DEIM Forum 2016 C6-2
非同期に文字が入力される複数ストリームに対する一般化接尾辞木の線
形時間構築アルゴリズム
高木 拓也
†稲永 俊介
††有村 博紀
††
北海道大学大学院情報科学研究科 〒 060–0814 北海道札幌市北区北 14 条西 9 丁目
††
九州大学 大学院システム情報科学研究院 情報学部門
〒 819-0395 福岡県福岡市西区元岡 744
E-mail:
†{
tkg,arim
}
@ist.hokudai.ac.jp,
††
[email protected]
あらまし
本稿では,非同期に文字が入力される複数ストリームに対する索引構築を考察する.総文字数 n からなる
K 本の文字列の集合を S =
{T
1, ..., T
K} とする.本問題は,新たな入力文字が任意の文字列 T
iの末尾に追加される文
字列集合 S に対して,パターンマッチングなどを高速に実行する索引である一般化接尾辞木をオンライン構築する問
題である.これは,マルチセンサーデータ等,複数のクライアントからデータが非同期に到着する状況に対する索引
構築問題を想定している.本稿では,入力に対する有向語グラフを並列に構築することによって非同期入力される複
数ストリームに対して,一般化接尾辞木を線形時間と領域で構築するアルゴリズムを提案する.
キーワード
テキスト索引,オンライン構築,Suffix Tree,DAWG
1.
は じ め に
テキスト索引のオンライン構築問題は,コンピュータサイエ ンスにおける基本的な問題の一つである.文字列集合索引とは, K本の文字列からなる集合S ={T1, . . . , TK}が与えられたと き,Sに対する文字列照合クエリを高速に答えるためのデータ 構造である.最近,多数のセンサーからのセンサーログや,都 市中を走行する車から送られる位置情報(注 1)など,複数のクラ イアントから非同期に到着するストリームデータが増大してい る.そのため,文字列集合に対する索引の需要が高まっている. 本稿では,オンライン文字列集合索引構築問題(online con-struction probelm for multiple texts indices)を考察する.こ れは,文字列集合Sの文字列すべてが空文字列の状況からス タートし,各時刻ごとにどれか一つの文字列の末尾に新しく文 字が付け加えられるたびに,Sの最新の索引を構築する問題で ある.これまで,i番目の文字列Tiの末尾に新たな文字が加え られた場合,文字列T1, . . . , Ti−1はそれ以上新たな文字が末尾 に追加されないことを仮定する準オンライン(semi-online)な 設定での文字列集合索引構築として,一般化接尾辞木 (general-ized suffix tree, GST)や部分語グラフ(directed acyclic wordgraph, DAWG)に対する研究が行われてきた[1–3].しかしな がら,常に任意の文字列の末尾に新たな文字が追加可能な完全 オンライン (fully-online)状況下での索引構築アルゴリズムは 知られていない.そこで,我々は,部分語グラフと一般化接尾 辞木に対する完全オンライン構築アルゴリズムを提案する. 初めに,2.節で必要な定義を準備する.次に3.節では,部分 語グラフの完全オンライン構築アルゴリズムを考察する.これ はBlumerらによる準オンライン構築アルゴリズムを拡張する ことにより得られることを示す.4.節では,left-to-rightな一 (注1):http://cabspotting.org/ 般化接尾辞木完全のオンライン構築アルゴリズムを与える.部 分語グラフと比べ,一般化接尾辞木の完全オンライン構築は難 しい.その理由を説明した後で,部分語グラフと並列に一般化 接尾辞木を構築するアルゴリズムを示す.最後の節では,まと めを与える.
2.
準
備
本節では,以降の節で必要な用語と定義を与える.また,本 論文で扱う主要なデータ構造である部分語グラフと一般化接尾 辞木を導入する. 2. 1 基本的な定義 文字の集合Σ ={a, b, · · ·}をアルファベット(alphabet)と いい,Σの要素数|Σ| = σをアルファベットのサイズという. アルファベットΣ上の長さnの文字列は,Σの要素の有限 列T = a1· · · an, (ai ∈ Σ, i = 1, . . . , n)である.各文字ai をT [i]と表記する.長さが0の空文字列をεで表す.各添字 1 <= i <= j <= nに対して,添字の区間[i, j]を{x | i <= x <= j} と定め,対応する部分文字列をT [i, j] = T [i]T [i + 1]· · · T [j]と する.もしi > jならばT [i, j] = εと定める. 与えられた文字列T に対して,ある文字列X, Y, Z∈ Σ∗が 存在してT = XY Zと分解できるとき,それぞれX をT の接頭辞(prefix),Y を部分語(factor),Z を接尾辞(suffix)と
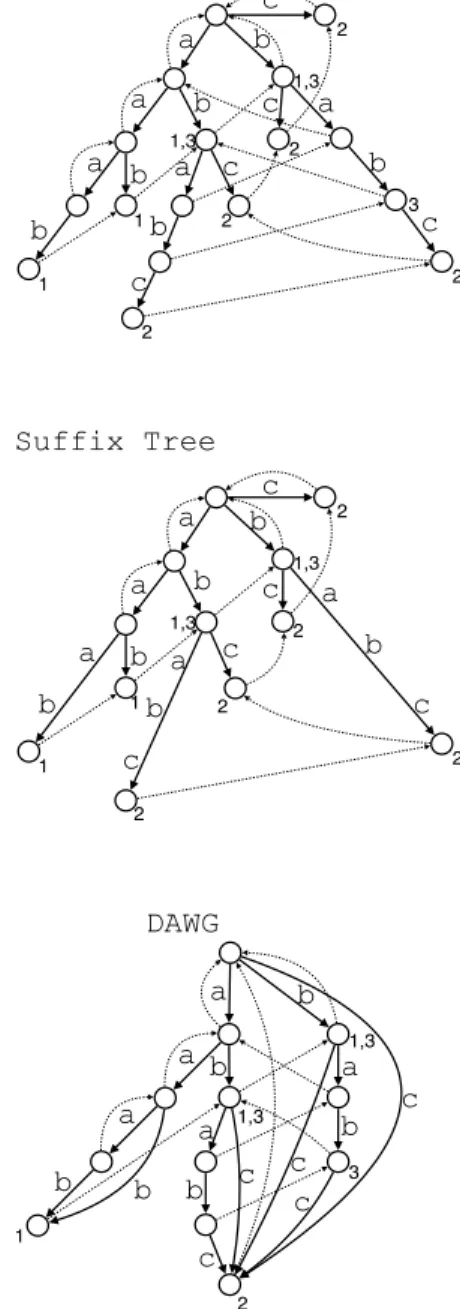
いう. 2. 2 接尾辞トライ 文字列集合S ={T1, . . . , TK}に対する接尾辞トライ(suffix trie)STrie(S)は,各文字列のすべての接尾辞の集合を格納す るトライ構造である.接尾辞トライは辺ラベルとしてSの文字 を持つ.S に対する接尾辞トライの領域はO(n2)語であるこ とが知られている.ここでnはSの総文字列長である.トラ イ上のあるノードvが表現する文字列xとは,根ノードからv までのパス上のラベル文字を連結した文字列(パスラベル)で
a
a
a
a
a
b
c
c
c
b
b
b
c
c
b
b
2 2 2 2 2 1 1 1,3 1,3Suffix Tree
a
a
a
a
a
b
c
c
c
b
b
b
c
c
b
b
2 2 2 2 2 1 1 1,3 1,3 3Suffix Trie
a
b
2a
a
b
c
b
a
b
c
c
a
b
b
c
1 1,3 1,3 3DAWG
c
図 1 文字列集合 S ={T1 = aaab, T2= ababc, T3 = bab} に対す
る,接尾辞トライ (Suffix Trie) と接尾辞木 (Suffix Tree),部分 語グラフ (DAWG) の例.実線と破線はそれぞれ枝と接尾辞リ ンクを表している. ある.この時,vを位置xのノード,または単にノードxと書 いて表現する.Sのすべての接尾辞は根からのパスラベルで表 現される.ノードaxからxへのポインタslink (ax) = xを接 尾辞リンク(suffix link)と呼ぶ. 2. 3 一般化接尾辞木 接尾辞トライから,分岐のないパスを辺におきかえ,ラベル として文字列をもたせたものを接尾辞木STree(S)という[4]. このような内部ノードがすべて分岐を持つトライはコンパクト トライと呼ばれる.n個の葉をもつコンパクトトライは,高々 n− 1個の内部ノードしかもたないことが保証される.各ラベ ル文字列x = TK[i..j]を,整数の三つ組⟨k, i, j⟩で表現するこ とにより,接尾辞木はO(n2)文字ある接尾辞集合をO(n)語領 域で表現できる.文字列集合に対する接尾辞木を特に一般化接 尾辞木と呼ぶ.一般化接尾辞木の任意の位置wは,wの直上に ある実ノードuとuからwまでのパスの最初の文字a,uから wまでのパスの長さℓの3つ組ϕ = (u, a, ℓ)で表すことができ る.この組ϕを参照(reference)と呼ぶ.オフセットℓ = 0の とき,参照ϕは実ノードを表すとみなすことができる.逆に, ℓ |= 0の位置を仮想ノードと呼ぶ.接尾辞木のノードにも,接 尾辞トライと同様に接尾辞リンクを定義できる. 2. 4 部分語グラフ 文 字 列 集 合 S = {T1, . . . , TK} に 対 す る 部 分 語 グ ラ フ (DAWG)DAWG(S)とは,S のすべての接尾辞を格納する DAG構造である[2, 5].部分語グラフは,接尾辞トライにおい て接尾辞リンクで接続された同一の部分木を統合したものであ る.より具体的には,S中のある部分文字列fとgが,出現し ている終端位置が同一の場合,fとgは同じノードで表現され る.図1の例では,部分文字列aaabと部分文字列aabの出現 位置は,それぞれT1[1, 4]とT1[2, 4]であり,終端出現位置が一 致しているため同一のノードで表現されている.しかし,部分 文字列abはT1[3, 4]以外にもT2[1, 2]やT2[3, 4],T3[2, 3]でも 表現されているため,異なるノードで表現される.したがって, 接尾辞木と違い,各辺ラベルは単一文字を表現する.Blumer らによって,DAWGのノード数と枝数はO(n)個であることが 示されている.根ノードから各文字列Tiで遷移した先のノー ドが,子ノードを持たない時,そのノードをsinkノードと呼 ぶ.DAWG(S)の根からあるノードvに到達するパスを考え る.このときvへの最長パスを構成する枝とそうでない枝に分 類され,それぞれをprimaryな枝とsecondaryな枝と呼ぶ. 同一の文字列集合に対する接尾辞トライと接尾辞木,部分語 グラフそれぞれの例を図1に示す. 2. 5 オンライン入力 次に,索引の完全オンライン構築を定義するために,いくつ かの概念を準備する.任意の正整数をK >= 1とおく.非負整 数t >= 0を時刻とし,初期状態をt = 0で表す.このとき,完 全オンライン入力とは,長さnの列 S = (k1, a1),· · · , (kt, at),· · · , (kn, an) (1 <= t <= n) である.ここに,各1 <= t <= nに対して,(kt, at)∈ [1, K] × Σ は時刻tに受けとった組である.すなわち,1 <= kt<= Kは任意 の文書番号であり,at∈ Σは任意の文字である.各時刻t >= 0 でのK-文字列集合S(t) ={S1(t), . . . , S (t) K }を次のように帰納 的に定める: • 時刻t = 0の時,S(0)は空文字だけからなるK-文字列 集合である.すなわち,任意の文書番号iに対して,Ti(t)= ε である. • 時刻t >= 1の時,入力の組(k, a) = (kt, at)にたいし て,集合S(t)は前の時刻の集合S(t−1) から,選ばれた文字 列Tkの末尾に新しい文字aを連結して得られる.すなわち, Tk(t)= Tk(t−1)· aかつTk(t)′ = Tk(t′−1), k ′̸= kである. また,準オンライン入力とは,長さnの列 S = (k1, a1),· · · , (kt, at),· · · , (kn, an) (1 <= t <= n, kt<= kt+1)
1 2 3 4 5 6 T1 a b a b … … T2 a b a b c … T3 a b b a … … 1 2 3 4 5 8 9 12 13 6 7 10 11 図 2 オンライン一般化接尾辞木問題における多重ストリームからの 文字列集合 S ={T1 = abab, T2 = abab, T3 = abba} の入力
例.完全オンラインテキスト (1,T1, a), (2,T1, b), (3,T1, a), (4,T1, b), (5,T2, a), (6,T3, a), (7,T3, b), (8,T2, b), (9,T2, a), (10,T3, b), (11,T3, a), (12,T2, b), (13,T2, c) からの入力 を示す.ここで,時刻 t の入力 (k, a) を三つ組 (t, k, a) で示し ている.図の左上の数字は入力順である. である.すなわち,ある時刻tで文字列Tktの末尾に文字が追 加された時,k1. . . kt−1番目の文字列が確定する. 図2に,完全オンライン入力における文字列集合の入力例を 示す. 2. 6 オンライン索引構築問題 以下に,文字列集合索引の準オンライン構築問題と完全オン ライン構築問題を定義する. 文字列集合索引の準オンライン構築問題 入力: 正整数K >= 1とΣ上の長さnの準オンライン入力 S = (k1, a1),· · · , (kt, at),· · · , (kn, an) (1 <= t <= n, kt <= kt+1). 出力: 各t = 1, . . . , nに対して,K-文字列集合S(t)に対す るテキスト索引I(t) =I(S(t))を出力する.ただし,任意の時 点でパターン照合クエリP∈ Σ∗が与えられたとき,これに正 しく答えられる必要がある. 文字列集合索引の完全オンライン構築問題 入力: 正整数K >= 1とΣ上の長さnの完全オンライン入力 S = (k1, a1),· · · , (kt, at),· · · , (kn, an) (1 <= t <= n). 出力: 各t = 1, . . . , nに対して,K-文字列集合S(t)に対す るテキスト索引I(t)=I(S(t))を出力する.ただし,任意の時 点でパターン照合クエリP∈ Σ∗が与えられたとき,これに正 しく答えられる必要がある.
3.
部分語グラフの完全オンライン構築
本節では,一般化接尾辞木の完全オンライン構築に必要な, 文字列集合に対する部分語グラフの完全オンライン構築アルゴ リズムについて考察する.はじめにBlumerらによって提案さ れた準オンライン構築アルゴリズムを紹介する.次に,そのア ルゴリズムを拡張した完全オンライン構築アルゴリズムを提案 する. 3. 1 Blumerらによる準オンライン構築アルゴリズム Blumerらによって提案された,文字列集合S ={T1, . . . , TK} に対する部分語グラフDAWG(S)の準オンライン構築アルゴ リズムを導入する [2].準オンラインの状況下では,もし入力 Tk a a lrsT ’(Tk) a a a a a}
Type-1 lrsT(Tka)}
Type-2}
Type-3 a 図 3 Tka の接尾辞の分類.lrsτ(Tk) は文字列集合 τ 上で2回以上出 現している最長の Tkの接尾辞を表す. の文書番号k (1 <= k <= K)と文字aの組(k, a)を受け取りTk の末尾に文字aを追加した場合,文字列T1, . . . , Tk−1はそれ 以上文字が追加されることはなく,また,文字列Tk+1, . . . , TK は空文字列のままである. 文字列集合S′に対する部分語グラフDAWG(S′)が構築され ていることを仮定し,入力(k, a)を受け取り,文字列Tkに文字 aを追加した後の文字列集合SのDAWG(S)を構築すること を考える.すなわち,DAWG(S′)にTkaの接尾辞を挿入する. このとき,Tkaの各接尾辞は以下の3つのタイプに分類され る.S中に2回以上出現するTkの最も長い接尾辞をlrsS(Tk) とする. タイプ1: lrss(Tk)aよりも長いTkaの接尾辞. タイプ2: lrss(Tk)aよりも短く,lrsS(Tka)よりも長いTka の接尾辞. タイプ3: lrsS(Tka)よりも短いTkaの接尾辞. 図3に上記の分類を図示する.BlumerらのアルゴリズはTka の接尾辞を長いものから順に挿入していく.すなわち,まずは じめにタイプ1の接尾辞から挿入され,次にタイプ2接尾辞が 挿入される.タイプ3の接尾辞は,定義より既にDAWG(S′) で表現されているため,挿入する必要はない. 準オンライン構築アルゴリズムは,位置Tkを表現する活性 点(active point)と呼ばれる参照から始まる.この活性点を位 置Tkから1つずつ短い接尾辞を表す位置に遷移させながら, 新たな文字aを挿入していくことでTkaのすべての接尾辞を挿 入する.活性点から文字aを挿入するとき,以下の2つの場合 に分類できる.いま活性点が表現しているノードをvとする. (1) 位置vから文字aで遷移できるパスが既に存在している場 合,vaのすべての接尾辞はタイプ3に分類される.この場 合,以下の2つに細分化される.場合1の手続きを終了し たとき,新たな文字aのDAWG(S′)への挿入は終了する. (a) vから伸びるaのラベルがついた枝がprimaryな枝で ある場合,部分語グラフの構造に更新はない.このと き位置vaはlrsS(Tka)を表現している.場合2によ り新たなsinkノードsを作成している場合は,sの接 尾辞リンクをvaに設定する.また,もしvが位置Tk を表現していたならば,新たな活性点はvaになる. (b) vから伸びるaのラベルがついた枝がsecondryな枝 である場合は部分語グラフの構造の更新が必要である[2].vからaで到達したノードをuとする.まず, 新たなノードwを作成する.次に,uに入るsecondry な枝でuのタイプ3接尾辞を表しているものをすべて wへの入力辺として付け替える.これは,vから接尾 辞リンクをたどることで実行できる.次に,uからの 出辺をすべてwにコピーする.最後に,wの接尾辞 リンクを,uの接尾辞リンク先に設定し,uの接尾辞 リンクはwへのポインタへと変更する.このとき位 置va = wはlrsS(Tka)を表現している.場合2によ り新たなsinkノードsを作成している場合は,sの接 尾辞リンクをwに設定する.もしvが位置Tkを表現 していたならば,新たな活性点の位置はwとなる. (2) vからaの出辺がない場合,vがsinkノードなら新たな sinkノードsを作成する.次にvからシンクsへ文字a の辺で接続する.活性点をvの接尾辞リンク先に変更し, もう一度文字aの挿入を試みる.新たなsinkノードsは Tkaを表現している.そのため,場合1により部分語グラ フの更新が終了した場合は,活性点をsに設定する. 新たに作成したノードと枝,接尾辞リンクの数をqとする場 合,明らかに上記の手続きはO(q log σ)時間かかる.ここで log σは文字aではじまる出辺を見つけるのにかかる時間であ る.DAWG(S)のノードと枝,接尾辞リンクの数はO(n)個で あるため,1文字挿入するのにかかる時間はならしO(log σ)時 間である. 以上により,DAWG(S)はO(n log σ)時間とO(n)
語領域で準オンライン構築可能である.
事実 1. Blumerらによるアルゴリズムは,総文字列長nの文
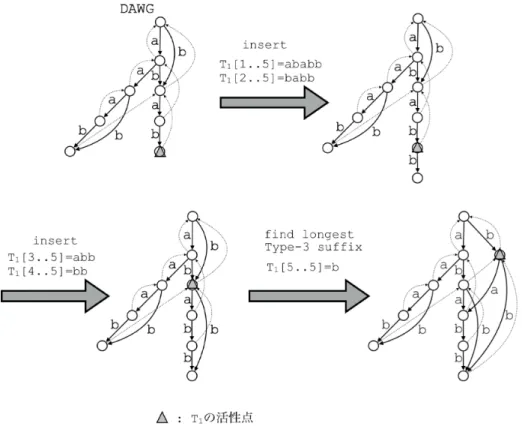
字列集合Sに対して,O(n log σ)時間とO(n)語領域で準オン ライン構築可能である. 3. 2 完全オンライン構築アルゴリズム 次に,上で説明したBlumerらの準オンラインアルゴリズム を基に,完全オンライン状況下での構築アルゴリズムを提案 する. 部分語グラフの完全オンライン構築は,準オンライン構築時 に管理していた活性点を1つではなく,すべてのテキストに 対し持つことで可能である.再び,文字列集合S′に対する部 分語グラフDAWG(S′)が構築されていることを仮定し,入力 (k, a)を受け取り,文字列Tkに文字aを追加した後の文字列集 合SのDAWG(S)を構築することを考える.部分語グラフの 更新は,k番目の文字列の活性点vk= [Tk]S′から始まり,それ 以後は3. 1節で示した準オンラインアルゴリズムの動作とまっ たく同様である.図 4に完全オンラインでの更新例を図示す る.新たに作成したノードと枝,接尾辞リンクの数をqとする 場合,明らかに上記の手続きはO(q log σ)時間かかる.ここで log σは文字aではじまる出辺を見つけるのにかかる時間であ る.DAWG(S)のノードと枝,接尾辞リンクの数はO(n)個で あるため,1文字挿入するのにかかる時間はならしO(log σ)時
間である. 以上により,DAWG(S)はO(n log σ)時間とO(n)
語領域で準オンライン構築可能である.ここで以下の定理を
得る.
定理1. K本の文字列の集合Sに対してn個の完全オンライ ン入力が与えられたとき,O(n log σ)時間かつO(n)語領域で
DAWG(S)を更新可能である. 各文字列の先頭に,他のどの場所にも出現しない特別な区切 り文字#kがついていることを仮定する.その時,部分語グラ フDAWG(S)の(逆)接尾辞リンクが,接尾辞木STree(S)に なることが知られている[2].ここに,SはSの各文字列をす べて反転したものである.これにより,定理1から,文字列が 右から左に伸長するright-to-left完全オンライン接尾辞木構築 についての以下の系が導かれる. 系 2. K 本の文字列の集合S に対してn個の完全オンライ ン入力が与えられたとき,O(n log σ)時間かつO(n)語領域で
STree(S)を更新可能である.
4.
一般化接尾辞木のオンライン構築
本節では,文字列集合に対する一般化接尾辞木の完全オンラ イン構築アルゴリズムを提案する.初めに,Ukkonenによっ て提案されたleft-to-right準オンラインアルゴリズムを導入す る.次に,Ukkonenによるアルゴリズムが,部分語グラフのよ うに簡単に拡張することができない理由を示す.最後に一般化 接尾辞木のleft-to-right 完全オンライン構築アルゴリズムを提 案する. 4. 1 UkkonenのLeft-To-Right準オンライン一般化接 尾辞木構築アルゴリズム 文字列集合S′に対する一般化接尾辞木STree(S′)が構築さ れていることを仮定し,入力(k, a)を受け取り,文字列Tkに 文字aを追加した後の文字列集合SのSTree(S)を構築するこ とを考える.準オンラインの状況下では,もし入力の文書番号 k (1 <= k <= K)と文字aの組(k, a)を受け取りTkの末尾に文 字aを追加した場合,文字列T1, . . . , Tk−1はそれ以上文字が追 加されることはなく,また,文字列Tk+1, . . . , TKは空文字列の ままである. このとき,静的な文字列T1, . . . , Tk−1の末尾に, 他のどの場所にも出現しない特別な区切り文字$kがついてい ることを仮定する.Ukkonenによる接尾辞木のオンライン構 築では,位置lrsS(Tk)から始まる活性点を1つずつ短い接尾辞 を表す位置に遷移させながら,新たな文字aを挿入していくこ とでTkaのすべての接尾辞を挿入する.このとき,葉ノードの 更新を省略することで,接尾辞木全体をO(n)時間で構築する. 位置vに新たな文字aの挿入を行う時,3. 1節で導入した挿入 するTkaの接尾辞の分類に従って次の3通りの場合がある. タイプ1 位置vは既に他の枝と重ならない単独の葉である. 葉ノードへ向かう枝のラベルを更新する必要があるが,後述す る方法で省略可能である. タイプ2 位置vから文字aで遷移できない.すなわちTkaは 木に含まれない.従ってvで分岐し,新しい葉を追加する. タイプ3 挿入点vから文字aで延長された点は,すでに木に 含まれている.木の更新の必要はない.図 4 完全オンライン部分語グラフにおける更新.S′ = {T1 = abab, T2 = aaab} から S ={T1b, T2} へ更新する.T1の sink ノードから順に新しい文字 b を挿入していく. Blumerらによる部分語グラフの準オンライン構築と同様に, Tkaの接尾辞を長いもの(タイプ1)から降順に挿入してい く.ここで,葉へ向かうラベルを(k, i,∞)の三組で表現し,常 にTk[i..|Tk|]を参照することで,タイプ1の接尾辞の明示的な 挿入を省略することができる.Ukkonenのアルゴリズムでは, 上記の性質を利用して,タイプ1では処理を省略し,タイプ2 の接尾辞から挿入していく.タイプ2の接尾辞で最長のもの は,位置lrsS(Tk)で表現されている.そのため,活性点は位 置lrss(Tk)を保存しておき,そこからタイプ2の接尾辞を長 さの降順に挿入していく.STree(S′)上の活性点の位置vから 文字aで遷移できないときは,新たな葉ノードwを作成し,v とwを文字aから始まるラベルで接続する.その後,活性点 をvの接尾辞リンク先に変更し,同様の処理を行う.この時, 最初に位置vから文字aで遷移可能であるとき,パスラベル va = lrss(Tk)は最長のタイプ3接尾辞である.そのため,活 性点を位置vaに変更し,文字aの挿入を終了する.この活性 点の更新はフェーズn =|S|が進むたびに,拡張される接尾辞 の開始位置jの深さが単調に増加することを意味する.そのた め,後戻りを行わずオンライン線形時間構築が可能となる. 4. 2 left-to-right完全オンライン接尾辞木構築の問題点 部分語グラフと違い,接尾辞木の場合,準オンラインと同様 の時間計算量で完全オンラインへの拡張することは容易ではな い.以下に,その理由を3つあげる. 問題1 入力として文書番号と入力文字の組(k, a)を受け取り, k番目の文字列TkがTkaに更新される場合を想定する.部分 語グラフの完全オンライン構築と同様に,文字列の本数だけ活 性点を用意する方法を考える.各活性点vkは準オンラインの 設定と同じく,2回以上出現しているTkの接尾辞の中で最も 長いものを表す位置lrsS(Tk)を覚えておき,そこから順に文 字aを挿入していく.しかしながら,完全オンラインの状況下 では,lrsS(Tk)の位置は,k番目の文字列以外の入力で逐次変 更される.図??に活性点が引き戻される例を示す.そのため, 入力のたびにすべての活性点を正しい位置に管理した場合,n 個の入力に対して,一般化接尾辞木の構築にO(Kn log σ)時間 を要する. 問題2 また,仮にすべての活性点を正しい位置に管理できた としても,活性点の位置が引き戻されることによる影響がある. いまj番目の活性点の位置が参照(vj, cj, ℓj)で表現されていた とする.その時,入力(k, a)により,j番目の活性点の位置が 参照(vj′, c′j, ℓj′)に変更された時,ℓ′j>= ℓjという不等式が成り 立つ.Ukkonenの準オンライン構築アルゴリズムでは,ℓ′jをタ イプ2の接尾辞の挿入回数で抑えることで,時間計算量をなら し線形時間にしていたが,活性点が引き戻される場合ℓ′jをなら すことはできない.このように,完全オンラインの状況下では, 準オンラインにおける計算量をならすテクニックが使えない. 問題3 別の問題として,葉ラベルの管理があげられる.各文 字列の末尾にユニークな区切り文字を挿入する準オンラインと 違い,完全オンラインの設定では,j番目の文字列の部分文字 列を参照する三つ組(j, i,∞)で表現された葉ラベルを,別の文 字列Tkが追い越す状況が発生する.このとき,j番目の文字 列が管理する葉ラベルで変更が必要なものをすべて,k番目の 文字列が管理する葉ラベルに変更しなければならない.このた
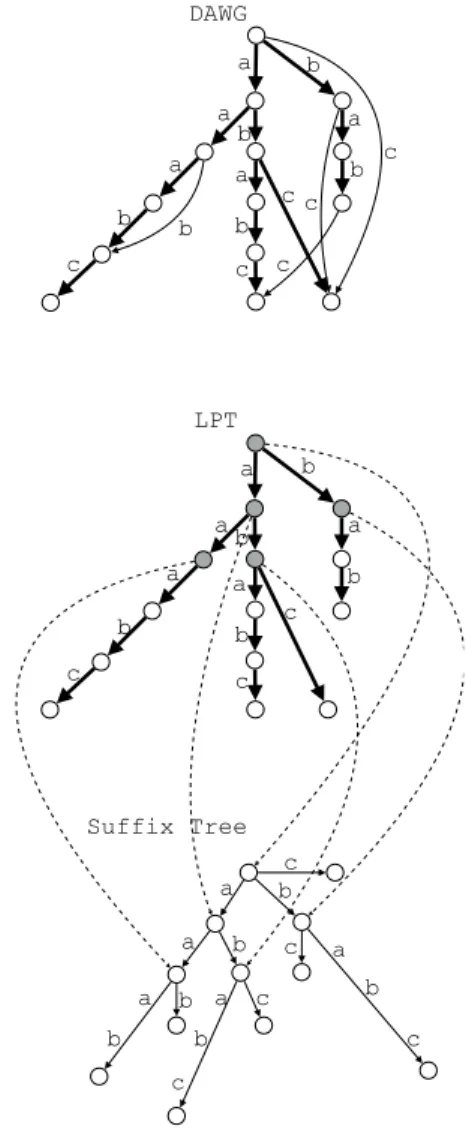
図 5 長 さ n = 10 の 完 全 オ ン ラ イ ン 入 力 S = (1, a), (1, b), (2, b), (1, a), (2, a), (1, b), (1, c), (2, b), (2, c), (2, d) が与えられた時の接尾辞木の構築.時刻 t = 8 時の S8={T 1= ababc, T2 = bab} における接尾時木と,時刻 t = 10 時の S10 ={T1 = ababc, T2 = babcd} における接尾時木を示す. lrsS(Ti) は文字列集合 S 上で 2 回以上出現している文字列 Ti の最長の接尾辞を表す.S8と S10において,lrs S(T1) の位置 が引き戻されることを示している. め,準オンラインでは可能だった,3つ組によるタイプ1接尾 辞の更新省略テクニックを用いることができない. 以下の節でこれらの問題を,部分語グラフを用いて解決する 方法を示す. 4. 3 left-to-right完全オンライン一般化接尾辞木構築アル ゴリズム 本小節では,部分語グラフを用いて,上記の問題点を解決し, 一般化接尾辞木の完全オンライン構築アルゴリズムを提案する. 図7に完全オンライン状況下における接尾辞木の更新例を示め す.アルゴリズムの概要を以下に示す.Tkaの接尾辞の挿入を, Ukkonenのアルゴリズムとは逆に,タイプ2の最も短いもの から順に昇順で挿入していく.そのために,最も長いタイプ3 接尾辞の位置vからアルゴリズムを始める.このアイデアは, 接尾辞木の実時間構築(real time construction)でも用いられ ている [7].挿入開始地点を見つけるために,まず部分語グラ フ上で挿入開始地点を見つけ,それに対応する接尾辞木上の位 置を計算する.また,1つ長い接尾辞へ移動するためには,接 尾辞リンクの逆リンクを導入する必要がある.対応する逆接尾 a b a a b c b a b c c a b b c DAWG c c a a a a a b c c c b b b c c b b Suffix Tree a b a a b c b a b a b c LPT c 図 6 S′={T1= aaab, T2= ababc, T3= ab} と S = {T1c, T2, T3} に 対 す る ,部 分 語 グ ラ フ DAWG(S) と そ の LPT (S) と
STree(S′) の対応.DAWG における太矢印は primary な枝 を表す.破線矢印は LPT (S) と STree(S′) で対応するノード間
を表す.
辞リンクを探す問題はsuffix tree oracleと呼ばれる.我々は,
FischerとGawrychowskiら[8]によるsuffix tree oracleのな らし計算量版を導入する.これらにより,問題1,2を解決す る.問題3のためには,葉ラベルの新たな表現方法を導入する. 補題3. 文字列集合S′に入力(k, a)を追加し,文字列集合S に更新する場合を考える.ある文字列Tkaの最長タイプ3接尾 辞lrsS(Tka)のSTree(S′)上の位置を,Sの総文字列長に線形 な領域の補助データ構造を用いることでO(log σ)時間で計算 可能である.
(証明) S′のlongest path tree, LPT LPT (S′)を導入する.
LPT (S′)は,DAWG(S′)のprimary枝のみからなる木構造で
ある.LPTの各ノードは,対応する部分語グラフのノードが分 岐している時,マークをつけられる.また,マークされたノー ドと,同じ部分文字列を表現するSTree(S′)上の実ノードを互 いにリンクする.また,LPT (S′)はnearest marked ancestor
(NMA)と呼ばれるデータ構造[9]により,(1)任意のノードか
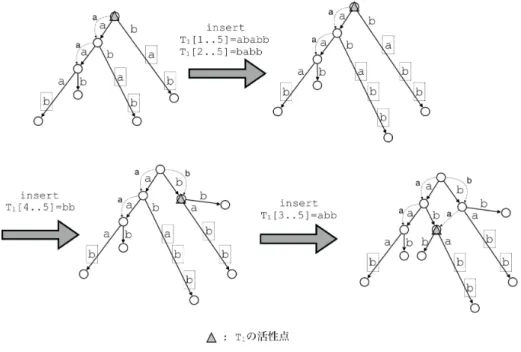
図 7 完全オンライン一般化接尾辞木問題における更新.S′={T1 = abab, T2 = aaab} から S ={T1b, T2} へ更新する.まず,タイプ 1 の接尾辞 ababb, babb は対応する部分語グラ フ DAWG(S) の更新で自動的に行われる.その後,タイプ 1 の接尾辞を,逆接尾辞リン クを用いて短いものから順に挿入していく. れていないノードを挿入する.(3)ノードをマークする.操作 をならしO(1)時間で行える. 入力(k, a)に対して,DAWG(S′)をDAWG(S)に更新した 時,DAWG(S′)上で最後に挿入した接尾辞は,ある文字列Tka の最長タイプ3接尾辞lrsS(Tka)のDAWG(S)上の位置を表し ている.そこで,DAWG(S′)を更新後,DAWG(S)のlrsS(Tka) に対応するLPT (S)のノードvから対応するSTree(S′)上の ノードv′へ移動を行えばよい.この時,ノードvがマークされ ているならば,リンクを辿った先がSTree(S′)上のlrsS(Tka) に対応するノードv′である.ノードvがマークされていない 場合,NMAクエリをかけることで,最も近いマークされた祖 先のノードuを見つけ,そこからuに対応する接尾辞木上の ノードu′に移動する.u′からv′への移動は,uとvの文字深 さの差をオフセットとしてu′から移動すれば良い.この時,枝 の選択にO(log σ)時間がかかる.また,u′からv′のパス上に は,LPTのマークされたノードの定義より実ノードは存在し ない.STree(S′)上のv′で新たな実ノードが作成された場合, LPT (S)のvをマークし,v′とリンクすれば良い.DAWG(S)
の領域計算量はSTree(S)と同じくO(n)語であり,NMAデー タ構造[9]はノード数に線形な領域で格納できるため,明らか にこの補助データ構造はS の総文字列長に線形な領域計算量 を持つ.時間計算量は,DAWG(S)のlrsS(Tka)の位置を見 つけるために,DAWG(S′)からDAWG(S)に更新するならし O(log σ)時間かかる.lrsS(Tka)からNMAクエリを引く時間 はならしO(1)時間である.接尾辞木上のlrsS(Tka)の位置を 計算するために,枝の選択が1回必要なので,O(log σ)時間 かかる.以上により,lrsS(Tka)のSTree(S′)上の位置を,S の総文字列長に線形な領域の補助データ構造を用いることで O(log σ)時間で計算可能である. 上記補題により,最長のタイプ3接尾辞の位置を計算でき る.そこから,接尾辞を昇順に挿入していくには,接尾辞木 上の逆接尾辞リンクをたどって,1文字長い接尾辞を表現す る位置に移動する必要がある.逆接尾辞リンクとは,ノードv と文字bに対して,slink (vb) = vの時,rslinkb(v) = vbと定
義されるリンクである.ここで,suffix tree oracleとは,ノー
ドvと文字bの組(v, b)が与えらえれた時,rslinkb(u)が定義
されているvの最近祖先uを返すデータ構造である.Fischer
とGawrychowski [8]によるsuffix tree oracleでは,最悪計算
量O(log log n + (log log σ)2/ log log log σ)時間とO(n)語領域 でこれを達成する.ここに,nは接尾辞木の葉ノードの個数 である.以下の補題で,より単純なならし計算量のsuffix tree
oracleを導入する.
補題 4. n個の葉を持つ接尾辞木に対して,領域O(n)語で,
suffix tree oracleクエリをならしO(log σ)時間で答え,ならし
O(log σ)時間で新たな接尾辞を挿入可能である,ここにσはア
ルファベットサイズである.
(証明) (Sketch) FischerとGawrychowski [8]のsuffix tree
oracleでは,最悪計算量を達成するために,NMAクエリを最
悪O(log log n)時間で解くデータ構造を採用している[7].こ のデータ構造をWestbrook [9]によるNMA構造に置き換え ることにより,ならしO(1)時間で解くことができる.また,
(log log σ)2/ log log log σの項は整数アルファベットを仮定し
二分木用いることで,より一般的なアルファベットに対して predecesorクエリをO(log σ)時間でとく.以上により,計算 量はならしO(log σ)時間となる. 最後に,問題3を解決するため,葉へ向かう辺のラベルの新 たな参照表現であるラベルの遅延表現を導入する.基本的なア イデアは,葉へ向かう最初の一文字のみ管理し,具体的なラベ ル文字は,対応する部分語グラフ上で読み取る方法である.こ れにより,以下の補題を与える. 補題 5. 入力(k, a)が与えられたとき,葉へ向かうラベルの遅 延表現により,ならしO(log σ)時間で,必要なすべての葉ラベ ルの更新が可能である. (証明) (Sketch). STreeSの内部ノードwから,新たな葉 ノードeを挿入した時,wに対応する部分語グラフのノードw′ は,sinkノードまでのパスで,wからeまでのラベルを表現し ている.葉へ向かうラベルは,部分語グラフによる新たなsink ノードの作成で自動的に更新される.問題となるのは,先頭文 字しか記憶していないwからeへの辺上で,新たな内部ノード uを作成した時である.この時,wからuへのラベルlは先頭 一文字を除いて不明だが,新たな入力が到着するたび,部分語 グラフの対応するノードからラベル文字を読み取り,lを遅延 評価で確定させることができる. 以上の補題により,以下の定理を得る. 定理 6. K本の文字列の集合Sに対してn個の完全オンライ ン入力が与えられたとき,O(n log σ)時間かつO(n)語領域で
STree(S)を更新可能である.
5.
ま
と
め
本稿では非同期に文字が入力される複数ストリームに対する 索引構築を考察した.その結果,まず完全オンライン構築の設 定を導入した.次に,部分語グラフのならしO(n log σ)時間と O(n)語領域で完全オンライン構築するアルゴリズムを与えた. ここでnは総文字列長,σはアルファベットサイズである.最 後に,一般化接尾辞木について,部分語グラフと並列に構築す ることでならしO(n log σ)時間とO(n)語領域で完全オンライ ン構築するアルゴリズムを与えた.今後の課題として,実際の ストリームデータでは,スライディングウィンドウ[10]や頻出 語の適応的収集[11, 12]などのより高度な機能をもつ文字列索 引も必要である.文 献
[1] E. Ukkonen. On-line construction of suffix trees.
Algorith-mica, Vol. 14, No. 3, pp. 249–260, 1995.
[2] A. Blumer, J. Blumer, D. Haussler, R. Mcconnell, and A. Ehrenfeucht. Complete inverted files for efficient text retrieval and analysis. J. ACM, Vol. 34, No. 3, pp. 578–595, 1987.
[3] Dan Gusfield and Jens Stoye. Linear time algorithms for finding and representing all the tandem repeats in a string.
J. Comput. Syst. Sci., Vol. 69, No. 4, pp. 525–546, 2004.
[4] P. Weiner. Linear pattern-matching algorithms. In Proc. of
14th IEEE Ann. Symp. on Switching and Automata The-ory, pp. 1–11, 1973.
[5] Anselm Blumer, Janet Blumer, David Haussler, Andrzej Ehrenfeucht, M. T. Chen, and Joel Seiferas. The small-est automaton recognizing the subwords of a text. TCS, Vol. 40, pp. 31–55, 1985.
[6] Dan Gusfield. Algorithms on Strings, Trees, and Sequences:
Computer Science and Computational Biology. Cambridge
University Press, 1997.
[7] Dany Breslauer and Giuseppe F. Italiano. Near real-time suffix tree construction via the fringe marked ancestor prob-lem. J. Discrete Algorithms, Vol. 18, pp. 32–48, 2013. [8] Johannes Fischer and Pawel Gawrychowski.
Alphabet-dependent string searching with wexponential search trees. In CPM 2015, pp. 160–171, 2015. Full version is available at http://arxiv.org/abs/1302.3347.
[9] Jeffery Westbrook. Fast incremental planarity testing. In
ICALP 1992, pp. 342–353, 1992.
[10] Shunsuke Inenaga, Ayumi Shinohara, Masayuki Takeda, and Setsuo Arikawa. Compact directed acyclic word graphs for a sliding window. In Proceedings of 9th International
Symposium on String Processing and Information Retrieval (SPIRE 2002), pp. 310–324, 2002. [11] 高木拓也, 有村博紀. マルチヘッド接尾辞トライを用いた低メモ リ型マルチストリーム索引の構築. 第 7 回データ工学と情報マ ネージメントに関するフォーラム (DEIM’15), No. P2. 電子情 報通信学会, 2008 年 3 月. [12] 上村卓史, 金田悠作, 喜田拓也, 有村博紀. 大規模なテキストに 対する部分文字列出現頻度の推定. 第 19 回データ工学ワーク ショップ (DEWS ’08), No. E7-1. 電子情報通信学会, 2008.