Real-Time Word Confidence Scoring using Local Posterior probabilities on Tree Trellis Search
4
0
0
全文
(2) where g(W) denotes the log Iikelihood of a sentence hy pothesis W derived from the recognition decoder, i.e.,. g(W) = logp(XIW)p(W)ー. We assume in this paper that the speech recognition al gorithm is based on a tree-trellis search[5][6], a typical two pass heuristic search based on tree lexicon. The first pass perfo口ns tree-Iexicon search to generate interm巴diate re sults in word trellis form, that consists of all the survived word hypotheses with their boundary times and accumu lated likelihoods from the beginning of the utterance. Then the second pass performs stack decoding in the reverse di rection with more precise models, using th巴 word trellis as the estimated heuristics of unreached part. ActuaIly, when connecting a word ωn to a partiaI sentence hypothesis ω?-1=ω1,ω2, "')ωn- on the second pa民the decoder l o切ective function of the second pass f(ωf) is computed as. (2). p(X) is appro氾mated by the sum over all paths through the lattice. This word posterior probability can be used directly as the confidence score of the word hypothesis. ( W) o",.g 一一 ) : .::_p(X) W E 会;L l. C([ω; T, t])=. 一_. (3). where αis a scaling parameter (α < 1) that is necessary to avoid only a few words to dominate the sums in these equations because of the large dynarnic r叩ge of acoustic likelihoods[2]. From the equations above, it is apparent that both the sum of probabilities of paths W,山;T,tl and of probabilities of all paths for p(X) should be computed to estimate a word confidence score of [w; T, t]. If the hypotheses are givenぉ N-best list, the computation process is a simple summation of sentence scores that contains [ω; T, t]. On word graph, forward-backward algorithm is normally applied Here, the computational cost of computing the word confidence scoring is discussed on the basis of total recog nition performance, that includes not only the cost of the confidence scoring but also the recognition cost to generate the hypothes巴s. Since a sufficient number of word hypothe ses is required to estimate the confidence, a large number of N-best hypotheses should be searched on the recognition decoder. They should be computed even if the final applica tion requires only the best one. Actually, several hundreds of sentence hypotheses are needed to get a sufficient result for N-best Iist bas巴d confidence scoring on large vocabulary continuous sp田ch rl目ognition. Obtaining such large num ber of hypotheses at the preliminary r氏ognition process re sult in a much growth of processing time. Moreover, since the computation of posterior probabil ity for any word hypothesis r,巴quires overall likelihoods for the whole utterance, the scoring process cannot be started before all the word hypotheses are generated by the decoder. Such post-processing may cause an increase of tum-around time for a user application.. f(ω�-l,[Wn; T, t]). =. f(吋) =. g(ω?-I,t)+ん(ωn,t). (4). f(吋一人[ωn;t]) (5) O�Iだら. where g(叫1, t) denotes the likelihood at the connecting edge of the partial sentence hypothesis ω�-l on time t , and h(tリ) denotes the Iikelihood of the connected word ωat time t on the word trellis Let us consider deriving approximated word post巴nor probabilities from the likelihood f(ωï). As it contains both Iikelihood of most likely path for the searched segment and heuristic Iikelihood of unsearched segment that are derived from the previous pass, it is possible to use the score directly instead of precise probability. It means approximation of p(ωn, X) by using only the maximum likelihood path and use heuristic likelihood for the unsearched segment. For the estimation of p(X), the summation of f(叫) for all words that exists around the target word can be used. Finally, the approximated posterior probability ß(ωηIX) of a word ωηcan be obtained from f(wI), Wc n X) ß(ωl. [ω; T, t] : T三tn壬t ef(山�). 2二Wc eJ(w�一人I叫T,t]). (6). (7). where tn is the maximum argument of equation (5). Introducing this approximation enables the posterior probability based confidence scoring at search process, on the word expansion Stage. The stack de氾oding algorithm integrated with the proposed confidence scoring is shown below.. 3. CONFIDENCE SCORINGWHILE DECODING. 1. Set initial hypotheses into the sentence hypothesis. We propose a new confidence scoring method that is appli cable directly in the way of speech recognition procedure. The aim is to compute a word posterior based confidence measures efficiently and faster without generating much hy potheses and with small computational cost. The basic ap proach is to use the local likelihoods of partial sentence hy pothesis at the point of word expansion in the decoding pro cedure to get approximated word posterior probability.. stack. 2. Repeat the following steps until requested number of sentences are obtained. (a) Pop the best hypothesis from the stack. (b) if the popped hypothesis has been reached at end of utterance, output it and exit.. 1-. 794. ハU 刈斗& 司Eム.
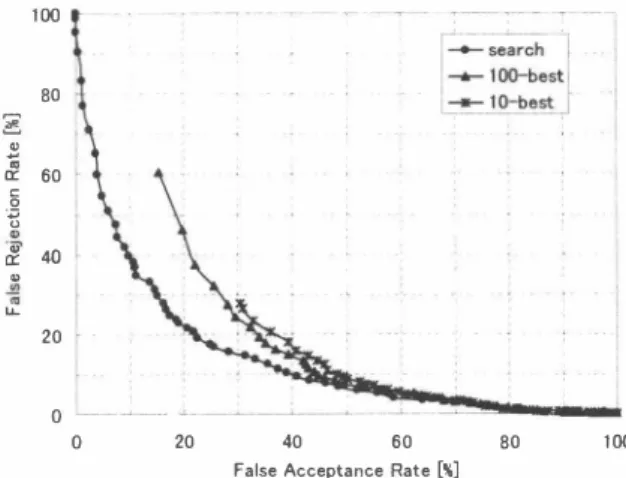
(3) to be obtained is set to 100.2 10 are also tested for compari son.. (c) Determining next words: estimate the end time of popped hypothesis, and look for words in the trellis to pick up words whose end node exist at the estimated end time. They are the next word candidates (equation (6)). (d) Generate new hypotheses by connecting those words, and compute their likelihoods by finding the optimal connection time for each (equation (4) and (5 )). (e) Co順位nce scoring: compute the word poste rior probabilities of those word candidates using the likelihoods (equation (7)). Store the confi dence score to each hypothesis. (f) Push them to the hypothesis stack and go to (a).. 4.2. Evaluation measures. To assess the quality of confidence scoring, a threshold (J is defined to label the recognized words. Each word will be labeled as“correct" if the confidence score is equal or above出e threshold, and ‘戸lse" if below the threshold. Several evaluation measure was introduced. To see the labeling accuracy of correct andfalse, confidence e町or rate (CER) was computed as the number of incorrectly assigned labels divided by the total number of recognized words. Detection-e町or-tradeoff (DET) curve was also drawn by plotting false acceptance rate over false rejection rate. Moreover, another criteria was introduced in山is exper iment to evaluate the confidence scores in the domain of spoken dialogue system: failure of acceptance (FA) and slot e町or (SE汀):. As shown from the above algorithm, it is obvious that the computation cost needed for the confidence scoring is substantially small, as compared with parsing all the N-best lists or word graph. Moreover, it is not necessary to s巴訂ch for a large number of word hypotheses only for getting the confidence scores. These feature realizes fast speech recog nition with confidence scoring. However, computing confidence measure from such ap proximated posterior probability may suffer the quality of confidence scores. The likelihood used in the proposed method reftects only the best path, and it also contains heuristic scores.. FA SErr. Hum. of co汀ect words labeled as cor町cl. , (8). num. of words labeled as cor陀Cl Hum. of correct words labeled as cor陀cl num. of referen心e words. ー(9). From the dialogue management's point of view, accepting wrong words has critical impact, since the wrongly acc巴pted word will cause further confusion of discourse. Consider ing this, the weighed sumrnation of the FA and SErr is also computed using weighing parameter入: (FA・入+SEπ). 4. EXPERIMENTAL RESULT. x. 2/入 ( + 1).. ( 10). 4.1. Conditions. 4.3. Results. The proposed method was evaluated through a recogni tion test. The proposed method is implemented on our open-source real-time large vocabulary recognition engine Julius[6], version 3.41• It applies word 2-gram on the first pass and word 3-gram on the second pass. For comparison, the conventional N-best rescoring is also implemented. The task domain is an unconstrain巴d, natural question and answer dialogue with a software agent, located at the public civil hall. The task of the agent is guidance of the hall, some inforrnation query in and around the hall, greet ings and so on. 5 00 utterances of adult's moderate sp田ch are extracted as a test set. The average length of spoken utterance is 2.1 seconds. Acoustic model is a phonetic tied-rnixture triphone model, and language model is a task dependent word 3-gram. The dictionary consists of 41,248 words, and test set perp1exity is 1 1.4. Other detai1s about this task are in [7]. The sca1ing p紅白neterαis set to 0.04 for all experiment. On N-best method, the number of recognized sentence. The FA, SErr and FA+SErr with several weights for various threshold (J ar右plotted in Figure 1 and Figur巴 2 for N-best list method and proposed method, respectively. It is shown that although approximations has been introduced, the pro posed method can provide almost the same confidence qual ity as the conventional N-best method. It was found that the proposed method can especially reduce the FA. This indi cates that, while the N-best method can deal with only the lirnited variety of hypotheses, while the proposed method compute the confidence scoring directly from the word can didates that will lat疋r be dropped from search. On the other hand, the increase of Slot eπor is observed. lt is supposed to occur by the approximation of likelihoods. DET curves are also plotted in Figure 3. It is shown that our proposed method (Iabeled as“search" in the figure) has substantial perforrnance over the N-best methods. Finally, the rninimal e汀or rate of FA+SE汀, CER, and average processing time is shown in Table 1. 80th FA+SErr 2. Since m田t of the leSI sel uuer田lce are short, search space become. exhausted given a large I Available al. http://julius.sourceforge . jp/enl. N. value. Actually, all 100 senten唱e resullS could. nol be oblained f,町253 oul of 500 uUer組問s.. 1 - 795. 可E4 ペ堂 、lA.
(4) 60. 1∞. 50. { t ] �匂. 40. [. �. E支 出 (. 80 r. 30. tE60 5. 20. <i. 2 0 ω. 百 @ω 伺 LL. 10. 40. 20. �ー. o ,. 」ー. o. ~. 0.2. a一ーー」一一--'- �- __..j_ ームー 0.4. 0.6. 0.8. 1. .o.___ ..t-_一一一一一. 。. Confidence Score Threshold. 20. 。. 40. 60. 80. False Acceptance Rate. Fig. 1.. 100. e百]. FA and SErr by N-best method (N= I (0) Fig. 3.. Detection-error tradeoff curves.. |. Minimal eπor rate [%] and average process tlme 臥 附4 叫tlme (sec) +SEπ +SEπ CER lO-best I 27. 1 2 1.9 12.3 2.0 100-best I 26.7 20.8 12.3 2.4 Search I 26.9 19. 1 1 1.8 2. 1 CPU: Intel Xeon 2.40Hz, baseline CER = 14. 1. Table 1.. 40 Z 30 20 10. dedicated to more evaluation at wide variety of tasks.. 一。. 。. 6. REFERENCES. 川. 。. [1]. Fig. 2.. FA and SErr by proposed method.. T. Kemp and T. Schaaf, “Estimating confìdence using word lattices," in Proc. EUROSPEECH, September 1997, vol. 2, pp. 8270830.. [問2勾] F. We凶ss叩剖el, R. Schlut附e釘r,K.Ma低ch恥1児er陀ey, and H. Ney払,. iトmeωas釦ures for larg巴 vocaぬbu凶l加訂y c∞o叩ntm加u凶ous sp巴ech r陀 ' ec∞ogI伊1か tion," IEEE Trans. Speech & Audio Process., vol. 9, no. 3,. and CER was slightly improved by the proposed method. This result suspects出at our approximation method not only contributes to reduction of computation, but also improves the quality of confidence. The computation cost of confidence scoring is relatively small as compared with the 100-b巴st result. Our method does not need N-best decoding and getting only the best sentence candidate is enough.. pp. 2880298, March 200 1. [3] C. Neti, S. Roukos, and E. Eide, “Word-based con自dence measures as a guide for stack search in speech recognition," in Proc. ICASSP, 1997, vol. 2, pp. 8830886. [4) G. Eve口nann and P. Woodland,“Large vocabu加y decoding and confìdence estimation using word posterior probabilities," in Proc. ICASSP, 2000, vol. llI, pp. 165501658. [5] F. K. Soong and. E.-F. Huang,. “'A tree-trellis based fast. search for白nding出e N best sentence hypotheses in contin uous speech recognition," in Proc. ICASSP, 1991, vol. 1, pp.. 5. CONCLUSION. 7050708. [6) A. Lee, T. Kawahara, and K. Shikano, “Julius - an open. A rapid and efftcient method to compute a word confidence measures based on word posterior probability has been in troduced. Our method computes confidence scores at recog nition decoder while recognition, and can produce con fidence scores without searching for N-best results while keeping its quality. It can be applied to other search al gorithm than the tree trellis search. Future work will be. 1-. source real-time large vocabulary recognition engine,". in. Proc. EUROSPEECH, September 2001, pp. 169101694. [7) R. Nisimura, Y. Nishihara, R. T surumi, A. Lee, H. Saruwatari, and K. Shikano, “Takemaru-kun:. Speech-oriented infor. mation system for real world research p1atform,". in Proc.. First lntemational "ゐrkshop on Language Understanding and Agentsfor Real"ゐrld lnteraction, Ju1y 2003, pp. 7ω78. 796. 円/“ 必吐 、tA.
(5)
図
関連したドキュメント
注意: 操作の詳細は、 「BD マックス ユーザーズマニュ アル」 3) を参照してください。. 注意:
Then optimal control theory is applied to investigate optimal strategies for controlling the spread of malaria disease using treatment, insecticide treated bed nets and spray
2022 年9月 30 日(金)~10 月 31 日(月)の期間で東京・下北沢で開催される「下北沢カレーフェステ ィバル 2022」とのコラボ企画「MANKAI
大六先生に直接質問をしたい方(ご希望は事務局で最終的に選ばせていただきます) あり なし
For performance comparison of PSO-based hybrid search algorithm, that is, PSO and noising-method-based local search, using proposed encoding/decoding technique with those reported
Gilch [ 11 ] computed two different formulas for the rate of escape with respect to the word length of random walks on free products of graphs by different techniques, and also a
○社会福祉事業の経営者による福祉サービスに関する 苦情解決の仕組みの指針について(平成 12 年6月7 日付障第 452 号・社援第 1352 号・老発第
2000 個, 2500 個, 4000 個, 4653 個)つないだ 8 種類 の時間 Kripke 構造を用いて実験を行った.また,三つ
