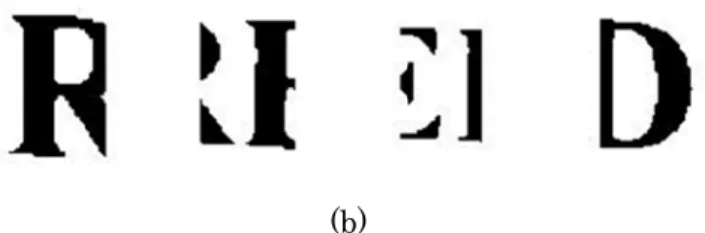2010 年度修士論文
K-means クラスタリングとサポートベクター
マシンを用いた情景内カラー文字列の 2 値化
2011 年 1 月 28 日提出
指導教官 若原 徹 教授
法政大学 情報科学研究科 情報科学専攻
学籍番号 09T0005 喜多
キ タ
耕
コウ
平
ヘイ
Abstract
This paper proposes a new technique for binalizing color character strings in scene images. The key ideas are as follows. (1) Generation of candidate binarized string images via every dichotomization of K clusters obtained by K-means clustering in the HIS color space. The total number of candidate binarized string images equals 2K 2 . (2) Every candidate binarized string image is divided into a set of tentative single-character images depending on aspect ratio. We calculate mesh and weighted direction code histogram feature from every tentative single-character images and feed the support vector machines (SVM) with the results of calculation to output the degree of “character-likeness.” (3) The binarized string image with the maximum average of
“character-likeness” is output as an optimal binarization result. In experiments, we used a total of 1,000 single-character color images extracted from “TrialTrain” subset of ICDAR 2003 robust OCR dataset for training SVM. Experiments made on a total of 1000 character strings extracted from
“TrialTrain” subset of ICDAR2003 robust word recognition dataset show that the generation rate of candidate binarized string images which contain a correctly binarized image equal 87.8% and the selection rate of correct binarized string image equal 91.6%. The total of proposes method achieves a correct binarization rate of 80.8%.
内容概要
本論文では,情景内カラー文字列の新たな 2 値化手法を提案する.キーとなるアイディ アは,次の通りである.(1) HSIカラー空間でK-meansクラスタリングによって得られる Kクラスタの羅的な 2分割により複数の2値化候補文字列画像を生成する.生成される 2 値化候補文字列画像の総数は2K 2枚である.(2) 全ての2値化候補文字列画像を横縦比か ら 1 文字単位への仮分割を行う.各仮分割画像からメッシュ特徴と加重方向指数ヒストグ ラム特徴を抽出し,サポートベクターマシン(SVM)に入力して「文字らしさ」の評価値を出 力する.(3) 2値化候補文字列画像の中で「文字らしさ」の最大平均評価値を持つものを最 適な2値化結果として出力する.SVMの学習には,ICDAR2003 robust OCR datasetから 抽出した 1000 枚のカラー単一文字画像を用いた.ICDAR2003 robust word recognition
datasetから抽出したカラー文字列画像1000枚を用いて2値化実験を行った結果,正解を
含む2値化候補画像の生成率は87.8%,正しい2値化画像の選択率は91.6%であり,全体
での正2値化率は80.4%を達成したことになる.
目次
第 1 章 序論 ... 4
1.1研究の背景 ... 4
1.2研究の目的 ... 4
1.3研究の構成 ... 5
第 2 章 使用した画像データ ... 6
第 3 章 k-meansクラスタリングを用いた2値化候補文字列画像の生成 ... 8
3.1 HSIカラー空間への投影 ... 8
3.2 HSIカラー空間におけるK-meansクラスタリング ... 9
3.3 Kクラスタの2分割による2値化候補文字列画像の生成 ... 9
第 4 章 サポートベクターマシンを用いた「文字らしさ」の判定と 2 値化画像の決定 ... 11
4.1 カラー文字列の 1 文字単位への仮分割 ... 11
4.2 カラー文字列の 2 値化候補画像からの特徴量の抽出 ... 12
4.3 サポートベクターマシンによる文字・非文字分類 ... 13
4.4 「文字らしさ」の判定と 2 値化画像の決定 ... 15
第 5 章 実験結果 ... エラー! ブックマークが定義されていません。 5.1 提案手法の処理時間 ... 116
5.2 提案手法による累積正 2 値化率 ... 17
第 6 章 考察 ... 18
6.1 提案手法の予備実験 ... 19
6.3 今後の課題 ... 22
第 7 章 むすび ... 23
謝辞 ... 24
参考文献 ... 25
第 1 章 序論
1.1 研究の背景
文字認識には半世紀近い活発な研究の歴史があり、パターン認識の中で最も実用化が進ん だ技術の一つであり,多くの論文が発表されている[1][2].特に、近年ではインターネット 上のWebドキュメントや情景内カラー文字に関する研究が文字認識の分野で注目されてお り[3],2003 年には英国エディンバラで開催された第 7 回文字認識・文書理解国際会議 ICDAR2003 に お い て カ ラ ー 情 景 画 像 か ら の 、(1) Text locating、(2) Robust word recognition、(3) Robust character recognition、についてそれぞれ別個のデータベースを 用意したコンペティションも実施されている.
文字認識を正しく行うためには画像中から文字領域を抽出する必要があり,そのための手 法として 2 値化処理がしばしば用いられている.特に,情景内カラー文字は多様な複雑背 景や複数の色相を有しているため,文字領域と背景を分離する 2 値化処理の精度が文字認 識性能を大きく左右する.
従来の情景内カラー文字の2値化においては,文字領域の明度や色相がほぼ一定している こと,背景と文字領域は明度や色相が大きく異なっていることが前提となっている.主な2 値化手法としては,明度に着目する局所 2 値化[4],[5],色相の一定性に注目する色クラスタ リング[6][7]がある.単一カラー文字を対象とした 2 値化の研究では,Yokobayashi 等[8]
のカラー空間での大津基準[9]による 2値化が挙げられる.しかし,これらの従来手法では 複数の異なる色相から成る文字領域に対応できない.
1.2 研究の目的
本研究の目的は,複数の異なる色相から成るカラー文字列の最適な2値化の実現である.
そこで,次の流れに沿って処理を行うことで研究目的の実現を目指す.
初めに,カラー文字列の全画素をカラー空間に投影し,K-means クラスタリングで得ら れるKクラスタの2分割により2値化候補文字列画像を生成する.次に,生成された2値 化候補文字列画像を横縦比から1文字単位に仮分割し,仮分割画像毎に特徴量を抽出する.
抽出された特徴量はSVMに入力されることで仮分割画像毎に「文字らしさ」の評価値を出 力することができる.最後に,仮分割画像毎の「文字らしさ」の評価値を 2 値化候補文字 列画像毎に平均し,2値化候補文字列画像の中で「文字らしさ」の最大平均評価値を持つも のを最適な2値化結果として出力する.
1.3 研究の構成
本章では,序論として本研究の背景や,どのような目的で行われたかを述べた.第2章で 使用した画像データを紹介する.第3章でK-meansクラスタリングを用いた2値化候補文 字列画像の生成,第4章でサポートベクターマシンを用いた「文字らしさ」の判定と2 値 化画像の決定,について説明する.第5章は実験結果であり,第6章で考察を述べる.
第
20 で,カ
・
・
・ の3部 が,応 れてダ
図1 R
本研 Robu 験を行 り,” 854枚 word り,” 171枚 実験に
第 2 章
03年英国エ
カラー情景画 Text locati Robust wo Robust ch 部門について 応募があった ダウンロー
各部門で公 Robust char
研究では,R ust word re
行っている
”Sample”,” 枚,TrrailTr d recognitio
”Sample”,” 枚,TrrailTr に使用した各
使用
エディンバラ 画像を対象に
ing
ord recognit aracter reco て別個のデー たのはText ド可能である
(a)
公開されてい racter recog
Robust cha cognition 部
.robust O TrailTrain”
rain:6185枚 on dataset TrailTrain”
rain:1156 各々の画像例
用した
で開催され に Robust re
tion ognition ータベースが
locating部 る[11].図1
いる画像例.
gnition.
racter reco 部門で用いら OCR datase
,”TrialTest 枚,TrialTe t は 文 字
,”TrialTest 枚,TrialTe 例を示す.
た画像
た第7回文 eading com
が用意された 門のみであ
はそれぞれ
(a) Text loc
ognition 部門
られたrobus
t は 1 文字
t”に分かれて st:5430枚
列 単 位 の t”に分かれて est:1110枚
像デー
字認識・文書 mpetitions が
た.実施結果 った.使用さ れの部門の画
(b)
ating.(b) R
門で用いられ st word reco 字のみを含む ている.それ 枚,合計1246 の 情 景 内 カ
ている.それ 枚,合計243
タ
書理解国際会 が企画され,
が同会議中に されたデータ
像例である.
Robust word
れた robust ognition da む情景内カラ れぞれの画像
69枚から成
カ ラ ー 文 字 れぞれの画像
7枚から成っ
会議ICDAR
に報告された タベースは公
.
(c)
d recognitio
OCR datas atasetを用い ラー文字画像 像枚数はSam る.一方,r 字 列 画 像 像枚数はSam
っている.図 R2003
た[10]
公開さ
n.(c)
set と いて実 像であ mple:
obust で あ mple:
図2に
公開 PPM
図2
開されてい M形式に変換
2 使用した
る画像は JP 換をした.
画像例.(a)
PEG 形式で
(a)
(b) ) 単一カラー であるため,
ー文字.(b) プログラム
カラー文字
ムで処理しや 字列.
やすいようにに予め
第 3 章 K-means クラスタリングを用い た 2 値化候補文字列画像の生成
本章では,カラー文字列の全画素をHSIカラー空間に投影し,K-meansクラスタリング によりK個のクラスタに分け,それらKクラスタを2分割する組合せにより網羅的な2値 化候補文字列画像を生成する手法を提案する.
3.1 HSI カラー空間への投影
RGBカラー空間からHSIカラー空間に変換を行う.ただし,R, G, B ∈ [0,255]と同様 に,H, S, I ∈[0,255]の値域となるようにスケール変換を施した.HSIカラー空間とは,
色相(Hue),彩度(Saturation),輝度(Intensity)の3つの成分からなる色空間である[12].
R G B
Imax , , ,mmin
R,G,B
, if I0 or Im then S0,H不定else 255
I m
S I ,
m I
R r I
,
m I
G I
g ,
m I
B b I
,
if RI then h
bg
3
,
if GI then h
2rb
3
,
if BI then h
4gr
3
,
if h0 then hh2,
255
h
H . (1)
画像サイズM×Nのカラー文字画像の全画素を(1)式に従ってHSIカラー空間に投影する と,総数M×N個の点がHSIカラー空間内に散布することになる.
予備実験において,RGBカラー空間からHSIカラー空間に変換することで,文字領域と 背景とが分類し易くなっていることが確認できている.
3.2 HSI カラー空間における K-means クラスタリング
HSIカラー空間内のM×N個の点に対してK-meansクラスタリングを行い,K個のクラ スタに分割する.当然,2値化候補文字列画像の中に正しい2値化画像を含むのに十分であ るようパラメータKを決定する.
K-meansクラスタリング[13]の手法を以下に示す.
Step 1: M×N個の点からランダムにK個の点を選択し,クラスタ中心の初期値{k(0)}
K
k1とする.次いで,全てのデータ点をそれぞれ最短距離のクラスタ中心に割り 振ってグループ分けをする.各グループが1つのクラスタとなる.
Step 2: 各グループに含まれるデータ点の平均を求め,当該クラスタのクラタ中心の更
新値とする.1となり,更新されたクラスタ中心を改めて{k()}Kk1と記す.
Step 3: 全てのデータ点をそれぞれ最短距離のクラスタ中心に割り振ってグループ分け
をする.グループ分けに変動がなかった場合は,それらK個のクラスタを出力 して終了する.変動があった場合は,Step 2に戻る.
K-meansクラスタリングにより得られたHSIカラー空間内の各クラスについて,当該ク
ラスタに属する画素群を元のカラー文字画像に逆投影すると,各々1枚の分離画像が生成さ れる.これらK枚の分離画像の和集合が元の画像となる.
K-meansクラスタリングの結果は,K個のクラスタ中心の初期値の選び方に依存するた
め,本研究ではK-meansクラスタリングにマルチスタート探索を適用した.
マルチスタート探索とは,最適化問題の解が一般に初期値に強く依存してしまうため,
初期値を複数設定してそれぞれの解を求めておき,それらから最適解を選択する手法であ る.
今回のK-means法へのマルチスタート探索の適用では,複数解の中からクラスタ内分散の
和が最小となるクラスタリング結果を採用した.
3.3 K クラスタの 2 分割による 2 値化候補文字列画像の生成
K枚の分離画像群を網羅的に2つのグループに2分割して,一方を文字部分(黒),他方を 背景部分(白)として,複数の2値化候補文字列画像を生成する.
上記2分割の全ての組み合わせにより生成される2値化候補文字列画像の総数Nbinaryは 次式の通りである.
2 2
1
0
K K
i i K
binary C
N (2)
図3に,1枚のカラー文字列に対する2値化候補画像の生成例を示す.ただし,クラスタ 数はK = 5とした.
図3 2値化候補 画像.
補文字列画像像の生成例.
(a)
(b)
(a) 元のカララー画像.(bb) 30枚の22値化候補文文字列
第
本章 ートベ
サポ 力し,
4.
ICD 平均値
カラ
式(
数S1 この にはほ
図
第 4 章
章では生成さ ベクターマシ ポートベクタ
,その出力値
1 カラー
DAR2003 ro 値alphaをあ ラー文字列の
(3)の計算を行 1,小数点以
の分割数S1 ほぼ1文字ず
4に,2値化
章 サ い 2
されたカラー シンを用いて ターマシンに 値を「文字ら
ー文字列
obust OCR あらかじめ求 の画像サイズ
/ X S
行うと値 S 以下を切り上
1,S2を用い ずつが含まれ 化候補文字列
サポー いた「
値化画
ー文字列の2 て,文字か非 には,仮分割
らしさ」の評
列の 1 文字
datasetから 求めておく.
ズがY×Xで
) /(Yalpha
S は一般に整 上げたS2とい
いてカラー文 れていると考 列画像の仮分
トベク 文字 画像の
2値化候補文 非文字かの判 した2値化候 評価値とする
字単位へ
ら抽出したカ
であるとき,
整数ではない いう2つの分 文字列をS1個
考えてよい.
分割の例を示
(a)
クター らしさ の決定
文字列画像を 判定を行う手 候補文字列画 る.
への仮分
カラーの単一
次式で文字
ため,Sの小 分割数を用い
個,S2個に各 示す.
ーマシ さ」の 定
を1文字単位 手法を提案す 画像から抽出
分割
一文字画像10
列内の文字数
(3)
小数点以下を いることとす
各々仮分割す
シンを の判定
位に仮分割し する.
出した特徴量
000枚の横縦
数を推定する
を切り下げた する.
すると,分割
用 定と
,サポ
量を入
縦比の
る.
た分割
割画像
図4
4.
2値 ると考 きさの に記す
(1)
(2)
(3)
ただ 正規 こでは いるメ メッシ サイ とに黒 ュ特徴
図
2値化候補
よる仮分割.
2 カラー
値化候補文字 考えられる.
の正規化処理 す.
画像内全て る.
予め定めた 決定する.
黒画素の重 のサイズと し,画像の伸 規化された仮 は,2値画像 メッシュ特徴 シュ特徴
イズ 120×8
黒画素数を計 徴とする.
5に,メッシ
補文字列画像
ー文字列
字列画像を1
.そこで,文 理を施す.正
ての黒がその
た平均距離の
重心 g を(40 とする.
伸縮には共一 仮分割画像か 像についての
徴と加重方向
80 の画像を
計算して黒画
シュ特徴の概
像の仮分割の
列の 2 値化
文字単位に 文字認識の前 正規化後の画
の重心g,お
の正規化値r
0,60)に移動し
一次内挿法[1 から,文字か の汎用的画像 向指数ヒスト
96 個の正方
画素比率を算
概念図を示す
(b) の例.(a) 分割
化候補画
に仮分割した仮 前処理として 画像サイズは
および重心g
r0(=25.0)に従
し,伸縮率 s
14]を用いた か非文字かを 像特徴ではな トグラム特徴
方ブロック(
算出する.そ
す.
割数S1によ
画像から
仮分割画像は てよく用いら
は 120×80 と
から各黒画
従い,重心g周
s で大きさを
た.
判定するた く,文字認識 徴[15]を取り
サイズ10×
それらを並べ
よる仮分割.
らの特徴量
はほぼ1文字 られる,文字 とした.具体
画素への平均距
周りの画像の
を正規化して
めの特徴量の 識技術で従来
上げる.
×10)に分割す べた96次元ベ
(b) 分割数
量の抽出
字を含む画像 字部分の位置 体的な手順を
距離r,を算
の伸縮率
て,縦 120,
の抽出を行 来よく用いら
する.ブロッ ベクトルをメ
S2に
出
像であ 置と大 を以下
算出す
⁄ を
横 80
う.こ られて
ックご メッシ
加重方 サイ とに局 タをか
図
4.
サポ 超平面
いま する.
を入力 数でマ
方向指数ヒス
イズ 120×8
局所方向ヒス かけ,96次元 6に,加重方
3 サポー
ポートベクタ 面による2ク ま,分類すべ
.ここで,文 力空間Xか マージンを最
ストグラム特
80 の画像を
ストグラムを 元ベクトルへ 方向指数ヒス
ートベク
ターマシン(S クラス分類器 べきデータ群 文字・非文字分 から特徴空間
最大化するも
図
特徴
96 個の正方
を算出する.
へと次元圧縮 ストグラム特
図6 加重方
ターマシ
SVM)はVap 器である[16]
群 とそ 分類であれば
Fへの写像 ものとして,
5 メッシュ
方ブロック(
局所方向ヒ 縮したものを 特徴の概念図
方向指数ヒス
シンによ
pnikらによ
].
その分類ラベ ば,文字で 1 像とする.SV 次式で定義
ュ特徴.
サイズ10×
ヒストグラム を加重方向指 図を示す.
ストグラム特
よる文字
って提案され
ベル ∈ 1,非文字で
VMは,特徴
義される.
×10)に分割す に対し,2次 指数ヒストグ
特徴.
・非文字
れたマージン
1, 1 が与 1となる.さ 徴空間Fにお
する.ブロッ 次元ガウスフ グラム特徴と
字分類
ン最大化に基
与えられたも さらに,:X おける線形識
ックご フィル する.
基づく
ものと F X 識別関
ここ 与え
と呼ば 本研
本研 非文字 ある SVM
文字 方法だ
① I べ
② 1 SVM
上記 の画像
図
こで,
x るカーネルは凸二次計 ばれる.
研究では,S
研究では,文 字の 2 クラ
ICDAR200 M学習用の文
字データは次 だけでは文字 ICDAR2003 べた手法を適 り,正しい
136種類の大
M学習用の非 記の方法①に 像全てを学習
7に,SVM
x f
N
i i 1
y
はデー
関数 K(x,y) 計画問題を解
SVMの実装
) , (x y K 文字列の2値 ラス分類を行
3 robust OC 文字データ
次の2種類の 字画像が非文 robust OCR 適用し, 2
2値化画像(
大小英文字の 非文字データ
において,2 習用の非文字
M学習用デー
(a)
N
i
i i
iy x
1
i
i
iyK x,x b
ータ x,yを
y)で置き換え
解いて得られ
にSVMlight
||
exp( x
値化候補画像 行うため,学
CR dataset
の方法で用意 文字画像に比
datasetから抽 2 枚の2 1枚とは限ら の活字フォン
値化候補画 字データとす
ータの例を示
xb 写像した特徴 えることがで
れる.非零の
t[17]を利用し )
||2
y 像を1文字単 学習用データ
を用いる.
意した. 2種 比べて少な過
抽出した100 値化候補画 らない)を選別 ントを収集し
画像 2 2 枚 する.
示す.
(c)
徴空間での内 できる.最大
係数 に対応
し,以下に示 単位に仮分割
にはカラー単
種類の方法を 過ぎるからで
00枚の単一
画像を生成す 別して学習用 し,136×52枚
枚から正しい
(b)
(4)
内積であり,
大マージンを 応する がサ
示すRBFカ (5) して特徴量を 単一文字画像
を用いている である.
カラー文字画 る. 2 2 用の文字デー 枚の文字画像
い2値化画像
この内積を を与える非負 サポートベク
ーネルを用
を抽出して文 像データベー
るのは,下記
画像に第3章 2 枚から目視 ータとする.
像を追加する
像を選別した を陰に 負係数 クター
いた.
文字・
ースで
記①の
章で述 視によ
る.
た残り
フォント).(c) 非文字画像(正しくない2値化候補画像).
また,本研究における SVMの文字・非文字分類精度は表1の通りであった.
表1 SVMの文字・非文字分類精度.
メッシュ特徴 加重方向指数ヒストグラム特徴 正分類率 97.88% 89.97%
適合率 95.99% 76.52%
再現率 95.76% 87.98%
4.4 「文字らしさ」の判定と 2 値化画像の決定
本研究の目的は,1枚のカラー文字列画像から生成される 2 2 枚の2値化候補文字列 画像の中から,最適な 2 値化画像を決定することである.そこで,本研究では,以下の方 法で最適な2値化画像を決定する.
文字・非文字分類を学習したSVMに,仮分割画像の特徴量xを入力する.式(4)の値f(x) が仮分割画像ごとに出力されるため,各2値化候補文字列画像についてf(x)の平均値を求め る.
4.1.で述べたように1枚の2値化候補文字列画像は分割数S1,S2で2通りに仮分割され
ているため,分割数S1における値f(x)の平均値と分割数S2における値f(x)の平均値とを比 較し,大きい方の値をその 2 値化候補文字列画像における「文字らしさ」の評価値と考え ることにする.これにより,総数 2 2 枚の2値化候補文字列画像の中で「文字らしさ」
の最大評価値,すなわち,f(x)の最大平均値をもつものを最適な2値化結果として出力する.
第 5 章 実験結果
1000枚のカラー文字列画像に提案手法を適用した実験結果を述べる.K-meansクラスタ リングで指定するクラスタ数はK = 5とした.式(2)より,生成される2値化候補文字列画 像の総数は30枚となる.
予備実験では,K = 4, 6を用いた2値化候補文字列画像の生成も行った.その結果,K = 4では正しい2値化画像が生成されない場合が明らかに増大し,一方,K = 5では正しい2 値化画像が生成されないが,K = 6では生成される場合もあることを確認した.ただし,K
= 5の場合よりも余剰な2値化候補文字列画像が生成され,処理時間も増大したため,実験 ではクラスタ数K = 5を採用した.
生成された 2値化候補文字列画像を目視で調べた結果,正しい2値化画像が含まれてい たものは,カラー文字列画像1000枚中878枚であった.すなわち,正解を含む2値化候補 画像の生成率は87.8%となった.この点については,次章で考察を行う.
5.1 提案手法の処理時間
開発環境は以下の通りであり,表2に処理モジュール毎の処理時間を掲げる.
・プログラミング環境: C言語,Microsoft Visual Studio 2008
・CPU: Intel CoreTM 2 Quad Q9550 2.83 GHz
・メモリ: 4GB RAM
表2 処理モジュール毎の処理時間.
処理内容 処理時間(s) 2値化候補文字列画像30枚の生成 4.059
文字列の仮分割と特徴量の抽出 2.702 SVMによる文字・非文字の評価値の
出力
0.901
最大平均評価値による2値化画像の 決定
0.002
合計 7.664
5.
図 た提案
図 正2値 が,次 いる.
2 提案手
8に,正し
案手法を適用 8より,メッ 値化率で99 次章で分析す
.
手法によ
い2値化画 用した結果の ッシュ特徴で
.0%に到達し するように,
図
よる累積
像が含まれて の累積正2値 では正しい2 していること
これは今回
8 カラー文
2 値化率
ていた 878 値化率を示す 2値化画像の とが分かる.数
回対象とした
文字列の累積
率
枚のカラー文 す.
の選択率が91 数値として十 たカラー文字
積正2値化率
文字列画像に
1.6%であるこ 十分に高い性 字の判読の困
率.
に対し,4.で
こと,第4位 性能とは言え 困難性を反映
で述べ
位累積 えない 映して
第
本章 る.
6.
提案 に仮分 ことは かとい 行った に予備
第 6 章
章では提案手
1 提案手
案手法では,
分割するこ は行わない.
いうと,ICD た予備実験に 備実験の結果
考察
手法の予備実
手法の予
情景内カラ とで特徴量を ではなぜこ DAR2003rob において,高 果を示す.
図9 カラ
察
実験と提案手
予備実験
ラー文字列の を抽出し,実 このような仮
bust OCR d 高精度で正
ラー単一文字
手法の能力の
の最適2 値化 実験を行って 仮分割を行っ datasetから
2 値化を行
字における各
の限界,および
化を実現する ているが,従 って文字列を ら抽出したカ
えることが確
各特徴量のR
び今後の課題
るため,文字 従来手法であ を 1 文字単位 ラー単一文字 確認できたた
ROC曲線.
題について考
字列を 1文字 あればこのよ 位に切り分け 字画像1000 ためである.
考察す
字単位 ような けたの 0枚で 以下
図 数ヒス FRR(
の5.7 では正 してい み合わ 響を受 は採用
6.
提案
① K 候
② 1 2
9はカラー単 ストグラム特 (False Reject 7%を達成し 正しい2値化 いることが分 わせた特徴は 受け易い点と 用していない
2 提案手
案手法のキー K-meansクラ 候補文字列画 1文字単位に 2クラス分類
図10
単一文字にお 特徴を組み合 Rate) = FAR している.ま
化画像の選択 分かる.ただ は,加重方向 と,文字列で い.
手法の能
ーアイディア ラスタリング 画像を生成す に仮分割した 類を行うサポ
0 カラー単
おける各特徴 合わせたメッ R(False Accep
た,図10よ
択率が93.7%
だし,このメ 向指数ヒスト では処理時間
能力と限界
アは次の2点 グで得られる する
た2値化候補 ポートベクタ
単一文字の累
徴量のROC ッシュ特徴+加
ptance Rate)と より,メッシ
%であること メッシュ特徴 トグラム特徴 間が大幅に増
界
点である.
るK クラスタ
補文字列画像 ターマシンに
累積正2値化
曲線であり,
加重方向指数 となるERR(
シュ特徴+加重
,第7位累積 徴と加重方向 徴が文字列を 増大する点を
タの網羅的な
像から特徴量 に入力して「
化率.
,メッシュ特 数ヒストグラ Equal Error R 重方向指数ヒ 積正2値化率 向指数ヒスト を仮分割した を考慮し,文
な2分割によ
を抽出して,
文字らしさ」
特徴と加重方 ラム特徴では Rate) の値が ヒストグラム
率で99.9%に
グラム特徴 た際のノイズ 文字列の実験
より複数の2
,文字・非文
」を判定する 方向指 は,
が最小 ム特徴 に到達 徴を組 ズの影 験の際
2値化
文字の る
上記 文字列 けされ 上記 なメ る上で 的で制 補文字 の学習
図
図11
一方 際に,
い.特 うに
図
記①により,
列画像に正し れている場合 記②について ッシュ特徴,
で有効であっ 制限のない非 字画像で「文 習を,提案手
11に,提案
提案手法 択された2
方,提案手法
,文字を分断 特に,加重方 2値化画像の
12に,提案
文字部分が しい 2 値化 合のみでなく ては, 2 値
加重方向指 った.また,
非文字画像を 文字でないも 手法の目的に 案手法により
により正し 値化画像.
法の限界とし 断してしまっ 方向指数ヒス の選択率がメ 案手法により
が複数の色相 化画像が含ま
く,様々な劣 値化候補文字
指数ヒストグ 文字・非文 を用いるので
もの」を用い に適したもの
正しく2値
く2値化画像
して,劣化の った場合など ストグラム特 メッシュ特徴 誤った2値
相にまたがる れる可能性 劣化を含む場 字列画像から抽
グラム特徴を 文字分類の学 ではなく,カ
いることがで のに限定して 値化画像が選
(a)
(b) 像が選択され
の大きい場合 どは誤った 2 特徴はノイズ 徴と比較して 値化画像が選
(a)
る場合も,生 が高くなる.
場合にも有効 抽出する特徴 を用いたこと
学習に用いる カラー文字画
できた.これ て,効率的に
択された例
れた例.(a) 元
合や 2 値化候 2 値化画像を ズの影響を受 て大きく劣っ 選択された例
生成された複 これは,単 効となる.
徴量として,
とが,「文字ら る非文字デー 画像から生成
れにより,文 に行うことが
を示す.
元のカラー文
候補文字列画 を選択してし 受け易いため った結果とな
を示す.
複数の 2 値化 単純に文字が
文字認識で らしさ」を評 ータとして,
成された 2 値 文字・非文字 が出来た.
文字列画像.(
画像を仮分割 しまう可能性 め,図 8 で示 なっている.
化候補 が色分
で有効 評価す 一般 値化候 字分類
(b) 選
割した 性が高 示すよ
図12
図 して誤
図13
この 字列画 に文字
図14
2 提案手法 択された2
13は,カラ
誤った2値化
3 2値化候補
された2値 列画像.
のように,仮 画像の文字間 字数を推測し
(a)
4文字間隔が が広い画像
により誤った 値化画像.
ラー文字列の 化画像が選択
(a)
補文字列画像 値化画像.(c)
仮分割が失敗 間隔が狭い画 して仮分割を
が極端な2値 像
た2値化画像
の文字数に対 択された例で
像の仮分割が 選択される
敗してしまう 画像でも,広 を行っている
値化候補文字
(b) 像が選択され
対して仮分割 である.
(b)
(d)
が失敗した例 るべき2値化
う例が発生す 広い画像でも るためである
字列画像例.
れた例.(a) 元
の分割数が不
例.(a) 元の 化画像.(d) 仮
するのは図14 もそれらを考 る.
(b)
(a) 文字間隔
元のカラー文
不足しており
(c)
カラー文字列 仮分割された
4に示すよう 考慮せず,式
隔が狭い画像
文字列画像.(
り,仮分割が
列画像.(b) た2値化候補
うに2値化候 式(3)によって
像.(b) 文字 (b) 選
が失敗
選択 補文字
候補文 て同様
字間隔
図 分割数 ばな
さ が含ま
図
図 大きい
6.
提案
①
②
③
④
14(a)の仮分 数S2 = 5で らないが,実 らに,第5章 まれない場合
15に,正し
73 図1
15の例は人
いカラー文字
3 今後の
案手法の高度 カラー文字 する.これ れるように
2 値化候補
る.
今回の実験 いられるメ 己相関関数 る特徴量を
SVMでの
組織的に拡
分割数は本来 で仮分割され 実際には分割 章で述べたよ 合があった.
しい2値化画
THIRD
15 正しい2
人間でも文字 字列画像につ
の課題
度化へ向けて 字列画像の色 れにより,最 にする.
補文字列画像
験では,「文 メッシュ特徴 数特徴のよう を採用する.
の学習に用い 拡充する.
来,文字数通り る.一方,図 割数S1 = 12 ように,30枚 画像が生成さ
E 2値化画像が
字列として判 ついては何ら
て,今後の課 色空間でのク 最小限の 2 値
像を仮分割す
文字らしさ」
徴と加重方向 うな他の特徴
る「文字」用
り9でなけれ 図14(b)の仮 2,分割数S
枚の2値化候 されなかった
Engineering が生成されな
判読が困難な らかの対策を
課題は次の通 クラスタリン 値化候補文字
する最適な分
を評価する 向指数ヒス 徴量を検討し
用データにつ
ればならない 仮分割数は本 S2 = 13で仮分
候補文字列画
カラー文字列
g なかったカラ
ものもある.
を講じる必要
通りである.
ングにおける 字列画像の中
分割数をカラ
ための特徴量 トグラム特徴 し,「文字らし
ついて,劣化
いが,実際には 本来,文字数
分割さていれ 画像の中に正
列画像の例を
SUMM ラー文字列の
.このため,
要がある.
る最適クラス 中に正しい 2
ラー文字列ご
量として,文 徴を採用した しさ」の評価
・変形モデル
は分割数S1 数通り8でな
れる.
正しい2値化 を示す.
MER の例.
劣化があま
スタ数を自動 2 値化画像が
ごとに自動決
文字認識技術 たが,高次局 価により適し
ルをも活用し
= 4,
けれ
化画像
まりに
動決定 が含ま
決定す
術に用 局所自 してい
して,
第 7 章 むすび
本研究では,認識に先立つ前処理として情景内カラー文字列の最適2値化手法を提案した.
まず,カラー空間をRGB空間からHSI空間へ変換し,K-meansクラスタリング(K = 5)
により得られたクラスタ網羅的な分割による総数30枚の2値化候補文字列画像を生成した.
次に, 2値化候補文字列画像を1文字単位に2通りの分割数で仮分割し,仮分割された各 画像からメッシュ特徴と加重方向指数ヒストグラム特徴を抽出することで,SVMによる文 字・非文字の評価値を出力させた.最後に,2値化候補文字列画像ごとに評価値の平均を求 め,「文字らしさ」の最大平均評価値をもつ2値化候補文字列画像を最適な2値化結果とし て出力した.
文字・非文字の2クラス分類を行うSVMの学習にはICDAR2003 robust OCR dataset から抽出した1000枚のカラー単一文字画像と136×52枚のフォント画像を用いた.
ICDAR2003 robust word recognition datasetから抽出したカラー文字列画像1000枚を
用いて2値化実験を行った結果,正解を含む2値化候補画像の生成率が87.8%,正解を含 む候補画像群からの正しい2値化画像の選択率が91.6%であった.これより,全体での正2
値化率80.4%を達成したこととなり,提案手法の有効性を確認した.
今後は2値化精度のさらなる向上のための課題として,最適クラスタ数および2値化候補 文字列画像の最適分割数の自動決定,文字らしさを評価する特徴量の工夫,劣化・変形モ デルをも活用した学習データの拡充について取り組んでいくつもりである.
謝辞
この論文が完成に至るまで,ご指導いただいた若原教授には大変お世話になりました.
同若原研究室の皆様も,自分の研究に行き詰った時などに,同じく遅くまで研究室に残り 研究を続ける皆様の姿を見ると大変励まされました.これまで私を支えてくださった全て の方々に,心より感謝申し上げます.
2011 年 1 月 28 日
参考文献
[1] 森稔,澤木美奈子, “低品質文字の認識手法とその応用に関するサーベイ,” 信学技報, PRMU2001-275, March 2002.
[2] 黄瀬浩一,大町真一郎,内田誠一,岩村雅一, “カメラを用いた文字認識・文書画像解析 の現状と課題,” 信学技報,PRMU2004-246, March 2005.
[3] D. Doermann, J. Liang, and H. Li, “Progress in camera-based document image analysis,” Proc.
of 7th Int. Conf. on Document Analysis and Recognition, vol. I, pp. 606-616, Edinburgh, Aug.
2003.
[4] 大谷淳, 塩昭夫, “情景画像からの文字パターンの抽出と認識”, 信学論(D), vol. J71-D, no.6, pp. 1037-1047, June 1988.
[5] 松尾賢一, 上田勝彦, 梅田三千雄, “適応しきい値法を用いた情景画像からの看板文字列 領域抽出”,信学論(D-II), vol. J80-D-II, no.6, pp. 1617–1626, June 1997.
[6] K. Wang and J. A. Kangus, “Character location in scene images from digital camera,” Pattern Recognition, vol. 36, no. 10, pp. 2287–2299, Oct. 2003.
[7] 芦田和毅, 永井 弘樹, 岡本正行, 宮尾秀俊, 山本博章, “情景画像からの文字抽出”, 信学 論(D), vol. J88-D-Ⅱ, no. 9, pp. 1817–1824, Sept. 2005.
[8] M. Yokobayashi and T. Wakahara, “Binarization and recognition of degraded characters using a maximum separability axis in color space and GAT correlation,” Proc. of 18th Int. Conf. on Pattern Recognition, vol. II, pp. 885-888, Hong Kong, Aug. 2006.
[9] N. Otsu, “A threshold selection method from gray-level histograms,” IEEE Trans. Systems, Man and Cybernetics, vol. SMC-9, pp. 62-69, Jan. 1979.
[10] S. M. Lucas, A. Panaretos, L. Sosa, A. Tang, S. Wong, and R. Young, “ICDAR 2003 robust reading competitions,” Proc. 7th Int. Conf. on Document Analysis and Recognition, vol. II, pp.
682-687, Edinburgh, Scotland, Aug. 2003.
[11] http://algoval.essex.ac.uk/icdar/Datasets.html
[12] R. C. Gonzalez and R. E. Woods, Digital Image Processing, Third Edition, Prentice Hall, 2008.
[13] C. M. Bishop, Pattern Recognition and Machine Learning, Springer, 2006.
[14] 奥富正敏編, ディジタル画像処理, CG-ARTS協会, 2004.
[15] 大岡信治,栗田昌徳,原田智夫,木村文隆,三宅康二,“加重方向指数ヒストグラム法に
よる手書き漢字・ひらがな認識,” 信学論(D), vol. J70–D, no. 7, pp. 1390–1397, July 1987.
[16] V. N. Vapnik, The Nature of Statistical Learning Theory, Second Edition, Springer, 2000.
[17] T. Joachims, “Making large-scale SVM learning practical,” Advances in Kernel Methods:
Support Vector Learning, B. Schölkopf, C. J. Burges, and A. J. Smola (eds.). Chapter 11, MIT
Press, 1998.