Abstract— This paper has presented an acquiring
method for agents’ actions using Ant Colony Optimization (ACO) in multi-agent system. ACO is one of powerful meta-heuristics algorithms and researchers have reported the effectiveness of applications with the algorithm. We have developed the experimental system with soccer agents using ACO in RoboCup Soccer Simulation League and have reported the results of some experiments with our system.
I. INTRODUCTION
Recently, some researchers have reported the effectiveness of systems installed swarm intelligence algorithms[1], [2]. Especially, Ant Colony Optimization (ACO)[1] and Ant Colony System (ACS) [3] have become a very successful and widely used in some applications[4], [5]. Real ants are capable of finding the shortest path from a food source to their nest without using visual cues by exploiting pheromone information. The ants exploit pheromone to find shortest path between two points. The behavior of real ants has inspired ACO and ACS. The system based on ACO and ACS are used artificial ants cooperate to the solution of a problem by exchanging information via pheromone. In this paper, I study that Simple-ACO (S-ACO) algorithm is applied to agents of RoboCup Soccer in multi-agent system and I would like to confirm the improvement of capability for attacking action in RoboCup soccer agents.
RoboCup[7],[8] is an international joint project to promote AI, robotics, and related field. A goal of this research, RoboCup Soccer, is to develop a team of fully autonomous humanoid robots that can win against the human world champion team in soccer by 2050. Soccer is one of the most popular sports in the world. Human soccer players need to select for their actions and need to do the actions in real time on their soccer games. For examples, a dribble, sending a pass, a shoot, a tackle and so on. We think that an ability to select actions can be developed by some factors. One of the factors is a large amount of experience in soccer games and another is a good imagination for their actions to do the excellent actions and so on.
This paper organized as follows. Section II puts my basic idea for this study. Section III is described my approach for agent in RoboCup soccer simulation system. Section IV is
reported evaluation experiments for our approach. Section V is dedicated to the consideration for the experiment in this study. In Section VI, I would like to conclusion this study and indicate directions for our research.
II. BASICIDEA
The traveling salesman problem (TSP) has no noise for solving and all of distances between each cities are given in advance. Moreover their situations have never changed for each simulation steps. However situations or outer information in environment is always changing in the real world, dynamically. In some cases, we are disable to know cues to solve a problem in advance. In other case, some outer noise gets information erased or interpolation them.
On the other hand, in a soccer game, players need to handle huge amount of information and take actions dynamically. Therefore, a soccer game is a very good test bed for multi-agent research. Then, I would like to apply S-ACO to soccer agent in this study.
In our study[9], [10], [11], [12], a goal is to figure out a learning ability and to put the ability to practical uses. Our basic idea for learning agents’ action is that there are some learning methods and sources. In this paper, Fig. 1 illustrates the basic idea for agents’ actions. We have considered that the sources of agents’ actions can be classified into three groups. In the figure, (1) and (2) mean these groups of rules and the structure of them.
In human soccer games, we consider that action rules in Group (1) are comparable to instructions or strategies from other persons, for example coaches in their team. To realize these cases, we consider that engineers can give soccer agents a part of these rules explicitly. In this research, the rules in Group (1) are hand-coded rules. We have developed the rules from our considerations of results in log files of some RoboCup Soccer simulation games. For the human soccer, we consider that action rules in Group (2) are comparable to empirical rules in soccer players. Human soccer players that have a lot of experiences of soccer games can adapt to some situations in games and take adequate actions. In other cases, players can get improve their skill of soccer through trials and errors during their training. In our research, the action rules in Group (2) are rules that are acquired from examples of actions using unsupervised learning.
In the case that an agent uses the only rule among Group (1), it could do fixed actions and could not have an ability of
Hisayuki Sasaoka
Asahikawa National College of Technology Shunkoh-dai 2-2 Asahikawa, 0718142 JAPAN
Email: [email protected]
Approach for Agent Actions' Acquiring Method
using Ant Colony Optimization
SCIS & ISIS 2010, Dec. 8-12, 2010, Okayama Convention Center, Okayama, Japan
adapting to dynamic situations. On the other hand, in the case that an agent uses the only rule among Group (2), it could adapt to some cases and would require a lot of trials and errors and a lot of calculation. Therefore, our system has used these two types of rules and has aimed to adjust tradeoff between them using unsupervised learning. Then the agent based on our method has done online-learning and has adapted an opponent team.
III. OUR APPROACH
In this study, agents are able to decide a direction of kicking soccer ball with S-ACO[1]. Initially, agents decide a direction of kick on randomly. At each construction step, they take a probabilistic choice to decide kicking direction. The probabilistic is caliculated by (1).
In (1), τij means the value of the associated pheromone
trail on arc (i, j).A value i means a current position on the soccer field. A value j means a chooses to kick to position. ηij is a heuristic value that is available a priori, αand βare
two parameters which determine the relative influence of pheromone trail and the heuristic information. Theηij s are
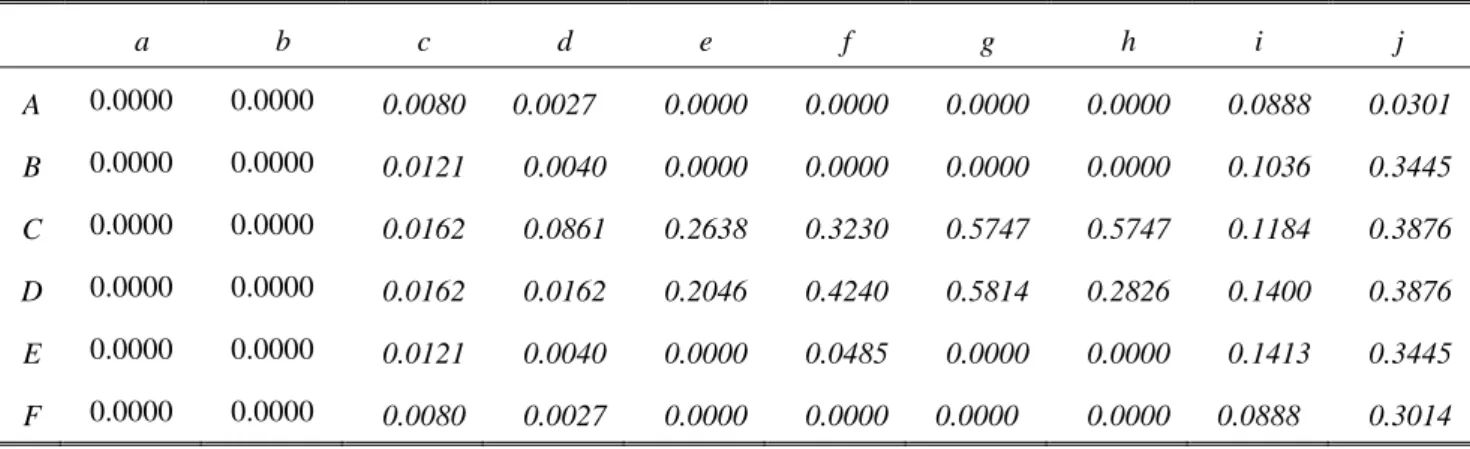
calculated in previous research[11]. They are shown Table 1.
The pheromone trails are updated and pheromone evaporation is able to be calculated by (2).
ρ means the pheromone evaporation rate, which is between 0 and 1. Δτis amount of deposited pheromone. Moreover value of Q is scored by our previous research [11] and are shown in Table 2.
IV. EVALUATION FOR OUR APPROACH IN OUR EXPERIMENTAL SYSTEM
We have developed experimental a soccer agent for evaluation, which is based on [13]. In this experiment, Team A is consisted of one experimental agent and other ten agents which are equal to agents [13]. Team B is consisted of only agents which are equal to agents[13].
Then we have done 30,000 steps simulation ( is equal to five games.) between Team A and Team B. The result of simulation is shown in Table 3. From the results, we can confirm that Team A is able to get score more than Team B.
V. CONSIDERATION FOR THE EXPERIMENTAL We have developed another soccer agent which donot update pheromone trail in each step. Then Team A' is consisted of this agent and other ten agents which are equal to agents[13]. We have also done 30,000 steps simulation ( is equal to five games.) between Team A' and Team B. The result of simulation is shown in Table 4. From these comparing between results, we have confirm the effectiveness of updates of pheromone trails.
VI. CONCLUSION AND FUTURE WORKS
This paper have presented our proposal and reported the effectiveness of updating pheromone trails in a agent with S-ACO. We have a plan to develop agents installed ACO algorithm in RoboCup Rescue Simulation League.
REFERENCES
[1] M. Dorigo end T.stuzle, “Ant Colony Optimization, ” The MIT Press, 2004.
[2] J. F. Kennedy, R. Eberhart and Y. Shi, “Swarm Intelligence, ” Morgan Kaufman Pub., 2001.
[3] M. Dorigo, L. M. Gambardella, “Ant Colony System: A Cooperative Learning Approach to the Traveling Salesman Problem, ” IEEE Trans. Evolutionary
Computation., vol. 1,No. 1, Apr. 1997, pp. 53–66
[4] H. Hernandez, C. Blum and J. H. Moore, “Ant Colony Optimization for Energy-Efficient Broadcasting in Ad-Hoc Networks, ” in Proc. 6th International
Conference, ANTS 2008, Brussels, 2008, pp.25 –36.
[5] L. D'Acierno, B. Montella and F. De Lucia, “A Stochastic Traffic Assignt Algorithm Based Ant Colony
Optimisation, ” in Proc. 5th International Conference,
ANTS 2006, Brussels, 2006, pp.25 –36.
[6] P. Balaprakash, M. Birattari, T. Stutzle and M. Dorigo, “Estimation-based ant colony optimization and local search for the probabilistic traveling salesman problem,”
(2) Knowledge acquired from doing some trials and errors (1) Knowledge
extracted from some experiences
Artificial soccer agent
Fig. 1 A Soccer agent has improved its ability by
some knowledge from a lot of experiences and some trials and errors
...(1)
case)
other
(in
0
)
(
)
(
)
(
)
(
k i J l il il ij ij k ij
J
j
if
t
t
t
p
k i
)
(
)
(
)
1
(
)
(
t
ijt
ijkt
ij
)
(
0
)
)
,
(
(
)
(
)
(
1other
L
j
i
if
t
L
Q
t
m k k ij
…(2) 118Journal of Swarm Intelligence, vol. 3, Springer, Sep. 2008,
pp. 223–242.
[7] RoboCup Official Homepage, http://www.robocup.org/. [8] RoboCup International Competition RoboCup2010
Official Homepage, http://www.robocup2010.org/. [9] H. Sasaoka, S. Muraki and K. Araki, “Soccer Agents
Using Inductive Learning with Hand-Coded Rules,” in
Proc. of 2003 IEEE International Conference on System, Man & Cybernetics ,IEEE 2003, Washington D.C., 2003,
pp.46 –51.
[10] H. Sasaoka and K. Araki, “Evaluation for Selection Method Using Reinforcement Learning with Hand-Coded Rules in Robocup Soccer,” in Proc. of the 3rd
International Symposium on Autonomous Minirobots for Research and Edutainment, AMiRE 2005, Fukui, 2005,
pp.99 –104..
[11] H. Sasaoka and T. Yamada, “Proposal of Acquiring Method for Agents' Actions using Ant Colony
Optimization in RoboCup Soccer Simulation League,” JSAI Trans. of 27th SIG-AI Challenge, May 2009, pp. 40–43
[12] H. Sasaoka, “Proposal of Acquiring Method for Agents' Actions using Ant Colony Optimization in Multi-agent System,” in Proc. of the 2010 International Symposium on
Intelligent System ,FAN 2010,Tokyo, 2010, (in Printing.)..
[13] UvA Trilearn 2003 - Soccer Simulation Team: http://remote.science.uva.nl/~jellekok/robocup/2003/
a b c d e f g h i j A 0.0000 0.0000 0.0080 0.0027 0.0000 0.0000 0.0000 0.0000 0.0888 0.0301 B 0.0000 0.0000 0.0121 0.0040 0.0000 0.0000 0.0000 0.0000 0.1036 0.3445 C 0.0000 0.0000 0.0162 0.0861 0.2638 0.3230 0.5747 0.5747 0.1184 0.3876 D 0.0000 0.0000 0.0162 0.0162 0.2046 0.4240 0.5814 0.2826 0.1400 0.3876 E 0.0000 0.0000 0.0121 0.0040 0.0000 0.0485 0.0000 0.0000 0.1413 0.3445 F 0.0000 0.0000 0.0080 0.0027 0.0000 0.0000 0.0000 0.0000 0.0888 0.3014
Status in game Value of Q
Getting a score by player in same team 1.0 Getting a corner kick by player in same team 0.5 Getting a goal kick by player in opposite team 0.1
Scores
Game Simulation Steps Team A Team B
1 1 ~ 6000 0 0 2 6001 ~ 12000 3 4 3 12001 ~ 18000 1 1 4 18001 ~ 24000 1 0 5 24001 ~ 30000 3 1 Total Scores 8 6
Win - Lose - Draw
( From Team A ) Win 2, Lose 1, Draw 2
Scores
Game Simulation Steps Team A' Team B
1 1 ~ 6000 1 0 2 6001 ~ 12000 1 3 3 12001 ~ 18000 2 1 4 18001 ~ 24000 0 3 5 24001 ~ 30000 2 1 Total Scores 6 8
Win - Lose - Draw
( From Team A' ) Win 3, Lose 2, Draw 0
TABLE 1: Values of Costs Calculated with both Result of simulations and Hand-Coding Rules
(ηused in equation-1 )
TABLE II: Values of Pheromone Trails in Case of Some Results in its Selecting Actions
TABLE III: Results in Experiments I TABLE IV: Results in Experiments II