分散制約最適化問題の階層化と
分散センサ網における
観測資源割り当て問題への適用
指導教員
松尾 啓志 教授
津邑 公暁 准教授
名古屋工業大学大学院工学研究科
修士課程創成シミュレーション工学専攻
平成
21
年度入学
21413516
番
太田 和宏
平成
23
年
2
月
3
日
目次
1 はじめに 1 2 分散制約最適化問題 2 2.1 形式化 . . . 2 2.2 分散制約最適化問題を解くための解法 . . . 3 2.2.1 厳密解法 . . . 3 2.2.2 非厳密解法 . . . 4 3 分散センサ網の観測資源割当て問題 7 3.1 グリッドモデル . . . 7 3.2 分散制約最適化問題に基づく形式化 . . . 8 3.2.1 STAV(Sensor-TargetAsVariable) . . . 8 3.2.2 TAV(Target As Variable) . . . 10 3.3 エージェンシによる協調モデル . . . 11 4 提案手法: 2 つの階層からなる形式化 12 4.1 リーダー選出層 . . . 13 4.2 観測資源割り当て問題解決層 . . . 16 4.3 2つの階層からなる形式化を用いた場合の解法 . . . 17 5 提案手法: 動的な問題への対応 20 5.1 センサの割り当ての状態 . . . 22 5.2 変数の生成・削除,表の作成 . . . 22 5.2.1 変数の生成・削除 . . . 23 5.2.2 割り当て状態を保持する表の生成 . . . 25 5.3 観測対象に割り当てられたセンサの組み合わせの変化の抑制 . . . 26 5.3.1 リーダーを同じグループから再選出するための制約 . . . 27 5.3.2 観測対象に割り当てられたセンサの組み合わせの変化を抑制 するための制約 . . . 28 5.4 部分的な観測対象に割り当てられたセンサの組み合わせの変化の抑制 296.3 変数の初期値 . . . 34 6.4 例題の生成方法 . . . 35 6.5 ランダムに例題を作成し,制約違反が発生する可能性が低い変数の初 期値を用いた場合の評価結果 . . . 35 6.5.1 準最適解を得るまでのサイクル数の比較 . . . 36 6.5.2 準最適解の評価値の比較 . . . 36 6.5.3 各観測対象に割り当てることが可能なセンサの数 . . . 37 6.5.4 観測対象に割り当てられたセンサの数に関する評価 . . . 38 6.5.5 観測対象に割り当てられたセンサの組み合わせの変化に関す る評価 . . . 39 6.6 意図的に複雑な例題を作成し,制約違反が発生する可能性が低い変数 の初期値を用いた場合の評価結果 . . . 40 6.6.1 準最適解を得るまでのサイクル数の比較 . . . 41 6.6.2 準最適解の評価値の比較 . . . 42 6.6.3 各観測対象に割り当てるとが可能なセンサの数 . . . 42 6.6.4 観測対象に割り当てられたセンサの数に関する評価 . . . 43 6.6.5 観測対象に割り当てられたセンサの組み合わせの変化に関す る評価 . . . 44 6.7 ランダムで例題を作成し,制約違反が発生する可能性が高い変数の初 期値を用いた場合の評価結果 . . . 45 6.7.1 準最適解を得るまでのサイクル数の比較 . . . 45 6.7.2 準最適解の評価値の比較 . . . 46 6.7.3 各観測対象に割り当てることが可能なセンサの数 . . . 46 6.7.4 観測対象に割り当てられたセンサの数に関する評価 . . . 47 6.7.5 観測対象に割り当てられたセンサの組み合わせの変化に関す る評価 . . . 49 6.8 意図的に複雑な例題を作成し,制約違反が発生する可能性が高い変数 の初期値を用いた場合の評価結果 . . . 49 6.8.1 準最適解を得るまでのサイクル数の比較 . . . 50
6.8.5 観測対象に割り当てられたセンサの組み合わせの変化に関す る評価 . . . 53 6.9 総括 . . . 54 7 まとめ 54 謝辞 55 参考文献 55
1
はじめに
近年,分散して配置されたセンサによる協調的なセンシングのような分散システム を構成する複数の自律的な主体が分散・協調的な処理を行う枠組みである,マルチエー ジェントシステムの研究が行われている.そのようなマルチエージェントシステムに おける協調的問題を解決する基本的な枠組みとして分散制約最適化問題 [1][2][3][4][5][6] が研究されている.分散制約最適化問題では,エージェントの状態/意思決定が変数と して表現され,エージェント間の関係が制約/評価関数として表現される.各エージェ ントは互いに情報を交換しつつ自身の変数値を決定し,制約/評価関数の評価値を統合 した値を最適化する変数値の割り当てを得る.このような表現は,分散システムにお ける資源スケジューリングなどに含まれる,協調問題解決の本質的な問題を表すもの として重要である. マルチエージェントシステムの応用分野として分散センサ網の研究も行われている [5][6][7][8][9].特に,分散センサ網における資源割り当て問題を分散制約最適化問題と して形式化する手法の研究がされている [5][6].分散センサ網には様々な目的があり, 広域の観測情報の収集や [7][8][9] などが挙げられる.本論文では注視制御可能な複数 の自律的なセンサによる観測システムを想定する.複数の対象を複数のセンサにより 注視するような制御のためには,観測資源の割り当て問題の解決が必要である.実際 的な観測システムでは観測対象が移動するなど,環境は動的に変化する.このような 動的な環境への追従は動的に変化する環境を表す時系列的な割り当て問題を反復的に 解くこととしてとらえることが出来る.一方で,各時刻の問題を解決するまでの時間 は限られており,解を短時間で得る必要がある.そのため比較的短時間で非厳密解を 得ることが可能な確率的な解法を用いることが有効であると考えられる.このような 観測資源の割り当て問題においては,準最適な観測資源の割り当てを得るうえで,各 エージェントが矛盾無く意思決定を行う必要がある.しかし,エージェントの協調と資 源割り当てを含む問題は複雑であり,探索に要する時間の抑制には課題がある.そこ で本論文では,問題をリーダーを選出する階層とリーダーにより観測資源割り当て問 題を解決する階層の 2 つの階層に分割し,解を得るまでの時間を削減する手法を提案 する.これにより,問題の複雑さを抑制し解探索時間を削減できると期待される.ま た,観測対象の配置が変化するような動的な問題では,頻繁なセンサの視野方向の制 御による観測情報の劣化を抑制する必要がある.この観点から,問題が変化した際に, 観測対象へ割り当てられたセンサの組み合わせの変化を抑制することは重要であるといえる.そこで,前の時刻の問題について得た解に基づいて,観測対象に割り当てら れたセンサの状態に関する情報を利用し,観測対象の配置が変化した後に観測対象へ 割り当てられるセンサの組み合わせの変化を抑制するための制約も導入する. 本論文の構成を次に示す.第 2 章では分散制約最適化問題について説明し,第 3 章 では分散センサ網の観測資源割り当て問題について説明する.また従来研究で提案さ れた分散制約最適化問題による分散センサ網の観測資源割り当て問題の形式化とエー ジェントのグループであるエージェンシに基いた協調的な観測システムについて説明 する.第 4 章及び第 5 章では提案手法について説明する.そして,第 6 章で評価を行 い,提案手法の有効性についての考察を示す.最後に第 7 章で結言を述べる.
2
分散制約最適化問題
分散制約最適化問題は,複数のエージェントに変数と制約/評価関数が分散して配 置された問題として形式化された,離散最適化問題である.分散制約最適化問題では, エージェントの状態/意思決定が変数として表現され,エージェント間の関係が制約/ 評価関数として表現される.各エージェントは互いに情報を交換しつつ自身の変数値 を決定し,制約/評価関数の評価値を統合した値を最適化する変数値の割り当てを得 る.このような表現は,分散システムにおける資源スケジューリングなどに含まれる, 協調問題解決の本質的な問題を表すものとして重要である.本章では分散制約最適化問題 (Distributed constaint Optimization Problem,DCOP)[1][2][3][4][5][6] の基本的な形式とその解法について説明する. 2.1 形式化 基本的な分散制約最適化問題の形式化を次に示す. • マルチエージェントシステムに含まれるエージェントの集合を A で表す. • A に含まれるエージェント ai ∈ A は変数の集合を持つ.aiが持つ変数の集合を Xi ={x1i, x2i,· · · , xki} で表す. • エージェント aiは Xiに含まれる変数 xki の値のみ決定できる.すなわち,変数は エージェントの意思決定を表す. • 変数間の関係は制約 c によって表す. • 制約 c に関する評価関数 fcを定義する.評価関数 fcは変数値の組み合わせについ ての評価値を定義する. • 制約の評価値の合計値が最適になる変数値を各変数に割り当てることが問題の目
的である. 特に本論文での形式化では,制約は次の 2 種類に分類される. • 緩和不可能な制約 満たさなければシステムが破綻してしまうような制約である. • 緩和可能な制約 満たしていなくてもシステムが破綻することはない制約である. このように制約が分類されるため,本論文での問題の目的は,緩和不可能な制約を充 足し,緩和可能な制約をできるだけ満足するような変数値の組合せを決定することで ある.一方で,緩和不可能な制約は全て充足しているが,緩和可能な制約の一部は満 されていない解を準最適解と呼ぶことにする. 2.2 分散制約最適化問題を解くための解法 分散制約最適化問題解の解法として解の完全性が保証されている厳密解法と完全性 が保証されない非厳密解法が提案されている. 2.2.1 厳密解法 分散制約最適化問題を解くための厳密解法として,ADOPT(Distributed Stochstic Search(Asynchronous Distributed Constraint Optimization)[1][10][11]や DPOP[2] が 提案されている. ADOPT[1][10][11] ADOPT[1][10][11]では,前処理として制約網に対する深さ優先探索木を生成する. また,深さ優先探索木に基く擬似木 (pseudo-tree) を生成する.そして,擬似木により 定義される半順序関係にしたがって,メッセージ交換型の解探索により最適解を求め る.解探索では ADOPT は分枝限定法/A*による探索を行う.ADOPT の問題点とし て,探索木の induced-width[2] にしたがって,解探索時間とメッセージ数が指数関数 的に増加する.そのため,induced-width が大きい場合は,探索時間の制限のために, ADOPTを分散センサ網における観測資源割り当て問題へ適用することには課題があ るといえる. DPOP[2] DPOP[2]も ADOPT と同様で,前処理として制約網に対する深さ優先探索木を生成 する.また,深さ優先探索木に基く擬似木 (pseudo-tree) を生成する.そして,擬似木 により定義される半順序関係にしたがって,メッセージ交換型の解探索により最適解 を求める.DPOP では動的計画法に基づく.DPOP の問題点として,前処理で生成さ
れた擬似木の幅にメッセージサイズが依存しており,メッセージサイズやメモリ使用 量が指数関数的に増加する.そのため,induced-width が大きい場合は,メモリ量の制 限のために,DPOP を分散センサ網における観測資源割り当て問題へ適用することに は課題があるといえる. 2.2.2 非厳密解法 一方で,分散制約最適化問題を解くための非厳密解法として,反復改善型のアルゴリズ ムである DBA(Distributed BreakOut Algorithm)[12],確率的なアプローチを用いた反 復改善型のアルゴリズムである DSA(Distributed Stochstic Search)[3] や DSTS(Distributed
Stochstic Tabu Sear)[4]が提案されている.これらの解法は厳密解法とは違い,解の完
全性が保証されないが,比較的短時間で非厳密解を得ることが可能である.本論文で 想定するような準時間性を要するシステムでは,解を得るまでの時間の観点から,非 厳密解法が有用であると考えられる.特に,本研究では,拡張が容易な確率的解法に 着目する. DBA[12] DBA[12]は反復改善型アルゴリズムであり,各エージェントが独立に繰り返し変数 値の改善を行うことで問題を解く.DBA では,局所最適解へ陥ることを防ぐために, breakoutという機構を持つ.準局所最適解を検知した場合,制約の重みを変更するこ とにより,準局所最適解から脱出する.バックトラックなどには頼らない.DBA は次 のような特徴を持つ. • 制約で関係するエージェント間で改善可能な評価値の改善量を交換し,もっとも 改善量が大きなエージェントのみ変数値を変更できる. • 制約で関係するエージェントが改善可能な評価値の改善量が 0 であり,自身に充 足されない制約が存在する場合,準局所最適解であると判断する. • 準局所最適解に陥った場合,充足されていない制約の重みに変更を加える. DBAは単純なバックトラックを用いた解法などより,高速に解を得ることが出来る. しかし,局所最適解から脱出するために制約の重みを変更する機構により,無限ルー プに陥る可能性が問題点として指摘されている. DSA[3] DSA[3]は確率的なアプローチを用いた反復改善型のアルゴリズムである.DSA の 詳細を図 1 に示す.図 1 はエージェント aiが主体の擬似コードである. DSAでは書くエージェントが互いに変数値を交換しつつ解を探索する.エージェン ト aiは制約で関係するエージェントの変数値に基き,自身の各変数値に対する評価値
1 initialize V;
2 own statuslef tarrow false;
3 empty tabu list;
4 whilemeet the end requirementdo
5 send v message to agents related by constraints;
6 receive others’ vmessage;
7 call set new value;
8 if new values of valiables is assigned then
9 generate v message(ai, V );
10 send v message to agents related by constraints;
11 end if
12 end while
13 procedureset new value 14 if ∆≥ 0 then
15 assign new values to variables withp1; 16 end if 図 1: DSA の擬似コード を計算する.最も評価値が良くなる値を,変数値の候補とする.エージェント aiは, 図 1中 14-16 行における処理で,評価値の改善量 ∆≥ 0 の場合,確率 p1に基づいて先述 の変数値の候補に変数値を変更する.変数値が変更された場合, 図 1 中 8-11 行におけ る処理で,変数値を通知するためのメッセージ v message を生成し,制約で関係する エージェントに送信する. DSAは非常にシンプルで軽量なアルゴリズムであるが,局所最適解に陥りやすく, また局所最適解から脱出しづらいという問題点がある.そのため,解の精度が求めら れるような場合では適用するには課題がある. DSTS[4] DSTS[4]は確率的なアプローチを用いた反復改善型アルゴリズムである DSA に,局 所解からの脱出を目的として,タブー探索を組み込んだアルゴリズムである.DSTS の詳細を図 2 に示す.図 2 はエージェント aiが主体の擬似コードである. DSTSでは各エージェントが互いの変数値を交換しつつ解を探索する.各エージェ ントは制約で関係するエージェントの変数値に基き,自身の各変数値に対する評価値 を計算する.そして,最も評価値が良くなる変数値を,変数値の候補とする.エージェ ントは,図 2 中 23-24 行における処理で,確率 p1に基づいて先述の変数値の候補に変 数値を変更する.また,変数値を変更する際に,以前の変数値の履歴をタブーリスト に追加し,一定期間 (TABU 期間) その値への遷移を禁止する.タブー探索のために, 評価値の改善量 ∆ が増加するような変数値しか選択出来ない可能性もある.その場合
1 initialize V;
2 own statuslef tarrow false;
3 empty tabu list;
4 whilemeet the end requirementdo
5 send message(v message, t message)agents related by constraints;
6 receive others’messages;
7 call set new value;
8 if all values ∈tabu listthen
9 own status← true; 10 generate t message(ai)
11 send t messageto agents related by constraints;
12 else if new values of valiables is assigned then
13 generate t message(ai, V );
14 send v message to agentsrelated by constraints;
15 add new value to tabu list;
16 end if
17 end while
18 procedureset new value 19 if all values ∈tabu listthen
20 noting to do;
21 else if all conflicting agents’own status= true then
22 assign new values to variables;
23 else if ∆≥ 0 then
24 assign new values to variables withp1; 25 else if current violation> 0 then
26 assign new values to variables withp2; 27 end if 図 2: DSTS の擬似コード にも,図 2 中 25-26 行における処理で,自身の制約が満されていなければ,確率 p2に 基づいて変数値を変更する.これらの処理で変数値が更新された場合,図 2 中 12-15 行 における処理で,自身の変数に関するメッセージ v message を生成し,制約で関係す るセンサに送信する. また,変数の値域に含まれる全ての値がタブーリストに含まれる場合,自身をタブー 状態とする.その場合は,図 2 中 19-20 行における処理のように,変数値の変更は行わ ない.また,図 2 中 8-11 行における処理で,メッセージ t message を生成し,タブー状 態であることを制約で関係するエージェントに通知する.制約で関係する全てのエー ジェントがタブー状態であった場合は,図 2 中 20-21 行に示すように,強制的に変数値 を違う値に変更する.図 2 中,V は変数の集合を示し,tabu list はタブーリストを示 す.また,own status は自身がタブー状態であるかどうかを示し,own status = true の場合がタブー状態である.
図 3: グリッドモデルでの表現
3
分散センサ網の観測資源割当て問題
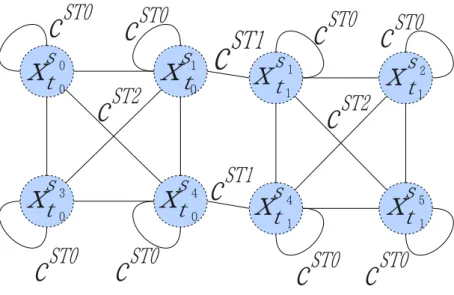
分散センサ網の観測資源割り当て問題とは,複数の自律的なセンサと複数の観測対 象が存在するような状況を想定した問題である.分散センサ網の観測資源割り当て問 題では,各センサをどの観測対象に割り当てるかを決定することが目的である. 本章では,分散センサ網の観測資源割り当て問題を形式化する.また, 本論文で想定 するような観測システムを実現するための関連研究についても説明する. 3.1 グリッドモデル 本論文ではセンサの持つ観測資源を観測対象に割り当てる観測資源割り当ての基礎 的な表現として,センサがグリッド状に配置され,観測対象が各区画に配置されるモ デルを用いる.このようなモデルは関連研究でも用いられている [5][6].本論文では, この様なモデルをグリッドモデルと表記する. 本論文で想定するシステムでは,制御の対象となるのはセンサのみである.すなわ ち,センサをエージェントとみなす.図 3 では siがセンサを示し,tjが観測対象を示 す.ここでは各区画には多くても 1 個の観測対象しか存在できないものとした.また, 実際のシステムでは様々な観測資源に関する制限やシステムの目的がある.本論文で は,次のような制限及び目的を設定する. • センサの視野に関する制限 実際のシステムではセンサの視野には制限がある.この制限を緩和することは できない.ここでは, センサは隣接する区画のみ観測することが可能とした. • センサの観測資源に関する制限 本論文では各センサが同時に多数の対象物を注視することは出来ないものとし た.この制限を緩和することはできない.ここでは,1 個のセンサを同時に複数図 4: STAV による制約網の表現 の観測対象に割り当てることはできないとした. • システムの目的 センサによる観測によって得られる情報量の向上のために,1 個の観測対象を 複数のセンサで観測することが望ましい.理由として,例えば,観測対象の座標 推定の精度を向上するための十分な観測情報の要求などが挙げられる.ここでは, 可能な限り 3 個のセンサを 1 個の観測対象に割り当てることを目的とした.しか し,この目的は緩和可能であり,3 個未満のセンサで観測対象を観測することも 可能である. 3.2 分散制約最適化問題に基づく形式化 分散制約最適化問題に基づく分散センサ網の観測資源割り当て問題の形式化につい て説明する.ここでは従来の形式化として,センサと観測対象の組について変数を定 義する表現である STAV(Sensor-Target As Variable),および観測対象について変数を 定義する表現である TAV(Target As Variable) について説明する. 3.2.1 STAV(Sensor-TargetAsVariable) STAVはセンサと観測対象の組を変数として定義する表現である.この表現に類似す る表現は文献 [5] で用いられている.この表現では各センサは観測可能な観測対象の数 だけ変数を持つ.図 3 の配置の制約網を STAV を用いて表現すると図 4 のようになる. 図 4 において xsi tj はセンサ siが持つ観測対象 tjに関する変数を表している.この例で
は,s0,s2,s3,s5は観測可能な観測対象が 1 個なので変数を 1 個持つ.一方,s1,s4は 観測可能な観測対象が 2 個なので変数を 2 個持つ.xsi tjの値はどのセンサが観測対象 tj に割り当てられているかを示す.観測対象 tjを観測可能なセンサの集合が{s0,· · · , sn} ならば,センサ siがもつ観測対象 tjに関する変数 xstjiは観測可能なセンサの組み合わ せを表す変数値をとる.変数 xsi tjの値域は{φ, {s0}, · · · , {sn}, {s0, s1}, · · · , {s0,· · · , sn}} と表すことができる. この表現における制約は図 4 中 cST 0, cST 1, cST 2で示した 3 種類の制約がある. • cST 0(xsi tj): 観測対象への観測資源割り当てに関する制約 この制約は各観測対象に可能な限り 3 個のセンサを割り当てるための制約である. 本論文で想定するシステムでは,可能な限り各観測対象に 3 個のセンサを割り当 てることを目的としている.そのため,観測対象 tjに割り当てられたセンサの数 が 3 個に満たない場合にこの制約は違反となる.この制約は緩和可能である. 制約 cST 0に対する評価関数 f cST 0は式 (1) で表現される.ただし wc ST 0 は制約の評 価値を示す定数値である.式 (1) では njは観測対象 tjに割り当てられたセンサの 数を示す. fcST 0(xsi tj) = wc0ST 0 nj = 0 wcST 0 1 nj = 1 wcST 0 2 nj = 2 0 otherwise (1) • cST 1(xsi tj, x si tj0): 観測資源の制限に関する制約 この制約は各センサが同時に複数の観測対象に割当てられることを制限するため の制約である.本論文で想定するシステムでは,各センサは同時に複数の観測対 象に割り当てることはできないとした.そのため,で 1 個のセンサが同時に 2 個 以上の観測対象に割り当てられた場合にこの制約は違反となる.この制約は緩和 不可能である. 制約 cST 1に対する評価関数 fcST 1は式 (2) で表現される.ただし wc ST 0 は制約の評 価値を示す定数値である. fcST 1(xsi tj,xsitj0) = wcST 1 xsi tj∩ x si tj0 6= φ 0 otherwise (2) • cST 2(xsi tj, x si0 tj ): 観測資源の割り当ての整合性に関する制約
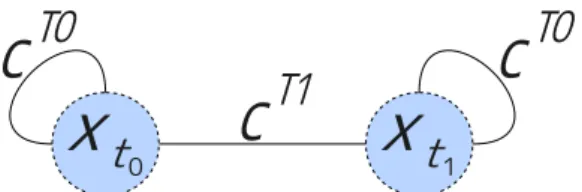
図 5: TAV による制約網の表現 この制約は同じ観測対象を観測可能なセンサが協調するための制約である.セン サ間で協調するには,同じ観測対象に割り当てられるセンサの組み合わせについ て,同じ意志を示さなければならない.そのため,同じ観測対象に対する観測資 源の割り当ての組み合わせがセンサ間で異なっていた場合にこの制約は違反とな る.この制約は緩和不可能である. 制約 cST 2に対する評価関数 f cST 2は式 (3) のように表される.ただし wc ST 2 は制約 の評価値を示す定数値である. fcST 2(xsi tj,x si0 tj ) = wcST 2 xsi tj 6= x si0 tj 0 otherwise (3) STAVを用いて形式化した場合,各センサは観測可能な観測対象の数だけ変数を持つ. そのため,観測対象数が増えた場合,システム全体の変数が増加する.また,観測対 象数が同じ場合でも,センサの数が増えれば変数の数が増加する.それに伴い制約の 本数が増加する. 3.2.2 TAV(Target As Variable) TAVは観測対象を変数として定義する表現である.この表現に類似する表現は文献 [6]で用いられている.この表現では各観測対象について変数を定義するので,1 個の 観測対象に関する変数は全体で 1 個である.図 3 の配置の制約網を TAV を用いて表現 すると図 5 のようになる.図 5 において xtjは観測対象 tjに関する変数を表している. xtj の値はどのセンサが観測対象 tjに割り当てられているかを示す.観測対象 tj を観 測可能なセンサの集合が{s0,· · · , sn} ならば,観測可能なセンサの組み合わせを表す 変数値をとる.変数 xtj の値域は{φ, {s0}, · · · , {sn}, {s0, s1}, · · · , {s0,· · · , sn}} と表す ことができる. この表現における制約は図 5 中 cT 0, cT 1で示した 2 種類の制約がある. • cT 0(x tj): 観測対象への観測資源割り当てに関する制約 各観測対象に可能な限り 3 個のセンサを割り当てるための制約である.本論文で 想定するシステムでは,可能な限り各観測対象に 3 個のセンサを割り当てること
を目的としている.そのため,観測対象 tjに割り当てられたセンサの数が 3 個に 満たない場合に違反となる.この制約は緩和可能である. 制約 cT 0に対する評価関数 f cT 0は式 (4) で表現される.ただし wc T 0 は制約の評価 値を示す定数値である.式 (4) では njは観測対象 tjに割り当てられたセンサの数 を示す. fcT 0(x tj) = wc0T 0 nj = 0 wc1T 0 nj = 1 wcT 0 2 nj = 2 0 otherwise (4) • cT 1(x tj, xtj0): 観測資源の制限に関する制約 1個のセンサが同時に複数の観測対象に割当てられることを制限するための制約 である.本論文で想定するシステムでは,各センサは同時に複数の観測対象に割 り当てることはできないとした.そのため,1 個のセンサが同時に 2 個以上の観 測対象に割り当てられた場合に違反となる.この制約は緩和不可能である. 制約 cT 1に対する評価関数 f cT 1は式 (5) で表される.ただし wc T 1 は制約の評価値 を示す定数値である. fcT 1(x tj,xtj0) = wcT 1 xtj ∩ xtj0 6= φ 0 otherwise (5) TAVを用いた形式化では STAV を用いた場合よりも変数及び制約の数が少ない.また, 観測対象ごとに変数を定義するため,センサの数が増えても変数の数は増加しない.そ のため,問題規模が大きくなっても,問題の複雑さは STAV よりも抑えられると考え られる.しかし,本論文で想定する観測システムでは,観測対象は制御の対象ではな く,制御の対象はセンサのみである.そのため,TAV を用いた形式化をそのまま適用 することは不可能である. 3.3 エージェンシによる協調モデル 分散制約最適化問題の枠組とは別にセンサのグループであるエージェンシを用いた 分散協調処理による観測システム [7][8][9] が提案されている.ここでは,エージェンシ による協調モデルと呼ぶ.エージェンシによる協調モデルの概念図を図 6 に示す.この システムでは,視野を制御可能な複数のカメラセンサと複数の観測対象からなる状況
図 6: エージェンシによる協調モデル を想定しており,本論文で想定するシステムの条件と同じである.システムは自律的 に動作するカメラセンサ(AVA: ActiveVisionAgent)の集合によって構成される.こ のシステムの概要は以下の通りである. • AVA を割り当て可能な観測資源として扱う • AVA は観測対象を検出すると,観測対象ごとにエージェンシを作成する • AVA 同士で情報を交換し,各観測対象に対して 1 つのエージェンシが存在するよ うに調整する • 各エージェンシには代表の AVA(エージェンシマネージャ)が 1 個存在する他の AVAはエージェンシマネージャの意思決定に従う • 各エージェンシマネージャは互いに情報を交換し,観測資源の配分を決定する • 観測対象の情報は各エージェンシマネージャに集約される このシステムは実機を用いた小規模な実験環境で有効性が実証されている.よって, 階層的な協調構造は効率的な協調動作を実現する手法として有効であると考えられる. しかし,この手法では,分散制約最適化問題のような最適化問題としての問題表現と その解法は用いられていない.
4
提案手法
: 2
つの階層からなる形式化
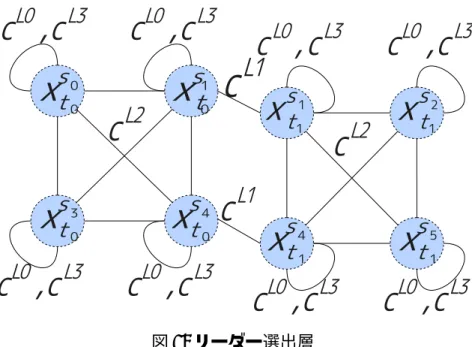
3.2.1で説明した STAV や 3.2.2 で説明した TAV のような制約網による形式化に,エー ジェンシによる協調モデルの持つ階層的な構造を導入することで,制約網による柔軟図 7: リーダー選出層 な問題の記述と,エージェンシによる効率的な協調動作を統合することができると考 えられる.本論文では,この様な形式化とその解法を提案する.すなわち,分散センサ 網における観測資源割り当て問題をリーダー選出層とリーダーによる観測資源割り当 て問題解決層の 2 つの階層に分割する.リーダー選出層では各センサが協調的に各観 測対象につき 1 個のセンサをリーダーとして選出する.観測資源割り当て問題解決層 では,選出されたリーダーによって,各観測対象に割り当られるセンサが決定される. 4.1 リーダー選出層 リーダー選出層では,各観測対象に対して 1 個のセンサをリーダーとして選出する. これはエージェンシによる協調モデルにおいて,各観測対象に対してエージェンシを 生成し,エージェント間で各観測対象につきエージェンシが 1 個になるように調整す ることに相当する. エージェントは観測対象ごとのグループに分けられる.観測対象 tjに関するグルー プとは観測対象 tjのリーダーと,観測対象 tjに割り当られたセンサからなる集合であ る.リーダーは,他の観測対象に関するリーダーと情報を交換し,同じグループに属 するセンサを決める.つまり観測対象 tjのリーダーは観測対象 tjに割り当てられるセ ンサを決定する.したがって,観測対象 tjを観測可能なセンサのいずれかが観測対象 tjのリーダーとなることが妥当である.また,後述の観測資源割り当て問題の解探索 空間を削減するために,観測対象 tjのリーダーは必ず観測対象 tjに割り当てられるこ とにする.
図 3 のような配置の場合,リーダー選出層の制約網は図 7 のように表現される.図 7において xsi tjはセンサ siが持つ観測対象 tjに関する変数である.x si tjの値は,観測対 象 tjのリーダーを示す.観測対象 tjを観測可能なセンサの集合が{s0,· · · , sn} ならば, センサ si がもつ観測対象 tj に関する変数 xstjiは{φ, s0,· · · , sn} のいずれかの値を表す 変数値をとる. リーダー選出層における制約は図 7 中 cL0, cL1, cL2, cL3で示した 4 種類ある. • cL0(xsi tj): 観測対象へのリーダーの選出に関する制約 この制約は各観測対象へ 1 個のセンサをリーダーとして選出するための制約であ る.観測対象 tjに対してリーダーが選出されていない場合にこの制約は違反とな る.この制約は緩和可能である. 制約 cL0に対する評価関数 f cL0は式 (6) のように表される.ただし wc L0 は制約の 評価値を示す定数値である. fcL0(xsi tj) = wcL0 xsi tj = φ 0 otherwise (6) • cL1(xsi tj, x si tj0): リーダーであるセンサの観測資源の制限に関する制約 この制約は各センサが同時に複数の観測対象のリーダーに選出されることを制限 するための制約である.本論文では,センサを同時に複数の観測対象に割り当て ることはできないとした.また,観測対象 tjのリーダーになったセンサは観測対 象 tjを観測するセンサとして必ず割り当てられる.つまり,センサを同時に複数 の観測対象に関するリーダーとして選出することは出来ない.そのため,1 個の センサが同時に 2 個以上の観測対象のリーダーに選出された場合にこの制約は違 反となる.この制約は緩和不可能である. 制約 cL1に対する評価関数 f cL1 は式 (7) のように表される.ただし wc L1 は制約の 評価値を示す定数値である. fcL1(xsi tj,xsit j0) = wcL1 xsi tj = x si tj0 0 otherwise (7) • cL2(xsi tj, x si0 tj ): 選出されたリーダーの整合性に関する制約 この制約は同じ観測対象を観測可能なセンサが協調するための制約である.同じ 観測対象に関するリーダーがセンサ間で異なっていた場合,正しく観測資源割り 当て問題を解くことができない.そのため,同じ観測対象についての変数の値が
センサ間で異なっていた場合にこの制約は違反となる.この制約は緩和不可能で ある. 制約 cL2に対する評価関数 f cL2は式 (8) のように表される.ただし wc L2 は制約の 評価値を示す定数値である. fcL2(xsi tj,x s i0 tj ) = wcL2 xsi tj 6= x si0 tj 0 otherwise (8) • cL3(xsi tj): 観測対象に割り当て可能なセンサの確保に関する制約 この制約は各観測対象に割り当て可能なセンサの数が十分な数だけ確保されるよ うにリーダーを選出するための制約である.観測対象 tjのリーダーは必ず観測対 象 tjを観測するセンサとして割り当てられるため,他の観測対象に割り当て可能 なセンサの集合から除外される.そのため,もともと 3 個以上のセンサを割り当 てらることが可能な観測対象に対して 3 個のセンサを割り当てられなくなる状況 に陥る可能性がある.この様な状況を避けるために,可能な限り観測可能な観測 対象の数が少ないセンサをリーダーとして選ぶことを意図して制約 cL3を設ける. 観測可能な観測対象の数が少ないセンサを選べば,割り当て可能なセンサの数が 減少する観測対象も減少する.この制約は観測可能な観測対象が一番少ないセン サ以外をリーダーに選出した場合に違反となる.この制約は緩和可能である. 制約 cL3に対する評価関数 f cL3は式 (9) のように表される.ただし wc L3 は制約の 評価値を示す定数値である.また,Ijは観測対象 tjを観測可能なセンサの集合を 示し,viはセンサ siが観測可能な観測対象の数を示す. fcL3(xsi tj) = wcL3 ∃si ∈ Ij, vi < vxsi tj 0 otherwise (9) リーダー選出層では 3.2.1 で説明した STAV を用いた制約網の表現と同様でセンサと観 測対象の組を変数として定義するため,変数の数は STAV を用いた手法と同じであり, さらに制約が増えている.しかし,各変数の取り得る値の集合の要素数はリーダー選 出層の方が少なくなる.グリッドモデルの場合,各観測対象を観測可能なセンサは 4 個である.そのため,STAV を用いた手法では,観測対象を観測可能なセンサを観測 対象に割り当てられるか割り当てらないかを選ぶので,各変数の値域は 24 = 16通と なる.一方,リーダー選出層では観測対象を観測可能なセンサのうちいずれかがリー ダーになるかリーダーを選出しないかの 5 通りである.各変数の取り得る値の集合の
図 8: 観測資源割り当て問題解決層 要素数が少ない方が,解探索空間が小さく,比較的容易に解くことが出来ると考えら れる. 4.2 観測資源割り当て問題解決層 観測資源割り当て問題解決層では,リーダー選出層で選出されたリーダーによって センサをどの観測対象に割り当てるかという問題を解決する.各リーダーは互いに情 報を交換して問題を解き,リーダー以外のセンサはリーダーの決定に従う.リーダー選 出層で各観測対象に 1 個のリーダーが選出されているため,図 3 のような配置の場合, 制約網は図 8 のように表現される.図 8 において xtjは観測対象 tjのリーダーに選出さ れたセンサが持つ観測対象 tjに関する変数である.xtj の値は,観測対象 tjを観測可 能なセンサのうち,どのセンサが観測対象 tjに割り当てられているかを示す.観測対 象 tjを観測可能なセンサの集合が{s0,· · · , sn} ならば,観測対象 tjのリーダーが持つ 変数 xsi tjは観測可能なセンサの組み合わせ{φ, {s0}, · · · , {sn}, {s0, s1}, · · · , {s0,· · · , sn}} を表す変数値をとる.しかし,観測対象 tjのリーダーは観測対象 tjに必ず割り当てら れるため,各観測対象 tj以外の観測対象を観測可能なセンサの集合から除外される. リーダーによる観測資源割り当て問題解決層における制約は,図 8 中 cA0, cA1で示し た 2 種類ある. • cA0(x tj): 観測対象への観測資源割り当ての要求に関する制約 この制約は観測対象への観測資源割り当ての要求に関する制約である.本論文で 想定するシステムでは,可能な限り各観測対象に 3 個のセンサを割り当てること を目的としている.そのため,観測対象 tjに割り当てられているセンサの数が 3 個に満たない場合にこの制約は違反となる.この制約は緩和可能である. 制約 cA0に対する評価関数 f cA0は式 (10) のように表される.ただし wc A0 は制約の 評価値を示す定数値である.また njは観測対象 tjに割り当てられたセンサの数を
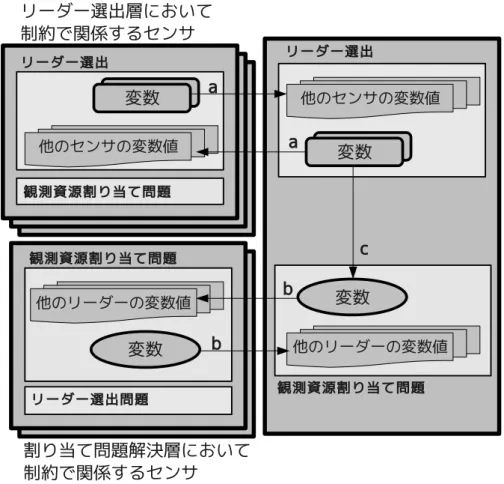
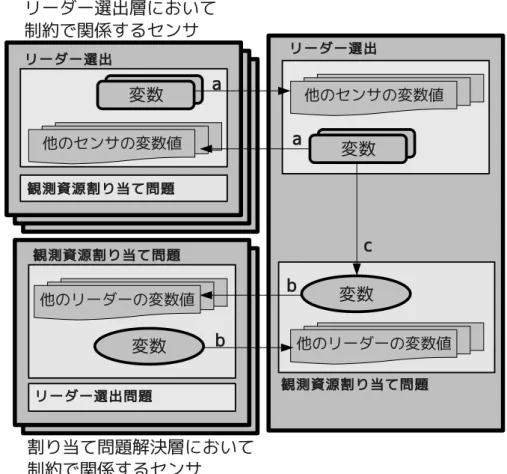
示す. fcA0(x tj) = wcA0 0 nj = 0 wcA0 1 nj = 1 wcA0 2 nj = 2 0 otherwise (10) • cA1(x tj, xtj0):観測資源の制限に関する制約 この制約は各センサが同時に複数の観測対象に割り当てられることを制限するた めの制約である.リーダーによる観測資源割り当て問題解決層では,各観測対象 につき 1 個の変数が存在し,観測対象 tjにどのセンサが割り当てられているかを 示す.そのため,複数の変数に同じセンサが割り当てられていた場合,そのセン サは複数の観測対象に割り当てられたことになる.そのため,1 個のセンサが同 時に 2 個以上の変数値の要素である場合にこの制約は違反となる.この制約は緩 和不可能である. 制約 cA1に対する評価関数 f cA1は式 (11) のように表される.ただし wc A1 は制約の 評価値を示す定数値である. fcA1(x tj,xtj0) = wcA1 xtj∩ xtj0 6= φ 0 otherwise (11) 観測資源割り当て問題解決層の問題の表現は TAV と同様であるため,変数と制約の数 が STAV で制約網を表現する場合よりも少ない.また,観測対象 tjに関するリーダー は必ず観測対象 tjに割り当てられるため,変数の取り得る値の集合も制限することに なる.つまり,解探索空間が削減される.この 2 点から,観測資源割り当て問題解決 は STAV を用いた手法よりも比較的容易に問題を解くことが出来ると考えられる. 4.3 2つの階層からなる形式化を用いた場合の解法 図 10 に 2 つの階層からなる形式化を用いた場合の解法の概念図を示す.2 つの階層 には,それぞれ独立した分散制約最適化問題の解法を適用する.それぞれの階層では 自身の変数値と制約で関係するセンサから送られてきた変数値に基いて独立に問題を 解く(図 10 中の a,b).リーダーによる観測資源割り当て問題解決層での変数は,リー ダー選出層での変数の 1 個と観測対象に割り当てることが可能なセンサの集合や観測 対象の情報が同じであるため,リーダー選出層の変数の情報に基づき作成したもので
図 9: 階層化による形式化の概念図 ある(図 10 中 c).
2つの階層からなる形式化を用いた場合の解法の擬似コードを図 11 に示す.図 11 は
センサ siを主体とした擬似コードである.図 11 中の my status は自分がリーダーに選
出されているかどうかを示す.my status = true であれば,センサ siはリーダーに選
出されている.また,leader list はリーダーであるセンサのリストである. 観測資源割り当て問題解決層では,リーダー選出層の解に基づき問題を解く必要が ある.一方で,各センサは制約で関係するリーダーの観測資源割り当て問題解決層に おける変数値に基づいて自身の割り当て問題を解決する.すなわち,観測資源割り当 て問題解決層において制約で関係するリーダーからの変数値を得ることができれば, 自身に関係する部分問題を解くことができる.したがって,自身がリーダーに選出さ れたと判断したとき,観測資源割り当て問題解決層において制約で関係する可能性の あるセンサの集合 Saに含まれるセンサにリーダーであることを通知する.自身がリー ダーに選出されたと判断するための条件は次の 2 種類である.
• 観測可能な観測対象のいずれかのリーダーに自身が選出されている.この条件は センサ siが観測可能な観測対象の集合を J とすると,式 (12) のように表すことが できる. l1 = true ∃tj ∈ J, xstji = i f alse otherwise (12) • リーダー選出層における緩和しない制約がすべて満たされている.この条件は緩 和しない制約の集合を C とすると,式 (13) のように表すことができる. l2 = true ∀c ∈ C, fc = 0 f alse otherwise (13) l1∧l2 = trueであれば,自身がリーダーであると判断する.そして,図 11 中 18-22 行目 における処理で,メッセージ is leader を生成する.メッセージ is leader は自身がリー ダーであることを通知するためのメッセージである.生成したメッセージ is leader は Saに含まれるセンサに送信される.Saに含まれるセンサは,観測可能な観測対象に 割り当てることが可能なセンサ,すなわち観測対象を観測可能なセンサの一部がリー ダーとなったセンサが担当する観測対象に割り当てることが可能なセンサと競合して いるセンサである.観測対象 tjに割り当てることが可能なセンサの集合を Stj,それ以 外の観測対象 tj0 が観測可能な観測対象に割り当てることが可能なセンサの集合を St j0 とすると,観測対象 tjのリーダーに選出されたセンサ siがリーダーであることを通知 するセンサの集合 Sa に含まれるセンサは式 (14) を満たす観測対象 tj0 を観測可能なセ ンサである. l3 = true Ssi ∩ Ssx 6= φ f alse otherwise (14) l3 = trueである観測対象 tjを観測可能であるセンサは Saに含まれるセンサである. グリッドモデルにおいて,Saに含まれる可能性のあるセンサは,グリッド上で近傍で あるセンサと,近傍であるセンサのさらに近傍であるセンサである.そのため,メッ セージ is leader はまずグリッド上で近傍であるセンサに送信される.そして,図 11 中 8-11 行目における処理で,メッセージ is leader を受信したセンサは同じメッセー ジを生成しグリッド上で近傍であるセンサに伝搬させる. リーダー選出層において全てのセンサが解を得ていない状況では,リーダーとなっ
図 10: 階層化による形式化の概念図 ていたセンサがリーダーである条件を満たせなくなる可能性もある.その場合には,図 11中 23-28 行目における処理で,メッセージ not leader を生成し,Sa に含まれるセン サに送信する.メッセージ not leader は自身がリーダーでなくなったことを通知する ためのメッセージである.メッセージ not leader を受信したセンサは,図 11 中 12-15 行目における処理で,同じメッセージを生成しグリッド上で近傍であるセンサに送信 する.
図 11 中 V は 2 つの階層における変数の集合を示す.is leader, not leader 及び変数 値は図 11 中 32 行目における処理で一括で送信する.
5
提案手法
:
動的な問題への対応
階層化された問題構造を分散制約最適化問題の枠組みに導入するということは,エー ジェントのグループを形成しグループ間での交渉を行うことを分散制約最適化問題の
1 initialize V;
2 my status← false;
3 empty leader list;
4 while
5 previous status← my status;
6 receive others’messagesAndadd others’messages to message list;
7 foreachmessage listdo
8 if receiveisleader(sx) then
9 add sx to leader list;
10 generate is leader(sx);
11 end if
12 if receivenot leader(sx) then
13 remove sx from leader list;
14 generate not leader(sx);
15 end if
16 end
17 DSTSfor leader election layer;
18 if Previous status6= leader then 19 if l1∧ l2= true then
20 my status← leader; 21 generate is leader(si);
22 end if
23 if previous status= leader then
24 if l1∧ l2= f alse then 25 my status← notleader; 26 generate not leader(si);
27 end if
28 end if
29 if my status == leader then
30 DSTS for resorce allocation layer 31 end if
32 sendmessages(is leader, not leader, V ) to others.
33 end while 図 11: 2 つの階層からなる形式化を用いた場合の解法 ダーには観測対象 tjに割り当て可能なセンサ,すなわち観測対象 tjを観測可能なセン サがどの観測対象に割り当られたかという情報が集約される.その情報を用いること により動的な問題,すなわち時刻とともに観測対象の配置が変化する問題における解 の安定性を考慮した要求に対応する制約を表現する枠組みも導入する.解を安定させ るとは,問題が変化した際に観測対象に割り当てられたセンサの組み合わせの変化を 抑制することである. 基本的に動的な問題への追従は,ある時刻のスナップショットを反復的に解くこと としてとらえることが出来る.また,想定するシステムでは,頻繁なセンサの視野方 向の制御による観測情報の劣化を抑制する観点から,観測対象に割り当てられたセン
サの組み合わせが頻繁に変化することは望ましくないと考えられる.そこで,観測対 象に割り当てられたセンサの組み合わせの変化を少くするために,センサの割り当て の状態を考慮し,その状態を交換する前処理を導入する.また,センサの割り当ての 状態を観測対象ごとに表として管理し,それを用いて観測対象に割り当てられたセン サの組み合わせの変化を抑制するための制約を設ける.また,本論文では,観測対象 の配置が変化する前の状態を問題変化前と表記し,観測対象の配置が変化した後の状 態を問題変化後と表記する. 5.1 センサの割り当ての状態 観測対象の配置が変化した後に観測対象に割り当てられたセンサの組み合わせの変 化を抑制するためには,各センサがどの観測対象に割り当てられているかという情報が 必要である.そのために,観測対象 tjに割り当て可能なセンサの割り当て問題解決層 での割り当ての状態を次のように分類する.この分類は,観測対象 tjに関するグルー プと観測対象 tjに割り当て可能なセンサの関係を表す.ここでの観測対象 tjに関する グループとは,4 で述べたとおり,観測対象 tjに関するリーダーと観測対象 tj に割り 当てられたセンサの集合である. • Inside group : 観測対象 tj に関するグループに属するセンサ • Outside group : 観測対象 tjに関するグループに属さないセンサ • New : 観測対象 tj に新しく割り当てることが可能になったセンサ • Other Leader : 観測対象 tj以外の観測対象のリーダー • Free : 上記以外のセンサ 先述のとおり,この分類は観測対象 tjに関するグループと観測対象 tjに割り当て可能 なセンサの関係を表すものである.そのため,観測対象 tj以外の観測対象にも割り当 て可能なセンサは,別の観測対象に関する割り当ての状態は異なった状態を取る可能 性がある.例えば,観測対象 tjに関する割り当ての状態が Inside group であるセンサ は,それ以外の観測対象については割り当ての状態が Outside group となる.また,こ れらの状態を保持する表を変数ごとに生成する. 5.2 変数の生成・削除,表の作成 動的な問題では,観測対象の配置が変化し,あるセンサが観測できる観測対象が変 化した場合,センサがが持つ変数に変化が生じる.自身が持つ変数に変化が生じたセ ンサは変数の生成・削除を行い制約で関係する可能性のあるセンサに対し変数の生成・
削除に関して通知するためのメッセージを送信する.また,観測対象に割り当てられ たセンサの組み合わせの変化を抑制するために,先述のセンサの割り当て状態を保持
した表を生成する必要がある.その際の擬似コードを図 12 に示す.図 12 はセンサ si
が主体の処理を示す擬似コードである.図 12 において,V はセンサ siが持つリーダー
選出層における変数の集合を示す.my status はセンサ siがリーダーであるかどうか
を示し,my status= true であればセンサ siはリーダーに選出されている.vtj はリー
ダー選出層における観測対象 tj に関する変数であり,vltj は観測対象 tjのリーダーが 持つ割り当て問題解決層における変数である.vtj.s listは観測対象 tjを観測可能なセ ンサ,すなわち観測対象 tjに割り当てることが可能なセンサの集合を示し,vtj.table は観測対象 tjに関する上述のセンサの割り当ての状態を保持する表を示す.また,こ の表は状態表と表記する. 5.2.1 変数の生成・削除 変数の生成 センサ siが新しく観測対象 tj を観測可能になった場合,図 12 中 5-9 行目における 処理で,観測対象 tjに関する変数を生成し観測対象 tjに関するメッセージ new target を生成する.観測対象 tjに関するメッセージ new target には観測対象 tj に関する変 数と観測対象 tjに対するセンサ siの割り当ての状態が含まれる.センサ siの割り当 ての状態に関する処理の詳細は後述する.観測対象 tjに関するメッセージ new target は観測対象 tjに関する変数についてリーダー選出層において制約で関係する可能性の あるセンサの集合 Slに通知する.新しく観測対象 tjに関する変数を生成したセンサ si が観測可能な領域の集合を Asi,それ以外のセンサ sxが観測可能な領域の集合を Asx とすると,式 (15) を満たすセンサ sxが Slに含まれる. Asi ∩ Asx 6= φ (15) グリッドモデルにおいて,Slに含まれるセンサはグリッド上でセンサ siの近傍である センサである.観測対象 tjに関するメッセージ new target を受信したセンサ sxは,図 12中 16-22 行目における処理で,自身が同じ観測対象 tjに関するの変数を持っていた 場合,センサ si を観測対象 tj に割り当てることが可能なセンサの集合に追加しメッ
セージ own message を生成する.own message には観測対象 tjに対するセンサ sxの
割り当ての状態が含まれる.観測対象 tj に対するセンサ sx の割り当ての状態のに関
する処理の詳細は後述する.メッセージ own status は観測対象 tjに関するメッセージ
1 my status← false;
2 initialize V;
3 while
4 detct targets;
5 if new targettj is detectedthen
6 generate new variablevtj;
7 add si tovtj.s list;
8 generate new target(si, vtj, status
tj
si);
9 end if
10 if targettj is lostthen
11 generate lost target(si, vtj);
12 remove variablevtj;
13 end if
14 receive others’messagesAndadd others’messages to message list;
15 foreachmessage listdo
16 if receivenew target(sx, vtk, status
tk
sx) then
17 if there is vtk ∧ sx6∈ vtk.s list then
18 addsx tovtk.s list;
19 addsx tovtk.table(sx, status
tk
sx);
20 generateown status(si, statustskx);
21 end if
22 end if
23 if receivelost target(sx, vtk) then
24 if there is vtk then
25 removesx fromvtk.s list;
26 removesx fromvtk.table;
27 end if
28 end if
29 if receiveown status(sx, statustskx) then
30 if there is vtk then
31 addsx tovtk.s list;
32 addsx tovtk.table(sx, status
tk
sx);
33 end if
34 end if
35 if receiveown table(sx, vltk.table) then
36 if there is vtk then 37 vtk.tabel← v l tk.table; 38 end if 39 end if 40 end
41 local caluculation for leader election layer and resorce allocation layer;
42 if my status ==true then
43 if suboptimal solution is foundthen
44 generatevtlown.table;
45 generateown table(si, vltown.table);
46 vtown.table← v
l
town.table
47 end if
48 end if
49 send messages(new target, lost target, own table)to others.
50 end while
したセンサ siは,図 12 中 29-34 行目における処理で,送信元である sxを観測対象 tj
に割り当てることが可能なセンサの集合に追加する. 変数の削除
センサ siが観測対象 tjを観測不可能になった場合は,図 12 中 10-13 行目における処
理で,観測対象 tjに関する変数を削除し観測対象 tjに関するメッセージ lost target を
生成する.観測対象 tjに関するメッセージ lost target は,vtj.s listに含まれるセンサ,
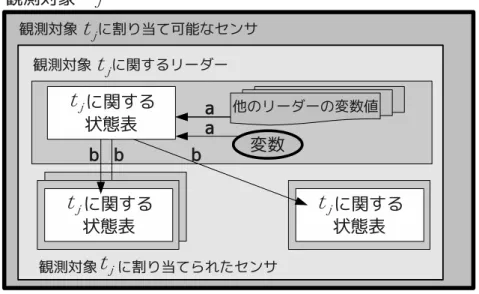
すなわち観測対象 tjを観測可能なセンサに送信される.観測対象メッセージ lost target を受信したセンサは,図 12 中 23-28 行目における処理で,観測対象 tjに関する変数を 持っていた場合,vtj.s list,すなわち観測対象 tjに割り当てることが可能なセンサの集 合から送信元であるセンサ siを除外する. 5.2.2 割り当て状態を保持する表の生成 観測対象に割り当てられたセンサの変化を抑制するための制約を表現するために, 各センサの割り当ての状態を保持する状態表を生成する.各センサは観測対象に割り 当てることが可能なセンサの割り当ての状態に関する状態表を各観測対象につき 1 つ 保持する.この状態表に関する概念図を図 13,14 に示す.この状態表は各観測対象の リーダーに選出されたセンサよって生成される場合と,各観測対象に割り当てられる ことが可能なセンサが生成する場合がある. リーダーが作成する場合 ある時刻の問題の解を得た時点では観測対象のリーダーに選出されたリーダーが状 態表を生成する.図 12 中 42-48 行目における処理で,観測対象 tj に関するリーダー であるセンサ siは観測対象 tjに関する状態表を生成しメッセージ own table を生成す る.メッセージ own table には,生成した観測対象 tjに関する状態表の情報が含まれ る.観測対象 tjのリーダーは他のリーダーと観測対象の割り当ての情報を交換し,観 測対象 tjにどのセンサを割り当てるかを決定する.そのため、観測対象 tj のリーダー は観測対象 tjに割り当てることが可能なセンサが他の観測対象に割り当てられている かどうかを知る.その情報を用いて担当する観測対象 tj に関する状態表を生成する. つまり,リーダーが生成する場合,他のリーダーから得られた変数値と自身の変数値 に基いて生成する(図 13 中 a).そして,メッセージ own table は観測対象 tjに割り当
てることが可能なセンサ,すなわち観測対象 tj を観測可能なセンサに送信される(図
13中の b).メッセージ own table を受信したセンサは,図 12 中 35-39 行目における 処理で,同じ観測対象に関する状態表を更新する.
各センサが作成する場合
問題が変化し,観測対象を観測可能なセンサの集合に変化が生じた場合は,図 14 に 示すように,他のセンサと情報を交換しつつ各センサが状態表を生成する.問題が変
化し,新しく観測対象 tjに割り当てられることが可能なったセンサ si は,図 12 中 5-9
行目における処理で,観測対象 tjに関する変数を生成し観測対象 tjに関するメッセー
ジ new target を生成する.観測対象 tjに関するメッセージ new target には観測対象 tj
対するセンサ siの割り当ての状態 status tj siが含まれる.すなわち,観測対象 tjを観測 可能なセンサに,自身の観測対象 tjに関する割り当ての状態を通知する(図 14 中 a). メッセージ new target は,先述のとおり,リーダー選出層において制約で関係する可 能性のあるセンサの集合 Slに通知する.観測対象 tj に関するメッセージ new target を受信したセンサ sxは,図 12 中 16-22 行目における処理で,観測対象 tjに関する状態
表にセンサ siを追加し,メッセージ own status を生成する.メッセージ own status
には観測対象 tjに関するセンサ sxの割り当ての状態 status tj
sxが含まれる.メッセージ
own statusはメッセージ new target の送信元であるセンサ siに送信される(図 14 中
b).センサ siが観測対象 tjを観測不可能になり,観測対象 tjに割り当てることが可
能なセンサの集合からセンサ si が除外される場合,図 12 中 10-13 行目における処理
で,観測対象 tjに関するメッセージ lost target を生成する.観測対象 tj に関するメッ
セージ lost target は vtj.slistに含まれるセンサ,すなわち観測対象 tjに割り当てること
が可能なセンサに送信される.観測対象 tjに関するメッセージ lost target を受信した センサは,図 12 中 23-28 行目における処理で,観測対象 tj に関する状態表からセン サ siの割り当ての状態に関する情報を除外する.各観測対象に割り当てることが可能 なセンサは作成する場合,状態表に関してメッセージを送信する対象は,変数の生成・ 削除の際にメッセージを送信するセンサと同じである.また,これらの処理は変数の 生成・削除と同じタイミングで行われる.そのため,変数の生成・削除に関する処理 に付随して処理を行う. 5.3 観測対象に割り当てられたセンサの組み合わせの変化の抑制 観測対象に割り当てられたセンサの組み合わせの変化を抑制するために,リーダー 選出に 2 種類の制約を設ける.また,観測資源割り当て問題解決層には 1 種類の制約 を設ける.これらの制約では,先述の状態表を用いる.
図 13: リーダーによる状態表の作成 図 14: 各センサによる状態表の生成 5.3.1 リーダーを同じグループから再選出するための制約 前述の状態表と問題変化前の変数値を用いて,リーダーを同じグループから再選出 するための制約を設ける.観測対象に対するグループの構造と観測対象に割り当てら れたセンサの組み合わせの変化を抑制するためには,問題変化後に,問題変化前と同 じセンサをリーダーとして選出する必要がある.問題が変化した際に観測対象 tjに関 するリーダーとなっていたセンサが観測対象 tjに割り当てることが可能なセンサでは なくなった場合は,同じグループ内からリーダーを選出する. • cla0: リーダーの変化を抑制するための制約 問題変化前に観測対象 tjに関するリーダーに選出されていたセンサと同じセンサ を観測対象 tjに関するリーダーとして選出するための制約である.問題変化前の リーダーと現在のリーダー選出層における変数値が異なっていた場合この制約は
違反となる.制約 cla0に対する評価関数 f cla0 は式 (16) のように表される.ただし wcla0 は制約の評価値を示す定数値である.また, pretjは観測対象 tjの配置が変 わる前のリーダーを示している.つまり問題変化前のリーダーである. fcla0(pre tj,xsitj) = wcla0 pretj 6= x si tj 0 otherwise (16) ただし,問題変化前に観測対象 tjにリーダーが選出されなかった場合と問題変化 前のリーダーが観測対象 tjに割り当てることが可能なセンサではない場合は制約 違反とはならない. • cla1: リーダーを同じグループから選出するための制約 観測対象 tjのリーダーが観測対象 tjを観測不可能になり,リーダーを変えなけれ ばならない場合,観測対象 tjに関するグループ内のセンサの中からリーダーを選 出するための制約である.観測対象 tjに関するグループ内からリーダーが選出さ れなかった場合に,この制約は違反となる.制約 cla1に対する評価関数 fcla1は式 (17)のように表される.ただし wcla1は制約の評価値を示す定数値である. fcla1(xsi tj)= wcla1 0 x si tj is N ew or F ree wcla1 1 x si tj is Inside group wcla1 2 x si tj is Outside group w3cla1 xsi tj is Other Leader (17) 1度作られたグループ構造を可能な限り維持するには,他の観測対象に割り当て られているセンサはリーダーとして適切でなく,割り当てられているセンサは 適 切であるため, 各定数値の大小関係は式 (18) で表される.
w3cla1 > w2cla1 > w0cla1 > wc1la1 = 0 (18)
5.3.2 観測対象に割り当てられたセンサの組み合わせの変化を抑制するための制約 リーダーだけでなく,リーダーが担当する観測対象に割り当てられたセンサの組み 合わせの変化を抑制するための制約を割り当て問題解決層に設ける.この制約では,状 態表を用いる. • caa0: 観測対象に割り当てられたセンサの組み合わせの変化を抑制するための制約 この制約では状態表を利用し評価値を計算する.この制約は次の 2 つの場合にこ の制約は違反となる.