Blind Source Separation of Acoustic Signals Based on Multistage Independent Component Analysis
6
0
0
全文
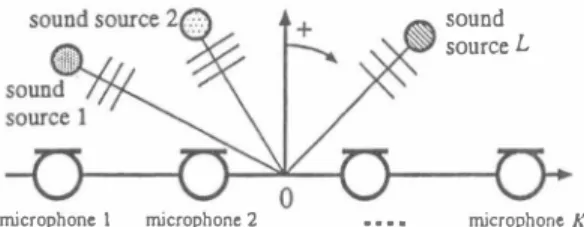
(2) (F3) The separation performance is saturated before reach. sound source L. ing a sufficient perform姐ce because the independence assumption collapses in eaιh narrow-band [ 15] (see,e.g., Sect. 5.2). (F4) Permutation among source signals and indeterminacy. microphone. Figure 1:. 1. microphonc 2. ・・・・. microphone. of each source gain in each subband.. K. Configuration of microphone array and sig. nals.. are explained. In Section 4, the proposed MSICA is de scribed in detail. In Section 5,the signal-separation experi ments are described and the results are compared with those of the conventional methods. Following a discussion on もhe results of the experiments,we give conclusions in Section 6.. 2. Sound Mixing Model of Microphone Array. In this study, a straight-line array is assumed. The number of町ay elements (microphones) is K血d the number of multiple sound sources is L (see Fig. 1),阻d we deal with the case of K = L = 2. In general, the observed signals in which multiple source signals are mixed linearly are given by the following equation in the frequency domain: X(f). = A(f)S(f),. (1). where X(f) is the observed signal vector,S(f) is the source signal vector, and A(f) is the mixing matrix (see Fig. 2); these are given箇 X(I) S(I). = =. A(f). 一. [ X1(1), ・. ,XK(fW , [ Sl(1),・ ・ ・,SL(fW , A{f) A {f). [. (2) (3). l. As for disadvむltage (F4),various solutions have already been proposed [ 11,16,17,18]. However,the collapse of the ind← pe凶ence assumption, (F3), is a serious and inherent prob lem,阻dぬis prevents us from applying FDICA in a real aιoustic environment wiもh a long reverberation. 3.2. Advantages: (Tl) We c担 treat the fullband speech signals where the. independence assumption of sources usually holds (T2) High-convergence possibility near the optimal point. Disadvantages: (T3) The iterative rule for FIR-fìlter learni時is compli. cated. (T4) The convergence degrades under reverberant condi. tions. おis known that TDICA works only inぬe case of mixtures with a short-tap FIR fìlter, i.e., less th姐 100 taps. AIso, TDICA fails to separate source signals under real acoustic environments because of disadv組tages (T3) 阻d (T4).. 4 (4). Time-Domain ICA. In the conventional BSS based on TDICA, each element of the mixing matrix is represented as a FIR filter. We can optimize its inverse, i.e., form a且inverse fìlter system, by using the fullband observed signals themselves. TDICA hω the following advantages and disadvantages.. Proposed Method: Multistage ICA. [19, 20]. Advantages:. As described above,ぬe conventional ICA methods have some disadvantages. However,note that the adv担tages and disadvantages of FDICA 担d TDICA are mutually comple ment紅あi.e., (F3) c姐 be resolved by (T1) 回d (T2),回d (T3) 回d (T4) c阻 be resolved by (F1) and (F2). Hence,in order to resolve the disadvantages, we propose a new algo rithm,MSICA,in which FDICA 阻d TDICA are combined (see Fig. 2). MSICA is conducted with the following steps. In the fìrst stage, we perform FDICA to separate the source signals to some ex旬nt with the high-stability advantages of FDICA, (F1) 担d (F2). In the second stage,we regard the separated signals of FDICA as the input signals for TDICA,阻d we remove the residual crosstalk components of FDICA by using TDICA. Finally, we regard the output signals of TDICA as the resultant separated signals. MSICA c阻 achieve a high stability and a separation performance superior to that of conventional FDICA組d TDICA. In the following sections, we describe details of the ICA・learning rules for each stage.. (Fl) We c阻 simplify the convolutive mixture down to si. 4.1. AK1 (f). ー.. AKL(f). In this case, A (f) is the mixing matrix which is assumed to be complex-valued because we introduce a model to deal with the arrival lags among the elements of the microphone array and the room reverberations. 3 3.1. Conventional ICA and Its Problems Frequency-Domain ICA. The conventional BSS based on FDICA is conducted with the following steps: (1) transform the observed fullband sig nals into the narrow-band signals, (2) optimize the inverse of the mixing matrix A(f ) in each subbband,回d (3) recon struct the fullb姐d separated signal仕om the narrow-band separated signals. FDICA has the following adv阻むages組d disadvantages.. multaneous mixtures byぬe frequency transform. (F2) 1も is easy to converge the separation fìlter in iterative. ICA learning with high stability.. D is advant a ge s :. First-Stage ICA: Frequency-Domain ICA. In the fìrst・stage ICA, we introduce the fast-convergence FDICA proposed by one of the authors [ 13]. We perform the signal separ抗ion procedure as described below (see FDICA in Fig. 2).. Aせ ph.u.
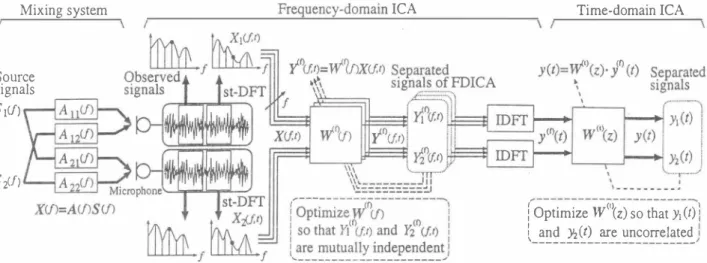
(3) Frequency-domain ICA. Mixing syst巴m. Time-domain ICA. Source signa!s S t<f). 一. 戸. 、 F V J n り 一 v ρ 一 ♂州 一 町 rL J 山 一 一 dh um一 一 d句一 nd -、 J免 uF n u 一 r F J EEη ,t ハリf 一 h 1 V 恥ν' 《 リ , t‘、 , けu,m M一 n J m 一 ・ I t nu e a H U U 1 n n -剛t t ← 0sほ γ h 一 C a. S2(/). Blind source separation procedure performed in multistage 1CA.. 1n FDICA, fust, the short-time analysis of observed sig nals is conducted by frame・by-frame discrete Fourier tr担任 form (DFT). By plotting the spectral values in a frequency bin of each microphone input frame by仕組le, we consider them as a time series. Hereafter, we designate七he time se ries ω X(/,t) =[ X (/, t) , ・・., XK(f,t W . Nex七, we per form signal separation using the complex-valued inverse of so that the L time-series output the mixing matrix, y(f)(/,t) = [巧(f (/, t),.・., yj,f) (/,t)]T becomes mutually in dependentj this procedure can be given as. 1 W(f)(f),. ). y(f)(/,t). =. W(I)(z) so that Yl (1) 1. (and乃(t) are uncoηe!ated. 一. 」. Figure 2:. r Optimize. W(f)(/)X(/, t).. (5). ) t),. d. (W z ). �b). where B is山number of local analysis blocks. �b)(吋is the∞削atìon matrix of the 抑制ted均叫s,i.e., �b)(η) denotes the time-averaging = (ν(t) ν(t ー ) ,where operator for the b-th local analysis block,ν(t) is the result阻t separated signal vect民組dW(り(z) is the z-transform of the S叩al前ion釦ter coefficientω(t)(n) ( = ,・ ・ ・,N l)j these are glVen as. 吋T P. (・)�b). η 0. -. W. (10). ) 噂A 唱A ,, ,‘、. ν(t) = [Yl(t),・..,YL(tW =W(り(z) . y(f)(t),. ). 山 玄. We perform this procedure with respect to all仕equency bins. Finally,by applying the inverse DFT an<:i the overlap add technique to th� �ep�ated time series y (f (/, we re construct the resultant source signals in the七ime domain, ν(f (t). 1� �onventional FDICA ,the optimal W(f) (1) is obtained by the following iterative equation [11]:. Fig. 2). We separate the sources by minimìzing the non negative ∞st function which takes the minimum value only when the second-order cross-correlation becomes zero if the source signals are nonstationary. The cost function can be given as [ 14) 1 Lj det di乱g �b)(O) 1 Q /,.. (\ 't)J ('-'/ log )1 一 一 〉 イl--o (9) }, 2B 会 det (0) J �. n=O. W�21(/) = W�f)(/) +η [di州 φ川(川y(f)(川) t ) 一(φ(y町の)y(勺. where (・)t denotes the time-averaging operator, i is used to express the value of the i・th step in the iterations,and ηìs ぬe sもep-sìze parameter. Also, we define the nonlinear vector function éþ(・)as. éþ(y(勺, t))三[φ(巧(り(/,t)),..., �(百円1, t))]T, (η φ巧 ( (η (/,t))三[1 + exp(-Re[巧 (/, t mr1 + j.. (り [1 + exp(-1m[巧 (/,t) ]). r1,. output of FDICA. Equatìon (9) becomes zero only when Yi(t)阻d Yi (t) are uncorrelated for all of the local analysis blocks . Calculating the natural gra的凶 [21) of Q W仰(z) ,明obtain もhe it erative equation of the separation fìlter ω(I)(n) to minimize Eq. (9) as [19). (. ). (wf)(z))wP(z)Twf) (z) ω��l1- 1 ( ) =ω?}(η)-2δQ B θ旬�t)(n). (7). π., ,.. -,. ,..,. B. =イ)(n)+�L{ 可>(0)一司)(n). (8). where Re[巧(f)(/,t)] and 1m[Yj(f)(/,t) ] are the real and imag inむy parts of巧(f (/, t), respectively.. ). 4.2. where Z-l is used ωぬe unit-delay operator for convenience, i.e., z-n . x(t) = x(t - n), 担d ν(f) (t) is the time-domain. Second-Stage ICA: Time-Domain ICA. 1n the second-stage ICA, we introduce七he TDICA which uses nonstationarity of七he source signals (see TDICA in. b=l. - (白州)(0)r1�b)(吋 W;I)(Z),. (12). where αis the s旬p-size 阿ameter. Equation (12) evaluates only off-diagonal of and we note that this is not sufficient for the separation under heavi1y reverber阻も con di七i ons [19]. Therefore we expand Eq. (12) to the following. R�b\O),. Fhd Fhu.
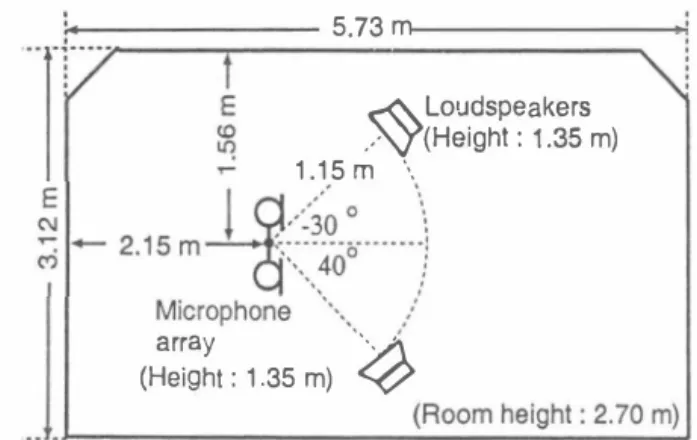
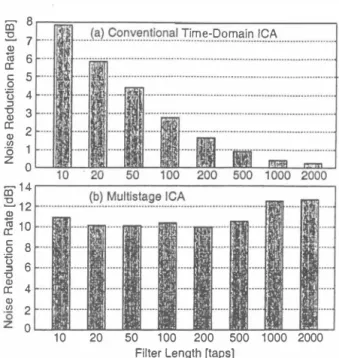
(4) rr 15 i. 品 2.. 5.73m. ciì 10 '0. $. 8. 6 () コ. 6. 伺 α. 1.15 州?132m). ℃ 。 広 。 的 。 z. 斗が ). ょ;:t:135m)φ. Figure 4:. Relation between separation perform乱nces and the number of subbands in conventional FDICA.. Figure 3: Layout of reverberant room used in experi ments.. 叩ation to evaluate the off-d.iagonal of delays n:. �b) (n) for all time. B. ωjtl(η)=吋)(n)+i�二{(d.ia叫め (0))ー1dia例的 (η) 一(d.iagR�b) (0) ) -1R�b) (π)) }W;t)(z) 川) 5 5.1. Experiments and Results Experimental Setup. A two-element釘ray with the interelement spacing of 4 cm is assumed. The speech signals are assumed to むrive仕om two d.irections, -300担d 400 (d.irection normal to the包-ray is set to be 00). The d.ist回ce between the microphone aπay 阻d the loudspeakers is 1.15 m (see Fig. 3). Two kinds of sen tences, spoken by two male and two female speakers selected from the ASJ continuous speech corpus for research [22], are used as the original speech samples. The sampling仕equency is 8 kHz and the length of speech is limited to within 3 sec onds. Using these sentences, we obtain 12 combinations with respect to speakers但d source d.irections. As for the mixing system, we use the impulse responses recorded in a real room with the reverberation time of 300 ms. In order to evaluate the performance, we used the noise reduction rate (NRR), defined出the output SNR in dB minus input SNR in dB. 5.2. Relation between Separation Performance and Number of Subbands in FDICA. In order to confirm the low-independence problem of sub band sign山in FDICA ((F3) described in Sect. 3.1), we car ried out the preliminary experiment under the following anal ysis cond.itions. The number of subbands (企ame length in DFT) is set to be from 32 to 4096,ぬe fr担le shi仇is 16 taps, the window function is a Hamming window, the number of iterations in ICA is 30, and the step-size parameterηfor iterations is set to be 1.0 x 10-5• Fi思ue 4 shows the NRR results for different numbers of subbands in FDICA. As shown in Fig. 4, the NRR of FDICA obviously degrades when the number of subb姐ds becomes too large, and the separation performance is saturated be fore reaching a sufficient performance. This is because we transform the fullband signals into the narrow-band signals. and the independence assumption collapses in each frequency band, particularly when the number of subbands is large In order to confirm the fact, we newly define the following objective measure to quantify an independence, and investi gate七he relation between the number of subbands and the independence among subb回d signals. J. = ( 11 拘 ((φ (Y (μ)) yH (f,t))t) 一(争 (Y (九収. where 11・11 is frobenius norm of matrix. This measure J is a part of the iterative equation (6). If narrow-band sig nals become mutually independent, the measure J becomes zero. Also we can consider that the independence of subband signals is high when J is small. In order to evaluate the inde pendence of real nan'ow-band speech signals, we carried out the experiment in which the input signal, Y (f , t) , in Eq. (14) is regむded as the perfectly separated sources, i.e., original speech samples. Figure 5 shows the relation between the number of subb回ds and the value of J which corresponds to the independence of subband signals. Figure 5 shows th品t the independence decreases as the number of subbands in creases, especially when the number of subbands is large. Above-mentioned experimental results clarify the d.isad vantage that the separation perform阻ce is saturated in FDICA because we transform the fullband signals into the narrow-b担d signals. We should lengthen the separation fil ter (or FFT length for analysis) when we confro凶with a long reverberation. In this case, however, the independence of subband signals decreases. Thus, there is a trad←off.re lation among the independence of subband signals and ro・ bustness against reverberation as shown in Figure 6. On the basis of these results, we should cascade another signal processing analysis, e.g., TDICA, with FDICA to obtain the further separation perform臼ces. 5.3. Relation between Separation Performance and Filter Length in TDICA. We carried out the experiments using TDICA回d MSICA to evaluate the contribution of increments of separation-filter length for improving the sep位以ion performances under re・ verberant conditions. The analysis cond.itions of these ex periments are as follows: the filter length N is set to be from 10 to 2000 taps, the maximum number of iterations is 500,. -156 -.
(5) 号. which corresponds. Æ. 10. Q) a: 由 由. 2. c. 8 s u コ 6 匂. to the independence of subband signals.. 呈. 4. ωH 国江cozuコ℃ωZO回一 oz. 0. 10. 20. 50. 100. 200. 500. Filter Length [taps]. 1000 2000. Figure 7:. Relation between sepa.ration performance and fil ter length in (a) TDICA 臼d (b) TDICA pa川in MSICA.. Sma". Number of Subbands. Large. Figure 6: Trade-off relation among the independence of subband signals and robustness against reverberation.. and the step-size pa.rameterαfor iterations is set色o be 1μv. As for the local 姐alysis block, we divided the signals equally into B pa.rω(B = 1 '" 10). We chose the optimal B 阻d number of iterations for each fìlter length because the con vergence is differe凶for every fìlter length. As for the FDICA pa.rt in MSICA, the analysis condiもions釘e the same as those given in Sect. 5.2, except for the number of subb組ds (which is fìxed at 1024 b姐ds). Figures 7(a) and (b) show the NRR results in the con ventional TDICA 回d MSICA for different filωr lengths. As shown in Fig. 7(a), when the sepa.ration fìlter is lengthened, the sepa.ration perform回ce of the conventional TDICA de grades. This also implies that the simple TDICA sepa.rates only the direct components of a.rriving signals. On the other h阻d, in Fig. 7(b), the sepa.ration performance of MSICA is improved when色he fì1七er length is longer. This reveals色ha色 the TDICA part in MSICA can sepa.rate the source signals even with the reverberation components, and the TDICA is stilJ useful nea.r the optimal point. 5.4. au 7' 内b RUA崎 qu 内4 噌,nv. { ∞℃]由戸 国ECOZUコ℃由広 由由一 oz. (14),. ICA. 4 iiì 1 12. Figure 5: Relation between the number of subbands and the value of J defined by Eq.. Time-Domain. Comparison. between. Conventional. ICA. and MSICA. We compared the performance of the proposed MSICA with that of the conventional ICA under the reverberant condi-. tion. As for FDICA, the analysis conditions a.re the s担1e as those given in Sect. 5.2, except for the number of sub bands (which is fìxed at 1024 b姐ds). As forぬe conventional TDICA, the number of local analysis blocks, B, is fìxed at 3 blocks, the number of iterations is 400, and the臼ter length is 10 taps. As for the TDICA pa.rt in MSICA, the number of local 阻alysis blocks, B, is fìxed at 9 blocks, the number of iterations is 400, and the臼ter length is 1000 taps. Figure 8 shows the NRRs of the conventional FDICA, con ventional TDICA, 回d MSICA. In this fì伊re, we sepa.rately plot the NRRs for different combination of speakers, and the averages of their NRRs. The results reveal that the sep a.ration performances of the proposed MSICA紅e superior to those of the conventional FDICA and TDICA with every combination. Specifìcally, compa.red with the conventional ICA, the proposed method c回 improve the NRR by about 2.7 dB over that of FDICA担d by about 6.2 dB over that of TDICA, for阻 average of 12 combinations. As described in Sect. 5.2, the FDICA in this study showed the saturation of NRR when we used the 1024・subband臼al ysis. As dωcribed in Sect. 5.3, the simple TDICA could no色 sep紅ateぬe source signals accurωely under the reverbera瓜 condition. These fìndings indicate the praιtical limitations of the sepむation performances of conventional ICA-based BSS methods; From the results of Fig. 8, however, we c回 con fìrm that the proposed MSICA can inherently remove these limitations, and is effective for improving the sepa.ration per formance担d convergence under reverber血色 conditions. 6. Conclusion. In this paper, we propose a new algoriぬm for BSS, in which FDICA 回d TDICA a.re combined to achieve a superior source-sepa.ration performance under reverberant conditions. The results of the signal sepa.ration experiments reveal that the sepa.ration performance of the'proposed algorithm is su-. ウi 「「U 1lム.
(6) [10] A. Bel1 and T. S吋nowski, “An informaもion maximization approach to blind separation and blind deconvolution," Neural Computation, vol. 7, pp.1129-1159, 1995.. 16H ・Tlme-Domain ICA Frequency-Domain ICA 1 4トl 回MultistageICA. I I I:lll. � 号12�..............", i2. 10�.・・ 5 ・ g 8r ∞. [11] N. Murata and S. 1keda,“An on・line algorithm for blind source separation on speech signals," Proc. of 1998 In・ temational Symposium on Nonlinear Theory and Its Application (NOLTA98), pp.923-926, Sept. 1998.. 官. o g o z. 韮6. 1. 2. 3. 6. 4 5 Comblnatlon. 7 8 9 01 Speakers. 10. 11. 12. Average. Figure 8: Comparison of noise reduction rates obtained by. MS1CA,conventional FD1CA and the conventional TDICA.. perior to that of conventional 1CA-based BSS methods,and the combination of FD1CA 担d TD1CA is inherently effective for improvingぬe separation performance. Specifically, the proposed method can improve the SNR by about 2.7 dB over that of FDICA 担d by about 6.2 dB overぬat of TDICA, for an average of 12 speaker-combinations. ケ. Acknowledgement. The authors are grateful to Dr. MitsuruKawamoto of Shi m姐e University, Dr. Shoji Makino, Miss Shoko Araki 回d Mr. Ryo Mukai of NTT. CO., LTD. for their useful discus sions. This work was partly supporωd by CREST (Core Research for Evolutional Science 姐d Technology) in Jap阻. References. [1] T. W. Parsons,“Separation of speech from interfering speech by me阻s of harmonic selection," J. Acoust. Soc. Am.,vo!.60,pp.911-918, 1976. [2] K.Kashino,K. Nakadai,T.Kinoshita,阻d H. Tan山, “Organization of hierarchical perceptual sounds," Proc. 14 th Int. Conf. Artポcial Intelligence, vo!.1, pp.158164, 1995. [3] M. Unoki and M. Akagi,“A method of signal extrac tion from noisy signal based on auditory scene姐alysis," Speech Communication, vo!.27, pp.261-279, 1999. [4] G. W. Elko,“Microphone array systems for hands-free telecommunication," Speech Communication, vo!.20, pp.229-240,1996. [5] T. W. Lee, Independent component analysis, Kluwer academic publishers,1998. [6] S. Haykin, Uns叩ervised Adapti凹Filtering. New York, NY: John Wiley & Sons, 1nc., 2000. [7] J. F. Cardoso,“Eigenstructure of the 4th-order cumu・ lant tensor with applicationもo the blind source separa tion problem," Proc. ICASSP '89, pp.2109-2112,1989.. [12] P. Smaragdis,“Blind separation of convolved mixtures in the frequency domain," Neurocomputing, vo!.22, pp.21-34,1998. [13] H. Saruwatari, T.Kawamura,血dK. Shikano,“Blind source separation for speech based on fast-convergence algorithm with 1CA and beamforming," Proc. Eu rospeech2001, pp. 2603-2606, Sept. 2001. [14] M.Kawamoto,K. Matsuoka,N. Ohnishi, "A method of blind separation for convolved non-stationary signals," Neurocomputing, 22, pp.157-171, 1998. (15] S. Araki, S. Makino, T. Nishikawa, H. Saruwatari, “Fundamental limitation of仕equency domain blind source sepむation for convolutive of speech," Proc. ICASSP2001, pp.2737-2740, May 2001. [16] S. Kurita, H. Saruw品.tari, S. Kajita,K. Takeda,出d F. Itakura, “Evaluation of blind signal separation method using directivity pattern under reverberant con ditions," Proc. ICASSP2000, pp.314(ト3143,June 2000. [17] L. Parra祖d C. Spence,‘'Convolutive blind separation of non-stationary sources," IEEE Trans. Speech and Au dio Processing, vo!.8,no.3, pp.320-327, May 2000. [18] F. As姐0,S. 1keda, M. Ogawa, H. Asoh, N. Kitawaki, “A combined approach of array processing and indepen dent component analysis for blind separation of acoustic signals," Proc. ICASSP2001, pp.2729-2732, May 2001. [19] T. Nishikawa, H. Saruwatari, 阻dK.印刷0,“Blind source separation based on multi-stage 1CA using frequency-domain ICA and time-domain ICA," Proc. The Intemational Conference on .F\mdamentals of Electronics, Communications and Computer Sciences ρCFS2002), pp.(1-7)一(1-12) ,March 2002.. [20]. T.. Nishikawa, H. Saruwatari,回d K. Shik回0,“Com・ parison of time-domain ICA, frequency-domain ICA 阻d multistage ICA for blind source separation," Proc. XI European Signal Processing Conference (EU SIPC02002), Sept. 2002. (in printing). [21] S. Amari,S. C. Douglas, and A. Cichocki,“Multichan・ neI blind deconvolution 姐d source separation Using the Natural Gradient," IEEE Trans. Signal Processing, Sept. 1997. [22] T.Kobayashi,S. Itabashi,S. Hayashi,姐d T. Takezawa, "ASJ continuous speech corpus for research," J. Acoust. Soc. Jpn., vo!.48, no.12, pp.888-893, 1992 (in Japanese).. [8] C. Jutten 担d J. Herault,“Blind separation of sources part 1: An adaptive algorithm based on neuromimetic architecture," Signal Processing, vo1.24, pp.1-10,1991. [9] P. Common,“1ndependent componenも analysis,a new concept?," Signal Processing, vo!.36,pp.287-314, 1994.. 口6 Fhd t,A.
(7)
図
+2

関連したドキュメント
Keywords: continuous time random walk, Brownian motion, collision time, skew Young tableaux, tandem queue.. AMS 2000 Subject Classification: Primary:
This paper develops a recursion formula for the conditional moments of the area under the absolute value of Brownian bridge given the local time at 0.. The method of power series
It is well known that the inverse problems for the parabolic equations are ill- posed apart from this the inverse problems considered here are not easy to handle due to the
Then it follows immediately from a suitable version of “Hensel’s Lemma” [cf., e.g., the argument of [4], Lemma 2.1] that S may be obtained, as the notation suggests, as the m A
In order to be able to apply the Cartan–K¨ ahler theorem to prove existence of solutions in the real-analytic category, one needs a stronger result than Proposition 2.3; one needs
Classical definitions of locally complete intersection (l.c.i.) homomor- phisms of commutative rings are limited to maps that are essentially of finite type, or flat.. The
Yin, “Global existence and blow-up phenomena for an integrable two-component Camassa-Holm shallow water system,” Journal of Differential Equations, vol.. Yin, “Global weak
Takahashi, “Strong convergence theorems for asymptotically nonexpansive semi- groups in Hilbert spaces,” Nonlinear Analysis: Theory, Methods & Applications, vol.. Takahashi,
