分散確率モ デ ル遺伝的アルゴ リ ズム
廣 安 知 之
†三 木 光 範
†下 坂 久 司
††佐 野 正 樹
††,☆筒 井 茂 義
†††本論文で は , 新し い 確率モ デ ルGA(PMBGA) で あ る , 分散確率モ デ ル遺伝的アルゴ リ ズム (DPM- BGA) を提案す る .DPMBGAで は , 主成分分析( PCA) に よ り , 設計変数の 相関を考慮し て 子個 体を生成す る . ま た, 島モ デ ルの 採用に よ り , 多様性の 維持を図っ て い る . テ スト 関数を用い た数値 実験に よ り , DPMBGAの 有効性を検証し た. 複数の モ デ ルを検討し た結果 , 全体の 半数の 島で の みPCAを行う DPMBGAは , 対象問題に お け る 設計変数間の 依存関係の 有無に か か わ らず , 良好 な 性能を示し た. 解 探索性能は , 単峰性正規 分布交叉を用い たMinimal Generation Gapモ デ ルと 比較 し て DPMBGAが よ り 優れ た性能を示し た. ま た, DPMBGAに Boundary Extension by Mirroring(BEM) を適用し たモ デ ルを用い て , 探索領域の 境界 の 取り 扱い に つ い て も 検討し て い る .
Distributed Probabilistic Model-Building Genetic Algorithm
Tomoyuki HIROYASU
†,Mitsunori MIKI
†,Hisashi SHIMOSAKA
††,Masaki SANO
††,☆and Shigeyoshi TSUTSUI
†††In this paper, a new model of Probabilistic Model-Building Genetic Algorithms(PMBGAs), Distributed PMBGA (DPMBGA), is proposed. In the DPMBGA, the correlation among the design variables is considered by Principal Component Analysis(PCA) when the offsprings are generated. The island model is also applied in the DPMBGA for maintaining the population diversity. Through the standard test functions, the effectiveness of the DPMBGA is exam- ined. In this paper, some models of DPMBGA are examined. The DPMBGA where PCA is executed in the half of the islands and not executed in the other islands can find the good solutions in the problems whether or not the problems have the correlation among the design variables. From these results, it is clarified that the DPMBGA has higher searching ability than the Unimodal Normal Distribution Crossover with Minimal Generation Gap. It is also discussed the treatment of the boundary condition of the design field using the Boundary Extension by Mirroring (BEM).
1. は じ め に
遺伝的アルゴ リ ズム ( Genetic Algorithm : GA ) は , 生物の 進化 と 自然淘汰を工学的に 模倣し た最適化 アルゴ リ ズム で あ る
1). 遺伝的アルゴ リ ズム で は , 探 索空間上の 探索点を生物の 個体と みな す . 個体の 母集 団( population ) に 対し て , 選択( selection ) , 交叉
( crossover ) , 突然変異( mutation ) , と い う 遺伝的
†同志社大学工学部
Department of Knowledge Engineering and Computer Sciences, Doshisha University
††同志社大学大学院
Graduate School of Engineering, Doshisha University
☆ 現在,IBM Japan, Ltd.
†††阪南大学経営情報学部
Department of Management Information, Hannan Uni- versity
操作( genetic operator ) を繰り 返し 適用す る . こ れ らの 操作の 中で , 効率良く 探索を行う ため に は , 交叉 に お い て 親の 持つ 良質な 形質を子が 受け 継ぐ こ と が 一 つ の 方法で あ る . こ れ を行う 新し い アプロ ー チ と し て , 母集団内の 良好な 個体の 統計情報を用い て 新し い 個 体を生成す る 手法が 挙げ られ る . こ れ らの 手法は , 確 率モ デ ル遺伝的アルゴ リ ズム ( Probabilistic Model- Building Genetic Algorithm : PMBGA )
2)も し く は Estimation of Distribution Algorithm (EDA)
3)と 呼ば れ , 多く の 研究が な さ れ て い る .
本研究で は , 連続関数最適化 に 注目す る . 連続関数
の 最適化 に お い て は , 目的関数に お い て , 設計変数間
に 依存関係が あ る 場合, 良好な 解 を得る ため に は , 依
存関係を考慮し て 探索点を生成す る こ と が 良好な 探
索に つ な が る . 設計変数値をそ の ま ま 個体の 染色体と
し て 用い る 実数値 GA ( Real-Coded GA ) で は , こ
の 点に 留意し た交叉法の 研究が な さ れ て い る . 代表 的な も の に , 小野らに よ っ て 考案さ れ た単峰性正規 分 布交叉( Unimodal Normal Distribution Crossover : UNDX )
4)が あ る . UNDX で は , 子個体の 設計変数 が 2 つ の 親個体が 形成す る 主軸付近に , 正規 分布に 従っ て 決定さ れ る . UNDX は , 設計変数間に 依存関 係を有す る 問題に 対し て 良好な 解 を得る こ と が で き る . し か し , UNDX に よ っ て 発生し た子個体は 多様性を 欠く . こ れ に 対し , 高橋らに よ り , 独立成分分析を用 い た実数値交叉
5)が 提案さ れ て い る . こ の 手法で は , 主成分分析と 独立成分分析で 座標系を変換し た後に , Eshelman らに よ る ブ レン ド 交叉( Blend Crossover : BLX- α ) を適用す る . 多様性の 維持に 優れ る BLX- α を, 個体分布を変換し て か ら適用す る こ と で , 依存 関係の 考慮と 多様な 解 の 生成と の 両方を図っ て い る . ま た, GA と 類似し た進化 計算手法に , 進化 戦略
6)が あ る . Schwefel に よ っ て 提案さ れ た correlated mu- tation で は , 個体の 分布の 方向を示す パ ラ メ ー タ が 採 用さ れ て お り , 設計変数間の 依存関係を考慮し た突然 変異を行う .
一方, 連続関数最適化 に お い て 設計変数間の 依存を 考慮し た PMBGA は 少な い . そ こ で , 本論文で は , 連 続関数最適化 に 対す る 新し い PMBGA の モ デ ルで あ る , 分散確率モ デ ル遺伝的アルゴ リ ズム ( Distributed PMBGA : DPMBGA ) を提案す る . DPMBGA で は , 主成分分析( Principal Component Analysis : PCA ) に よ っ て 親個体の 分布を変換す る こ と に よ り , 設計変 数間の 依存関係を考慮し て 子個体を生成す る . 先に 述 べ た, 進化 戦略に お け る correlated mutation
6)で は , 設計変数間の 相関の 情報を各 個体が 保持す る . そ し て , 突然変異や 組み替え に よ っ て , 確率的に そ の 適切な 値 を探索す る . こ れ に 対し , DPMBGA で は , 良好な 個 体を蓄積し たアー カ イブ に PCA を適用し , 相関の 情 報を算出す る . ま た, DPMBGA で は , 個体の 母集団 を複数の サ ブ 母集団に 分割 す る こ と で , 多様性の 維持 を図っ て い る . DPMBGA の 利点と し て , PCA 変換 を行う 集団を別に 採用す る こ と で , よ り 設計変数間の 依存情報を個体生成の 際に 反映す る こ と が 可 能と な る こ と , 個体生成の 際に 確率モ デ ルを利用す る こ と で , よ り 親の 形質を子に 伝え る こ と が 可 能と な る こ と な ど が 挙げ られ る .
本論文の 構成は , 以下 の と お り で あ る . 2 節と 3 節 に お い て , 提案モ デ ルの ベ ー スと な っ て い る PMBGA と 分散遺伝的アルゴ リ ズム に つ い て 説明す る . 4 節 で , 提案モ デ ルで あ る DPMBGA に つ い て 説明す る . 5 節に お い て , 数値実験を通じ て 提案モ デ ルの 特性お
! #"$"%'&"(*)+#,.-!$
/'
012
3
4 56*371
8
1093#6:56;
<#=>?@+A'>?B!C+BED
F!?=>G?H'IE>?B!C J.K.$ L&"M
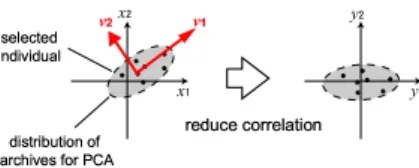
図1 確率モ デ ル遺伝的アルゴ リ ズム Fig. 1 Probabilistic Model-Building GA
よ び 有効性に つ い て 検討す る .
2. 確率モ デ ル遺伝的アルゴ リ ズム
PMBGA で は , GA と 同様に ラ ン ダ ム に 生成さ れ た 個体群の 中か ら, 良好な 解 が 選択さ れ る . 選ば れ た個 体の 確率分布が 推定さ れ , 確率モ デ ルが 構築さ れ る . 構築し た確率モ デ ルに 従い , 新し い 探索点が 生成さ れ る . こ う し て 生成さ れ た新し い 探索点は 母集団内の 個 体と 置き 換え られ る . こ れ を終了条件を満たす ま で 繰 り 返す . 図 1 は こ の 流れ を模式的に 表し たも の で あ る . し たが っ て , PMBGA は , GA に お け る 交叉に よ る 子個体の 生成を, 良好な 個体の 確率モ デ ルの 構築 と , 構築し たモ デ ルに よ る 新し い 探索点の 生成と に 置 き 換え たも の で あ る と 考え る こ と が で き る .
3. 分散遺伝的アルゴ リ ズム
GA は , 多点探索で あ り , 評価 計算を反復し て 行う ため , 計算コスト が 高い と い う 問題点が あ る . こ の た め , GA の 並列モ デ ルに つ い て は , 多く の 研究が な さ れ て き た
7).
GA の 並列モ デ ルの 1 つ に , Tanese に よ っ て 提案 さ れ た, 分散遺伝的アルゴ リ ズム ( Distributed GA : DGA ) が あ る
8). こ の モ デ ルで は , 個体の 母集団 を複数の サ ブ 母集団( 島) に 分割 し , 島ご と に 遺伝的 操作を適用す る . DGA は 島モ デ ルと も 呼ば れ る . ま た, 一定世代ご と に 他の 島と 個体を交換す る . こ の 個 体の 交換を移住 (migration) と い い , 移住を行う 間隔 と 移住を行う 個体数の 割 合を, そ れ ぞ れ 移住間隔 , 移 住率と い う . DGA は 通常の 単一母集団モ デ ルと 比較 し て , よ り 適合度の 高い 解 を発見す る こ と が 報告さ れ て い る
8). 本研究で は , DGA を解 の 多様性を維持す る メ カ ニ ズム と し て 利用し て い る .
4. 分散確率モ デ ル遺伝的アルゴ リ ズム
本研究で は , 新し い PMBGA の モ デ ルで あ る 分散
確率モ デ ル遺伝的アルゴ リ ズム ( Distributed Proba-
bilistic Model-Building Genetic Algorithm : DPM-
BGA ) を提案す る . DPMBGA で は , DGA と 同様
!"#%$&
')(
'* +)(
x*
y( y* v( v*
,-
図2 分散確率モ デ ル遺伝的アルゴ リ ズム Fig. 2 DPMBGA
に 母集団を複数の 島に 分割 し , 島ご と に PMBGA を 実行す る . 母集団の 分割 に よ り , 多様性が 維持さ れ , 複雑な 問題に お い て も 局所解 に 陥る こ と な く 探索を行 う こ と が 期待さ れ る . ま た, 確率分布の モ デ ル構築の 際に , 主成分分析( PCA ) に よ っ て 個体群の 分布を変 換す る . こ れ に よ り , 設計変数間の 依存関係を考慮し て 子個体を生成す る こ と が で き る .
4.1 DPMBGA の 概 要
DPMBGA で は , 母集団内の 全個体を複数の 島に 分割 す る . 各 島内に お い て PMBGA を行い , 一定世 代ご と に , 島間で 個体の 交換( 移住) を行う . 本論文 で 採用す る ト ポ ロ ジ は , 移住の たび に , 全て の 島が 無 作為な 順番の 1 つ の リ ン グを形成し , 隣の 島が 移住先 と な る も の で あ る . 移住個体の 決定法は , 島内か らラ ン ダ ム に 選出さ れ た個体を送り 出し て 最悪 個体と 入れ 替え る 方法で あ る .
DPMBGA で は , 次の 手順を各 世代 t に お い て 実 行す る ( 図 2 ) .
1. エ リ ー ト の 保存 2. 良好な 個体の 抽出
3. PCA を用い て , 良好な 個体群の 設計変数を無相 関化
4. 新し い 個体の 生成
5. 設計変数の 相関の 復元と 島内の 個体の 置き 換え 6. 突然変異
7. 制約条件外 の 個体を, 実行可 能領域の 境界 上に 引き 戻し
8. エ リ ー ト の 復帰 9. 個体の 適合度を評価
以降で は , そ れ ぞ れ の 操作に つ い て 説明す る . 4.2 良好な 個体の 抽出
各 島 P
sub(t) か ら, 良好な 個体を, 抽出率 R
sで 定 め られ た割 合だ け 選択し , サ ン プル個体 S(t) と し て 抽出す る . S(t) は 島ご と に 存在す る . 新し い 子個体は
./01
.2/31 .2/41 5678/01
5678/31
GH@ 52I
?
5678/4 1 JF=
F@
<K
DH=0
JF=
F@
<K
DH=-4
JF=
F@
<K
DH=L3
図3 PCAへの 過 去の 最良個体群の 利用 Fig. 3 PCA with the archive of the best individuals
こ れ らの 情報を基に 生成さ れ る . 適合度の 高い 順番 に 個体を選択す る が , 同じ 設計変数値を持つ 個体は 重 複し て 選択し な い . こ の こ と は , 抽出さ れ る 個体数が 少な い こ と に 起 因す る . DPMBGA で は 多く の サ ブ 母 集団を用い て 探索を行う ため , 一島あ たり の 母集団サ イズは 必然的に 小さ く な る . そ の ため , 重複個体を選 択す る こ と は , 確率分布を推定す る ため の 情報量が 大 き く 減少す る こ と を意味す る . 重複個体を除い たと き に 島内に 個体が 不足す る 場合に は , ラ ン ダ ム に 個体を 生成し て S(t) に 追加 す る . 追加 す る 個体の 設計変数 値は , 定義域内の 一様乱数に よ っ て 設定す る .
4.3 PCA を用い た, 良好な 個体群の 設計変数の 無相関化
S(t) は PCA に よ り デ ー タ 変換さ れ る . PCA に 利 用す る サ ン プル個体は S(t) と は 別に 用意す る . 現在の 世代ま で に 島内に 出現し た最良個体群を, PCA の 対 象と す る 個体群 T (t) と す る ( 図 3 ) . 以降, こ の T (t) をアー カ イブ と 呼ぶ . アー カ イブ の 更新は 毎世代行わ れ る . アー カ イブ に は 常に 適合度の 高い 順に 個体が 格 納さ れ る ため , 各 世代に 更新さ れ る 個体数は 探索の 状 況に よ っ て 異な る . 現世代ま で に 島内に 出現し た個体 の 数が T (t) の サ イズに 満たな い 場合, 新し い 個体を 追加 せ ず に そ の ま ま 処理を続行す る . T (t) の サ イズを 超え た場合に は , 適合度の 低い 個体か ら順に 削除す る . 島内の 個体数に か か わ らず , 任意の 数の 個体を PCA に 用い る こ と が で き る . こ れ らの アー カ イブ は 島ご と に 存在す る も の と す る .
アー カ イブ に 格 納さ れ て い る 個体数を N
Tと し , T (t) の 各 設計変数( D 個) か ら T (t) の 平均値を引い たも の を, 行列
M( N
T行 × D 列) と す る . サ ン プル個 体数を N
Sと し , 抽出し た S (t) の 各 設計変数( D 個)
か ら T (t) の 平均値を引い たも の を, 行列
N( N
S行
× D 列) と す る .
次に ,
Mの 共分散行列
O( D 行 × D 列) を求め ,
そ の 固有値と 固有ベ クト ルを算出す る .
Oは , 実数値
x x
y v y
v
!
"#%$&%'( *)*+,
'-'#'
%&
"-
図4 座標変換に よ る , 設計変数値の 無相関化
Fig. 4 Reduction operation of correlation between design variables with PCA
対称行列と な り , 次式で 求ま る .
O
= 1
N
T− 1
MT
M
(1)
O
の 固有値は 大き い 順に λ
1, λ
2, . . . , λ
Dと し , 対応す る 固有ベ クト ルを
. 1,
. 2, . . . ,
.0/( D 次元) と す る . 最も 大き い 固有値は , 設計変数の 分散が 最大と な る よ う に 座標軸をと っ たと き の 分散値に 等し い . 固有ベ ク ト ルは , そ の 座標軸自身を示す .
求め た固有ベ クト ルを用い て , 抽出し た個体群 S(t) の 設計変数
Nを無相関化 す る . 固有ベ クト ルを並べ て , 座標軸変換の ため の 行列
1= [
. 1,
. 2, . . . ,
. /] を作成す る .
Nに 対し て 座標軸変換行列
1をか け た 行列を,
2と お く .
2( N
S行 × D 列) は , 無相関 化 さ れ た設計変数を示す .
2の 座標軸は , 固有ベ ク ト ルに 等し い .
4.4 新し い 個体群の 生成
新し い 子個体を島内の 個体数と 同じ 数( N
P) だ け 発 生さ せ る .
2の 分布に 従い , 正規 乱数 に よ っ て , 各 設計変数を独立に 決定す る . す な わ ち, 設計変数が n の 場合に は , n 個の 正規 分布を用意す る . 正規 乱数の 分散は ,
2に お け る 各 設計変数( 各 列) の 分散に 倍率 Amp をか け たも の で あ る . ま た, そ の 平均は ,
2に お け る 各 設計変数の 平均に 等し い . 発生さ せ た個体の 設計変数は ,
2 of f s( N
P行 × D 列) に 格 納す る .
4.5 設計変数の 相関の 復元と 島内の 個体の 置き 換え
2 of f s
に
1の 逆行列をか け , 座標軸を元に 戻す .
N of f s
=
2 of f s·
1
−1
(2)
N of f s
の 平均値を元に 戻し , 島内の 個体 P (t) と 入 れ 替え て P (t + 1) と す る .
4.6 突 然 変 異
あ らか じ め 定め た突然変異率 R
muに し たが っ て , 設計変数を, 制約条件内の 無作為な 値に 変更す る .
4.7 エ リ ー ト の 保存と 復帰
あ らか じ め 定め た数( N
E) の エ リ ー ト を E(t) と し て 保存す る . 確率モ デ ルに よ る 個体の 生成の 後, エ リ ー ト を母集団に 戻す E(t) を, 島内の 個体群 P (t+1) の 劣悪 な 個体と 置き 換え る .
4.8 特 徴
DPMBGA の 特徴は 以下 の と お り で あ る .
• 実数値確率モ デ ル GA で あ る .
• 島モ デ ルに よ り , 多様性の 維持を図っ て い る .
• 主成分分析( PCA ) を用い , 1 次の 設計変数間の 依存関係を考慮し て 子個体を生成す る .
• 最良個体を蓄積し たアー カ イブ を用い る こ と で , 島内の 個体数に か か わ らず , 任意の 数の 個体を PCA の 適用対象と す る こ と が で き る .
• 確率分布に 正規 分布を採用し て い る .
DPMBGA で は , 新し い 個体は , 良好な 個体の 分布 を基に , 正規 分布に よ っ て 生成さ れ る . こ の ため , 現 在の 世代の 良好な 個体付近に 収束す る 傾向が 強く , 早 期収束が 発生し や す い モ デ ルで あ る と い え る . そ こ で , 母集団を複数の 島に 分割 す る 島モ デ ルを採用し て い る . 母集団の 分割 に よ り , 多様性が 維持さ れ , 複雑な 問題 に 対し て も , 局所解 へ陥る こ と な く 探索が 行わ れ る こ と が 期待さ れ る .
5. 数 値 実 験
5.1 対 象 問 題
本論文で 対象と す る テ スト 関数は , 以下 に 示す Ras- trigin 関数, Schwefel 関数 , Rosenbrock 関数, Ridge 関数, Griewank 関数の 5 つ で あ る . い ず れ も 最小化 問題で あ り , 大域的最適値は 0 で あ る . Schwefel 関数 は 10 次元の も の を, そ れ 以外 の 関数は 20 次元の も の を用い る .
Rastrigin 関数と Schwefel 関数は , 設計変数間に 依 存関係の 無い 多峰性の 関数で あ る . Rosenbrock 関数 と Ridge 関数は , 設計変数間に 依存関係の あ る 単峰 性の 関数で あ る . Griewank 関数は , 設計変数間に 依 存関係の あ る 多峰性の 関数で あ る .
FRastrigin= 10n+
n
X
i=1
x2i−10 cos(2πxi)
(3) (−5.12≤xi<5.12) FSchwef el=
n
X
i=1
−xisin
p
|xi|
−C (4)
(C:optimum.) (−512≤xi<512) FRosenbrock=
n
X
i=2
100(x1−x2i)2+ (1−xi)2
(5) (−2.048≤xi<2.048)
表1 パ ラ メ ー タ Table 1 Parameters
Population size 512
Number of elites 1
Number of islands 32
Migration rate 0.0625
Migration interval 5
Archive size for PCA 100
Sampling rate 0.25
Amp. of Variance 2
Mutation rate 0.1/ (Dim. of function)
FRidge=
n
X
i=1
X
ij=1
xj
2(6) (−64≤xi<64)
FGriewank= 1 +
n
X
i=1
x2i 4000−
n
Y
i=1
cos xi
√i
(7)
(−512≤xi<512)
5.2 主成分分析の 効果 と 環境分散スキー ム の 検討 DPMBGA で は , 主成分分析( PCA ) を用い て 個 体群の 分布を変換す る こ と で , 設計変数間の 依存関係 を考慮し て 新し い 個体を生成す る . 設計変数間に 依存 関係を有す る 問題で は , PCA を用い て 設計変数の 分 布を無相関化 す る こ と に よ り , 親個体の 分布が 持つ 性 質を保存し て 子個体を生成す る こ と が で き る . よ っ て , こ の よ う な 問題に 対し て , DPMBGA が 良好な 性能 を示す こ と が 期待さ れ る .
本節で は , DPMBGA に お け る PCA の 効果 に つ い て , 数値実験を通じ て 検討す る . 数値実験で 用い る パ ラ メ ー タ は , 表 1 の と お り で あ る .
数値実験で は , 次に 示す モ デ ルに つ い て 比較 を行う . model 1 : 全て の 島に お い て PCA を行う . model 2 : 全て の 島に お い て PCA を行わ な い . model 3 : 全体の 半分の 島に お い て PCA を行う .
そ れ 以外 の 島で は 行わ な い .
各 モ デ ルは , PCA を行う 島の 数が 異な る . model 1 は , 4 節で 述べ たアルゴ リ ズム と 同様の も の で あ る . model 2 は PCA を全く 行わ な い モ デ ルで あ る . model 3 は PCA の 使用に 関し て , 環境分散スキー ム を採用 し て い る .
環境分散スキー ム を用い た GA ( Distributed Envi- ronment GA : DEGA ) は , 三木らに よ っ て 提案さ れ た DGA の モ デ ルで あ る
9). DEGA で は , 各 島が 異 な る パ ラ メ ー タ で 遺伝的操作を行う . GA の 解 探索に お け る 最適な パ ラ メ ー タ は 対象問題に 依存し , 未知で あ る . そ こ で , DGA に お い て 各 島に 異な る パ ラ メ ー
表2 20試行中で 最適値に 到達し た回 数
Table 2 Number of times that the threshold is obtained model 1 model 2 model 3
Rastrigin 0 20 20
Schwefel 20 20 20
Rosenbrock 20 0 20
Ridge 20 20 20
Griewank 19 17 20
!
"#"
$#"%&'"(
&#"%&'")
&#$%&'")
*#"%&'")
*#$%&'")
+,- ./01 2 345 6,5
7819 :
;<
:
;'=
:
;>
図5 最適値に 到達す る ま で の 関数評価 回 数の 平均 Fig. 5 Average number of evaluations to reach the
threshold
タ を設定し , ど の よ う な 問題に 対し て も 安定し た解 探 索性能を実現す る こ と を目的と し たモ デ ルが DEGA で あ る .
本検討で は , 関数評価 値が 1.0× 10
−10以下 の と き , 最適値に 到達し たと みな す . 探索の 終了条件を関数評 価 3.0 × 10
6回 と し , 20 試行中で 最適値に 到達し た回 数を 表 2 に 示す . 高い 割 合で 最適値に 到達し て い る モ デ ルほど , 安定し た解 探索を行っ て い る と い え る . ま た, 最適値に 到達し た試行に お け る 関数評価 回 数の 平均を, 図 5 に 示す . よ り 少な い 関数評価 回 数で 最 適値に 到達す る モ デ ルほど , 性能が 高い と い え る .
Schwefel 関数で は , ど の モ デ ルも , 全て の 試行に お い て 少な い 評価 回 数で 最適値に 到達し て い る . Ras- trigin 関数で は , model 1 の 性能が 悪 い . す な わ ち,
PCA が 探索性能を悪 化 さ せ て い る . 設計変数間に 依 存関係の あ る Rosenbrock 関数で は , PCA を行わ な い model 2 が 最適値に 到達し て い な い . 同じ く 依存 関係の あ る Ridge 関数で は , model 2 は 高い 割 合で 最適値に 到達し て い る が , 多く の 関数評価 を必要と し て い る . よ っ て , こ れ ら関数に 対し て は , PCA が 効 率よ く 機能し て い る と 考え られ る . 以上の 結果 よ り , PCA に よ る 設計変数の 無相関化 は , 設計変数間に 依 存関係の あ る 単峰性の 問題に は 有効に 機能す る が , 依 存関係の 無い 多峰性の 問題に 対し て は 十分な 性能を実 現で き な い 場合が あ る と い え る .
一方, PCA を行う 島と 行わ な い 島と の 両方を有す
る model 3 は , ど の 関数に 対し て も 優れ た性能を示し
て い る . Griewank 関数は , 設計変数間に 依存関係が あ り , 多数の 局所解 を持つ 多峰性の 関数で あ る . こ の ため , 局所解 に 陥る 可 能性が 高く , model 1 と model 2 と の 両方に お い て , 最適値に 到達し な い 試行が 存在 す る . こ れ に 対し , model 3 は , 全て の 試行に お い て 最適値に 到達し て い る . こ の 結果 よ り , model 3 は , 設計変数の 依存関係の 有無に 関わ らず 良好な 解 を発見 し , 多数の 局所解 を持つ 問題に 対し て も 安定し た性能 を示し て い る と い え る .
5.3 主成分分析が 有効に 機能し な い 原因に つ い て の 検討
5.2 節の 数値実験に お い て , Rastrigin 関数に 対し て は , PCA の 実行が 探索性能を悪 化 さ せ る こ と が 明 らか と な っ た. PCA が 有効に 機能し な い 原因と し て , 以下 の こ と が 考え られ る . DPMBGA で は , PCA が 最良個体の アー カ イブ に 対し て 適用さ れ る ため , 望ま し い 探索性能を得る ため に は , アー カ イブ の 個体分布 が 対象問題の 特性を正確に 反映し たも の で あ る 必要 が あ る . し か し , 局所解 を多く 持つ Rastrigin 関数に お い て は , 多く の 個体が 局所解 に 陥り , アー カ イブ が 更新さ れ に く く な る 可 能性が あ る . こ の よ う な 場合に は , アー カ イブ に 最新の 探索結果 が 反映さ れ な く な り , PCA に よ っ て 適切な 個体分布の 変換が 行わ れ な い と 考え られ る .
上記 の 点に つ い て , 数値実験を通じ て 検討す る . 数 値実験で 用い る パ ラ メ ー タ は , 表 1 の 通り で あ る . 検 討対象と す る DPMBGA の モ デ ルは , 5.2 節の model 1 ( 全て の 島で PCA を行う モ デ ル) で あ る . 対象問 題は , Rastrigin 関数と Rosenbrock 関数で あ る .
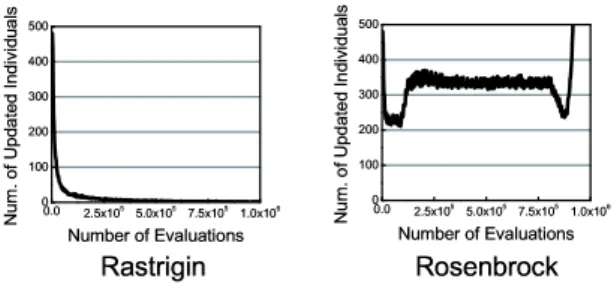
図 6 に , アー カ イブ の 更新の 履歴を示す . 横軸は 目 的関数の 評価 回 数で あ る . 縦軸は 更新さ れ た個体数の 20 試行平均で あ る . こ の 値が 大き い ほど , そ の 世代の 多く の 個体が アー カ イブ に 導入さ れ たこ と を示す . 同 図よ り , Rastrigin 関数で は , 探索が 進むと アー カ イ ブ の 更新が き わ め て 少な く な る . 一方, Rosenbrock 関数で は , つ ね に アー カ イブ 内の 多く の 個体が 更新さ れ て い る こ と が わ か る .
図 7 に , 解 の 履歴を示す . 横軸は 目的関数の 評価 回 数で あ る . 縦軸は 関数評価 値の 20 試行平均で あ る . 最小化 問題で あ る ため , 目的関数値が 小さ い ほど , 良 い 解 を得て い る こ と に な る . 図中の normal は 通常の モ デ ルで あ り , erase/10 は , 10 世代ご と に アー カ イ ブ 内の 個体を全て 消去す る モ デ ルで あ る . 同図よ り , アー カ イブ を 10 世代ご と に 消去す る と , Rastrigin 関 数で は 探索性能が 向上し , 逆に , Rosenbrock 関数で は 解 探索の 効率が 悪 化 す る . こ の こ と は , Rastrigin
!
"$#&%('*),+.-*/10.2*3.4#*3657-.869
:<;>=@?BA(C>DE;>FHG IJIK
JLMNIOLJIMNIOPJLMNIOQNJIMNIR
I
NII KII SII TII LII
UVWX
Y
Z [\ ]^ _` ]ab ]cd c]V^
ef
g$h&i(j*k,l.m*n1o.p*q.rh*q6stmvu6w
xzyH{}|~6
図6 最良個体アー カ イブ に お け る 更新さ れ た個体数の 履歴 Fig. 6 History of number of updated individuals in
archive of the best individuals
v,, ¢¡1£,¤1¥,¤&¦§¨&©
ª*«.¬¯®,°
±.¬®&²6±6³´µ
¶z·(¸}¹º»¼»½
¾¿¾ À
¿ÁÂÃ¾Ä Á¿¾ÂþÄ
¾Á
þ ÃÁ À¾
ÅÆ
Ç
ÈÉ
Ç
Ê
ËÌÍ ÎÇ ÈÉ
Ï
ÐÑvÒÓ,ÔÕÖ&×ÙØ1Ú,ÛÜÑ,Û&ÝÞÖß&à á*â.ãä¯å,æ
ç.ãå*è*ç6éêë
ìîí>ïðBñ>ò>óôíõ¯ö
図7 10世代ご と に アー カ イブ を消去す る モ デ ルに お け る 解 の 履歴 Fig. 7 History of averave of evaluation values in the model
in which archive is erased each 10 generation
関数に お い て , アー カ イブ が 有効に 機能し て い な い こ と を示し て い る .
以上の 結果 よ り , Rastrigin 関数に お い て PCA が 探索性能を悪 化 さ せ る 原因の 1 つ は , アー カ イブ の 更 新の 停滞で あ る と い え る . 更新の 停滞は , アー カ イブ 内の 個体が 局所解 を含む峰に 陥る こ と に 起 因す る と 推 測さ れ る . 先に 述べ たと お り , アー カ イブ を用い る と , 実際の 個体数が 少な い 場合で も , 多く の 個体を PCA の 対象と す る こ と が で き る と い う 利点が あ る . し か し , 本節の 実験に よ り , 設計変数間に 依存関係の 無い 多峰 性の 関数に お い て は , アー カ イブ の 使用が 探索性能を 低下 さ せ る こ と も あ る こ と が 明らか と な っ た.
5.4 アー カ イブ サ イズの 検討
DPMBGA で は , 現在の 世代ま で に 島内に 出現し た 最良個体群を PCA の 対象と す る アー カ イブ と し て 格 納す る . アー カ イブ に PCA を適用し て 得られ る 情報 は , サ ン プル個体群の 設計変数を無相関化 す る ため の 座標軸変換行列で あ る . こ の ため , アー カ イブ サ イズ は , PCA に よ っ て 得られ る 座標軸変換行列の 精度に 大き く 関係す る パ ラ メ ー タ で あ る と 考え られ る .
本節の 数値実験で は , アー カ イブ サ イズが 解 探索性 能に 与え る 影響を検討す る . 数値実験で 用い たパ ラ メ ー タ は 表 1 と 同様で あ る . ただ し , アー カ イブ サ イズを 5 , 20 , 50 , 100 , 500 の 5 通り に 変化 さ せ た.
対象と す る 問題は , 20 次元の Rastrigin 関数お よ び
表3 20試行中で 最適値に 到達し た回 数
Table 3 Number of times that the threshold is reached
Rastrigin Rosenbrock
Size model 1 model 3 model 1 model 3
5 2 20 0 0
20 0 20 18 20
50 0 20 20 20
100 0 20 20 20
500 0 20 20 20
Rosenbrock 関数で あ る . 検討対象と す る DPMBGA の モ デ ルは , 5.2 節の model1( 全て の 島で PCA を行 う モ デ ル ) と model3( 環境分散スキー ム ) で あ る . 探 索の 終了条件を関数評価 3.0 × 10
6回 と し , 20 試行中 で 最適値に 到達し た回 数を示す . 結果 を表 3 に 示す . 表 3 よ り , アー カ イブ サ イズが 50 以上の 場合, 5.2 節の 結果 と 同様に , Rastrigin 関数で は model3 が , Rosenbrock 関数で は model1 と model3 が 安定し た 解 探索性能を示し て い る . し か し な が ら, アー カ イブ サ イズが 50 よ り 小さ い 場合, 5.2 節の 結果 と は 異な る 傾 向を示す . ま ず , Rosenbrock 関数に お い て は , model1 と model3 の 両方で 最適解 発見率が 0/20 と な っ た. ま た, Rastrigin 関数の model1 に お い て , アー カ イブ サ イズが 5 の 場合, 最適解 発見率は 2/20 と な っ た.
5.2 節の 結果 と 照らし あ わ せ る と , アー カ イブ サ イズ が 小さ い 場合, model2( 全て の 島で PCA を行わ な い モ デ ル ) と 類似す る 傾向を示す こ と が わ か っ た. ま た,
20 次元の 問題を対象と し た場合, 5.2 節の 実験で 用い たアー カ イブ サ イズ 100 は , PCA が 有効に 機能す る ため の 十分な サ イズと い え る .
5.5 UNDX を用い た MGG モ デ ルと の 比較 本節で は , DPMBGA と 既存の 実数値 GA と の 比 較 を行う . 比較 対象は , 単峰性正規 分布交叉を用い た MGG モ デ ルで あ る .
単峰性正規 分布交叉( Unimodal Normal Distribu- tion Crossover : UNDX ) は , 小野らに よ っ て 考案さ れ た, 実数値 GA の 代表的な 交叉法で あ る
4). UNDX で は , 3 つ の 親個体か ら 2 つ の 子個体が 生成さ れ る . 子個体の 設計変数は , 第 1 , 第 2 の 親個体が 形成す る 主軸付近に , 正規 分布に 従っ て 決定さ れ る . 第 3 の 親 は , 主軸以外 の 成分の 決定に 用い られ る . UNDX で は , 対象問題に お け る 設計変数間の 依存関係に 沿 っ て 子個体を生成す る こ と が で き る .
ま た, Minimal Generation Gap ( MGG ) は 佐藤ら に よ っ て 考案さ れ た世代交代モ デ ルで あ る
10). MGG で は , 世代交代の 際, 母集団か ら親個体をラ ン ダ ム に 選択す る . 親個体を 1 回 あ る い は 複数回 交叉さ せ , 子 個体を生成す る . 生成さ れ た子個体と 親個体を合わ せ
"!#%$'&(*)*+,'-,./&'01 234
564 789:
;4 56<
=?>'@BACED "!#%$%&(F)%+,'-,./&'01 234
564 789:
;4 56<
GHJIKFLM
NOGFPQ*IRLSL
GOHTIKFLM
NOGFPQ*IRLSL
UVAEWX>'@Y@C "!#%$%&(F)%+,'-,./&'01 234
564 789:
;4 56<
GHTI"KFLM
NOGTPQ*IRLSL
UVZEW"C\[E>ZED "!#%$%&(F)%+,'-,./&'01 234
564 789:
;4 56<
GOHTIKFLM
NOGTPQ%IRLSL
U]@^EY\
"!#%$'&(*)*+,'-,./&'01 234
564 789:
;4 56<
GOHTIKFLM
NOGTPQ%IRLSL
図8 DPMBGAと UNDXを用い たMGGモ デ ルと の 比較 Fig. 8 History of average of evaluation values
た個体群か ら, あ らか じ め 定め た選択法に 基づ い て 次 世代に 生き 残る 個体を選択し , 母集団に 戻す . MGG で は , 世代交代の 限定化 と 選択の 局所化 と に よ り , 多 様性を維持し て 解 探索を行う こ と が 可 能で あ る .
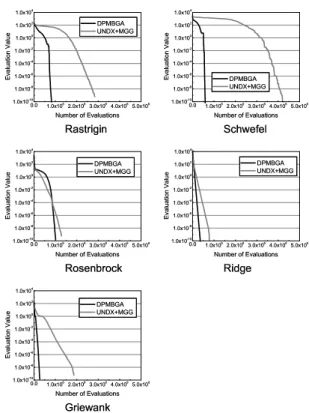
図 8 に , DPMBGA と 比較 対象の モ デ ル( UNDX+
MGG ) と の 解 の 履歴を示す . 横軸は 目的関数の 評価 回 数で あ る . 縦軸は 関数評価 値の 20 試行平均で あ る . ただ し , UNDX+MGG に つ い て は , 20 試行中で 前 述の 最適値に 到達し た試行の みの 平均値をプロ ッ ト し て い る . 最小化 問題で あ る ため , 目的関数値が 小さ い ほど , 良い 解 を得て い る こ と に な る .
UNDX+MGG の パ ラ メ ー タ に つ い て は , 文献
4)を 参考に , 多峰性関数で は 300 個体, 単峰性関数で は 50 個体と し , 交叉回 数 100 回 , α = 0.5 , β = 0.35 , と し て い る . DPMBGA の パ ラ メ ー タ 設定は , 5.2 節 の model 3 ( 環境分散スキー ム ) と 同様で あ る .
図 8 よ り , ど の 関数に 対し て も , 環境分散スキー
ム を採用し た DPMBGA が 良好な 性能を示し て い る .
よ っ て DPMBGA は , 設計変数間の 依存関係の 有無
に 関わ らず , 連続関数最適化 に お い て 有効な モ デ ルで
あ る と い え る .
表4 目的関数の 定義域 Table 4 Domain of objective functions Function Optimum ofxi Domain
Rastrigin 0.0 [0 , 5.12]
Schwefel 420.968746 [-512, 421]
Rosenbrock 1.0 [-2.048, 1]
Ridge 0.0 [0, 64]
5.6 最適解 が 設計変数空間の 端に 位置す る 問題に つ い て の 検討
実数値 GA の 交叉法は , 最適解 が 探索領域の 中心に 位置す る 問題に 対し て は 良好な 性能を示す が , 探索領 域の 境界 付近に 最適解 を有す る 問題に 対し て は 良好な 解 を発見で き な い こ と が 知られ て い る . こ の よ う な 問 題を解 決す る 方法と し て , Tsutsui に よ っ て 提案さ れ た Boundary Extension by Mirroring (BEM)
11)が あ る .
BEM で は , 探索領域の 境界 か ら一定距離以内の 個 体の 存在を許す . 外 部の 個体を許容す る 範囲は , 拡 張 率( extension rate ) r
e(0.0 < r
e< 1.0) に よ っ て 定 義さ れ る . 探索領域外 の 個体の 関数評価 値は , 境界 を 基点と し て 鏡像の よ う に 折り 返し た目的関数を用い て 計算す る .
DPMBGA は 実数値 GA で あ る の で , 上記 と 同様の 問題を有す る 可 能性が あ る . ま た, 探索領域の 端で は , 個体の 分布が 探索領域の 境界 の 作用を受け る ため , 確 率モ デ ル構築・ 子個体の 生成の アルゴ リ ズム の 効果 が , 予期し たも の と 異な る こ と が 推測さ れ る . 本節で は , 探索領域の 境界 付近に 最適解 が 位置す る 対象問題に お け る DPMBGA の 探索能力に つ い て 検討す る . BEM を DPMBGA に 適用し , そ の 有効性に つ い て 議論す る . DPMBGA の パ ラ メ ー タ 設定は , 5.2 節の model 3 ( 環境分散スキー ム ) と 同様で あ る . ただ し , 表 4 に 示す よ う に , 最適解 が 探索領域の 境界 付近に 位置す る よ う に 定義域を設定し て い る .
図 9 に , 通常の DPMBGA お よ び BEM を適用し た DPMBGA の 解 の 履歴を示す . 横軸は 目的関数の 評価 回 数で あ る . 縦軸は 関数評価 値の 20 試行平均で あ る .
同図よ り , BEM を用い な い 通常の モ デ ルが , 良好 な 性能を示し て い る . DPMBGA で は , 探索領域の 外 に 発生し た個体に つ い て は , 最も 近い 探索領域の 境界 上に 引き 戻し て い る . 最適解 が 境界 上に あ る 場合, 引 き 戻し に よ っ て 境界 付近に 個体が 集中す る 可 能性が あ る . こ の 点が , 最適解 が 境界 上に あ る 関数に お い て , BEM を適用し な い 通常の モ デ ルが よ り 良好な 性能を 示す 原因で あ る と 考え られ る . よ っ て , 探索領域が 各
! #"%$'&'(*),+.-*/'0*/*12(.3*4 576!89;:!<
=,>,?
@A;BDCFEHGIJGKMLONQPSRJGTOGU;RJV
WXWY
XZ[\W]ZXW[\W]_^XZ[\W]`\XW[\Wa
\XW[\Wbcd
\XW[\Wbe
\XW[\Wba
\XW[\W bf
\XW[\Wbg
\XW[\Wd
\XW[\Wg
\XW[\Wf
hi
j
kl
j
m
nop
q
jkl
r
st!u#v%w'x!y%z,{.|*}'~t*}*y.*
7% S!
D
;SH; ¡H ;J¢
£¤£ ¥¤¦§¨£© ¦¤£§¨£©
¨¤£§¨£ª«¬
¨¤£§¨£ ª
¨¤£§¨£ª®
¨¤£§¨£ª¯
¨¤£§¨£ª°
¨¤£§¨£¬
¨¤£§¨£°
¨¤£§¨£¯
±²³
´µ³
¶·¸¹ º³
´µ»
¼½!¾#¿%À'Á!Â%Ã,Ä.Å*Æ'ǽ%Æ*ÈÉÂ.Ê*Ë ÌOÍ!ÎÏSÐ%Ñ
ÒDÓÔ
ÕÖ×ØÚÙÛÜÙÝÞHßàSáJâÛHâÙ;áJã
£¤£ ¥¤¦§¨£© ¦¤£§¨£©
¨¤£§¨£ª«¬
¨¤£§¨£ª
¨¤£§¨£ª®
¨¤£§¨£ª¯
¨¤£§¨£ª°
¨¤£§¨£¬
¨¤£§¨£°
¨¤£§¨£¯
±²³
´µ³
¶·¸¹ º³
´µ»
¼½!¾#¿%À'Á!Â%Ã,Ä.Å*Æ'ǽ%Æ*ÈÉÂ.Ê*Ë ÌOÍ!ÎÏSÐ%Ñ
ÒDÓÔ
ä âáSå;ÙæÞHßà;áâÛHâÙ;áJã
図9 最適解 が 探索空間の 端に 位置す る 問題に お け る 解 の 履歴 Fig. 9 History of average of evaluation values on functions
which have optimum at the edge of search space
設計変数の 上限と 下 限で 定義さ れ て い る 問題に つ い て は , 最適解 が 端に 位置し て い て も , DPMBGA は 良好 な 解 を得る こ と が で き る と い え る .
5.7 正規 分布を用い た分布推定に 関す る 検討 DPMBGA で は 正規 分布に よ り 良好な 個体群の 分布 を推定し , 子個体を生成す る . し か し な が ら, 個体群 の 分布が 一つ の 固ま り で は な く , 複数の 固ま り か ら形 成さ れ る よ う な 場合に は , 個体群を正規 分布で 推定す る に は 問題が 生じ る 場合が あ る も の と 考え られ る . 例 え ば , 多峰性の 関数, ま たは , 最適解 が 端に 位置す る よ う な 関数に お い て , こ れ に 該 当す る 場合が あ る .
そ こ で , 本節で は 10 次元の Schwefel 関数を対象と
し , 上記 の 点に つ い て 数値実験に よ り 分布を観察す る .
Schwefel 関数は 多峰性の 関数で あ り , か つ 最適解 が 各
設計変数の 定義域の 端付近に 存在し , 準最適解 が 他の
端に 存在す る 問題で あ る . そ の ため , 解 の 分布が 複数
に 分離し て 存在す る 可 能性が あ る . 数値実験で 用い る
基本的な パ ラ メ ー タ は , 表 1 の 通り で あ る が , 分割
母集団モ デ ルを適用せ ず , PCA を行う 1 つ の 母集団
128 個体を対象と し , 分散の 増幅率を 1.0 と し た. 数
値実験は , 抽出さ れ た良好な 個体群 (32 個体 ) と , 生
成さ れ た子個体群 (128 個体 ) の 分布を比較 す る こ と
で 行う . こ れ らの パ ラ メ ー タ は , 良好な 個体群と 生成
さ れ た個体群の 分布の 比較 を行い 易く す る ため に 決定
し た. 分布の 比較 に は , 各 世代に お け る 各 設計変数の
平均値と 最適解 ま で の 距離の 絶対値, 分散, 歪度を用
い た. 歪度と は 分布の 歪みを示す 尺度で あ り , 正方向
への 分布が 伸び て い る 場合は 正, 逆に 負方向に 伸び て
い る 場合は 負の 値をと る . ま た 0 に 近け れ ば 対称形に
Generated Individuals Extracted Individuals
Skewness ValueVariance ValueDistance to optimum
Design Variable1 Design Variable2 Design Variable1
Design Variable2
Number of Generations 1.00E-01
1.00E+00 1.00E+01 1.00E+02 1.00E+03
0 300 600 900 1200 1500
Number of Generations 1.00E-01
1.00E+00 1.00E+01 1.00E+02 1.00E+03
0 300 600 900 1200 1500
1.00E-01 1.00E+00 1.00E+01 1.00E+02 1.00E+03 1.00E+04 1.00E+05
Number of Generations 0 300 600 900 1200 1500
1.00E-01 1.00E+00 1.00E+01 1.00E+02 1.00E+03 1.00E+04 1.00E+05
Number of Generations 0 300 600 900 1200 1500
-6.00E+00 -4.00E+00 -2.00E+00 0.00E+00 2.00E+00 4.00E+00 6.00E+00
Number of Generations 0 300 600 900 1200 1500
-6.00E+00 -4.00E+00 -2.00E+00 0.00E+00 2.00E+00 4.00E+00 6.00E+00
Number of Generations 0 300 600 900 1200 1500
図10 各 設計変数の 平均と 最適解 ま で の 距離, 分散, 歪度の 履歴 Fig. 10 History of distance between average and optimum
point, variance value and skewness value of each design variable