG • グラフィックスの作成 一貫したモデリング機能 • トレーニング、バリデーション(デフォルト)、 または検定のデータにもとづき、損益、 AlC、SBC、平均二乗誤差、誤判別率、 ROC、ジニ、KS(Kolmogorov-Smirnov) など各種の基準を用いてモデルを選択 • モデル開発プロセスに事前確率を組み 入れ • 2値(バイナリ)、名義(ノミナル)、順序 (オーディナル)、間隔(インターバル)の 入力とターゲットをサポート • スコアリング・コードとすべてのパーティ ション化したデータソースに簡単にアク セス • 複数の結果を1つのウィンドウに表示す ることで、モデル・パフォーマンス評価の 効率を向上 • ターゲット事象を設定し、優先行列と損益 行列を定義するDecisionsノード 図8. カスタマイズしたSASコードを統合することで、変数変換の作成、SASプロシジャの組み込み、新モデ ルの開発、スコアリング・ロジックの強化、レポートの仕様変更などが可能。 図9. ステップ毎の選択方式と複数のモデル選択診断機能を使用して、線形回帰モデルとロジスティック回帰 モデルを作成。
回帰 • 線形およびロジスティック • 段階的選択、前進選択、後退選択 • 方程式条件ビルダー:多項式、一般相互 作用、効果階層をサポート • クロス・バリデーション • 効果階層ルール • 最適化手法の種類:共役勾配、ダブル・ ドッグレッグ、ニュートン・ラフソン(直線 探索またはリッジング)、準ニュートン、信 頼領域 • Dmine Regressionノード: • 高速前進ステップワイズ最小二乗回帰 • 非線形関係を検出する変数ビニング (オプション) • クラス変数削減(オプション) • 相互作用条件の使用 • Teradata 13用のIn-Databaseモデリ ング • PMMLによるスコアリング・コード 決定木 • 方法論: • CHAID、分類・回帰木(CART)、バギ ングおよびブースティング、勾配ブー スティング、ブートストラップ森 • 利益またはリフト目標にもとづくツリー の選択と刈り込み • K分割クロス・バリデーション • 分割基準:確率カイ二乗検定、確率F検 定、ジニ、エントロピー、変数削減 • 多目的セグメンテーション戦略を設計す るためのターゲット交換 • モデリングおよびグループ処理の入力と してリーフIDを自動出力 • 英語ルールの表示 • 予備的な変数選択とモデル解釈のために、 変数の重要性を計算 • 樹形図の一意の統合ツリーマップ表現 • ツリーに関する対話操作機能: • 対話操作によるツリーの成長/刈り込 み、ツリーノードの展開/折りたたみ • ツリーの安定性を評価するバリデー ション・データの取り込み • 2分岐や多分岐を含む分岐点のカスタ ム定義 • 任意の候補変数上での分岐 • 分岐のコピー • テーブルとプロットを動的にリンクさ せ、ツリー・パフォーマンス評価の効率 を向上 • 樹形図を単一ページまたは複数ペー ジに簡単に印刷 • 対話操作によるサブツリー選択 • 高速ARBORETUMプロシジャに準拠 • PMMLによるスコアリング・コード ニューラル・ネットワーク • Neural Networkノード: • 組み合わせと活性化の関数を備えた柔軟なネットワーク・アーキテクチャ • 10種類のトレーニング手法 • 予備的な最適化 • 入力の自動標準化 • 有向接続(direction connection)のサポート 図10. 対話操作またはバッチモードで意思決定木を開発。決定木全体の安定性の計測に役立つ多数の評価 プロットが用意されています。 図11. Neural Networkノードを使用して、非常に複雑な非線形関係を当てはめ。一般化線形モデル、多層 パーセプトロン、放射基底関数などのアーキテクチャに加え、組み合わせ、活性化、エラーなどの幅広い関数 をサポートしています。
• Autoneural Neuralノード: • 多層パーセプトロン構築時のノード検 索を自動化することで、コンフィギュ レーションを最適化 • 4種類の異なるアーキテクチャから選 択されるタイプおよび活性化関数 • PMMLによるスコアリング・コード • DM Neuralノード: • 次元削減と関数選択によるモデル構築 • 高速トレーニング、線形および非線形 推定 サポート・ベクター・マシン(評価版) • 多変数の問題に有効な最大マージン・ク ラシファイア • 2値変数ターゲットをサポート • 推定法(密な二次、分解型二次、ラグラン ジュ、最小二乗など) • 線形関数、多項式関数、放射基底関数、シ グモイド・パラメータ • サンプリングとクロス・バリデーション(オ プション) • プロシジャにもとづくSASスコアリング
Partial Least Squares
(部分最小二乗)ノード • 相関する可能性のある大量の変数から要 因を抽出する場合に特に有効 • 主成分回帰と縮小ランク回帰も実行 • 要因の個数のユーザー選択または自動 選択 • 5種類のクロス・バリデーション戦略から 選択 • 変数選択をサポート ルール推論 • 再帰予測モデル手法 • まれな事象のモデル化に特に有効
2
段階モデリング • クラスと間隔ターゲットの両方に関する 逐次および同時モデリング • 各段階について決定木、回帰、または ニューラル・ネットワークのモデルを選択 • クラス予測を間隔予測に適用する方法を コントロール • 顧客価値を正確に推定 記憶にもとづく推論 (MBR
:Memory-based reasoning
) • k近傍法による観測結果の分類または 予測 • 次元削減ツリーおよびスキャン(特許取得) モデルのアンサンブル • モデルによる予測結果を組み合わせて、より強力なものになる可能性があるソリューションを作成 • 手法の種類:平均化、投票、最大 時系列データマイニング(評価版) • 時系列データの準備: • トランザクション・データの集約、変換、要約 • 時系列の自動転置により、類似度分析、クラスタリング、予測モデリングをサポート • 類似度分析: • 新製品予測、パターン認識、短期ライフサイクル予測に有効 • ターゲットと入力系列の間、または入力時系列の間の類似度を計算 • 系列のすべての組み合わせを表現する類似度行列 • 類似度行列にデンドログラムの結果を組み合わせる階層的クラスタリング • クラスター評価に役立つ星座プロット • 指数平滑法: • 1つ以上の平滑パラメータを用いて荷重減衰をコントロール • 最適な平滑化手法を自動選択 • 削減された時系列を、記述統計手法を使用して発掘 生存時間分析 • 離散的なtime to event型回帰と加法型ロジスティック回帰 • ある期間に事象が発生する確率を3次スプラインでモデル化 • データ分析と打ち切り処理の方法を指定するためのユーザー定義の時間間隔 • オプションのサンプリングでデータを自動拡張 • 非時変性の共変量をサポート • 提示されたバリデーションで生存時間関数を計算 • 計算リスクまたはサブハザードを生成• 平均残存寿命(Mean Residual Lifetime)を計算してスコアカードを生成
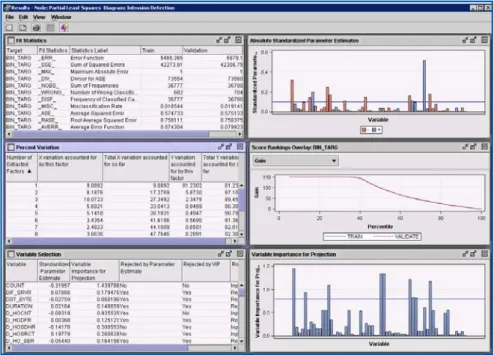
図12. Partial Least Squaresノードを使用して、相関関係が見られない(潜在的な)要因や成分の候補集 合を抽出。SAS Enterprise Minerの標準モデルを当てはめて統計情報を収集し、チャレンジャーとなる他 のモデリング手法と比較できます。
モデルの評価 • Model Comparisonノードは、提示された全データについて単一のフレームワークで複数のモデ ルを比較する • ユーザー定義のモデル基準にもとづき、最適なモデルを自動選択 • ユーザーによる手動変更にも対応 • 当てはめと診断に関する豊富な統計情報 • リフトチャート、ROC曲線 • 決定を選択できる損益チャート、混同(分類)行列 • クラス確率スコア分布プロット、スコア・ランキング行列プロット • 間隔ターゲット・スコアのランキングと分布 • 2値ターゲットの確率のカットオフ・ポイントを特定するCutoffノード • デフォルトの選択をユーザーが手動変更可能 • 最大KS統計値 • 最小誤判別コスト • 最大累積プロファイル • 最大真陽性(True Positive)率 料率設定(保険分野) • 請求の頻度、重度、純保険料をモデル化 • 適切な分布およびリンク関数の自動選択。 ユーザーによる手動変更も可能 • 分布の種類:ポアソン、負の2項、ガ ンマ、正規、逆ガウス、Tweedie、ZIP
(Zero-inflation Poisson)
• リンク関数の種類:対数、逆数、2乗、 3乗、対数の対数 • 効 果 の 事 前ビ ニングを 伴う高 速 In-Memoryモデリング • Tweedieモデル最適化手法の種類: 自動、鞍点、尤度、最終尤度 • 相互作用ビルダー • 過分散を処理するZIPモデルの定義方 法をユーザーがコントロール • 標準統計手法: AIC、SBC、ピアソンのカ イ二乗、偏差値 • 各モデルの効果の相対プロットを計算 • SASスコアリング・コードを生成
Start and End Groups
ノードによる グループ・プロセッシング • プロセスフロー・ダイアグラム(PFD)の セグメントにおける処理の反復 • 使用例:層化モデリング、バギングおよび ブースティング、複数ターゲット、クロス・ バリデーションModel Import
ノード• SAS Enterprise Minerモデルを登録す ることで、別のダイアグラムやプロジェク トで再利用可能
• 外部モデルのインポートと評価
SAS
®Enterprise Guide
®またはSAS
®Add-In for Microsoft Office
(
Microsoft Excel
のみに対応)に おける、SAS
®Rapid Predictive
Modeler
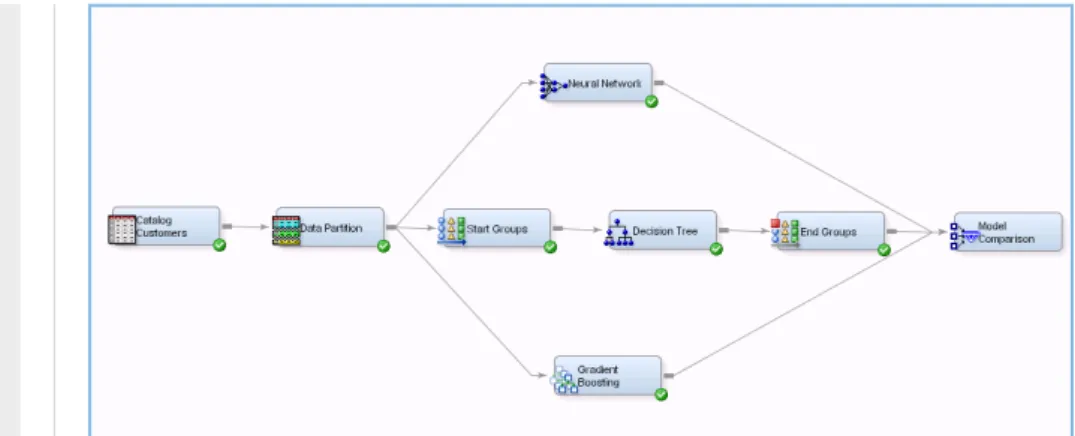
タスクのカスタマイズ • さまざまなビジネス問題の予測モデルを 自動生成 • 作 成したモデ ル はSAS Enterprise Minerで開き、強化や変更が可能 • 利用と検討が簡単に行える、変数重要性 リフトチャート、ROCチャート、モデル・ス コアカードを含む簡潔なレポートを作成 • トレーニング・データをスコアリングでき、 スコアリングされたデータセットを保存す るオプションも利用可能図13. Start and End GroupsノードとDecision Treeノードを使用して、バギングおよびブースティング・ モデルを作成。
図14. SAS Enterprise GuideまたはSAS Add-In for Microsoft Office (Microsoft Excelのみに対 応)でSAS Rapid Predictive Modelerタスクを使用し、さまざまなビジネス課題について予測モデルを 自動生成。
SAS Institute Japan
株式会社www.sas.com/jp
jpnsasinfo@sas.com本社 〒106-6111 東京都港区六本木6-10-1 六本木ヒルズ森タワー 11F Tel: 03 6434 3000 Fax: 03 3434 3001
大阪支店 〒530-0004 大阪市北区堂島浜1-4-16 アクア堂島西館12F Tel: 06 6345 5700 Fax: 06 6345 5655
このカタログに記載された内容は、改良のため予告なく仕様・性能を変更する場合があります。あらかじめご了承ください。
SAS、SAS ロゴ、その他の SAS Institute Inc. の製品名・サービス名は、米国およびその他の国における SAS Institute Inc. の登録商標または商標です。
その他記載のブランド名および製品名は、それぞれの会社の商標です。Copyright©2011, SAS Institute Inc. All rights reserved. JP2011_EM_SE
SAS
®Enterprise Miner
™システム要件
SAS Enterprise Miner の詳細なシス
テム要件、ホワイトペーパーのダウン
ロード、スクリーンショットの確認、関連
資料の閲覧については、
http:
//
www.
sas.com
/
jp
/
platform
/
analytics
/
datamining
/
em.html
をご覧ください。
スコアリング
• Scoreノードでは、SAS Enterprise MinerのGUIを用いて対話操作でスコアリングを実行可能
• 最適化されたスコアリング・コードがデフォルトで作成され、使用されない変数は除外
• SAS、C、Java、PMML(バージョン3.1)でスコアリング・コードを自動生成
• SAS、C、Javaのスコアリング・コードは、モデリング、クラスタリング、変換、欠損値補完用のコード をキャプチャ
• SAS Scoring Acceleratorを併用することにより、Teradata、IBM DB2、Netezzaデータベース 内でSAS Enterprise Minerのモデルを直接スコアリング可能
• 複数の環境にモデルを展開
モデルの登録と管理
• SAS Enterprise MinerのモデルをSAS Metadata Serverに登録可能
• SAS Model Managerとの統合により、スコアリング・コードのバージョン管理、開発から本稼働ま でのモデルのライフサイクル管理、モデルの監視が可能
• スコアリング用モデルに関して、SAS Enterprise Guide、SAS Add-In for Microsoft Office、
SAS Data Integration Studioとの統合を提供
• 事前トレーニングからの最大事象精度 (Max Event Precision from Training
Prior)
• 事象精度の同等再現率
(Event Precision Equal Recall)
• プロファイラーが対話操作型のグラフィッ クス環境を提供: • 同一または別個のファミリーに属する 競合モデルの比較と対照 • 変数の重要性と、予測された反応に及 ぼす影響を評価 • 計測対象の結果に合わせて最適な関数 設定を特定(シミュレーションを含む)
Reporter
ノード• SAS Output Delivery Systemを用い てプロセスフローのPDFまたはRTFを 作成可能
• 分析プロセスの文書化を支援し、結果の 共有を促進
• ドキュメントはSAS Enterprise Miner
の分析結果パッケージ内に保存およびイ ンクルード可能 • プロセスフロー・ダイアグラム(PFD)の イメージをインクルード可能 • ユーザー定義のノートエントリ 図15. Model Comparisonノードを使用して、理解しやすい単一のフレームワークで複数のモデルを同時 に評価。