Coding Disfluency Phenomena for a Fluency Measure in TBLT Research
Tomohito Ishikawa
The aim of this article is to describe coding steps for a disfluency measure employed in Ishikawa (2008a, b). According to Ellis and Barkhuizen (2005), fluency measures can be divided into two major categories. One is related to speed of speaking (i.e., temporal variables) and the other is related to repair fluency. In the sections to follow, I will first describe Shriberg's classifica- tion system of disfluency. After the description of Shriberg's classification system, I will describe an L2 disfluency measure used in Ishikawa (2008a, b).
In contrast to the relatively straightforward definitions and operationaliza- tions of the temporal aspect of L2 fluency such as speech rate, the repair aspect of L2 fluency needs somewhat extended descriptions. The present arti- cle adopts the disfluency classification system developed by Shriberg (1994;
also see Bear, Dowding, Shriberg, & Price, 1993). There have been many classification systems for coding L1 disfluencies (e.g., Allwood , Nivre, &
Ahlsen, 1990, Clark & Clark, 1977; Maclay & Osgood, 1959, see Lickley, 1994, for a review) and L2 disfluencies (e.g., e.g., Fathman, 1980; Foster &
Skehan, 1999; Foster, Tonkyn, & Wigglesworth, 2000). However, as
Shriberg (1994) points out, most of the categorization systems have in com-
mon; that is, they are based on "correspondences in wording" between the items before and after the interruption point (IP).
It should be noted here that Shriberg's system is originally developed for same-turn disfluencies (Shriberg, 1994, P. 6) and is designed to handle only within-sentence disfluencies (in the present article, "sentences" are defined as
"T -units ," which is virtually the same as what Shriberg refers to as "sen- tences"). Other speech phenomena not considered in her system include:
silent pauses, pathological stuttering, discourse markers, uncorrected errors (Shriberg, 1994, p. 2, 6-7, chapter 4, and some specific cases are mentioned in this thesis). Although the coding methods described in the present article were almost identical to Shriberg's, some modifications were made.
General modifications to Shriberg (1994)
Shriberg distinguishes basic disfluency types from complex ones, which contain more than one disfluency episode (an example is given below).
Although Shriberg treats both simple and complex disfluencies separately, I decomposed complex disfluencies into their disfluency components and counted each disfluency episode separately. The decomposition was neces- sary in order to add consistency in counting the number of disfluencies, which previous studies did not clarify criteria about, which is criticized by Ellis and Barkhuizen (2005). A sample of complex disfluencies given by Shriberg (1994, p. 58) is:
he she she liked it
This is regarded as a complex disfluency because: (1) "he" is substituted
by the fist "she," which is the output of the first repair; (2) the output of the
first repair operation (i.e., "she") is also an input to the second repair opera-
CODING DISFLUENCY PHENOMENA 103 tion. That is, the output of the first repair operation is repeated (i.e., repaired) by the second "she." Formally, the sample above is represented as follows:
he she she liked it [R[ s . s]. r
The two sets of square brackets in the above example indicate that two disfluency components are involved in this case (i.e., "he she" and "she she"). Such cases are called complex disfluencies because the first "she" is involved in two disfluency components. In Ishikawa (2008a, b), however, I did not distinguish simple and complex disfluencies as Shriberg did, and decomposed complex ones into simple ones. For instance, rather than treating the above example as a single complex disfluency, I treated it as two disflu- encies or two disfluency episodes. In other words, the number of disfluency episodes is equal to the number of interruption points.
Major coding steps of Shriberg (1994)
The first step for disfluency coding is to identify the interruption point (IP) by carefully listening to the recorded speech and checking the transcribed speech. After identifying the IP with the help of sudden interruptions, prosod- ic cues, editing expressions, and retracing of words, three structural regions of the disfluency are identified: the reparandum (RM), the interregnum (IM), and the repair (RR).
she liked really liked I-RM-II-IM-II---RR---I
it
The extent of the whole disfluency region is dependent on the extent of
correspondences between items before and after the IP, which marks the onset of the interregnum (IM). In the above example, if the repair is made by retracing up to "she," the RM and the RR both expand to accommodate the retracing:
she liked she really liked it I---RM---II-IM-II---RR---I
If the reparandum is expanded or delayed up to "it," the structural regions of both the RM and the RR may expand similarly:
she liked it I---RM---I I-IM-I I
really liked it --RR---I
The disfluency region is delimited by a set of two square brackets. Below the onset of the RM is indicated by "[", the offset of the RR by "]", and the IP by 6,.":
she liked [ •
really liked it ]
Subsequently, items before and after the IP are annotated with symbols based on the nature of correspondences in wording. In the case mentioned immediately above, because "liked" is repeated, both items are marked with
"r (= repetition) ." In contrast, "really" does not have its corresponding item in
the RM; so, it is marked with "i (= inserted)." The output of these annotation
procedures is below:
CODING DISFLUENCY PHENOMENA 105 she liked really liked it
[r. i r ]
When a filled pause is present in the interregnum (IM), it is indicated by
"f" after the IP (_ " ."):
she liked um really liked it
[ r .f i r ]
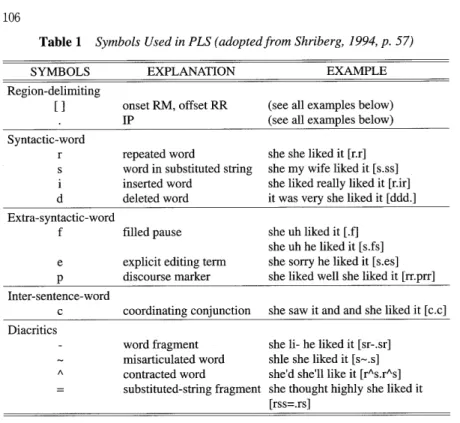
These symbols are summarized in Table 1, which is taken from Shriberg's Pattern Labeling System (PLS) (1994, p. 57). I describe PLS in the following sections.
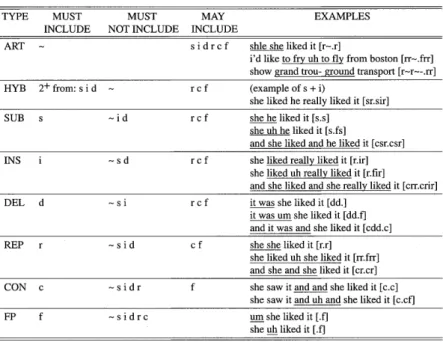
When the labeling task is complete, the next step is to determine its disflu- ency type by considering only types of annotations marked with the square brackets (not their frequencies). In this example, the square brackets contain three "types" of annotations (i.e., "r," "f," and "i"). The types of disfluencies are automatically identified based on Shriberg's Type Classification Algorithm (TCA). Table 1 is from Shriberg (1994). Table 2 specifies (1) must symbols, (2) must-not symbols, and (3) optional symbols, in identifying disfluency types. Table 7 also contains her samples annotated with pattern symbols. Going back to the example introduced above, because the brackets contain the three different symbols (i.e., r, f, i), the only category that can accommodate the sample is INS (= insertion), which must contain "i" but can include "r" and "1" as optional symbols within a single set of square brackets.
It should be noted that all the categories except for REP is characterized by
having "r" as an optional symbol. These are the major steps in classifying
disfluencies. In what follows, I describe the Pattern Labeling System (PLS).
Table 1 Symbols Used in PLS (adopted from Shriberg, 1994, P. 57)
SYMBOLS EXPLANATION EXAMPLE
Region-delimiting
[] onset RM, offset RR
IP
(see all examples below) (see all examples below)
Syntactic-word
d
repeated word
word in substituted string inserted word
deleted word
she she liked it [r.r]
she my wife liked it [s.ss]
she liked really liked it [r.ir]
it was very she liked it [ddd.]
Extra-syntactic-word f e P
filled pause explicit editing term discourse marker
she uh liked it [.f]
she uh he liked it [s.fs]
she sorry he liked it [s.es]
she liked well she liked it [rr.prr]
Inter-sentence-word
c coordinating conjunction she saw it and and she liked it [c.c]
Diacritics
A
word fragment misarticulated word contracted word substituted-string fragment
she li- he liked it [sr-.sr]
shle she liked it [s—.s]
she'd she'll like it [r^s.r^s]
she thought highly she liked it [rss=.rs]
Pattern Labeling System (PLS) Region-delimiting "1 1 "
As described above, the square brackets "[ 1" indicate the whole extent of the region of the disfluency. The left square bracket indicate the onset of the RM and the left square bracket the off set of the RR.
Interruption point ". "
The symbol "." indicates the interruption point (IP). This is based on the
surface form only. Therefore, it does not indicate the point where the speaker
actually detects the trouble. To sum up the region-delimiting symbols, the
Table 2 Type Classification Algorithm (TCA) (from Shriberg, 1994, p. 78)
TYPE MUSTMUST
INCLUDENOT INCLUDE
MAY INCLUDE
EXAMPLES
ART sidrcf
shle she liked it [r-.r]
i'd like to fry uh to fly from boston [rr-.frr]
show grand trou- ground transport [r-r--.rr]
HYB 2+ from: s i d r c f
(example of s + i)
she liked he really liked it [sr.sir]
SUB s -id rcf
she he liked it [s.s]
she uh he liked it [s.fs]
and she liked and he liked it [csr.csr]
INS i
-
sd r c f
she liked really liked it [r.ir]
she liked uh really liked it [r.fir]
and she liked and she really liked it [crr.crir]
DEL d ~si r c f
it was she liked it [dd.]
it was urn she liked it [dd.f]
and it was and she liked it [cdd.c]
REP r -sid cf
she she liked it [r.r]
she liked uh she liked it [rr.frr]
and she and she liked it [cr.cr]
CON c -sidr f
she saw it and and she liked it [c.c]
she saw it and uh and she liked it [c.cf]
FP f -sidrc
um she liked it [1]
she uh liked it [.f]
RM then is indicated by the region ranging from "[" to ".". The IP is often followed by filled pauses ("f'), editing terms ("e"), discourse markers ("p" =
"pragmatic expressions") . The interregnum (IM) may or may not contain "f,"
"e
," or "p." The repair (RR) extends from the last of "f," "e," or "p" to the right square bracket "I"
Syntactic-word symbols
According to Shriberg (1994, p. 59), "syntactic words" are defined as "any
words that play a role in the formal syntax of a sentence." These syntactic
words are distinguished from "extra-syntactic words" (i.e., "e," "f," and "p"),
which "break from or are not part of the formal syntax" and from "inter-sen-
tence" words (i.e., coordinating conjunctions or "c"), which "are outside the
scope of the sentence syntax." Syntactic words are of four types: "r," "s,"
"d
," and "i."
Syntactic word "r" According to Shriberg, the symbol "r" is used for words that are exactly repeated before and after the IP. Samples from my cor- pus are (hereafter, disfluency regions are underlined):
• Joe came late came late for a meeting [rr .rr]
• so because of ah because of the Beth's showing up later for the meeting [rr.frr]
These are distinct from the use of repetitions for rhetorical purposes.
Syntactic word "s" The symbol "s" is used for items that are substituted.
According to Shriberg, items involved in substitution must show syntactic and semantic correspondences. Sometimes one item is substituted by more than item; therefore, there is no necessary one-to-one correspondence between the substituting and the substituted items. Shriberg also suggests that
anaphora and changes in tense, number, definite article form etc. are also characterized by the substituting repair operations. Below are samples from my corpus:
• so it was the meeting was OK [ss .ss] (reference)
• and because of that because of his ah attitude Ann got angry [rrs.rrsfs]
(reference)
• now after that trouble Mike and Beth completely has have no conversa- tion [s.s] (tense)
• can you could you please call me back [sr.sr] (surface tense)
• I think the reason is un Cathy help Cathy helps Nick [rs.rs] (subject-
CODING DISFLUENCY PHENOMENA 109 verb agreement)
• last week Mike Mike collected many um much information [s.fs]
(countable vs. uncountable)
• their relationship becomed become very bad now [s.s] (overgeneraliza-
tion)
• ah there is a the section chief Mike [s.s] (article)
• Bob is very how to say hard I mean not easy to be friendly [sppps .eess]
(rephrasing)
Topicalizations and left-dislocations are not analyzed in Ishikawa (2008a, b). They were treated as learner errors; therefore, items involved in them are not marked with "s" (i.e., "Cathy the secretary" and "she" in the sample below):
• and then Cathy the secretary she is in good condition with Nick section chief
Finally I found (though only one case in my corpus) unintentional code- switching that was repaired immediately. Below is the case with its discourse contexts:
• and because of that because of his ah attitude Ann got angry and their /kan-/ their relationship has changed because at first their relationship
was quite good that after his after the trouble they were not doing well
Given the lack of strong clues for contextual intrusions and the fact that
one of the Japanese translation equivalents of English "relationship" is "kan-
kei," the sound strings /kan/, which was produced without hesitation (see
Poulisse, 1999), was considered as an unintentional code switching, and the disfluency was coded as [rs-.rs], which means that the fragment (indicated by
" -") of the Japanese translation equivalent was substituted by the target lan- guage word "relationship."
Syntactic word "d" Whereas corresponding items are found in the cases of repetition and substitution operations, in the case of deletion and insertion operations, no such correspondences can be assumed. Deletion is then char- acterized by "[w]ords deleted from the RM and having no corresponding words in the RR" (Shriberg, 1994, p. 61). What is termed "fresh starts" or
"false starts" belong to this class; however
, deletion can also occur in mid- sentential positions as Shriberg points out. Below are samples from my cor- pus (the symbol "c" is annotated to a coordinating conjunction, the symbol
"f' to a filled pause):
• and Kate and John s- ah OK I have to report the relationships between Kate John ah Nick and Cathy [cddddd-.f]
• so th- he can figure out what is going on what is Ka- Kate and Nick [d-.]
• and mm also Kate for Kate our section staffs Kate is not mm Kate is our section staffs [d.] [dd.] [dddddd.f]
• it became very difficult to work with both of both Joe Bob and Ann [dd.]
Disfluencies that involved word order including reordering (Allwood, et al., 1990, p. 21-22) were also treated as deletions. In my corpus I found only one instance:
• Cathy secre- secretary Cathy is also doing well quite well [dd-.]
CODING DISFLUENCY PHENOMENA 111 Syntactic word "i" When new items are inserted in the RR, these items are marked with "i." Below are samples from Shriberg's and my corpus:
• please give me fares round trip fares from pittsburgh [r.iir] (from Shriberg 1994, p. 61)
• and she is actually she is a strict person about the time [rr.irr]
• I h- first I have to introduce my section members [rr- .irr]
• and section chief Nick and Cathy secre- secretary Cathy is also doing well quite well [r.ir]
There are some cases, which are not considered as insertion. These are:
seamless insertions; between-element parenthetical asides; and full-clause parenthetical asides. Following Shriberg (1994) and Blackmer and Mitton (1991), adding materials as an afterthought is not analyzed in (2008a, b).
Instances of such cases are found in Carletta, Caley, and Isard (1993). Sample utterances in the map-task corpus (Carletta et al., 1993) provide us with ideas about what the category of "seamless insertions" refers to (those afterthought materials are underlined):
• It's three inches above it if you go south (added clause)
• Go to your right horizontally (added adverbials)
• you're next to banana tree the word (nouns of apposition; here the information receiver could see "banana tree" on the map)
• Rockfall I've got (continuations from topical noun phrases)
Carletta et al. (1993) included these under the category of "insertions" on
the grounds that "hearing them made us believe that the speakers had not
conceptualized the added material until after they would have preferred to
include it in the utterance and that the speakers would have performed seamed insertions if they had not found ways to add the new material" (p. 6).
Their rationale sounds convincing; however, because Shriberg's system is designed to handle only disfluencies, where the speaker's hypothesized intended utterances can be restored by deleting some items, those seamless insertions have nothing to be deleted; therefore, they are outside the scope of the present article.
Under the heading of "inserts," Clark and Fox Tree (2002, p. 78) mention several parenthetical asides. These include: editing expressions (e.g., "I mean," "you know," "that is," "no," "sorry" etc.); certain discourse markers (e.g., "well," "now," "oh," "like" etc.); and laughter, sighs, and tongue clicks.
In PLS, discourse markers and editing terms are marked with "p" and "e"
respectively; however, they are distinct from "i" (i.e., insertion). In other words, those including laughter and sighs are not included in the analysis of Ishikawa (2008a, b).
Clark and Fox Tree (2002) also describe full-clause parenthetical asides by citing utterances produced by radio announcers reported by Goffman
(1981, p. 290):
• Seventy-two degrees Celsius. I beg your pardon. Seventeen degrees Celsius. Seventy would be a little warm.
Following Shriberg (1994, p. 61), these full-clause parenthetical asides are not marked with "i" in Ishikawa (2008a, b). Thus, they were not considered as disfluencies.
Extra-syntactic-word symbols
According to Shriberg (1994), extra-syntactic words "do not play a role in
CODING DISFLUENCY PHENOMENA 113 formal syntax of a sentence, but rather serve a discourse purpose" (p. 61).
The PLS distinguishes three types of extra-syntactic words: filled pauses;
explicit editing phrases; and discourse markers. These three extra-syntactic words are distinguished for the purpose of correction procedures, in which words are deleted so that the speaker's hypothesized intended utterances could be restored. These correction procedures are described later.
Extra-syntactic word 7" Filled pauses are marked with "f." These include "uh" and "um" and their variants as well as L1 filled pauses of the L2 speaker (i.e., Japanese filled pauses, e.g., "ee" "nnto" etc., see Yamane, 2002). These filled pauses are distinguished from grunts or unintelligible vocalizations, and heavily vocalized stops (Shriberg, 1994, 42). Some filled pauses are very difficult to distinguish whether they are English or Japanese (e.g., "ah"). In Ishikawa (2008a, b), however, these filled pause types are not counted separately.
The other treatments of filled pauses are identical to Shriberg (1994).
More specifically, with respect to how to count the number of filled pauses, they are treated differently depending on whether they occur outside or inside the disfluency region marked by the two square brackets. Filled pauses that occur in otherwise fluent speech (i.e., outside the "[ 1") are coded as in the following sample from my corpus:
• I have four people in my office ah two men and two woman [.f]
Placing "." before "f" is a convention procedure. In this case, the number
of filled pauses is one. How do we count the number of filled pauses if more
than filled pause occurs in direct sequence as in the following sample from
my corpus?:
114
• a secretary named Beth ah /a/ lost a document [1][•f]
In this case, following Shriberg (1994, P. 63), the number of filled pauses is one (silent pauses between filled pauses are disregarded even when they are long). This is true even when multiple filled pauses are placed in serial, which is frequent for L2 speakers. Quite often filled pauses occur adjacent to the disfluency region. In such cases, consistent with the aforementioned state- ment, "[.f]" is marked outside the disfluency region and is counted as one filled pause:
• um he didn't he didn't accept it [.f] [r r .r r ]
In contrast, filled pauses that occur inside the disfluency region are not counted separately. Below are samples from Shriberg (1994, p. 62):
• show flights arriving in uh arriving in boston
[ r r.f r r]
• show flights arriving uh in arriving in boston [ r f r. r r]
• show flights arriving in arriving uh in boston [ r r . r f r]
In any of these cases, the number of filled pauses is zero.
Extra-syntactic word "e" The symbol "e" is assigned to each word of
editing phrases. Instances of editing words are "no," "sorry," "oops," "I
CODING DISFLUENCY PHENOMENA 115 mean," etc. L2 speakers often transfer L1 editing phrases into the L2.
Although Ll transfer of editing words are not present in my corpus, narrative data that Ishikawa (unpublished) elicited from Japanese high school students contained L1 editing phrases (e.g., "chigau (= wrong)"). Below is a sample from my corpus:
• they were in good condition ah I mean in good relationship
[r r s .f e e r r s ]
Editing phrases typically occur in the IM; however, Shriberg (1994, p. 63) cites a case, where editing phrases appear in the RR as well.
• list flights to boston i mean to denver rather
[r r .e e r r e]
Extra-syntactic word "p" Words in discourse markers (e.g., "well," "of course," "you know," "by the way") are marked with "p" only when they appear in the disfluency region (i.e., inside of "[ ]"). The symbol "p" stands for "pragmatic expression" because the symbol "d" is already used for delet- ed words in the RM. Discourse markers can also occur outside of "[ ]" (Ball,
1986); however, those discourse markers are not considered as disfluencies and therefore they are not labeled. Below is a sample from my corpus:
• Bob is very how to say hard I mean not easy to be friendly [s p p p s.e e s s ]
In this case, discourse markers (along with editing phrases) are used in
rephrasing.
116
Inter-sentence-word symbol "c" As Shriberg (1994, P. 64) notes, these inter-sentence words can be re-labeled with "r" or "s." Below are samples from my corpus:
• but ah so they worked really hard [c.fc] (recodable as [s.fs])
• and and Joe is the section chief [c.c] (recodable as [r.r])
• but but yesterday Beth deleted data on a computer [c.c] (recodable as [r.r])
The symbol "c" can also be recodable as the samples above show.
Diacritic marker "-" Word fragments are marked with the diacritic marker "-" and the diacritic marker is attached after the syntactic symbols "r"
and "s." Samples from my corpus are:
• and h- she did a good job [s-.s]
• but yesterday Beth accidentally dele- deleted data on a computer [r-.r]
Diacritic marker "—" Misarticulated words within the two squared brackets are labeled with the diacritic marker "- ." The diacritic marker is attached after the syntactic symbols "r" and "s," but sometimes the diacritic marker "—" combines with the previously mentioned diacritic marker for word fragments (i.e., "-"). In that case, "—" is attached between the syntactic word and the diacritic marker "-." Below are samples from my corpus:
• because he hafs has to use the document [r— .r]
• and malefme male staff is doing well [s—.s]
• hello Mr. President this is nam- Minami calling [r--.r]
CODING DISFLUENCY PHENOMENA 117 In Shriberg's classification system, any disfluency that contains "—" is cat- egorized as ART (= misarticulation).
Diacritic marker "A" The diacritic marker "A" indicates the existence of contractions (e.g., "she's"). Below are examples from Shriberg (1994, p. 65):
• she'd she'll like it [Os .r^s]
• she'd he'd like it [Or . Or]
• she she'd like it [r. r^
A contracted word is treated as one word.
Diacritic marker "_" According to Shriberg (1994), the diacritic marker
"=" is used "when a substitution is strongly suggested b
ut the first string is one or more words short" (p. 66). Below is a sample from her corpus:
• urn i guess we're going to talk describe uh job benefit [s= • s ]
Here the diacritic marker "=" is attached because the hypothesis is that the speaker substituted "describe" for "talk about." Another case, where the dia- critic marker "=" is used, is given below (from Shriberg, 1994, p. 66):
• for star- children that are starving
[s-= . s s s s I
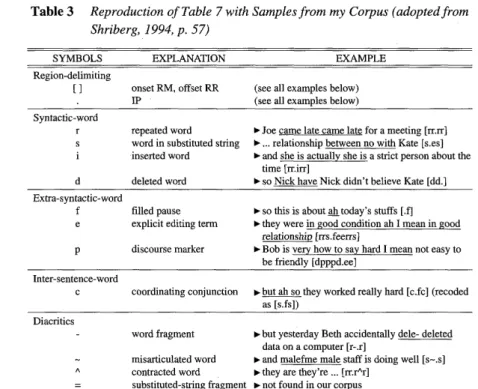
According to Shriberg, the hypothesis here is that the speaker was about to say "starving children" but stopped to rephrase the noun phrase. Table 3 reproduces Table 2 with samples from my corpus. In the next section I describe complex disfluencies, where items of one disfluency component are also part of another. The clarity and the consistency in coding those complex disfluencies were lacking in the past TBLT research as pointed out by Ellis and Barkhuizen (2005).
Complex disfluencies
Shriberg (1994, p. 68) defines complex disfluencies as "cases in which
Table 3 Reproduction of Table 7 with Samples from my Corpus (adopted from Shriberg, 1994, p. 57)
SYMBOLS EXPLANATION
EXAMPLERegion-delimiting
[] onset RM, offset RR IP
(see all examples below) (see all examples below) Syntactic-word
d
repeated word word in substituted string inserted word deleted word
^ Joe came late came late for a meeting [rr.rr]
^ ... relationship between no with Kate [s.es]
^ and she is actually she is a strict person about the time [rr.irr]
^ so Nick have Nick didn't believe Kate [dd.]
Extra-syntactic-word e p
filled pause explicit editing term discourse marker
^ so this is about ah today's stuffs [.f]
^ they were in good condition ah I mean in good relationship [rrs.feerrs]
^ Bob is very how to say hard I mean not easy to be friendly [dpppd.ee]
Inter-sentence-word
coordinating conjunction ^ but ah so they worked really hard [c.fc] (recoded as [s.fs])
Diacritics
word fragment misarticulated word contracted word
substituted-string fragment
^ but yesterday Beth accidentally dele- deleted data on a computer [r-.r]
^ and malefme male staff is doing well [s—.s]
^ they are they're ... [rr.r^r]
^ not found in our corpus
two or more IPs lowing material.
disfluencies ("--"
CODING DISFLUENCY PHENOMENA 119 bound material that correspond to both preceding and fol- Shriberg cites the following example to illustrate complex indicate an IP below):
he -- she -- she went
In the above example, the item between the two IPs (i.e., "she") performs multiple functions: the first "she" is located in the RR and substituting "he";
the same "she" is also located in the RM in the second disfluency component and is repeated by the second "she." The basic assumption here is that rather than conceptualizing the case above as a single disfluency consisting of mul- tiple IPs within it, each IP forms only one disfluency component. Therefore, in the above case, because there are two IPs within complex disfluency, it means that the complex disfluency has two disfluency components. This is a componential view of disfluency. In essence, the above disfluency case is represented as follows:
he she [R[s
she went s].r]
In the above case, there are two sets of square brackets (i.e., inner and
outer ones), each set indicating a single disfluency component. The new
information here is the uppercase letter "R," which is attached to the left of
the inner disfluency component. This "R" refers to the output entity of the
inner disfluency component (i.e., "she"); however, the label "R" represents
the nature of correspondence in wording within the outer disfluency compo-
nent (i.e., repetition). Likewise, if the output of the inner disfluency compo-
nent is involved in the substitution operation within the outer disfluency
component, it is represented by "S."
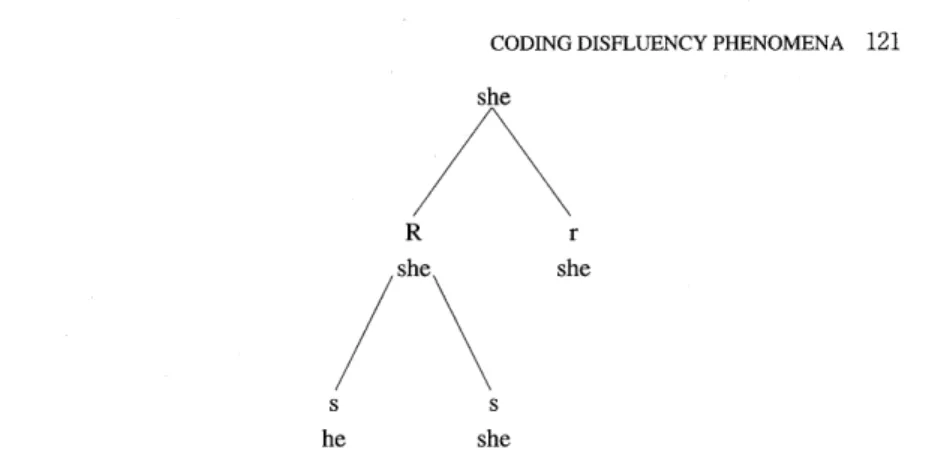
The above-mentioned bracket-based formal representation can also be rep- resented as a hierarchical structure of complex disfluencies as represented in Figure 1:
In this case, the inner brackets correspond to the lower disfluency compo- nent in Figure 1 Each node in this representation corresponds to the output of each disfluency component.
Structures of complex disfluencies
The degree of disfluency overlapping varies and Shriberg distinguishes three structural patterns of complex disfluencies (Shriberg, 1994, pp. 70-72):
completely chained structure; partially chained structure; nested structures.
Completely chained structures Completely chained structures of com- plex disfluencies are identified "[w]hen a lower disfluency is not fully con- tained within an upper one." This is illustrated below ("I---I" indicates the extent of each disfluency component):
Higher component:
Lower component:
he she she
"Completely" here refers to the fact that the items of the output of the lower disfluency are all involved in the higher disfluency component. When items are partially involved in the higher disfluency component, it is said to have a "partially chained structure." In addition, when the lower disfluency component is fully contained within an upper one, it is said to have a "nested structure."
As Shriberg (1994, p. 70) points out, ambiguities in the analysis occur
she
R she
r she
ss heshe
Figure 1. Hierarchical representations of complex disfluencies (from Shriberg, 1994, p. 70).
when chained structures are involved (both completely and partially chained structures); thus, "he she she" can be represented in two ways:
he she she
[R[s. s]. r]
he she she
[s . S[r . r]]
In terms of the hierarchical representation, this ambiguity concerns the
direction of branching (i.e., left- or right-branching; Figure 27 is a left-
branching representation). Shriberg (1994, pp. 70-72) illustrates some prob-
lems of the right-branching analysis and recommends the left-branching
analysis. Following her recommendation, in Ishikawa (2008a, b) whenever I
found chained structures, the left-branching analysis was applied because I
needed to ensure coding consistency as demonstrated below. Here are sam-
ples from my corpus:
Mike Mike couldn't ah Mike couldn't do the presentation well well [ R [ r . r ] r .f r r ]
I we have mm we have some trouble [R[s. s .f r r]
I wanna I just wanted to I wan- I just wanted you to give me some advice [DD-[RDRD[r s .r i s s]. r r- ].]
Partially chained structures Whereas all items of the output of the lower disfluency component are participants of the higher disfluency component in completely chained structures, in partially chained structures, some of the items of the output of the lower disfluency component are not. Shriberg cites the following example to illustrate partially chained structures ("." indicates
the IP below):
Higher component:
Lower component:
show me the flight . the delta flight . delta fare
The point here is that because the extent of the disfluency region is in part
dependent on the extent of retracing of the RR, the higher disfluency compo-
nent does not include the definite article "the" in "the delta flight," which are
the output items of the lower component. This means that this "the" is incor-
porated into the fluent part of the utterance. In other words, it is not the input
of the higher disfluency component (Shriberg, 1994, p. 72). Such an item is
represented by "#":
CODING DISFLUENCY PHENOMENA 123 show me the flight the delta flight delta fare
#[RS[r r . r i r ]. r s]
Nested structures When one disfluency component is fully contained within its higher component, it is said to have a nested structure. The coding
step is the same. First, all IPs and the extents of all the disfluency compo- nents are identified:
the flight . the . the fare I---I I---I
Note that the first IP is for the higher disfluency component only (i.e., "the flight the the fare") not for "the flight the." Therefore, the sample above is
coded as [rs.R[r.r]s].
More complex cases The applications of the coding procedures described above ensure coding consistency. Below is a sample of more com- plex disfluencies:
• but ah once John ah John mm John lost a important ah John didn't send the important email to secretary Cathy before
Because this sample involves a fresh start, only the portion preceding the
resumption (i.e., "John didn't ...") is shown below with the extent of the
whole (i.e., highest) disfluency component with all IPs:
but ah once John . ah John . mm John lost a important . ah
Because the whole disfluency extent contains three IPs, it involves three disfluency components including the highest one. For clarity, filled pauses are deleted and the lower components' extents are also below:
once John . John . John lost a important .
Component A Component B
By visually showing the extent of each disfluency component, it is now
clear that the structure of Components A and B is one of completely chained
structures; therefore, the left-branching procedure should be applied. This
means that the analysis of Component A precedes the analysis of Component
B because the whole or the part of the output of Component A is the input to
the analysis of Component B. The analyses of both components yield
[R[r.r].r]. Finally, the final output of the preceding analyses is reflected in the
analysis of the highest disfluency component. Because of the fresh start, all
items of the highest disfluency components is assigned "d," with the result
being [dD[R[r.r].r]ddd.] (but of course the previously omitted filled pauses
need to be added to the result). In my corpus, three-level disfluencies were
the deepest ones. In Shriberg's system, the identification of the IPs and the
determination of the extents of all disfluency components together with the
appropriate applications of the left-branching procedure ensure the consistent
order of the analyses of disfluency components involved in complex disfluen-
cies.
CODING DISFLUENCY PHENOMENA 125 Type Classification Algorithm (TCA)
Once simple disfluencies are coded, they are automatically classified into eight types based on the Type Classification Algorithm (TCA). As noted pre- viously, in Ishikawa (2008a, b), complex disfluencies are decomposed further into their components, which can also be classified into eight types based on the TCA. Type specification is carried out based on the types of symbols (but not their frequencies) each disfluency component contains within it. Symbols are specified in terms of: (1) must symbols; (2) must-not symbols; (3) option- al symbols. Table 4 is a reproduction of Table 2 with samples from my cor- pus.
Word-deletion procedures
After the disfluency type is identified, word deletion procedures were applied in order to restore the speaker's hypothetical intended fluent utter- ance. The rule is simple given that the annotation procedures are complete.
Thus, I deleted all the items in the RM and the IM. Also deleted were editing phrases annotated with the symbol "e." Shriberg (1994) leaves to the researcher the decision whether discourse markers are deleted or not. In Ishikawa (2008a, b), discourse markers annotated with the symbol "p" were also deleted. In addition, when pruned words results were counted (see subse- quent section), I also deleted words that were caused by coughing and laugh- ing although they were not included in the disfluency analyses.
The number of words was counted as follows. Contracted words were counted as single words. Word fragments were counted as a 0.5 word.
Unfilled pauses (see Clark & Fox Tree, 2002) were also counted as lexical items, but serial filled pauses were counted as one words as described previ- ously. With respect to the use of Japanese words, they were counted in the
same way English words were treated although their occurrences were rare in
Table 4 Reproduction of Table 8 with Samples from my Corpus
TYPE
MUST
INCLUDE
MUST NOT INCLUDE
MAY INCLUDE
EXAMPLE
ART -
sidrcf • this is nam Minami calling [r--.r]
• secretary pa- Cathy [r--.r]
HYB 2+ from: s i d - rcf
(example of s + i)
• Ann did not have relationships good relationship with Bob [s.is]
SUB s -id rcf
• till Joe come came to the meeting [s.s]
• Mike was confusing confused about the next presentation [s.s]
•Joe was working with secretary Ann ah af- before trouble [s-.s]
INS - sd rcf
• and she is actually she is a strict person about the time [rr.irr]
• Beth showed up later for the meeting the important meeting [rr.rir]
DEL d s rcf
^ so th- he can figure out what is going on [d-.]
^ and Kate and John s- ah ok I have to report the relationships between Kate John ah Nick and Cathy [cdddd-.f]
•but he but because of his lost of important document [cd.]
REP r -sid cf
• Joe came late came late for a meeting [rr.rr]
• so because of ah because of the Beth's showing up later for the meeting [rr.frr]
CON c -sidr
•but ah so they worked really hard [c.fc] (recodable as
[s.fs], hence, SUB)
• and and Joe is the section chief [c.c] (recodable as [r.r] hence REP)
FP f