1.は じ め に
David Marrは,生物の脳を含む情報処理装置を理解 するためには,三つの水準があると述べている [Marr 82].① 計算理論,② アルゴリズム,③ ハードウェアに よる実現の三つである.我々システム神経科学の研究者 の多くは,脳の機能を明らかにするために研究を行って おり,Marr の言う① と ② のレベルで脳を理解するこ とを主な目的としている.脳に学ぶ人工知能(Artificial Intelligence:AI)とは,脳機能の計算理論的記述をも とに,そのアルゴリズムを推定し,ニューロンのネット ワークではなく,コンピュータ上でそれを実現する,と いうことになる.神経科学においても,工学的視点から の問題解決に必要な計算理論・アルゴリズムの提案は, 脳機能の計算理論・アルゴリズムを考えるうえでの大き なヒントになった.その典型が,[Sutton 81, Sutton 98] による強化学習理論のドーパミン─大脳基底核回路の価 値学習機能への適用であろう [Schultz 97].中脳ドーパ ミン細胞がつくり出す報酬予測誤差情報が,大脳基底核, 特に線条体に送られて価値情報がつくり出されるとする 仮説は,多くの検証実験で確認され,さらなる仮説・モ デルを導くことで,2000 年代の意思決定研究の興隆に つながる. それに比べて,近年の深層学習(Deep Learning: DL)による新たな可能性の発見に基づく AI ブームは, 問題解決に詳細な計算理論・アルゴリズムは使わず,ビッ グデータ解析によりその正答率を上げるという方法を とっている.一方,神経科学,特に意思決定神経科学 の世界では,新しい遺伝子・分子技術の出現で,Marr の 3 番目の水準(ハードウェアによる実現),すなわち, 脳という制約のもと,ニューロン回路がどのように機能 を実現しているかに関心が移ってきているように思われ る.これが,神経科学と AI の融合研究の低迷につなが ることは,いうまでもない [Hassabis 17].このまま神 経科学と AI は,それぞれ独自の道を歩むことになるの だろうか?2.高次般化機能の計算理論の必要性
ヒトの脳機能をまねようがまねまいが,学習における 般化機能は AI の汎用性のキーであり,現在の DL が不 得意とするところである.推論や想像といった,類似性 だけに依存しない般化機能は,AI がヒトの脳に劣る部 分でもある.神経科学分野においても,推論や想像といっ た高次の般化機能がどのように脳で実現されているか, ほとんど解明されていない状態である.しかし,少しず つではあるが,高次般化機能の計算理論的解明を目指す 試みも行われるようになってきた. 本稿では,我々が行ってきたカテゴリー推論の実験的 研究について紹介し,今後の脳研究と人工知能研究の融 合について考えてみたい.3.条 件 付 け
動物における学習の基本形は,大きく古典的(パ ブロフ型)条件付けと道具的(オペラント型)条件付 けに分けることができる.古典的条件付けとは,条 件 刺 激(conditioned stimulus:CS) と 無 条 件 刺 激 (unconditioned stimulus:UCS)が対呈示されることで,推移的推論の脳メカニズム
─汎用人工知能の計算理論構築を目指して─
Neural Mechanisms of Transitive Inference
─ Aiming to Construct Computational Theory for General Purpose
Information Processor ─
田中 慎吾
玉川大学脳科学研究所Shingo Tanaka Brain Science Institute, Tamagawa University. [email protected]
坂上 雅道
(同 上)Masamichi Sakagami [email protected]
Keywords:
lateral prefrontal cortex, striatum, reward inference, model-free learning, model-based learning. 「脳科学と AI のフロンティア」846 人 工 知 能 32 巻 6 号(2017 年 11 月) CSと UCS が連合し,本来 UCS が引き起こす無条件反 応(unconditioned response:UCR)を CS が引き起こ すようになるような学習(条件反応:CR(conditioned response)= UCR)を指す.一方,道具的条件付けとは, 何かの行動を行った結果,動物にとって良いことが起こ るとその行動を繰り返す傾向が高まり(正の強化),逆 に悪いことが起こるとその行動の生起頻度が下がる(負 の強化)といった学習である.さらに,学習された刺激 1と刺激 2 の関係と,刺激 2 と刺激 3 の関係が,脳の中 で結び付くことによって,直接経験していない刺激 1 と 刺激 3 の関係が出来上がる.このように条件付けの関係 性の次元が上がっていくことを高次条件付けという.
4.モデルフリーとモデルベース
Dawらは,条件付けのように,刺激や反応に伴い報 酬や罰が起こると,その程度と確率に応じて刺激と反応 の関係性についての学習が生じるような学習過程を「モ デルフリープロセス(model-free process)」と呼び,こ れには大脳基底核が重要な役割を果たしているとした [Daw 05].モデルフリープロセスにおける学習には,中 脳ドーパミン細胞の報酬予測誤差情報(実際に得た報酬 量と予測された報酬量の誤差)が決定的な役割を果たし ており,この情報が大脳基底核に運ばれ,古典的条件付 けや道具的条件付けを形成する [Samejima 05, Schultz 97].それに対して,刺激や反応の生起とその結果とし て起こる報酬や罰の間に内的な表象を介在させる学習過 程を「モデルベースプロセス(model-based process)」 と呼んだ.内的表象とは,刺激や反応の間の状態遷移を 学習したものであり,この学習には,報酬や罰による強 化は必ずしも必要ではない.Daw らは,モデルベース プロセスの核は状態遷移学習にあり,これには大脳新皮 質,特に前頭前野が重要な役割を果たすと考えた. モデルフリープロセスとモデルベースプロセスの違 いを調べるため,Daw らは,2 段階マルコフ判断課題 (two-stage Markov decision task)と呼ばれる課題を開 発し,それを用いてヒトの行動と脳活動を調べた [Daw 11](図 1).2 段階マルコフ判断課題では,第 1 段階(上 段)で左の図形を選ぶと,70%の確率で第 2 段階(下段) における左の選択肢ペアに進み,30%の確率で右の選択 肢ペアに進む.第 2 段階での選択では,図形ごとに報酬 確率が割り当てられているので,選択した図形の報酬確 率によって報酬の有無が決定される(図 1 A).この報酬 確率は試行ごとに変動するため,被験者は報酬経験を通 じて,その報酬確率を学習する必要がある.図 1 B は, ある試行における報酬の有無によって,その次の試行の 第 1 段階の選択で,前の試行と同じ選択肢を選ぶ確率を 予想したものである.モデルフリー戦略を取る場合(左 のパネル),ある試行で報酬を得ることができたならば, 第 2 段階が 70%の確率側に行こうと 30%の確率側に行 こうと,次の試行では,前の試行の第 1 段階で選択した 刺激と同じ刺激を選ぶと考えられる.逆に,報酬がなかっ たならば,次の第 1 段階の選択は,前の試行で選んだ刺 激とは異なる刺激を選ぶと考えられる.一方,モデルベー ス戦略を取った場合(右のパネル)には,ある試行で報 酬を得ることができても,確率的に移行した第 2 段階が 70%の確率側である場合に比べ,30%側であった場合は, 次の試行の第 1 段階では選択する刺激を変える確率が上 がる,つまり同じ第 2 段階へより移行しやすい刺激を選 ぶ傾向がある,と考えられる.ある試行で報酬がなけれ ば,そのとき移行した第 2 段階が 30%側であった場合 には,70%側であった場合に比べ,次の第 1 段階で選択 を変える確率は減る,つまり同じ第 2 段階へより移行し にくい刺激を選ぶ傾向がある,と考えられる. 2段階マルコフ判断課題の遂行中,被験者がモデルフ リー戦略をとる場合には,課題探索により報酬予測誤差 情報が検出され,モデルベース戦略をとる場合には,状 態予測誤差情報(第 1 段階から第 2 段階への移行確率の 学習のための誤差情報)が検出されると予想される.実 際,モデルフリー戦略をとっている場合には,大脳基底 核の線条体(striatum)が強く活動し,モデルベース 戦略をとっている場合には,大脳新皮質,特に前頭前野 が強く活動していた [Daw 11, Glascher 10].このこと 図 1 2 段階マルコフ判断課題. A. 2段階マルコフ判断課題の概略.B. モデルフリー戦略 とモデルベース戦略を用いた場合の,被験者の選択行動 の予測から,モデルベース戦略の核となる環境情報の状態遷移 学習に前頭前野は重要な働きをしていることが示唆され た.前頭前野損傷患者は,ウイスコンシンカードソーティ ング課題やストループ課題など文脈的判断が要求される 課題での成績が低下すること [Lhermitte 86, Luria 80, Milner 64, Owen 96, Perret 74],また,ヒト以外の霊 長類での前頭前野ニューロン活動記録実験によって,文 脈やルール,高次条件付けを反映するニューロンが多数 見いだされていること [Amemori 06, Han 09, Hoshi 00, Sakagami 94, Vallentin 12, Wallis 01, White 99]を考え ると,前頭前野が状態遷移学習に関係していることは想 像に難くない.
5.間接的報酬予測課題
前頭前野の状態遷移予測機能を確認するために,我々 は直接的な報酬経験を経ることなく,報酬を予測させる 課題を開発した [Pan 08, Pan 14].この課題では,被験 体であるニホンザルは,まず連続対連合課題(sequential paired association task)によって,六つの視覚刺激 の関係性について学習した(A1 → B1 → C1 もしくは A2→ B2 → C2)(図 2 A).その後,C1 と C2 を使って グループとジュース報酬の関係を教え(例えば,C1 →大報酬,C2 →小報酬)(reward instruction trial:RIT), 続く連続対連合試行(sequential paired association trial:SPAT)で,A1,A2 と報酬との関係を推測させた (図 2 B).ある課題試行ブロックにおいて RIT と SPAT における刺激と報酬の関係は共通であるため,C1 が大 報酬と関連付けられた場合,SPAT においては,A1 が 提示された段階で,大報酬を予測することが可能となる. 実際に,ニホンザルは RIT 課題における報酬情報を保 持し,SPAT 課題において利用することで,SPAT 課題 の第 1 試行から報酬を予測することが可能であった.こ のことは,サルが SPAT における刺激の状態遷移を学習 しており,それを RIT で獲得した報酬情報と結び付け ることができることを示している. さらに,我々はこの課題を行っているニホンザルの 前頭前野外側部(lateral prefrontal cortex:LPFC)と 大脳基底核線条体から単一ニューロン活動の記録を行っ た.LPFC と線条体のニューロンは,SPAT 課題の第 1 試行目から,報酬の大小を区別するような活動を示した (図 2 C).このことは,サルの行動同様,LPFC ニュー ロンと線条体のニューロンは RIT 課題における報酬情 報を保持し,SPAT 課題において報酬予測ができること を示している.しかし,線条体のニューロンも,LPFC ニューロン同様 SPAT の第 1 試行から正しく報酬予測を 図 2 間接的報酬予測課題における,前頭前野外側部ニューロンと線条体ニューロンの活動. A. 2グループの視覚刺激.B. 間接的報酬予測課題の概略.C. 前頭前野外側部と線条体における,第 1 刺激に 対する報酬弁別的ニューロン活動
848 人 工 知 能 32 巻 6 号(2017 年 11 月) 行っており,状態遷移情報がコードされているかどうか だけでは,前頭前野と線条体の機能的違いは説明できな い. そこで次に,直接経験がない状態においても,状態遷 移情報を利用し,推移的推論機能(A ならば B,かつ,B ならば C,ならば,A ならば C)を実現し得るのか,と いう点について検討した.先ほどの 6 種類の視覚刺激に 加え,新たに新奇刺激(例えば N1 と N2)を導入し,B1 と B2 を利用した対連合課題によって,新奇刺激がどちら のグループに属するか,ということを学習させた(図 3 A). 次に RIT 課題によって,二つのグループに対する報酬 情報を与えた後,SPAT 課題において,新奇刺激に対し ての報酬予測が可能かどうか調べた(図 3 B).その結果, SPAT課題において,初めて新奇刺激が導入された試行 においてさえ,ニホンザルは,その刺激と関連付けられ た報酬の大小を予測することが可能であることがわかっ た.このことは,ニホンザルは直接の経験がなくても刺 激と報酬の関係を推論することが可能であることを示し ている.同様に,LPFC のニューロンも,新奇刺激導入後, 初めての試行から報酬の大小を区別するような活動を示 した(図 3 C 左).一方,線条体のニューロンは,新奇 刺激導入後,最初の試行においては報酬の大小を予測す ることができなかった(図 3 C 右).しかし,試行を繰 り返すことで,報酬予測が徐々に可能になっていった. 以上の結果は LPFC のニューロンが状態推移情報を利 用した報酬予測に加え,推移的推論を利用した報酬予測 も行えることを示している.それでは,なぜそのような 推論が可能なのであろうか.特定の視覚刺激と報酬との 組合せをコードしているニューロン同士が情報をやり取 りし,推移的推論を行うのであろうか.SPAT 課題にお いて,我々は視覚刺激を ABC の順番で提示していたが, これを BCA や CAB のような順番に変更して同様の実験 を行った.もし LPFC ニューロンが特定の視覚刺激と報 酬との組合せをコードしているのであれば,視覚刺激の 図 3 新奇視覚刺激を導入した,間接的報酬予測課題. A. 新奇視覚刺激の例.B. 新奇視覚刺激を用いた,間接的報酬予測課題の概略. C. 前頭前野外側部と線条体における,第 1 刺激に対する報酬弁別的ニューロン活動
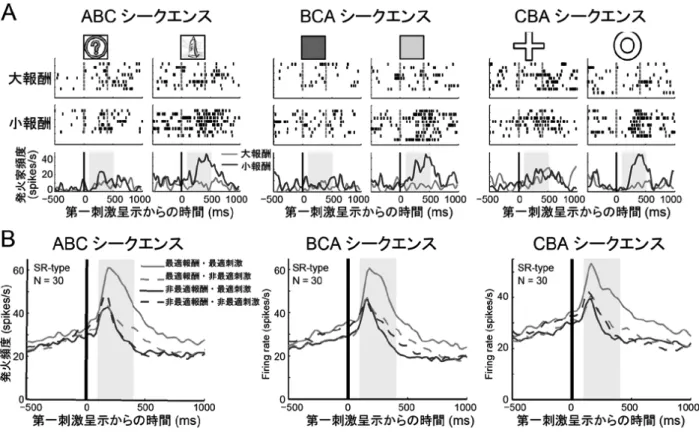
呈示順序が変化すると,つまり B や C の刺激が一番初 めに提示されると,視覚刺激の弁別はできなくなると予 測された.しかしながら,この実験の結果,LPFC ニュー ロンは,特定の視覚刺激ではなく,特定のグループと報 酬との組合せをコードしていることが明らかとなった (図 4).一方で,線条体のニューロンは LPFC ニューロ ンのように,特定のグループと報酬との組合せに応じて, 活動を変化させることはなく,特定の視覚刺激と報酬と の組合せをコードしていることがわかった.
6.カテゴリー化と報酬予測
この結果から推測されることは,LPFC ニューロンが 情報を抽象化する能力をもつということである.LFPC ニューロンは視覚刺激をカテゴリーに分け,そのカテゴ リーに報酬情報を付加することで,直接経験のない条件 でも,視覚刺激に関連付けられる報酬を推測することが 可能であった.このような,情報の抽象化とそれを利用 した学習がヒトを含む動物の思考や推論の基礎になるの ではないだろうか.7.お わ り に
他方,人工知能技術でも,このような情報の抽象化 は可能なのであろうか.一連の研究で用いた視覚刺激は グループごとに特徴があるわけではなく,対連合課題に よって学習するものである.そのため,対連合課題を用 いた視覚刺激のカテゴリー化を実現するためには,これ までに実績のある画像認識や物体認識とは異なる手法を とる必要はあるだろう.しかし,もし CNN や DL を用 いることで,視覚刺激のカテゴリー化が可能であるなら ば,それと機械学習を組み合わせることで,人工知能に よる推移的推論が可能となるだろう.また,たとえ同じ 感覚刺激を用いたとしても,環境や状況により,抽象化 されるべき情報は異なってくる.状況や環境に応じて, 情報の抽象化が可能になれば,推移的推論に限らず,多 くの認知機能を再現可能な,いわゆる汎用人工知能の開 発につながるのではないだろうか. このように,神経科学研究からも,これまで手を付 けられなかった思考や推論,想像の計算理論的記述を可 能とするデータが発表されるようになってきた [Donoso 14, Funamizu 16, Johanson 07, Pfeiffer 13].脳科学とAIの融合研究を促進するのは,何よりも Marr の言う計
算理論,アルゴリズムの解明である.このような視点に 立った高次認知機能研究の進歩は,ビッグデータに依存 した現在の AI を超える汎用 AI の開発に不可欠である.
◇ 参 考 文 献 ◇
[Amemori 06] Amemori, K. and Sawaguchi, T.: Rule-dependent shifting of sensorimotor representation in the primate prefrontal cortex, Eur. J. Neurosci., Vol. 23, pp. 1895-1909 (2006)
図 4 前頭前野外側部における,カテゴリー化ニューロンの神経活動.
A. 刺激呈示順を変更した,間接的報酬予測課題における前頭前野外側部ニューロンの活動例.B. 刺激呈示順 を変更した,間接的報酬予測課題における前頭前野外側部ニューロン集団の平均的活動
850 人 工 知 能 32 巻 6 号(2017 年 11 月)
[Daw 05] Daw, N. D., Niv, Y. and Dayan, P.: Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control, Nat. Neurosci., Vol. 8, pp. 1704-1711(2005)
[Daw 11] Daw, N. D., Gershman, S. J., Seymour, B., Dayan, P. and Dolan, R. J.: Model-based influences on humans’ choices and striatal prediction errors, Neuron, Vol. 69, pp. 1204-1215 (2011)
[Donoso 14] Donoso, M., Collins, A. G. and Koechlin, E.: Human cognition, Foundations of human reasoning in the prefrontal cortex, Science, Vol. 344, pp. 1481-1486(2014)
[Funamizu 16] Funamizu, A., Kuhn, B. and Doya, K.: Neural substrate of dynamic Bayesian inference in the cerebral cortex, Nat. Neurosci., Vol. 19, pp. 1682-1689(2016)
[Glascher 10] Glascher, J., Daw, N., Dayan, P. and O’Doherty, J. P.: States versus rewards: Dissociable neural prediction error signals underlying model-based and model-free reinforcement learning, Neuron, Vol. 66, pp. 585-595(2010)
[Han 09] Han, S., Huettel, S. A. and Dobbins, I. G.: Rule-dependent prefrontal cortex activity across episodic and perceptual decisions: An fMRI investigation of the criterial classification account, J. Cogn. Neurosci., Vol. 21, pp. 922-937 (2009)
[Hassabis 17] Hassabis, D., Kumaran, D., Summerfield, C. and Botvinick, M.: Neuroscience-inspired artificial intelligence,
Neuron, Vol. 95, pp. 245-258(2017)
[Hoshi 00] Hoshi, E., Shima, K. and Tanji, J.: Neuronal activity in the primate prefrontal cortex in the process of motor selection based on two behavioral rules, J. Neurophysiol., Vol. 83, pp. 2355-2373(2000)
[Johanson 07] Johnson, A. and Redish, A. D.: Neural ensembles in CA3 transiently encode paths forward of the animal at a decision point, J. Neurosci., Vol. 27, pp. 12176-12189(2007) [Lhermitte 86] Lhermitte, F., Pillon, B. and Serdaru, M.:
Human autonomy and the frontal lobes, Part I: Imitation and utilization behavior: A neuropsychological study of 75 patients,
Ann. Neurol., Vol. 19, pp. 326-334(1986)
[Luria 80] Luria, A. R.: Higher Cortical Functions in Man(2nd ed.), Basic Books, New York(1980)
[Mar 82] Marr, D.: Vision: A Computational Investigation into the
Human Representation and Processing of Visual Information,
MIT Press, Cambridge(1982)
[Milner 64] Milner, B.: Some effects of frontal lobectomy in man, Warren, J. M. and Akert, K.(eds.), The Frontal Granular
Cortex and Behavior, pp. 313-334, McGraw-Hill, New York
(1964)
[Owen 96] Owen, A. M., Evans, A. C. and Petrides, M.: Evidence for a two-stage model of spatial working memory processing within the lateral frontal cortex: a positron emission tomography study, Cereb. Cortex, Vol. 6, pp. 31-38(1996) [Pan 08] Pan, X., Sawa, K., Tsuda, I., Tsukada, M. and Sakagami,
M.: Reward prediction based on stimulus categorization in primate lateral prefrontal cortex, Nat. Neurosci., Vol. 11, pp. 703-712(2008)
[Pan 14] Pan, X., Fan, H., Sawa, K., Tsuda, I. and Tsukada, M., et al.: Reward inference by primate prefrontal and striatal neurons, J. Neurosci., Vol. 34, pp. 1380-1396(2014)
[Perret 74] Perret, E.: The left frontal lobe of man and the suppression of habitual responses in verbal categorical behaviour, Neuropsychol., Vol. 12, pp. 323-330(1974) [Pfeiffer 13] Pfeiffer, B. E. and Foster, D. J.: Hippocampal
place-cell sequences depict future paths to remembered goals,
Nature, Vol. 497, pp. 74-79(2013)
[Samejima 05] Samejima, K., Ueda, Y., Doya, K. and Kimura, M.: Representation of action-specific reward values in the striatum, Science, Vol. 310, pp. 1337-1340(2005)
[Sakagami 94] Sakagami, M. and Niki, H.: Encoding of behavioral significance of visual stimuli by primate prefrontal neurons: relation to relevant task conditions, Exp. Brain Res., Vol. 97, pp. 423-436(1994)
[Schultz 97] Schultz, W., Dayan, P. and Montague, P. R.: A neural substrate of prediction and reward, Science, Vol. 275, No. 5306, pp. 1593-1599(1997)
[Sutton 81] Sutton, R. S. and Barto, A. G.: Toward a modern theory of adaptive networks: Expectation and prediction,
Psychol. Rev., Vol. 88, pp. 135-170(1981)
[Sutton 98] Sutton, R. S. and Barto, A. G.: Reinforcement
Learning: An Introduction, A Bradford Book, Cambridge
(1998)
[Vallentin 12] Vallentin, D., Bongard, S. and Nieder, A.: Numerical rule coding in the prefrontal, premotor, and posterior parietal cortices of macaques, J. Neurosci., Vol. 32, pp. 6621-6630(2012)
[Wallis 01] Wallis, J. D., Anderson, K. C. and Miller, E. K.: Single neurons in prefrontal cortex encode abstract rules, Nature, Vol. 411, pp. 953-956(2001)
[White 99] White, I. M. and Wise, S. P.: Rule-dependent neuronal activity in the prefrontal cortex, Exp. Brain Res., Vol. 126, pp. 315-335(1999) 2017年 9 月 27 日 受理