The Ryu Corpus: Longitudinal Speech Data from Three Korean Children Added to the CHILDES
Database
Ju-Yeon Ryu
Abstract
In this paper I describe in detail the Ryu Corpus, the first language acquisition corpus for Korean published in the Child Language Data Exchange System (CHILDES, http://childes.psy.cmu.edu) in 2017. I suggest various methods for how language analysis can be performed using CHILDES, an online application that publicly discloses first language (L1) acquisition data for approximately 40 languages worldwide (MacWinney, 2000). The Ryu Corpus is the first compilation of Korean-language longitudinal speech data to have been published in CHILDES. The corpus serves as a record of natural utterances collected from three children who began learning Korean as their L1 and interacted with their caretakers between 1.5 and 3.5 years of age. The total recording time was 87 hours and 15 minutes; the corpus contains a huge volume of data, with the total number of utterances from children and caretakers exceeding 150,000. In this paper, I delve into the creation of the Ryu Corpus, from the collection stage to the preparation of transcripts, in order to offer a useful resource for L1 acquisition research. CHILDES is composed of a database containing children’s transcribed utterances, which have been converted to the Codes for the Human Analysis of Transcripts (CHAT) format (for linguistic analysis), as well as the Computerized Language Analysis (CLAN) program, which enables scholars to examine large amounts of linguistic material. I propose potential applications while discussing the results of executing Frequency of Word Appearance (FREQ) and Search for Sentences Using Target Word (Key Word And Line: KWAL) commands in the CLAN program using the Ryu Corpus.
1. Introduction
The field of Korean first language (L1) acquisition research has thus far lacked a shareable infant language corpus. The reality of this area in South Korea today is that the collection, transcription, and analysis of data, particularly in L1 longitudinal studies, requires considerable time. As such, only individual researchers can conduct studies, which might be based only on a small number of cases.
In 2017, I uploaded L1 acquisition data (the Ryu Corpus) for Korean to the language acquisition data sharing system known as the Child Language Data Exchange System (CHILDES). In global L1 acquisition
research, the CHILDES project (http://childes.psy.cmu.edu; MacWinney 2000), which provides computer- based data sharing and analytical tools, has enabled the scrutinization of a large amount of spontaneous utterance data. Many studies have been carried out using a shared corpus in various L1 acquisition studies performed in Europe and the United States. Data from children whose native language is Japanese can be investigated on a large scale using data published by JCHAT (Oshima-Takane & MacWhinney 1998), the Japanese version of CHILDES. This resource has been actively used in L1 acquisition research in recent years. According to Slobin (2014), editor of the Journal of Child Language, 10 books on L1 acquisition research for Korean were published between 1974 and 2013, compared to 23 on Japanese, 27 on Mandarin, and 11 on Cantonese, implying that research on Korean language acquisition is lagging behind. Most research completed to date has been based on psychological experiments in particular, and there are almost no studies grounded in longitudinal utterance data, the most basic research technique. In this paper, I introduce the first publicly available Korean language corpus, and discuss various potential analytical applications of the Computerized Language Analysis (CLAN) tool provided by CHILDES.
2. The Ryu Corpus
2.1 Method of data collection
To clarify the L1 acquisition process, it is necessary to possess natural utterance data from infants collected over a long period of time. However, no data concerning children learning Korean have previously been published as a corpus. For this reason, I gathered spontaneous utterance data from three children who learned Korean as their mother tongue over a two-year period (this paper is a doctoral thesis). Table 1 (below) depicts the method of data collection applied.
Table 1 Method for collecting children’s natural utterance data
Target child Children learning Korean as their mother tongue
Age of target child Between 1 and 2.5 years old (when data collection begins) Collection period 2 years
Collection frequency It does not matter how many times data are collected, but they are gathered so that the total is 1 hour per month
Recording method Video camera recording Recording location Target child’s house Interview
arrangements
Recording starts when the caretaker and target child read a picture book
Caretaker range Mother, father, grandmother, grandfather
research, the CHILDES project (http://childes.psy.cmu.edu; MacWinney 2000), which provides computer- based data sharing and analytical tools, has enabled the scrutinization of a large amount of spontaneous utterance data. Many studies have been carried out using a shared corpus in various L1 acquisition studies performed in Europe and the United States. Data from children whose native language is Japanese can be investigated on a large scale using data published by JCHAT (Oshima-Takane & MacWhinney 1998), the Japanese version of CHILDES. This resource has been actively used in L1 acquisition research in recent years. According to Slobin (2014), editor of the Journal of Child Language, 10 books on L1 acquisition research for Korean were published between 1974 and 2013, compared to 23 on Japanese, 27 on Mandarin, and 11 on Cantonese, implying that research on Korean language acquisition is lagging behind. Most research completed to date has been based on psychological experiments in particular, and there are almost no studies grounded in longitudinal utterance data, the most basic research technique. In this paper, I introduce the first publicly available Korean language corpus, and discuss various potential analytical applications of the Computerized Language Analysis (CLAN) tool provided by CHILDES.
2. The Ryu Corpus
2.1 Method of data collection
To clarify the L1 acquisition process, it is necessary to possess natural utterance data from infants collected over a long period of time. However, no data concerning children learning Korean have previously been published as a corpus. For this reason, I gathered spontaneous utterance data from three children who learned Korean as their mother tongue over a two-year period (this paper is a doctoral thesis). Table 1 (below) depicts the method of data collection applied.
Table 1 Method for collecting children’s natural utterance data
Target child Children learning Korean as their mother tongue
Age of target child Between 1 and 2.5 years old (when data collection begins) Collection period 2 years
Collection frequency It does not matter how many times data are collected, but they are gathered so that the total is 1 hour per month
Recording method Video camera recording Recording location Target child’s house Interview
arrangements
Recording starts when the caretaker and target child read a picture book
Caretaker range Mother, father, grandmother, grandfather
I set the target children’s age range between 1 and 2.5 years old because this is when children enter the second stage of vocabulary acquisition and gradually begin to produce two-word sentences. The first phase of vocabulary acquisition takes place before the first word occurs, when children start to exhibit comprehension behavior and to pronounce about 30–50 words, from around 10 months to 1.5 years old.
The first period of vocabulary acquisition happens when the spontaneous production of words exceeds about 50 words, resulting in an explosive absorption of vocabulary, and the child slowly begins to learn syntax and morphology. In this study, I accumulated data for two years by observing children between 1.5 and 3.5 years old, when the process of syntax and morphology development is clearly noticeable.
I set the frequency of data collection to 1 hour per month, regardless of the number of collections. At first, I asked the caretakers to record every 30 minutes once every two weeks, although it might be difficult for some children to stay still for that long. As such, I asked the caretakers to record the children when they were relaxed and in a good mood, so that the total recording time per month would be one hour.
I obtained data using a video camera with a built-in HDD (Hard Disk Drive), Victor [Japan] Everio GZ- MG840. I gave the video camera to caretakers, who were instructed to use the camera for each recording session. The recorded data were stored on an SD card (Secure Digital Memory Card); I gathered and compiled the data every six months by replacing the SD card. Fig. 1 displays a representative screenshot from the recorded data.
Fig. 1 Examples of data recorded by video cameras
In L1 acquisition research, there was a time when the innate theory (Noam Chomsky) that “grammar is inherent in children’s minds” was mainstream. However, in recent years, Tomasello (1999) has advocated for an approach that emphasizes social interaction whereby “children have a powerful ability to understand the minds of others such as caretakers, allowing for the acquisition of language.” Tomasello views language acquisition as the process of guessing the intentions underlying adult communication in certain circumstances, and linking those intentions to words. From this perspective, children are social entities that guess intentions. For this reason, I recorded data with a video camera so that temporal or spatial elements in which a verbal action occurred (as well as words) could be grasped. Conventionally, in linguistics, sound recorders have been used to analyze words only, but I did not account for actual situations – or when the caretaker and child were paying attention – as these aspects can be difficult to grasp. By gathering data with a video camera, it is possible to measure a child’s intention to communicate, and to provide high-quality video data in the form of a corpus.
I chose the scene of the caretaker and child reading a picture book because when recording the data, it is necessary to control the scene since the recorder is not accompanied each time. If the scene is not restricted, there is a risk that the use of specific vocabulary may be biased depending on the scene; for example, some children often choose scenes of outside play, while others choose mealtimes. Therefore, it was imperative to capture data for the three children in the same scene and to create background circumstances that were consistent to some extent. In addition, according to Nakata and Kobayashi (2008), their study “MLU [mean length of utterance] data fluctuations in daily observation data [of] two-year-olds when waking up” reported that MLU differs depending on the scene. For example, when watching TV, the number of utterances and MLU are at their lowest. In contrast, the number of utterances and MLU are approximately five times higher during playtime, changing clothes, and mealtimes. Furthermore, when reading picture books, the number of utterances and MLU are at their highest (10 times greater than when watching TV and 5 times higher than during playtime). Thus, in this study, I set the scene for recording data to be while reading a picture book, during which I could easily record the children’s utterances within a limited timeframe. Although they were only allowed to read picture books, children cannot focus on this activity alone for an extended period. While reading a picture book, children will likely soon start playing with toys, paying attention to other things, and running around. In this study, I started with reading a picture book; if the children lost interest while doing so, I recorded the child speaking naturally about everyday life, instead of forcing him/her to read the book. Nonetheless, since the scene was restricted to reading picture books, I did not observe natural language behavior from a variety of scenes, and caretakers read the picture book entirely on their own while the children memorized it. I noted that this type of data are far from natural language use. In fact, it is quite difficult to evenly extract natural utterances produced during diverse scenes, and there are some aspects that I could not control during the study, as it did not involve the researcher’s presence at every recording session. As for the problem of rote reading and memorization, I found that none of the
In L1 acquisition research, there was a time when the innate theory (Noam Chomsky) that “grammar is inherent in children’s minds” was mainstream. However, in recent years, Tomasello (1999) has advocated for an approach that emphasizes social interaction whereby “children have a powerful ability to understand the minds of others such as caretakers, allowing for the acquisition of language.” Tomasello views language acquisition as the process of guessing the intentions underlying adult communication in certain circumstances, and linking those intentions to words. From this perspective, children are social entities that guess intentions. For this reason, I recorded data with a video camera so that temporal or spatial elements in which a verbal action occurred (as well as words) could be grasped. Conventionally, in linguistics, sound recorders have been used to analyze words only, but I did not account for actual situations – or when the caretaker and child were paying attention – as these aspects can be difficult to grasp. By gathering data with a video camera, it is possible to measure a child’s intention to communicate, and to provide high-quality video data in the form of a corpus.
I chose the scene of the caretaker and child reading a picture book because when recording the data, it is necessary to control the scene since the recorder is not accompanied each time. If the scene is not restricted, there is a risk that the use of specific vocabulary may be biased depending on the scene; for example, some children often choose scenes of outside play, while others choose mealtimes. Therefore, it was imperative to capture data for the three children in the same scene and to create background circumstances that were consistent to some extent. In addition, according to Nakata and Kobayashi (2008), their study “MLU [mean length of utterance] data fluctuations in daily observation data [of] two-year-olds when waking up” reported that MLU differs depending on the scene. For example, when watching TV, the number of utterances and MLU are at their lowest. In contrast, the number of utterances and MLU are approximately five times higher during playtime, changing clothes, and mealtimes. Furthermore, when reading picture books, the number of utterances and MLU are at their highest (10 times greater than when watching TV and 5 times higher than during playtime). Thus, in this study, I set the scene for recording data to be while reading a picture book, during which I could easily record the children’s utterances within a limited timeframe. Although they were only allowed to read picture books, children cannot focus on this activity alone for an extended period. While reading a picture book, children will likely soon start playing with toys, paying attention to other things, and running around. In this study, I started with reading a picture book; if the children lost interest while doing so, I recorded the child speaking naturally about everyday life, instead of forcing him/her to read the book. Nonetheless, since the scene was restricted to reading picture books, I did not observe natural language behavior from a variety of scenes, and caretakers read the picture book entirely on their own while the children memorized it. I noted that this type of data are far from natural language use. In fact, it is quite difficult to evenly extract natural utterances produced during diverse scenes, and there are some aspects that I could not control during the study, as it did not involve the researcher’s presence at every recording session. As for the problem of rote reading and memorization, I found that none of the
caretakers actually read the whole book. Rather, they converted the book’s content into their own words and narrated it based on the child’s understanding and interests. I did not witness full memorization by the children among the data. Thus, I derived the natural language data from information gathered while reading picture books and discussing everyday activities.
The next section will describe the target children in detail. The caretakers included mothers, fathers, grandmothers, and grandfathers. In many cases, fathers, grandmothers, and grandfathers also participate in childrearing, rather than mothers alone. When I gathered the data, primarily mothers took part in the recording, but fathers, grandmothers, and grandfathers also did in some cases. However, if the data encompassed the utterances of siblings, I excluded them from the analysis because they were not included in the study’s analytical target.
I began to record data in February 2009 and did so for two years until February 2011. In order to recruit the target children, I contacted friends and acquaintances with young children, as well as caretakers of children, who met the target conditions (such as age).
Before starting data collection, I explained the study’s purpose to the caretakers, how to use the video camera, and how to collect data. To protect the participants’ privacy, I promised not to use data and materials collected for reasons other than research, and to use pseudonyms when publishing results in order to maintain the target children’s anonymity. I also informed the participants that our goal was to obtain data over a two-year period, but that I would prioritize the convenience of the target children’s households, and that they could freely withdraw from the study at any time.
2.2 Characteristics of the children selected for data collection
Since I used qualitative and longitudinal research techniques and acquired data from a small group to compile the Ryu Corpus, it is susceptible to individual differences. Thus, this section provides background details concerning the three target children (Table 2).
I used abbreviated pseudonyms instead of the children’s full names to protect their privacy. The children were two boys and one girl, one of whom is a child of the author. Jong lived in Miyagi Prefecture, Japan during the data collection period, but his parents are ethnic Koreans, his language at home is Korean, and he has learned Korean as his native tongue. The presence of siblings can also affect language development, but only Joo has an older sibling. All of the parents have earned a college degree or higher and live in Seoul, South Korea. At the time of the study, none of the children had attended nursery school before going to kindergarten (i.e., before age three).
Table 2 Characteristics of the children selected for data collection
Jong Joo Yun Birthday December 2007 May 2007 November 2006
Sex Male Female Male
Presence of siblings Sister, 2 years and 4 months younger
Sister, 3 years older None
Location of data collection Miyagi, Japan Seoul, South Korea
Seoul, South Korea Seoul, South Korea
Age of subject providing data
1;3 - 3;5 1;9 - 3;10 2;3 - 3;9
Caretakers appearing in the data
Mother, father, grandmother,
grandfather
Mother, father, grandmother
Mother
Mother’s educational background
Finished graduate school
Finished university Finished university
Nursery school experience before age 3
None None None
2.3 Details of collected data
Table 3 depicts the details of the data used for analysis. The number of collections varies greatly between the children. This may be due to differences between remaining focused and staying in the same spot, versus soon losing interest and trying new games. In addition, the recording time was much longer than planned.
I initially asked the caretakers to record for a specific number of hours per month, but they recorded more data than that, indicating that they actively cooperated with data collection. However, in the case of Yun, his caretaker initially planned to gather data for the first two years and obtained data for 2;3–4;3, but I decided not to include the last 6 months (3;10–4;3) in the corpus, as Yun’s learning of grammar was quite advanced. For this reason, Yun’s recording time is comparatively short.
Table 3 Details of the collected data Age
No. of
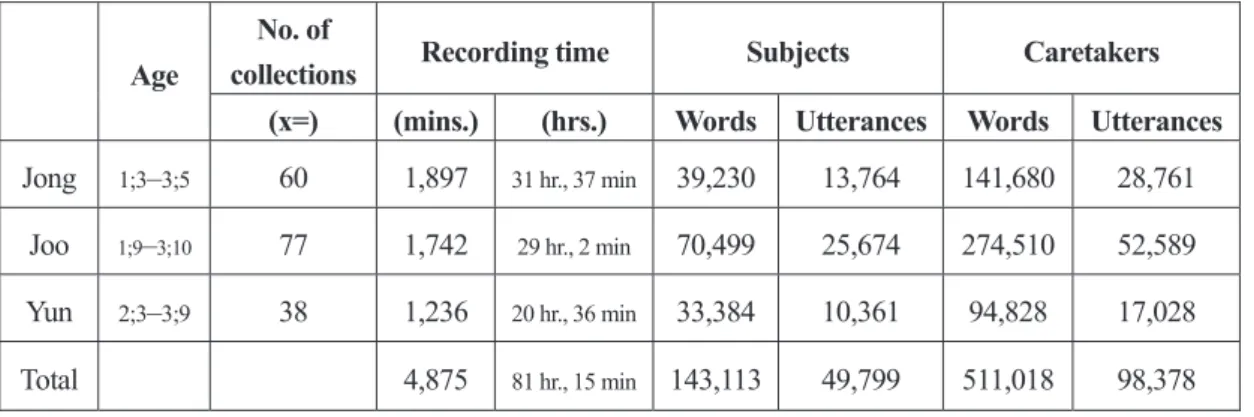
collections Recording time Subjects Caretakers (x=) (mins.) (hrs.) Words Utterances Words Utterances Jong 1;3–3;5 60 1,897 31 hr., 37 min 39,230 13,764 141,680 28,761 Joo 1;9–3;10 77 1,742 29 hr., 2 min 70,499 25,674 274,510 52,589 Yun 2;3–3;9 38 1,236 20 hr., 36 min 33,384 10,361 94,828 17,028 Total 4,875 81 hr., 15 min 143,113 49,799 511,018 98,378
Table 2 Characteristics of the children selected for data collection
Jong Joo Yun Birthday December 2007 May 2007 November 2006
Sex Male Female Male
Presence of siblings Sister, 2 years and 4 months younger
Sister, 3 years older None
Location of data collection Miyagi, Japan Seoul, South Korea
Seoul, South Korea Seoul, South Korea
Age of subject providing data
1;3 - 3;5 1;9 - 3;10 2;3 - 3;9
Caretakers appearing in the data
Mother, father, grandmother,
grandfather
Mother, father, grandmother
Mother
Mother’s educational background
Finished graduate school
Finished university Finished university
Nursery school experience before age 3
None None None
2.3 Details of collected data
Table 3 depicts the details of the data used for analysis. The number of collections varies greatly between the children. This may be due to differences between remaining focused and staying in the same spot, versus soon losing interest and trying new games. In addition, the recording time was much longer than planned.
I initially asked the caretakers to record for a specific number of hours per month, but they recorded more data than that, indicating that they actively cooperated with data collection. However, in the case of Yun, his caretaker initially planned to gather data for the first two years and obtained data for 2;3–4;3, but I decided not to include the last 6 months (3;10–4;3) in the corpus, as Yun’s learning of grammar was quite advanced. For this reason, Yun’s recording time is comparatively short.
Table 3 Details of the collected data Age
No. of
collections Recording time Subjects Caretakers (x=) (mins.) (hrs.) Words Utterances Words Utterances Jong 1;3–3;5 60 1,897 31 hr., 37 min 39,230 13,764 141,680 28,761 Joo 1;9–3;10 77 1,742 29 hr., 2 min 70,499 25,674 274,510 52,589 Yun 2;3–3;9 38 1,236 20 hr., 36 min 33,384 10,361 94,828 17,028 Total 4,875 81 hr., 15 min 143,113 49,799 511,018 98,378
2.4 Mean length of utterance
Linguist Roger Brown put forth the metric MLU (mentioned earlier) in 1973 as a syntactic indicator of language development. Behind his proposal is the fact that sentence elements increase as sentence structures become more complex due to the development of grammar. For example, the utterance “teddy jump” [bear jump] at the beginning of language acquisition changes to “the teddy is jumping” [bear is jumping], and becomes longer due to the addition of articles, determiners, and verb conjugation endings. Brown (1973) suggested using a morpheme as a unit of speech length calculation. Specifically, a grammatical suffix can also be a unit, in addition to independent semantic words. Plural forms of nouns and -s, -ed, and -ing endings of verbs are recognized as one morpheme. In the above example, teddy/jump has two morphemes, while the/teddy/is/jump/-ing has five morphemes.
For the Ryu Corpus, I adopted an MLU calculation method based on “separation.” Korean, like English, has the feature of writing words with “separation.” This means writing a sentence with a space between words. For example, the phrase “엄마가 사과를 먹었다 (Mom ate an apple)” has three words and one utterance based on “separation” and an MLU of 3.0. I have already segmented characterized data in the corpus, and if the criterion for word segmentation in AWK programs is set as the criterion for segmentation, the number of words can be calculated easily. I conducted these calculations, and the results are displayed in Tables 4, 5, and 6 (below).
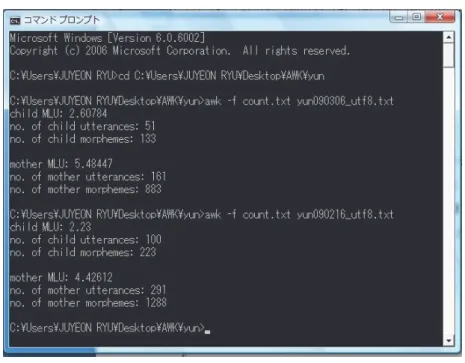
Here, Fig. 2 shows the count.txt command used in the AWK program. Fig. 3 shows the outcome generated when the AWK program is run.
Fig. 2 Commands for the count.txt file /CHI/ {
chi_morphemes = chi_morphemes + (NF-2) chi_count++
} /MOT/ {
mot_morphemes = mot_morphemes + (NF-2) mot_count++
} END {
print “child MLU:”, chi_morphemes / chi_count print “no. of child utterances:”, chi_count print “no. of child morphemes:”, chi_morphemes print ““
print “mother MLU:”, mot_morphemes / mot_count print “no. of mother utterances:”, mot_count print “no. of mother morphemes:”, mot_morphemes }
Fig. 3 Example of table of results generated by the AWK program
As presented in Fig. 3, when the command “awk –f count.txt yun090216_utf8.txt” is input, the child’s MLU is automatically calculated and a result is generated. yun090216_utf8.txt is the name of the text file saved for Yun on February 16, 2009 in the utf8 format. MLU is calculated by dividing the number of words by the number of utterances. Under Child MLU: 2.23, the child’s number of utterances is written out: 100 (number of utterances the child made), in addition to the number of the child’s morphemes: 223 (words the child spoke).
In this paper, while I determined MLU using another program called AWK, MLU can also be established using CHILDES’ CLAN program, described in the next chapter. However, morphological analysis is conducted on the premise that MLU is calculated with the CLAN program, and morphological analysis functionality is not yet supported by the Ryu Corpus. I am currently constructing “Grammar” and
“Dictionary” for the Korean language to enable morphological analysis, but this process will take a long time to complete. In this paper, I present the MLU outcomes that can be analyzed at this stage, and discuss their utility when using the Ryu Corpus.
2.5 Details of the Ryu Corpus
The Ryu Corpus consists of utterance data obtained from three target children: Jong, Joo, and Yun (mentioned earlier). Here, Tables 4, 5, and 6 show the details of the data obtained (including MLU data) for each file name. I created each file name so that the child’s age would be apparent. For example, 020300a.cha means the first (a) recorded data at 2 years and 3 months (020300). The last .cha signals that the file is in
Fig. 3 Example of table of results generated by the AWK program
As presented in Fig. 3, when the command “awk –f count.txt yun090216_utf8.txt” is input, the child’s MLU is automatically calculated and a result is generated. yun090216_utf8.txt is the name of the text file saved for Yun on February 16, 2009 in the utf8 format. MLU is calculated by dividing the number of words by the number of utterances. Under Child MLU: 2.23, the child’s number of utterances is written out: 100 (number of utterances the child made), in addition to the number of the child’s morphemes: 223 (words the child spoke).
In this paper, while I determined MLU using another program called AWK, MLU can also be established using CHILDES’ CLAN program, described in the next chapter. However, morphological analysis is conducted on the premise that MLU is calculated with the CLAN program, and morphological analysis functionality is not yet supported by the Ryu Corpus. I am currently constructing “Grammar” and
“Dictionary” for the Korean language to enable morphological analysis, but this process will take a long time to complete. In this paper, I present the MLU outcomes that can be analyzed at this stage, and discuss their utility when using the Ryu Corpus.
2.5 Details of the Ryu Corpus
The Ryu Corpus consists of utterance data obtained from three target children: Jong, Joo, and Yun (mentioned earlier). Here, Tables 4, 5, and 6 show the details of the data obtained (including MLU data) for each file name. I created each file name so that the child’s age would be apparent. For example, 020300a.cha means the first (a) recorded data at 2 years and 3 months (020300). The last .cha signals that the file is in
the Codes for the Human Analysis of Transcripts (CHAT) format, which will be introduced in the next chapter. Jong’s data come with a video file, but I only made transcription files for Joo and Yun.
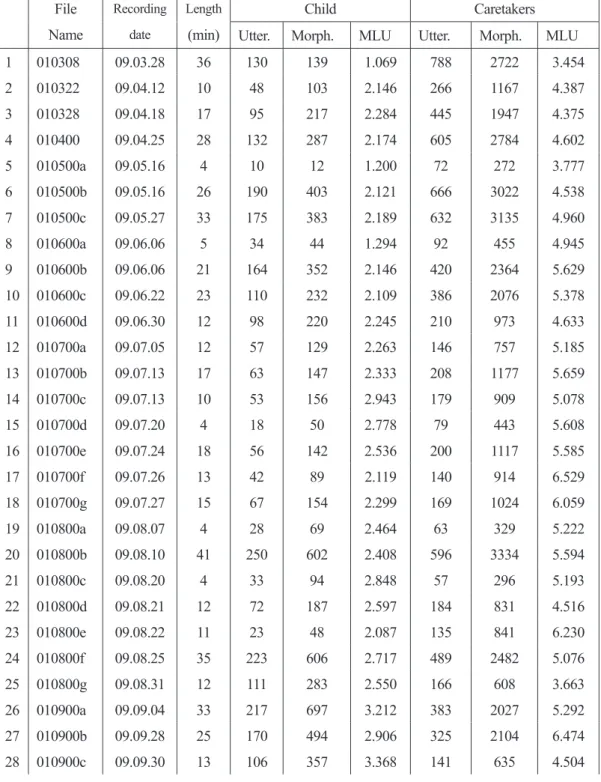
Table 4 Details of the data collected from Jong (Utter.=Utterances, Morph.=Morphemes) File
Name
Recording date
Length (min)
Child Caretakers Utter. Morph. MLU Utter. Morph. MLU
1 010308 09.03.28 36 130 139 1.069 788 2722 3.454 2 010322 09.04.12 10 48 103 2.146 266 1167 4.387 3 010328 09.04.18 17 95 217 2.284 445 1947 4.375 4 010400 09.04.25 28 132 287 2.174 605 2784 4.602
5 010500a 09.05.16 4 10 12 1.200 72 272 3.777
6 010500b 09.05.16 26 190 403 2.121 666 3022 4.538 7 010500c 09.05.27 33 175 383 2.189 632 3135 4.960
8 010600a 09.06.06 5 34 44 1.294 92 455 4.945
9 010600b 09.06.06 21 164 352 2.146 420 2364 5.629 10 010600c 09.06.22 23 110 232 2.109 386 2076 5.378 11 010600d 09.06.30 12 98 220 2.245 210 973 4.633 12 010700a 09.07.05 12 57 129 2.263 146 757 5.185 13 010700b 09.07.13 17 63 147 2.333 208 1177 5.659 14 010700c 09.07.13 10 53 156 2.943 179 909 5.078
15 010700d 09.07.20 4 18 50 2.778 79 443 5.608
16 010700e 09.07.24 18 56 142 2.536 200 1117 5.585 17 010700f 09.07.26 13 42 89 2.119 140 914 6.529 18 010700g 09.07.27 15 67 154 2.299 169 1024 6.059
19 010800a 09.08.07 4 28 69 2.464 63 329 5.222
20 010800b 09.08.10 41 250 602 2.408 596 3334 5.594
21 010800c 09.08.20 4 33 94 2.848 57 296 5.193
22 010800d 09.08.21 12 72 187 2.597 184 831 4.516 23 010800e 09.08.22 11 23 48 2.087 135 841 6.230 24 010800f 09.08.25 35 223 606 2.717 489 2482 5.076 25 010800g 09.08.31 12 111 283 2.550 166 608 3.663 26 010900a 09.09.04 33 217 697 3.212 383 2027 5.292 27 010900b 09.09.28 25 170 494 2.906 325 2104 6.474 28 010900c 09.09.30 13 106 357 3.368 141 635 4.504
29 011000 09.10.13 20 92 261 2.837 234 1234 5.274 30 011100a 09.11.03 40 291 821 2.821 538 2762 5.134 31 011100b 09.11.17 20 95 217 2.284 445 1947 4.375
32 011100c 09.11.23 10 52 181 3.481 89 414 4.652
33 020000a 09.12.01 25 164 499 3.043 315 1468 4.660 34 020000b 09.12.06 50 294 846 2.878 648 3544 5.469
35 020000c 09.12.27 2 8 46 5.75 5 31 6.200
36 020100a 10.01.11 45 310 899 2.900 625 3536 5.658
37 020100b 10.01.21 40 294 1025 3.486 534 2968 5.558
38 020200a 10.02.11 45 205 654 3.290 506 2527 4.994 39 020200b 10.02.19 35 226 755 3.341 409 1924 4.704
40 020300a 10.03.04 40 394 1158 2.939 617 2880 4.668
41 020300b 10.03.18 45 366 996 2.721 691 3453 4.997
42 020400a 10.04.04 30 324 1070 3.302 413 1543 3.736
43 020400b 10.04.20 20 129 356 2.760 248 997 4.020
44 020400c 10.04.23 55 549 1421 2.588 1019 4865 4.774
45 020500a 10.05.21 40 346 1004 2.902 676 3063 4.531
46 020500b 10.05.29 10 71 238 3.352 65 273 4.200
47 020600a 10.06.16 55 586 1572 2.683 911 4198 4.608
48 020600b 10.06.30 45 433 1132 2.614 760 3793 4.991
49 020700 10.07.12 90 521 1609 3.088 943 3973 4.213
50 020800 10.08.21 50 411 1166 2.837 813 3882 4.775
51 020900 10.09.18 55 520 1509 2.902 883 4264 4.829
52 021000a 10.10.01 10 50 144 2.880 103 399 3.874
53 021000b 10.10.23 90 803 2247 2.798 1450 7237 4.991
54 021100a 10.11.17 35 367 920 2.507 706 2782 3.941
55 021100b 10.11.23 53 467 1265 2.709 893 4199 4.702
56 030000 10.12.22 60 585 1994 3.409 902 4503 4.992
57 030100 11.01.19 50 369 1251 3.390 767 4182 5.452
58 030200a 11.02.23 35 249 677 2.719 485 2338 4.821 59 030200b 11.02.29 40 293 798 2.724 604 3339 5.528
60 030300 11.03.26 60 414 1303 3.147 863 4868 5.641
61 030400 11.04.18 50 333 986 2.961 772 4264 5.523
62 030500 11.05.28 55 430 1616 3.758 756 4043 5.348
29 011000 09.10.13 20 92 261 2.837 234 1234 5.274 30 011100a 09.11.03 40 291 821 2.821 538 2762 5.134 31 011100b 09.11.17 20 95 217 2.284 445 1947 4.375
32 011100c 09.11.23 10 52 181 3.481 89 414 4.652
33 020000a 09.12.01 25 164 499 3.043 315 1468 4.660 34 020000b 09.12.06 50 294 846 2.878 648 3544 5.469
35 020000c 09.12.27 2 8 46 5.75 5 31 6.200
36 020100a 10.01.11 45 310 899 2.900 625 3536 5.658
37 020100b 10.01.21 40 294 1025 3.486 534 2968 5.558
38 020200a 10.02.11 45 205 654 3.290 506 2527 4.994 39 020200b 10.02.19 35 226 755 3.341 409 1924 4.704
40 020300a 10.03.04 40 394 1158 2.939 617 2880 4.668
41 020300b 10.03.18 45 366 996 2.721 691 3453 4.997
42 020400a 10.04.04 30 324 1070 3.302 413 1543 3.736
43 020400b 10.04.20 20 129 356 2.760 248 997 4.020
44 020400c 10.04.23 55 549 1421 2.588 1019 4865 4.774
45 020500a 10.05.21 40 346 1004 2.902 676 3063 4.531
46 020500b 10.05.29 10 71 238 3.352 65 273 4.200
47 020600a 10.06.16 55 586 1572 2.683 911 4198 4.608
48 020600b 10.06.30 45 433 1132 2.614 760 3793 4.991
49 020700 10.07.12 90 521 1609 3.088 943 3973 4.213
50 020800 10.08.21 50 411 1166 2.837 813 3882 4.775
51 020900 10.09.18 55 520 1509 2.902 883 4264 4.829
52 021000a 10.10.01 10 50 144 2.880 103 399 3.874
53 021000b 10.10.23 90 803 2247 2.798 1450 7237 4.991
54 021100a 10.11.17 35 367 920 2.507 706 2782 3.941
55 021100b 10.11.23 53 467 1265 2.709 893 4199 4.702
56 030000 10.12.22 60 585 1994 3.409 902 4503 4.992
57 030100 11.01.19 50 369 1251 3.390 767 4182 5.452
58 030200a 11.02.23 35 249 677 2.719 485 2338 4.821 59 030200b 11.02.29 40 293 798 2.724 604 3339 5.528
60 030300 11.03.26 60 414 1303 3.147 863 4868 5.641
61 030400 11.04.18 50 333 986 2.961 772 4264 5.523
62 030500 11.05.28 55 430 1616 3.758 756 4043 5.348
Table 5 Details of the data collected from Joo (Utter.=Utterance, Morph.=Morphemes) File
Name
Recording date
Length (min)
Child Caretakers Utter. Morph. MLU Utter. Morph. MLU
1 010900a 09.02.15 10 30 79 2.633 160 1125 7.031
2 010900b 09.02.17 3 8 23 2.875 36 243 6.750
3 010900c 09.02.19 12 8 17 2.125 125 909 7.272 4 010900d 09.02.20 25 28 66 2.357 166 1162 7.000 5 011000a 09.03.05 8 32 83 2.594 101 590 5.842 6 011000b 09.03.09 36 204 457 2.240 404 1989 4.923 7 011000c 09.03.17 21 100 270 2.700 213 1272 5.972 8 011000d 09.03.26 19 75 271 3.613 169 1155 6.834 9 011100a 09.04.07 30 191 525 2.749 312 2009 6.439 10 011100b 09.04.16 12 80 264 3.300 133 1159 8.714 11 011100c 09.04.20 27 187 579 3.096 338 2130 6.302 12 011130a 09.05.08 14 80 229 2.863 145 922 6.359 13 011130b 09.05.18 20 170 513 3.018 284 2288 8.056 14 011130c 09.05.19 23 196 590 3.010 310 2050 6.613 15 011130d 09.05.28 9 96 301 3.135 124 619 4.992 16 020100a 09.06.12 21 50 187 3.740 193 1818 9.420 17 020100b 09.06.22 23 87 357 4.103 200 1810 9.050 18 020100c 09.06.24 26 113 331 2.929 259 2091 8.073 19 020200a 09.07.06 28 217 624 2.876 350 2206 6.303 20 020200b 09.07.21 16 55 153 2.782 136 842 6.191 21 020200c 09.07.28 25 240 723 3.013 347 2108 6.075 22 020300a 09.08.08 20 168 376 2.238 359 1664 4.635 23 020300b 09.08.14 15 163 412 2.528 401 1948 4.858 24 020300c 09.08.19 20 163 412 2.528 401 1948 4.858 25 020300d 09.08.26 25 161 400 2.484 411 2065 5.024 26 020400a 09.09.08 25 99 249 2.515 393 2180 5.547 27 020400b 09.09.17 25 109 282 2.587 416 2197 5.281 28 020400c 09.09.23 20 109 263 2.413 338 1782 5.272 29 020500a 09.10.08 15 95 230 2.421 238 1194 5.017 30 020500b 09.10.15 35 189 494 2.614 511 2611 5.110 31 020500c 09.10.25 15 161 391 2.429 473 2083 4.404
32 020600a 09.11.03 32 249 561 2.253 690 3271 4.741 33 020600b 09.11.23 24 136 297 2.184 553 2447 4.425 34 020600c 09.11.30 10 41 102 2.488 155 714 4.606 35 020700a 09.12.06 9 51 109 2.137 198 865 4.369 36 020700b 09.12.15 36 175 375 2.143 823 3784 4.598 37 020700c 09.12.22 15 86 180 2.093 347 1488 4.288 38 020800a 10.01.08 16 143 300 2.098 342 1293 3.781 39 020800b 10.01.12 22 52 110 2.115 347 1535 4.424 40 020800c 10.01.19 10 109 241 2.211 386 1850 4.793 41 020800d 10.01.25 29 165 385 2.333 518 2472 4.772 42 020900a 10.02.04 35 264 578 2.189 751 3211 4.276 43 020900b 10.02.20 13 117 248 2.120 291 1230 4.227 44 020900c 10.02.24 27 138 330 2.391 381 1788 4.693 45 021000a 10.03.10 26 203 443 2.182 500 2280 4.560 46 021000b 10.03.24 24 96 227 2.365 410 2057 5.017 47 021000c 10.03.25 12 58 129 2.224 201 866 4.308 48 021100a 10.04.01 23 145 387 2.669 428 2103 4.914 49 021100b 10.04.11 28 105 244 2.324 407 1845 4.533 50 021100c 10.04.20 25 156 324 2.077 408 1794 4.397 51 030000a 10.05.04 15 108 267 2.472 242 1017 4.202 52 030000b 10.05.21 25 91 202 2.220 316 1612 5.101 53 030000c 10.05.22 30 163 398 2.442 429 2095 4.883 54 030000d 10.05.29 8 90 195 2.167 150 476 3.173 55 030100a 10.06.01 26 211 566 2.682 436 1906 4.372 56 030100b 10.06.23 17 95 263 2.768 221 779 3.525 57 030100c 10.06.29 20 223 576 2.583 333 1238 3.718 58 030200a 10.07.06 18 122 350 2.869 328 1567 4.777 59 030200b 10.07.11 28 185 516 2.789 403 1747 4.335 60 030200c 10.07.15 15 116 421 3.629 208 1106 5.317 61 030200d 10.07.27 20 163 429 2.632 296 1289 4.355 62 030300a 10.08.17 10 91 229 2.516 181 881 4.867 63 030300b 10.08.22 40 321 854 2.660 638 2901 4.547 64 030300c 10.08.31 20 190 574 3.021 330 1511 4.579 65 030400a 10.09.11 15 131 512 3.908 270 1342 4.970
66 030400b 10.09.19 56 401 1307 3.259 831 4059 4.884
32 020600a 09.11.03 32 249 561 2.253 690 3271 4.741 33 020600b 09.11.23 24 136 297 2.184 553 2447 4.425 34 020600c 09.11.30 10 41 102 2.488 155 714 4.606 35 020700a 09.12.06 9 51 109 2.137 198 865 4.369 36 020700b 09.12.15 36 175 375 2.143 823 3784 4.598 37 020700c 09.12.22 15 86 180 2.093 347 1488 4.288 38 020800a 10.01.08 16 143 300 2.098 342 1293 3.781 39 020800b 10.01.12 22 52 110 2.115 347 1535 4.424 40 020800c 10.01.19 10 109 241 2.211 386 1850 4.793 41 020800d 10.01.25 29 165 385 2.333 518 2472 4.772 42 020900a 10.02.04 35 264 578 2.189 751 3211 4.276 43 020900b 10.02.20 13 117 248 2.120 291 1230 4.227 44 020900c 10.02.24 27 138 330 2.391 381 1788 4.693 45 021000a 10.03.10 26 203 443 2.182 500 2280 4.560 46 021000b 10.03.24 24 96 227 2.365 410 2057 5.017 47 021000c 10.03.25 12 58 129 2.224 201 866 4.308 48 021100a 10.04.01 23 145 387 2.669 428 2103 4.914 49 021100b 10.04.11 28 105 244 2.324 407 1845 4.533 50 021100c 10.04.20 25 156 324 2.077 408 1794 4.397 51 030000a 10.05.04 15 108 267 2.472 242 1017 4.202 52 030000b 10.05.21 25 91 202 2.220 316 1612 5.101 53 030000c 10.05.22 30 163 398 2.442 429 2095 4.883 54 030000d 10.05.29 8 90 195 2.167 150 476 3.173 55 030100a 10.06.01 26 211 566 2.682 436 1906 4.372 56 030100b 10.06.23 17 95 263 2.768 221 779 3.525 57 030100c 10.06.29 20 223 576 2.583 333 1238 3.718 58 030200a 10.07.06 18 122 350 2.869 328 1567 4.777 59 030200b 10.07.11 28 185 516 2.789 403 1747 4.335 60 030200c 10.07.15 15 116 421 3.629 208 1106 5.317 61 030200d 10.07.27 20 163 429 2.632 296 1289 4.355 62 030300a 10.08.17 10 91 229 2.516 181 881 4.867 63 030300b 10.08.22 40 321 854 2.660 638 2901 4.547 64 030300c 10.08.31 20 190 574 3.021 330 1511 4.579 65 030400a 10.09.11 15 131 512 3.908 270 1342 4.970
66 030400b 10.09.19 56 401 1307 3.259 831 4059 4.884
67 030500a 10.10.16 43 318 996 3.132 573 2892 5.047
68 030500b 10.10.31 25 285 1246 4.372 171 791 4.626
69 030600a 10.11.22 23 453 1798 3.969 431 2144 4.974
70 030600b 10.11.28 42 190 574 3.021 410 1898 4.629 71 030700a 10.12.19 18 142 599 4.218 193 1031 5.342
72 030700b 10.12.26 34 431 1391 3.227 768 3277 4.267
73 030800a 11.01.08 15 107 407 3.804 193 950 4.922 74 030800b 11.01.15 25 206 821 3.985 407 1490 3.661 75 030800c 11.01.29 45 316 978 3.095 717 3487 4.863 76 030900 11.02.06 30 257 822 3.198 493 2447 4.963
77 031000 11.03.04 40 406 1236 3.044 599 2660 4.441
Table 6 Details of the data collected from Yun (Utter.=Utterance, Morph.=Morphemes) File
Name
Recording date
Length (min)
Child Caretakers Utter. Morph. MLU Utter. Morph. MLU
1 020300a 09.02.16 21 100 223 2.230 291 1288 4.426 2 020300b 09.02.28 47 234 513 2.192 657 3108 4.731 3 020400a 09.03.06 15 51 133 2.608 161 883 5.484 4 020400b 09.03.14 17 83 188 2.265 183 916 5.005 5 020400c 09.03.20 16 58 137 2.362 215 1161 5.400 6 020400d 09.03.31 15 57 148 2.596 186 1073 5.769 7 020500a 09.04.06 15 50 146 2.920 157 979 6.236 8 020500b 09.04.20 30 103 278 2.699 368 1972 5.359 9 020500c 09.04.28 17 71 172 2.423 280 1434 5.121 10 020600 09.05.11 31 125 307 2.456 376 1822 4.846 11 020700a 09.06.04 30 140 348 2.486 386 2097 5.433 12 020700b 09.06.17 31 158 424 2.684 432 2133 4.938 13 020700c 09.06.26 30 135 355 2.630 391 1894 4.844 14 020800a 09.07.18 4 9 26 2.889 52 345 6.635 15 020800b 09.07.28 30 120 420 3.500 331 2021 6.106 16 020900a 09.08.11 30 151 455 3.013 311 2158 6.939 17 020900b 09.08.17 15 81 296 3.654 153 961 6.281 18 020900c 09.08.17 15 62 252 4.065 135 823 6.096 19 021000a 09.09.07 30 175 524 2.994 393 2098 5.338
20 021000b 09.09.21 35 164 479 2.921 467 2535 5.428 21 021100a 09.10.01 30 140 524 3.743 384 2132 5.552 22 021100b 09.10.07 35 115 313 2.722 397 2245 5.655 23 030000a 09.11.07 30 254 777 3.059 352 1644 4.670 24 030000b 09.11.25 30 140 383 2.736 369 2197 5.954 25 030100a 09.12.09 35 73 203 2.781 450 2760 6.133 26 030100b 09.12.23 35 153 414 2.706 398 2353 5.912 27 030200a 10.01.08 30 116 336 2.897 411 2410 5.864 28 030200b 10.01.25 35 134 475 3.545 381 2216 5.816
29 030300 10.02.03 60 353 1057 2.994 849 4403 5.186
30 030400 10.03.17 65 392 1253 3.196 789 4362 5.529
31 030500 10.04.28 65 549 2000 3.643 762 4186 5.493
32 030600a 10.05.25 65 430 1395 3.244 806 4645 5.763
33 030600b 10.05.31 35 175 548 3.131 348 1935 5.560 34 030700a 10.06.04 35 264 851 3.223 405 2036 5.027 35 030700b 10.06.15 35 159 517 3.252 318 1999 6.286
36 030800a 10.07.09 65 304 1256 4.132 684 4738 6.927
37 030800b 10.07.27 65 383 1585 4.138 544 3048 5.603
38 030900 10.08.20 60 257 975 3.794 700 5102 7.289
3. CHILDES
CHILDES is a corpus of first language acquisition data created by Brian MacWhinney and Catherine Snow in 1984, and is also the name of a project to build a system that operates the corpus. The project, which initially started with CHILDES, has evolved into a larger system called Talk Bank, a spoken language database. CHILDES is now being run as a part of Talk Bank. While “Talk Bank” mainly focuses on L1 acquisition, it also contains a collection of databases from a wide range of fields such as second language (L2) acquisition, bilingualism, language disorders, and sign language research.
CHILDES is composed of the following three components:
① Utterance database
② CHAT (Chat) transcription format
③ CLAN (language analysis program)
3.1 Utterance database
CHILDES (http://childes.psy.cmu.edu/) includes a database of utterances in approximately 40 languages (more than 50,000,000 words) as of 2018 (Fig. 4). The data include transcripts, audio and video data, as
20 021000b 09.09.21 35 164 479 2.921 467 2535 5.428 21 021100a 09.10.01 30 140 524 3.743 384 2132 5.552 22 021100b 09.10.07 35 115 313 2.722 397 2245 5.655 23 030000a 09.11.07 30 254 777 3.059 352 1644 4.670 24 030000b 09.11.25 30 140 383 2.736 369 2197 5.954 25 030100a 09.12.09 35 73 203 2.781 450 2760 6.133 26 030100b 09.12.23 35 153 414 2.706 398 2353 5.912 27 030200a 10.01.08 30 116 336 2.897 411 2410 5.864 28 030200b 10.01.25 35 134 475 3.545 381 2216 5.816
29 030300 10.02.03 60 353 1057 2.994 849 4403 5.186
30 030400 10.03.17 65 392 1253 3.196 789 4362 5.529
31 030500 10.04.28 65 549 2000 3.643 762 4186 5.493
32 030600a 10.05.25 65 430 1395 3.244 806 4645 5.763
33 030600b 10.05.31 35 175 548 3.131 348 1935 5.560 34 030700a 10.06.04 35 264 851 3.223 405 2036 5.027 35 030700b 10.06.15 35 159 517 3.252 318 1999 6.286
36 030800a 10.07.09 65 304 1256 4.132 684 4738 6.927
37 030800b 10.07.27 65 383 1585 4.138 544 3048 5.603
38 030900 10.08.20 60 257 975 3.794 700 5102 7.289
3. CHILDES
CHILDES is a corpus of first language acquisition data created by Brian MacWhinney and Catherine Snow in 1984, and is also the name of a project to build a system that operates the corpus. The project, which initially started with CHILDES, has evolved into a larger system called Talk Bank, a spoken language database. CHILDES is now being run as a part of Talk Bank. While “Talk Bank” mainly focuses on L1 acquisition, it also contains a collection of databases from a wide range of fields such as second language (L2) acquisition, bilingualism, language disorders, and sign language research.
CHILDES is composed of the following three components:
① Utterance database
② CHAT (Chat) transcription format
③ CLAN (language analysis program)
3.1 Utterance database
CHILDES (http://childes.psy.cmu.edu/) includes a database of utterances in approximately 40 languages (more than 50,000,000 words) as of 2018 (Fig. 4). The data include transcripts, audio and video data, as
well as L1 acquisition, bilingual, clinical, and narrative data. To download them, go to Database → Downloadable Transcripts from the CHILDES homepage and download them for free. Korean data can be found at Database → Downloadable Transcripts → East Asian → Korean.
Fig. 4 CHILDES project homepage
3.2 CHAT transcription format
CHAT is a transcription format. Transcripts made using this format must follow a certain CHAT style to enable them to be analyzed by CLAN (language analysis program). The following is a transcript example (Ryu-Copus, Jong021100b.cha).
0 @Loc: EastAsian/Korean/Ryu/Jong/021100b.cha 1 @PID: 11312/c-00042751-1
2 @Begin
3 @Languages: kor
4 @Participants: CHI Target_Child, MOT Mother, GMT Grandmother 5 @ID: kor|Ryu|CHI|2;11.00|male|||Target_Child|||
6 @ID: kor|Ryu|MOT|32;11.00|female|||Mother|||
7 @ID: kor|Ryu|GMT|59;06.00|female|||Grandmother|||
8 @Media: 021100b, video 9 @Date: 23-NOV-2010
10 @Comment: Ju-yeon Ryu coded on 4-OCT-2011
11 @Comment: 53min
12 *CHI: 흔들면 안 돼 이지윤 . ▶ 13 *MOT: 응 ? ▶
14 *CHI: 여기 흔들면 안 돼 . ▶ 15 *MOT: 지윤이한테 그러는 거야 ? ▶ 16 *CHI: 응 . ▶
17 *MOT: 우리 오늘 책 읽자 . ▶
18 *MOT: 무슨 책 읽고 싶어 종현아 봐봐 . ▶
19 *MOT: 종현이가 무슨 책 읽고 싶은가 골라 보세요 . ▶ 20 *MOT: 어떤 책 읽을까 ? ▶
21 *CHI: 응 이거 . ▶
22 *MOT: 이거 먼저 읽을 거야 ? ▶ 23 *CHI: 응 . ▶
…… (omitted)….. @End
―Header
Lines starting with @ are called headers and contain basic information about the file. @Begin is used when the data start and @End is used when it ends. @Loc indicates the file storage location, and @Languages indicates the language used. @PID is the backup number managed by the CHILDES server. When you provide data to CHILDES, you can get it from CHILDES. @Participants describes all speakers in a conversation. For example, CHI represents Target_Child, and MOT represents Mother. Speaker information (age, gender, etc.) is inserted with @ID. In particular, the target child’s age is described in the format “year; month. day”. Additional information is provided in @Comment. In the example given in this paper, I describe the date and time when the data were recorded (see @Date), as well as when the audio data were transcribed (translate, transcribe, code, and transliterate), with @Comment, in addition to the time recorded in the last @Comment.
―Independent tier (utterances)
Actual utterances are written in the independent tier in the following format, starting with an asterisk (*).
Asterisk(*) speaker utterance
*CHI: 여기 흔들면 안 돼 . ▶ colon tab space period video