マルチチャネル非負値行列因子分解における階層的クラスタ分析 を用いた音源分離性能の向上 *
浦本 昂伸
†上ノ原進吾
†古家 賢一
†Improvement of Sound Source Separation by Using Hierarchical Cluster Analysis in Multichannel Nonnegative Matrix Factorization
∗Takanobu URAMOTO
†, Shingo UENOHARA
†, and Ken’ichi FURUYA
†あらまし 非負値行列因子分解(Nonnegative Matrix Factorization: NMF)とは,非負値の行列を二つの非 負値行列に因子分解する手法である.音響分野では,NMFをマルチチャネル拡張することで空間情報を活用し,
高精度に音源分離を行う手法であるマルチチャネルNMF (Multichannel NMF: MNMF)が提案されている.し かし,MNMFは自由度の高いモデルであるため局所最適解に陥りやすく,分離性能の初期値依存性が課題となっ ている.先行研究として,2チャネルを用いた研究が盛んに行われているが,本論文では,3チャネル以上にチャ ネル数を増やした場合を検討する.音源の分離実験より,ランダムな初期値を設定した場合には,チャネル数を 増加させても,分離性能が向上しないことが確認された.そこで,ランダム初期値を設定した従来法の分離結果 として得られる空間相関行列を用い,分離信号に対して階層的クラスタ分析を行う.分析結果として得られたク ラスタの中で同じものに属する信号同士をアンサンブル平均することで,新たな信号を算出する手法を提案した.
ランダム初期値の場合よりも分離性能が向上することから,提案法の有効性を確認した.
キーワード 音源分離,雑音除去,非負値行列因子分解(NMF),マルチチャネルNMF,階層的クラスタ分析
1.
ま え が き近年,スマートフォンやハンズフリー機器,テレビ 会議システムなどの音声を取り扱うオーディオ機器が 身の回りに広く普及している.様々な音が混在する環 境下での利用が想定され,実際に利用する場合には,
周囲の雑音や他話者の音声の影響によって,目的音の 抽出が困難になるという問題が生じる.この問題の解 決には,音源分離技術が必要であり,様々なアプロー チが提案されている.例えば,音源の独立性を仮定 することで雑音と目的音を分離する独立成分分析
[1]
や独立ベクトル分析
(Independent Vector Analysis:
IVA) [2], [3]
,音源信号がスパースと仮定し時間周波数 マスキングにより分離するDUET (Degenerate Un- mixing Estimation Technique) [4]
,頻出する基底ご とに分離して雑音の成分を除く非負値行列因子分解†大分大学,大分市
Oita University, Dannnoharu, 700 Oita-shi, 870–1192 Japan
*本論文は学生論文特集秀逸論文である.
DOI:10.14923/transinfj.2018PDP0007
(Nonnegative Matrix Factorization: NMF) [5]
,IVA
にNMF
による低ランク近似分解を導入し,空間モデ ルと音源モデルを同時に推定することで分離を達成 する独立低ランク行列分析(Independent Low-rank Matrix Analysis: ILRMA) [6]
などがある.NMF
で は単一チャネルのモノラル信号から複数の音源に分離 できるが,基底ごとに分解した音を各音源に対応付け るのは容易ではない.そこで,NMF
をマルチチャネ ル拡張し,多チャネル信号に対応したマルチチャネルNMF (Multichannel NMF: MNMF)
が提案されてい る[7]
.MNMF
ではチャネル間の空間情報を活用し,音源数を事前に設定することで,音源と基底の対応付 けが可能である.
IVA
やILRMA
はMNMF
よりも,モデルパラメータ推定が容易かつ低コストで分離可能 であるが,優決定条件(音源数
≤
観測マイク数)の場 合において有効な手法である.一方,MNMF
は劣決 定条件(音源数>
観測マイク数)に有効な手法であ り,観測環境下に多くの音源が存在する場合でも,少 ないマイク数で分離できる.ただし,自由度の高いモデルであるため,局所最適解に陥りやすく,分離性能 の初期値依存性が課題となる
[8], [9]
.また,チャネル 数が増加するほど自由度が増加するので,この初期値 依存性が顕在化して分離が困難となる.先行研究によ り,チャネル数を増加させたMNMF
に対して有効な 手法が提案されており,分離行列にランダムな初期値 を設定する従来法に比べると事前に計算した初期値を 設定することで,分離性能が向上し,ばらつきが安定 することが分かっている[10]
.ただし,問題点として 初期値を計算するには,あらかじめ音源の到来方向が 既知でなければいけないなどの制約条件が必要となる.本論文では,
MNMF
のチャネル数増加によって引 き起こる分離性能低下の問題を解決するための手法と して,事前の初期値設定を行わず,ランダム初期値の まま音源分離をして得られた分離信号を利用し,新た な信号を算出する手法を提案する.この手法では,複 数のランダム初期値を用いた音源分離の後,得られた 行列をもとにクラスタ分析を行う.そして,同じクラ スタに属する行列から復元した信号をアンサンブル平 均することで,単一のランダム初期値の分離信号より も高い分離性能をもつ新たな信号を算出する.得られ た信号から分離性能を評価して,提案法の有効性を検 証する.論文の構成は以下のようである.
2.
では,MNMF
について説明し,3.
では,ランダムに初期値を設定し チャネル数を増加させた場合の分離性能の初期値依存 性について実験的に分析を行う.4.
では,チャネル数 を増加させた場合に有効な階層的クラスタ分析とアン サンブル平均を用いた手法を提案し,5.
では,提案法 の評価実験を行う.最後に6.
で本論文をまとめ,今 後の課題を提示する.2. MNMF
2. 1
概 要MNMF [7]
とは,NMF [5]
をマルチチャネル拡張し たものであり,複素観測行列X
を2. 2
に述べる四つ の行列H, Z, T, V
に分解する.MNMF
では空間情 報を用いてスペクトル基底をL
個の音源にクラスタ リングすることで事前の学習なしで音源分離を実現す る.位相情報を扱うために複素数を用いるので,複素 数における非負性に対応するものとして,エルミート 半正定値行列を用いる[7]
.2. 2
定 式 化M
をマイクロホン数として入力ベクトルを˜ x =
[˜ x
1, · · · , x ˜
M]
とする.ただし,は転置を表す.x ˜
mは
m
番目のマイクロホンでのShort Time Fourier Transform (STFT)
の複素係数であり,スペクトログ ラムを指す.周波数i (1 ≤ i ≤ I )
,時間j (1 ≤ j ≤ J )
のとき˜ x
ijで表すと行列X
のi , j
成分をX
ijとし,X
ij= ˜ x
ijx ˜
Hij若しくはi , j
それぞれについてX
ij= ˜ x
ij˜ x
Hij=
⎡
⎢ ⎣
| x ˜
1|
2· · · x ˜
1x ˜
∗M.. . . . . .. . x ˜
Mx ˜
∗1· · · |˜ x
M|
2⎤
⎥ ⎦ (1)
となる.ただし,Hはエルミート転置を表し,対角成 分には各マイクロホンで観測したパワー(実数),非対 角成分にはマイクロホン間の位相差(複素数)が示さ れる.すなわち,行列
X
は,I
行J
列のそれぞれの要 素がM × M
のエルミート半正定値行列であり,これ らの行列からなる階層的な構造をもつ.この行列X
をMNMF
で分解すると,K
個の基底からなる基底行列T ( ∈ R
I×K)
,アクティベーション行列V ( ∈ R
K×J)
, 音源の空間情報を示す空間相関行列H
と音源の空間情 報と各基底を関連付ける潜在変数行列Z(∈ R
L×K)
と いう四つの行列の積X ˆ
に分解され,次式で示される.X ≈ X ˆ = ( HZ ◦ T ) V (2)
ただし,
◦
はアダマール積を表す.行列H
は行列X
と同様にそれぞれの要素がM × M
の複素行列をもつI
行L
列の階層的なエルミート半正定値行列である.図
1
は式(2)
を図式化したもので,このとき,右辺はX ˆ
ij=
K k=1 L l=1H
ilz
lkt
ikv
kj(3)
と表すことができ,理想的には行列
X
とˆX
ijを要素 にもつ行列X ˆ
は等しくなる.しかし,一般的には誤差 が生じるため,MNMF
では行列X
と行列X ˆ
との距離図1 MNMFで分解された行列の例(グレーは複素数)
Fig. 1 Example of a decomposed matrix by using MNMF (Gray denotes complex values).
D
∗( X, X ˆ ) =
Ii=1
J j=1d
∗( X
ij, X ˆ
ij) (4)
を定義し,この距離を最小化する行列
T , V , H , Z
を 求める.今回はダイナミックレンジが大きい音楽や音 声に適しているItakura-Saito (IS) divergence [14]
を 用いる.式(4)
の右辺におけるX
ijとX ˆ
ij間の距離に ついて以下のように定義する.d
IS( X
ij, X ˆ
ij) =
tr ( X
ijX ˆ
−ij1) − log det X
ijX ˆ
−ij1− M (5)
ただし,tr (
・)
は対角要素の和を表している.2. 3
行列分解アルゴリズムD
IS(X, X) ˆ
を最小化するために,Multiplicative up- date rule [15]
と呼ばれる反復アルゴリズムを,ランダ ムな非負の値で初期化した行列T
,V
,Z
並びに各要 素へ単位行列をもたせた行列H
に繰り返し適用する.IS divergence
を用いた場合,更新式は以下のように なる.t
ik←t
ikl
z
lkj
v
kjtr (ˆ X
−ij1X
ijX ˆ
−ij1H
il)
l
z
lkj
v
kjtr (ˆ X
−ij1H
il) (6)
v
kj←v
kjl
z
lki
t
iktr (ˆ X
−ij1X
ijX ˆ
−ij1H
il)
l
z
lki
t
iktr (ˆ X
−ij1H
il) (7)
z
lk←z
lki,j
t
ikv
kjtr (ˆ X
ij−1X
ijX ˆ
−ij1H
il)
i,j
t
ikv
kjtr (ˆ X
−ij1H
il) (8) H
ilについては次式のA
,B
を係数にもつ代数リッカ チ方程式を解くことで求めることができる.A =
k
z
lkt
ikj
v
kjX ˆ
−ij1(9)
B = H
ilk
z
lkt
ikj
v
kjX ˆ
−ij1X
ijX
−ij1H
il(10)
H
ilAH
il= B (11)
ただし,
H
ilは更新前の行列H
ilを表しており,解き 方は文献[7]
に示されている.2. 4
正 規 化行列
H
と行列Z
については,更新ごとに発散を防ぐために正規化を行わなければならない.正規化は以 下の式で行った.
H
il= H
iltr ( H
il) ,
z
lk= z
lkl
z
lk(12)
2. 5
音 源 分 離音源分離を行うために次式で表されるウィナーフィ ルタを用いる.
Y = S ˆ
S ˆ + N X (13)
た だ し ,
Y
は 目 的 信 号 ,S ˆ
は 目 的 信 号 の 推 定 値 ,N
は雑音信号,X
は雑音信号を含んだ目的信号を 示 す.y ¯
(ijl) を 分 離 後 の 音 源 と し た と き ,Y = ˜ y
(ijl), S ˆ = (
Kk=1
z
lkt
ikv
kj) H
il, ˆ S + N = ˆ X
ij, X = ˜ x
ijを 代入すると,次式のマルチチャネルウィナーフィルタ となり,各音源に対応した分離信号を得られる[7]
.y ˜
(ijl)=
K k=1z
lkt
ikv
kjH
ilX ˆ
−ij1x ˜
ij(14)
3.
チャネル数増加に伴う初期値依存性の 分析MNMF
は自由度の高いモデルであるため,反復更 新処理の最中に局所最適解が増えることで,2
チャネ ルの場合でも初期値依存による分離性能のばらつきが 問題となることが報告されている[8]
.更に3
チャネ ル以上になると,この初期値依存性が顕在化すること によって,音源分離がより困難になる[10]
.ここでは,ランダム初期値の従来法でチャネル数を増加させた場 合の初期値依存性について実験的に提示する.
3. 1
実 験 条 件実験に用いた混合信号は表
1 [16]
の音楽データに,図
2
の環境で測定したRWCP
実環境音声・音響デー タベースのインパルス応答(E2A) [17]
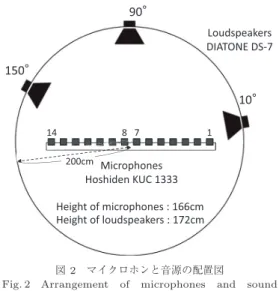
を畳み込み作成 した.図2
においてマイクロホンは右から順に1-14
ま で番号が付いている.今回の実験で使用したマイクロ ホン番号を表2
に示す.ここで,チャネル数を増やし た際に,元のマイクロホンが含まれているようにした.例えば
3
チャネルのマイクロホンの組には2
チャネル のマイクロホンの組が含まれている.なお,使用マイ クロホン間隔は5.66cm
である.分離処理に用いたパ ラメータを表3
に示す.なお,表3
をもとに計算した 表1
の各音楽データのスペクトログラムは,I =513
,J
図2 マイクロホンと音源の配置図
Fig. 2 Arrangement of microphones and sound sources.
は
ID1
:991
,ID2
:1598
,ID3
:1536
,ID4
:1161
であ る.また,MNMF
でのIS divergence
の計算(4)
にお いて行列式が0
になるのを防ぐためにX
ijの対角要素 に10
−10を足している.プログラムはSawada
らのア ルゴリズム[7]
をMATLAB
で実装した.ただし,音 源数は既知としてpairwize-merge
は導入せず,Mul- tiplicative update rule
の反復適用のみ行っている.また,文献
[7]
に倣い,初めの20
回は空間相関行列H
と潜在変数行列Z
を更新せず,その他の変数のみを更 新した.潜在変数行列Z
と基底行列T
,アクティベー ション行列V
には,一様分布から生成した10
個の初 期値パターンを用意し,音源分離を実行する.ただし,文献
[7]
と同様に空間相関行列H
は対角成分が1 /M
の対角行列,潜在変数行列Z
は0.2
〜0.4
の一様乱数を もたせた.分離性能の評価基準は,分離信号が目的と する正解信号に対してどの程度ひずんでいるのかをパ ワー比で表すSignal-to-Distortion Ratio (SDR) [18]
を用いた.
SDR
の計算には,[19]
に公開されているス クリプトを利用した.なお,bss decomp mtifilt.m
を 用いて式(15)
,bss mcrit.m
を用いて式(16)
の計算 を行った.SDR
を計算する際に評価したい音を成分 ごとに分解しなければならない.分解するとs
est( t ) = s
img( t )+ y
spat( t )+ y
int( t )+ y
artif( t ) (15)
となる.ここで,s
estは目的音源の推定信号,s
imgは 目的音源の正解信号,y
spatは空間(フィルタリング)ひずみ,
y
intは目的音源以外の音源の信号,y
artifは 分離処理による信号のひずみを表す.これらは最小2
表1 実験に用いた音楽データ Table 1 Music data used for the experiment.
ID Author/Song Snip Part
1 Bearlin 85-99 piano
Roads (14 sec) ambient vocals 2 Another Dreamer 69-94 drums The Ones We Love (25 sec) vocals guitar
3 Fort Minor 54-78 drums
Remember The Name (24 sec) vocals violin+synth
4 Anonymous 43-61 drums
Ultimate Nz Tour (18 sec) guitar synth
表2 チャネル数ごとのマイクロホン番号 Table 2 Microphone IDs of each channel.
2ch 6,8 3ch 6,8,10 4ch 4,6,8,10 5ch 4,6,8,10,12 6ch 2,4,6,8,10,12
表3 分離処理に用いるパラメータ Table 3 Parameters of a separation process.
Reverberation time 300ms Sampling rate 16kHz Flame size 1024
Shift size 256 Number of basis K 30 Number of source L 3 Number of iteration 500
乗法による予測によって求めることができる.なお,
フィルタサイズは
512 (32ms)
とした.そして,これ らの成分を用いてパワー比を計算するとSDR = 10 log
10t
s
img( t )
2t
y
spat( t )
2+ y
int( t )
2+ y
artif( t )
2(16)
を求めることができる.この尺度を用いる場合は各音 源の独立したデータが必要である.3. 2
初期値依存性図
3
は2
チャネルを用いたときのMNMF
におい て,行列Z
,T
,V
にランダムな初期値を10
回与え て音源分離を行ったときの分離性能の結果を示してい る.音楽データは表1
のID4
を使用した.この図か ら,1
回目の分離ではSDR
が約6 . 5 dB
だが,3
回目 ではSDR
が約1 dB
というように設定した初期値に よって分離性能が大きく異なっていることが分かる.3. 3
チャネル数増加に伴う初期値依存性ランダム初期値の従来法において,単純にチャネル
図3 音源分離性能の初期値依存性
Fig. 3 Initial-value dependency of sound source sep- aration performance.
図4 チャネル数増加に伴う初期値依存性 Fig. 4 Initial-value dependency with increasing the
number of channels.
数を増やした場合の分離性能の結果を示す.図
4
は 各音楽データとチャネル数ごとの分離後に得られた3
音源の平均SDR
を示したものである.エラーバーはSDR
のばらつきの大きさを表した標準偏差である.こ の図から,チャネル数が増加しても分離性能が必ずし も向上しないことや標準偏差が大きくなることが分か る.これは,局所最適解による初期値依存性がチャネ ル数の増加に伴って,より顕在化したためだと考えら れる.4.
提 案 手 法4. 1
着 眼 点MNMF
の分離性能は,空間相関行列H
に対する初 期値依存性が最も大きいことが分かっている[9]
.そこ で,行列H
に着目する.ここでは,初期値がランダム の従来法で得られた分離後の行列H
に対して,SDR
が最も高いものとその他との関係性について,二つの 行列H
の非対角成分の差の絶対値を距離として用い て分析を行った.この距離はそれぞれの音源に対応す図5 bestHとの距離とSDRの関係性(2ch) Fig. 5 Relationship between distance to bestH and
SDR.
表4 チャネル数ごとの相関係数 Table 4 Correlation coefficient for each channel.
2ch -0.87 3ch -0.91 4ch -0.94 5ch -0.91 6ch -0.86
る二つのマイクロホン間の相関同士の違いの大きさを 表している.行列
H
間の差異を評価するには,対角 成分に含まれるパワーよりも非対角成分の位相情報を 用いた方が2
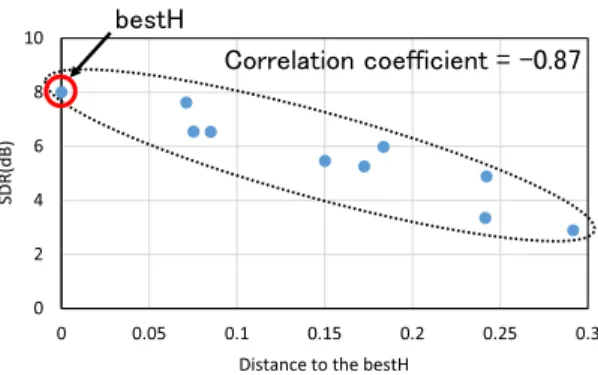
点間を比較するには望ましいと考え,こ の距離を採択した.図5
では,最もSDR
が高いもの をbestH
と表記した.bestH
から距離が離れていく ほどSDR
が低下する傾向が見られる.表4
に示され るように,各チャネル数で距離とSDR
には高い負の 相関が見られる.そこで,提案法ではこれらの関係性 に着目し,複数のランダムな初期値に対する分離後の 行列H
に対して,上記距離に基づいて階層的クラスタ 分析を行う.その結果,得られたクラスタの中で同じ ものに属する信号同士をアンサンブル平均して,SDR
という観点から単一のランダム初期値から復元された 分離信号よりも更に高性能な分離信号を算出する手法 を提案する.4. 2
階層的クラスタ分析階層的クラスタ分析
[11]
とは,数値分類法の一種で ある.異なる集団に属する複数の個体から個体間の距 離に基づいて,類似するものを順次集めてクラスタ を作成する手法である.なお,個体間距離には分離後 の行列H
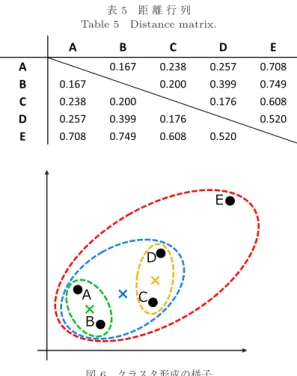
の非対角成分に含まれる位相情報を利用し,二つの行列間の差の絶対値の位相を距離として計算し た.表
5
は五つの個体について,全ての組合せについ て距離を計算し,行列の形式で配列した距離行列であ表5 距 離 行 列 Table 5 Distance matrix.
図6 クラスタ形成の様子 Fig. 6 State of cluster formation.
る.数値が小さいほど,互いに類似度が高い(距離が 近い)ことを示す.クラスタ分析を行う際には,この ような距離データを基準としてクラスタを分類する.
図
6
はクラスタ形成の様子を示している.はじめにA
〜E
の五つの標本点がある.その中で最も距離が近 い組合せは,A
とB
である.A
とB
でクラスタを形 成し,この2
点の重心を求める.次にAB
の重心,C
,D
,E
の4
点で最も距離の近い組合せを探索する.C
とD
が最も距離が近い組合せなので,C
とD
でクラ スタを形成し,重心を求めて新たな組合せを探索する といった処理を残りの標本点がなくなるまで繰り返し 行う.それと同時にクラスタが形成される途中過程を 階層のように表すことができ,図7
のようなデンドロ グラム(注1)ができる.ただ分類するだけではなく,結 果として出力されるデンドログラムから任意の数のク ラスタに分類することが可能である.例えば図7
を三 つのクラスタに分類する場合は,縦線を横に切るよう な線を引き,その線から下につながっている葉を一つ のクラスタとする.なお,クラスタ間の距離計算には ウォード法[12]
を使用した.(注1):木構造に似ているグラフで,ラベルが付いている箇所を葉と言 い,葉から伸びている線が連結するまでの高さが短いほど個体が類似し ている.
図7 クラスタ分析の例 Fig. 7 Example of cluster analysis.
4. 3
行列距離の求め方行列
H
の各成分はM × M
の行列から構成されて おり,これらの非対角成分の差の絶対値の位相をクラ スタ分析に用いる距離とした.行列距離をD
,標本数 をN
として,NC
2個の重複しない組合せから全ての 距離について以下の式から算出する.なお,この距離 は距離の公理を満たす(付録参照).D =
Ii=1
L l=1a
il(17)
a
il=
M1
m1=1 M2
m2=1
2arcsin( | ( h
(mN1=mn2)− h
(mN1=mn2)|
2 ) u
m1m2(18)
U =
⎡
⎢ ⎢
⎢ ⎣
u
11· · · · u
1m2.. . . . . .. . .. . . . . .. . u
m11· · · · u
m1m2⎤
⎥ ⎥
⎥ ⎦ =
⎡
⎢ ⎢
⎢ ⎣
0 1 · · · 1 .. . . . . . . . .. . .. . . . . 1 0· · · · 0
⎤
⎥ ⎥
⎥ ⎦
(19)
ただし,MNMF
の性質上,異なる初期値で分離す るたびに行列H
のl
番目に一意の音源情報が定まら ない.そこで,L !
個の並び替えを考慮して,全通りの 距離D
を計算する.その中で,最小の距離を同じ順でl
が並んでいると判断し,クラスタ分析に適用する距 離として算出する.その様子を図8
に示す.4. 3. 1
ウォード法ウォード法とは,二つのクラスタを結合したときに クラスタ内の分散が小さく,かつクラスタ間の分散の 比を最大化する基準でクラスタを形成する手法である.
標本点を
x
iとし,二つの標本点x
1,x
2に対して距離 を用いる場合はD ( x
1, x
2)
と表す.同様に各クラスタ図8 行列H間距離の計算
Fig. 8 Calculation of distance between matrix H.
を
C
iとすると,クラスタ間距離はD ( C
1, C
2) = E ( C
1∪ C
2) −E ( C
1) −E ( C
2) (20)
と定義される.ただし,E ( C
i) =
x∈Ci
( D ( x, c
i))
2(21)
であり,
c
iはクラスタの重心となる標本平均ベクトル であり,以下の式から求める.c
i= 1
|C
i|
x∈Ci
x (22)
4. 4
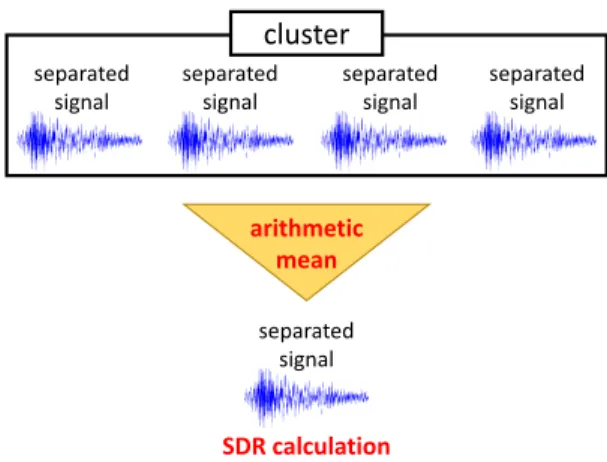
アンサンブル平均アンサンブル平均
[13]
とは,同一の信号を複数回観 測し,加算平均することで雑音を抑圧する手法である.x
は観測信号,s
は目的音源の正解信号,w
は雑音信 号ならば,x
n= s
n+ w
n(23)
と表せる.更に,観測信号を何度も取得し,それらの 平均を計算することで,
1 N
N n=1x
n= 1 N
N n=1( s
n+ w
n) (24)
となる.観測回数が
N
回のとき,もしも同じ目的信 号を繰り返し取得できれば,それらを平均することで 不規則に発生する雑音の影響を少なくすることができ,N →∞
で目的音源s
に近づいていく.このとき,目的 信号の振幅は等しく,一方で雑音信号は1/ √
N
倍と なる.SN
比は√
N
倍に向上し,相対的に目的信号が図9 信号に対するアンサンブル平均の例 Fig. 9 Example of ensemble processing on signals.
強調されることになる.提案法では,クラスタ分析の 後に得られた同じクラスタ内に属する信号に対してア ンサンブル平均を適用する.
4. 5
信号の並び替え4. 3
で述べたように,MNMF
は異なる初期値で分 離するたびに行列H
のl
がもつ音源情報の順番は異 なる.同様に復元した分離信号も一意の箇所に割り当 てられない.ただし,アンサンブル平均する際には同 じ種類の音源の分離信号同士で行うため,分離信号の 順番を揃えておく必要がある.そこで,行列H
間の 距離D
を計算するときの並び替え情報を利用する.図8
に示されるように距離D
の計算には,L !
個の並び替 えを考慮して全通りの中から最小のものを算出してい る.同時に並び替え情報を取得し,それらをもとに復 元した信号を並び替えるようにした.4. 6
信号に対するアンサンブル平均初期値パターンが
10
個であるため,クラスタ数を2
〜9
に設定して分析する.音楽データは表1
のID4
を使用した.分類の結果,同じクラスタに属する行列H
によって得られた分離信号のうち,同一音源に対 応する分離信号をアンサンブル平均して算出した信号 からSDR
を計算した.図9
にアンサンブル平均のイ メージを示す.図10
は2
チャネルのデンドログラム を示し,最もSDR
が高いクラスタを赤色,最も低い クラスタを青色で囲んでいる.なお,葉の部分の数値 は分離実験に用いた初期値パターンを生成したときの シード値を示している.同じクラスタに属する信号同 士をアンサンブル平均することで,best
(従来法にお ける最高SDR
)よりも高いSDR
を得ることができ図10 デンドログラム(2ch) Fig. 10 Dendrogram (2ch).
表6 クラスタ数とSDRの関係性
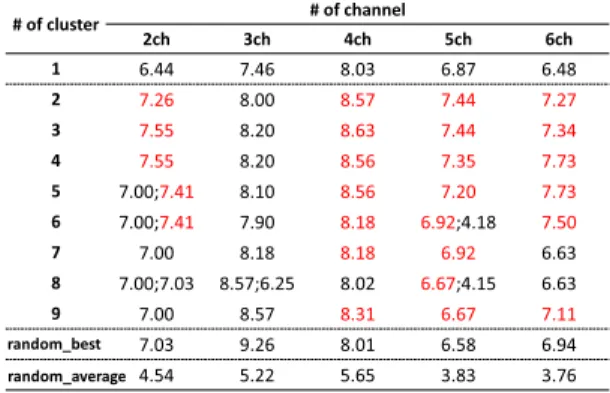
Table 6 Relationship between number of cluster and SDR.
た.また,最も
SDR
の高いクラスタはbest
を含んで おり,最もSDR
が低いクラスタは,これとは離れた 位置に存在している.更に,SDR
が最高のクラスタ は,分類されたクラスタの中で最大の要素数を含んで いる傾向が見られた(他のチャネル数でも同様).表6
に要素数最大のクラスタに属する信号同士をアンサ ンブル平均して計算したSDR
の分析結果を示す.な お,表中のクラスタ数1
はクラスタ分析をせずに全て の分離信号同士をアンサンブル平均して算出した信号 からSDR
を計算したものである.チャネル数とクラ スタ数にもよるが,おおむねbest
を超えるSDR
(赤 色で表示)が算出されており,average
(従来法にお ける平均SDR
)に対しては,全てのパターンで上回っ ていることが確認できる.4. 7
提案法の手順まとめ本論文の提案法は以下のとおりである.
(
1
)MNMF
の行列Z
,T
,V
にランダムな10
個 の初期値パターンを用意し,乗算更新式の適用によるMNMF
のパラメータ推定を10
回行う.(
2
) 分離後に得られた行列H
をもとにクラスタ リングする.(
3
) 要素数最大のクラスタに属する行列H
とそ れらに対応するZ
,T
,V
を用いて,式(14)
により 音源分離を行い,分離信号を算出する.(
4
) 各音源分離で得られた分離信号のうち,同一 の音源に対応するものをアンサンブル平均することで,仮定した音源数
( L = 3)
と同数の分離信号を算出する.要素数最大という基準でクラスタを選ぶため,音源 分離をするときに事前知識を使わず従来の初期値依存 性の問題を緩和することができる.
5.
実 験4. 6
では,表1
の音楽データID4
に対して分析を 行った.ここでは,ID1
〜ID3
に対しても同様の分析 を行い,評価実験を通して,提案法の有効性について 検証する.実験条件は3. 1
と同じである.5. 1
提案法を各指標と比較表
6
に示すように,クラスタ数2
〜9
に分類した 中で最も高いSDR
が得られたクラスタ数3
のSDR (“proposed cluster = 3”)
を4. 6
でも用いた以下の 指標と比較する.•
ランダム初期値の従来法における平均SDR (“random average”
と表記)
•
従来法における最高SDR (“random best”) 5. 2
実 験 結 果5. 2. 1
では,従来法と提案法で得られた分離性能 を示す.5. 2. 2
では,ID4
を分離したときのチャネル 数増加に伴う計算時間を示す.5. 2. 3
では,6
チャネ ルのID4
を分離したときを対象として,更新回数とSDR
の関係性を示す.計算には,Intel Core i7-4790 (3.40 GHz) CPU
を搭載したMATLAB 8.2
(64
ビッ ト)を使用した.5. 2. 1
分離性能の比較図
11
は分離性能の比較結果である.なお,音楽デー タID1
〜ID4
から得られた結果の平均を示す.各音楽 データの結果から平均を求めた場合でも,従来法より も高いSDR
が算出された.また,各チャネル数にお いて同等の性能が得られたことが確認できる.ただし,従来法の
best
に性能が及ばない部分も見られる.5. 2. 2
チャネル数増加に伴う計算時間図
12
は従来法と提案法における計算時間である.な お,提案法はクラスタ分析に掛かる時間を含む.本論図11 提案法による実験結果 Fig. 11 Experimental result.
図12 計 算 時 間 Fig. 12 Computational time.
文の実験条件により,提案法は各チャネル数で
10
回 ずつ分離をしてからクラスタ分析を適用するので,従 来法の約10
倍の計算時間が掛かる.また,チャネル 数の増加に伴って,計算時間が増加することが分かる.計算量はおよそ
O(n
3)
である.5. 2. 3
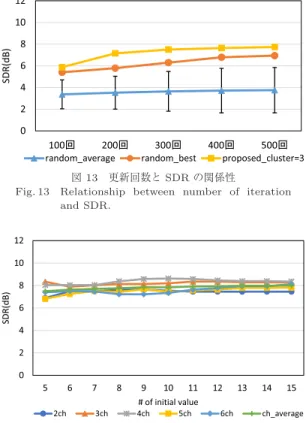
更新回数とSDR
の関係性図
13
は100
,200
,300
,400
,500
回ごとに階層的 クラスタ分析とアンサンブル平均を適用したときの結 果である.本論文の実験条件により,500
回の更新回 数のもとで分離を行っているが,図13
から提案法は200
〜300
回の間でSDR
が収束していることから,少 ない更新回数で高い性能を得られることが分かる.そ のため,図12
における(“proposed cluster”)
で費や している時間のおよそ2/5
まで削減することが可能で ある(“reduction”)
.5. 3
初期値パターン数についての検証ここでは,ランダム初期値のパターン数について検 証する.これまでパターン数を
10
に固定して実験を 行ってきたが,更に5
〜15
まで一つずつパターン数を 増やして提案法を適用する.なお使用音楽データはID4
である.図13 更新回数とSDRの関係性
Fig. 13 Relationship between number of iteration and SDR.
図14 初期値パターン数5-15 (cluster = 3) Fig. 14 Number of initial-value patterns 5-15 (cluster =
3).
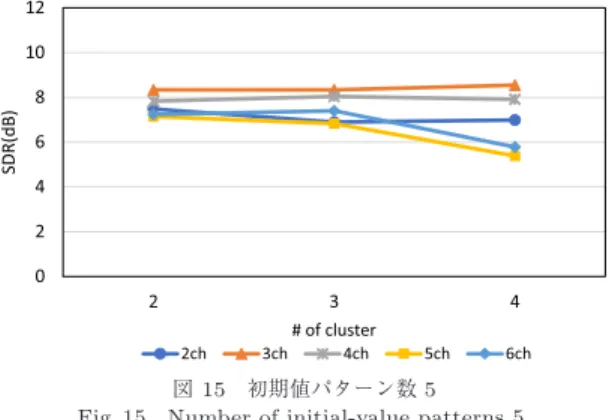
図
14
は各パターン数における分離性能の比較結 果である.ただし,5. 1
と同様にクラスタ数3
とし,(“ch average”)
は各パターン数における全チャネル数 のSDR
の平均を示す.各パターン数においてSDR
が 約8 dB
となっていることが分かる.図
15
はパターン数5
,図16
はパターン数10
,図17
はパターン数15
において,提案法を適用したとき の結果である.それぞれのグラフから,少ないクラス タ数に分類した場合よりも多くのクラスタに分類した 方がSDR
低下が見られる.他のパターン数において も同じ傾向が見られた.5. 4
考 察図
11
から提案法において,各チャネル数において 従来法の(“random average”)
よりも高い分離性能を もつ信号が算出できていることが分かる.従来法では チャネル数とともに行列の自由度が増加するため,局 所最適解に陥りやすくなり分離性能の低下,ばらつき の拡大が課題となる.一方,提案法では各チャネル数 で同等の分離性能が得られていることから,分離性能図15 初期値パターン数5 Fig. 15 Number of initial-value patterns 5.
図16 初期値パターン数10 Fig. 16 Number of initial-value patterns 10.
図17 初期値パターン数15 Fig. 17 Number of initial-value patterns 15.
の向上に加えて安定化という側面からも有効だと考え られる.ただし,
best
よりも分離性能が及ばない部分 に関しては,表6
の3ch
に示されるように,best
のSDR
が他のSDR
よりも抜き出て高いため,他の信号 と加算平均することで却って低下してしまったのだと 考えられる.図
12
から,音源分離の試行回数とチャネル数に依 存して計算コストが増加していくことが分かる.ただし,図
13
から提案法では1
回の音源分離に要する更 新回数が200
〜300
の間でSDR
が収束していること が分かるため,更新回数の削減によって,更に高速な 分離が可能だと考えられる.図
14
から,パターン数5
〜15
の範囲内で大きな分 離性能の差異は見られなかった.パターン数が多すぎ ると,同一クラスタ内に属する行列H
から復元され た信号の目的音が全く同じではなく,雑音が無相関で はないものが増加する可能性があるため,アンサンブ ル平均の効果が薄くなったのだと考えられる.またパ ターン数が少なすぎても,アンサンブル平均の効果は あまり得られないと考えられる.更に2
チャネルでは パターン数9
,3
チャネルではパターン数11
,4
チャネ ルではパターン数10
のときに最高の分離性能が得ら れている.チャネル数によって違いはあるが,パター ン数10
付近が妥当だと考えられる.図
15
,図16
,図17
から,いずれのパターン数の場 合でも多くのクラスタに分類したときに比べ,少ない クラスタに分類したときの方が高い分離性能が得られ ており,各チャネル数同士の性能の差異も小さいこと が分かる.そのため,パターン数に関係なく,少ない クラスタに分類したときのものから分離信号を復元す ることが望ましいと考えられる.6.
む す び本論文では,
MNMF
のチャネル数増加に伴う初期 値依存性によって起こる分離性能低下の問題を解決す るために,階層的クラスタ分析とアンサンブル平均を 用いた音源分離手法を提案した.ランダム初期値の従 来法で音源分離を行うと分離性能のばらつきが見られ た.そこで提案法では,階層的クラスタ分析を用いる ことで,複数のランダム初期値で音源分離をして得ら れた行列H
を分類し,同じクラスタ内の行列H
から 復元された信号同士をアンサンブル平均することに よって,単一の分離信号よりも更に高い分離性能をも つ信号を算出することができた.また,チャネル数が 増加すると分離性能が低下する従来法に比べ,提案法 では各チャネル数で一定の性能が得られていることか ら,チャネル数にかかわらず音源分離が行えると考え られる.ただし,試行回数が少ないため今後パラメー タを増やすなど,回数を重ねた実験を行う必要がある.現状では,実験を行うのに多大な時間を要するため,
今後,計算時間の短縮を検討していく必要がある.
文 献
[1] T.-W. Lee, Independent Component Analysis-Theory and Applications, Kluwer, Norwell, MA, 1998.
[2] A. Hiroe, “Solution of permutation problem in fre- quency domain ICA using multivariate probability density functions,” ICA 2006 (LNCS 3889), pp.601–
608, 2006.
[3] T. Kim, T. Eltoft, and T.-W. Lee, “Independent vec- tor analysis: An extension of ICA to multivariate components,” ICA 2006 (LNCS 3889), pp.165–172, 2006.
[4] O. Yilmaz and S. Rickard, “Blind separation of speech mixtures via time-frequency masking,” IEEE Trans. Signal Process., vol.52, no.7, pp.1837–1847, 2004.
[5] D.D. Lee and H.S. Seung, “Learning the parts of objects with nonnegative Matrix Factorization,” Na- ture, vol.401, pp.788–791, 1999.
[6] D. Kitamura, N. Ono, H. Sawada, H. Kameoka, and H. Saruwatari, “Determined blind source separation unifying independent vector analysis and nonnegative matrix factorization,” IEEE Trans. Audio, Speech, Language Process., vol.24, no.9, pp.1626–1641, 2016.
[7] H. Sawada, H. Kameoka, S. Araki, and N. Ueda,
“Multichannel extensions of non-negative matrix fac- torization with complex-valued data,” IEEE Trans.
Audio, Speech, Language Process., vol.21, no.5, pp.971–982, 2013.
[8] 吉山文教,上ノ原進吾,西島恵介,古家賢一,“マルチチャ ネル非負値行列因子分解における分離性能の高い初期値の 判別法,”音響講論集,pp.777–780, 2014.
[9] 三浦伊織,太刀岡勇気,成田知宏,石井 純,吉山文教,
上ノ原進吾,古家賢一,“マルチチャネルNMFを用いた 音源分離における初期値依存性の挙動解析と音声認識で の評価,”信学論(D),vol.J100-D, no.3, pp.376–384, March 2017.
[10] 浦本昂伸,太刀岡勇気,成田知宏,三浦伊織,上ノ原進吾,
古家賢一,“マルチチャネルNMFを用いたブラインド音 源分離のためのチャネル数増加に伴う逐次的初期化法,”信 学論(D),vol.J101-D, no.3, pp.569–577, March 2018.
[11] 新納浩幸,Rで学ぶクラスタ解析,オーム社,2007.
[12] J.H. Ward, Jr., “Hierarchical grouping to optimize an objective function,” J. American Statical Associ- ation, vol.58, pp.236–244, 1963.
[13] 日野幹雄,スペクトル解析,朝倉書店,1977.
[14] C. Fevotte, N. Bertin, and J.-L. Durrieu, “Nonneg- ative matrix factorization with the Itakura-Saito di- vergence: With application to music analysis,” Neu- ral Comput., vol.21, no.3, pp.793–830, 2009.
[15] M. Nakano, H. Kameoka, J.L. Roux, Y. Kitano, N. Ono, and S. Sagayama, “Convergence-guaranteed multiplicative algorithms for non-negative matrix factorization with beta-divergence,” Proc. MLSP 2010, pp.283–288, 2010.
[16] S. Araki, F. Nesta, E. Vincent, Z. Koldovsk´y, G.
Nolte, A. Ziehe, and A. Benichoux, “The 2011 signal separation evaluation campaign (SiSEC2011): Audio source separation,” Latent Variable Analysis and Sig- nal Separation, pp.414–422, Springer, Bearlin, 2012.
[17] RWCP, “実環境音声・音響データベース(RWCP-SSD),” 音声資源コンソーシアム,http://research.nii.ac.jp/src/
RWCP-SSD.html,閲覧日:2017/05/31.
[18] E. Vincent, H. Sawada, P. Bofill, S. Makino, and J.
Rosca, “First stereo audio source separation evalua- tion campaigh: Data algprithm and results,” Inde- pendent Component Analysis and Signal Separation, pp.552–559, Springer, Bearlin, 2007.
[19] Stereo Audio Source Separation Evaluation Cam- paign, http://www.irisa.fr/metiss/SASSEC07/?show
=criteria,閲覧日:2018/08/10.
付 録
距離の公理
本論文におけるクラスタ分析の際に用いた距離は距 離の公理を満たす.距離の公理とは
R
を空でない集合 として,任意の点x, y, z ∈ R
に対し,次の性質を満た すものである.•
正値性d ( x, y ) = |x − y| ≥ 0 , d ( x, y ) = |x − y| = 0 ↔ x = y
絶対値の性質より,|x| ≥ 0
,|x| = 0 ↔ x = 0
•
対称性d ( x, y ) = |x − y| = | − ( x − y )| = |y − x| = d ( y, x )
•
三角不等式図A·1 距離の公理 Fig. A·1 metric definition.
d ( x, y ) = |x − y||x − z + z − y|
= | ( x − z ) + ( z − y ) |
≤ |x − z| + |z − y| = d ( x, z ) + d ( z, y )
絶対値の性質より,|x + y| ≤ |x| + |y|
図
A · 1
のようにx = H
1,y = H
2,z = o
とした上 で用いた.(平成30年5月31日受付,9月27日再受付,
12月4日早期公開)
浦本 昂伸
2017年大分大学工学部知能情報システ ム工学科卒業.現在は同大大学院工学研 究科博士前期課程に在籍.音源分離を研究 テーマとしている.
上ノ原進吾
2011年東京都市大学環境情報学部情報 メディア学科卒業.2012年より大分大学 工学部技術職員.以来,音声・音響信号処 理の教育研究の支援に従事.日本音響学会 会員.
古家 賢一 (正員:シニア会員)
1985年九州芸工大・音響設計卒.1987 年同大大学院情報伝達専攻修士課程了.同 年NTT入社.以来,音声・音響信号処理 の研究に従事.2012年より大分大学工学 部教授.博士(芸術工学).1991年佐藤論 文賞受賞.IEEEシニア会員,AES,米国 音響学会,日本音響学会学会各会員.