Oracle Database 11g High Availability
Oracle ホワイト・ペーパー
2007 年 6 月
ご注意 本書は、オラクルの一般的な製品の方向性を示すことが目的です。また、情報提 供を唯一の目的とするものであり、いかなる契約にも組み込むことはできません。 下記の事項は、マテリアルやコード、機能の提供を確約するものではなく、また、 購買を決定する際の判断材料とはなりえません。オラクルの製品に関して記載さ れている機能の開発、リリース、および時期については、弊社の裁量により決定 いたします。
Oracle Database 11g High Availability
はじめに ... 4
停止時間の原因... 4
コンピュータ障害に対する保護... 5
Oracle Real Application Clusters ... 6
データベースのクラッシュ・リカバリ時間の制限設定 ... 7
データ障害に対する保護 ... 7
ストレージ障害に対する保護... 8
ASM ブロックの修復 ... 8
ASM のローリング・アップグレード... 9
サイト障害に対する保護... 9
Oracle Data Guard ... 9
人為的エラーに対する保護... 12
人為的エラーの防止 ... 13
Oracle のフラッシュバック・テクノロジ... 13
データ破損に対する保護... 16
Oracle Hardware Assisted Resilient Data(HARD) ... 17
バックアップとリカバリ ... 17
計画停止時間の回避 ... 19
オンライン・システムの再構成 ... 20
オンラインのパッチとアップグレード ... 20
オンライン・データおよびスキーマ再編成 ... 23
Maximum Availability Architecture(MAA) - ベスト・プラクティス ... 25
Oracle Database 11g High Availability
はじめに
企業は、情報技術(IT)を使用して、競争で優位に立ち、運用コストを削減し、 顧客とのコミュニケーションを向上させて、中心的なビジネス・プロセスの管理 性を高めています。IT と IT Enabled Services(ITeS)の使用が業務のあらゆる側面 に浸透するにつれて、現代の企業は IT インフラストラクチャに大きく依存するよ うになっています。重要なアプリケーションまたはデータが使用できなくなると、 生産性、収益、顧客満足度、および企業イメージの低下によって企業に大きな損 失をもたらします。このため、現在の動きの速い"絶えず変化する"経済で企業が 成功するには、可用性の高い IT インフラストラクチャの構築が不可欠です。 企業内の IT 需要の増加によって、ビジネ スの成功と IT インフラストラクチャの可 用性の間に重要な関係が確立されています。 可用性の高いインフラストラクチャを構築する従来の方法を使用すると、異なる ベンダーによって提供される冗長なハードウェアとソフトウェア・リソースを広 範に使用することが必要になります。この方法は、実装に非常にコストがかかり、 コンポーネントの疎結合、技術上の制限、管理の複雑さのためにユーザーのサー ビス・レベルの要望を十分に満たしません。これらの課題に対して、オラクルは、 事前に統合して最小のコストで実装できる包括的な業界最高の高可用性テクノロ ジを顧客に提供することに熱心に取り組んでいます。 このホワイト・ペーパーでは、アプリケーション停止時間の一般的な原因を調査 し、Oracle データベース・テクノロジを使用して停止の長期化を防ぎ、避けられ ない障害から迅速にリカバリする方法について説明します。また、Oracle Database 11g で導入された新しいテクノロジにも注目します。このテクノロジによって、 企業は、さらに強力でフォルト・トレラントな IT インフラストラクチャを構築し、 高可用性インフラストラクチャの投資利益率を最大にして、サービス品質を向上 できます。
停止時間の原因
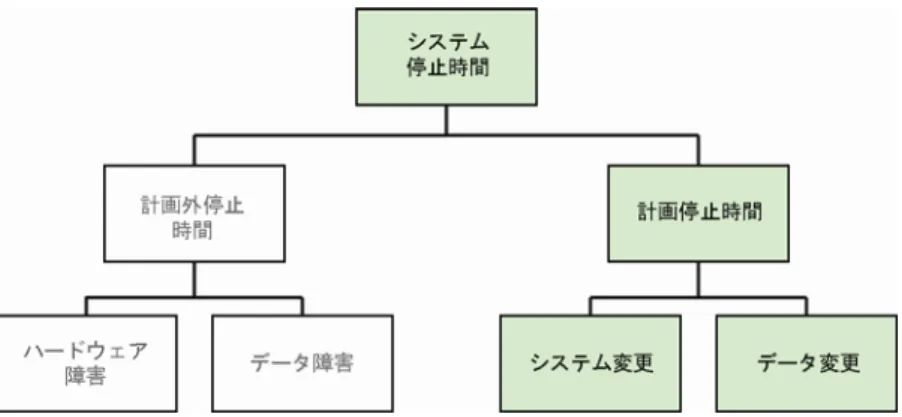
可用性の高い IT インフラストラクチャを構築する場合、アプリケーション停止時 間のさまざまな原因を最初に把握することが重要です。以下の図 1 では、停止時 間を計画外停止時間と計画停止時間に大別しています。計画外停止時間の主な原 因は、コンピュータ障害とデータが使用できなくなるその他の障害(ストレージ の破損、サイト障害など)です。計画停止時間の主な原因は、ハードウェア、ソ フトウェア、アプリケーション、データ変更などのシステム・メンテナンス・ア クティビティです。 効果的な高可用性アーキテクチャを構築 するため、アプリケーション停止時間の さまざまな原因を把握することが重要です。図 1:停止時間の原因 サービス妨害の原因となるさまざまな要素を把握している IT 企業は、停止時間を 回避する態勢が整っています。これによって、システム停止時間のすべての原因 から保護されるよう設計された強力な高可用性アーキテクチャを実装できます。 次の各項では、上記の各障害に対する包括的な保護を実現できるさまざまな Oracle データベース・テクノロジについて説明します。
コンピュータ障害に対する保護
コンピュータ障害は、データベース・サーバーを実行するマシンで予期しない障 害(ほとんどハードウェアの故障が原因)が発生した場合に発生します。これは 最も一般的な障害です。オラクルのグリッド・コンピューティング・アーキテク チャの基盤である Oracle Real Application Clusters は、このような障害に対して最 も効果的な保護を実現できます。Oracle Real Application Clusters
Oracle Real Application Clusters(Oracle RAC)は、クラスタの 2 台以上のコンピュー タ("ノード"とも呼ばれる)が 1 つの共有データベースに同時にアクセスできる 優れたデータベース・クラスタ化テクノロジです。このテクノロジによって、単 一の統合データベースとしてアプリケーションに示される複数のハードウェア・ システムにまたがる 1 つのデータベース・システムを効果的に作成できます。こ のため、可用性とスケーラビリティの次のような大きな利点がすべてのアプリ ケーションに得られます。
Oracle Real Application Clusters(Oracle RAC)は、エンタープライズ・アプリケー ションの可用性、パフォーマンス、およ びスケーラビリティを最大にする優れた グリッド・コンピューティング・テクノ ロジです。 • クラスタ内のフォルト・トレランス(特にコンピュータ障害) • 必要に応じて、またビジネス・ニーズの変化に応じて、システムを任意 の容量に拡張できる容量計画の柔軟性と費用効率の高さ
Oracle Real Application Clusters を使用すると、エンタープライズ・グリッドを実現 できます。エンタープライズ・グリッドは、プロセッサ、サーバー、ネットワー ク、ストレージなどの標準化された、コモディティ価格のコンポーネントで構成 される大規模システムです。Oracle RAC は、これらのコンポーネントを利用して、 企業に有効な処理システムを構築できる唯一の技術です。Oracle Real Application Clusters およびグリッドは、システムの適応性、事前対応力および機動性を向上さ せるため、運用コストを大幅に削減し、新しいレベルの柔軟性を提供します。ノー ド、ストレージ、CPU、メモリーの動的なプロビジョニングによって、サービス・ レベルを容易かつ効率的に維持できます。また、使用率が向上するため、コスト がさらに削減されます。Oracle Real Application Clusters は、RAC データベースへ アクセスするアプリケーションから完全に透過的で、既存のアプリケーションを 配置するための変更は一切不要です。 RAC アーキテクチャの主な利点は、複数のノードによって提供される固有のフォ ルト・トレランスです。物理ノードが独立して実行されるので、1 つ以上のノー ドの障害がクラスタの他のノードに影響しません。フェイルオーバーは、グリッ ドのどのノードでも発生する可能性があります。極端な例をあげると、RAC シス テムは、1 つのノード以外すべてがダウンしてもデータベース・サービスを提供 します。このアーキテクチャを使用して、メンテナンスのためにノードのグルー プを透過的にオンラインまたはオフラインに設定できます。残りのクラスタは、 引き続きデータベース・サービスを提供します。RAC は、Oracle Fusion Middleware の組込み統合によって、接続プールのフェイルオーバーを実現します。この機能 を使用すると、TCP タイムアウトが発生するまで数 10 分待機することなく、即座 に障害がアプリケーションに通知されます。アプリケーションは、適切なリカバ リ・アクションを即座に実行できます。グリッド・ロード・バランシングで、ロー ドが次第に再分散されます。 サーバー障害からアプリケーションを保 護する最適な方法です。RAC データベー スで実行しているアプリケーションは、 クラスタの 1 台を除くすべてのマシンが ダウンする場合でも実行を継続します。
また、Oracle Real Application Clusters は、容量増加の要望に応じてクラスタにノー ドを追加できる柔軟性をユーザーに提供します。段階的にシステムを拡張してコ ストを削減するので、小規模な単一ノード・システムから大規模なシステムへの 変更は不要です。既存システムを新しい大容量ノードと交換してシステムをアッ プグレードする場合と比較すると、1 つ以上のノードをクラスタに段階的に追加 できるため、容量のアップグレード・プロセスが簡単に短期間で実現します。Oracle Real Application Clusters に実装されているキャッシュ・フュージョン・テクノロジ と InfiniBand ネットワーク・サポートによって、アプリケーションを変更するこ となく容量をほぼリニアに拡張できます。 RAC は、動的なハードウェア・リソース の割当てによって柔軟性のあるスケーラ ビリティを実現します。必要に応じて ハードウェア・リソースを追加する機能 によって、IT コストが大幅に削減され、 ビジネスの要望に基づく IT インフラスト ラクチャの拡張が可能です。
Oracle Database 11g は、Oracle Real Application Clusters のパフォーマンス、スケー ラビリティ、およびフェイルオーバーのメカニズムを最適化して、スケーラビリ ティと高可用性の利点をさらに高めます。
Oracle Real Application Clusters に つ い て 、 詳 し く は http://otn.oracle.co.jp/products/database/clustering/index.html を参照してください。
データベースのクラッシュ・リカバリ時間の制限設定
計画外停止時間の最も一般的な原因の 1 つは、システム障害またはクラッシュで す。システム障害は、ハードウェア障害、電源異常、オペレーティング・システ ムまたはサーバーのクラッシュなどによって発生します。このような障害による 中断の範囲は、影響を受けるユーザーの数とサービスが復旧するまでの時間に よって異なります。高可用性システムは、障害発生時に迅速かつ自動的にリカバ リするように設計されています。重要なシステムを使用するユーザーが IT 企業に 期待しているのは、障害からの迅速なリカバリと予測可能な時間内でのリカバリ です。この期待されている時間よりも停止時間が長くなると、運用に直接影響を 及ぼし、収益と生産性の低下につながる可能性があります。 Oracle データベースは、迅速にシステム障害およびクラッシュからリカバリする 機能を備えています。迅速であることも重要ですが、予測可能であることも重要 です。Oracle データベースに含まれるファスト・スタート障害リカバリ・テクノ ロジは、データベースのクラッシュ・リカバリ時間の制限を自動的に設定する、 Oracle データベース固有の機能です。この機能によって、データベースはチェッ クポイント処理を自動調整し、目標とされるリカバリ時間を守ります。このため、 リカバリ時間が短縮され、かつ予測可能になり、サービス・レベルの目標を達成 する能力が向上します。オラクルのファスト・スタート障害リカバリ機能は、高 負荷のデータベースのリカバリ時間を数 10 分から 10 秒未満へと短縮できます。データ障害に対する保護
データ障害とは、重要な企業データの損失、損傷または破損を意味します。デー タ障害の原因には多面性があります。多くの場合、分かりづらく識別が困難です。 通常、データ障害の原因は、ストレージ・サブシステムの障害、サイト障害、人 為的エラー、破損のいずれか、またはこれらの組合せです。図 3:データ障害
ストレージ障害に対する保護
Oracle Database 10g は、Automatic Storage Management(ASM)という画期的なス トレージ・テクノロジを導入しました。このテクノロジは、オラクルのデータベー ス・ファイル用に特別に設計されたファイル・システムとボリューム・マネージャ 機能を統合します。低コストで管理しやすく高パフォーマンスの ASM は、すぐに スタンドアロン・データベースと RAC データベースの両方を管理する IT 管理者 にとって最適なストレージ・テクノロジとなりました。 パフォーマンスと高可用性を第一の目的として、ASM はストライプとミラーの原 則に基づいています。インテリジェントなミラー化機能によって、管理者は重要 なビジネス・データを完全に保護する 2 重化または 3 重化のミラー化を定義でき ます。ディスク障害が発生した場合、ミラー化されたディスクで使用できるデー タを利用して、システム停止時間を回避できます。障害が発生したディスクを ASM から永久に削除すると、基本となるデータは、高パフォーマンスを維持する ために残りのディスクでストライプ化またはリバランスされます。
ASM ブロックの修復
Oracle Database 11g では、ASM の信頼性と可用性を高めるために新しい機能が導 入されました。1 つ目の機能は、ミラー化されたディスクで使用できる有効なブ ロックを活用して、ディスクの破損ブロックをリカバリする機能です。読取り処 理でディスクの破損ブロックが識別されると、ASM は、ディスクの破損していな い部分に不良ブロックを自動的に再配置します。また、管理者は、ASMCMD ユー ティリティを使用して、ディスクの破損による特定のブロックを手動で再配置で きます。
ASM のローリング・アップグレード
Oracle Database 11g の ASM では、ASM ソフトウェアのローリング・アップグレー ド機能を使用して、クラスタ環境全体の可用性を高めます。ASM ローリング・アッ プグレードによって、管理者は、移行中に使用できるクラスタの他のノードを維 持して個々のノードの ASM をアップグレードする際に、アプリケーションをオン ラインの状態に維持できます。ASM インスタンスは、クラスタのすべてのノード がアップグレードされるまで、異なるソフトウェア・バージョンで実行できます。 ASM ソフトウェアの新しいバージョンに導入された機能は、クラスタのすべての ノードがアップグレードされるまで有効にはなりません。
Oracle Database 11g では、ASM インス タンスのローリング・アップグレード機 能によって、ASM を使用するデータベー スの可用性が向上します。
サイト障害に対する保護
企業は、データ・センター全体がオフラインになるほどの壊滅的なイベントから 重要なデータとアプリケーションを保護する必要があります。自然災害、停電、 通信障害などのイベントは、データ・センターに悪影響を与えるシナリオの一部 にすぎません。Oracle データベースは、完全なサイト障害による停止の長期化か ら企業を保護するさまざまなデータ保護ソリューションを提供します。データ保 護の最も基本的な形式は、データベース・バックアップのオフサイト・ストレー ジです。サイト全体におよぶ障害のバックアップをリストアするプロセスは、HA 戦略に不可欠でありながら、企業が許容できる時間よりも長く時間がかかる可能 性があるので、バックアップに最新のデータが含まれない場合があります。より 迅速で包括的なソリューションは、物理的に離れたデータ・センターに本番デー タベースを 1 つ以上コピーして管理することです。Oracle Data Guard
Oracle Data Guard は、あらゆる IT インフラストラクチャにおける障害時リカバリ の実装の基盤となるものです。本番データベースの 1 つ以上のスタンバイ・コピー を世界各地のローカル・データ・センターまたはリモート・データ・センターに 配置して管理するテクノロジを提供します。また、さまざまな構成オプションが 使用できます。これによって、管理者はビジネスに必要な保護のレベルを定義で きます。フェイルオーバーが必要な場合にはサーバーをスタンバイ・データベー スに動的に追加できるため、グリッド・クラスタ間で透過的に動作します。Oracle Data Guard は、2 種類のスタンバイ・データベース(Redo Apply テクノロジを使 用するフィジカル・スタンバイ・データベースと SQL Apply テクノロジを使用す るロジカル・スタンバイ・データベース)をサポートします。
Oracle Data Guard Redo Apply(フィジカル・スタンバイ)
フィジカル・スタンバイ・データベースは、Redo Apply テクノロジを使用して、 本番データベースの保守と同期を行います。本番データベースの REDO データは、 フィジカル・スタンバイに付属しています。メディア・リカバリを使用すると、 REDO データからスタンバイ・データベースに変更が適用されます。Redo Apply を使用する場合、スタンバイ・データベースは、本番データベースと物理的に同 じにする必要があります。フィジカル・スタンバイ・データベースは、障害やデー タ・エラーからの保護機能として有効です。エラーまたは障害の発生時に、フィ ジカル・スタンバイ・データベースをオープンして使用することで、データ・サー ビスをアプリケーションおよびエンド・ユーザーに提供できます。スタンバイ・
データベースへの変更の適用には優れたメディア・リカバリ・メカニズムが使用 されているため、スタンバイ・データベースは各アプリケーションでサポートさ れ、最大のトランザクション・ワークロードにも簡単に効率よく対処できます。 オラクルの高可用性戦略の焦点は、高可用性インフラストラクチャを日常的にす べて使用できることです。これを実現すると、顧客は、スタンバイ・データベー スに対するレポート・ワークロードまたはバックアップ・アクティビティの負荷 の軽減やテスト・アクティビティ用スタンバイ・データベースの使用など、幅広 い操作に障害時リカバリの投資を活用できます。 フィジカル・スタンバイ・データベースは、読取り専用モードでオープンする機 能を常に使用でき、データベースへの読取りアクセスだけが必要な本番ワーク ロードを軽減する方法を提供します。従来、この方法の欠点として、フィジカル・ スタンバイ・データベースを読取り専用モードでオープンしてもメディア・リカ バリを静止する必要があったので、フィジカル・スタンバイ・データベースと本 番データベースを同期できませんでした。Oracle Database 11g の飛躍的な進歩に よって、フィジカル・スタンバイ・データベースを読取り専用モードでオープン した状態でメディア・リカバリの続行が可能になりました。Physical Standby with Real Time Query(リアルタイム問合せを使用したフィジカル・スタンバイ)と呼 ばれる魅力的な新しい機能は、読取り専用アクティビティ用にスタンバイ・デー タベースをオープンする前述の欠点を排除します。読取り専用アプリケーション にサービスを提供している場合でも、フィジカル・スタンバイ・データベースと 本番データベースが同期されます。 フィジカル・スタンバイ・データベース は、REDO データが継続的に適用される 場合でも読取り専用モードでオープンで きます。 本番データベースと物理的に同じスタンバイ・データベースを使用する主な利点 として、バックアップ・アクティビティのソースにこのスタンバイ・データベー スを利用できる点があります。Oracle Database 10g では、最後の増分バックアップ が実行されてから変更されたブロックのログを保持するブロック・トラッキン グ・テクノロジが導入されました。これによって、増分バックアップに必要な時 間が大幅に削減されます。Oracle Database 11g の以前、ブロック・トラッキング・ テクノロジを使用した高速の増分バックアップは、プライマリ・データベースで のみ実行できました。この制限が Oracle Database 11g でなくなったので、顧客は スタンバイ・データベースへのすべてのバックアップ・アクティビティの負荷を 軽減できます。 また、Oracle Database 11g では、"スナップショット・スタンバイ"と呼ばれる新し い機能が導入されました。この機能によって、障害に対する保護を損なうことな く一時的なテスト・アクティビティ用の読取り/書込みアクティビティに対して フィジカル・スタンバイ・データベースをオープンできます。この機能を使用す ると、テストなどの目的でプライマリ・データベースとは独立したトランザクショ ンを処理するために読取り/書込みでオープンできる"スナップショット・スタンバ イ"データベースにフィジカル・スタンバイ・データベースが一時的に変換されま す。スナップショット・スタンバイ・データベースは、引き続きプライマリ・デー タベースから更新を受信およびアーカイブします。ただし、プライマリ・データ ベースから受け取った REDO データは、スナップショット・スタンバイ・データ ベースがフィジカル・スタンバイ・データベースに変換されるまで、適用されま せん。スナップショット・スタンバイ・データベースのときに実行されたすべて の更新は破棄されます。これによって、常に保護された状態で本番データを使用
できます。
Oracle Database 11g は、スタンバイ・データベースの変更を並行して適用できます。 このため、パフォーマンスが大幅に向上します。
Oracle Data Guard SQL Apply(ロジカル・スタンバイ)
ロジカル・スタンバイ・データベースは、SQL Apply テクノロジを使用して、本 番データベースの保守と同期を行います。メディア・リカバリを使用して本番デー タベースの変更を適用するのではなく、SQL Apply は、REDO データを SQL トラ ンザクションに変換して、読取り/書込み操作用にオープンするデータベースに適 用します。データベースをオープンの状態にする機能によって、使用するロジカ ル・スタンバイ・データベースで本番データベースの特定のワークロードを同時 に軽減できます。多くの組織は、索引とマテリアライズド・ビューをスタンバイ に追加することによって最適化できる、レポートおよび意思決定サポート・シス テムのロジカル・スタンバイを活用します。 SQL Apply プロセスは、論理的な破損を回避するためにプライマリの REDO デー タの変更前の値とスタンバイの変更後の値を比較して、本番データベースとロジ カル・スタンバイ・データベース間のデータの整合性を維持します。このため、 ロジカル・スタンバイ・データベースは、IT インフラストラクチャのスケーラビ リティを向上させる拡張機能によって高可用性を実現する最も重要なデータ保護 機能です。 Oracle Database 11g の機能強化によって、ロジカル・スタンバイ・データベースの 機能が拡張され、適用パフォーマンスが大幅に向上して使いやすくなります。 Oracle Database 11g の SQL Apply は、以下の機能を含む追加のデータ型、他の Oracle 機能、および PL/SQL を引き続きサポートします。 • XMLType データ型(CLOB として保存される場合) • ロジカル・スタンバイ・データベースで並行して DDL を実行する機能 • 透過的データ暗号化(TDE) • DBMS_FGA(ファイングレイン監査) • DBMS_RLS(仮想プライベート・データベース)
Oracle Data Guard Broker
プライマリ・データベースとスタンバイ・データベース、およびその間のさまざ まな通信は、SQL*Plus™ を使用して管理できます。また、管理を容易にするため
に、Oracle Data Guard Brokerと呼ばれる、Data Guard構成の作成、メンテナンス、 監視を自動化して一元化するための分散型管理フレームワークも実装されていま す。管理者は、Oracle Enterprise ManagerあるいはOracle Data Guard Brokerの特殊コ マンドライン・インタフェース(DGMGRL)によって、Oracle Data Guard Broker の管理機能を活用できます。Oracle Enterprise Managerの使いやすいGUIを使用する と、マウスのシングル・クリックでプライマリ・データベースからスタンバイ・ データベースのいずれかのタイプにフェイルオーバー処理を開始できます。Oracle Data Guard BrokerとOracle Enterprise Managerを使用すると、DBAのスタンバイ・ データベースの管理および操作が容易になります。フェイルオーバーおよびス イッチオーバーなどのアクティビティを容易にすることで、エラーの可能性が大
幅に軽減されます。
Oracle Database 11g は、Oracle Data Guard Broker を拡張して、ネットワーク転送オ プションのサポートを強化し、最大可用性および最大パフォーマンスから保護構 成を変更して停止時間をなくし、コールド・フェイルオーバー・クラスタとして Oracle Clusterware を使用して HA 用に構成される単一インスタンスのデータベー スのサポートを追加します。
ファスト・スタート・フェイルオーバー
Oracle Data Guard のファスト・スタート・フェイルオーバーを使用すると、ユー ザー介入を必要とせず、本番データベースからスタンバイ・データベースへのデー タベース処理のフェイルオーバーを完全に自動化する機能によって、フォルト・ トレラントなスタンバイ・データベース環境を作成できます。障害が発生した場 合、ファスト・スタート・フェイルオーバーは、管理者が複雑な手動の手順を実 行してフェイルオーバー操作の呼び出しおよび実装を行うことなく、指定され同 期されたスタンバイ・データベースに迅速で信頼性の高いフェイルオーバーを自 動的に実行します。これによって、停止時間が大幅に短縮されます。ファスト・ スタート・フェイルオーバーが発生した後、Oracle Data Guard Broker によって、 構成の再接続時に古いプライマリ・データベースが新しいスタンバイ・データベー スに自動的に復元されます。このため、Data Guard 構成では、構成の障害に対す る保護を素早く簡単にリストアできます。これによって、Data Guard 構成の堅牢 性が向上します。この機能によって、Oracle Data Guard は、透過的なビジネスの 継続性を維持し、DR 構成の管理コストを削減します。 オラクルでは、ファスト・スタート・フェ イルオーバー機能を使用して、フェイル オーバー・プロセスを自動化します。 ファスト・スタート・フェイルオーバー は、障害が発生した場合にスタンバイを アクティブ化するために管理者の可用性 への依存を軽減します。 Oracle Database 11g のファスト・スタート・フェイルオーバー・メカニズムの新し い拡張機能を使用すると、フェイルオーバー時間がさらに削減されます。また、 管理者は、フェイルオーバーのシナリオおよび動作をさらに制御できます。たと えば、管理者は、ファスト・スタート・フェイルオーバーを引き起こすデータベー ス・エラー(ORA-xxxx)などの特定のイベントを定義できます。同様に、意図し ない更新を防止するためにファスト・スタート・フェイルオーバーを開始する場 合、管理者は、Data Guard 環境を構成してプライマリ・データベースを停止でき ます。
人為的エラーに対する保護
停止時間の原因に関するほとんどの調査では、最大の原因として人為的エラーが あげられています。不注意による重要データの削除や、UPDATE 文の不適切な WHERE 句によって、意図した以上の行が更新されるなどの人為的エラーを可能 なかぎり防止し、それに対する予防措置が機能しなかった場合は、元に戻す必要 があります。Oracle データベースには、このようなエラーが発生した場合に、エ ラーを迅速に診断してリカバリを行うために役立つ管理者向けの使いやすい強力 なツールがあります。また、エンド・ユーザーが管理者の介入なしでリカバリを 行えるようにする機能も装備しているため、DBA のサポート作業が削減され、損 失データや損傷データのリカバリ時間が短縮されます。人為的エラーの防止
エラーの防止に最も有効な方法は、ユーザーのアクセスをそのユーザーの仕事に 必要なデータおよびサービスのみに限定することです。Oracle データベースには、 アプリケーション・データへのユーザーのアクセスを制御する様々なセキュリ ティ・ツールが用意されています。これらのツールでは、ユーザーを認証し、管 理者がユーザーの職務に必要な権限のみをユーザーに付与できます。また、Oracle データベースのセキュリティ・モデルは、Virtual Private Database(VPD)機能を 使用してデータ・アクセスを行レベルで制限できる機能を提供し、アクセスする 必要のないデータからユーザーを切り離します。Oracle のフラッシュバック・テクノロジ
認可されたユーザーがミスを犯した場合、そのエラーを修復するツールが必要で す。Oracle Database 11g は、フラッシュバックと呼ばれる人為的エラーを修復する 一連のテクノロジを提供します。フラッシュバックは、データ・リカバリを刷新 します。以前は、数分で損傷したデータベースのリカバリに数時間かかる場合が ありました。フラッシュバックを使用することで、エラーの発生にかかった時間 と同じ時間内に修復を行えます。フラッシュバックは非常に使いやすく、1 つの 短いコマンドを使用してデータベース全体をリカバリできるため、複雑な手順は 必要ありません。フラッシュバックは、人為的エラーの迅速な分析および修復を 行うための SQL インタフェースを提供します。顧客の注文を誤って削除した場合 などの部分的な破損に対して、細分化された分析と修復を行います。また、ある 月の顧客の注文がすべて削除された場合など、広範囲にわたる破損も短時間で修 復できるため、停止時間を短縮できます。フラッシュバックは Oracle データベー ス固有の機能で、行、トランザクション、表、表領域およびデータベース全体な どすべてのレベルでのリカバリをサポートします。 フラッシュバック問合せ Oracle フラッシュバック問合せを使用して、管理者は過去のある時点のデータを 問合せることができます。この強力な機能を使用すると、誤って削除または変更 された可能性がある論理的に破損したデータを表示し、再構築できます。 このシンプルな問合せは、特定のタイムスタンプでの EMP 表の行を表示します。 この機能は強力なツールです。管理者は、この機能を活用して、論理データの破 損をすばやく識別して解決します。ただし、この機能は簡単にアプリケーション に組み込むことができるので、アプリケーション・ユーザーは、管理者に連絡す ることなく、データの変更をロールバックまたは元に戻すメカニズムを素早く簡 単に使用できます。フラッシュバック・バージョン問合せ フラッシュバック問合せと似ているフラッシュバック・バージョン問合せは、管 理者による過去のデータの問合せを実現する機能です。フラッシュバック・バー ジョン問合せの違いと処理能力は、特定の時間間隔で異なるバージョンの行を取 得できる機能です。 この問合せは、特定のタイムスタンプでの各バージョンの行を表示します。管理 者は、この期間に異なるトランザクションによって変更された値を参照できます。 このメカニズムによって、データ変更の日時と方法を特定する機能が管理者に提 供されるので、データの修復とアプリケーション・デバッグの両方に大きな利点 があります。 フラッシュバック・トランザクション 多くの場合、論理的な破損は、複数の行または表のデータが変更される可能性の あるトランザクションで発生します。フラッシュバック・トランザクション問合 せを使用すると、管理者は特定のトランザクションによるすべての変更を参照で きます。 この問合せは、特定のトランザクションによる変更を表示し、トランザクション のフラッシュバックまたは取り消しに必要な SQL 文を生成します。このような精 密なツールを使用することで、管理者は、データベース内の論理的な破損を詳細 に効率よく診断して修復できます。 Oracle Database 11g の新機能であるフラッシュバック・トランザクションは、トラ ンザクション・レベルのデータ・リカバリを容易にするシームレスで強力な PL/SQL インタフェースです。フラッシュバック・トランザクション問合せの処理 能力に基づくこの新機能によって、論理データの破損を修復する、さらに強力で フェイルセーフな方法が実現します。多くの場合、データ障害の識別には時間が かかります。この場合、論理的に破損したデータに基づいて追加のトランザクショ ンを実行できます。フラッシュバック・トランザクションは、最初のトランザク ションだけではなくすべての依存するトランザクションを識別して解決します。
フラッシュバック・データ・アーカイブ 上記のフラッシュバック問合せ文は、UNDO 表領域の履歴データの可用性に依存 します。UNDO 表領域に履歴データが残される期間は、表領域のサイズ、データ 変更の割合、構成可能なデータベース設定によって異なります。通常、管理者は、 データベースを構成して日単位または週単位で UNDO データを保存します。年単 位や 10 年単位では保存しません。この制限を克服するため、Oracle Database 11g では、フラッシュバック・データ・アーカイブを通じて使用できる画期的な新し い機能が導入されました。フラッシュバック・データ・アーカイブは、ビジネス で必要とする期間保存できるデータベース内の通常のデータとして、以前のバー ジョンのデータを保存します。フラッシュバック・データ・アーカイブは、サー ベンス・オクスリー法や HIPPA などの絶え間なく変化する規制状況に直面する企 業をサポートするため、データ保存戦略を刷新しています。保存したデータの整 合性を確保するため、フラッシュバック・データ・アーカイブでは、以前のバー ジョンのデータへの読取り専用アクセスを許可しています。 Oracle Database 11g の新機能であるフ ラッシュバック・データ・アーカイブは、 拡張された期間で以前のバージョンの データを保存するメカニズムです。 フラッシュバック・データ・アーカイブは、重要なビジネス・データを管理する 際に優れた柔軟性を企業に提供する堅牢なツールセットです。フラッシュバッ ク・データ・アーカイブの利点は、データ障害を修復するという暗黙の利点より もはるかに優れています。このテクノロジを使用すると、アプリケーション開発 者と管理者は、ユーザーによる情報の変更の追跡および参照を有効にできます。 フラッシュバック・データ・アーカイブの不変的な性質を考慮すると、企業は、 監査などを目的としたデータ保護の観点から、戦略上および財務上の利点を得る ことができます。アプリケーション開発者は、豊富な機能をアプリケーションに 導入して、フラッシュバック・データ・アーカイブを利用できます。ユーザーは、 銀行取引明細書など、過去のバージョンのデータを参照できます。アプリケーショ ン開発者と管理者は、重要なビジネス・データの変更を追跡するカスタム・ロジッ クを作成および保守する必要がなくなります。 Oracle によって自動的に管理されるので、 データが変更されるたびに、元のバー ジョンのデータの読取り専用コピーをフ ラッシュバック・データ・アーカイブで 使用できます。 フラッシュバック・データベース データベース全体を過去のある時点の状態にリストアする場合、従来の方法では、 RMAN バックアップのデータベースをリストアしてエラー発生前のポイント・イ ン・タイム・リカバリを実行します。データベースのサイズが増加すると、デー タベース全体のリストアに数時間あるいは数日かかる場合があります。 フラッシュバック・データベースは、データベース全体を過去のある時点の状態 にリストアする新しい方法です。フラッシュバック・ログを使用して、データベー スをある時点の状態に巻き戻します。フラッシュバック・ログを使用したフラッ シュバック・データベースは、変更されたブロックをリストアするだけなので、 非常に高速です。使いやすく効率的なので、以前は数時間かかったデータベース のリストアが数分で完了します。
ご覧のとおり、複雑なリカバリ手順は必要ありません。テープからバックアップ をリストアする必要もありません。フラッシュバック・データベースは、データ ベースのリストアが必要なシナリオの停止時間を大幅に短縮します。 フラッシュバック表 多くの場合、論理的な破損は、単一の表または一連の表に切り離されます。この ため、データベース全体をリストアする必要がありません。フラッシュバック表 は、管理者が単一の表または一連の表を特定の時点に素早く簡単にリカバリでき る機能です。 この問合せは、orders 表と order_items 表を巻き戻します。現在の時刻と特定のタ イムスタンプの間に行われた表の更新は元に戻されます。誤って表が削除された 場合、管理者は、フラッシュバック表機能を使用して、削除された表、そのすべ ての索引、制約、およびトリガーをごみ箱からリストアできます。削除されたオ ブジェクトは、管理者が明示的に消去するまで、またはオブジェクトの表領域で 空き領域が必要になるまで、ごみ箱に残ります。 フラッシュバック・リストア・ポイント フラッシュバック・データベースとフラッシュバック表の上記の説明と例では、 リストア操作またはフラッシュバック操作の基準として時間を使用しています。 Oracle Database 10g Release 2 では、データ障害の解決を簡素化し迅速に処理する手 段として、フラッシュバック・リストア・ポイントが用意されました。リストア・ ポイントは、管理者がデータベースを良好な状態と判断した特定の時間をブック マークするユーザー定義ラベルです。フラッシュバック・リストア・ポイントに よって、管理者は、損害を与える不正なアクティビティからデータベースを容易 に効率的に修正できます。 IO パス
データ破損に対する保護
物理的なデータ破損は、IO スタックを構成するさまざまなコンポーネントのいず れかの障害によって引き起こされます。高レベルで Oracle が書込み操作を発行す ると、データベースの IO 操作は、オペレーティング・システムの IO コードに渡 されます。これによって、さまざまなコンポーネントを通じて渡される IO スタッ クの IO を渡すプロセスが開始されます。ファイル・システムから順にボリュー ム・マネージャ、デバイス・ドライバ、Host-Bus Adapter、ストレージ・コントロー ラ、ディスク・ドライブへと渡されてデータの書込みが行われます。いずれかの コンポーネントにハードウェア障害またはバグがあると、無効なデータまたは破 損したデータがディスクに書き込まれる場合があります。このため、内部 Oracle 制御情報やアプリケーション・データ、ユーザー・データが破損することもあり、 その場合は、データベースの機能性や可用性が深刻な打撃を受けるおそれがあり ます。Oracle Hardware Assisted Resilient Data(HARD)
Oracle Hardware Assisted Resilient Data(HARD)は、IO スタック内の障害による物 理的な破損を未然に防ぐための包括的なプログラムです。この独特のプログラム は、オラクルと主要なストレージ・ベンダーの協力によるものです。つまり、ス トレージ・ベンダーの参加によって、それぞれのストレージ・デバイスにオラク ルのデータ検証アルゴリズムが実装されます。Oracle データベース固有の HARD は、データベースとストレージ・デバイス間の IO パスの破損を検出します。この エンドツーエンドのデータ検証によって、破損したデータが永続ストレージに書 き込まれることを防ぎます。HARD の拡張によって、さらに包括的な検証アルゴ リズムとすべてのファイル・タイプのサポートが提供されます。データ・ファイ ル、オンライン・ログ、アーカイブ・ログ、およびバックアップは、HARD プロ グラムですべてサポートされます。Automatic Storage Management(ASM)は、RAW デバイスを使用しないで HARD 機能を利用します。 主要なストレージ・ベンダーは、オラク ル固有の HARD プログラムを使用して、 直接ストレージ・デバイスにオラクルの データ検証アルゴリズムを実装します。
バックアップとリカバリ
このホワイト・ペーパーで説明してきた多くの予防テクノロジやリカバリ・テク ノロジの機能があっても、IT 企業は、包括的なデータ・バックアップ手順を配置 する必要があります。めったにありませんが複数の障害が同時に発生する場合、 管理者はバックアップからビジネスの重要なデータをリカバリできる必要があり ます。オラクルは、効率よく適切にデータをバックアップし、以前のバックアッ プからデータをリストアして、障害が発生する前の時点までデータをリカバリす る、業界標準のツールを提供しています。Oracle Recovery Manager(RMAN)
大規模なデータベースは、多くのマウント・ポイントを使用した数百のファイル で構成できます。このため、バックアップ・アクティビティが大きな課題となり ます。バックアップでの1つの重要なファイルの軽視や見落としによって、デー タベース・バックアップ全体が無効になる場合があります。多くの場合、緊急の シナリオで必要になるまで、不完全なバックアップは検出されません。Oracle Recovery Manager(RMAN)は、データベース・バックアップ、リストア、および リカバリ・プロセスを管理する複合ツールです。RMAN は、構成可能なバックアッ プとリカバリ・ポリシーを保守し、すべてのデータベースのバックアップ・アク ティビティとリカバリ・アクティビティの履歴を保存します。包括的な機能セッ トを通じて、RMAN は、データベースの正常なリストアとリカバリに必要なすべ てのファイルが完全なデータベース・バックアップに含まれていることを確認し ます。さらに、RMAN バックアップ操作を通じてすべてのデータ・ブロックを分 析して、破損ブロックがバックアップ・ファイル全体に伝播しないようにします。 RMAN の拡張機能によって、大きなデータベースのバックアップが効率的で簡単 なプロセスになります。RMAN では、ブロック追跡機能を利用して、増分バック アップのパフォーマンスを向上します。最後のバックアップから変更されたブ ロックのバックアップだけなので、RMAN バックアップの時間とオーバーヘッド が大幅に削減されます。Oracle Database 11g のブロック追跡機能は、管理されるス タンバイ・データベースで使用できます。エンタープライズ・データベースのサ イズが増加する場合、Bigfile 表領域を使用するとさらに効果的です。Bigfile 表領 域は、多くの小さなファイルではなく 1 つの大きなファイルで構成され、Oracle 増分バックアップの速度を大幅に向上さ せるオラクルのブロック追跡テクノロジ は、管理されるスタンバイ・データベー スで利用できるようになりました。
データベースを 8 エクサバイトまで拡張できます。Bigfile 表領域のバックアップ およびリカバリ操作のパフォーマンスを向上させるには、Oracle Database 11g の RMAN を使用して、内部ファイル・パラレル・バックアップおよびリカバリ操作 を実行できます。 多くの企業は、テストや品質保証に使用するため、およびスタンバイ・データベー スを生成するために本番データベースのクローンまたはコピーを作成します。 RMAN には、データベース複製機能を介した既存の RMAN バックアップを使用 してデータベースをクローンする機能があります。Oracle Database 11g 以前の必須 バックアップ・ファイルは、クローンされたデータベースのホストでアクセス可 能にする必要がありました。Oracle Database 11g のネットワーク・ベースの複製は、 ソース・データベースに既存のバックアップを保存することなく、ソース・デー タベースをクローン・データベースに複製します。つまり、ネットワーク・ベー スの複製は、ソースからクローンに直接必要なファイルを透過的にクローンします。
Oracle Database 11g は、Microsoft Volume Shadow Copy Service(VSS)との緊密な 統合をサポートします。つまり、Microsoft Volume Shadow Copy Service は、ボリュー ムの一貫性のあるポイント・イン・タイム・バックアップの実行中にアプリケー ションでディスク・ボリュームへの書込みを続行できるテクノロジ・フレームワー クです。Windows システムのサービスとして実行される個別の実行ファイルであ る Oracle VSS Writer は、Oracle データベースと他の VSS コンポーネントを仲介し ます。たとえば、Oracle VSS Writer は、ホット・バックアップ・モードでデータ ベース・ファイルを配置して、VSS コンポーネントによる VSS スナップショット のデータ・ファイルの回復可能なコピーの取得を可能にします。Oracle VSS Writer は、VSS スナップショットからリストアされるファイルのリカバリを実行する ツールとして、RMAN を活用します。また、RMAN の拡張によって、フラッシュ・ リカバリ領域に保存される増分バックアップのソースとして、VSS スナップ ショットを利用できます。
Data Recovery Advisor
予測できない状況が発生して重要なビジネス・データが危険にさらされる場合、 すべてのリカバリと修復オプションを評価して、迅速で安全なリカバリを実行す る必要があります。このような状況は、非常に負担が大きく、真夜中に発生する こともよくあります。管理者が修復時間のほとんどをデータ損失の内容、理由、 および経緯の調査に費やしているという調査結果があります。管理者は、多くの 情報を詳細に調査して、関連するエラー、アラート、およびトレース・ファイル を識別する必要があります。 リカバリの調査および計画フェーズの時間を最小限に抑えるために作成された Oracle Database 11g Data Recovery Advisor は、停止時間中の不確実性と混乱を軽減 します。Data Guard や RMAN などのオラクルの高可用性機能と緊密に統合されて いる Data Recovery Advisor は、すべてのリカバリ・シナリオを素早く正確に分析 します。この統合を通じて、Data Recovery Advisor は、特定の条件を考慮して実行 可能なリカバリ・オプションを識別できます。使用できるリカバリ・オプション は、リカバリ時間とデータ損失に基づいて、管理者に提供されます。Data Recovery Advisor を構成して、最適なリカバリ・オプションを自動的に実装できます。これ によって、管理者への依存性が軽減されます。
停止前に示されるエラーやトレース・ファイルの正確な分析に基づいて、多くの 障害シナリオを軽減できます。このため、Data Recovery Advisor は、さまざまな状 態チェックを実行して、データベースの条件を自動的かつ継続的に分析します。 データベースが停止する可能性のある兆候を Data Recovery Advisor が識別すると、 管理者は、リカバリ・アドバイスの取得を選択できます。また、必要なアクショ ンを実行して、関連する問題を修正してシステムの停止時間を回避できます。
Oracle Secure Backup
オラクルの新製品である Oracle Secure Backup は、データベースやファイル・シス テムを含む Oracle 環境全体の一元化されたバックアップ管理を提供します。また、 非常にセキュアで費用効率に優れた高パフォーマンスのテープ・バックアップ・ ソリューションを顧客に提供します。Oracle データベースとの緊密な統合によっ て、主要な競合製品よりも最大 25%速く Oracle データベースをバックアップでき ます。これを実現するには、データベース・エンジンへのダイレクト・コールと 未使用のデータ・ブロックをスキップする効率的なアルゴリズムを使用します。 Oracle Secure Backup とデータベース・エンジンとの統合が強化されるため、この パフォーマンスの利点が今後も増える予定です。この結果、特別な最適化が行わ れて、バックアップ・パフォーマンスがさらに向上します。
一 元 化 さ れ た テ ー プ 管 理 シ ス テ ム の Oracle Secure Backup は、主要な競合製 品よりも最大 25%速くデータベースを バックアップします。
Oracle Secure Backup は、Web ベースの GUI 管理ツールである Oracle Enterprise Manager とも統合します。管理者は、これまでになかった簡単な操作でテープ・ バックアップの設定やテープからのデータのリストアおよびリカバリを行うこと ができます。
計画停止時間の回避
通常、計画停止時間は、システムやアプリケーションのメンテナンスを実行する 時間を管理者に提供するために設定されます。このようなメンテナンス期間に、 管理者は、バックアップや修復、ハードウェア・コンポーネントの追加、ソフト ウェア・パッケージのアップグレードまたはパッチ適用、データ、コード、およ びデータベース構造を含むアプリケーション・コンポーネントの変更を行います。 今日のネットワーク化されたグローバル経済では、企業のアプリケーションと データベースに 1 日 24 時間アクセスできる必要があります。ネットワークとイン ターネット・テクノロジの進歩はビジネスの生産性に大きな影響を与えましたが、 このような進歩は、高可用性アーキテクチャの新しい課題と要件ももたらしまし た。図 5:システムの変更 オラクルでは、システムおよびアプリケーション停止時間を回避する一方で従来 のシステムとメンテナンス・アクティビティを継続する管理者のニーズを認識し ています。Oracle Database 11g の拡張機能は、この合理化された目的をさらにサ ポートします。
オンライン・システムの再構成
オラクルでは、Oracle ハードウェア・スタックのすべてのコンポーネントに対す る動的なオンライン・システム再構成をサポートします。オラクルの Automatic Storage Management(ASM)には、オンラインで ASM ディスクを追加または削除 できる組込み機能があります。ASM ディスク・グループからディスクを追加また は削除すると、オラクルは、ストレージ、データベース、およびアプリケーショ ンがオンラインの状態で新しいストレージ構成のデータを自動的にリバランスし ます。前述したとおり、Oracle Real Application Clusters は、優れたオンライン再構 成機能を提供します。管理者は、データベースまたはアプリケーションを損なう ことなく、クラスタ化されたノードを動的に追加および削除できます。オラクル は、このオンライン機能を持つ SMP サーバーの CPU の動的な追加または削除を サポートします。オラクルの動的な共有メモリー調整機能によって、管理者は共 有メモリーとデータベース・キャッシュをオンラインで拡大および縮小できます。 自動的なメモリー調整機能を使用すると、管理者は、Oracle がメモリー使用特性 を分析するたびに共有メモリーのサイジングおよび分散を自動化できます。オラ クルの広範なオンライン再構成機能によって、管理者は、メンテナンス・アクティ ビティによるシステム停止時間を最小限に抑え、必要に応じて企業の処理能力を 変更できます。オンラインのパッチとアップグレード
高可用性の要望のある企業は、Oracle テクノロジを活用して、エンド・ユーザー の介入なしでシステムのパッチ適用およびアップグレードを行うことができます。 Oracle Real Application Clusters と Oracle Data Guard を戦略的に使用すると、管理者 はビジネスの要望に応じて適切なサポートを行うことができます。ローリング・パッチ更新
オラクルは、パッチ適用プロセスでデータベースの可用性を実現するローリング 方式を使用して、Oracle Real Application Clusters(RAC)システムのノードへのパッ チ適用をサポートします。オンライン・パッチ適用プロセスを以下の図6 に示し ます。最初のボックスは、2 つのノードの RAC クラスタです。ローリング・アッ プグレードを実行するには、インスタンスのいずれかを静止します。クラスタの 他のインスタンスは、引き続きエンド・ユーザーにサービスを提供します。2 つ 目のボックスのインスタンス'B'では、すべてのクライアント・トラフィックがイ ンスタンス'A'に送信される間、静止してパッチが適用されます。パッチがインス タンスに正しく適用された後、クラスタに再接続してオンラインに戻すことがで きます。インスタンスが異なるメンテナンス・レベルで実行されていて、任意の 期間これを継続できることに注意してください。これによって、管理者は、クラ スタの残りのインスタンスにパッチを適用する前に、新しくパッチが適用された インスタンスをテストし検証できます。パッチが検証された後、同じローリング・ アップグレード方法を使用して、クラスタの他のインスタンスを静止してパッチ を適用できます。この例の 3 つ目のボックスは、静止してパッチが適用されたイ ンスタンス'A'とクライアント・トラフィックを再度受け入れるようになったイン スタンス'B'を示しています。最後に、クラスタのすべてのインスタンスにパッチ が適用されます。同じメンテナンス・パッチ・レベルで、クラスタ間のクライア ント・リクエストを再度オンラインでバランスします。OPATCH、オペレーティ ング・システム・アップグレード、およびハードウェア・アップグレードを使用 して、緊急用の 1 回限りのデータベースと診断パッチにローリング・アップグレー ド方法を使用できます。
Oracle RAC と Oracle Data Guard は、 パッチ、ハードウェア・メンテナンス、 およびソフトウェア・アップグレードの 実行中でもアプリケーションの可用性を 維持する戦略的な機能を提供します。
図 6:オンライン・パッチ
オンライン・ソフトウェア・アップグレード
オラクルの SQL Apply Data Guard テクノロジを利用すると、管理者は、データベー ス・パッチセット、主要リリース・アップグレード、およびエンド・ユーザーに 停止時間をほとんど提供しないクラスタ・アップグレードを適用できます。プロ セスは、ロジカル・スタンバイ・データベースのインスタンス化と Data Guard の 構成から開始され、本番データベースとスタンバイ・データベースの同期を維持 します。Data Guard 構成が完了した後に管理者が同期を一時停止すると、すべて の REDO データがキューに格納されます。スタンバイ・データベースがアップグ レードされてオンラインに戻ります。Data Guard はアクティブになります。キュー のすべての REDO データは、2 つのデータベース間のデータ損失がないように、 スタンバイ・データベースに伝播され適用されます。スタンバイ・データベース と本番データベースは、アップグレードが正常に終了したことがテストで確認さ れるまで、混合モードのままです。この時点で、スイッチオーバーの発生によっ て、スタンバイ・データベースが本番ワークロードを処理して本番データベース がアップグレードの準備状態になるデータベース・ロール切替えが行われる可能 性があります。本番データベースがアップグレードされると、スイッチオーバー 中にプライマリ・データベースに変換されたスタンバイ・データベースは、REDO データをキューに格納します。本番データベースがアップグレードされて REDO データが適用されると、2 回目のスイッチオーバーが発生して、元の本番システ ムが本番トラフィックを再取得します。以下の図 7 に、停止時間のほとんどない データベースのアップグレード・プロセスを示します。
図 7:ローリング・ソフトウェア・アップグレード
Oracle Database 11g では、"Transient Logical Standby(一時ロジカル・スタンバイ)" という新しい機能が導入され、ローリング・アップグレード・プロセスの魅力を さらに高めています。この機能によって、ユーザーは、一時的にフィジカル・ス タンバイ・データベースをロジカル・スタンバイ・データベースに変換して、ロー リング・データベース・アップグレードを実行でき、アップグレードが完了して からフィジカル・スタンバイ・データベースに戻します(KEEP IDENTITY 句を使 用)。これは、冗長ストレージに投資しないでローリング・データベース・アッ プグレードを実行したいフィジカル・スタンバイ・ユーザーに利点があります。 この機能を使用しない場合、ロジカル・スタンバイ・データベースを作成する必 要があります。
オンライン・データおよびスキーマ再編成
オンライン・データおよびスキーマ再編成では、再編成プロセスを通じてユーザー によるデータベースへの完全アクセスを許可することで、全体のデータベース可 用性を向上させ、計画停止時間を削減します。オラクルの各リリースでは、索引 の作成と再構築、表の再配置とデフラグ、列の追加、削除、名前変更などの強化 されたオンライン再編成機能が導入されました。オンライン再編成機能のサポー トは、アドバンスト・キューイング(AQ)表、マテリアライズド・ビューのログ、 抽象データ型(ADT)を使用した表、クラスタ化された表などの追加のオブジェ クト・タイプに継続して拡張されます。Oracle Database 10g の魅力的な新しいオン ライン再編成機能によって、管理者はセグメントから未使用の領域を取り戻すことができます。このため、エンド・ユーザーの介入なしでデータベース・フット プリントが削減されます。 オンライン・データとスキーマ再編成のさらなる改善が Oracle Database 11g で導 入されています。従来、デフォルト値の設定されている列を多くの行を含む表に 追加する場合、多くの時間がかかり、処理が終了するまで基本的に表がロックさ れるので、このプロセス実行中のアプリケーションの可用性が制限される可能性 がありました。オラクルは、デフォルト値が設定されている列を追加する方法を 大きく改善しました。このような技術革新によって、デフォルト値の指定に関連 するオーバーヘッドが削除されるので、デフォルト値の設定されている列の追加 がデータベースの可用性およびパフォーマンスに影響しません。 多くのデータ定義言語(DDL)のメンテナンス処理が強化されています。ノーウェ イト・ロックが不要になった DDL 処理もあります。管理者は、DDL 処理を中止 する前に、DDL 処理でロック待ちを許可する期間を定義できます。多くの DDL 処理が拡張されて、メンテナンス処理の期間に排他ロックではなく共有ロックが 取得されます。このような進歩によって、管理者は、ルーチン・メンテナンス処 理やスキーマ・アップグレードを実行する機能に影響を与えることなく、高可用 性の環境を維持できます。 Oracle Database 11g では、スキーマ・メンテナンスとアップグレード・プロセスを 通じて可用性を高めるために、索引の新しい属性が導入されています。索引は、 Invisible 属性を使用して作成できるようになりました。この属性を使用すると、 コストベースのオプティマイザ(CBO)で索引が無視されます。SQL 文内のヒン トは、アプリケーション SQL で誤って索引を使用することなくメンテナンスと アップグレードの SQL 文で索引を活用できるように、非表示の索引を CBO に対 して'可視化'します。索引が CBO に対して非表示の場合、非表示の索引は、DML 処理によって保守されます。本番の可用性に備えて索引を決定する場合、簡単な
Alter Index 文を使用して、CBO に対して索引を可視化します。
アプリケーション・アップグレード
ビジネス要件が向上すると、ビジネスをサポートするアプリケーションとデータ ベースも向上します。従来は、アプリケーションのアップグレードに計画停止時 間が必要でした。DBMS REDEFINITION パッケージ(Oracle Enterprise Manager で も使用可能)の戦略的な使用を通じて、管理者は、オンラインの本番システムを 引き続きサポートして、アプリケーションのアップグレードをシームレスに管理 できます。この API を使用する管理者は、アップグレード・プロセスで表の暫定 コピーを変更するので、挿入/更新/削除操作を含む元の表へのエンド・ユーザーに よるアクセスを許可できます。暫定表は、元の表と定期的に同期されます。アッ プグレード手順が終了すると、管理者は、最後の同期を実行して、アップグレー ドされた表をアクティブ化します。
パーティション化 データベースが大きくなると、管理が非常に困難になることがあります。パーティ ション化は非常に重要なテクノロジです。管理者は、大きい表と索引を管理の容 易な小さい単位に分割できます。ほとんどのメンテナンス・アクティビティをオ ンラインで実行できますが、1 度に 1 パーティションずつメンテナンスを行うと、 ほとんどのオンライン処理で柔軟性とパフォーマンスの利点があります。また、 パーティション化は、Oracle データベースのフォルト・トレランスを高めます。 管理者は、個別のパーティションを異なるディスクに戦略的に配置できます。こ のため、ディスク障害は、そのディスクのパーティションにのみ影響します。
Maximum Availability Architecture(MAA) - ベスト・プラクティス
IT インフラストラクチャの実装を成功させる鍵は、運用のベスト・プラクティス です。オラクルの Maximum Availability Architecture(MAA)は、オラクルの最善 の組合せによる高可用性(HA)テクノロジの統合スイートに基づくオラクルのベ スト・プラクティスの青写真です。MAA では、Oracle Real Application Clusters、 Oracle Data Guard、Oracle Recovery Manager、Oracle Enterprise Manager を含む高可 用性を実現する Oracle データベース機能を統合します。MAA には、サーバー、 ストレージ・システム、ネットワーク・システム、アプリケーション・サーバー などの重要なインフラストラクチャ・コンポーネントのベスト・プラクティスの 推奨事項も含まれます。テクノロジ以外に、MAA の青写真には、テストによって 最適なシステム可用性と信頼性を保証された特定の設計と構成の推奨事項が含ま れます。IT インフラストラクチャに MAA を活用する企業は、高可用性を実現す るビジネス要件を満たすアプリケーションを素早く効率的に配置できます。 オ ラ ク ル の Maximum Availability Architecture(MAA)は、最も包括的で費 用効率の高い高可用性テクノロジを提供 する最善の組合せによるテクノロジです。 テクノロジと運用ベスト・プラクティスを適切に組み合わせたオラクルの Maximum Availability Architecture によって、企業は堅牢な IT ソリューションを配置できま す。MAA のベスト・プラクティスは、継続的に拡張されています。MAA の詳細 は、 http://otn.oracle.co.jp/products/availability/htdocs/maa.html を参照してください。