2016 年度卒業論文
素粒子実験データ解析における機械学習の応用
広島大学理学部物理科学科
B131251 坂田麻侑
指導教員:高橋 徹
主査 : 高橋徹
副査 : 岡部信広
平成 29 年 2 月 10 日
第
2
章 機械学習 ... 32.1.
概要 ... 32.2.
カット ... 42.3. BDT(Boosted Decision Tree) ... 4
2.3.1. Ada Boost ... 5
2.4.
ニューラルネットワーク ... 52.4.1.
ニューラルネットワークの学習方法 ... 62.4.2.
誤差逆伝播法 ... 72.4.3.
活性化関数 ... 102.4.4.
単純パーセプトロン ... 112.4.5.
多層パーセプトロン(MLP : Multi Layer Perceptron) ... 122.5.
ディープラーニング ... 122.5.1.
畳み込みニューラルネットワーク(Convolution Neural Network : CNN) .. 13第
3
章 素粒子実験 ... 163.1.
概要 ... 163.2.
標準模型 ... 163.3. ILC
で探索する物理 ... 173.4.
加速器で生成される過程 ... 17第
4
章 検出器 ... 184.1.
概要 ... 184.2.
飛跡検出器 ... 184.2.1.
崩壊点検出器(VTX) ... 194.2.2.
主飛跡検出器 ... 194.3.
カロリメータ... 194.3.1.
電磁カロリメータ ... 194.3.3.
ハドロンカロリメータ ... 204.4.
ミューオン検出器 ... 204.5.
前方検出器 ... 20第
5
章 特徴量を用いた機械学習の利用 ... 215.1.
概要 ... 215.2.
解析条件 ... 215.3.
特徴量 ... 225.3.1.
電磁カロリメータでのエネルギー損失 ... 225.3.5.
不変質量(mdilep) ... 245.3.6.
反跳質量(mercol) ... 255.3.7.
レプトン対角度(acl) ... 255.3.8. xy
平面におけるレプトン対角度(acp) ... 265.3.9. PFO
損失角度(𝑐𝑜𝑠𝑚𝑖𝑠𝑠𝑖𝑛𝑔𝜃) ... 265.4.
結果 ... 28第
6
章4jets
クラスタリングを行い機械学習 ... 346.1.
概要 ... 346.2.
解析条件 ... 346.3.
結果 ... 38第
7
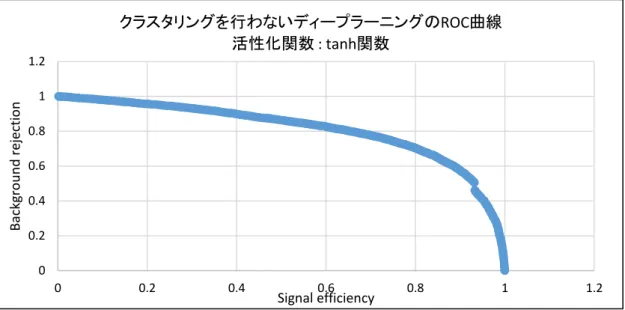
章4jets
クラスタリングを行わず機械学習 ... 417.1.
概要 ... 417.2.
解析条件 ... 417.3.
結果 ... 41第
8
章 結論 ... 43 謝辞44
参考文献 45
図 2.2 ニューラルネットワークの概念図 ... 5
図 2.3 以下の計算で考えるニューラルネットワーク概念図 ... 8
図 2.4 単純パーセプトロンの概念図 ... 11
図 2.5 多層パーセプトロンの概念図 ... 12
図 2.6 CNNの階層の概念図 ... 13
図 2.7 畳み込み概念図 ... 14
図 2.8 叩き込み層概念図 ... 14
図 2.9 プーリング層概念図 ... 15
図 3.1標準模型を構成する素粒子 ... 17
図 5.1 電磁カロリメータでのエネルギー損失の分布 ... 22
図 5.2 ハドロンカロリメータでのエネルギー損失の分布 ... 23
図 5.3 粒子最大運動量の分布 ... 23
図 5.4 レプトンの横運動量の分布 ... 24
図 5.5 粒子の不変質量の分布 ... 24
図 5.6 粒子の反跳質量の分布 ... 25
図 5.7 レプトン対ベクトルの間の角度の分布... 25
図 5.8
xy
平面のレプトン対角度の分布 ... 26図 5.9
𝒄𝒐𝒔𝒎𝒊𝒔𝒔𝒊𝒏𝒈𝜽の分布 ... 27
図 5.10
BDT
のROC
曲線 ... 28図 5.11 活性化関数に
tanh
関数を用いたときのノード数に対するAUC
値 ... 29図 5.12 活性化関数に
tanh
関数を用いたときのAUC
分布 ... 29図 5.13 活性化関数:tanh関数 ノード数
13
の時のROC
曲線 ... 30図 5.14 活性化関数に
sigmoid
関数を用いたときのノード数に対するAUC
値 ... 30図 5.15 活性化関数にシグモイド関数を用いて、ノード数
19
のときのROC
曲線 . 30 図 5.16 活性化関数にradial
関数を用いたときのノード数に対するAUC
値 ... 31図 5.17 活性化関数に
radial
関数、ノード数13
のときのROC
曲線... 31図 5.18 ノード数を
3
に固定して隠れ層を変化させた時のAUC
の値 ... 32図 5.19 ノード数を
3
に固定して隠れ層を変化させた時のAUC
の値 ... 32図 5.20 正則化を行った時の
ROC
曲線 ... 33図 6.1
4jets
の順番を入れ替えない時の4
元運動量 ... 35図 6.2
4jets
の順番を入れ替えない時の4
元運動量 ... 36図 6.3
4jets
の順番をランダムに入れ替えた時の4
元運動量 ... 37図 6.4
4jets
の順番を入れ替えない時のROC
曲線 ... 38図 6.8
4jets
の順番をランダムに入れ替えた時のAUC:0.86
の時のROC
曲線 ... 40 図 6.9 4jetsの順番をランダムに入れ替えたときのAUC
分布 ... 40 図 7.1 衝突終状態の4
元運動量を入力に用いて得られたAUC:0.811
の時のROC
曲線(活性化関数:ランプ関数) ... 41 図 7.2 活性化関数にランプ関数を用いてディープラーニングを
20
回行った時のAUC
分布 ... 41 図 7.3 衝突終状態の4
元運動量を入力に用いて得られたROC
曲線(活性化関数:tanh)... 42
図 7.4活性化関数をtanh
関数としてディープラーニングを10
回行った時のAUC
分布 ... 42
第 1 章 概要
機械学習とは機械が何かを学習する能力をも出せる技術であり人工知能と呼ばれるもの の一種である。人工知能という言葉は
1956
年のダートマス会議で用いられたのが始まりと 言われている。このころ盛んに研究が行われていたのはパーセプトロンという機械学習の アルゴリズムである。しかしパーセプトロンでは線形分離不可能なパターンを識別できな いという欠点が明らかになり、機械学習の発達は停滞した[4]。当時の状況は人工知能が冬 の時代を迎えたと表現されている。1980年代になると機械学習は再びブームを迎えること になった。このブームの立役者となったのはエキスパートシステムと第五世代コンピュー ターシステムである。感染症診断治療支援エキスパートシステム[24]を使うことで新米医師 よりもエキスパートシステムの診断のほうが診断成績が良いという結果を出した。これを 背景に第五世代コンピューターというプロジェクトが推進され機械学習は二回目のブーム が巻き起こった[5]。このころに注目されたのがニューラルネットワークという人の神経細 胞をモデル化した機械学習のアルゴリズムである。ニューラルネットワークは入力層、隠れ 層、出力層からなる階層構造で構成される。ニューラルネットワークをもとに様々な学習を 行うことはできだが3
層以上の構造で上手く学習をさせることが出来なかったため、性能 向上の限界を迎えてしまい、再び機械学習の発達は停滞した。現在、機械学習は三度目のブ ームを迎えている。注目されているのはディープラーニングという機械学習のアルゴリズ ムである。これはニューラルネットワークではできなかった3
層以上の多層の学習を可能 にした。それにより、機械学習のさらなる可能性が期待される。現在まで、素粒子実験のデータ解析においてニューラルネットワークなどの機械学習は 積極的に使われてきた。しかしその特徴の把握や入力パラメータに対する系統的な最適化 が完全になされてきたとは言えない。また、ディープラーニングの素粒子実験データ解析に おける適応可能性はこれからの課題である。現在、素粒子実験データ解析で用いられる入力 データは人間が事象選別のために選んだ特徴量を用いている(例えば検出器で測定される エネルギーや角度など)。今までに使用されてきた学習器としてニューラルネットワークや 決定木 (DT, Decision Tree)などはあらかじめ人が背景事象か信号事象か事象を識別するた めの特徴量を学習器に学習させる必要があるからである。それに対してディープラーニン グはシグナルかバックグラウンドかが未知の事象を学習させることで特徴量を機械が作り 出し、事象の判別をすることが期待される学習方法である。
本研究ではこれまで行われてきた方法として、特徴量を用いたニューラルネットワーク
(
そ の 中 で も 多 層 パ ー セ プ ト ロ ン :MLP)や ブ ー ス テ ィ ン グ を 用 い た 決 定 木 (Boosted
Decision Tree : BDT)についてそれらの比較、 MLP
の構成と性能の比較検討などを行った。さらに、特徴量ではない一般的な量としての粒子の
4
元運動量を入力とした時のMLP、
BDT、ディープラーニングの比較を行い、実験データ解析への応用の可能性を検討した。
本論文では第
2
章に使用した機械学習について述べる。第3
章と4
章では素粒子実験と素粒子実験に使われる検出器について記述する。第
5
章では特徴量を用いてMLP
とBDT
に学習させたその内容と結果について、第6
章と7
章では特徴量ではない一次情報をもとに
MLP、BDT、ディープラーニングの比較を行う。最後に第 9
章で本論文のまとめを記述する。
第 2 章 機械学習
2.1.
概要機械学習は教師あり学習と教師無し学習に分類できる。これらは学習器が扱う入力と出 力に対するフィードバック情報の与えられ方に関する分類である。
教師あり学習とは、機械学習を行う学習器に教師信号を与えることで学習器が訓練デー タについてその出力の正しさを検証して、徐々に入力と出力の関係を学習していく学習の ことである。ここで認識対象に対して、予めわかっている理想的な出力を教師信号と呼ぶ。
画像認識を例にとると、林檎や梨などの果物の画像と、その画像はなんという名の果物に対 応しているかという正解データ(教師信号)を用意して、画像と教師信号をセットで学習させ ることである。
教師なし学習は入力に対して学習器は出力を返すが、それに対する外部からの教師信号 は存在せず、学習器が入力情報のみに従って学習を進める学習のことである。学習は事前に 学習器内部に埋め込まれた規範やアルゴリズムに従って進められる。多くの場合何らかの 評価関数を最大化(もしくは最小化)するようにアルゴリズムが構成されていることが多い。
例えば与えられたたくさんの果物の画像から果物の類似性を判断して、似たような果物を グループ分けしていくようなクラスタリングに使われる。
また、機械学習は入力から出力への変換を学習する存在としてモデル化される。「学習器 は内部に関数を持ち、そのパラメータを学習することによって、入力から出力への変換を行 うことが可能になる」と考えることができる。例えば、後述するニューラルネットワークの 場合は結合荷重を学習する。機械学習においてはパラメータの学習に用いる訓練データと テストデータを区別することが重要である。特に教師あり学習では訓練データに対して教 師信号が与えられるため、入力データを学習器がすべて記憶し、正しい答えの出力ができる ようになることがある。このような現象は過学習と呼ばれる。したがって、過学習を回避し、
訓練データで学習した学習器がテストデータに対して正しい答えを返せるようになる必要 がある。
機械学習を利用してできることの一つにパターン認識がある。パターン認識とはある認 識対象がいくつかの概念に分類可能であるとき、認識対象の持つ特徴を用いてある特定の 概念に分類する処理のことである。この時の概念をクラス(class)、または類(category)とい う。パターン認識を行う際に用いる認識対象の特徴は通常複数あり、それらをまとめて定量 的に表したものを特徴ベクトルと呼び、
𝐱 = (𝑥
1, 𝑥
2, 𝑥
3, … , 𝑥
𝑀)で表される(M:特徴量の数)。特
徴ベクトルによって張られる空間を特徴空間と言う。各認識対象は特徴空間の1
点として 表される。複数の認識対象を考えたとき、同じクラスに属するものは特徴空間上のある領域 に集中することになる。この集中した塊のことをクラスタと呼ぶ。代表的な機械学習の学習器の例として、ナイーブベイズモデル [5]、ニューラルネットワ ーク [4],[5],[8]、決定木 (BDT)[8]、サポートベクトルマシン(SVM)[9]、ディープラーニン グ [6],[11],[12],[13]などが挙げられる。そのなかで、本研究では
BDT
とニューラルネットワーク、ディープラーニングを取り扱った。
2.2.
カットカットとは特徴量ごとにシグナルとバックグラウンドの切り分けを行う。特徴空間内で シグナルとバックグラウンドを識別する面を探すことに相当する。特徴空間において、シグ ナルに相当する空間は一つしかない。また、カット学習器は出力にシグナルかバックグラウ ンドのみのバイナリ応答を返す。
2.3. BDT(Boosted Decision Tree)
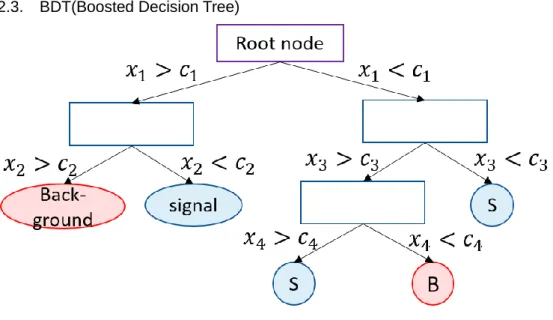
図 2.1: 決定木の概念図
決定木(Decision Tree=DT)とは、各特徴量について、シグナルとバックグラウンドを切り 分け閾値を決定する方法である。シグナルとバックグラウンドが混在した最初の状態を
Root node
という。後述するBoosting
という手法によって性能を向上させたものをBoosted
Decision Tree(BDT)という。BDT
はRoot node
を最もうまく分ける変数を探してシグナルとバックグラウンドを分ける。まず、ある変数の値に対してイベントを分類する。分類され たイベントに対してさらに別の変数の値によってイベントを分類していく。変数の値に対 してイベントを分ける処理を行う部分をノードといい、最終的に分けられたノード(leaf
node)において、イベントがシグナルかバックグラウンドのどちらのノードに属するかによ
って識別する。このような方法を次々と分けられた結果に適応し、この作業を停止させる条 件が満たされるまで続け、一つの決定木が完成する。各ノードで使われる変数は他のノード で使われたことがあるものも考慮され、与えられた変数の中でまったく用いられなかった 変数がある場合もある。カットにおいてもこの決定木を書くことができるがシグナルを示す
leaf node
は一つしかないのに対して、DTでは複数ある。この手法は基本的考え方が簡単なためによく使われる手法ではあるが、統計量が少ない
ときや複数の変数が複雑な関係にある場合にシグナルとバックグラウンドをうまく分けら れないという短所がある。この短所を克服するために
Boosting
という手法が用いられる。Boosting
とは過去の学習の結果を使って、間違った学習と正しい学習の重みを変えて更新することで、学習結果をより安定にする方法である。Boostingの一つに
Ada Boost
とい う手法がある。本研究ではAdaBoost
を用いたのでこれを以下で説明する。2.3.1. Ada Boost
Boosting
とは識別性能の低い弱学習器を複数組み合わせて、識別性能の良い学習器を構成するという考えを基にしたアルゴリズムである。Ada Boostは一つの決定木を選択して、
決定木の出力に対する重みを更新する。重みを変えることで、BDTの弱点を補完する手段 である。まず一つの決定木を作り、最終的に分けられたイベントの中で誤って分類された比
(err)を算出する。この比を用いて
α = 1 − 𝑒𝑟𝑟
𝑒𝑟𝑟 (2-1)
で表される重みを計算し、イベントをご分類した学習器の出力にかける。ただし重みは初め に与えられた重みの総和が保たれるように規格化する。 ある変数群xに対して決定木
h
の出力を
h(x)と定義し、シグナル(h(x)=1)とバックグラウンド(h(x)=-1)とする。 N
個の決定木がある場合、決定木を組み合わせて作られた最終的な学習器としての出力(𝑦𝐵𝑜𝑜𝑠𝑡
(𝑥))は 𝑦
𝐵𝑜𝑜𝑠𝑡= 1
𝑁 ∑ ln(𝛼
𝑖)
𝑁
𝑖=1
ℎ
𝑖(𝑥) (2-2)
と表す。𝑦𝐵𝑜𝑜𝑠𝑡
(𝑥)が小さいほどバックグラウンドに近く、大きいほどシグナルに近い。
2.4.
ニューラルネットワークニューラルネットワークは生物の脳の神経回路の仕組みを模したモデルである。
図 2.2 ニューラルネットワークの概念図
ニューラルネットワークには「入力層」、「隠れ層」、「出力層」とよばれる層を持つ。これら は入力層→隠れ層→出力層と並ぶ。隠れ層はない場合もあれば複数の層を持つこともある。
各層は複数のノード持ち、各ノードは値を持つ。異なる層のノード間は結合荷重によって結 ばれており、上流のノードの出力は結合荷重を通して(出力と結合荷重の積として)歌集のノ ードに入力される。また、ノード間は活性化関数と呼ばれる関数を持つ。活性化関数はノー ドに対する入力に対して出力を決める関数であり、シグモイド関数、tanh関数、ランプ関 数などがある。(2.4.4.参照)
ニューラルネットワークを利用した機械学習では、ニューラルネットワークの結合荷重 の値を最適化することにより、入力値を適切に出力値に変換する方法を定める。このニュー ラルネットワークの入力層に値を入力すると、各層を順番に伝わり、最後に出力ノードの値 が算出される。最終的に出力層の値を出力値として判定処理などに利用する。
2.4.1.
ニューラルネットワークの学習方法ニューラルネットワークでは多くの場合、教師あり学習を通じて、結合荷重の値が最適化 される。結合荷重の最適化は出力層の値と教師データの差を評価する損失関数の和が小さ くなるように行われる。この結合荷重の最適化は勾配降下最適化法という方法が利用され る。
勾配降下最適化法とは数値計算で関数の最小値を算出するときによく利用されるものの 一つである。ある関数が与えられたときにその関数の最小値をとるような変数を求めるこ とを考える。初めに、変数の初期値を定める。その変数の値に応じた関数の勾配を計算する。
次に変数を勾配の方向に動かして次の変数の値とする。これを繰り返すことでこの関数の 最小値となる変数の値に近づけていく。結合荷重を更新するための更新式は以下のように なる。
𝜔
𝑘+1= 𝜔
𝑘− 𝜂 𝜕𝐸
𝜕𝑤
𝑘(2-5)
𝜔
𝑘+1はk+1
層での変数の値であり、E
は教師信号と出力をパラメータにもつ損失関数、𝜔 は関数f
のパラメータ、𝜕𝑓𝜕𝑦は勾配、
𝑥
𝑖+1は次の変数の値、εは学習率である。勾配降下最適化
法で必要となるのは1. 最適化される変数(結合荷重の値) 2. 最小化する関数(損失関数) 3. 最小化する関数の勾配
の
3
つである。最適化される変数は、損失関数によって求められた出力と教師信号の偏差 を全訓練データ分合計した値が最小になるように計算するので、教師データ数が多いほど 計算する数も増える。そのため、収束が速い計算方法や、局所解に入りにくい計算方法が考 案された。その中の一つが確率的勾配法である。確率的勾配法とははじめに訓練データの中からランダムにデータを複数選ぶ。選ばれた データの損失関数のみを使って変数の値を変更する。変数が修正された訓練データの中か ら再びランダムにデータを選び、変数の値を変更する。この方法を繰り返すことで変数の値 を更新する。確率的勾配法は損失関数の総和をとるデータの数が少ないので、すべてのデー タを利用して更新処理を行うバッチ法よりも一回当たりの更新処理を高速に行うことがで きるため、アルゴリズムの収束速度が速い。損失関数を最小化するようにパラメータの修正 を行う方法の一つが誤差逆伝播法である。
2.4.2.
誤差逆伝播法誤差逆伝播法は出力層から入力層にかけて誤差を逆伝播させて各パラメータの修正量を 決める。ニューラルネットワークで最適化されるパラメータは結合荷重である。
ニューラルネットワークのあるノード
j
は前の層のノードの出力の和を入力として受け る。すると前の層の出力を𝑜𝑖としたときに、あるノードj
への入力𝑢𝑗は𝑢
𝑗= ∑ 𝜔
𝑖,𝑗𝑜
𝑖𝑚
𝑖=1
(2-6)
と書ける。𝜔
𝑖,𝑗は前の層i
番目のノードと次の層j
番目のノードの間の結合荷重、ノードj
か らの出力𝑜𝑗は𝑜
𝑗= 𝑓(𝑢
𝑗) (2-7)
と書ける。出力と教師信号をパラメータに持つ損失関数
E
を考えるとノードからの出力は ノード間の結合荷重によって決まるので、誤差関数は結合荷重によって定義された関数と 言える。そのため任意の重みの状態から損失関数の極小値に達するためには結合荷重を∆𝜔
𝑖,𝑗= η ∂E
∂𝜔
𝑖,𝑗(2-8)
ずつ変化させればよい。これを一般に行うと∆𝜔の評価一回毎に信号伝播の計算が必要なた め、計算量が膨大になる。膨大な計算を回避し、現実的な量の計算で可能にしたのが誤差逆 伝播法である。
誤差逆伝播法は入力層と出力その間に任意の個数の隠れ層を設けたニューラルネットワ ークに対する、教師あり学習の代表的方法である。入力データが与えられたとき、その出力 層の値と、教師信号の値の差を小さくするようにニューラルネットワークの各結合荷重が 修正されていく。誤差逆伝播法では、あるノードの学習に使われる情報は下流のノードの情 報のみである。誤差逆伝播法の考え方は以下のような手順である。
1.
学習用に、入力層への入力パターンベクトルと出力層からの出力(教師信号)を用 意する。2.
入力層、隠れ層、出力層の順に各ノードの出力を計算する。3.
教師信号と実際の出力の損失を計算する。4.
教師信号と実際の出力の損失関数が減少するように、出力層から入力層に向かっ て、ニューラルネットワークの各層間の結合荷重を修正する。5.
全てのパターンに対する誤差が設定値以下になれば計算を終了する。設定値以上 であれば2に戻る上記のことを詳しく式で見ていく。前提として
m
層から構成されるニューラルネットワー クを考えることとする。図 2.3 以下の計算で考えるニューラルネットワーク概念図
第
k-1
層の(𝑛𝑘−𝑖+1)番目に常に出力値 1
をとるバイアスノードを仮定すると、イベントp
を提示したときの第k層(k=1,2,3,..,m)j番目の入力値𝑢𝑝,𝑗𝑘 は次式のように表される。
𝑢
𝑝,𝑗𝑘= ∑ 𝜔
𝑖,𝑗𝑘−1,𝑘𝑛𝑘−1+1
𝑖=1
𝑜
𝑝,𝑖𝑘−1(2-9)
𝜔
𝑖,𝑗𝑘−1,𝑘は第k-1
層i
番目のノードと第k
層j
番目のノードとの結合荷重である。k層j
番目の出力値𝑜𝑝,𝑗𝑘 は以下のようになる
𝑜
𝑝,𝑗𝑘= 𝑓
𝑗𝑘(𝑢
𝑝,𝑗𝑘) (2-10)
𝑓
𝑗𝑘は第k
層j
番目のノードの活性化関数である。イベントp
の出力層(m層)I番目のノード 出力値に対する教師信号を𝑡𝑝,𝑖𝑘 、ニューラルネットワークの評価関数として、出力層の出力 に対する教師信号と実際の出力値𝑜𝑝,𝐼𝑚の損失関数E
を考える。以下では、簡単のために損失 関数は教師信号と出力の2
乗誤差とする。𝐸
𝑝= 1
2 ∑(𝑡
𝑝,𝑖𝑚− 𝑜
𝑝,𝑖𝑚)
2𝑛𝑚
𝑖=1
(2-11) 𝐸 = ∑ 𝐸
𝑝𝑝
(2-12)
E
pはイベントp
における損失関数の値、Eは全イベントに対する損失関数の結合荷重𝜔𝑖,𝑗𝑘−1,𝑘を損失関数が小さくなるように変化させればよい。
E
pは𝜔𝑖,𝑗𝑘−1,𝑘を間接的に含 むので結合荷重の変化量は∆
𝑝𝜔
𝑖,𝑗𝑘−1,𝑘∝ − 𝜕𝐸
𝑝𝜕𝜔
𝑖,𝑗𝑘−1,𝑘(2-13)
という関係が成り立っている。また右辺は次のように分解できる。
𝜕𝐸
𝑝𝜕𝜔
𝑖,𝑗𝑘−1,𝑘= 𝜕𝐸
𝑝𝜕𝑢
𝑝,𝑗𝑘・ 𝜕𝑢
𝑝,𝑗𝑘𝜕𝜔
𝑖,𝑗𝑘−1,𝑘(2-14)
ここで式(2-14)の右辺の積第
1
項は第k
層へのノードj
への入力𝑢𝑝,𝑗𝑘 の変化が損失関数E
pに 与える影響を表す項である。また、右辺の積第2
項は第k-1
層のノードi
と第k
層のノー ドj
の結合荷重𝜔𝑖,𝑗𝑘−𝑖,𝑘の変化が第k
層のノードj
の入力𝑖𝑝,𝑗𝑘 に与える影響を表す項である。式(2-6)を用いると式(2-14)の右辺の積第
2
項は次式のように表せる。𝜕𝑢
𝑝,𝑗𝑘𝜕𝜔
𝑖,𝑗𝑘−1,𝑘= 𝜕
𝜕𝜔
𝑖,𝑗𝑘−1,𝑘∑ 𝜔
𝑖,𝑗𝑘−1,𝑘𝑛𝑘−1+1
𝑙=1
𝑜
𝑝,𝑙𝑘−1= 𝑜
𝑝,𝑖𝑘−1(2-15)
また、式(2-13)は比例定数𝜂を用いて次式のように表すことができる。
∆
𝑝𝜔
𝑖,𝑗𝑘−1,𝑘= −𝜂 𝜕𝐸
𝑝𝜕𝑢
𝑝,𝑗𝑘𝑜
𝑝,𝑖𝑘−1(2-16)
よって𝜂が定数で、𝑜𝑝,𝑖𝑘−1が既知の値であることから、結合荷重の修正量∆𝑝
𝜔
𝑖,𝑗𝑘−1,𝑘は𝜕𝐸𝑝𝜕𝑢𝑝,𝑗𝑘 を計 算することで求めることができる。
𝜕𝐸𝑝
𝜕𝑖𝑝,𝑗𝑘 は次式のように分解することができる。
− 𝜕𝐸
𝑝𝜕𝑢
𝑝,𝑗𝑘= − 𝜕𝐸
𝑝𝜕𝑜
𝑝,𝑗𝑘・ 𝜕𝑜
𝑝,𝑗𝑘𝜕𝑢
𝑝,𝑗𝑘(2-17)
式(2-14)の右辺第2項は式(2-10)から入出力関数の1次導関数であり
𝜕𝑜
𝑝,𝑗𝑘𝜕𝑢
𝑝,𝑗𝑘= 𝜕𝑓
𝑗𝑘(𝑢
𝑝,𝑗𝑘)
𝜕𝑢
𝑝,𝑗𝑘(2-18)
となる。式(2-17)の右辺第
1
項を計算する場合以下の2
つの場合に分けて考える必要があ る。1.
出力層のノードI
の出力値𝑜𝑗𝑚の変化の損失関数E
pへの影響を考える場合2.
入力層または隠れ層における第k
層のニューロンj
の出力値𝑜𝑗kの変化の損失関数
E
pへの影響を考える場合まず、1.の場合を考えると式(2-17)の右辺の積第
1
項は式(2-9)より𝜕𝐸
𝑝𝜕𝑜
𝑝,𝐼𝑚= −(𝑡
𝑝,𝐼𝑚− 𝑜
𝑝,𝐼𝑚) (2-19)
と書くことができるので、1.の場合式(2-17)は以下のようになる。𝜕𝐸
𝑝𝜕𝑢
𝑝,𝐼𝑚= (𝑡
𝑝,𝐼𝑚− 𝑜
𝑝,𝐼𝑚) 𝜕𝑓
𝐼𝑚(𝑢
𝑝,𝐼𝑚)
𝜕𝑢
𝑝,𝐼𝑚𝑗 = 1,2,3, … , 𝑛
𝑚(2-20)
次に
2.の場合について考えると式(2-17)の右辺第 1
項は次式のようになる。𝜕𝐸
𝑝𝜕𝑜
𝑝,𝑗𝑘= ∑ 𝜕𝐸
𝑝𝜕𝑢
𝑝,𝑙𝑘+1・𝜕𝑢
𝑝,𝑙𝑘+1𝜕𝑜
𝑝,𝑗𝑘𝑛𝑘+1
𝑙=1
= ∑ 𝜕𝐸
𝑝𝜕𝑢
𝑝,𝑙𝑘+1・𝜕 ∑
𝑛ℎ=1𝑘+1𝜔
ℎ,𝑙𝑘,𝑘+1𝑜
𝑝,𝑗𝑘𝜕𝑜
𝑝,𝑗𝑘𝑛𝑘+1
𝑙=1
= ∑ ( 𝜕𝐸
𝑝𝜕𝑢
𝑝,𝑗𝑘+1𝜔
𝑗,𝑙𝑘,𝑘+1)
𝑛𝑘+1
𝑙=1
(2-21)
式(2-17),(2-18),(2-21)から式(2-17)は次式のようになる
𝜕𝐸
𝑝𝜕𝑢
𝑝,𝑗𝑘= 𝜕𝑜
𝑝,𝑗𝑘𝜕𝑢
𝑝,𝑗𝑘∑ ( 𝜕𝐸
𝑝𝜕𝑢
𝑝,𝑗𝑘+1𝜔
𝑗,𝑙𝑘,𝑘+1)
𝑛𝑘+1
𝑙=1
𝑗 = 1,2,3, … , 𝑛
𝑚, 𝑘 = 2,3, … , 𝑚
(2-22)
式(2-20)に教師信号𝑡𝑝,𝑖𝑚
,m
層の出力値𝑜𝑝,𝑗𝑚を代入することで𝜕𝐸𝑝𝜕𝑢𝑝,𝐼𝑚が求まる。さらに式(2-16)に
𝜕𝐸𝑝
𝜕𝑢𝑝,𝐼𝑚を代入することで
m-1
層とm
層の間の結合荷重の修正量∆𝑝𝜔
𝑖,𝑗𝑚−1,𝑚が求まる。次に式(2-22)に今求めた𝜔
𝑖,𝑗𝑚−1,𝑚、𝜕𝐸𝑝𝜕𝑢𝑝,𝑗𝑚と既存の𝑜𝑝,𝑗𝑚−1を用いると 𝜕𝐸𝑝
𝜕𝑢𝑝,𝑗𝑚−1が求まり、式(2-16)に 𝜕𝐸𝑝
𝜕𝑖𝑝,𝑗𝑚−1を代入 すると第
m-2
層と第m-1
層の結合荷重修正量∆𝑝𝜔
𝑖,𝑗𝑚−2,𝑚−1を求めることができる。同様に計 算すると結合荷重修正量が下流から上流へと順次求まっていく。求められた結合荷重修正 量を用いて、勾配降下最適化法(2.4.1参照)に従って結合荷重が求められていく。2.4.3.
活性化関数活性化関数とは各層のノードの出力値を計算する関数である。活性化関数でよく使われ るのはシグモイド関数、tanh関数、ランプ関数であり、以下のよう表せられる。
シグモイド関数
y = 1
1 + 𝑒
−𝜀𝑥(2-23)
tanh
関数y = 𝑒
𝑥− 𝑒
−𝑥𝑒
𝑥+ 𝑒
−𝑥(2-24)
ランプ関数
y = { 0 (𝑥 < 0)
𝑥 (𝑥 ≥ 0) (2-25)
シグモイド関数や
tanh
関数は値が大きくなると関数の勾配が0
に近づくため、関数の学習 が進まなくなる。そのため近年ではランプ関数がよく使われている。2.4.4.
単純パーセプトロン図 2.4 単純パーセプトロンの概念図
単純パーセプトロンはニューラルネットワークの一種であり、入力層と出力層から成る。入 力を𝐱 = (𝑥1
, 𝑥
2, 𝑥
3, … , 𝑥
𝑀)としたとき、単純パーセプトロンの出力 Z
はy = ∑ 𝑎
𝑖𝑥
𝑖+ 𝑎
0𝑀
𝑖=1
(2-26)
Z = f(y) (2-27)
で表される。ここで𝑎𝑖は入力層の
i
番目のニューロンから出力層への結合荷重、𝑎0はバイア ス、fは活性化関数である。バイアスノードは常に次の層に対して1の出力を出す。そのた め結合荷重を𝒂 = (𝑎1, 𝑎
2・・・𝑎𝑀)とすると式(2-26)は
y = 𝒂
・𝒙 (2-28)
と書くことができる。
前述した方法(2.4.1、
2.4.2
参照)で最適化された結合荷重を用いることで、式(2-28)から特 徴空間を分割する平面を探し出すことが出来、出力ベクトルを線形分離することができる。2.4.5.
多層パーセプトロン(MLP : Multi Layer Perceptron)多層パーセプトロンは入力層と出力層の間に一層以上の隠れ層を用いた構造である。多層 構造を持つことで単純パーセプトロンの欠点であった非線形分離を可能にした。多層パー セプトロンの構造は各層に値を持つノードを持ち、通常入力層と隠れ層にはバイアスノー ドという値が1に固定されたノードを持つ。
隠れ層を増やしていくことでより正確な非線形分離ができると考えられるが実際には、
ニューラルネットワークは階層を深くしてもあまり性能が向上しないことが知られている。
前節(2.4.2)で述べたように結合荷重の修正される量
∆𝜔
𝑘−1,𝑘はk
層の損失関数の偏微分係数 が必要であり、そのためにk-2,k-1
層間の結合荷重が必要になる(前の層の出力が必要なた め)。今まで使用されてきた活性化関数の導関数の値は1
未満であることが多く層を重ねる ごとに勾配が減衰してしまう[13]。よって多層パーセプトロンでは出力層に近い層では結合 荷重は大きな変動をし、入力層に近い層では大きな変動を示さない。入力層で近い層での結 合荷重の変動が大きくないとはいえ、極小値は存在する。そのため出力層に近い層での結合 荷重だけではなく入力層に近い層での結合荷重も適切に最適化しなければならない。損失 関数は結合荷重をパラメータに持つ関数であるが、このパラメータが張る空間での損失関 数の勾配は大きい方向と小さい方向とが混在する。このような場合勾配法では現実的な時 間で最適化が収束しないことが知られている[13]。2.5.
ディープラーニングディープラーニングとは、多層のニューラルネットワークの総称を指す。ニューラルネッ トワークの多層化は前節で説明した問題があったが、多層のニューラルネットワークを学 習する有効な手段が提案されたために、現実的な手法となった。これまでのニューラルネッ トワークは各層の重みを同様に扱っている。その結果として出力層に近い層の重みが重要 視された。それに対してディープラーニングでは各層に役割を持たせることによって多層 の教育ができるようになった。すなわち、役割の持った層によって特徴量が抽出されると考
図 2.5 多層パーセプトロンの概念図
えることができる。その代表的なアルゴリズムの一つに畳み込みニューラルネットワーク
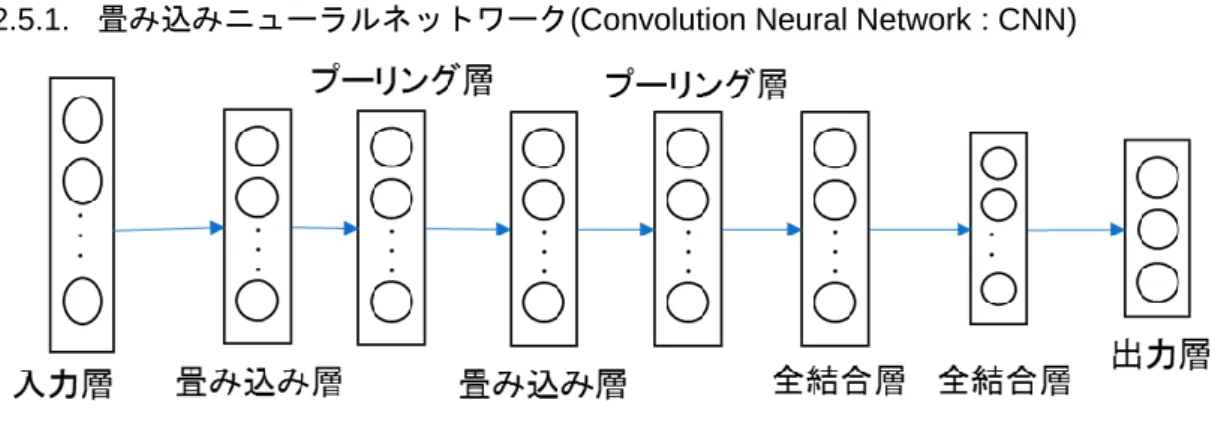
(Convolution Neural Network : CNN)が挙げられる。以下、CNN
について記述する。2.5.1.
畳み込みニューラルネットワーク(Convolution Neural Network : CNN)図 2.6 CNNの階層の概念図
CNN
は「畳み込み層」と「プーリング層」、「全結合層」と呼ばれる層を持つニューラル ネットワークである。典型的なCNN
は図2.5
のように畳み込み層とプーリング層という特 殊な層を交互に設置し、出力層付近には1
層以上の全結合層を置いた構造から成る。全結 合層とは前の層のノードと次の層のノードがすべて結合荷重で結ばれている層であり、ニ ューラルネットワークの隠れ層と同じ働きを持っている。畳み込み層とプーリング層を持 つこと以外は多層パーセプトロンと変わらず、あるj
層からの出力𝑧𝑗は𝑦
𝑗= ∑ 𝑎
𝑖𝑥
𝑖+ 𝑎
0𝑀
𝑖=1
(2-34)
𝑧
𝑗= f(𝑦
𝑗) (2-35)
と書ける。Mは
j
層におけるノードの数、𝑎𝑖は入力層のi
番目のニューロンから出力層へ の結合荷重、𝑎0はバイアス、fは活性化関数である。近年、活性化関数にはランプ関数がよ く使われている。以下、例として画像認識を行うときを仮定して畳み込み層とプーリング層 について述べる。2.5.1.1.
畳み込み層図 2.7 畳み込み概念図
畳み込み層では入力画像に対して、フィルタを掛けることで入力画像の局所的な部分の 特徴抽出を行う。入力に
W×W
サイズの画像を用いるとし、H×Hサイズのフィルタを入 力画像にかける。すると入力画像は新たな画像に叩き込まれる。入力画像の画素(i,j)の画素 値を𝑥𝑖,𝑗(i=0,・・・,W-1、 j=0,・・・,W-1)、フィルタ(p,j)の画素値をℎ
𝑝𝑞(p=0,・・・,H-1、 p=0,・・・,H- 1)とすると
𝑎
𝑖𝑗= ∑ ∑ 𝑥
𝑖+𝑝,𝑗+𝑝ℎ
𝑝𝑞𝐻−1
𝑞=0 𝐻−1
𝑝=0
(2-36)
という値が得られる。得られた𝑎𝑖𝑗はその後活性化関数
f(a)を経て次の層への出力𝑦
𝑖,𝑗𝑦
𝑖,𝑗= f(𝑎
𝑖𝑗) (2-36)
となる。入力画像上でフィルタを移動させることで入力画像にかけるフィルタの位置を変 化させて一枚の畳み込み画像(特徴マップ)を作る。このフィルタは一種類ではなく
2
種類以 上かけることができる。フィルタ一種類につき一枚の画像に入力画像を叩き込むので、フィ ルタの種類だけ特徴マップが存在する(図2.8)。フィルタはニューラルネットワークにおけ
る結合荷重のようなものとして考えることができ、フィルタの画素値ℎ
𝑝𝑞を学習する。図 2.8 叩き込み層概念図
2.5.1.2.
プーリング層プーリング層は通常畳み込み層の後ろに設置される。プーリング層では畳み込み層で作 られた特徴マップの小領域から値を出力し、次の層への入力へ変換を行う(プーリング)。こ の値の変換方法は複数あるがよく使われる方法は小領域の最大値を一つとる方法である。
最大値をとることで小領域における微小変化が生じてもプーリング層にはほとんど同じ値 が出力される。そのため、画像内に現れる特徴の微小な位置変化に対する応答の不変性を実 現する[15]。プーリング層において、畳み込み層小領域の大きさや値を抽出する計算内容な どは設計時に決まり、学習するパラメータは存在しない。
図 2.9 プーリング層概念図
CNN
では畳み込み層で局所的な特徴を抽出し特徴マップを作成、プーリング層では特 徴マップの小領域の値の変換を行い新たな画像を作り出す。畳み込み層とプーリング層を 複数層積み重ね最後に全結合層を設けることで従来のニューラルネットワークよりも精度 の良い画像認識を可能にした。第 3 章 素粒子実験
3.1.
概要素粒子物理学とは、「物質を構成する最も基本的な粒子とは一体何か」・「最も基本的な粒 子を支配する物理法則とは一体何か」を探求する学問のことである。現在、標準模型を構築 するに至っている。標準模型は、現在の素粒子物理学の中で最も成功している理論体系であ るが、完全な理論ではなく、解決のできない問題もある。そのため、素粒子物理学が次に行 うべきことは、この標準模型を超える新物理の探索である。その手掛かりの一つがヒッグス 粒子である。ヒッグス粒子は標準模型でその存在が予言されていながら長らく発見されて いなかった粒子であるが
2012
年に大型ハドロン加速器(LHC)で発見された[20][21]。LHC は欧州原子核研究機構(CERN)が要する陽子・陽子衝突型の円形加速器である。しかし、LHC
で発見されたヒッグス粒子のさらなる検証においてLHC
よりも精密な測定が必要となる。そのために最適な手段として計画されているのが
ILC(国際リニアコライダー)である。ILC
は電子・陽電子衝突型の線形加速器で、ヒッグス粒子やトップクォークなどの質量の大きな 素粒子を生成することのできる装置である。ILC は内部構造の内素粒子である電子と陽電 子を用いるため、現象の精密測定に適している。今後ILC
の精密測定を通した、ヒッグス 粒子の詳細な性質の解明や新現象の発見が期待される。3.2.
標準模型標準模型は、現在素粒子物理の中で最も成功している体系である。標準模型はゲージ原理 とヒッグス機構の
2
つの柱から構成されている。この模型を構成する粒子は全部で18
種類 ある。まず、3世代6
種類のレプトンとして荷電レプトン(電子(e)、ミューオン(μ),タウ(τ)) と対応するニュートリノ(𝜈𝑒, 𝜈
𝜇, 𝜈
𝜏)、 3
世代6
種類のクォーク(アップ(u)、ダウン(d)、チャー ム(c)、ストレンジ(s)、トップ(t)、ボトム(b))、力を媒介するベクトルボソンとしては電磁相 互作用を媒介する光子(γ)、弱い相互作用を媒介するZ
ボソン、𝑊
±ボソン、強い相互作用を 媒介するグルーオン(g)、そして最後に素粒子の質量の起源となっているスカラーボソンで あるヒッグス粒子(h)が存在している。図
3.1
は標準模型構成粒子を分類した表である。物質粒子と呼ばれるクォーク・レプトン は半整数スピンを持ち、陽子や中性子といったさらに大きな物質を構成する要素である。3.3. ILC
で探索する物理国際リニアコライダー(International Linear Collider, ILC)は次世代の電子・陽電子衝突 させて行う実験設備であり、全長
31km
の線形加速器である。電子・陽電子衝突の重心系エ ネルギーが250GeV~500GeV
までによる実験を行う計画である。その後アップグレードに よる1TeV
の実験も計画されている。ILC
で研究される予定の物理はヒッグスの物理やトッ プクォークの精密測定、標準模型を超えた物理の探索など多岐にわたる。本研究では電子・陽電子を衝突させた時に生じる事象の識別を行うので以下で簡単に説明する。
3.4.
加速器で生成される過程標準模型に含まれるヒッグス粒子の場合、電子・陽電子衝突で生成される主な過程は
𝑒
+𝑒
−→ Zhと𝑒
+𝑒
−→ 𝜈
𝑒𝜈 ̅ ℎである。Z
𝑒 粒子やヒッグス粒子は一定の確率でレプトンやクォ ーク対に崩壊する。また、例えば𝑒+𝑒
−→ 𝑞𝑞̅などの過程でもクォークが生成される。クォ
ークは単独では存在せず、生成された後、新たにハドロンを形成する。これを繰り返しな がら大量の粒子群が出できる。これをジェットという。クォーク生成のシグナルとして電 子・陽電子衝突実験で実際に検出されるのは崩壊後のジェットである。図 3.1標準模型を構成する素粒子
第 4 章 検出器
4.1.
概要ILC
に 設 置 さ れ る 予 定 の 検 出 器 はILD(International Large Detector)
測 定 器 とSiD(Silicon Detector)測定器の 2
つである。実際にはこの2
つの測定器を並べてスライドさせて、ビームラインに設置する測定器をその都度交換し、測定を行うことが計画されている。
本解析では
ILD
測定器を想定したデータサンプルを用いているのでILD
測定器について述 べる[22]。図4.1
はILD
検出器の全体図である。図 4.1 ILD測定器全体図[8]
ILD
測定器はビーム軸に対象に設計されており、内側から
飛跡検出器
崩壊点検出器
主飛跡検出器
カロリメータ
電磁カロリメータ
ハドロンカロリメータ
ソレノイドコイル
ミューオン検出器
前方検出器という構造になっている。
4.2.
飛跡検出器飛跡検出器は崩壊点検出器、シリコン内部検出器、中央飛跡検出器、シリコン外部検出器 から構成される。また、後述するカロリメータがソレノイドコイルに囲まれているため、ソ レノイドの磁場によって荷電粒子は曲げられるが、飛跡検出器によってその曲率半径(飛跡) を求めることで、磁場の強さから運動量が計算できる。
4.2.1.
崩壊点検出器(VTX)崩壊点検出器はビームの衝突点から最も近い位置に設置される検出器である。VTX の役 割は崩壊点の位置を測定、bクォーク、cクォーク同定を行うことである。崩壊点検出器は 通過する荷電粒子の位置を精密に測定することができるのでそこから二次粒子の崩壊点を 測定することができる。
4.2.2.
主飛跡検出器ILD
測 定 器 の 飛 跡 検 出 器 と し て 主 飛 跡 検 出 器 で あ る 時 間 投 射 測 定 器(TPC:Time Projection Chamber)とシリコン飛跡検出器の二つがある。
TPC
はガス検出器であり、TPC
内に充満しているガスをイオン化させる。TPC
内を通過 する荷電粒子によって分離された陽イオンと電子を、一様電場をかけることで読み出し面 へ移動させて電気信号として読み取る。そこから荷電粒子の飛跡の3
次元的(r, φ, z)な再構 成を行うことで粒子の運動量の測定を行うことができる。VTX でも飛跡の再構成を行って いるがVTX
が各レイヤーにおけるヒット点から飛跡が得られるのに対して、TPC
では連続 的な飛跡を得ることが可能である。シリコン飛跡検出器は
TPC
の前方検出部分やTPC
とVTX
の間などに設置し、飛跡の時 間情報を取得する。シリコン飛跡検出器とTPC
を併用することで運動量分解能が向上する。4.3.
カロリメータILD
測定機におけるカロリメータは内側から電磁カロリメータ(ECAL)とハドロンカロリメ ータ(HCAL)から構成される。カロリメータの役割は通過する粒子に内部でシャワーを発生 させることで粒子の損失したエネルギーを測定することである。ECAL は電磁相互作用に よる電磁シャワー発生させ、HCAL は強い相互作用や原子核との衝突によるハドロンシャ ワーを発生させる。シャワー粒子を検出することでジェット中の粒子のエネルギー損失を 見積もることができる。またこの検出器の反応は実際のエネルギーと比例するように設計 される。4.3.1.
電磁カロリメータ電磁カロリメータの目的は光子や荷電ハドロン、電子のエネルギーの測定である。荷電粒 子や光子は電磁カロリメータ中で、電磁相互作用による対生成と対衝突を繰り返し、電磁シ ャワーを発生させる。 電磁カロリメータは粒子にシャワーを発生させるエネルギー吸収 層と、電磁シャワーを検出するセンサー層から成る。吸収層からエネルギーが測定でき、セ ンサー層からは
2
次粒子の位置が測定できる。その後のデータ解析でシャワーの形を得る ことができるので、元の粒子が何であったかが識別することができる。4.3.3.
ハドロンカロリメータハドロンカロリメータはハドロンのエネルギーを測定することが目的である。中性ハド ロンから作られるハドロンシャワーは電磁シャワーを比べて反応が複雑である。これはハ ドロンシャワー中では強い相互作用によるものだけでなく電磁相互作用も同時に起きてし まうため、これらの相互作用によるエネルギー損失が違うこことシャワー内の反応比率が 事象ごとに違うからである。そのため、ハドロンカロリメータの分解能は電磁カロリメータ の分解能に比べて悪い。しかし、中性ハドロンはハドロンカロリメータによってはじめて観 測されるので、重要な検出器である。
4.4.
ミューオン検出器ミューオン検出器の目的はミューオンの同定とカロリメータで測定しきれなかったエ ネルギーの測定と回収である。ミューオン検出器とカロリメータの併用はジェットエネル ギー分解能を向上する。
4.5.
前方検出器ビームパイプに非常に近い前方領域部分には前方検出器と呼ばれる検出器群が置かれる。
これらの測定器によってビームパイプ付近の前方領域部分の測定を可能にするため、損失 エネルギーの測定精度が向上する。
第 5 章 特徴量を用いた機械学習の利用
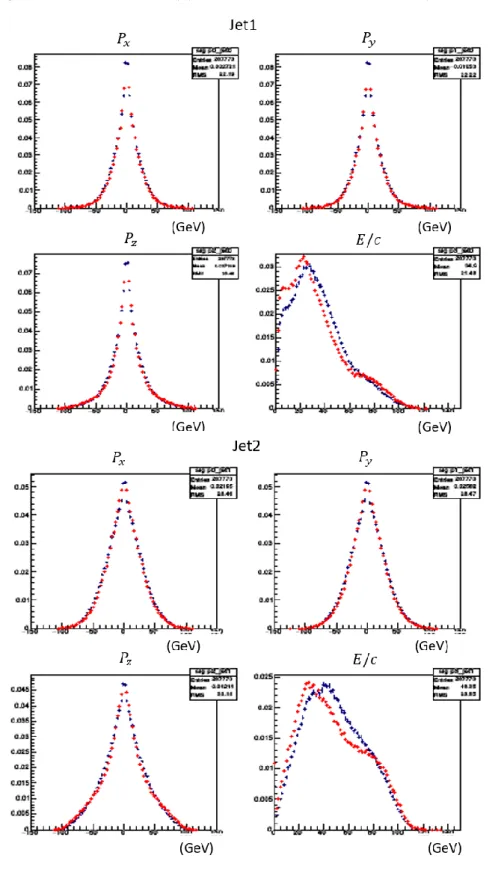
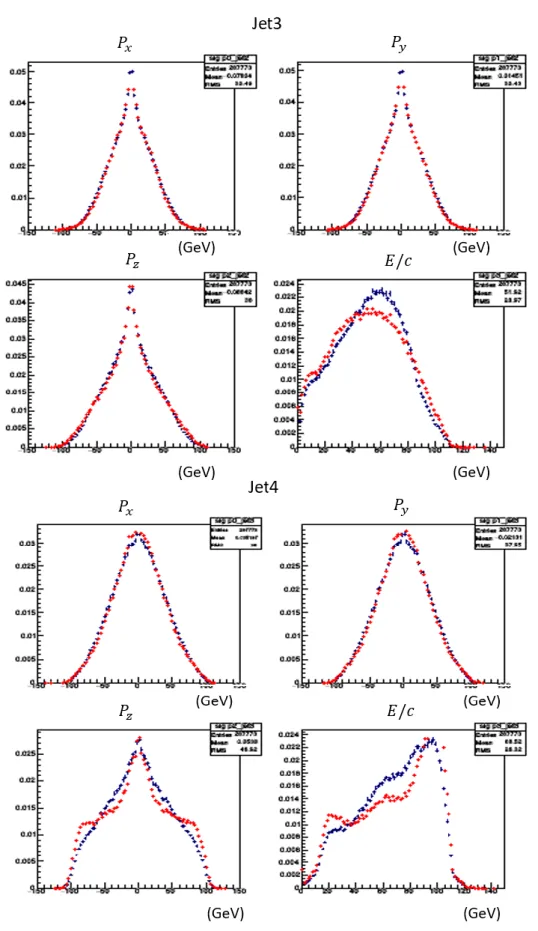
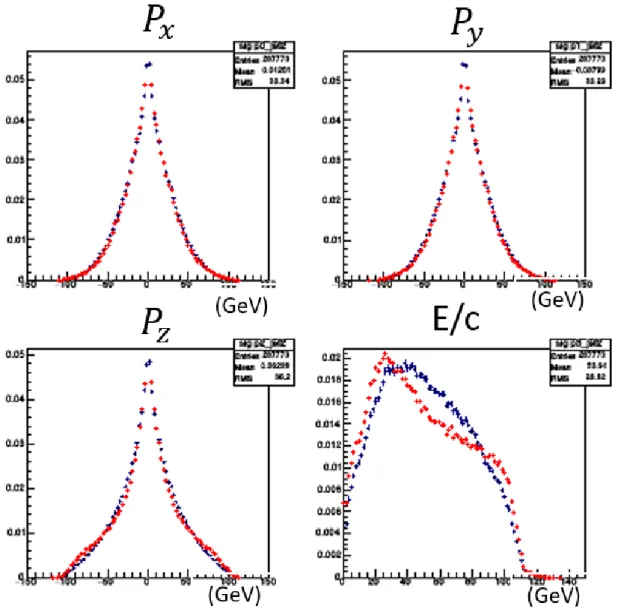
5.1.
概要シグナルとなる
𝑒
+𝑒
−→ 𝑧ℎ事象とその他背景事象(バックグラウンド)との識別性能を BDT
とニューラルネットワークで調べた。またこのとき学習器に学習させるための特徴と して、測定器で検出されるシグナルとバックグラウンドの違いを利用したものを用いた(5.2 参照)。まず、入力データとなる事象生成を行う。事象生成で使用された
WHIZARD[15]は多粒子
の散乱断面積の計算およびシミュレーションにおけるサンプル作成のためのジェネレータ ープログラムの呼称である。また、機械学習のパッケージとして多変量解析ツールTMVA[16]内の BDT
とMLP(TMVA
内におけるニューラルネットワーク)を使用している。5.2.
解析条件本研究で電子・陽電子衝突から生成された事象でシグナル・バックグラウンドと定義した ものが以下の表である。WHIZARD によって事象を生成したあと,個々の粒子の運動量と エネルギーを,
ILD
測定器の運動量分解能,エネルギー分解能を想定して「ぼかす」ことに よって,実際の測定に近い条件で解析した。シグナル
𝑒
−𝑒
+→ 𝑍ℎ → 𝜇
−𝜇
+ℎ
バックグラウンド
𝑒
−𝑒
+→ 𝑍𝑍 → 𝜇
−𝜇
+𝜇
−𝜇
+𝑒
−𝑒
+→ 𝑍𝑍 → 𝜇
−𝜇
+𝜏
−𝜏
+𝑒
−𝑒
+→ 𝑍𝑍 → 𝜇
−𝜇
+𝑒
−𝑒
+𝑒
−𝑒
+→ 𝑍𝑍 → 𝜇
−𝜇
+𝜈𝜈̅
𝑒
−𝑒
+→ 𝑍𝑍 → 𝜇
−𝜇
+𝑞𝑞̅
𝑒
−𝑒
+→ 𝑍ℎ → 𝑒
−𝑒
+ℎ
表 5.1 用いた信号のシグナルとバックグラウンドの定義訓練データのイベント数は
35007
個、そのうちシグナルが5001
個、バックグラウンドが
30006
個としている。テストに用いたイベント数は30006
個でシグナルとバックグラウンドの数は訓練データと同様にした。各イベントの重みはすべて
1
としている。使用した機械学習の学習器は
BDT
とMLP
の2
つである。BDT
の決定木の数は850
個、MLP
の訓練のための繰り返し回数は500
回である。また、入力特徴量には以下の9
種類12
個を使用した。
電磁カロリメータでのエネルギー損失
ハドロンカロリメータでの粒子のエネルギー損失
粒子の最大運動量(上記の 3
つの特徴量は荷電粒子の正負ごとの各2
つづつの特徴量とする)
レプトン対系の横運動量
レプトン対系の不変質量
反跳質量
レプトン対の角度 xy
平面に射影したときのレプトン対角度
損失角度5.3.
特徴量以下の章では使用した特徴量についての説明とシグナル、バックグラウンドにおける特徴 量の描写を示す。特徴量の描写では青がシグナル、赤がバックグラウンドを示している。
5.3.1.
電磁カロリメータでのエネルギー損失再構成された粒子が
ECAL
で損失したエネルギーである図 5.1 電磁カロリメータでのエネルギー損失の分布
青がシグナルで赤がバックグラウンドを表している。グラフ縦軸はグラフを積分したとき に
1
になるように規格化したものである。以下、特徴量のグラフはこれと同様である。5.3.2.
ハドロンカロリメータでのエネルギー損失(ehcal) 再構成された粒子がHCAL
で損失したエネルギーである。図 5.2 ハドロンカロリメータでのエネルギー損失の分布
5.3.3.
粒子の最大運動量(pmx)飛跡検出器で測定される最大運動量である。
図 5.3 粒子最大運動量の分布
5.3.4.
レプトン対の横運動量(Ptdilep)粒子の持つ運動量の内ビーム軸(z軸)に垂直な成分(運動量ベクトルの
xy
平面への射影)を 横運動量と呼ぶ。横運動量はレプトン対がZ
ボソンから崩壊した場合は、Z
ボソンの横運動 量となる。Zボソンの横運動量は以下の式で表される。𝑃𝑡𝑑𝑖𝑙𝑒𝑝 = √(𝑃
𝑥𝑙++ 𝑃
𝑥𝑙−)
2+(𝑃
𝑦𝑙++ 𝑃
𝑦𝑙−)
2(6-1)
図 5.4 レプトンの横運動量の分布
5.3.5.
不変質量(mdilep)不変質量は再構成された粒子の質量に等しい。レプトン対が
Z
ボソンから崩壊している 事象はZ
ボソンの質量(91.2GeV)にピークを持つ。一方でレプトン対がZ
ボソンから崩壊し ていなければ不変質量分布はZ
ボソン質量付近以外にも広がる。図 5.5 粒子の不変質量の分布
5.3.6.
反跳質量(mercol)𝑒
+𝑒
−→ 𝑍ℎ事象において、始状態の 4
元運動量は理想的には既知なので再構成により、Zボソンの
4
元運動量の計算を行うと、ヒッグスの質量が計算される。この計算によって求 められたヒッグスの質量を反跳質量という。𝑀
𝐻𝑖𝑔𝑔𝑠= √(𝐸
𝑐𝑚𝑠− 𝐸
𝑍𝑏𝑜𝑠𝑜𝑛)
2− |𝑃
𝑍𝑏𝑜𝑠𝑜𝑛|
2(6-2)
反跳質量用いることによる利点は、ヒッグス粒子から崩壊した粒子を用いた再構成より も精度が良いことと、ヒッグス粒子の崩壊分岐比による不定性の影響を受けないことであ る。図 5.6 粒子の反跳質量の分布
5.3.7.
レプトン対角度(acl) レプトン対のベクトルの間の角度図 5.7 レプトン対ベクトルの間の角度の分布
5.3.8. xy
平面におけるレプトン対角度(acp)レプトン対のベクトルを
xy
平面に射影した際の、間の角度(Rad.)をAcoplanarity
と呼 ぶ。𝑎𝑐𝑝 = 𝑐𝑜𝑠
−1𝑃
𝑥𝑦𝑙+・𝑃
𝑥𝑦𝑙−|𝑃
𝑥𝑦𝑙+||𝑃
𝑥𝑦𝑙−| (6-3)
𝑒
+𝑒
−→ 𝑍ℎでは Z
ボソンはヒッグス粒子と共に生成する。図 5.8
xy
平面のレプトン対角度の分布5.3.9. PFO
損失角度(𝑐𝑜𝑠𝑚𝑖𝑠𝑠𝑖𝑛𝑔𝜃)
𝑐𝑜𝑠
𝑚𝑖𝑠𝑠𝑖𝑛𝑔𝜃とは検出されない粒子の運動量の和𝜃から計算された値である。検出されない
粒子とは以下の二つが主に影響している。
終状態にニュートリノを含む場合ニュートリノは検出されないので損失角度に強く影響する。ニュートリノを含む事 象ではニュートリノが様々な方向に運動するので𝑐𝑜𝑠𝑚𝑖𝑠𝑠𝑖𝑛𝑔
𝜃分布は平たんになる傾
向が予測される。
粒子がビームパイプに入射し、検出しで粒子が検出されない場合ビームパイプには検出器が置くことが出来ないので、ビームパイプに入射するよう な前後方向に飛びやすい粒子が入射した場合、
‖𝑐𝑜𝑠
𝑚𝑖𝑠𝑠𝑖𝑛𝑔𝜃‖
は1にピークを持つように なる。𝑐𝑜𝑠
𝑚𝑖𝑠𝑠𝑖𝑛𝑔𝜃 = ∑ 𝑐𝑜𝑠𝜃
𝑃𝐹𝑂= (∑ 𝑃
𝑃𝐹𝑂)
2‖∑ 𝑃
𝑃𝐹𝑂‖ (6-4)
図 5.9
𝒄𝒐𝒔
𝒎𝒊𝒔𝒔𝒊𝒏𝒈𝜽の分布
5.4.
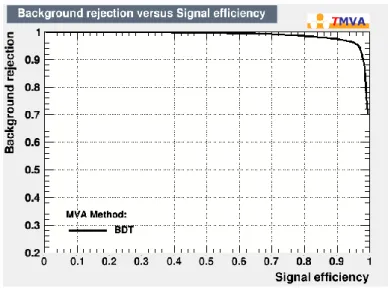
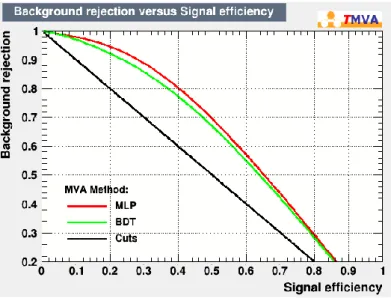
結果図 5.10
BDT
のROC
曲線図
5.10
は学習器にBDT
を使用してイベントの識別を行ったときのROC
曲線(ReceiverOperatorating Characteristic curve)である。ROC
曲線を用いることで機械学習の学習器の学習モデルを評価できる。
教師信号と実際に学習器が出力したシグナルとバックグラウンドのイベント数を以下の ように定義する。
表 5.2シグナルとバックグラウンドのイベント数
図
5.10
のROC
曲線の横軸、縦軸は以下のようにしている。𝐵𝑎𝑐𝑘𝑔𝑟𝑜𝑢𝑛𝑑 𝑟𝑒𝑗𝑒𝑐𝑡𝑖𝑜𝑛 = 𝑇𝑁 𝐹𝑃 + 𝑇𝑁 𝑆𝑖𝑔𝑛𝑎𝑙 𝑒𝑓𝑓𝑖𝑐𝑖𝑒𝑛𝑐𝑦 = 𝑇𝑃
𝑇𝑃 + 𝐹𝑁
上記から
Background rejection
が1
に近いほど正確にバックグラウンドを除去できており、同様に
Signal efficiency
が1
に近いほど正確にシグナルを識別している。ROC
曲線の示す学習器の性能を表した値がAUC(Area Under the Curve)で、ROC
曲線 と縦軸、横軸で囲まれた面積である。AUC
が1
のときは完全な分類が可能であり、AUC
が0.5
の時はランダムな分類となることを表している。BDT
のAUC
の値は0.9877 ± 0.0006となった。次に、MLPを使用したときの解析結果について述べる。まず、MLPの隠れ層を
1
層に 固定する。ノードの数を2
から20
まで変化させた時のAUC
の推移を図5.12
に記す。ただ しこの時の隠れ層のノード数はバイアスノードを含むノード数である。使用した入出力関 数はtanh
関数、sigmoid 関数(2.4.3 参照)、radial 関数の3
つとした。radial 関数はy =𝑒
−𝑥2⁄2の関数である。まず、活性化関数に
tanh
関数を用いたときの結果を示す。図 5.11 活性化関数に
tanh
関数を用いたときのノード数に対するAUC
値図
5.11
から活性化関数にtanh
関数を用いたとき、ノード数が3,4
ときノード数5~20
の 時に比べてAUC
が低い値が出る。図5.11
をy
軸方向に射影したときのAUC
分布を示す。図 5.12 活性化関数に
tanh
関数を用いたときのAUC
分布ノード数が
5~20
の時のAUC
のノード依存性は見られず統計誤差でふらついていると考え られる。この時のAUC
平均値は0.95 ± 0.01である。0.88 0.89 0.9 0.91 0.92 0.93 0.94 0.95 0.96 0.97 0.98
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 AUC
ノード数
tanh 関数を用いたときのノード数に対する AUC 値
0 2 4 6 8 10
0.88 0.89 0.9 0.91 0.92 0.93 0.94 0.95 0.96 0.97 0.98 0.99
回数AUC
tanh 関数を用いたときの AUC 分布
ノード数
3
の時のROC
曲線とノード数13
のときのROC
曲線を以下で示す。図 5.13 活性化関数:tanh関数 ノード数
13
の時のROC
曲線次にシグモイド関数を用いたときの結果を示す。
図 5.14 活性化関数に
sigmoid
関数を用いたときのノード数に対するAUC
値顕著な
AUC
のノード数依存は見られない。AUC値の平均は0.934 ± 0.008である。この 時のROC
曲線は以下の図である。図 5.15 活性化関数にシグモイド関数を用いて、ノード数
19
のときのROC
曲線0.88
0.89 0.9 0.91 0.92 0.93 0.94 0.95 0.96 0.97 0.98
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 AUC
ノード数
シグモイド関数を用いたときのノード数に対する AUC 値
次に
radial
関数用いたときの結果を示す。図 5.16 活性化関数に
radial
関数を用いたときのノード数に対するAUC
値活性化関数に
radial
関数を用いたとき、3~6ノードの時にはそれ以上と比較してAUC
値 が低い傾向があるが、ノード数7
以上では一定と考えられる。この時のAUC
値の平均は0.95 ± 0.01となった。
活性化関数に
radial
関数を用いたときのROC
曲線は以下のようになった。図 5.17 活性化関数に
radial
関数、ノード数13
のときのROC
曲線MLP
の隠れ層を1
層に固定、ノード数を変化せた時、AUCのノード数依存性は見られ なかった。また活性化関数によるAUC
値の値も変わらない。ただし活性化関数によるAUC
値のふらつきが異なる。tanh関数を用いたときは低ノード側では統計誤差から外れる低いAUC
値を出力した。radial関数の時はノード数におけるAUC
の誤差がsigmoid
関数の時0.88 0.89 0.9 0.91 0.92 0.93 0.94 0.95 0.96 0.97 0.98
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 AUC
ノード数