Speaker Verification with Non-Audible Murmur Segments by Combining Global Alignment Kernel and Penalized Logistic Regression Machine
4
0
0
全文
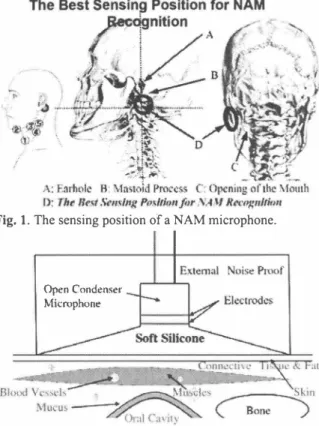
(2) all possible alignments is instead considered and a smoothed version of their maximum is taken. 1ts effectiveness was confirmed through comparison with the conventional HMM based method (HMM: hidden Markov method) in isolated word speech recognition experiments. Now let us consider the alignment π of length Iπ1= p between two sequences x and y and a pair of increasing p tuples (π"π2) such that 1=π,(1 )三・・ 三π,(P) = n,. ,, Fig. 1.. 1 = 7[2(1)三・・・三π2(P)=m, with unitary increments and no simultaneous repetitions. We write the DTW score S(π) as. The sensing position of a NAM microphone.. Open Condenser. 、‘, l,, ,,‘、. S(π) =. I��1ψ(XIrI(i)'Yπ2(i) ). where ψis an arbitrary conditionally positive-definite kernel. The GA kernel is then defined as. Microphone. K(x,y)=. Ié例= Ie早川山州). rT llrl = て""I 之乙�l [�=J 戸 x促εA(玄 川. Fig. 2.. body.. The cross section of a NAM microphone and human. where A(作x, y) is the set of all possible alignments between and y and k=e'!'.. +1巾日斗Tロ叫山山リ一一一ー三点 Sp<mr C". 5p<北町C', I 田Il-k,町明田d 聞cronc明甜d 白E 岨�soro曲目符四k.... 10lc<�市町d 凶eranc明. Fig. 4.. ド 雫". (2). !'. x. T四1血11g Pl'ocedミ注目. CbSil晶catiou f_ • ・ ー 1 LJ拘置噛躍晶d間-1 ..�..叩 �ake;é-:: PLRMj I伽蜘印刷j Training and testing procedures.. 2ふPenalized logistic regression machine. 1n PLRM [6,7], the posterior probability of a class y given an observation X is modeled as. P(y I x) = Fig. 3.. エy'εyexp(f(x,y')). (3). where. Comparison of Spectrogram and waveform of normal speech (top) and NAM (bo抗om).. f(x,y) = L nαn(y)k(xn,x).. 2.2. Global alignment kernel. (4). Here, {Xn} is a set of training observations, k(γ) is a kernel,. The GA kernel [5] elaborates on the DTW family of distances by considering the same set of elementary operations, namely substitutions and repetitions of tokens, to map one sequence onto another. Associating a certain score with each of these operations, DTW algorithms use dynamic programming techniques to compute an optimal sequence of operations with a high overall score. For the GA kernel, the score spanned by. -. exp(f(x,y)). and αn(y) are the kernel product weights, which are the 仕切 parameters of the model and subject to optimization. 1t should be evident from these formulations that P(y防) is a real number between zero and one.. 1370 192. -.
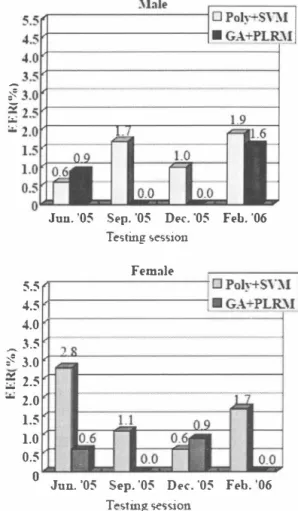
(3) L(A) =-LnlogP(Yn IXn). (5). A = argminL(A).. (6). { X L XU尚 一品. Assume that we have a collection of N feature vectors Xn and coπesponding labels Yn- Let A be a IYJ x N matrix containing all of the kemel product weights {αn(y)}' The weights are optimized according to the negative log likelihood of the training labels:. A. Although we do not present the details here, the gradient and Hessian of the total loss L(A) with respect to A have some very nice properties that enable us to use conjugate gradient descent methods relatively efficiently. To avoid overtraining and subsequent poor generalization, one usually adds a re思llarization term to the total loss.. Jun. '05. Dl'c.・05. Fl'b. '06. Fl'mall'. 2.4. Speaker verification procedure. 5.5. The proced町e of our method is shown in Fig. 4. In training, a PLRM is trained for each speaker. Although PLRM is a multi-class classifier, we use it here as a binary classifier. The training data for each speaker is divided into two sets for positive (+1 ) and negative (・1 ) classes. The + 1 class data consists of keyword utterances of a customer speaker and the ・1 class data consists of non-keyword utterances of the speaker and utterances of other speakers. Concatenations of n short-term feature vectors extracted仕om the training data are made for each u町rance and used as an input vector sequence to caIculate the Gram matrix with the GA kemel. The concatenation was originally assumed to represent keyword specific acoustic features well. By utilizing the GA kemel,we 白rther capωre the keyword-specific acoustic features. The PLRM parameters are estimated using the Gram matrix. In testing, as in training, concatenations of n short-term feature vectors are made for the input utterance, and the values of the GA kemel function between the input utterance and all training utterances are caIculated. The values are given to the PLRM of the claimed speaker, and the probabilistic estimate of the speaker is obtained. This estimate is compared with a threshold to judge the speaker's identity.. 3.. Sl'p.・05. Testing sessioll. 4.5 4.0. ,・、 3.5. �. 3.0. ?í 2.5 占2.0 1.5 1.0 0.5. 。. Jun.・05. Sl'p. '05. Dec. '05. Fl'b. '06. Testìng 'ieSslOn Fig. 5. Comparison of the perfoロnance for each session between the GA kemel+PLRM method and the polynomial.. of MFCCs (.ð.MFCCs) computed in匂rms of five successive MFCC vectors. Cepstrum mean normalization was applied. The training dataset of each customer speaker was composed of the data uttered by customer speakers of the same gender in three sessions. The data for each session consisted of 10 keyword u悦erances for the + 1 class and 1 5 non-keyword utterances of the speaker (randomly selected 仕om 30 keywords) and utterances of the other customer speakers for the - 1 class (in detail, 1 70 utterances of the other male customer speakers when the speaker was male and 90 ' utterances of the other female customer speakers wheíí the speaker was female). In testing, we used keyword utterances uttered by each customer speaker in a session that was different合om the training sessions and imposter utterances. The test dataset basically consisted of 6 keyword utterances of the customer speaker and imposter utterances (in detai1, 1 08 u抗erances of male imposter speakers when the customer speaker was ma1e and 54 utterances of female imposter speakers when the customer speaker was female). We call this test dataset the “basic case" The threshold for speaker decision was speaker-dependent and set a posteriori to equalize the false acceptance and false rejection rates. For the GA kemel function,ψwas defined as the Gaussian kemel with parameterσ= 1. For the polynomial kemel function, the power was chosen to be 7. For SVM, we use SVMlight , which is a toolkit provided by Comell University [9].. Experiments. We compared the performances of our GA kemel+PLRM・ based method and the polynomial kemel+SVM method in speaker verification experiments. 3.1. Data description and experimental conditions. We used keyword phrases uttered by 1 8 male and 10 female speakers in four sessions over a 9 -month period (Jun. 2005, Sep. 2005, Dec. 2005 and Feb. 2006) as customer data, while we used keyword phrases uttered by a different set of 1 8 male and 9 female speakers in a different session as imposter data. The interval between sessions was more than three months. Each keyword phrase was a concatenation of two place names (Japanese prefec旬res, e.g.,“Tokyo-Saitama" and “Kyoto Nara"). In each session, each customer/imposter uttered hislher own keyword 1 6 times and uttered 29 keywords of other customers/imposters twice. An MFCC (Mel frequency cepstral coefficient) vector of 3 1 components, consisting of 1 5・dimensional MFCCs plus .ð.MFCCs and .ð.power, was derived for 10 ms over a 25・ms Hamrning-windowed speech segrnent. NAM segrnents were created by concatenating several feature vectors consisting of only MFCCs because the segments can include information about the first derivatives. qtu n可U ‘,i. 137 1.
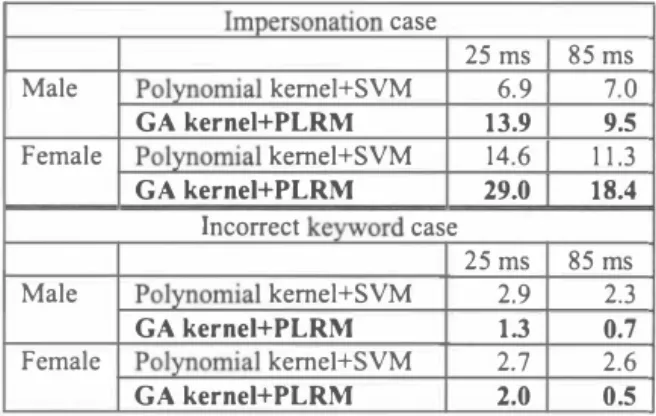
(4) Table 2. Comparison of equal e汀or rates between the GA kemel+PLRM method and the polynomial kemel+SVM method when using 25 and 85・ms-Iong NAM segments.. Comparison of equal e汀or rates between the GA kemel+PLRM method and the polynomial kemel+ SVM method when using 25- and 85-ms-Iong NAM segments (basic case). Table 1.. Impersonation case. Table 1 lists the equal e汀or rates (EERs) in the basic case for NAM segments with lengths of 25 ms (31 ・dimensional vector; MFCC+ðMFCC+ðpower) and 85 ms (85・dimensional vector; 7 MFCC vector concatenations). In [3], we compared the performances with 45-ms, 85・ms and 145-ms-Iong segments and found that 85・ms-Iong segments were practica1. Therefore we selected to use 85・mシlong segments here. For both mal巴 and female speakers, our GA kemel+PLRM method outperformed the polynomial kemel+SVM method: the averaged eηor reduction rate was 59%. Moreover, the size of the Gram matrix for the GA kemel was roughly the reciprocal of 250x250 (roughly 250 vectors in each utterance) times the size of the Gram matrix for the polynomial kemel and the PLRM training was fast. These results indicate that our GA kemel+PLRM method is effective and can capture keyword-specific acoustic features very wel1. Figure 5 compares the EERs for each session for testing between our GA kemel+PLRM method and the polynomial kemel+SVM method. F or half of the sessions,the EERs were 0.0, so our method is efficient.. 4.. GA kernel+PLR九f. 13.9. 9.5. Female. Polynomial kemel+SVM. 14.6. 1 1 .3. GA kernel+PLRM. 29.0. 18.4. 25 ms 2.9. 85 ms 2.3 0.7. Male. Pol戸lOmial kemel+SVM GA kernel+PLRM. 1.3. Female. Polynomial keme1+SVM. 2.7. 2.6. GA kernel+PLRM. 2.0. 0.5. NAM segments. In future, we plan to investigate a priori threshold settings for verification.. 6.. References. [ 1 ] D. A. Reynolds,“An Overview of Automatic Speaker Recognition Technology," in Proc. ICASSP, pp. 4072・ 4075,2002. [2] M. Kojima, T. Matsui, H. Kawanami, H. Saruwatari and K. Shikano, “Speaker Verification with Non-Audible Murmur Segments," in Proc. Interspeech, pp. 2 1 14・2 1 1 7, 2006. [3] H. Okamoto, M. Kojima, T. Matsui, H. Kawanami, H. Saruwatari, and K. Shikano, “Study on Speaker Verification with Non-Audible Murmur Segments," in Proc. Interspeech, pp. 20 1 7・2020,2007. [4] Y. Nak勾ima,H. Kashioka,N. Campbel1,and K. Shikano, “Non-Audible Murmur (NAM) Recognition," IEICE Trans. Information and今'stems, vo1. E89-D, no. 1 , pp. 1・ 8,2006. [5] M. Cu旬ri, J. P. Ve口, O. Birkenes, and T. Matsui,“A Kemel for Time Series Based on Global Alignrnents," in Proc. ICASSP, pp. 4 1 3・4 1 6,2007. [6] K. Tanabe,“Penalized Logistic Regression Machines: New methods for statistical prediction 1 ," ISM Cooperative Research Report 143,pp. 163・194,200 1 . [7] K. Tanabe,“Penalized Logistic Regression Machines: New methods for statistical prediction 2," in Proc. IBIS, Tokyo,pp. 7ト76,200 1. [8] T. Matsui and K. Tanabe,“Comparative Study of Speaker Identification Methods: dPLRM, SVM and GMM," IEICE Trans. Information and Systems, vo1. E89・D,no. 3, pp. 1066・1073,2006 [9] T. Joachims, SVMlight,http://svmlight.joachims.org/. Discussion. In practical conditions, we sometimes need to assume that keyword u町rances uttered by other speakers (impersonation case) or non-keyword utterances uttered by the customer speaker (incorrect keyword case) are false utterances. For testing, in the impersonation case, we assigned the customer keyword utterances u伐ered by the other speakers to the - 1 c1ass,and in the inco汀ect keyword case, we assigned the non keyword utterances uttered by the customer speaker to the - 1 c1ass. Table 2 lists the EERs for the impersonation and incoπect keyword cases, respectively. While the EERs of our GA kemel+PLRM method were lower than those of the polynomial kemel+SVM method for the incorrect keyword case,the results were opposite for the impersonation case. For both cases, the EERs for 85-ms-Iong NAM segments were lower than those for 25-ms・long ones. It can be considered that since the GA kemel captures keyword-specific acoustic features very wel1, it has trouble dealing with the impersonation case. However, in a real situation, the keyword of the customer cannot be stolen because NAM is not captured by others. Moreover, speaker-specific features are wel1 represented in NAM segments. 5.. 85 ms 7.0. Polynomial kemel+SVM. Incorrect keyword case 3.2. Results. 25 ms 6.9. Male. Conclusions. We investigated speaker verification using NAM segments based on a combination of the GA kemel and PLRM. Our method was found to be effective especial1y for the basic and incorrect keyword cases and reduced the eπor rates by more than half. Keyword-specific acoustic features are wel1 represented on the Gram matrix of the GA kemel and the. 1372 -194-.
(5)
図
関連したドキュメント
In particular, Proposition 2.1 tells you the size of a maximal collection of disjoint separating curves on S , as there is always a subgroup of rank rkK = rkI generated by Dehn
It is suggested by our method that most of the quadratic algebras for all St¨ ackel equivalence classes of 3D second order quantum superintegrable systems on conformally flat
In Section 3, we show that the clique- width is unbounded in any superfactorial class of graphs, and in Section 4, we prove that the clique-width is bounded in any hereditary
BOUNDARY INVARIANTS AND THE BERGMAN KERNEL 153 defining function r = r F , which was constructed in [F2] as a smooth approx- imate solution to the (complex) Monge-Amp` ere
Inside this class, we identify a new subclass of Liouvillian integrable systems, under suitable conditions such Liouvillian integrable systems can have at most one limit cycle, and
Abstract. Recently, the Riemann problem in the interior domain of a smooth Jordan curve was solved by transforming its boundary condition to a Fredholm integral equation of the
Next, we prove bounds for the dimensions of p-adic MLV-spaces in Section 3, assuming results in Section 4, and make a conjecture about a special element in the motivic Galois group
Transirico, “Second order elliptic equations in weighted Sobolev spaces on unbounded domains,” Rendiconti della Accademia Nazionale delle Scienze detta dei XL.. Memorie di
