HTML Table情報のXMLによる統合
8
0
0
全文
(2) 1. はじめに. 英語 II. 本稿では、WWW ページ上に別々に存在する、複 数の「内容の類似した表」を、その中のデータの意. 学年: 2 年. English II. 学期: 前期. 担当教官名: 鈴木 太郎. 味を解析し、分類することにより、それらを1つの. [科目名]. 音楽. [教官]. 佐藤. [開講学期]. 未定. [学年]. [単位] 2. 3. 共通の表構造に変換し、統合するための手法を提案 する。 現在、WWW の普及により、世界中に分散された 多様な文書情報に簡単にアクセスすることが可能と なったが、その多様さゆえにユーザは何らかの形で、. 科目名(和) 英 語. 科目名(英). EnglishII. 音楽. 教官名. 学年. 学期. 鈴木太郎. 2年. 前期. 佐藤. 3. 未定. 単位. 2. これらの情報を整理する必要がある。情報をどのよ 図1. うに整理するし、統合するかについては様々な方針. 表の統合の動作例. が考えられるが、本研究では、まず第一段階の試み と し て 、 表 、 す な わ ち HTML の Table タ グ. 空会社のフライト情報の一覧といったものへの適用. (<TABLE></TABLE>)で囲まれた部分に着目し、表. も考えられるため、情報統合の最も有効な例として. の統合を行うことを目指した。. 表を取り上げた。. 次節以降まず第 2 章では、表の統合における本研. 本研究が目指す、HTML Table の XML による統. 究の目標、およびこれまでの関連研究について述べ. 合を行うためには、まず各ページの表が、 「どのよう. る。そして第 3 章では、本稿で用いる用語の定義を. な構造で、どのような情報を表現しているか」の解. 解説し、第 4 章では、我々の実験手法の詳細な説明. 析が必要となり、さらに解析された情報から、意味. を行う。第 5 章では、実験結果・考察を示し、最後. 的に類似したデータ同士を分類する必要がある。例. に第 6 章で、今後の課題について述べる。. えば、 「 住所」と「住居」、 「 メールアドレス」と「E-mail」 と「e メール」、「誕生日」と「生年月日」、等は同一. 2. 表の統合. の内容を表しているはずであり、このように、表現. 2.1 問題設定. が異なっていても、内容的には同じであるというよ. WWW 上に点在する、内容の類似した表を、XML の形で 1 つに統合することができれば、それは各ペ. うに自動分類されるような方法の提案を試みる。. 2.2 先行研究と本研究のアプローチ. ージの表情報の一覧となり、それらを一目で比較す. HTML ページを XML ページに変換する研究とし. ることが出来るようになる。XML では HTML と異. ては[1]がある。これは XWRAPElite とい う wrapper. なり、目的に応じて自由にタグを定義することが可. を作成し、HTML ページのコンテンツを解析するこ. 能である。そのため、各データに対し、意味による. とにより、 ブ ラウジング の ための記号 で しかない. タグ付けをすることができ、表の統合を実現する手. HTML タグのページを、意味のある XML タグのペ. 段として最適であると考えられる。. ージに変換させるというものである。この. 図 1 に本手法が目標とする動作例を示す。この例. XWRAPElite は、いくつかのヒューリスティクスを. では、各大学の授業科目情報についての表(HTML). 用いて HTML ページから情報抽出を抽出する。まず、. を、1 つの表(XML)にまとめている。Web 上の表形. HTML タグ構造を利用してページ全体を表現する. 式のデータは多く、授業科目情報だけでなく、例え. tree を作成する。そこである大きさ以上の sub-tree. ば、各種の製品情報の一覧(カタログ)、あるいは各航. を Object として抽出する。さらに Object から、. 2 −132−.
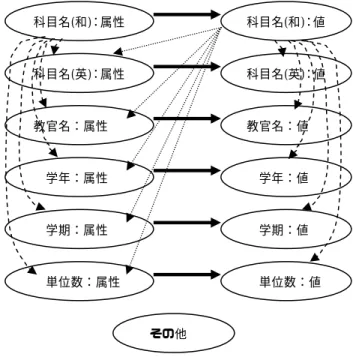
(3) <tr>,<td>,<br>,<font>といった細かい HTML タグ をデリミタとして Element を抽出する。次に、人手 によってルールを作成し、似通った Element をグル ープ化し、各グループに XML タグを付加する。 XWRAPElite では、HTML ページ全体を対象とし、. [科目名]. 音楽. 属性. 値. [教官]. 佐藤. 属性. 値. [学期]. 未定. 属性. 値. [学年] 3. [単位] 2. 属性. 値. 属性. 値. 図 2. 授業科目の表の例とその論理構造. 文字列マッチングや出現順序に基づいて、各 Element を分類している。 本稿では、前述のアプローチとは異なり、対象は HTML ページ内の表(Table)情報に限定するが、表デ. 2.3 用語の定義. ータを意味に基づいて分類する。本稿では、この「表. 表は、1 つまたは複数の実世界に存在するオブジ. 中データの意味による分類」というタスクに対し、2. ェクトを属性により表現したものである。図 2 に授. つの解決法を提案し、実験を通してその有効性を調. 業科目の表の例を載せる。この表では、科目オブ. べる。. ジェクトを、「科目名」「英文科目名」「教官名」「学. WWW 上の表からのオントロジー抽出については. 期」 「単位数」という 6 種類の属性と、その値 を用い. [2]の研究がある。これでは EM アルゴリズムを用い. て記述している。つまり、スキーマとはある表に表. て表構造を推定するという内容である。これに対し、. 記された属性の集合である。. 本稿では、各表から細かくデータを切り出し、各々. また表は、複数のセルが 2 次元に配置された行列. の デ ー タ に 記 述 さ れ て い る 内 容 を 、 (I) Support. として捉えることができる。セル内に表記されてい. Vector Machine(SVM)によるクラス分類、(II) 隠れ. る語を、ここでは要素語と呼ぶことにする。. マ ル コ フ モ デ ル (HMM) の 状 態 遷 移 を 用 い て 分 類 するという 2 つの手法を試みている。. 同じ種類のオブジェクト(例えば科目情報)を持つ、 複数の表を統合するためには、まず各表の中で、 「属. SVM を使ったクラス分類は、とりわけテキスト分. 性を記述している部分」と「値を記述している部分」. 類の研究[3]に用いられることが多い。しかし本研究. を判別する必要がある。表中の各セルの要素語が、. においては、テキストではなく、表中の各データ(単. 属性であるか値であるかに関する仮説を、表の論理. 語、あるいはフレーズ)の分類のためにこの SVM を. 構造と呼ぶ。図 2 に表の論理的構造を示す。. 用いた。 また、HMM を用いた情報抽出に関しては[4]のよ. 3. 実験概要. うな研究がある。ここでは、より正確なターゲット. 本章では、各表から要素語を抽出し、その各々に. 文字列を抽出するために、EM アルゴリズムにより. 記述されている内容を自動判別し、分類するための. 繰り返し重み付けを行い、最適な HMM の状態遷移. 提案手法について述べる。またそれらを 1 つの XML. 構造を自動的に見つけるということが行われている。. の表にまとめる手法についても言及する。. 一方、本研究においては、EM アルゴリズムによる. 3. 1 対象データ. パラメータ推定は行わず、あらかじめ HMM の学習. 今回は、日本の 20 大学における授業科目情報の. モデルを独自に決定しておき、そこから Viterbi アル. HTML ページ、約 10,100 ページを対象に実験を行. ゴリズムを用いて、出力遷移系列を求める、という. った。図 3 に本手法の流れを示している。 各 HTML ページの Table から要素語を抽出するた. 最も単純な方法で行った。そして最終的には、1 つ の XML の表に統合している。. め、まず<TD><TH>タグを区切りにデータを切り出. 3 −133−.
(4) 情報抽出・分類 HTML Table. 要. 形. 素. 態. 語. 素. 抽. 解. 出. 析. SVM による. 1 つに統合 共通の XML. クラス分類 HTML Table. HMM による. 共通の XML. 表構造推定 HTML Table. 共通の XML. 図3. (a) 全て属性がついいる表. 本実験全体の流れ. す。各要素語に分けるため、 「:」 「;」 「・」などの デリミタをセパレータとして、データを切り出す。 次に、上で取り出された各要素語を、その意味に より幾つかのグループに分類することになるが、詳 細については、次節以降で述べる。ただし、この 2 (b) 全く属性のない表. つのどちらの手法を実行するにあたっても、前もっ て全ての要素語に対し、形態素解析を施しておく必 要がある。 各要素語を、その指し示す意味によって幾つかの グループに 分 類した後、 その各グルー プ に対し、 XML タグを付加する。XML では、タグを自由に定 義することができるため、 「データの意味によるタグ 付け」が可能となる。その結果、各 HTML ページの. (c) 一部に属性がついている表. 全く構造の異なる表は、規定された共通の表に変換 されることとなり、全てを 1 つにつなげることが可 図4. 能となる。今回、この XML ページを表示するにあ. 実験で使用した表の例. たって、W3C による 1999 年勧告仕様 XSLT を用い た。また、XML パーサは MSXML3 を使用している。. Vapnik によって提唱されてきたが[6]、その性能が. また、今回の実験で使用した、様々な大学の授業. 注目され始めたのは最近のことである。現在では、. 科目情報の Table の構造は図 4 のように全くマチマ. 様々な応用に用いられており、例えば手書き数字の. チであり、属性がすべてついているもの(図 4(a))、図. 認識、顔画像の検出、話者特定など、その範囲は幅. 属性の全くついてなく値だけのもの(図 4(b))、一部属. 広い。SVM をテキスト分類に応用した例も数多くあ. 性のついているもの(図 4(c))、というような具合であ. るが[3]、本研究ではテキストのような長い文章では. る。. なく、要素語という短いフレーズに対して、SVM を. 3. 2. SVM による要素語分類. 適用し、その内容によって分類することを試した。. SVM は、高性能なクラス分類器として注目を集め ている。その考え方自体は 1970 年代後半から. 今回の実験では、属性に対しては<属性>クラスを、 そして値に対しては、<科目名(和)>、<科目名(英)>、. 4 −134−.
(5) 科目名(和) 科目名(英) 教. 官 ・・・. 単. 5.2324. 3.2870. 0.23. English 0.9845. 6.5324. −1.24. −1.5672. 3.67. −2.4578. 英語. 佐藤. 1.1231. 2 単位 −1.2378. 図5. ー1.4527. −0.9523 −2.57. 科目名(和):属性. 科目名(和):値. 科目名(英):属性. 科目名(英):値. 教官名:属性. 教官名:値. 学年:属性. 学年:値. 学期:属性. 学期:値. 単位数:属性. 単位数:値. 位. 0.9987. SVM による複数クラスへの分類. <教官名>、<学年>、<学期>、<単位数>の 6 つのク ラスを、つまり各要素語が 7 つのクラスのいずれか. その他. に分類されるようにした。 まず、ある 1 大学の全ての授業科目の HTML ペー 図6. ジ(約 2500 ペ ー ジ)を ト レ ー ニ ン グ セ ッ ト と し て. HMM モデル 状態遷移図. SVM に学習させる。その際、学習データから抽出さ れた各要素語に対しては、人手によって、正解クラ. 力記号系列から、それを生成した状態遷移系列を一. スを与えた。そして、残り全ての大学の約 7600 ペー. 意的に復元することが出来ないため「隠れ(Hidden)」. ジの授業科目情報のページをテストセットとし、そ. という名前が付けられている。日本語の形態素解析. れらの各要素語を上に挙げた 7 つのクラスに分類し. において、HMM、観測可能な言語データから言語現. た。. 象の背後にある隠れた構造を推定する場合に有効な. 本来 SVM は 2 値分類のためのクラス分類器であ. モデルである。そのため、単語分割モデルや音声認. る。しかし今回の実験の場合、各要素語を 7 つのク. 識のための音響モデル、あるいは英語の品詞タグ付. ラスに分類しなければならない。そこで 7 つのクラ. けに使われる統計的言語モデルによく用られる。本. スそれぞれについて SVM 学習モデルを作成する。. 研究では、表中の各要素語に対し、この HMM を適. そして、各要素語について作成した 7 つの学習モデ. 用することを考える。. ルからの数値を算出し、 「各クラスの数値の中で最も. 本実験では、 「状態」を「属性あるいは値の種類」、. 大きな値をつけた要素語をそのクラスに分類する」. そして「出力記号」を「要素語を形態素解析したも. という手法をとった。具体的には図 5 に図示するよ. の」とする。そのモデルの様子を図 6 に示す。矢印. うな値を各列で選択する。この結果については、第. は状態遷移を表現しており、全部で 13 の状態を用意. 4 章で述べることにする。. した。. 3. 3. ここでは、20 大学それぞれから全体の約 20%、約. HMM による表構造推定. 前節と同様に、表中の各要素語を意味によって幾. 2000 の授業科目情報の HTML ページをランダムに. つかのグループに分類する方法として HMM の状態. 選びトレーニングセットとした。トレーニングセッ. 遷移を適用することを考えた。. トから要素語を抽出し形態素解析したものを出力記. HMM は確率的な状態遷移と確率的な記号出力を 備えた有限状態オートマトンである。観測された出. 号とした。その結果、状態数 13 で 13×13 の状態遷 移確率行列、そして出力記号数 約 10500 語で、. 5 −135−.
(6) <VSUBJ> 科目名(和) </VSUBJ>. <OBJECT>. <VSUBE> 科目名(英) </VSUBE>. <VSUBJ> 英語 </VSUBJ>. <VTEAJ> 教官名 </VTEAJ>. <VSUBE>English</VSUBE>. <VGRADE> 学年 </VGRADE>. <VTEAJ> 鈴木</VTEAJ>. <VSEM> 学期 </VSEM>. <VGRADE> 2 年</VGRADE>. <VUNIT> 単位数 </VUNIT>. <VSEM> 前期</VSEM>. 図7. 付与した XML タグ. <VUNIT> 1</VUNIT> </OBJECT>. 13×10500 の出力確率行列を持つ、学習モデルが作. 図8. 作成した XML の例. 成された。この学習モデルを基に、Viterbi アルゴリ ズムを用いて残りの科目情報の表の状態遷移系列を. XML タグを示す。このように全ての表から要素語を. 復元することを試みた。トレーニングセットに用い. 抽出し、図 7 で定めた 6 つのタグ構造に埋め込むこ. なかった約 8100 の表について、各表における要素語. とにより、1 つの共通の XML の表に統合される。. のみの連続列を入力とし、そこから推定される状態. またさらに、一つの表からの情報は、一つの object. 遷移系列が出力となる。つまり各要素語が 13 の状態. として<OBJECT></OBJECT>というタグで挟まれ. のうちのどの状態からの出力であるかを推定するの. る形となる。そして XSLT を用いて Web ページ上に. である。その結果については、第 4 章で述べること. 表示される。実例として、HTML Table からの情報. にする。. を XML の形でまとめたものを図 8 に、またそれを. 3. 4 XML タグの付与. XSLT スタイルシートを用いて Web ページに表示さ. 表から抽出された各要素語の値は、<科目名>、<. せた。. 英文科目名>、<教官名>、<学年>、<学期>、<単位. 4. 実験結果・考察. 数>の 6 つのグループに分類される。 XML の大きな特徴は、「タグを自由に設定し、そ. 第 3 章で述べた手法を、C, C++, Perl を用いて実. のタグに意味情報を与えることが出来る」という点. 装し、実験データとして得られた表の集合に適用し. にある。例えば、<血液型>A 型</血液型>というタグ. た。. を使うことで、A 型という文字列に「血液型」とい. 4.1 分類結果 SVM による要素後分類によって作成された XML. う意味を与えているのである。 このような XML タグのメタデータ的な性質を、. の表(図 9)と、HMM による要素語分類によって作成. 本研究では分類された要素語の意味付けとして用い. された XML の表(図 10)を、それぞれ各項目につい. る。具体的には、3.2 節 3.3 節でグループ分類された. て正解判定を行い正解率を計算したところ、表 1 の. 各要素語に対し「科目名の値」として分類された. ような比較結果が得られた。(図 9,図 10 に示す例は、. ものについては<VSUBJ></VSUBJ>というタグで. 共に図 1 の表を統合させたものである). 挟み、 「教官名の値」として分類されたものについて. が、全体的に精度良く分類されていることがわかる。. は<VTEAJ></VTEAJ>というタグで挟む。ここで、. SVM の場合、各値の要素語そのものだけを見て分類. V は Value(値)の意味で、A: Attribute(属性)と区別. していくのに対し、HMM の場合状態遷移系列から. するために付けている。図 7 に今回の実験で用いた. その表の構造を推定し要素語を分類していくという、. 6 −136−. SVM の方.
(7) 値の分類. SVM. HMM. <科目名(和)>. 0.8013. 0.9186. <科目名(英)>. 0.9756. 0.8490. <教官名>. 0.7270. 0.4289. <学年>. 0.9425. 0.7243. <学期)>. 0.9556. 0.9457. <単位数>. 0.9478. 0.6610. 表1. 要素語分類. 図9. 正解率. 図 1 の 2 つの表を統合した XML(SVM). 全く異なるアプローチである。表構造全体を推定し なければならない HMM の方が精度が下がるのは当 然の結果といえるであろう。. 4.2 考察 SVM、 HMM のそれぞれの分類結果を詳しく見て いく。まず SVM の場合、科目名(和)、科目名(英)、 図 10. 教官名は比較的良く分類されている。また「1 年次」、. 図 1 の 2 つの表を統合した XML(HMM). 「2 単位」あるいは「前期」というような、 「 年」、 「 期」、 「単位」がついている語は、ほぼ 100%確実に分類. 以上の考察より、新たに考えられる方法として、. できていた。一方、誤って分類された例としては、. まず HMM における教官名の正解率の下がり方を抑. ・「2」(単位数)と「001」(講義番号)のような数. えるために、人名辞典を用いてトークン処理を前も. 値のみの要素語が複数存在した場合、「001」. って行うという方法が考えられる。 また、この SVM と HMM を組み合わせるような. の方が単位数として分類されてしまう。 ・「1 年前期」という要素語があった場合、その. 手法も考えられる。具体的には、まず SVM による. 要素語のまま学期に分類されてしまい、学年. 分類を行う。その際、各要素語に対して 7 つの学習. には一つも分類されない. モデルから算出される数値をすべて 1 つのベクトル とする。次にそのベクトルを HMM に適用する。す. という現象が起こってしまった。 一方 HMM では、要素語の前後に記述されている. なわち、HMM の各状態からの出力記号を SVM で求. 情報を加味して各要素語を分類するように働くと考. められたベクトルとする。現在、その手法で実験を. えられる。その場合、確かに「単位数:2」「講義番. 新たに進めているが、2 つの手法を組み合わせるこ. 号:001」とあった場合、 「2」という要素語は単位数. とにより、各手法単独での分類よりも分類の精度が. の値としてきちんと分類される。しかし、HMM で. 改善されることが期待される。. は、トレーニングセットに存在しなかった単語が出 現した場合、12 状態以外であると認識されてしまう ため、非常に正解率が下がってしまうという難点が ある。特に、教官名での下が方は激しい。. 5. おわりに 本稿では、WWW 上の情報統合の第一段階として、 複数の「内容の類似した表」を解析し、それらを XML の 1 つの表に統合する手法について述べた。本研究. 7 −137−.
(8) では、データを意味により分類するというアプロー. Learning, Springer, 1998. チをとり、(I) SVM によるデータのクラス分類、(II). [4]Dane. HMM による表構造推定・データ分類、の 2 通りの. Extraction with HMM Structures Learned by Stochastic. 手法を提案した。SVM および HMM を単独で使用し. Optimization” Proceedings of AAAI-2000. た場合の結果を示し、さらにこの 2 つを組み合わせ. [5]伊藤史朗,上田隆也 ,池田裕治 “分散情報に対する情報. て分類の精度を高めることが出来るようにする方法. エージェントのための事例に基づくフレームマッピング”,. を試していくことを考えている。. 電子情報通信学会論文誌 D-I Vol.J81-D-I No.5 pp433-442. また本研究では、大学の授業科目情報の Web ペー. Freitag,. Andrew. McCallum,. “Information. 1998 年 5 月. ジの Table 部分を実験データとして使用したが、そ. [6]Vladimir N. Vapnik, “The Nature of Statistical. の他に、各社の製品情報(カタログ)や、各航空会社の. Learning Theory”, Springer, 1995. フライト情報の時刻表など、異なるジャンルにおけ. [7] 吉田稔,鳥澤健太郎,辻井潤一, “表形式からの情報抽出. る Table の統合についても今後取り組み、本手法の. 手 法 ”, 言 語 処 理 学 会 第 6 回 年 次 大 会 発 表 論 文 集 , pp.. 有効性を評価したいと考えている。. 252--255, 石川, March, 2000. さらに、統合の対象として現在は Web ページ上の 表構造(Table)のみを考えているが、例えば、今回の 実験データの授業科目情報のページについて言えば、 表構造の部分だけでなく、「授業概要」「シラバス」 といった長い文書も含まれる。そのような Web ペー ジ上のテキスト文書も統合の対象として考えていく 予定である。. 6. 謝辞 本研究は、文部科学省科学研究費補助金特定領域 研究「情報学」 (課題番号 13224087)の助成のもと に行われました。. 参考文献 [1]Wei Han, David Buttler, Calton Pu,. “Wrapping Data. into XML”, ACM SIGMOD Record Vol.30, No.3 Sep 2001 [2]Minoru Yoshida, Kentaro Torisawa, Jun’ichi Tsujii, “Extracting ontologies from World Wide Web via HTML tables”, Proceedings of the Pacific Association for Computational Linguistics. 2001 page332-341. [3]T.Joachims, “Text Categorization with Support Vector Machines: Learning with Many Relevant Features”, Proceedings of the European Conference on Machine. 8 −138−.
(9)
図
関連したドキュメント
Table 3 Measurement results of breaking mode 60W, Maximum feed rate.. and table
Nov, this definition includ.ing the fact that new stages on fundamental configuration begin at the rows 23 imply, no matter what the starting configuration is, the new stages
地域の名称 文章形式の表現 卓越もしくは変化前 断続現象 変化後 地域 風向 風向(数値) 風速 風力 起時
Maria Cecilia Zanardi, São Paulo State University (UNESP), Guaratinguetá, 12516-410 São Paulo,
In this diagram, there are the following objects: myFrame of the Frame class, myVal of the Validator class, factory of the VerifierFactory class, out of the PrintStream class,
Sharpen may be applied for burndown control of emerged broadleaf weeds and/or residual control of germinating broadleaf weeds (refer to Table 1 and Table 2 for list of weeds
The purpose of the Graduate School of Humanities program in Japanese Humanities is to help students acquire expertise in the field of humanities, including sufficient
Amount of Remuneration, etc. The Company does not pay to Directors who concurrently serve as Executive Officer the remuneration paid to Directors. Therefore, “Number of Persons”
