Musical-Noise-Free Blind Speech Extraction Using ICA-Based Noise Estimation with Channel Selection
4
0
0
全文
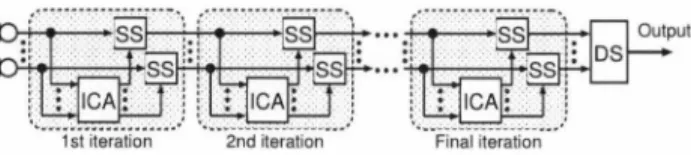
(2) Jooo. Aσ ,, , ,, z. p x e α -. α 一α Z一 町. 一 一. z p. 。 一 →. xmP(x )dx, whereμm is themth引der moment given byμm = and P(x) is the proba幼bilitザy d巴nsi幻ity flωu山I削 doma創1汀lß】 s剖ignal x. A kurtosis ratio of unity corresponds to no musical noise. This m巴asure increases as th巴 amount of generat巴d musical nOlse Ißcreases. In this paper, we assume that the input signal x in the power sp巴ctral domain is mod巴l巴d using the gamma distribution as. = Jooo. (4). wh巴re,αis the shape paramet巴にo is the scale parameter, and r(α) t'Jt-l exp ( - )d . IS批伊una function, defined as r(α) Using (4), the mth-order moment after SS,μm, is given by [6]. t t. μm=O;;'M(αn,ß,η,m),. (5). where On andαn ar巴 the scale and the shape parameter for noise, and. M(αn,ß,η,m). =). ι t r(m+ l )r(αn+m-l,βαn) :( 一βαn) 一 一 ハ ー一'. 2 + η mγ(αn+m,βαn)/r(αn).. 一 一tの). (6). r(b,α) and γ(b,α)訂巴 the upp巴r and lower incomplet巴 gamma functions d必E負fìn巴ed aおs r(伊b,α吋) = and γ(作b,α吋) = 1 叫( dtム, respe氏倒削ct叩tive均 From (2勾), (σ3), (5幻), and (6め), t山h巴. J:taα. Jboo ta-→le目xp(←一tの)d必t. kurtosis ratio aft巴r SS can be expr巴ss巴d as kurtosisratio =. 2 (αn,ß,η,2) ん1(αn,β,η,4)/ん1 ,-��--'&Jr;..I :1 ��'I.. ���--U l ':.';:I�:. M(αn,0,0,4)/M2(αn,0,0,2). (7). Fig. 1. Block diagram of iterativeBSSA.. 3. THEORETICAL ANALYSIS OF DEGRADATION II唱ICA AND ITS IMPROVEMENT 3.1. Accuracy of wavefront estimated by ICA after SS. In this subsection, we discuss the accuracy of the estimated noise sig nal in each iteration of iterativeBSSA to clarify why i印刷iveBSSA distorts the speech component. In actual environments, not only point-source noise but also non-point-source ( e.g., diffuse) noise of ten exists. It is known白紙ICA is proficient in noise estirnation rather than speech estimation under such a noise condition [2]. This is b巴cause the target speech can be regard巴d as a point-source sig nal (thus, th巴 wavefront is static in 巴ach subband) and ICA acts as an effective blocking fiIter of the speech wavefront even in a time Ißvanant mann巴r, resulting in good noise estimation. However, in iterative BSSA, we should address the inherent question of whether the distorted speech wavefront after nonlinear noise reduction such as SS can be blocked by ICA or not; thus, the speech component after channel-wis巴 SS can become a point sourc巴 agalß or not. Hereaft巴r, we quantify the degree of point-source-liken巴ss for SS叩pli巴d spe四h signals. For convenience of discussion, a simple two-channel array model is assumed. First, we defin巴血e speech component in each channel after channel-wise SS as. =. 2.4. Musical-noise-free speech enhancement. れ(1,r) =ん(!)s(f,r) +ムsl (1,r ),. (8). In [6], we have proposed musical-noise-free noise r巴duction, wher巴 no musical noise is generated even for a high SNR in iterative SS. The authors have deriv巴d the optimal parameters satisfying the musical-noise-台ee condition by finding a fixed-point status in由E kurtosis ratio [6]. Given the noise shape paramet巴r αn, we can choose combinations of the oversubtraction parameterβand the flooring p紅arneterηthat simultaneously sati均the musicaトnoise free cond】tlOn.. ゐ(1,r). (9). 2.5. Conventional BSSA and iterative BSSA. In the previous musical-nois巴・free noise r巴duction, we assum巴d that th巴 input noise signal is stationary, m巴aning that we can estimate the expectation of a noise signal from a time-frequency period of a signal that contains only nois巴, i.e., speech absence. However, in actual environments, e.g., a nonstationary noise field, it is necess紅y to dynarnically estimate the nois巴 power spectral d巴nSlty. To solve this problem, we previously proposedBSSA [2], which involves a∞urate noise estimalion by ICA followed by a speech 巴x traction procedure bas巴d on SS. BSSA improves the nois巴 r巴duc tion performance, particularly in the pres巴nce of both of diffuse and nonstationary noises. However,BSSA always suffers from musical noise owing to SS. To achieve low musical noise g巴n巴ration, we have r巴cently pro posed iterative BSSA [5] (see Fig. 1). This method consists of iter ative blind dynamic noise estimation by ICA and musical-noise-fr巴E spe巴ch extraction by modified iterativ巴 SS, where multiple iterative SS is applied to each channel while m 創ntaining the multトchannel property reused for ICA. The main drawback of this method is a generation of large speech distortion, instead of less musical noise.. h2(1)s(f,r) + ßS2(1,r),. where 5k(l,r) is the speech component after channel-wise SS, hk(1) is the transfer function from th巴 target signal position to each. microphone at the kth channel, and ムsk(!,r) is the speech com ponent d凶tort巴d by channel-wise SS. AIso, we assume that s(f, r ) , ムsl(1,r), and ßS2(1,r) are uncorrelated with each other. Obvト ously, 51(1,r) and 52(1,r) can be regard巴d as being gen巴削ed by a point source if ßSl(1, r) and ßS2(1, r ) are zero, i.巴 , a valid static blocking filter can be obtained by ICA. However,江ムsl(1,r) and ßS 2(1, r ) become nonzero as a result of SS, ICA does not have a va1id speech blocking filter with a static (time-invariant) form Second, the cosine distance between spe巴ch power spectra 2 151(1,r)1 and 152(1,rW is introduc巴d in each frequency subband to indicate the degree of point-source-likeness, as. Z.,. 15 1 ( J,r W I 52( J,r W. COS(f) = Iー. ム 'ー. 、. 、. 宇 'ー. 、. ・. (10). From (10) , th巴 cosine distance reaches its maximum valu巴 of unity if and only ifムsl(1,r) =ムS2(1,r) = 0, regardless of the val U巴s of hl(1) and h2(1), meaning that the SS-applied speech signals 51(1, r) and 52(1,r) can be assum巴d to be produced by the point source. The value of COS(I) decreases with increasing magnitudes ofムSI (1,r) andムS2(1,r) as well as th巴 di仔erence b巴tween hj (1) and h2(1); this indicates the non-po川-source state. Third, we evaluate th巴 degre巴 of point-source-likeness in each iteration of iterative BSSA by using COS(I). We statistically estト mate the distort巴d speech component of the enhanced signal in each iteration. Her巴, we assume that the original speech power spectrum.
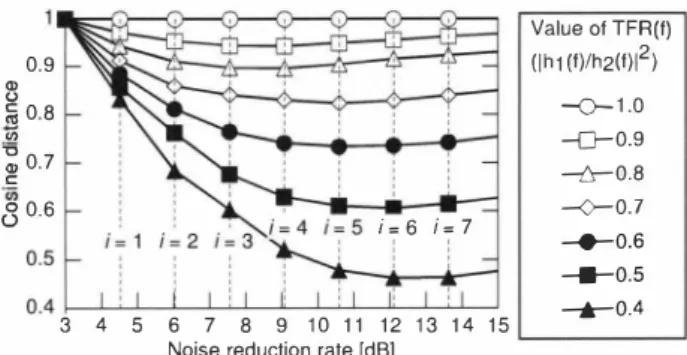
(3) 0. Value 01 TFR(I) 2 (Ih1(1)/h2(1)1 ). 0.9. 一0-ー1.0. 20 8 '". 一仁〉ー0.9. � 0.7. ーゼ:;-0.8. c 帥. 80.6 0.5 ト 3. I=1 1 4. 5. 4 2 15 5 4. で5 i=6 i=7. 争、_:. 6. 7. 8. ー〈トー0.7. -・←-0.6. -・1-0.5. 9 10 11 12 13 14 15. 。o. 一合「ー0.4. Noise reduction rate [dB]. Fig.2. Relation between number of iterations of iterative BSSA and cosine distance. Input SNR is 0 dB.. Is(f,r)12 obりs a gamma distribution with a shape pararr削er ofO.1. (this is a typical value for speech). Also, the amount of residual noise after the ith iteration is given. , . μtiJ = 9nMi(αn, ß,η1)α�-i. ( 1 1). Next, we assum巴 that speech and noise are disjoint, i.e., th巴r巴 are no overlaps in the time-frequency domain, and that speech distortion is caused by subtracting the average noise from the pure speech com. ponent. Thus, the sp悶h component Ist+1J(f,rW at the kth chan n巴1 aft巴r the ith iteration is repres巴nt巴d by subtracting the amount of residual nois巴 (1 1) as. 1 Ist+ J(f,r)12 =. , ( IsrJ(f,r)12 - ß9nMi(αll, ß,η1)αl-t (ifjstJ(frW , >β9nM'(αu, ß,η1)α�--i) , , (otherwise) , l '1)2lstJ(frW. �. (12). Here, we define the input SNR as the average of both channel SNRs,. の1&ー フ フ ISNR(f) = 一一ょ(lh1(fW + Ih (f)I< ). 2 2αn9n If we normalize the sp巴巴ch scale parameter the noise scale parameter 9n is giv巴n by. 9s to unity, from. 。n = 0.1(lh1(f)12 + Ih (f)12)/(2αnISNR(f)). 2. (13) (13),. (14). Furthermore, we de血児白E住ansfer function ratio (TFR) as. TFR(f) = Ih1(f)/ h (f)12, 2. (15). and if we normalize Ih1 (f)12 to unity in 巴ach台叫uency subband, Ih1(fW + Ih (fW b巴comes1 +1/TFR(f). Finally, we express 2 (12) in lerms of ISNR(J) and TFR(f) as. (. l st+勺,r)12 =. ldl…O.l(関川βη1)αJ (if IstJ(f,rW > ßQ勺2415(mM'(αn, ß,η1 , )αご), rwise ) '1)2IstJ(f,rW (othe. (16). As can be seen, the speech component is subjected to greater sub traction and d凶tortion as ISNR(f) and/or TFR(f) d巴crease. Figure 2 shows the relation between the TFR and the corre sponding value of COS(f) caJcuJat巴d by (10) and (16)目In Fig. 2, we plot th巴 av巴rage of COS(f) over the whole frequency subbands.. 1000 2000 3000 4000 5000 6000 7000 8000 Frequency [Hz). Fig. 3. Typical 巴xampl巴s of TFR(f) (lh1 (f)/九 (fW ) in each fre 2 quency subband, where solid and broken Iines are different combi nations of microphones. The nois巴 shape parameterαn is set to 0.2 with the assumption of super-Gaussian noise, the input SNR is set to 0 dB, and th巴TFR is set from 0.4 to 1.0 (1ん(f)1 is fixed to 1.0). Note that the宵R is highly correlated to the room reverberation and the intereJ巴ment spacing of th巴 microphone array; we d巴termined the range of th巴 TFR by simulating a typical moderately reverberant room and the ar ray with 2.15 cm interelement spacing us巴d in S巴ct. 4. From Fig. 2, when the TFR is dropped to 0.4 and i is mor巴 than 3, th巴 d巴gre巴 of pomt-sourc巴-Iikeness is lower than 0.6. Thus, more than 40% of the speech components cannot be regarded as a point source, and this leads to poor noise estimation. 3.2. Channel selection in ICA. In this subsection, we propose a channel s巴lection strategy in ICA for achieving high accuracy of noise estimation. As mentioned prevト ously, speech distortion is su句ect吋to ISNR(f) and TFR(f), and the accuracy of noise estimation is degrad巴d along with its sp巴巴ch distortion. Figure 3 shows a typical 巴xample of the TFR. From Fig. 3, we can confirrn that the TFRs in different combinations of microphon巴s are nol the same in 巴ach frequency subband; in a spe cific fr巴quency, one microphone pair has higher TFR(f) than an other pair, and vice versa in another fr巴quency. Thus, we are abl巴 to seJect the appropriat巴 combination of the microphones to obtain higherTFR. Therefore, we introduce the channel s巴lection method into ICA in each frequency subband, where we automatically choose less var ied inputs to maintain high accuracy of noise estimation. Hereafter, we d巴scribe the detail of the chanr】巴1 selection method. First, we cal culate the average power of th巴 observed signaJ Xk(f,r) at the kth chann巴1 as. ,. Er [IXk(f, r ) 12] =Er[IS(f,r)12]lhk(f)12 + Er[lnk(f, r)12].. (17). Her巴 Er[ls(f,rW ] is a constant, and iげfw巴 as“m則s乱su叩H川r町町I 白eld, E rベ[1同ηkバ(fr吋)川|門2可 ] i凶s als加sωoa c∞o叩nsta伽n川t. Thus, we can estimate the , relative order of Ihk(f)ドby comparing (17) for every k. Next, we sort Er[lXk(f, r ) 12] in descending order and select the channels k corresponding to high amplitude of Ihk(f)ド satisfying the following condition. mFL[|ZK(fr)|21・5三Er[lxk(f,rW],. (18). where ç( <1) is th巴 threshold for the selectiol】. Finally, we perform noise estimation bas巴d on ICA using the select巴d channels in each frequency subband, and we apply the pro jection back operation to remove the ambiguity of the amplitude and cons廿uct the estimated noise signal.
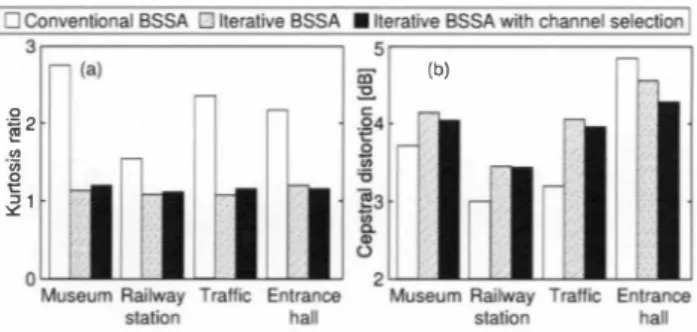
(4) 一o-川= 一 -K一-. S二 計 e二 一川二. A'' vト ' 一T il l-. 一. ea -一 一IhH M 一一 -F. 』 wk d V4副 畑 町M 一R S M. n 日 a副 uh. E c l. 凶. ・ n o ・ 1. c. FL W 叶 ea. E. ' ' 凶. m. 創. d. d. 14s. ・』-u 05. a. u ・. i M. 窃。00 盟百官』 モO一】 - 由主 co. 5 I s O. r. 一w二 一A一一 一S一一. A= 一I. 一 一 一 “日 一e. 一町一戸. 一・一. uuuuu u e. u. k. Since we found the above-mentioned 汀ade-o仔, w巴 next conducted a subjective evaluation for settling the performance competition. In this evaluation,we presented a pair of signals process巴d by the con v巴ntional BSSA and new iterative BSSA in random order to eight examinees, who selected which signal they pref,巴町巴d. The result of the experim巴nt is shown in Fig. 6. It is found that new iterative. -----EC H -n a a d 1 1 1 1 1 3 4 1 ー1 1 111 -u h. 4.3. Subjective evaluation. f O U. First, Fig. 4 shows the typical example of the number of s巴lect巴d chanr】巴Is in each fr巴quency subband based on the propos巴d channel sel巴ctlOn m巴thod for museum noise,and th巴 threshold ç】s set to 0.5. As shown Fig. 4, we use di仔'erent number of microphones in ICA in each frequency subband. This indicates that th巴 channel selection method automatically removes the undesirable channel(s) that has a risk of decreasing the degree of point-sourc巴ーlikeness. Next, Fig. 5 shows a exampl巴 of behaviors for the proposed iterative BSSA under each of noise conditions. ln these 白gures, we depict血e values of the kurtosis ratio defin巴d by (2) and cep合 stral distortion at each iteration; these scor巴s indicat巴 the創nount of musical noise generat巴d and spe巴ch distortion, respectively. The kurtosis ratio for iterative BSSA with/without channel selection in Fig. 5 (a ) is close to 1.0, meanir】g that musical-noise-fr.巴巴 nOlse re duction is achieved. AIso, Fig. 5 (b) shows that speech distortion of the propos巴d iterative BSSA with channel selection is lower than that of the original iterativ巴 BSSA. However,as shown in Fig. 5 (b), a trade-o仔 exists between the amount of musical noise generation and speech distortion in the conventional BSSA and the proposed iterative BSSA except for the entrance hall noise cas巴.. c. 4ふObjective evaluation. l. We conduct巴d objectiv巴 and su同巴ctive evaluation experiments to confirm出e validity of the proposed method. We used an eight element microphon巴 array with an interelement spacing of 2.15 cm, and the direction of the target speech was set to be normal to th巴 ar ray. The size of the experimental room was 4.2 x 3.5 x 3.0 m3 and the r巴verberation time was approximately 200 ms. AlI the signals used in this experiment were sampled at 16 k Hz with 16-bit accu racy. The observed signal consisted of the target signal of six speak ers (three males and thr巴e females) and four types of reaトrecorded diffuse noise (museum noise,railway station noise, 回血c noise, 加d entrance hall noise) 巴mltt巴d from eight suπounding loudspeakers. Th巴 input SNR was 0 dB. The FFT size was 1024,and th巴 frame shift length was 256. We compare the proposed method with the conventional BSSA and iterative BSSA under the same noise reduc tion rate (NRR) [2] condition, wh巴re the NRR is set to 10 dB.. E. 4.1. Experimental conditions. ・. 4. EVALUATION EXPERIMENTS AND RESULTS. m E. 5 E 4 L 劃 ・. F 比M nu. Fig. 4. Typical example of number of sel巴cted channels.. 4 Ill111. 8000. 一一 A一「l l 一一、 加 5 VA-九日一-日二. 7000. E仇一一 一. 6000. ・・・・・・』 附 -創 /一ソ T. 5000. 1 1 』 刷 M Ja h Rs L 圃m a u -au. 4000. Frequency [Hz]. e h二 二 一 m F」二. 氏二 一 ] 二 -n二 一町二 ) -川一-a 一- , 。、 -r-. 3000. : E. 回 一 川 コ nu 《U n ltH 一 @ 一 一 一 一 一 : 一 一 -川 匂 置 二 凶 = 一回 E -H こ ;1 、J 斗内O ' ' 必 B内4 UH E U i I | hH ] l l 一 二 時 割 二 E i - I r i 二 -泊 E w n 川 i j i 」t 副 一 ・ ; i 時 時・ 」 二 。,』 ‘, O Z 伺』 ω a o t コ ¥. 一 一m一「 qd 一円u 口一 一. nu aU 7' au 民d AU寸qu n4 4, 同 一也 c c g 七 万 曲 目U 由 一由 的 』O 』 由 a E コ Z. 1000 2000. (b). 口Conventional BSSA ト斗95% confidential interval 図Iterative BSSA with channel se. ぶぶミミぶぶぶぶぷぶぶぶ際社→ Preference 5∞re [%] 日g. 6. Su対ective evaluation result.. BSSA gains a higher preference score than the conv巴ntional BSSA, indicating the higher sound quality of the proposed method in terms of human perception. 5. CONCLUSION. In出is paper, we propose a modified musical-noise-free BSSA based on ICA-based iterative noise estimation with channel selec tion. From 0句巴ctive and Sl判巴ctive evaluation 巴xperiments,it巴rative BSSA with the channel sele氾tion is advantageous to th巴 conven tional BSSA and the conventional iterative BSSA in terms of sound quality. 6. REFERENCES. [1] J. Benesty, S. Makino, J. Chen, Springer- Ver1ag,2005.. Speech Enhancement,. [2] Y. Takahashi, T. Takatani, K. 0叫(0, H. Saruwatari, K. Shikano, “Blind spatial subtraction array for speech en hancement in noisy environment," IEEE Trans. Audio, Speech, and Lang. Process., vo1.17,no.4, pp.650-664,2009.. [3] P. Comon,“Ind巴pend巴nt component analysis,a new concept?," Signal Processing, vo1.36,pp.287-314, 1994.. [4] S. F. Boll, “Suppression of acoustic noise in sp巴ech using spec. tral subtraction, " IEEE Trans. Acoustics, Speech, and Signal Process., vo1.27, no.2, pp.113-120, 1979.. [5] R. Miyazaki, H. Saruwatari, K. Shikano,K. Kondo, “Musical noise-fr巴e blind sp巴巴ch extraction using ICA-based noise 巴stl mation and it巴rativ巴 sp巴ctral subtraction," Proc. ISSPA20J2 (in printing) [6] R. Miyaz心ci,H. Saruwatari,K. Shikano,K. Kondo, “Musical noise-free sp巴巴ch enhancement: theory and evaluation," Proc. ICASSP20J2, pp.4565-4568,2012.. [7] S. Li,J.-Q. Wang,M. Niu, X.-J. Jing,T. Liu, “Iterative sp削ral subtraction method for millimeter-wave conducted speech en hancement, " Joumal of 8iomedical Science and Engineering, vo1.20 10, no.3, pp.187-192,2010.
(5)
図
関連したドキュメント
In this paper, we extend the results of [14, 20] to general minimization-based noise level- free parameter choice rules and general spectral filter-based regularization operators..
At the same time, a new multiplicative noise removal algorithm based on fourth-order PDE model is proposed for the restoration of noisy image.. To apply the proposed model for
Using the semigroup approach for stochastic evolution equations in Banach spaces we obtain existence and uniqueness of solutions with sample paths in the space of continuous
In Section 3, the comparative experiments of the proposed approach with Hu moment invariance, Chong’s method is conducted in terms of image retrieval efficiency, different
In order to predict the interior noise of the automobile in the low and middle frequency band in the design and development stage, the hybrid FE-SEA model of an automobile was
しかし、 平成 21 年度に東京都内の公害苦情相談窓口に寄せられた苦情は 7,165 件あり、そのうち悪臭に関する苦情は、
If the Output Voltage is directly shorted to ground (V OUT = 0 V), the short circuit protection will limit the output current to 690 mA (typ).. The current limit and short
フロートの中に電極 と水銀が納められてい る。通常時(上記イメー ジ図の上側のように垂 直に近い状態)では、水
