修士論文
タブレット端末より書き込んだ
記号の認識とキーワード抽出
平成
24
年度修了
三重大学大学院 地域イノベーション学研究科
博士前期課程
服部 晋之介
目 次
Abstract 1 第1章 はじめに 2 第2章 キーワード抽出法の提案 4 2.1 システムの流れ . . . . 4 2.2 文書(画像)データの読み込み . . . . 5 2.3 手書きによる書き込み . . . . 6 2.4 キーワード抽出記号とメモの識別. . . . 8 2.5 記号に対応した文字列の抽出 . . . . 9 2.6 文字列抽出後の応用(将来構想). . . . 10 第3章 キーワード抽出記号の識別 11 3.1 文書画像の読み込み . . . . 12 3.2 前処理 . . . . 13 3.3 手書き入力の取得 . . . . 15 3.4 キーワード抽出記号の識別処理 . . . . 16 3.4.1 領域判定 . . . . 17 3.4.2 画数判定 . . . . 20 3.4.3 行の高さ判定 . . . . 21 第4章 文字列の抽出 22 4.1 下線からの文字列抽出 . . . . 234.2 囲い線からの文字列抽出 . . . . 27 4.2.1 X,Yの最大・最小座標の取得 . . . . 27 4.2.2 文字列の高さ決定 . . . . 28 4.2.3 文字列の幅決定 . . . . 28 第5章 評価実験 29 5.1 実験器具. . . . 29 5.2 キーワード抽出記号の識別実験 . . . . 30 5.3 文字列抽出実験 . . . . 32 第6章 まとめ 34 謝辞 35 参考文献 36 発表論文リスト 37
図 目 次
2.1 提案システムのフローチャート . . . . 4 2.2 画像の読み込み . . . . 5 2.3 画像への書き込み1 . . . . 6 2.4 画像への書き込み2 . . . . 7 2.5 キーワード抽出記号とメモ . . . . 8 2.6 文字列の抽出 . . . . 9 2.7 将来像 . . . . 10 3.1 キーワード抽出記号識別のフローチャート. . . . 11 3.2 実験で使用した電子テキストの例. . . . 12 3.3 2値化→文字の高さ候補取得 . . . . 13 3.4 文字高さhℓと行間の幅ℓ . . . . 14 3.5 文字「あ」の座標データ . . . . 15 3.6 本研究で使用する記号 . . . . 16 3.7 印字領域と空白領域 . . . . 17 3.8 1[dot]をℓ×ℓ倍に膨張 . . . . 18 3.9 膨張処理後の文書画像例 . . . . 18 3.10 メモとキーワード抽出記号の識別:予備実験結果 . . . . 19 3.11 印字領域を飛び出したキーワード抽出記号. . . . 19 3.12 印字領域内に書き込まれたメモ(ルビ) . . . . 19 3.13 手書き入力の行われたテキスト . . . . 20 3.14 手書き入力画像の高さho . . . . 214.4 黒画素の探索1 . . . . 24 4.5 高さの決定 . . . . 24 4.6 文字の途中で下線が切れている場合(上・原画像 下・抽出結果) . . . . 25 4.7 文字列の幅補正例(上・原画像 下・抽出結果) . . . . 26 4.8 X,Yの最大・最小座標取得 . . . . 27 4.9 文字列の高さ決定1a . . . . 28 4.10 文字列の高さ決定2a . . . . 28 5.1 実験システムの接続図 . . . . 29 5.2 対象画像の一例 . . . . 29 5.3 識別成功例 . . . . 30 5.4 キーワード抽出記号の誤識別例 . . . . 31 5.5 メモの誤識別例:「矢印」 . . . . 31 5.6 正抽出・過抽出:「無限集合」を抽出した場合 . . . . 32 5.7 抽出成功・失敗例. . . . 33
表 目 次
5.1 識別法の実験結果 . . . . 30 5.2 実験結果. . . . 32
Characters Extraction from Strings on a Document Image
Using Handwritten Mark on Tablet
Shinnosuke Hattori
March 2013
1. IntroductionMost school classes use paper media such as textbooks and notebooks. We expect that learning method using mobile communications devices such as tablet and smart phone are increasing in the future. But, in the learning system using tablet, the current quality of interactive learning software is not adequate for user demand. To improve the advantage of the interface on mobile devices, we want to extract some character strings specified by marks such as an underline or fence-line from a document image on tablet.
In the document image, some users would write marks and notes. We propose a new classification method for handwritten mark and note on a document image. For the extracted mark using underline and fence-line, we develop a new character extraction system from a document image using C language on Windows 7.
2. Mark classification and character extraction methods on a document image
2.1. Mark and note classification method
The proposed method consists of three classification criteria. “Printing Area” criterion is defined by the range of document of printing area and blank area on a document image. “The number of stroke” criterion is defined by the number of character stroke, as the number of handwritten marks strokes is fewer than that of notes. “Object height” criterion is defined by the height of the input object because
3. Evaluation Experiments
I implemented the software system, and conducted evaluation experiments of my proposed methods. I used a pen tablet (WACOM DTI-520) and personal computer.
3.1. Mark and note Classification experiment
I experimented with 50 notes and 50 marks in document images.
Table 1 Mark and note classification results
3.2. Character extraction experiment
I experimented with 25 underlines and 25 fence-lines in document images. We defined as success even if over extraction.
Table 2 Character extraction results
4. Conclusions
I proposed a new handwritten mark and note classification method on document images, and character extraction method from the mark. As results of the evaluation experiment, I confirmed that more investigations and improvements are required for practical use.
Correct /Total cases Correct rate[%]
Note 48/50 96.0 Mark 41/50 82.0 Over extraction rate [%] Positive extraction rate[%] Underline 96.0 84.0 Fence-line 96.0 76.0
第
1
章 はじめに
近年,iPadやNexus7などのタブレット端末が急速に普及しつつある.その理由とし て,一般的なノートPCと比べ,以下の点が優れていると考えられる. • 軽量で持ち運びしやすい • タッチパネル画面で指(またはペン)での文字入力が可能 • 電子書籍の閲覧が可能 一方で,従来から学習をサポートするe-Learningシステムの研究は数多く報告されている [1, 2, 3].例えば,Bonds-RaackeらはタブレットPCを使用した授業での生徒の反応を調査 した[1].また,柴田は黒板に板書された文字や図形の抽出を行い,映像を用いたe-Learning システムを開発した[2].これらの研究は,とても有効なe-Learningシステムである.しか し,これらはパソコンを使用した研究事例が多く,タブレット端末のタッチパネルを活か し,また学生の能動的学習(アクティブ・ラーニング)を促すe-Learningシステムの研究 は少ない.近年の教育に対する期待として,学習の能動的学習(アクティブ・ラーニング) 能力の育成が重視されており,本研究は最近の教育界の流れを促進するためのシステムが あると考えている.本研究では,学生が授業で教師から黒板や教科書を用い教わることを 受動的学習とし,その際に,学生自身が気になったキーワードやフレーズを自ら調べ,解 決させることを能動的学習と定義する. ここで,タブレット端末は教科書を電子化することができ,その電子テキストに書き込 みを行うことができる.また,従来の教科書には文章,図,表などの様々なコンテンツが 存在し,授業中に生徒はしばしば書き込みを行う.加えて,生徒が書き込んだ情報にはそ の授業での補足事項や重要なキーワードを示す下線など(キーワード抽出記号)が含まれンライン認識[4]により,書き順などの時系列筆跡[5]が利用できる.本研究では,最終的 にユーザーの求めるキーワードを抽出するため,電子テキストと時系列筆跡からキーワー ドを含む文字列の抽出を行った. 本論文の構成は,2章で提案するシステムの説明を行う.3章では,キーワードを指し示 す記号を取得するため,文章画像のレイアウト情報を用い,書き込みデータからメモとキー ワード抽出記号を識別する手法を提案する.4章では,キーワード抽出記号からキーワー ドを含む文字列を抽出する手法を提案する.次に5章で文字列抽出実験を行い,結果と考 察を示す.最後に6章でまとめを行う.
第
2
章 キーワード抽出法の提案
この章では,キーワードを抽出するために必要な文字列の抽出法を提案する.また, キーワードを抽出後の使用例について示す.2.1
システムの流れ
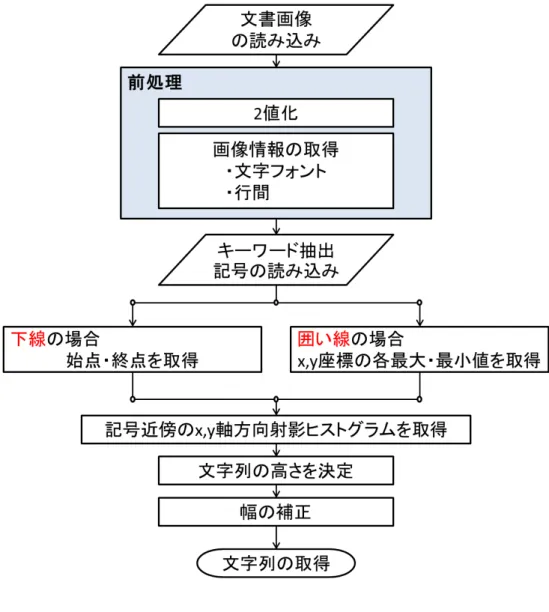
本研究では,Windows上のC言語を使用して記号とキーワード抽出記号の識別アルゴ リズムとキーワード抽出モジュールを作成した.図2.1に提案する処理システムのフロー チャートを示し,各処理の具体的な説明を次節以降に示す. 図2.1: 提案システムのフローチャート2.2
文書(画像)データの読み込み
(授業などで使用する)教科書や資料などの紙文書をスキャナで電子化し,文書(画像) データとしてタブレット端末に読み込み,表示する(図2.2).現在,専門書の電子書籍は普 及していないため,本研究で扱う文書データはイメージスキャナでスキャンした文書デー タを対象に研究を行った. 図2.2: 画像の読み込み2.3
手書きによる書き込み
2.2節で表示した文書(画像)データにペンや指先を使って,文字や記号を書き込む.書
き込み例を,図2.3,図2.4に赤文字で示す.
2.4
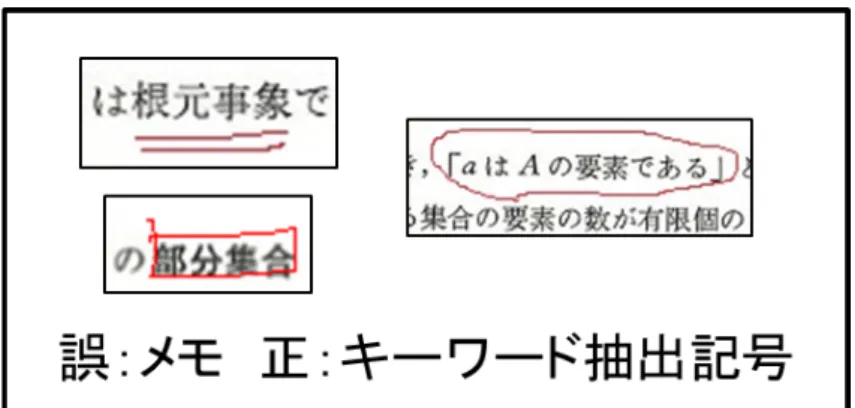
キーワード抽出記号とメモの識別
図2.1で示すように,キーワードを抽出するためには文字列を示す記号とそれ以外(メ モ)に識別する必要がある.ここで,タブレット端末は書き込んだ文字,記号の書き順や 座標といった時系列筆跡[5]が利用できる.これを用いて,書き込まれた文字や記号から画 像の文章,数式に記された下線や丸などのキーワード抽出に必要な記号(キーワード抽出 記号)とメモに識別を行う(図2.5). 識別を行った際,キーワード抽出記号については,2.5節の文字列の抽出を行う.また, 本論文ではメモについての記述はしていないが,最終的に手書き文字認識を行い,データ ベースへ格納する.その後,このメモについてもタグ付けや検索などのアプローチを行う. 図2.5: キーワード抽出記号とメモ2.5
記号に対応した文字列の抽出
読み込んだ画像と特定の記号の位置情報から対応した文字列を抽出する.例として,図 2.6の場合,文字列 は丸の中に含まれる文字列「接線の傾き」を抽出し,文字列 は下線 上にある文字列「極限まで近づいたとき」を抽出する.具体的な抽出手法については,4章 で説明する. 図2.6: 文字列の抽出2.6
文字列抽出後の応用(将来構想)
抽出した文字列をユーザー固有の検索データベースへ格納する.さらに,抽出した文字 列からキーワードを抜き出す.最終的に,キーワードについて以下のような付加を行う. • キーワード検索,補助説明の表示[6] • 文書(画像)データへのタグ付け • 生徒の理解度に対する指標材料 また,タブレット端末特有のインターフェース(スワイプ機能等)を活用したe-learning システムを目指す(図2.7). 本論文では,文字列を抽出するまでの手法を示し,その後のキーワードの抽出方法,キー ワードへのアプローチについては示さない.第
3
章 キーワード抽出記号の識別
2章で述べたキーワード抽出記号の識別の提案手法を示す.図3.1に,キーワード抽出記
号識別までの流れを示し,次節より各処理の説明を行う.
3.1
文書画像の読み込み
本論文で扱う電子テキストは大学授業で用いる教科書をイメージスキャナでスキャンし た画像(図3.2[7])とする.ここで,扱うスキャン画像の特徴を以下に示す. • 文字認識されていない(.bmp形式,210[dpi]) • フォントがある程度統一されている • スキャン時の画像の傾きがない • 書字方向は横書きのみとする3.2
前処理
記号の識別,また次章の文字列抽出に必要となる情報を取得するため,前処理を行う. 初めに,文書画像の2値化を行い,それよりy軸方向射影ヒストグラム[2]を取得する. y軸方向射影ヒストグラムより,文字の高さ候補を得ることができる(図3.3).この高さ 候補の中央値を取ることにより,文書画像の標準文字高さhℓを得る.同様に,行間の幅ℓ を取得する(図3.4).
3.3
手書き入力の取得
本研究では,手書き入力情報として,座標値をカーソルが移動毎に取得し,配列への格 納を行っている.また,タブレットペンのペンダウンからペンアップまでを1ストローク とし,1つの文字列抽出が行われるまでのデータを3次元配列に格納し保存している.例 として,図3.5に文字「あ」が記入された際の3次元配列データ構造を示す.また,手書き 入力の座標値は文書データの座標から取得できるため,互いの位置合わせは必要としない.3.4
キーワード抽出記号の識別処理
キーワード抽出記号とメモを分けるために,3つの判定手法を提案する.ここで,本 論文でのキーワード抽出記号は,教科書に書き込まれたキーワードを指す記号のため,基 本的に記号の種類は限られる.また,各ユーザーが用いる特有の記号を抽出することは難 しいと考え,今回は,図3.6に示す記号のみをキーワード抽出記号として認識するものと する. 図3.6: 本研究で使用する記号3.4.1
領域判定
キーワード抽出記号は必然的にキーワードの存在する文章が印字された領域(印字領域) に書き込まれる.また,メモについては何も印字されていない領域(空白領域)に書かれ ることが多い.そこで,図3.7印字領域と空白領域を分けることにより,キーワード抽出記 号候補を識別する手法を提案する. 今回は,シンプルなレイアウト解析を用い,印字領域を生成する.手順としては,はじ めに2値化された文書画像を読み込む.次に,画像内の黒画素を検索し,黒画素1[pixel]に 対し,行間ℓを埋めるためℓ×ℓ倍の膨張処理を行い,それを印字領域とする(図3.8,図 3.9).最後に,膨張処理を行った画像を原画像の裏に配置し,手書き入力の60%が印字領 域に含まれていた場合をキーワード抽出記号候補とした.ここで,予備実験として,文書 画像5枚にメモ・キーワード抽出記号を各10個書き込み,識別を行った際,図3.10のよう な結果が得られ,60%以上であれば,誤り率最小で記号と識別されたため,本論文では, 印字領域に含まれる割合60%を識別基準とした. 図3.7: 印字領域と空白領域
図 3.8: 1[dot]をℓ×ℓ倍に膨張
図3.10: メモとキーワード抽出記号の識別:予備実験結果 図3.10から60%の識別基準に当てはまらない事例(印字領域に含まれる割合が0%,30 %のキーワード抽出記号,100%のメモ)が数件ある.その理由としては,以下の様な印 字領域から飛び出た記号(図3.11)やルビによる印字領域内へのメモの書き込み(図3.12) が挙げられる. 図3.11: 印字領域を飛び出したキーワード抽出記号
3.4.2
画数判定
下線や囲い線のようなキーワード抽出記号は,手書き文字や図が含まれるメモに比べ,画 数が少ない(図3.13).そこで,図3.6で示したキーワード抽出記号の中で描くのにもっと も画数が多い矩形(囲い線)の画数(4画)を判定基準とし,4画以下の手書き入力図形を キーワード抽出記号候補とする. 図 3.13: 手書き入力の行われたテキスト3.4.3
行の高さ判定
キーワード抽出記号は,キーワードを含む1つの文字列を示すために使用され,その文 字列は基本的に文章の1行である.そこで,3.2節で求めた行の高さhℓ,行間の幅ℓと手書 き入力画像の高さh0を比較することで,キーワード抽出記号を識別する方法を提案する. 次に,手書き入力図形のy座標最大値,最小値の差を求め,その値をh0とする(図3.14, 式3.1).手書きデータがキーワード抽出記号である場合,1行と行間の縦幅よりも広くな ることはないと考え,今回は以下の式3.2を満たした入力図形をキーワード抽出記号候補 とする. h0 = ymax− ymin (3.1) h0 < hl + l×2 (3.2)第
4
章 文字列の抽出
4節に示したキーワード抽出記号として,本論文では,教科書で主に書き込まれる下線
と囲い線(丸,四角)からの文字列抽出法を提案する.
図4.1に文字列抽出の流れを示し,次節より各処理について詳しい説明を示す.
4.1
下線からの文字列抽出
4.1.1
始点・終点の取得
書き込まれた下線から始点(タブレット端末にペンで書き込みを始めた点)と終点(タ ブレット端末からペンが離れた点)の座標を取得する(図4.2). 図 4.2: 始点・終点の取得4.1.2
文字列の高さ決定
始点・終点間のY軸正の方向に1[pixel]ごとの水平方向射影ヒストグラム[2](Y軸ヒス トグラム)を作成し(図4.3),始点のY座標から正の方向に黒画素の探索を行う(図4.4). 最初に黒画素が現れた位置から黒画素のなくなる位置までを文字列の高さとする(図4.5). 図4.3: Y軸ヒストグラム 図 4.4: 黒画素の探索1 図4.5: 高さの決定4.1.3
文字列の幅決定
下線の始点・終点のX座標を用いることによって文字列の幅を決定する.しかし,筆記者
によって下線の引き方が異なり,図4.6のように文字列の両端が途中で切れる場合がある.
4.1.4
文字列の幅補正
そこで,文字列の幅補正を行う[8].3.2.2節で求めた抽出領域間の垂直方向射影ヒストグ ラム(X軸ヒストグラム)を作成する.始点からX軸負の方向に黒画素のない位置を探索, 同様に終点からX軸正の方向に黒画素のない位置を探索し,検出された2ヶ所を文字列の 幅として抽出する(図4.7). 図4.7: 文字列の幅補正例 (上・原画像 下・抽出結果)4.2
囲い線からの文字列抽出
4.2.1
X
,Y の最大・最小座標の取得
囲い線を書いた時に得られる座標から,Xの最小時の座標と最大時の座標を取得する.同 様にYの最小座標と最大座標を取得する(図4.8). 図4.8: X,Yの最大・最小座標取得4.2.2
文字列の高さ決定
Yの最小座標と最大座標の中点を取り,その座標から,Y軸負の方向に黒画素のない位 置を探索し,決定する.さらに,その位置からY軸正の方向にもう一度黒画素の探索を行 い,黒画素のなくなる位置を決定し,その2ヶ所を文字列の高さとする(図4.9,図4.10). 図4.9: 文字列の高さ決定1a 図4.10: 文字列の高さ決定2a4.2.3
文字列の幅決定
Xの最小座標と最大座標を用い,4.1.3節の下線の幅決定と同様の処理を行い,文字列の 幅を決定する.第
5
章 評価実験
5.1
実験器具
本実験では,Windows7 PC使用しプログラム言語Microsoft Visual C#で開発を行った
(図5.1).また,入力デバイスとしてペンタブレットWACOM DTZ-1200WをPCに接続し 使用した.対象画像は,教科書「岩波書店 確率・統計[9]」から5ページを抜粋し,スキャ ンしたものを使用する(図5.2). 図5.1: 実験システムの接続図
5.2
キーワード抽出記号の識別実験
3.4章で提案したメモとキーワード抽出記号の識別法の有効性を示すため,対象画像に 「メモ」50個,「キーワード抽出記号」50個の計100個を書き込み実験を行った.今回,識 別処理は各手書き入力図形が書き込まれた直後に手動で行う. 実験結果を表5.1に示す. 表5.1: 識別法の実験結果 描画数[個] 成功数[個] 成功率[%] メモ 50 48 96.0 キーワード抽出記号 50 41 82.0 実験の結果,メモの識別成功率は96.0%,キーワード抽出記号の識別成功率は82.0%と なった(図5.3).ここで,示される成功とは,メモもしくはキーワード抽出記号として書き 込んだ入力が正しく識別された場合の事を言い,キーワード抽出記号として書き込んだ入 力がメモとして識別された場合,キーワード抽出記号での誤識別とする(5.4). キーワード抽出記号の識別成功率がメモの成功率よりも低いことが分かる.これは,図 5.5のようなメモが間違ってキーワード抽出記号として識別されてしまったことを示してい る.そのため,3.4章の提案手法の改善が必要だと考える. 図5.3: 識別成功例
図5.4: キーワード抽出記号の誤識別例
5.3
文字列抽出実験
4章で提案した文字列抽出法の有効性を示すために実験を行った.対象画像(図5.2)の 文章に「下線」25個,「囲い線」25個を書き込みを行い,文字列抽出を行った.また,今回 下線と囲い線の対象となるキーワードは予め指定されている.抽出処理については,識別 処理同様に入力直後に手動で行う. 実験結果を表5.2に示す. 表 5.2: 実験結果 過抽出数[個] 過抽出率[%] 正抽出数[個] 正抽出率[%] 下線 24 96.0 21 84.0 囲い線 24 96.0 19 76.0 ここで,抽出した結果に筆記者が目的とした文字列のみが正確に抽出された場合を正抽 出とし,筆記者が意図したキーワードの他に余分な文字が含まれていた場合(正抽出の場 合も含む)を過抽出とした(図5.6).本研究では,将来的に今回抽出した文字列の結果に キーワード認識を行い,必要なキーワードを抜き出すため,過抽出であっても成功とした (図5.7). 図 5.6: 正抽出・過抽出:「無限集合」を抽出した場合図 5.7: 抽出成功・失敗例 表5.2に示すように,余分な文字を含む(過抽出)文字列の抽出成功率は下線と囲い線 共に96.0%となった.また,下線と囲い線の正抽出率を比べると8.0%の差が生じた.こ の結果は,下線を引く場合よりも丸などの囲い線を描く場合の方が余分な文字が含まれや すいことを示している.その原因として,ペンタブレットの扱いに不慣れであり,それに よって下線などの直線は目的の文字列からほとんどずれることはないが,丸など少し特殊 な形になると,目的の文字列からずれることがあり,これが正抽出の差を生じさせたと考
第
6
章 まとめ
本研究では,タブレット端末の普及による将来的な学習形態の変化により,電子化され た教科書を利用した授業の増加を見据え,学生の能動的学習(アクティブ・ラーニング)能 力の育成を目指したタブレット端末を使ったe-learningシステムの提案を行った.具体的に は,電子教科書に書き込まれたキーワード抽出記号からキーワードを抽出するべく,メモ とキーワード抽出記号の識別手法の提案,キーワード抽出記号からの文字列抽出手法の提 案を行った.また,提案手法のシステムをWindows7上でVisualC#で作成し,評価実験を 行った.メモとキーワード抽出記号の識別実験では,メモの認識率は96.0%,キーワード 抽出記号は82.0%の結果が得られた.次に,キーワード抽出記号からの文字列抽出実験で は,下線と囲い線の過抽出率は共に96.0%,正抽出率は下線で84.0%,囲い線で76.0%得 られた.最終的に,キーワード抽出記号の識別から文字列の抽出までの過程を一括処理し た場合,78.7%となり,実装にはまだ精度が不十分であることを示しており,さらなる改 善が必要であることが分かった.謝辞
本研究の遂行および修士論文の作成にあたり,丁寧なご指導とご助言,ご協力を頂きま した本学地域イノベーション学研究科鶴岡信治教授,工学部電気電子工学科高瀬治彦准教 授,川中普晴助教に心から感謝申し上げます.また,共に頑張った仲間や,困ったときに助 言を下さった情報処理研究室の大学院生の先輩方に感謝致します.
参考文献
[1] Bonds-Raacke, Jennifer M., Raacke, John D.,“Using Tablet PCs in the classroom: an investigation of students’ expectations and reactions”, Journal of Instructional Psy-chology, pp.235 - 239, 2008.
[2] 柴田彰洋“ 映像eラーニングのための板書された文字と図形の抽出 ”,電子情報通信学
会 2007年総合大会ISS特別企画「学生ポスターセッション」,2007.
[3] Ming. Y, Bai, ZS,“A Mandarin E-Learning System Based on Speech Recognition and Evaluation”, COMPUTER APPLICATIONS IN ENGINEERING EDUCATION, pp.651 - 659, 2011. [4] 田中宏“ オンライン認識とオフライン認識の候補統合によるハイブリッド型ペン入力文 字認識エンジン ”1998. [5] 大田郁実,山本遼,西本卓也,嵯峨山茂樹“ 文字構造の文法記述に基づくオンライン 手書き漢字列認識 ” 電子情報通信学会技術研究報告, PRMU, pp.75-80,2007. [6] 錦見一志: 遠隔授業支援システムのためのキーワード説明文の自動抽出,平成14年度三 重大学電気電子工学科卒業論文, 2002. [7] 柴田望洋(2004)『新版 明解C言語 入門編』ソフトバンクパブリッシング [8] 依田文夫: 手書き日本語文字列の文字切り出し方法,昭和60年度電子通信学会総合全国 大会, 1554, 1986. [9] 薩摩順吉(1989)『理工系の数学入門コース7 確率・統計』岩波書店
発表論文リスト
[1] 服部晋之介,鶴岡信治,川中普晴,高瀬治彦,三宅康二 “ タブレット端末上の電子文
書画像に書き込んだ記号認識とキーワード抽出方法 ”,平成 23年度電気関係学会東海
支部連合大会, A5-4, 2011
[2] S. Hattori, S. Tsuruoka, H. Takase, and H. Kawanaka“Characters Extraction from Strings on a Document Image Using Handwriting Marks on Touch Screen”, 10th IAPR International Workshop on Document Analysis Systems (DAS2012), pp.35, 2012 [3] S. Hattori, S. Tsuruoka, H. Kawanaka, and H. Takase“Characters Extraction from
Strings on a Document Image Using Handwritten Mark on Tablet - Classifying for Handwritten Note and mark -”, Proceedings of Fourth International Workshop on Regional Innovation Studies 2012 (IWRIS2012), pp.75-78, 2012