細粒度な要求駆動計算機構に基づく関数プログラミング
森本 武資
電気通信大学大学院電気通信学研究科 博士(工学)の学位申請論文
2007 年 3 月
細粒度な要求駆動計算機構に基づく関数プログラミング
博士論文審査委員会
主査 岩崎 英哉 教授
委員 野下 浩平 教授
委員 笠井 琢美 教授
委員 岩田 茂樹 教授
委員 尾内 理紀夫 教授
委員 中山 泰一 助教授
著作権所有者 森本 武資 2007
Functional Programming based on a Mechanism for Small Demand Driven Computation
Takeshi Morimoto Abstract
This thesis shows techniques that enable purely functional programmers to write efficient programs in the same form as simple and naive but inefficient programs.
They eliminate unnecessary computations while retaining a simple program form by exploiting a mechanism for small demand driven computation.
The mechanism is based on a data type called an improving sequence, which is a monotonic sequence of approximation values that approach the final value. If some approximation value in an improving sequence has sufficient information to yield the result of some part of the program, the computations that produce the values remain- ing after the approximation can be eliminated. By using improving sequences together with suitable functions defined on the sequences, we can write efficient programs, in the same form as simple and naive programs.
In this thesis, we present three techniques that extend of the applicability, efficiency, and generality of the elimination of unnecessary computations by the small demand driven evaluation of functional programs based on improving sequences.
The applicability of improving sequences can be extended by the language mech- anism for memoization. The use of improving sequences and memoization brings significant effect; improving sequences eliminate unnecessary memoizations, while the memoization resumes computations eliminated by improving sequences. Therefore it enables us to describe incremental computations that evaluate only necessary com- putations and resumes eliminated computations on demand.
The efficiency of an improving sequence can be improved by speculative evaluations of too small demands, because the overhead due to the control of too small demands can be reduced. We analyzed the main factor of the overhead, and stably reduced the overhead of the improving sequence-based computation.
The generality of improving sequences can be extended by the library for improv- ing sequences. The library enables us to write efficient search programs in the same form as exhaustive search programs, which can be regarded as the specification of the
search problem. We implemented the most known search algorithms, namely best- first, depth-first branch-and-bound, and iterative-deepening. Based on the implemen- tations, three efficient search programs can be easily constructed from an exhaustive one.
細粒度な要求駆動計算機構に基づく関数プログラミング 森本 武資
論文要旨
要求駆動型のプログラムは,要求に応じて必要な計算だけを進めるので,結果に寄与し ない不要計算を除去することができる.そのため潜在的な実行効率がよく,遅延評価を行 う関数型言語により簡潔に記述できる.要求を細かく出せば,計算の必要性を細かい単位 で調べられ,より多くの不要計算を除去できることから,細かい要求を簡潔に記述するた めの言語機構(細粒度な要求駆動計算機構)が考案されている.
細粒度な要求駆動計算機構は,式の値が必要になっても,値に至る途中の中間結果まで しか式の評価を進めない.評価をさらに進めるかどうかは,中間結果を見て決める.もし 中間結果の内に十分な情報が含まれていれば後続の不要計算を除去し,含まれていなけれ ば次の中間結果に至るまで評価を進める.このように十分な情報が得られるまで中間結果 を細かく読み進めることにより,式の値が必要になると値に至るまで評価を進める遅延評 価よりも,粒度の細かい要求駆動計算を行う.式の値に徐々に近づいていくような中間結
果の列は Improving Sequence(以下 IS と略す)と呼ばれる.細粒度な要求駆動計算機
構は,この IS というデータ構造をプリミティブとする言語機構である.
IS を用いれば,問題の定義式(仕様)と,その問題を解く方法(実装)を分離すること ができる.中間結果を読み進める手順を,問題の定義式から抽出し,別のモジュール(関 数定義)に分離できるからである.したがって,問題の解き方を記述したモジュールを蓄 積し再利用できれば,問題の定義式を記述するだけで,問題を実行効率よく解くプログラ ムが構成できるようになる.このような IS の高いモジュール性を活用するプログラミン グ手法の確立が,本論文の目標である.
IS の従来研究は,このようなプログラミングの基本的な手法と,その潜在的な有効性 を示している.しかし,その高い潜在能力を顕在化するためには,適用範囲の拡大,効率 化,ライブラリの拡充が重要である.
本論文では,次の三つの手法を実現した.まず,適用範囲を拡大するために,IS とメモ 化機構の併用法を明らかにした.次に,実行効率を向上するために,IS のオーバヘッドの 削減法を明らかにした.そして,ライブラリを拡充するために,IS 上における探索アルゴ リズムの実装法を明らかにした.
手法の実現に際し,問題の定義式の形を完全に保つことを,本論文の方針とした.この 方針により,これらの手法を用いれば,問題の定義式を記述するだけで,問題を実行効率 よく解くプログラムが構成できるようになる.
本論文の第一の提案である,IS とメモ化機構の併用法に基づけば,必要な計算だけを進 め,必要に応じて中断した計算を再開する漸次計算を簡潔に記述することができる.メモ 化とは同じ引数値への関数適用によって生じる重複計算を除去する技法であり,メモ化機 構はその簡潔な記述を支援する言語機構である.一方,IS は,中間結果を基に不要な後続 計算を除去するという枝刈り技法の簡潔な記述を支援する.ゆえに,両機構を用いれば,
枝刈りとメモ化の併用を簡潔に記述することができる.この二つの技法を併用すれば,相 乗効果が生まれる.すなわち,枝刈りは無駄なメモ化を除去する.またメモ化は枝刈りに より中断された計算を待機させることで,別の場面でその計算値が必要になったときに,
中断された所から計算を再開できるようにする.本論文では,両機構の併用を実現するた めに,遅延評価を行う関数型言語を,両機構を併せもつよう拡張した.拡張した言語は,
枝刈りとメモ化の併用の簡潔な記述を可能にするだけでなく,遅延評価よりも一般化され た評価戦略を実現する.この特徴により,この言語を用いることにより,必要な計算だけ を進め,必要に応じて中断した計算を再開する漸次計算を簡潔に記述することができた.
第二の提案である,オーバヘッド削減法に基づけば,IS を用いるプログラムの実行効 率を安定的に向上することができる.IS を用いるプログラムにおいては,要求が細かい ほど,より多くの不要計算を除去できる.しかし,要求が細かすぎると,いずれ必要にな る計算の必要性を調べるという無駄が生じ,せっかくの不要計算除去による改善効果を打 ち消してしまう.この改善効果とオーバヘッドのトレードオフに対処するため,本論文で は,要求の細かさを投機的評価を用いて調節する機構を提案した.提案する機構では,要 求に応じて計算を進める際に,要求された計算の後続計算も投機的に進めることで,要求 の細かさを調節した.細粒度の要求駆動計算には投機的評価に伴うリスクが少ないという 特徴があるため,単純な手法を用いるだけで,安定的にオーバヘッドを削減することがで きた.
第三の提案である,探索アルゴリズムの実装法に基づけば,全探索プログラムを記述す るだけで実行効率のよい探索プログラムの構成を可能にするような,探索アルゴリズム・
モジュールを実装することができる.IS を用いる探索プログラミングにおいて,探索空 間を網羅的に探索する全探索プログラムは,探索問題の定義式とみなすことができる.ゆ えに,探索問題の解き方,すなわち探索アルゴリズムを定義式から分離し,別のモジュー ルに分離できる.本論文では,最もよく知られた探索アルゴリズムである,最良優先,深 さ優先分枝限定,反復深化のためのモジュールの実装法を示した.三つのモジュールは差 し替えが可能であり,探索アルゴリズムの使い分けを容易にした.提案する実装法は,他 の探索アルゴリズムにも適用できるものと考えられ,IS 上における探索アルゴリズム・ラ イブラリ構築の礎となるものである.
目次
第1章 序論 1
1.1 本研究の背景と目的 . . . 1
1.2 本論文の構成 . . . 5
第2章 枝刈り機構 7 2.1 定義. . . 7
2.2 使用法 . . . 8
2.3 基本演算 . . . 9
2.4 Haskell 上での実装. . . 11
第3章 関連研究 15 3.1 枝刈り機構 . . . 15
3.2 メモ化機構 . . . 19
3.3 漸次計算 . . . 20
3.4 要求駆動計算における投機的評価 . . . 21
3.5 探索プログラミングのための言語機構 . . . 21
第4章 枝刈り機構とメモ化機構の併用 31 4.1 枝刈りとメモ化 . . . 31
4.2 枝刈り機構とメモ化機構 . . . 32
4.3 記述例 . . . 32
4.4 まとめ . . . 40
第5章 枝刈り機構のオーバヘッドの削減 41 5.1 細分化された要求駆動のオーバヘッド . . . 41
5.2 要求の粒度調節機構 . . . 43
5.3 記述例 . . . 47
5.4 実験. . . 51
5.5 考察:粒度調節と探索戦略 . . . 55
5.6 まとめ . . . 56
第6章 枝刈り機構における探索アルゴリズムの実装 57 6.1 探索プログラム . . . 57
6.2 最良優先探索 . . . 58
6.3 深さ優先分枝限定探索 . . . 59
6.4 反復深化探索 . . . 61
6.5 高階関数によるモジュール化 . . . 63
6.6 記述例 . . . 64
6.7 まとめ . . . 65
第7章 結論 67
謝辞 69
参考文献 71
関連論文の印刷公表の方法及び時期 75
図目次
4.1 ナップサック問題を解くプログラム . . . 34
4.2 枝刈り機構とメモ化機構を用いたプログラムの計算の進行過程 . . . 35
4.3 編集距離を求めるプログラム . . . 37
4.4 行列積に必要なスカラー積の回数の最小値を求めるプログラム . . . 39
5.1 spec の定義. . . 45
5.2 ナップサック問題を解くプログラム . . . 48
5.3 8 パズルの初期配置と目的配置 . . . 49
5.4 8 パズルを解くプログラム . . . 50
5.5 ks の計測結果 . . . 53
5.6 pz の計測結果 . . . 54
表目次
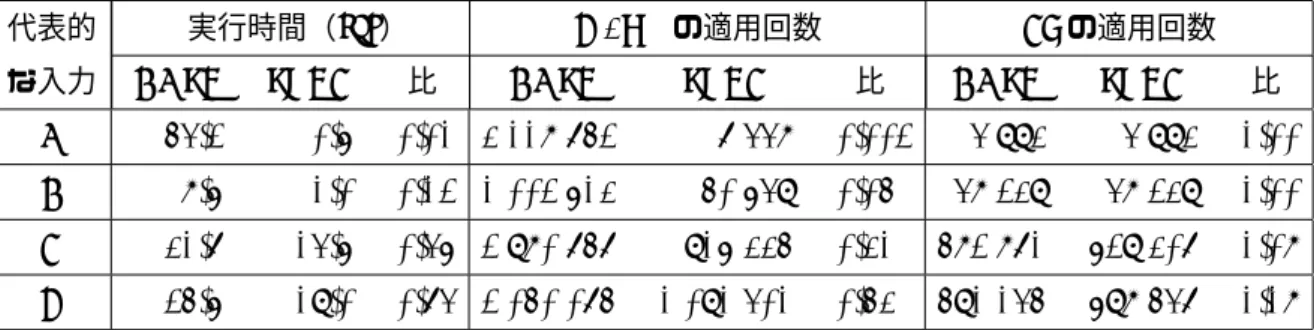
4.1 ks 100 [A, B, C, D] の後に ks 99 [A, B, C, D] を評価したときの,関数 ks の適用回数 . . . 36 4.2 ed”abcef ghi” ”abcdef gz” の後にed”abdef ghij” ”bcdef gyij”を評価
したときの,関数 edの適用回数 . . . 38 4.3 mm ms 1 13の後に mm ms 7 20を評価したときの,関数 mm の適用
回数. . . 40 5.1 代表的な入力における ks の計測結果 . . . 55 5.2 代表的な入力における pz の計測結果 . . . 55
第 1 章 序論
1.1 本研究の背景と目的
プログラミングとは計算機を用いて問題を解く行為である.プログラマは問題を解くた めに,解こうとしている問題がどのようなものなのか(what to be),問題を解くために はどうすればよいのか(how to do)を,プログラムとして記述する.プログラミングの 目的は問題を解くことであるから,what to be という言わば問題の仕様を記述するだけ
で,how to do という実装を記述することなく,解を得られることが理想である.
しかし,現実の計算機で行われる計算は,アルゴリズムに従った手順の積み上げであ
る.What to be を記述するだけでは,解く方法が見つからない問題や,実行効率の悪い
解き方しか見つからない問題が無数に存在する.
プログラミング言語研究の主要な目標は,what to be とhow to do の間に横たわる広 く深い溝を埋めることにある.この動機のもと,プログラム可能な計算機が提案されて以 来今日まで,様々なプログラミング言語が考案されてきた.What to be の記述に重点を おくプログラミング言語は宣言型 [26] と呼ばれ,how to do の記述に重点をおく言語は 手続き型と呼ばれる.最も原始的な言語であるアセンブリ言語は手続き型の最右翼であ
り,how to do が一切ない制約プログラミング言語は宣言型の最右翼である.実践的な
言語の多くは両極の中間に位置し,そうした言語のプログラムにおいては what to be と how to do の記述が混在する.
プログラミング言語研究の主要な課題は,混在する what to be とhow to doを分離す るための道具を提供することにある.別の言い方をすれば,モジュール化のための枠組み を提供するということである.How to doを記述することはやむを得ないとしても,両者 が分離されていれば,どちらか一方を変更したり,別の用途に再利用したりできるため,
プログラムの生産性が向上する.このようなモジュール化の利点は古くから指摘されてい る [20].実際,今日なじみの深い,抽象データ型の概念やオブジェクト指向プログラミン
グは,how to do に混じり込んでいた what to be を抽出し,両者を別々のモジュールと
2 第1章 序論 して記述するというものである.すなわち,抽象データ型の概念はあるデータに関するプ ログラム記述をその仕様と実装に分離し,オブジェクト指向プログラミングは仕様と実装 を抽象度に応じて階層的に分離する.
モジュール化の鍵はモジュールの合成法にある [15].モジュール化を軸とする分割統治 的なプログラミングにおいては,モジュールの分割法はその合成法と表裏一体の関係にあ るからである.Hughes [15]によれば,合成法の重要性は大工仕事との類比によって説明 できる.例えば,椅子は,座部や脚,背もたれといった部品を作り,それらを合成すると いう工程を経ることにより容易に構成できる.しかし,これは木材を接合するための合成 法があるからこそ可能な構成法である.もし合成法がなければ,椅子を作る方法は一つ,
木の塊から彫り出す以外になく,非常に難しい作業になる.このように,モジュール化の 実現には合成法の確立が不可欠である.
モジュールの合成法が強力であるほど,モジュールの分割は容易になる.さらに,how
to do に関するモジュールを蓄積し再利用できれば,what to beに関するモジュールの記
述に専念できる.そのようなモジュール化プログラミングに成功している言語の一つ [12]
に,遅延評価という評価戦略に基づいて強力な合成法を提供する,純関数型言語 [14] が ある.
関数型言語は計算の主体を関数とする宣言型言語の一派である.ことに,純粋な関数型 言語においては,副作用がないため,通常の数学的な記述と同じような等式による推論が 可能である.ゆえに,数学的な記述に近い,高水準なプログラム記述が可能である.一方 で,純関数型言語においては,遅延評価と呼ばれる評価戦略が提供するモジュール合成法 の働きにより,プログラム記述の断片(モジュール)を実行効率よく合成することがで きる.
遅延評価とは,式の値が必要になるまで式の評価を遅延する評価戦略である.遅延評価 の下では,プログラマは,データ構造のどの部分が必要でどの部分が必要ないかといった 配慮をせずにすむので,そのデータ構造がどのようなものなのか(what to be)を記述す ることに専念できる.逆の見方をすれば,そのデータ構造をどのように使うのか(how to do)という記述を分離することができる.ゆえに両者は別の用途に再利用することがで き,そのようなプログラム記述の断片の蓄積が生産性の向上につながる.このように,遅 延評価は実行効率のよいプログラムの簡潔な記述を支援する.
遅延評価に基づくプログラムは,要求に応じて必要な計算だけを進めるので,結果に寄 与しない不要計算を除去することができ,潜在的な実行効率がよい.要求を細かく出せ ば,計算の必要性を細かい単位で調べられ,より多くの不要計算を除去できることから,
細かい要求を簡潔に記述するための言語機構(細粒度な要求駆動計算機構) [17] が考案 されている.
細粒度な要求駆動計算機構は,式の値が必要になっても,値に至る途中の中間結果まで
1.1 本研究の背景と目的 3 しか式の評価を進めない.評価をさらに進めるかどうかは,中間結果を見て決める.もし 中間結果の内に十分な情報が含まれていれば後続の不要計算を除去し,含まれていなけれ ば次の中間結果に至るまで評価を進める.このように十分な情報が得られるまで中間結果 を細かく読み進めることで,遅延評価よりも粒度の細かい要求駆動計算を行う.中間結果 を基に不要な後続計算を除去するというこの計算法は一般に枝刈りと呼ばれる.本論文で は,枝刈りの記述を簡潔にするという,細粒度な要求駆動計算機構の一性質に焦点を絞る ため,この機構を単に枝刈り機構と呼ぶことにする.
枝刈り機構は純関数型言語における式の内容(what to be)と評価手順(how to do) を分離する.中間結果を読み進める手順を式から抽出し,別のモジュールに分離できるか らである.したがって,枝刈り機構を用いれば,問題の定義式と,その問題を解くための 方法を分離することができる.
このような枝刈り機構の高いモジュール性を活用するプログラミング手法の確立が,本 研究の目標である.
さて,枝刈り機構の従来研究は,このようなプログラミングの基本的な手法と,その潜 在的な有効性を示している.しかし,その高い潜在能力を顕在化するためには,適用範囲 の拡大,効率化,ライブラリの拡充が重要である.このために,次の三つの手法の実現を,
本研究の目的とする.
• 枝刈り機構とメモ化機構の併用法 . . . 枝刈り機構の適用範囲を拡大
• 枝刈り機構のオーバヘッドの削減法 . . . 枝刈り機構の実行効率を向上
• 枝刈り機構における探索アルゴリズムの実装法 . . . . 枝刈り機構のライブラリを拡充 これらの手法の実現に際し,問題の定義式の形を完全に保つことを,本研究の方針とす る.この方針により,これらの手法を用いれば,問題の定義式を記述するだけで,問題を 実行効率よく解くプログラムが構成できるようになる.
本論文における提案手法は,いずれも枝刈り機構に基づいているため,実現にあたって は,枝刈り機構が言語処理系に備わっていることが必要である.枝刈り機構の実現法に は,次の二つが考えられる.
• 処理系を拡張し,組込みのデータ型として実現する方法
• 処理系を拡張せず,枝刈り機構を模倣するようなデータ型を定義する方法
これに加え,第一の提案におけるメモ化機構を実現するためには,言語処理系を拡張す る必要がある.本論文では,枝刈り機構とメモ化機構を併せもつような関数型言語処理系 を作成し,実験を行った.
第二の提案でのオーバヘッドの削減では,枝刈り機構を備える言語の枠組みの中で,新 たな機構を導入し,その機構に基づいてオーバヘッドを削減する.この機構そのものは,
4 第1章 序論 通常の(組込でない)関数として定義できるものではあるが,本論文では,実行効率を重 視して,枝刈り機構とオーバヘッド削減の機構をいずれも組込みとして実現した関数型言 語処理系を作成した.
第三の提案は,言語処理系が枝刈り機構さえ備えていれば,探索アルゴリズムを実現す る高階関数としてライブラリ化が可能であることを示している.ライブラリ化という点を 重視し,ここでは,既存の関数型言語Haskell の上に枝刈り機構を模倣するようなデータ 型を定義し,Haskell で記述されたライブラリとして提案機構を実現した.
以下,提案する三つの手法について順に述べる.
枝刈り機構とメモ化機構の併用法
メモ化とは,枝刈りと同じく,無駄な計算を除去することによってプログラムの実行効 率を改善する技法である.枝刈りが結果に寄与しない計算を除去するのに対し,メモ化は 同じ引数値への関数適用によって生じる重複計算を除去する.両者は併用することにより 相乗効果を期待できる.すなわち,枝刈りは無駄なメモ化を除去する.またメモ化は枝刈 りにより中断された計算を待機させることで,別の場面でその計算値が必要になったとき に,中断された所から計算を再開できるようにする.
しかし,従来の言語では両者の併用を簡潔に記述できない.これまでに,枝刈り機構だ けをもつ言語 [17] やメモ化機構だけをもつ言語 [2] は提案されているが,両機構を併せ もつ言語はまだ提案されていない.このため,従来の言語で両者の併用を記述しようとす ると,これらの技法を明示的に記述する必要が生じ,プログラムの見通しが悪くなってし まう.
本研究では,枝刈り機構とメモ化機構を純関数型言語に積極的に採り入れることによ り,この問題を解決する.そのように拡張した言語は,枝刈りとメモ化の併用の簡潔な記 述を可能にするだけでなく,遅延評価よりも一般化された評価戦略を実現する.これによ り,この言語を用いれば,必要な計算だけを進め,必要に応じて中断した計算を再開する 漸次計算(incremental computation)[23]を簡潔に記述することができる.
枝刈り機構のオーバヘッドの削減法
枝刈り機構を用いれば,細粒度な要求駆動計算を行うプログラムを簡潔に記述できる が,その一方で,要求駆動にはオーバヘッドが伴う.必要以上に要求を細かくしすぎる と,いずれ必要になる計算の必要性を調べるという無駄が生じ,せっかくの不要計算除去 による改善効果を打ち消してしまう.この改善効果とオーバヘッドのトレードオフに対処 するには,要求の細かさを適切に調節することが重要である.しかし,要求の細分化のみ を行う従来の方法では,要求を適切な粒度に調節することができず,必要以上の要求の細 分化によるオーバヘッドの増大が効率改善の妨げとなっていた.
1.2 本論文の構成 5 本研究では,この問題を解決するため,要求の細かさを投機的評価を用いて調節する機 構を提案する.提案する機構では,要求に応じて計算を進める際に,要求された計算の後 続計算も投機的に進めることで,要求の細かさを調節する.細分化された要求駆動には投 機的評価に伴うリスクが少ないという特徴があるため,単純な手法を用いるだけでオーバ ヘッドを安定的に削減することができる.
枝刈り機構における探索アルゴリズムの実装法
探索プログラミングにおいて枝刈り機構を用いれば,枝刈りの方法,すなわち探索アル ゴリズムをモジュール化できる.そのようなモジュールをライブラリとして蓄積すること ができれば,探索問題の性質に応じたアルゴリズムの使い分けが可能になり,したがっ て,探索問題の仕様を記述するだけで探索プログラムを構成できるようになる.
本研究では,従来の最良優先(best-first)[13]のためのモジュール[5]に加え,新たに,深 さ優先分枝限定(depth-first branch-and-bound)[19]と反復深化(iterative-deepening) [18] のためのモジュールを実装する.これら三つのアルゴリズムは主要な探索アルゴリズ ムとして知られており [29],適用範囲が広い.新たな二つのモジュールは,その適用法が 従来の最良優先モジュールの適用法と同じになるように設計することができる.したがっ て,これらのモジュールは差し替えが可能であり,探索アルゴリズムの使い分けを容易に する.提案する実装法は,他の探索アルゴリズムにも適用できるものと考えられ,枝刈り 機構における探索アルゴリズム・ライブラリを構築する礎となるものである.
1.2 本論文の構成
まず,第 2 章で枝刈り機構の定義と基本的な用法を述べる.この章は関連論文(3)に 基づくものである.次に,第 3 章において,関連研究との比較により,本研究の位置づけ とその新規性を述べる.第 4 章においては枝刈り機構とメモ化機構の併用法について述 べる.この章は関連論文(1)に基づく.第 5 章では枝刈り機構のオーバヘッドの削減法 について述べる.この章は関連論文(2)に基づく.第 6 章においては枝刈り機構におけ る探索アルゴリズムの実装法について述べる.この章は関連論文(3)に基づく.最後に 第 7 章において,本研究の成果を論ずる.
本論文ではプログラムの表記法として,純関数型言語の標準である Haskell [3] に枝刈 り機構とメモ化機構を記述するための拡張を加えた記法を用いる.
第 2 章 枝刈り機構
本章では枝刈り機構の定義と基本的な用法を述べる.枝刈り機構は,徐々に真の値に近 づいていくような近似値の列 Improving Sequence [17] と,列を要求駆動で読み進める 関数からなる.もし列の中途の近似値が計算結果を求めるのに必要な情報を十分に含んで いれば,その近似値より先の,結果に寄与しない近似値の生成にかかる計算を除去でき る.また,列の読み進め方,すなわち枝刈りの仕方は,列の上で定義された関数としてモ ジュール化でき,再利用できる.ゆえに,そのような関数をあらかじめ用意しておけば,
列を返す関数を記述するだけで,枝刈りをするプログラムを構成できる.真の値に近づい ていく近似列を返すプログラムは,真の値のみを返す通常の(枝刈りをしない)プログラ ムを基に構成できるため,枝刈りをしない素朴なプログラムの構造を保ったまま,枝刈り をするプログラムを構成的に記述できる.
2.1 定義
Improving Sequence(以下IS と略す)の個々の要素は近似値,後続計算,二項関係か
らなるデータ構造である.後続計算もまた IS であるため IS は近似値の列をなす.隣り 合う近似値の間に推移的かつ全的な二項関係が成り立つように列を構成することにより,
IS はその二項関係において単調に改善する列となる.この単調性を基に,後続計算の必 要性を,近似値と二項関係から判定する.
IS の構成にはデータ構成子 ¿ を用いる.x¿R xsという記述は,近似値 x,後続計 算 xs,二項関係 Rからなる IS を示す.IS の列の長さは有限でも無限でもよい.有限の 場合には零項構成子 ε を用いて,IS の終端,すなわち真の値に到達し後続計算がないこ とを表す.例えば,次の式
0 ¿< 1 ¿< 2 ¿< 3 ¿< ε
は,二項関係 < のもとで,近似値が 0 から徐々に改善され真の値 3 に至る IS を表す.
8 第2章 枝刈り機構 また,糖衣構文として À がある.ÀR は a R−1b ≡ b R a なる R−1 に関する ¿R−1 と等しい.¿ からなる IS を上昇列,À からなる IS を下降列と呼ぶ.以後,読みやすさ のために,二項関係の明示が不要な文脈においては,¿R,ÀR を単に ¿,À と記す.
2.2 使用法
IS を用いて枝刈りをするプログラムを構成するには,まず,IS を用いない通常の関数 定義を基に,IS を返す関数を構成する.この関数が返す IS を要求駆動で読み進むことで 不要計算を除去する.リストの長さを返す関数 lengthを例に,IS の基本的な使用法を説 明する.以下は通常の length の定義である.
length [ ] n = n
length (x :xs)n = length xs (n + 1)
ここで,length の第二引数 n は検査済みのリストの長さを保持する累積変数であり,初
期値は 0 である.この length を用いて 1 < length [1..100] 0 の値を求める場合を考え よう.演算子 < は両オペランドについて正格であるから,length[1..100] 0 は最終値 100 に至るまで評価される.1 と100 が比較され,求める値は T rue に決まる.
1 < length[1..100] 0
⇒1 < length[2..100] 1
⇒1 < length[3..100] 2 :
⇒1 < 100
⇒True
しかし,length [1..100] 0 の評価は 1 との大小比較という文脈においてなされているか ら,二度目の再帰呼び出し length [3..100] 2 より先の後続計算は,評価結果に寄与しない 不要な計算である.それ以上計算を進めずとも,length [3..100] 2 の最終値が少なくとも 2 以上であることは,その累積変数から知ることができる.
IS を用いれば,このような不要計算を除去できる.まず,length の関数定義を,IS を 返すように書き換える.IS を返す関数の定義は,計算の終端と近似値を示す式を追加す ることで得られる.length は,与えられたリストが空であれば,検査済みのリストの長 さである n を返して計算を終える.空でなければ,リストの長さは少なくとも n 以上で あることが確定するので,その近似値は n,後続計算は length xs (n + 1) である.ゆえ にIS を返す新しい length の定義は,終端を示す ¿< ε を第一式に追加し,近似値を示 す n ¿< を第二式に追加することにより得られる.
2.3 基本演算 9 length [ ] n = n ¿< ε
length (x :xs)n = n ¿< length xs (n+ 1)
例えばlength [ 9,4 ] 0は0 ¿< 1 ¿< 2 ¿< ε を返す.このように,ISを返す関数は,
素朴かつ簡潔な関数定義の構造を完全に保つ.
IS を要求駆動で読み進める演算子 <R を< の代わりに用いることにより,不要計算を 除去することができる.
n <R ε =False
n <R (x ¿R xs) =if n R x then True else n <R xs
演算子 <R は第一引数(通常の値)が第二引数(IS)の真の値よりも R の意味で小さい か否かを判定する.この演算子は第二式において,第二引数の近似値 x を参照し,n が x より小さいことが決まり次第,即座に T rue を返す.後続計算 xsを評価しないことで 枝刈りを実現している.この結果,不要計算 length [4..100] 3 を,以下のように枝刈りで きる.
1 << (length [1..100] 0)
⇒1 << (0 ¿< length [2..100] 1)
⇒1 << (1 ¿< length [3..100] 2)
⇒1 << (2 ¿< length [4..100] 3)
⇒True
IS は,このように,実行効率のよいプログラムの簡潔な記述を可能にする.
2.3 基本演算
IS 上の基本的な関数minB,approx,finalize,final と演算子 ⊕,]について述べる.
関数 minB は Burton が考案した minimum [5](3.1.1 節)を IS の記法に書き換えた 関数である.二つの上昇列を引数に取り,最小値に至る上昇列を返す.
minB εys = ε minB xsε = ε
minB (x ¿R xs) (y ¿R ys) | x == y = x ¿R minB xs ys
| x R y = x ¿R minB xs(y ¿R ys)
| otherwise = y ¿R minB (x ¿R xs)ys minB は本質的にはマージソートの要領で二つの上昇列を二項関係 R の順に併合する.
どちらか一方の上昇列が真の値に至った時点で minB も計算を終えることにより,まだ
10 第2章 枝刈り機構 真の値に到達していないもう一方の上昇列の後続計算を除去する.この点がマージソート と異なる.minB を用いた計算の様子を以下に示す.
minB (1 ¿ 2 ¿ 4 ¿ 6 ¿ 9 ¿ ε) (2 ¿ 3 ¿ ε)
⇒1 ¿ minB (2 ¿ 4 ¿ 6 ¿ 9 ¿ ε) (2 ¿ 3 ¿ ε)
⇒1 ¿ 2 ¿ minB (4 ¿ 6 ¿ 9 ¿ ε) (3 ¿ ε)
⇒1 ¿ 2 ¿ 3 ¿ minB (4 ¿ 6 ¿ 9 ¿ ε)ε
⇒1 ¿ 2 ¿ 3 ¿ ε
この例では結果に寄与しない後続計算 4 ¿ 6 ¿ 9 ¿ ε を除去している.下降列に関 して同様の処理を行う関数を maxB とする.
maxB εys = ε maxB xsε = ε
maxB (x ÀR xs) (y ÀR ys) | x == y = x ÀR maxB xs ys
| y R x = x ÀR maxB xs (y ÀR ys)
| otherwise = y ÀR maxB (x ÀR xs)ys また,上昇列のリストについて minB と同じ要領で最小値に至る上昇列を返す関数を minimumB とする.
minimumB = foldl1minB
関数 approx,finalize,final と演算子 ⊕,] の定義は次の通りである.
approx (x ¿R xs) =x
finalize(x ¿R ε) =x ¿R ε finalize(x ¿R xs) =finalize xs
final =approx . finalize
n ⊕ ε =ε
n ⊕ (x ¿R xs) = (n + x) ¿R (n ⊕ xs) (x ¿R xs) ] (y ¿R ys) = (x + y) ¿R zs
where
zs | xs == ε = x ⊕ ys
| ys == ε = y ⊕ xs
| otherwise = xs] ys
関数approx は与えられた ISの近似値を返す.関数 finalize は与えられたIS の真の値の みからなるISを返し,関数final は与えられたISの真の値そのものを返す.演算子⊕は
2.4 Haskell 上での実装 11 数と IS の加算を行う.例えば1 ⊕ (1 ¿ 2 ¿ 3 ¿ ε) は2 ¿ 3 ¿ 4 ¿ ε を返す.
また,演算子 ] はIS 同士の加算を行い,例えば(1 ¿ 2 ¿ 3 ¿ ε) ] (8 ¿ 9 ¿ ε) は (9 ¿ 11 ¿ 12 ¿ ε) を返す.
2.4 Haskell 上での実装
以上に示したプログラムの表記法は,IS を簡潔に記述するために関数型言語 Haskell の表記法を拡張し ¿R と ÀR を追加したものであるが,一方で,IS は Haskell の既存 の枠組みの中でも記述することができる.本節では,そのような,Haskell におけるIS の 実装法の一例を示す.本節で示す表記法は,第6 章において探索アルゴリズムを実装する 際に用いる.本論文では,両記法を区別するため,拡張した表記法には数式用のフォント
を用い,Haskell における実装を用いた表記法にはタイプライタ体フォントを用いる.
IS は,Haskell においては,次のように定義できる.
data Ord a => IS a = a :? IS a | E deriving Eq
式 x :? xs は,近似値 x とその後続計算 xs からなる IS を表す.IS の二項関係には,
型クラス Ord の演算子 < を用いる.ゆえに近似値の型は Ord のインスタンスでなければ ならない.また,IS の終端を表すには,零項構成子 E を用いる.例えば,次の式
0 :? 1 :? 2 :? 3 :? E
は整数型 Int 上の二項関係 < のもとで,近似値が初期値 0 から徐々に改善され真の値 3 に至る IS を表す.このような IS の定義は Haskell の通常の遅延リストの定義と似てい るが,本論文では IS の説明を明確にするため,遅延リストの代わりに型 IS を新たに導 入した.
IS a 型の IS の二項関係は型a 上の< であるから,型 a を使い分けることで,二項関 係を使い分けることができる.例えば近似値が徐々に減少してゆく IS を構成するには,
演算子 < が二項関係> を判定するようなOrd クラスのインスタンスを新たに定義すれば よい.演算子 < は型クラス Ord のメソッドであるから,Ord のインスタンス型 Gt を新 たに定義する.
newtype Gt a = Gt a deriving Eq instance Ord a => Ord (Gt a) where
(Gt x) < (Gt y) = y < x
IS (Gt a) 型の IS の二項関係は型 a 上の > となる.例えば Gt 2 :? Gt 1 :? Gt 0 :? E は,Int 上の> において単調に改善するISである.次のように定義した演算子>?
12 第2章 枝刈り機構 (>?) :: Ord a => a -> IS (Gt a) -> IS (Gt a)
x >? xs = Gt x :? xs
を用いれば,この IS は 2 >? 1 >? 0 >? E と読みやすくなる.
型 Gt a は IS の二項関係を型 a 上の > に差し替えている.同様に,二項関係を型 a 上の <= と >= に差し替えるための型 LtE a と GtE a を定義する.
newtype LtE a = LtE a deriving Eq instance Ord a => Ord (LtE a) where
(LtE x) < (LtE y) = x < y || x .== y
newtype GtE a = GtE a deriving Eq instance Ord a => Ord (GtE a) where
(GtE x) < (GtE y) = y < x || y .== x
ここで .== はオペランドの同値性を Ord の演算子 < を用いて判定する演算子である.
(.==) :: Ord a => a -> a -> Bool x .== y = (x < y) == (y < x)
例えば Gt 1 .== Gt 1 と LtE 1 .== LtE 1 はどちらもTrueを返す.型LtE とGtE 上の IS を構成する演算子をそれぞれ<=? と>=? と定義する.
(<=?) :: Ord a => a -> IS (LtE a) -> IS (LtE a) x <=? xs = LtE x :? xs
(>=?) :: Ord a => a -> IS (GtE a) -> IS (GtE a) x >=? xs = GtE x :? xs
これらの演算子 >?,<=?,<=? との表記上の一貫性を保つため,関数定義等におけるパ ターンマッチ部を除き,:? の別名として <? を用いることにする.*1
(<?) :: Ord a => a -> IS a -> IS a (<?) = (:?)
型 a 上の IS の二項関係は a のみに依存するから,IS の上で定義された関数や演算子 を,様々な種類の IS に適用することができる.Gt a によって < の順序を逆にするとい
*1データ構成子の名前を<? と定義できれば,このような使い分けをせずに済むが,Haskellの構文規則に おいては,ユーザ定義のデータ構成子の名前は: から始めなければならないという制限がある.
2.4 Haskell 上での実装 13 うこのOrd の用法は,一風変わったものではあるが,プログラムの再利用性を高められる という利点がある.例えば 2.2 節の <R に対応する演算子 .< は次のように定義される.
(.<) :: Ord a => a -> IS a -> Bool n .< E = False
n .< (x :? xs) = if n < x then True else n .< xs
この演算子は,ある値と,二項関係を > とするIS との比較にも再利用できる.同様の比 較を行うための演算子 .> を新たに定義するというような繁雑な作業は必要ない.
前節の minB はこの表記法においては次のように記述される.
minB :: Ord a => IS a -> IS a -> IS a minB E ys = E
minB xs E = E
minB xxs@(x :? xs) yys@(y :? ys)
| x == y = x <? minB xs ys
| x < y = x <? minB xs yys
| otherwise = y <? minB xxs ys
関数 minB は,型 Gt a 上のIS においては,Gt a における最小値,すなわち a におけ る最大値に至る IS を返す.ゆえに型 Gt a や GtE a 上の IS に minB を適用する際に は,可読性のため,以下の別名を用いる.
maxB = minB
Haskell を拡張した(数式フォントを用いる)表記法と,本節で用いた Haskell 上での
実装における(タイプライタ体フォントを用いる)表記法は,表現力は同じであるが,二 項関係の保持の仕方に,本質的な違いがある.データ構成子 ¿R を用いる拡張記法にお いては,二項関係 R がデータ構造の中に保持されるのに対して,本節で示した型クラス Ord a を用いる記法においては,二項関係 < は,IS の値の型 a に保持される.
第 3 章 関連研究
本章では,関連研究との比較により,本研究の位置づけとその新規性を述べる.まず,
枝刈り機構の従来研究である Improving Value とImproving Sequence について述べる.
次に,第 4 章に関連するメモ化と漸次計算について述べ,さらに第 5 章に関連する要求 駆動計算における投機的評価について述べる.最後に,第 6 章に関連する探索プログラミ ングのための言語機構について述べる.
3.1 枝刈り機構
枝刈り機構の研究は Burton のImproving Value [5] に端を発する.Burton は並列計 算における投機的評価を記述するために Improving Value を考案した.一方,Iwasaki は逐次計算に焦点をあて,可読性の高い表記法をもち,ゲーム木探索の簡潔な記述も可能 にする Improving Sequence [17] を考案した.
枝刈り機構の実現において最も重要なアイデアは,計算過程で生成される中間結果(IS における近似値)を第一級の対象に格上げしたことにある.これにより中間結果に基づい て後続計算の必要性を判定できるようになり,計算の進行を制御できるようになった.
中間結果を第一級の対象とすることにより,二つの優れた性質が得られる.一つは,高 モジュール性,すなわち,中間結果の生産法と消費法の記述を分離できることである.中 間結果の生産法とは,データ構成子 ¿R を用いた中間結果の示し方のことである.中間 結果の生産の仕方は,例えば前章で述べた関数 length のように,枝刈り機構を用いない 従来の関数定義の簡潔な形を保ったまま記述することができる.また,中間結果の消費法 とは,中間結果の読み進め方のことである.消費法は,演算子 <R や関数 minB などの ように,生産法とは独立に記述することができ,多くの場合ライブラリ関数として提供さ れる.したがって,プログラマは,生産法の記述を問題の定義式に基づいて構成的に行う ことができるし,消費法の記述,すなわち問題の解き方の記述を別の問題を解く際に再利 用することができる.
16 第3章 関連研究 もう一つの優れた性質は,弱頭部正規形(weak head normal form:遅延評価における
値の形)[21, page 198] に到達しない無限に続く計算を扱えることである.これは通常の
遅延評価にはない特徴である.計算はそれが必要になったときにだけ要求に応じて進めら れるため,例えば length [1..] 0 といった無限に続く計算であっても,不要になった時点 で計算を打ち切ることができる.無限に続く計算を,有限時間で停止する計算と分け隔て なく扱えることは,プログラムの記述性を高める.例えば,多くの探索問題がそうである ように,無限の探索空間における有限の部分空間の内に解が存在する場合においても,無 限に続く計算を記述するための特別な配慮を要しない.
これらの従来研究は,序論でも述べたように,枝刈り機構に基づくプログラミングの基 本的な手法と,潜在的な有効性を示している.一方で本研究は,従来研究に基づき,その 高い潜在能力を顕在化するために,適用範囲の拡大,効率化,ライブラリの拡充を実現す る.Improving Value と Improving Sequence の個々の概要を以下に述べる.
3.1.1 Improving Value
Improving Value(以下 IV と略す)は,投機的評価を行う並列計算のプログラム記述
を支援するために考案されたデータ構造であり,並列計算のための特別な関数 spec(後 述)を備えるよう拡張された純関数型言語において定義される.(Burton の文献 [5]で
は,Haskell に似た構文をもつ Miranda [27] で記述されているが,本節では比較のため
Haskell の表記に書き換えたプログラムを示す.)
IV は,Improving という型の,次のような仕様をもつ抽象データ型である.
make ::α → Improving α break ::Improvingα → α
minimum ::Improvingα → Improvingα → Improvingα spec max ::improving α → Improvingα → Improvingα
関数 make は Improving 型のデータを構成し,関数 break は Improving 型のデータ から値を取り出す.この二つの関数は,概念的には,IS の ¿ と f inal に対応する.関 数minimum*1とspec max は,Improving 型の上で最小値と最大値を求めるものであ る.BurtonのminimumはIS のminB に対応するものであるが,spec max はmaxB
とは異なり,第一引数が(IS で言うところの)真の値に至るまで第二引数を参照しない.
また,並列評価を伴うという点においても,spec max は minB と異なる.
*1このminimumは,最小値を返す通常のminimumとは異なることに注意されたい.なお,本論文の 他の章節におけるminimumは,このBurton のものではなく,通常のものを意味する.
3.1 枝刈り機構 17
Burton は,抽象データ型 IV の実装の一例として,遅延リストを用いる定義を示して
いる.すなわち,型 α 上の IV である Improving α を,α 上の遅延リスト [α] の別名 として定義した.
type Improvingα = [α]
そして,四つの関数を次のように実装した.
make a = [a] break x = last x
minimum xs ys = short merge xs ys short merge [ ] [ ] = [ ]
short merge (x :xs) [ ] = [ ] short merge [ ] (y :ys) = [ ]
short merge (x :xs) (y :ys) | x == y =x : short merge xs ys
| x < y =x : short merge xs (y :ys)
| x > y =y : short merge(x :xs)ys spec max xs ys = spec(monotonic append xs)ys
monotonic append xs ys = xs ++ dropWhile(≤ last xs)ys
関数 make は引数に取った値を唯一の要素とするリストを返し,関数 break はリストの 終端の([ ] の直前の)値を返す.関数minimum の定義は minB とほぼ同じである.関
数 spec max は,第二引数ys の投機的並列評価を開始してから,第一引数 xsを評価す
る.ys の評価値を参照するのは,xs を終端まで評価した後であり,xs の終端の値より も大きい値以降のリストを xs の後続として繋げたリストを返す.
並列計算を実現するための関数 spec は,次のように定義される,特別な関数である.
この Burtonによる spec は,本論文の第 5 章で提案する我々の specとはまったく異な
るものである.
spec :: (α → β) → (α → β) spec f x = f x
spec は意味的には恒等関数と同じであるが,実行上は,第一引数f を第二引数 x に適用 する前に,x の投機的評価を開始する.例えば,非決定性プログラムの記述例としてよく 引合いに出される,論理和の並列計算 spec or は,spec を用いると次のように記述でき る [4].
spec or a b = spec(or a)b
18 第3章 関連研究 この関数定義は「b の投機的評価を開始してから,(or a) を b に適用する」と読む.
spec or は (or a) を必須計算(mandatory computation)として評価し,もし結果が T rue ならば,bの投機的評価を停止させて,spec or 自身の計算を終える.もし,結果が
F alse ならば,bを必須計算に格上げして,計算を進める.
IVに基づくプログラム記述の一例として,Burtonは,最良優先探索によって木の葉の 最小値を求めるプログラム search を示している.まず,IV を用いない,次のような素 朴な全探索プログラムを考える.
search root
|is leaf root = cost root
|otherwise = sub search where
sub search = (foldr1min .map search.children)root
ここで,is leaf root は(部分)木の根 root が葉であるか否かを返し,cost root はroot のコストを返す.children root は root の子のリストを返す.
次に,この素朴なプログラムに IV を適用することで,効率のよい次の記述を得る.
search = break .search0 search0root
|is leaf root = make(cost root)
|otherwise = spec max bound sub search where
bound = make (lower bound root)
sub search = (foldr1minimum.map search .children)root
ここで,lower bound root は root を根とする木の葉の最小値の下限を返す.また,
make (cost root) は IS における cost root ¿ ε に対応し,spec max (make x) は IS の x¿ に対応する.この search は,minimum の働きによって下限を基に最良優先探 索をするプログラムであり,全探索をする素朴なプログラムよりも実行効率がよい.
この例で示した「素朴な記述を基に,枝刈り機構を適用し,効率のよい記述を得る」と いう方法論は,IS の研究や本研究においても踏襲される,枝刈り機構の研究の根幹とい えるものである.Burtonの IV は 枝刈り機構に基づくプログラミングの基本的な手法を 示すものであるが,彼の研究の主眼は並列計算における投機的評価の記述法にあり,ま た,プログラムの実行効率に関する具体的な言及もなされていない.一方,本研究では,
第5 章で述べるように,枝刈り機構のオーバヘッドについて詳細に調べ,逐次計算におけ る投機的評価によって,その削減に成功した.
3.2 メモ化機構 19
3.1.2 Improving Sequence
IS は逐次計算に焦点をあてて考案された言語機構である.可読性の高い表記法をもち,
ゲーム木における探索の簡潔な記述も可能にする.その定義と用法の一部については第 2 章で示した.
IS の従来研究 [17] の主眼は,ゲーム木探索の簡潔な記述法の考案にある.ゲーム木探 索については本論文では詳しく述べないが,その概要は次のようなものである.Iwasaki は,上昇列と下降列を同時に引数に取り,最小値や最大値を返す関数 minduR ,minudR, maxduR ,maxduR を考案した.そして,これら四つの関数を適切に組み合わせることで,
素朴なミニマックス探索プログラムの簡潔さを完全に保ったまま,分枝限定法に基づく ゲーム木探索プログラムを構成的に記述できることを明らかにした.
IS の表記法は,IVのそれに較べ洗練されており,可読性が高い.その理由の一つには,
様々な二項関係の上の IS を統一的に扱えるようにしたことが挙げられる.またもう一つ の理由には,spec max という投機的評価のための関数を採り入れず,遅延評価に基づく
¿,À というデータ構成子を導入したことが挙げられる.前節でも触れたように,IS の 表記法においては,IV の表記法においてspec max (make x) xsと記述しているところ を,単に,x¿xs と記述できる.このような可読性の向上は,ささやかだけれども,役 に立つことである.
IS の従来研究に対する本研究の新規性は二つある.一つは,Burton の minimum を IS に導入し,ライブラリの拡充という形で発展させたこと.もう一つは,¿やÀといっ た数学的な表記法に対応する Haskell 上の具体的なデータ型の定義を,可読性を保ちつつ 与えたことである.
3.2 メモ化機構
メモ化機構は,遅延評価を一般化した評価戦略を実現し [21],重複計算の積極的な除去 を可能にする.その本質は,空間を犠牲にして,重複計算を除去する対象領域を拡大する ことにある.
メモ化にかかるコストの削減と,対象領域の拡大を実現するために,様々な研究 [2] が なされている.Acar の分類によれば,メモ化機構に関する従来研究は,三つの観点から 捉えることができる.その観点とは,同値性(equality)の検査法,入力と出力の関連性 の検査法,空間計算量の節約法の三つである.
同値性の検査法とは,同じ入力に対する重複計算を除去するというメモ化において,入 力が「同じ」であることを調べるための方法である.この検査に時間がかかると,重複計
20 第3章 関連研究 算の除去による改善効果を打ち消してしまうが,実際的なプログラミングで扱う大きく複 雑なデータ構造の検査には時間がかかってしまうという問題点があり,様々な提案がなさ れている.
入力と出力の関連性の検査法とは,入力のどの部分が出力に影響するのかという関連を 調べるための方法である.例えば,次の関数 f においては,
f x y z = if x >0 then g y else h z
入力 x が正数の場合の出力は z の影響を受けず,非正数の場合の出力は y の影響を受け ない.このような関数において,より多くの重複計算を再利用できるようにするというの が,入力と出力の関連性検査の目的である.
空間計算量の節約法とは,再利用のために保持する入力と出力の対応表(メモ表)を,
効率よく実装するための方法である.メモ表の大きさは計算を進めるにつれて増大するか ら,規模の大きな計算ではメモリを圧迫してしまうという問題があり,様々な対処法が提 案されている.
本研究では,以上の三つの分類に当てはまらない,従来のメモ化機構の研究にはなかっ た観点から,再利用可能な重複計算の対象領域を拡大する.従来のメモ化機構が計算済み の値のみを再利用の対象としているのに対し,第 4 章で提案する枝刈り機構とメモ化機 構を併せもつ言語は,計算済みの値のみならず計算途中の状態の再利用も可能にすること で,異なる場所の計算を途中まで共有できるように対象領域を拡大している.
3.3 漸次計算
漸次計算(incremental computation)[23] とは,計算結果を積極的に再利用すること で重複計算を除去し,必要な計算だけを徐々に進めていく,実行効率のよい計算法の総称
である.Ramalingamと Reps による抽象的な表現を借りれば,漸次計算とは,
入力 x に対する出力を f(x) とするような計算 f において,新たな入力 x+ ∆x に対して f を計算する際に,入力の差分 ∆x に伴う計算だけを進めることで出力 f(x+ ∆x) を得るような計算
である.従来の漸次計算は,似た入力には似た出力が得られる問題を対象としている.入 力の違いによる影響を受けない計算済みの値を再利用することで実行効率を向上させると いう,入力のデータ構造上の変化に注目したものであった.一方,第4 章で提案する枝刈 り機構とメモ化機構をもつ言語は,計算の必要性に伴う変化に着目した漸次計算を実現す る.ゆえに,提案言語を用いれば,計算済みの値のみならず計算途中の状態の再利用も可 能になるため,必要な計算だけを進め,必要に応じて中断した計算を再開する漸次計算を
3.4 要求駆動計算における投機的評価 21 簡潔に実現できる.
3.4 要求駆動計算における投機的評価
第 5 章で提案する枝刈り機構のオーバヘッドの削減法は,Optimistic Evaluation [7]
に着想を得ている.Optimistic Evaluation とは「要求駆動計算の大半の部分計算は結局 は必要になる」という経験則に基づき,投機的評価によって,通常の遅延評価のオーバ ヘッドを削減する評価戦略である.経験則に従えば「今のところ必要でない計算であって もいずれ必要になる可能性が高い」ので,まだ必要ではない計算をも投機的に評価するこ とによって,計算の遅延にかかる(遅延計算を表現する処理系内部のデータ構造である
thunk の生成などの)オーバヘッドを削減する.投機の判断に実行時の情報を利用するこ
とで,静的な正格性解析 [31] では行えないような,実行内容に即した最適化を行うこと ができる.
我々の提案手法においても,細分化された要求駆動のオーバヘッドを削減するために,
同様の経験則に基づき,実行時の情報を用いた投機的評価を行う.細分化された要求駆 動には投機的評価に伴うリスクが少ないという特徴がある(5.1 節)ため,Optimistic
Evaluation のような大掛かりな機構を用いずとも,単純な関数を用いるだけで安定的に
オーバヘッドを削減することができる.
3.5 探索プログラミングのための言語機構
探索プログラムの記述を支援するための言語機構は,言語を問わず,様々な研究がなさ れている.しかし,いずれの言語においても共通するのは,要求駆動計算を簡潔に記述す るための,何らかの機構に基づいていることである.論理型言語を代表する Prolog にお いては,言語の基本的な評価機構そのものがバックトラックを実現するものであるし,オ ブジェクト指向言語においては,継続を第一級の対象とすることにより,探索プログラミ ングを支援する機構が提案されているもの [28] もある.また,関数型言語においては,遅 延評価によって要求駆動計算が実現される.本節では,関数型言語とオブジェクト指向言 語における従来研究について述べる.
3.5.1 関数型言語
遅延評価に基づく探索プログラミングの手法は古くから知られている [30] が,そのよ うな手法を積極的に支援するような関数型の言語機構はあまり知られていない [8].ここ では,比較的新しい二つの研究について述べる.一つは,素朴な方法で型クラスを利用し
22 第3章 関連研究 た言語機構である.もう一つは,枝刈り機構に似た方法を用いて幅優先探索を行う,曖昧 な文法のための構文解析器結合子(parser combinator)である.
型クラスを利用した言語機構
Erwig [8] は関数的な探索プログラミングを支援するために,状態の表現,状態遷移,
探索アルゴリズムの三つをパラメータ化した型クラス SearchP roblem を提案している.
説明のため,まず,探索アルゴリズムを幅優先に固定したバージョンを説明し,次に,探 索アルゴリズムをパラメータ化したバージョンを説明する.
幅優先による探索プログラミングのためSearchP roblem は,状態の型sと状態遷移の 手(move)を表す型 mの二つを取る多重パラメータ型クラスであり,四つの関数 trans, space,solutions,isSolution を備える.
class SearchProblem s m where trans :: s → [ (m,s) ] space, solutions :: s → [ ( [m],s) ] isSolution :: ( [m],s) → Bool
関数 transは状態を引数に取り,「次状態と,その次状態へ遷移するための手」の組のリ
ストを返す.つまり,この trans は一回分の状態遷移を表す関数である.trans を繰り 返し適用してゆけば状態空間全体を構成することができる.それを行うのが関数 space
である.space は初期状態を引数に取り,状態空間全体を返す.trans が定義されていれ
ば,状態空間の構成法は決まりきった処理であるから,space は次のように,あらかじめ 定義される.ゆえに,利用者はspace の定義を記述しなくてよい.
space s = step ++ expand step where
step = [ ( [m], t) |(m, t) ← trans s] expand ss = [ (ms ++ns, t)|(ms,s) ← ss,
(ns, t) ← space s]
この space は,幅優先的に探索空間を構成してゆくので,展開したばかりの状態のリス
ト expand ssを,展開済み状態のリスト step の後続として追加してゆく.さて,探索と
は,探索空間全体から,解となる条件を満たす状態を見つけることであるから,解のリス トを返す関数 solutions は,状態が解かどうかを判定する関数isSolution を用いて,次 のように記述される.
solutions = filter isSolution . space