JAIST Repository: A Study on Restoration of Bone-Conducted Speech with MTF-Based and LP-Based Models
13
0
0
全文
(2) Journal of Signal Processing, Vol. 10, No. 6, pp. 407-4 17, November 2006. PAPER. A Study on Restoration of Bone- Conducted Speech with M TF-Based and LP-B ased Models T ha ng Tat Vu, Kenj i Kim ura, Masashi Unoki and Mas at o Akagi. School of Inform ation Science, J ap an Advan ced Institute of Science and Technology. 1-1 Asahidai, Nomi, Ishikawa 923-1292, Japan. E-mail: {vu- t han g.kkimura. unoki.akagi}@.jaist .ac.jp. Journal of Signal Processing f .f5- i& JI J::J.
(3) Journal of Signal Processing, Vol. 10, No.6, pp. 407-417, November 2006. PAPER. A Study on Restoration of Bone-Conducted Speech with MTF-Based and LP-Based Models Thang Tat Vu, Kenji Kimura, Masashi Unoki and Masato Akagi. School of Information Science, Japan Advanced Institute of Science and Technology. 1-1 Asahidai, Nomi, Ishikawa 923-1292, Japan. E-mail: {vu-thang.kkimura.unoki.akagi}@.jaist.ac.jp. Abstract Bone-conducted speech in an extremely noisy environment seems to be more advantageous than normal noisy speech (i.e., noisy air-conducted speech) because of its stability against surrounding noise. The sound quality of bone-conducted speech, however, is very low and restoring bone-conducted speech is a challenging new topic in the speech signal-processing field. We describe two types of models for restoration: one based on the modulation transfer function (MTF) and the other based on linear prediction (LP). The MTF-based model is expected to yield a restored signal with higher intelligibility while the LP based model is expected to yield one that is not only more intelligible to human hearing systems but also enables automatic speech recognition (ASR) systems to achieve better performance. To evaluate the ability of these models to improve voice-quality, we compared them with the other previous two models using one subjective and three objective measurements. The mean opinion score (MOS) and log-spectrum distortion (LSD) were used to evaluate the improvements in intelligibility, which is useful for human hearing systems. The distances based on LP coefficients and mel-frequency cepstral coefficients (MFCCs) were used to evaluate the improvements in cepstral distances which are useful for ASR systems. The results proved that both the MTF-based and LP-based models are better than the other previous models for improving intelligibility. They particularly proved that the LP-based model produces the best results for both human hearing and ASR systems. Keywords: bone-conducted (BC) speech, air-conducted (AC) speech, modulation transfer function (MTF), linear pre diction (LP), speech intelligibility. 1.. Introduction. The sound quality and intelligibility of speech are influenced by their transmission environments. It is very difficult for automatic speech recognition (ASR) systems as well as humans to accomplish speech communications in an extremely noisy environment. There are many different complex models and/or al gorithms that are used as a solution to canceling or reducing interfering noises. These are only efficient at low and medium noise levels and are ineffective when the noise levels are too high. Another possible solution is to use a special micro phone to record the speech signal transmitted through the speaker's head and face. This recorded signal is referred to as "bone-conducted speech". Its stabil ity against interfering noise from a noisy environment seems to make bone-conducted (BC) speech more ad-. Journal of Signal Processing, Vol. 10, No.6, November 2006. vantageous than noisy air-conducted (AC) speech. Al though BC speech is not affected by external noise as AC speech is, there is a drawback to using BC speech; the signal is attenuated in a complex manner when it is transmitted through bone-conduction. This causes the voice-quality of BC speech, which means both its intelligibility by human hearing systems and features that are robust in ASR systems, to be very poor. If the voice-quality of BC speech can be improved, the restored signal can be applied to speech applications in noisy environments with greater efficiency instead of using noisy AC speech. Such applications include hu man hearing aids and machine hearing systems. Since it is very difficult to blindly restore BC speech, this is a challenging new topic in the speech signal processing field. The attenuation of the BC speech signal varies for different positions of measurement (BC microphone 407.
(4) positions ), pronounced syllables, and sp eakers. This is becaus e th e characterist ics of bon e-conduction cha nge for different measuring positions , and the distribution of frequency components vari es with speakers who pronounce syllables differentl y. This attenuation is generally strong at high frequ encies and it seems to b e low-pass filterin g with a cut -off frequency of about 1 kHz [1]. A st ra ight forward method of restorin g BC speech is to emphas ize t hese attenuated frequency components by using high-p ass filtering (inverse of the low-pass filterin g pr eviously describ ed). However , it is difficult to adequately design one unique kind of high-pass filterin g that is ind epend ent of pronoun ced syllables, speakers, and measuring positions. There are various methods of deriving inverse filt erin g such as t he cross-spect ru m met hod [2] and th e long-t erm Fouri er transform [3, 4], but t hese yield rest ored sig nals with art ifacts such as musical noise and echoes so t here are only slight improvements in voice-qu ali ty. We investigated t he relationships bet ween Be and clea n AC speech using an ACjB C sp eech dat ab ase as an essent ial st ep towar d const ructing compl et e mod els to restore BC sp eech and find significan t cha rac t eristi cs (for inverse filterin g) that would be useful in restoring BC speech. We propose two mod els of restoration from t hese results. Th e first is bas ed on t he modul ation transfer function (MT F) [5] and t he second is based on linear prediction (LP) [6] . All cur rent mod els (including t he ones we propose) obtain t heir par am et ers by using various inform ation on AC sp eech; we regarded t he consideration of blindly de termined model parameters to be the next st ep we will undertake in future work. The MTF-based mod el originat es from t he idea that t he te mporal envelope contains most of t he im p ortant information related to speech int elligibili ty, and t his int elligibility can be improved by using power envelope inverse filt erin g such as t ha t with the speech dereverberation method [7, 8]. The LP-based model origina tes from t he idea t hat th e information corre sponding to the sour ce (glottal) characteristics as t he LP residu e is the same for both AC and BC speech signals. Therefore, adapt ive inverse filtering will be prim arily derived from t he LP coefficients of AC and BC speech relat ed to filter inform ati on (voca l tract) . Both mod els manipulate source and filter inform a t ion; t he tempora l envelopes and car riers are used in the MTF-based model an d t he LP residu e and LP coefficient s are used in t he LP -based model. The dif ference is in the processing dom ain , the MTF-based mo del restores BC speech in the time dom ain with each sub-band (channel) an d th e LP-based mod el re st ores BC sp eech in t he frequency domain with each fram e. We investigat ed both models, which are ex pect ed to yield rest ored signals t hat a re not only more intelligible to hum an hearin g systems but which also enable ASR systems to achieve bet ter recognit ion . 408. Tabl e 1 List of equipment Measurement sit e Measurement p ositi ons Number of speakers Recorder Sampling frequency Sample size Mic. A for AC speec h Mic. amp. A for AC speec h Mic. B for BC speech Mic. C for BC speec h Mic. a mp. B for BC speec h. Soundproof room 5 posit ions 10 people SONY, TCD-D I D Proll 48 kHz 16 bits SON Y, C536 P SON Y, AC148F Temco, HG-1 7 Handmad e Handmad e. Soundproof room 5. . Mlc.S. ,R. 4.. I. ~ ~ .... "__ ..... II y(t) I. Mic A. -------------",/ .. ..... /. Fig. 1 Environment for recording ACjB C speec h. The rest of t his pap er is organized as follows. The next secti on describes the AC jBC speech datab ase that was used in our st udy. Section 3 explains our as sumptions and a pproaches to BC speech rest oration. We then pr esent our MTF-bas ed and LP-based mod els in sections 4 and 5. These mod els ar e evaluat ed and discussed in sect ion 6. Secti on 7 concludes wit h a summary and mentions future work. 2.. AC /BC Speech Database. A datab ase is indi spensable for an alyzin g th e re lationships and differences between BC speech and clean AC speech signa ls before any mod els are used t o rest ore BC speech. We constructed a large-scale da tabase containing pairs of BC and clean AC speec h signals recorded simul tan eously usin g a DAT syste m (two channels) . Fi gur e 1 an d Tabl e 1 show the enviro nment and equipment we used to const ruc t this dat ab ase. The BC spe ech was collected at five different positi ons on the head and face, i.e., the (1) mandibul ar an gle, (2) te mple, (3) philtrum , (4) forehead , a nd (5) calvaria . Thus, one positi on was associated wit h one pair of clean AC speech and BC speec h. Microphone B was only used at position 5 and microph one C was used at t he ot her positions. Ten spea kers (eight males and two females) participat ed in t he recording Journal of Signal Processing, Vol. 10, No.6, November 2006.
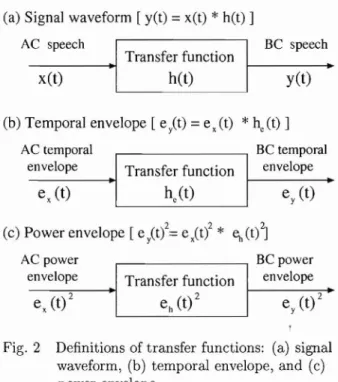
(5) of t he pronoun ced speech of 100 J ap an ese words and 45 J ap an ese syllables. T he select ed words were chose n from the NTT dat ab ase by their degree of famili arity [9]. The dat ab ase had two parts . The first was (i) a J ap an ese word dat aset of 100 J apanese words select ed from J ap an ese word lists compiled by NTT-AT (2003) . With 10 speakers , 100 words , and 5 measurement po sit ions, there were 5000 pairs of wave files. T he second was (ii) a J apanese syllable dataset of 45 J ap anese syl lables. Wi th 10 speakers , 45 syllables, and 5 measure ment positions, t here were 2250 pairs of wave files.. (a) Signal waveform [ yet) =x(t) * h(t) ] AC speech. BC speech. - - - - + 1 -1 Transfer. function h(t). x(t). (b) Temporal envelope [e it) = e x(t). 3.1. Restoration Approaches. Assumptions. * he(t)]. AC temporal envelope -------+1_1 Transfer function. ex(t). 3.2. Approach es to rest orin g BC speech. T here are three ty pes of transfer fun ctions t hat can be used as different ap proaches to restorin g BC speech in Fi g. 2. In general, these should be investigat ed as t ransmission characteristics from AC speech to BC speech before designin g t he inverse filterin g to restore observed BC speech . As we can see from Fig. 2(a), one st raightforward approach is to design t he invers e transfer fun ction from yet) to x(t) . Ther e are also the cross-spectral and long-term FFT methods [2]-[4] . These are used to const ruct t he inverse transfer func ti on from the BC spectru m to the AC spectru m using cross-s pectrum or FFT methods. The LP- base d mod el t hat we propose can be regard ed as this kind of approach to rest ora t ion because it is used to design the inverse transfer fun ction t hat can easily restore BC speech. However , here, its inverse filte ring was designed by using t he. Journal of Signal Processing, Vol. 10, No.6, November 2006. envelope. e (t). he(t). y. 2. (c) Power envelope [ e y(t) =eit). *. 2,. ~( t) J. BC power envelope. AC power envelope. e y (t) 2. ex (t) 2 In the work report ed here, clean AC speech was used instead of noisy AC speech and t his will be re ferred to as "AC speech" afte r t his. AC speech was record ed/ observed simultaneously with BC speech, as in the AC/B C speech dat abase. We assume d t hat there were exist ing relationships bet ween AC and BC speech that would be significant to rest ore BC speech. T herefore, our st rategy was to cons truct restoration mod els through the following ste ps : (1) to investigate the relat ionship bet ween clean AC and Be speech sig nals, (2) to find significant cha rac te ristics an d rest ora t ion mod els to restore BC speech (toward clean AC speech) , and (3) to consider how to blindly determ ine mod el param et ers only from observed BC speech and app ly t hese to realisti c communication. T his pap er fo cused on the first two essent ial st eps . We considered different app roaches to designin g inverse filteri ng for t he restoration models, which will be discussed in t he next section.. BC temporal. --. 2. 3.. yet). Fig. 2 Definitions of transfer fun ctions: (a) signal waveform , (b) tempo ral envelope, and (c) power envelope. LP coefficients related to the spectral characterist ics of signals. The signa l in each sub-ban d (cha nnel) can be re stored ind epend entl y where the te mporal envelope and carr ier are t he two components to be restored , when representing a signal in t he filterbank. More over, t he te mporal envelop e contains most of t he im portant inform at ion relat ed to speec h intelligibility rather than the carrier difference [10, 11]. Thus, th e primary goal is to rest ore t he tem poral envelope in each channel, as can be seen in Fig. 2(b) . The cross spectrum and long-term FFT methods , for exa mple, can be applied to temporal-envelope inverse filt erin g (inverted he(t)) for BC speech. When focusing on the repr esent ation of t he power envelopes of signals (F ig. 2(c)) rather t han t hose of the te mporal envelopes (F ig. 2(b)) , we can clearly express t he charact erist ics of the power envelopes as follows [7, 8]:. ey(t?. = eh(t? * ex( t)2. (1). where "*" denotes convolution , and ex(t)2, ey(t)2, and eh(t)2 corr esp ond to the power envelopes of signal s x (t ), yet) , and h(t ). In this relat ion , the carriers were assumed t o be mutually independ ent respective whit e noise random variable functi ons (see [7] for details). T hus, restorin g t he power envelope in each channel is t he primary goal. As mentioned a bove, t he t emp oral envelope contains most of the impor tan t inform ation rela ted to speech int elligibility. T he modulation t ran s fer function of %(t) 2 is strongly related to speech in te lligibility and t his can be applied to deriving p ower envelope inverse filt erin g, so t hat speech int elligibility 409.
(6) can be improved by using this kind of inverse filtering used in MTF-based speech dereverberation [7, 8]. Although the MTF-based and LP-based models seem to be different approaches, both, in fact, involve the same concept to restore the observed BC signal, i.e., the same representation of source and filter in- __ formation. The MTF-based model tries to restore the temporal power envelope in each channel, while the LP-based one tries to restore the spectral enve lope. Thus, their only difference lies in the processing domain, one processing in the time domain, and the other processing in the frequency domain. In the next two sections, we present the two models based on the MTF and the LP concepts in detail. 4.. filtering as post-processing to remove the higher fre quencies components in the envelopes.. cYn (t). Yn(t) eY n (t). (5). Analysis. Model concept. Definitions. x(t) y(t). = =. We analyzed the relationships between all pairs of speech signals (BC and AC speech) to design the MTF-based inverse transfer function, using the follow ing: (1) Correlation. Corr(ex(t)2, e y(t)2). faT ~ex(t)~ey(t)dt. (6). {faT ~ex(t)2dt} {faT ~ey(t)2dt} ~ex(t). = ex(t)2 - e x(t)2. ~ey(t). = ey(t) 2 - ey(t)2. (2) SNR (dB) 2. x. SNR(e (t )2, ey(t) ). = 20. itT ex(t)2dt. I. _~o:!....--. oglO. _. JoT (ex(t)2 - ey(t)2)1~). (3) Complex modulation transfer function MTF. Let x(t) and y(t) be AC speech and associated BC speech. With the N-channel band-pass filterbank, we assumed that the signals could be represented as N. N. n=l. n=l. N. N. n=l. n=l. L xn(t) = L e. oo. M(w) = I fo. fa eh(t)2dt. X n. (t) . cxJt). (8). (2) h(t). L Yn(t) = L e. eh(~2 exp( -jwt)dt I. (4) Transfer functions via long-term FFT. Yn. (t) . <; (t). (3). Here, xn(t) and Yn(t) are the sub-band signal compo nents, e X n (t) and eY n (t) are the temporal envelopes, and cX n (t) and cY n (t) are the carriers in the n-th chan nel of the filterbank. We used the Hilbert transform to decompose the signal in each channel into an envelope and a carrier. This method was based on the calculation of the in stantaneous amplitude of the signal, using low-pass 410. (4). MTF-Based Model. The MTF concept was proposed by Houtgast et al. to measure the room acoustics to assess what effect the enclosure had on speech intelligibility [10, 12, 13]. The model originated from the idea that the temporal envelope contained most of the important information related to speech intelligibility, and this intelligibility could be improved if the power envelope of BC speech were restored, as processing did with the method of speech dereverberation [7, 8]. Thus, the primary goal of the MTF-based model was to restore the power en velopes of BC speech by using power envelope inverse filtering related to the MTF concept, in the filterbank [5]. According to this concept, the input signal is di vided into sub-band signals, and the sub-band signal in each channel is then manipulated independently. Here, the power envelope and carrier are represented as the two components to be restored in each channel. 4.2. LPF [IYn(t) + j . Hilbert(Yn(t))I]. In these equations, Hilbertr-) is the Hilbert transform. LPF[·] denotes low-pass filtering with a 20 Hz cut off frequency to remove the high-pass envelope [7, 8]. This cut-off value (20 Hz) was chosen because the im portant modulation region, for speech perception [14] and speech recognition [15, 16], ranges from 1 to 16 Hz. eX n (t) and CX n (t) can also be calculated from x(t) using the same method (Eqs. (4) and (5)). 4.3. 4.1. eYn (t). eh(t)2. F-. 1[H(w)]. 1. F- [Eh(w)]. = F -1 [F[y(t)]] F[x(t)] y(t)2]] = F -1 [F[e F[e (tF] x. (9) (10). where F[·] is the long-term Fourier transform and F- 1 [.] is the inverse of the long-term Fourier trans form. The signal was resampled at a sampling frequency of 16 kHz with 16 bits per sample. Then, to analyze the signal within 8 kHz, we used a constant-band N channel filter bank, with 200 channels and a constant bandwidth of 40 Hz. Figure 3 shows the analyzed Journal of Signal Processing, Vol. 10, No.6, November 2006.
(7) ~. OJ. (a). (b). -0. ~o~. -=. ~5:~. Cl. -0. -50. - -. T,-. -. - - - <,. 1. Q). -1- -. _. OJ. ~ -100 ~ 0. 50. «. 100 150 Channel number. 200. I. ~. -50. 0. 2000. 4000 6000 Frequency [Hz]. (c). . 200. ......... - -. ~. 1 00. Q). .~. o. (d). 200. ";.-.... '31. ";.-.... ~ 100 Q). ~. . .~ 0.2. 0.4 Time [s]. .~~~ 0.2 0.4 0.6 Time[s] (f). o. 0.6. (e). jo:~ f:~:: o. 8000. 50. 100 150 Channel number. o. 200. 50. (g). $02~. .2 0.1 Cl.. ~-o~~==. o 50. 100 150 Channel number. 200. 100 150 Channel number. (h). :. 200. ~1. ~o~. f-. -I. -1. 0. 50. 100 150 Channel number. 200. Fig.3 Analysis results: (a) averaged e x(t)2 (solid line) and e y(t)2 (dashed line) in channels, (b) IH (w)1via long-term FFT, (c) e x(t)2, (d) e y(t)2 , (e) power envelope correlation Corr(ex(t)2,e y(t)2) , (f) SNR (ex (t)2, ey (t)2), (g) slope of the MTF M(w), and (h) slop e of IEh(w) I via long-term FFT in each channel. results for a pair of AC/BC mal e spe ech /asahan/ , recorded at position 5 via Microphone B. Figure 3(a) shows the averaged powers of AC (solid line) and BC speech (dashed line). The averaged pow ers of AC speech were reduced to less than 40 dB in th e first 130 chan nels, while this was only in the first 40 channels with BC speech . Figure 3(b) showes the transfer function , H(w), as a low-pass filter. There fore , generally speaking, these figures indi cated low pass characteristics as their transfer functions. Fig ures 3(g) and 3(h) show the magnitude curv es of MTF M(w) and IEh(w)1in 200 channels that we analyzed. The signs of their valu es correspond to the charac teristics of the transfer function in each channel. A positive value implies a high-pass filter and a negative value implies a low-pass filter. From Figs . 3(g) and 3(h), we know that the significant characteristics to restore BC speech in the power envelope can be in terpreted as low-pass or hig-hpass filtering . In Fig s.. Journal of Signal Processing, Vol. 10, No.6, November 2006. 3(e) and 3(f), the corr elation between the power en velopes of AC and BC speech, Corr(e x(t)2 ,e y(t)2) , is high within ab out 100 cha nnels while the gain reduc tion, SNR(e x(t)2, e y(t)2) , is small in most channels, and variants of th ese 100 channels. Therefore, the shapes of the power envelopes seem to be alm ost the sam e (Fig. 3(e)) and the difference is only in mag nitude (Fig . 3(f)) . Therefore, the relative reduction in the BC power envelopes with AC sp eech can be approximately interpret ed as a reduction in constant gain within 100 channels (respective to 4 kHz) . These results were used to design the MTF-based inverse transfer function to construct the restoration mod el as descuss ed in the following. 4.4. Restoration method. From the above results, we predicted that the MTF-based transfer function with constant gain would be useful for restoring BC speech. We there 411.
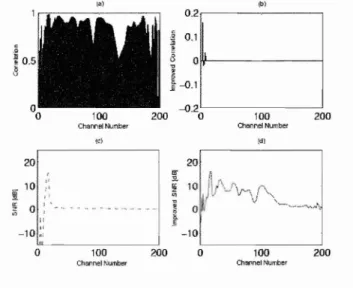
(8) ,a). [b). 0.2. Be speech y(t). N-ch annel co nstant bandwidt h filterban k (analysis). N-chann el Restored constant speec h bandwidth filterbank ~ (t) (synth esis). .•. a. 0.1. I1. h .5. <3. ,~. 0 111. -0.1. -0.2 0. 200. 100. 100 «I). (I:). 20. Fig. 4. Restorati on of BC speech by MTF model. 0;. " rr. ~. 20. i' 1)1~ If'\·J'v'~V\.. \ or. 10 ". 0. 0 :. [. ". I. (13.8) z" I} T is. 1{. E- (z) = - 2 h a. 1 - exp. - -. -. R .. (11). where is is th e sampling frequency (16 kHz) , a is th e gain fact or , and T R is th e delay parameter. Param ete rs a and T R can be estimated using the following algorit hm: TR =. max ( 0 :::;. a= ~ I. arg min. {iT iT (-~~ 8t). T R :::; T R ,max. f iT::~ :~~. dt /. 0. min (ex,TR (t)2, O)dt. exp. }). (12). dt. (13). where TR ,max is th e upp er limited region of T R , R (t )2 is t he set of candidates for th e power en velope restored as the function of TR , and T is the signal durati on of y(t ). These algorithms for param ete rs TR and a originated in Unoki et at. [7, 8] and were modified for AC jBC sp eech. The algorithm for a. ex ,T. was change d with a gain factor of ) 412. t JoT ::i ~l~ dt that. o. __ " "_''''_A. 0. E. - 10 ~ :. fore propose a meth od of restoration based on MT F with t he power envelope gain compensation out lined in Fig. 4 [5]. T he BC speech signal is decomp osed into te mpora l envelopes and carr iers in N- channels as Eq. (3), using Eqs. (4) and (5). Here, the power enve lope could be obtained as the square of t he t emporal envelope. After pro cessing in the BC power envelopes and th e BC carriers, the restored sub-band signals in th e channels are reconstructed into a restored speech signal, x( t), using synthesis pro cessing . Because th e carr iers are not important for speech intelligibility [11] during the carrier process, we used th e BC carriers as the AC carriers as in the MT F based mod el in Unoki et at. [5], i.e. , cX n = CYn' A gain value is norm ally used as compensation for t he BC power envelope during t he power envelope pro cess; this value is obtained from the average differences between BC and AC power envelopes in each channel. However, when th e correlat ion is lower t han 0.8 and t he BC power envelope is low (~ - 20 dB ), inverse filtering, Ei:1(z ), as in some methods of MT F-based dereverberation [7, 8] is used to restore t he BC power envelope as follows:. 200. ChannelNumber. Channel Number. -10 100. 200. o. 100. 200. Channel Number. Channel NUlrtler. Fig . 5 Signal improvement in N -channel filt erb ank (N = 200, 40 Hz const ant bandwidth ): (a) correlat ion Corr(ex (t )2, ey (t )2), (b) SNR(ex (t)Z, e y(t)2) (dB) , (c) improved correlation , and (d) improved SNR (dB). reflect ed th e relation between AC and BC power en velop es. Here, the BC power envelop e was rest ored us ing its gain control when parameter TR was 0 ( ~ -40 dB ), Figur e 5 compares a restored signal and the BC speech signal. There are improvements in t he corre lation and SNR of the power envelope in each chan nel (N = 200). The left panel (a) in Fig. 5 shows t he corr elation between AC jB C power envelopes and (c) shows t heir SNR. Using th e MTF-based model with power envelope gain compensation, t he correla t ion was improved in lower frequency regions as shown in Fig. 5(b) , and the SNR was also imp roved as seen in Fig. 5(d). These results prove t he advantages of t he MTF-based model. 5.. LP -Based Model. 5.1 Model concept Linear pr ediction (LP) is one of th e most power ful t echniqu es for analyzing speech . It pr ovides ex tremely accurate estimates of speech param et ers such as fund am ental frequency, formants, spectra, and vo cal tract area functions, and it is relatively efficient in comput ation [6]. The LP-based model can be in terpreted as a sour ce-filter model; t he LP residue is relat ed to th e source , which corresponds to th e char acterist ics of t he glottis and th e LP coeffi cients are relat ed to t he filt er , which corr espond s to t he cha ra c te rist ics of t he vocal tract. Th e LP -based mod el orig inat es from t he idea that th e inform ation correspond ing to t he source (glot t al) characterist ics can be t he Journal of Signal Processing, Vol. 10, No.6, November 2006.
(9) G(z). -1 .IF(z) = p -- a(i) Z-i. r... Speaker: Kimura. I. •. Syllable: hi. Position: 5. ., ~. i. S(z ). 0 ~O. 1. J"~. i=O. ~. (b). 0. Fig. 6. LP as source-filt er mod el. ec h. - 0. 1. same for both BC and AC speech. Therefore, inverse filt ering is primarily derived from the LP coefficients. Moreover, since the LP coefficients correspond to the voca l tract , inverse filt ering based on LP coefficients could be adapted for the different characterist ics of speakers and t hose of t he syllables t hey pron ounce. 5.2. . l:~. ; ~~. soo. iooo. iseo. -. , :- -. aooo. ssoo. aooo. :~ _~ :~~~ ~! I ~~ I.~R_;:_.\~. - 40. <!). o. 2000. 4000. 6000. 8000. 10000. 12000. 14000. 16000. IrBq ue n c:y. Fig. 7 Ratio of AC/ BC residu es: (a) AC speech , (b) BC speech, (c) residu e correlat ion Corr(g,,(n ), gy(n )), and (d)residue ratio. Definiti on. When the LP order is sufficient ly high , the all-po le mod el provides a goo d representation for al most all speech sounds, s(n), as in Rabiner [6]. Gy(z) IG ,,(z ). p. s (n ) =. 2:= s(i)a(n -. i). + g(n). (14). ;= 1. where P is t he LP orde r, a(i) is the i-th LP coefficient, an d g(n) is t he LP residue of speech signa l s(n). We can rewr ite Eq. (14) in t he z-domai n as p. - G(z ) = S(z). 2:= a(i )z- ;. (15). Assuming th at the mathematic al description of. h(t ) is an M-order FIR filt er, the transfer fun cti on from x(t) t o y(t) in t he z-domain , H (w), is repr esented as. M. H (z ) =. p. where a(O) = -1 , G( z) and S( z) are t he z tran sform s of g(n ) an d s(n) . As we can see in Fig. 6, LP repre sentation can be inter pret ed as a source- filt er model. The LP residu e, G( z) , is related to t he source, which correspo nds to t he characteristics of t he glottis. T he LP coefficients are relat ed t o the filter , F (z ), which corresponds t o t he characteristics of the voca l t ra ct . Let x(t) and y(t) be t he AC and it s associated BC speech. The signals x(n) an d y(n) are discret e signals of x( t ) and y(t) with a sam pling frequency of 16 kHz. Thus, the two signals, x(n) and y(n ), are represent ed by t he LP model in the z-domain as: p. X( z) 2:= a,,(i) z - ;. (16). ;=0. Q. - Gy(z ) =. Y (z ). 2:= ay(i) z -;. (18). From Eqs. (16)-(18), we have. ;=0. - G,,(z ) =. ~ ~:~ = ~ h(i )z - ;. (17). ;=0. where a,,(O) = -1 , ay(O) = -1 , X (z) an d Y( z) ar e z transforms of x(n) and y(n) , P and Q are LP ord ers , a,,(i) and ay(i) are i-th LP coefficients , and G,,(z) and Gy(z ) ar e z t ransforms of LP residu es g,,(n ) and gy(n) , respecti vely. Journal of Signal Processing, Vol. 10, No.6, November 2006. ~. . . 2:= ax (i) z - ; L h(z) z - ' = ;=0 ; =0. 2:= ay(i) z-; Q. Gy( z) . G,,(z). (19). ;= 0. 5.3. An alysis. Since t he LP resid ues g,,(t) and gy(t ) are related to t he source information (or glottal information) of x( t) and y(t) , t his kin d of infor mati on may rem ain un changed in both the AC and BC speech signals. To verify this suppos iti on , we ana lyzed every pair of AC and BC speech signals in a J ap an ese syllable dataset. The te chnique for LP a nalysis as aut ocorrelation us ing the Levin son-Durbin recursion algorithm. There is a typical example of the results of analysis in F ig. 7. The AC and BC vowel Iii signa ls ar e in Fig s. 7(a) and 7(b) , resp ecti vely. Figur e 7(c) indicates that the cor relation bet ween g" (n) an d gy(n) is very high . E ach correlation value here is associate d wit h a pair of 4 millisecond AC / BC speech fram es. Figure 7(d) shows t hat t he rat io of t he LP residues in the frequ ency do main , G,,(z )/ Gy(z ), is almost constant. Although t his ratio is not stable at any frequ ency, we can approxi-. 413.
(10) Y(z). mately represent it as. H(z) =. Gy(z) Gx(z). =k. (20). where k is a constant factor.. G,(z) = k (const .) G,(z) X(z). G,(z) I'. Y(z) = G,(z) .j. r,a.(i). z. 5.4. X(z). Restoration method. ·1. From Eqs. (19) and (20) , we can rewrite this ratio. Fig . 8. fa,(i) .. H (z). i=O. zi. ,=0. Transfer function of LP-based model. as. (~h(i)Z-i) .. (t,. ay(i)z-i) = k. t,. ax(i)z-i. (21) Deriving the zero-th variable of both sides in Eq. (21), we obtain Gy(z) (22) h(O) = k = Gx(z) Figure 8 outlines a typical conversion from AC speech to BC speech with transfer function H(z). The inverse filter, H - 1 (z), can be found as the inverse function of H( z) and used to straightforwardly restore BC speech to AC speech. All equations in the fig ure have been implied from Eqs . (16),(17), and (22) . From these, we can obtain the equation for H- 1 (z) simply as Q. 1 1 H- (z) = h(O)'. .. L ay(i)z-' La i=O p. (23). '-i. x(2)z. i=O. We should obtain the restored speech from ob served BC speech with the inverse transfer function, H- 1 (z), which depends on the LP coefficients and residue ratio of the AC and BC speech signals . Equa tion (23) gives us a different way to estimate this transfer function . Inverse transfer function H - 1 (z) is decomposed into two parts. In the first part, the con stant value, h(O) , can be chosen manually and used to control the magnitude of restored speech. The second part primarily depends on the LP coefficients of sig nals . Therefore, in the LP-based model, the relation ship between the LP coefficients of AC and BC speech signals is essential to restore BC speech. Here, we chose h(O) = 1 and set the LP orders at P = Q = 20. 6.. Evaluation. This section discusses the feasibility of the mod els to restore BC speech signals. The main aim of our evaluation was to determine which model would be the most useful with regard to sound quality to achieve two different purposes: speech intelligibility for human hearing systems and robustness for ASR 414. systems. Using a number of different measurements, we evaluated two previous models and our two pro posed models. The two previous were (1) the cross spectrum signal (CrossSig) and the (2) the long-term FFT (LTFSig) models. Ours were (3) the MTF-based (MTFGain) and (4) the LP-based (LPSig) models. Log-spectrum distortion (LSD) and the mean opin ion score (MOS) were used to evaluate the improve ments in intelligibility, and the LP coefficient distance (LCD) and mel-frequency cepstral coefficient distance (MCD) were used to evaluate the improvements in the cepstral distance of restored speech signals. The Japanese vowel dataset from the AC/BC database was used to evaluate improvements with the objective measurements (LSD, LCD, and MCD), and ten words that were chosen randomly from the Japanese word dataset were used to evaluate improvements with the subjective measurements (MOS). 6.1. Objective evaluations. We used LSD, LCD, and MCD for the Japanese syllable dataset to objectively evaluate the four meth ods . These three measurements were computed as fol lows: LSD. ~. LCD. P. t. [20 log". r. (:~i:~:). (24). 1 p. L (ax (i) -. ay(i))2. (25). i =l 12. MCD. L(. C X. I'/,. -. C Y ,l.. ). 2. (26). i=O. where W is the upper frequency (8 kHz in this case), and 5 (w) and S(w) are the am plitude spec tra obtained by 1024-point FFT calculation of 25 millisecond frames. The time these frames overlapped was 15 ms. Here, ax (i) and ay (i) are the i-th LP coefficients of signals with the LP order being set at P = 20, and Cx ,i and Cy,i are the i-th MFCC of the signals. After measuring the distances between the clean AC speech signal and the other signals, i.e., the obJournal of Signal Processing, Vol. 10, No.6, November 2006.
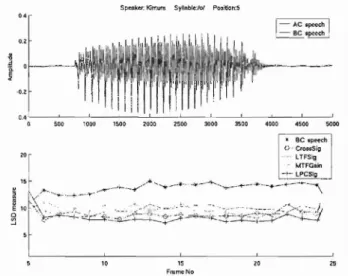
(11) Sylinble:/oI. Spe Okl!f: Kimum. Ta ble 2. Aver age LSD improvem ents in restored speech Measurem ent positi on Method - 3 2 1 4 5 1.14 CrossSig 5.00 2.14 3.53 5.54 LTFSi g 3 .18 4.64 4.58 3.95 6.27 MTFGa in 1.94 4.04 2.60 1.68 6.55 LPSig 3.02 5.80 4.29 5.00 7.71. Po , ition:5. I-. ~~~W! I""I~~~ 1.:r-1 Irml";ilmmrrm". ,::f. ltt!lIw.il-·- - - ·. ,. OA f. sec. a. ". 1000. ". l!>OO. ". "~ J _. 2000. 2500. 3000. 3500. 4000. Average LCD imp rovements in restored speec h Measurement position Method 2 1 3 4 5 1.09 0.56 0.89 CrossSig 0.60 0.57 LTFSig 0.62 1.24 1.15 1.07 0.78 MTFG ain 0.61 0.18 0.08 0.25 0.31 LPSi g 0.73 1.26 0.91 0.92 0 .82. Tabl e 4. Method Cross Sig LTFSig MTFGain LPSig. BC spee ch 2.44. Aver age MCD improvem ents in restored sp eech 1 6.13 4.91 5.72 9.69. Measur em ent posi tion 2 4 3 7.00 7.74 5.4 2 10.13 13.84 7.98 4.22 7.22 5.5 3 11.66 13.95 10.09. 5 1.71 7.56 4.91 8.33. Tabl e 5 Results of MOS t est Cros s LTF MTF LP AC -Sig -Sig -Gain -Sig speech 2.45 2.91 4.33 1.72 2.68. served BC speech and the rest ored speech signals, we evaluated the improvem ents in the restored sp eech in comparison with BC spe ech. Tabl es 2, 3, an d 4 list the average imp rovem ents in t he three ob jecti ve m ea sur ements. T he LP-based model is genera lly the best for all the measurem ents . Alth ough the MT F-based mo del doe s not have advantages in the obj ecti ve mea sure ments, it does yield bet t er results than the pre vious mod els with t he LSD measurement at measure ment in Positi on 5. Figure 9 shows typi cal LSD curve s in t his position . 6.2. Subjective evaluat ion. We carr ied out MOS (mean op inion score) tests usin g the four methods for the subjective evaluat ion. We conducte d t hese wit h five sub jec t s who had nor mal hearing. The MOS t est s were used t o measure t he sound qu ali ty of restored speech using t he four method s in five evaluations graded as perceived by the subjects. The levels rated were: bad (1), poor (2) , fair (3), goo d (4), and excellent (5). T he speech signals in these tes t s were t en words that had been Journal of Signal Processing , Vol. 10, No.6, November 2006. 4!i00 •. 5000. BC. p",". O ' CrOfl;8S.;,. zo ~. ...." LT FSig [. Table 3. I. AC speech. Be speech. 15. I,J("'. ~ -. y • •. ~-. -'* .......... _ . 4. ~. .".......... -. -. . ». '.- . .. · . .... - ..........~. •• •. ••. - .. ,. IvtTFGlI.in - t·· LPCSlg. ..~-\. -~ --- -. ~. -+-_ .... _ -. ..-~ + - .- . -. -. I. ! ' l ''i'~ ~ ''''''~'''-~'-'''''='~'~ :tJ 5. 10. 15. 20. ~. Fntm e No. Fi g. 9. LSD between AC and restored speech signals. randomly chosen from t he J ap an ese word dataset . Table 5 list s the mean scor es for the subjective rat ings. The LP-based model is t he best for restoring BC speech to AC speech. This is followed by the MTF based mod el. These subjective results also pr ove t hat the previous mod els were not as goo d. The improve ment s with the LTFSig mod el are almost zero, and even minus wit h t he Cr ossSig mod el. 6.3. Discussion. As previously mentioned , we used LSD and MOS to evaluat e improvemen t s in sp eech intelligibili ty, whi ch is useful in human hea rin g system s. LCD and MCD were used to evaluate t he cepstral dist an ces, which are significant for ASR sys te ms. Wi th LCD and MCD measur ements, the MTF-based mo del did not seem to have as good ASR robust -features. Al t hough the LSD measurem en ts demonstrat ed t hat t he . MTF-based model significan tl y improved intelligibil ity, the subjective MOS measurements also revealed its advantages in comparison with th e two previous mod els. The object ive measur em ents were better for evaluat ing t he mo dels for ASR sys tems , and the lis te ning tests were be tter for evaluating sp eech intelli gibilit y. Overall , t he MTF-based mod el was b est for improving intelligibility. All the obj ective measurem ents (LSD , LCD , and MCD ) and the subject ive measurements (MOS) re vea led that t he pr op osed mo de ls, i.e. , MTF-based a nd LP-based , were bet t er at improving voice-quality than t he other pr eviou s method s. In particular , t he LP based model was t he best for both human hearing and ASR systems . The proposed models still curre ntly need t o use some inform ation from AC speech to restore the ob served BC speech . The ga in values of t he power en 415.
(12) velope in t he MTF-based model, and t he LP coeffi cient s of AC speech in t he LP -based mod el, are essen t ial in const ructing inver se filtering. This also means t hat th ere ar e only a few par ameters (gain , LP coef ficients) that affect t he ability of the pr oposed mod els in restoration . These parameters should depen d on the characterist ics of pronoun ced sounds such as vowels and consonant s from each specific positi on of meas urement . By investi gatin g t he var iances in these par am et ers along wit h BC speech sounds, we sho uld be able to find pr acti cal algorit hms to determin e t hem a ut omatically wit hout AC speech. 7.. Conclusion. We construct ed a lar ge-scale AC/BC speech database (5 measur ement p ositions , 10 speakers, and 145 st imuli for both AC and BC speech) to investi gate t he significant characte ristics in the relati onship between AC and BC speech signa ls. By ana lyzing all AC/ BC dat asets in this dat ab ase, we foun d t hat t he gain of t he p ower envelope is approximately con st ant in abo ut 100 channels, corres ponding to 4 kHz. We also found a constant ratio of LP residues of AC and BC spe ech signal s with t he LP method . These cha rac te rist ics seem to be significant in rest orin g BC speech. We then pro posed two mod els accor ding to t hese characterist ics, i.e., MTF-based and LP-based models. Both models worked wit h t he same conce pt , but t here were differences in t heir processing domains. T he MTF-based mod el decomp osed a signal into su b band signals and t hen separately manipulated tempo ral envelopes and carriers in each channel, while the LP-based model manipul at ed th e LP residu e and LP coefficients in each frame. These differen ces can re sult in different rest orati on goals in improving speech int elligibility and feat ur es t hat are robust in ASR. We evaluated b oth t hese models and demonstrated t heir advantages by comparing t hem wit h two ot her methods (CrossSig and LTFSig). As a result , we found t hat both t he MTF-based and LP-based models were better t han t he ot her two methods for improving voice-quality. The MTF-based mod el, in parti cular, efficient ly restore speech int elligibility which is use ful for human hearing syst ems . The LP-based model efficiently improved voice-quality. We t herefore veri fied both t he pr op osed methods based on our concept could adequately rest ore BC speech to imp rove not only its intelligibility but also t he perform an ce of ASR syste ms . These result s were obtained as the first steps to ward investi gat ing t he possibility of rest oring BC speec h. We thus focused on analyzing the signifi can t relationship between AC and BC speech signals, and t he feasibility of models to restore BC speech signals . The pr op osed models still cur rent ly need to use AC speec h to determine t he coefficients of MT F416. based and LP -based inverse filterin g. The gain values of p ower envelope inverse filt erin g in t he MTF-based model were det erm ined by t he ratio of the AC/B C envelopes . The inverse transfer fun ction in t he LP bas ed mod el was det ermined usin g t he LP coefficients of AC/BC speech signals. As t he next st ep toward developin g blind restora t ion of BC speech in future work , we int end to investi gate the varian ces in t he mod el par am et ers in associ atio n wit h BC speech signals before findin g practical algorit hms to automatically calibrate t hese par am e ters only from t he characterist ics of BC speech sig nals. A different developm ent , i.e., a hybrid model based on the sam e concept (of b oth MTF-based and LP-based mod els) may be able to be pr op osed , which would rest ore te mporal-spectral inform at ion in both the t ime an d frequency domains. It would have su peri or p erformance for b oth human hear ing and ASR systems . A cknowledgments. This work was supported by a Grant-in-Aid for Science Research (No. 17650048) an d a scheme for the "21st Century COE Program" in Special Coor dination Funds for pr omoting Science an d Technology made availabl e by the Ministry of Education , Cult ure, Sports , Science, and Technology.. References [1] M. Kumashita, T . Shimamur a and J . Suzuki : Property of voice record ed by bone-cond uct ion microph on e, Proc. 1996 spri ng meeting on Acoust . Soc. Jpn , 2-Q- 3, pp . 269-270, March 1996 (in Japan ese) . [2] S. Ishimit su , H. Kitakaze, Y . T su chibush i, H. Yanagawa and M. Fu kus him a: A noise-r obu st spe ech recog nitio n sys te m maki ng use of body-conducted signals. Acou st . Sci. & Tec h. , Vol. 25, pp . 166-169,2004. [3] T. Tomikur a and T . Shimamura: A study on improving t he qu ality of voice of bone cond uctio n, Proc. 2003 spring meeting on Acoust . Soc . Jpn,2-Q-14, pp . 401-402, 2003 (in Japanese) . [4] T . Tami ya and T . Shimamura: Reconstruct filt er desig n for bone-condu ct ed spe ech , Proc . ICSLP 2004, II , pp . 1085-1088, 2004. [5] M . Unoki, K. Kimura and M. Akagi: A st udy on a bone co nd ucted speech resto rat ion wit h t he modulation trans fer funct ion , Trans. Tech. Comm . P sycho . Phyciol. Acoust. ASJ, Vol. 35, No.3, pp . 191-196, H-2005-33, Ap ril 2005 (in Japanese) . [6] L. R . Ra bi ner : Digital P roc essing of Speec h Signals, Prenti ce-H all Inc., Englewoo d Cliffs, New J ersey, 1978. [7J M . Unoki, M. Furukawa, K. Sakata and M . Akagi : An im proved met hod bas ed on t he MT F concept for restoring the power envelop e from a reverberant signal, Acoust . Sci. & Tech ., Vol. 25, No .4, pp . 232-242 , 2004 .. Journal of Signal Processing , Vol. 10, No.6, November 2006.
(13) [8] M. Unoki, K. Sakata, M. Furukawa a nd M . Aka gi: A speech derever bera tio n method based on t he MTF concept in power envelope restoratio n, Acoust . Sci. &Tech ., Vol. 25, No. 4, pp . 243-254, 2004. [9J Database for speech intelligibil ity testing using Japanese word lists, NTT-AT, March 2003. [10] T . Houtgast, H. J . M. Steenken and R . P lom p: P redict ing sp eech inte lligibility in rooms from t he mo d ulat ion transfer funct ion , Part I General Room Acousti cs, Acustica, Vol. 46, pp . 60-72, 1980. [11] R . Dru llm an: Tem poral envelope and fine st ructure cues for speech intelligibility , J . Acoust . Soc. Am, Vol. 97, pp. 585-592 , 1995. [12J T . Hout gast and H. J . M. Steenken: Th e mo d ulation trans fer function in room aco usti cs as a pr edict or of speech intel ligibility, Acusti ca , Vol. 28, pp . 66-73, 1973. [13] T . Houtgast and H. J . M. Steenken: A r eview of th e MTF con cept in room aco ustics and its use for est im at ing speech int elligibi lity in aud it oria, J . Aco ust. Soc. Am ., Vol. 77, pp. 1069-1077, 1985. [14J T . Arai , M. P avel , H. Hermans ky and C . Avendano: Syl la ble inte lligibility for temporally filte red LPC cep stral tra j ect or ies, J . Acoust. Soc . Am. , Vol. 105, pp . 2783-2791 ,1999. [15] N. Ka nedera, T . Ara i, H. Hermansky and M. Pavel : On the impo rtance of various mod ulation freq uencies for speech recogni t ion, Proc. EuroSpeech 97, pp. 1079-1082, 1997. [16] N. Ka nedera , T . Ara i and T . Fu nada: Robust automatic sp eech recognit ion emphasi zing im port ant modu lation spec trum, IE ICE Tr ans. D-II , J8 4-D-II , pp . 1261-1269, 2001.. Thang Tat Vu received his B.E . and M .E . in elect ronic & te lecom munication engi neering from t he Hanoi Univ ersity of Tec hnology (HUT) , in 2002 and 2004. He was a member of t he Speech Process ing Group at th e Insti tu te of In format ion Technology (IO IT) of t he Vietnamese Academy of Science an d Techn ology (VAST) from 2002 . He has been a Ph .D. cand idate at the Schoo l of In for mat ion Scien ce of the J apan Advanced Inst itu te of Science and Tech nology (J AIST ) sin ce 2005.. received his K enji Kimura B.E. in electri cal engineering from Dosh isha University in 2003, and his M .S. from the Japan Advanced In sti t ute of Science and Technology (JAIST) in 2005. He has been with th e Tokyo Electric Power Company sinc e 2005 .. Journal of Signal Processing, Vo l. 10, No.6, November 2006. Mas a shi Unoki rece ived his M.S. and P h. D. (Informat ion Sci ence) from the J a pan Advanced In st itute of Science and Tec hnology (JA IST) , in 1996 and 1999. His main resea rch interests are in aud i torymotivated sign al processing and the modeling of auditory systems. He was a JSPS research fellow from 1998 to 2001. He was associated with th e ATR Human Informat ion Processing La boratories as a visit ing researcher from 1999-2 000, and he was a visit ing research associate at the CNBH in t he Depart ment of Physio logy at the Uni ver sity of Cambridge from 2000 to 2001. He has been on the faculty of t he Schoo l of In form at ion Science at JA IST sinc e 2001 and is now an Asso ciate Professor. He is a member of t he Research Institute of Signa l P rocessing (R ISP ), the Insti tu te of Electronics, Informat ion a nd Commu nicati on Engineers (IE ICE) of J a pan and the Acousti cal Societ y of America (ASA ). He is also a memb er of t he Acoustical Society of Japan (AS J) , and t he Int ern at ion al Speech Communicat ion Association (ISCA) . Dr. Unoki rec eived the Sato Prize fro m th e ASJ in 1999 for an Out standing Paper and the Yamas hita Taro "Young Researcher" Prize from th e Yamashita Taro Research Foundation in 2005.. Masato Akagi received his B .E . from Nagoya Institute of Tech nology in 1979, and his M.E. and Ph. D. En g. from th e Tokyo Insti tute of Technology in 1981 and 1984. He joi ned the Elect r ical Commu ni cation La b orat ories, Nipp on Te le graph and Te lephone Corporation (N T T ), in 1984. From 1986 to 1990, he worked at t he ATR Aud itory and Visual perception Research La bora t ories. Since 1992 he has b een on t he facul ty of the Schoo l of Informat ion Science , J apan Ad van ced Inst itu te of Science and Tech nology (JAIST ) and is now a Professor. His research interests include speech per ception , th e modeling of speech perception me cha nisms of hum an bein gs, and signal pr ocessi ng of speech. Du ring 1998, he was associat ed with th e Research La b orat ories of Elec tronics, MIT as a visit ing resea rcher , and in 1993, he st udi ed at the Inst itu te of P hon eti cs Science, Univ. of Am st erdam. He is a me mb er of t he Inst it ute of Electronics, Inform at ion and Com munication E ngi neers (IE ICE) of J a pan , th e Acoustical Societ y of Japan (ASJ ) , th e Inst it ut e of Electrical and Elect ronic Engi neering (IEE E) , the Acoustical Societ y of America (ASA) , and the Int ern at ion al Speech Communicatio n Associat ion (ISCA). Dr. Akagi received the lE ICE Ex cellent Paper Award from the IEICE in 1987, and th e Sat o Prize for Outstand ing Papers from t he ASJ in 1998 and 2005. (Received May 30, 2006 ; revised August 14, 2006). 417.
(14)
図


+3
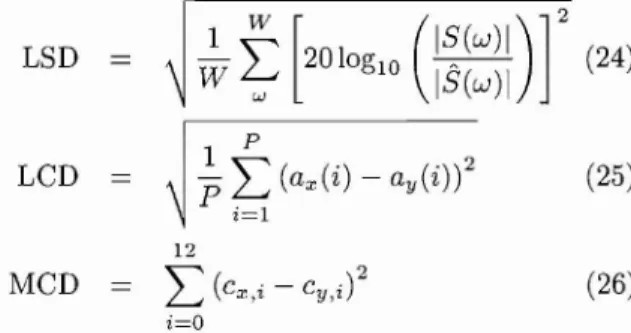
関連したドキュメント
This paper presents a data adaptive approach for the analysis of climate variability using bivariate empirical mode decomposition BEMD.. The time series of climate factors:
Time series plots of the linear combinations of the cointegrating vector via the Johansen Method and RBC procedure respectively for the spot and forward data..
In 2003, Agiza and Elsadany 7 studied the duopoly game model based on heterogeneous expectations, that is, one player applied naive expectation rule and the other used
One of the procedures employed here is based on a simple tool like the “truncated” Gaussian rule conveniently modified to remove numerical cancellation and overflow phenomena..
This paper deals with the a design of an LPV controller with one scheduling parameter based on a simple nonlinear MR damper model, b design of a free-model controller based on
The problem is modelled by the Stefan problem with a modified Gibbs-Thomson law, which includes the anisotropic mean curvature corresponding to a surface energy that depends on
To overcome the drawbacks associated with current MSVM in credit rating prediction, a novel model based on support vector domain combined with kernel-based fuzzy clustering is
By an inverse problem we mean the problem of parameter identification, that means we try to determine some of the unknown values of the model parameters according to measurements in
