An
Algorithm
for Simultaneous Band Reduction of
Two Dense
Symmetric
Matrices
Lei
\mathrm{D}\mathrm{u}^{1),2)}
Akira
Imakura1)
Tetsuya
\mathrm{S}\mathrm{a}\mathrm{k}\mathrm{u}\mathrm{r}\mathrm{a}\mathrm{i}^{1),2)}
1)
Faculty
ofEngineering,
Information andSystems, University
ofTsukuba, 305‐8573,
Japan
2)\mathrm{J}\mathrm{S}\mathrm{T}
CREST,
4‐1‐8Hon‐cho, Kawaguchi‐shi,
Saitama332‐0012,
Japan
Abstract
In thispaper, weproposean
algorithm
forsimultaneously reducing
twodensesymmetric
matrices to band form with the same bandwidthby
congruent
transformations. The simultaneous band reduction can be considered as an
extensionof the simultaneous
tridiagonalization
oftwo densesymmetric
ma‐trices. In contrast to
algorithms
of simultaneoustridiagonalization
that arebased on Leve1‐2 BLAS
(Basic
LinearAlgebra
Subroutine)
operations,
ourband reduction
algorithm
is devised to take fulladvantage
of Leve1‐3 BLASoperations
for betterperformance.
Numerical results arepresented
toillus‐tratethe effectiveness ofour
algorithm.
1
Introduction
Giventworeal
n‐by‐n
densesymmetric
matricesA,
B,weconsider the simultaneous bandreduction ofA and B via
congruent
transformations withrespect
to amatrixQ\in \mathbb{R}^{n\times n}
asfollows
K=Q^{T}AQ, M=Q^{T}BQ
,(1)
where K and M areband matrices with the same odd‐numbered bandwidth s.
It is well known that the band reduction ofa
single
densesymmetric matrix,
as apre‐processing
step,
iswidely applied
tocompute
thespectral
decomposition,
whichcanbe also used to solve shifted linear
systems
forexample.
Please refer to[3, 17]
andreferences therein formoredetails.
For a
pair
ofnonsymmetric
matrices A and B,algorithms
for different condensedforms have also been
proposed,
forexample algorithms
for theHessenberg‐triangular
form
[1,
4, 7,
12].
Considering
thesymmetry,
algorithms
for thetridiagonal‐diagonal
form have beenproposed
in[2,
11,
16].
Recently,
methods for thetridiagonal‐tridiagonal form,
simul‐taneous
tridiagonalization,
have beenproposed
in[6, 15]
by
congruent
transformations.Compared
with other condensedforms,
thetridiagonal‐tridiagonal
canbe obtained underaweak condition that the matrix
pencil
(A, B)
isregular.
Thecomplexity
of simultane‐ous
tridiagonalization
is\mathcal{O}(n^{3})
FLOPs. Inaddition,
thecomputations
are based ontheLeve1‐2 BLAS
operations.
In this paper, we propose an
algorithm
forsimultaneously reducing
two dense sym‐metric matrices toband form with the samebandwidth
by
congruent
transformations.In contrast tothe
algorithms
of simultaneoustridiagonalization
that are basedonLevel‐Leve1‐3 BLAS
operations
and able to achieve betterperformance.
The band reductioncan be also used as a
pre‐processing
step
forsolving problems
such as thegeneralized
eigenvalue problem
Ax= $\lambda$ Bx and thegeneralized
shifted linearsystems
(A+$\sigma$_{i}B)x=b
etc. Please refer to
[5,
8, 9, 10,
13]
foralgorithms
ofsolving
the band(tridiagonal)
gen‐eralized
eigenvalue problems.
Thepaperis
organized
asfollows. In the Section2,
webriefly study
theexisting
meth‐ods for simultaneous
tridiagonalization.
In Section3,
weempoly
thetridiagonalization
ideas and propose an
algorithm
for the simultaneous band reduction.Implementation
details will be discussed. In Section
4,
wegive
some numerical results to illustrate theeffectiveness ofour
algorithm. Finally,
wemakesomeconcluding
remarks andpoint
ourfuture work in Section 5.
Throughout
this paper thefollowing
notation is used. If the size of a matrix ora vector is
apparent
from the context withoutconfusion,
we willdrop
theindex,
e.g.,denotean
m‐by‐n
matrixA_{m\times n} by
A andann‐dimensionalvector x_{n}by
x. I willalways
represent
theidentify matrix,
A^{T}
denotes thetranspose
ofA. The Matlab colon notationis used. For
example,
theentry
ofA at the ith row andjth
column isA(i, j)
, the kthcolumn of A is A
k)
and A i :j
)
=[A(:, i), A i+1
)
,.. ., A j )]
is a sub‐matrixwith
j-i+1
columns.2
A brief review of the simultaneous
tridiagonaliza‐
tion
The simultaneous
tridiagonalization
of twosymmetric
matrices isfirstly
discussedby
Garvey
et al in[6].
ThenSidje
[15]
gavemore details onsimultaneoustridiagonalization
under a unified framework. In this
section,
webriefly study
their methods.For
simplicity,
welet n=8 and assumethat twoiterationsteps
oftridiagonalization
of A and B have been
complete,
whichgives A^{(2)}
andB^{(2)}
asfollows,
A^{(2)}=(/\backslash
andB^{(2)}=(**
***
*******
****** ****** ****** ******
******)
,where * denotes the nonzeroentries.
The third iteration
step
forA^{(3)}
andB^{(3)}
canbe describedby
thefollowing
two‐stage
computations.
Stage
1: ifA^{(2)}(
4 :8,
3)\neq $\alpha$ B^{(2)}(4
:8,
3)
for thegiven
scalar $\alpha$, then construct amatrix
L3
andcompute
\overline{A}^{(2)}=L_{3}^{T}A^{(2)}L_{3}, \overline{B}^{(2)}=L_{3}^{T}B^{(2)}L_{3}
to make\overline{A}^{(2)}(
4 :8,
3)=
Stage
2: construct a matrixH3
and letA^{(3)}=H_{3}^{T}\overline{A}^{(2)}H_{3}, B^{(3)}=H_{3}^{T}\overline{B}^{(2)}H_{3}
toeliminate nonzeroentires of
\overline{A}^{(2)}
(5
:8,
3)
and\overline{B}^{(2)}(5
:8,
3)
.Meanwhile,
there should be no fill‐in for all the zero entries(i, j)
, when|i-j|>1,
during
bothstages.
In thefollowing subsections,
webriefly
describe howto constructL3
and
H_{3}
. Please refer to[6, 15]
formore details.2.1
Stage
1: constructmatrix
L3
It is easy to check that
L3
with thefollowing
pattern
canalways
avoid fill‐in for thecomputations
\overline{A}^{(2)}=L_{3}^{T}A^{(2)}L_{3}
and\overline{B}^{(2)}=L_{3}^{T}B^{(2)}L_{3},
Theoretically,
allnonsingular
matrices could be chosen for the sub‐blockL_{3}(4:8,4
:8).
Inpractice,
various rank‐oneupdates
have beengiven
in[6, 15],
whereL_{3}(3
:8,
3 :8)=I_{6}+[0, x^{T}]^{T}[1, y^{T}]
. In order to make\overline{A}^{(2)}(4
:8,
3)
and\overline{B}^{(2)}(4
:8,
3)
be collinear(the
corresponding
\otimes entiresi.e.,
\overline{A}^{(2)}(4:8,3)= $\alpha$\overline{B}^{(2)}(4:8,3)
,\displaystyle \bigotimes_{\otimes}^{*}\otimes\otimes\otimes*
\displaystyle \bigotimes_{*}****
\displaystyle \bigotimes_{*}**** \displaystyle \bigotimes_{*}**** \displaystyle \bigotimes_{*}****
\displaystyle \bigotimes_{*}****)
the unknownvector x can be
efficiently
determined asfollows[1, x^{T}]^{T}=\displaystyle \frac{(A^{(2)}(3:8,3:8)- $\alpha$ B^{(2)}(3:8,3:8))^{-1}e_{1}}{e_{1}^{ $\tau$}(A(2)(3:8,3:8)- $\alpha$ B(2)(3:8,3:8))^{-1}e_{1}}
.(2)
Moreover the solution is also
unique.
To avoidsolving
the linearsystem
for x periteration and reduce the total
computation cost,
apractical approach
isgiven
in[6].
Only
the LDL^{}
decomposition
ofA- $\alpha$ B or its inverseneeds to becomputed
in\mathcal{O}(n^{3})
operations.
In thefollow‐up
steps,
x can beefficiently computed by using
the LDL^{}
orits inverse in
\mathcal{O}(n^{2})
operations.
Although
x is determineduniquely,
there are different choices for y. Here we recall(i)
y=0
corresponding
toL_{3}(4
:8,
4:8)=I
;(ii)
Determineyby letting
\overline{A}^{(2)}(4:8,3)= $\sigma$ e_{1}
;(iii)
y=-(1+\sqrt{1+\Vert x\Vert_{2}^{2}})x/\Vert x\Vert_{2}^{2}
by minimizing
the condition number ofL3;
(iv)
y=-2x/\Vert x\Vert_{2}^{2}
;Remark 2.1. For thecase
(ii),
thecomputation
ofstage
2 willnot be neededfortridiag‐
onalization.
2.2
Stage
2: constructmatrix
H3
When the
stage
1 iscomplete,
it is easy tosimultaneously
eliminate thenonzero entiresof
\overline{A}^{(2)}
(5
:8,
3)
and\overline{B}^{(2)}(5
:8,
3)
. Forexample,
a Householder transformationH3
asfollows canbe
applied
to both\overline{A}^{(2)}
and\overline{B}^{(2)}.
H_{3}=\left(1 & 1 & 1 & I & -2uu^{T}\right),
where u is an unit vector and is determined
by \overline{A}^{(2)}
(4
:8,
3).
Then we can obtainA^{(3)}=H_{3}^{T}\overline{A}^{(2)}H_{3}
andB^{(3)}=H_{3}^{T}\overline{B}^{(2)}H_{3}
asfollows,
A^{(3)}=(/\backslash
andB^{(3)}=(**
*** ***
******
***** ***** *****
*****)
Wecan continuethe
two‐stage
computations
recursively
untiltwotridiagonal
matri‐ces are obtained. For the
general
case, we describe the simultaneoustridiagonalization
procedure
inAlgorithm
1.Remark 2.2. In
steps
5,
7 and8,
matrixupdates
likeM=(I+uv^{T})^{T}M(I+uv^{T})
are
needed,
where M is amatrix,
u and v are vectors. Leve1‐2 BLAS such asDSYR,
DSYR2,
DSYMVcan be used forupdating
M.From discussions
above,
we see thealgorithm
of simultaneoustridiagonalization
hasthe
following disadvantages.
Complexity
of thealgorithm
is order ofn^{3}
flops
;\overline{\frac{\mathrm{A}1\mathrm{g}\mathrm{o}\mathrm{r}\mathrm{i}\mathrm{t}\mathrm{h}\mathrm{m}1\mathrm{P}\mathrm{s}\mathrm{e}\mathrm{u}\mathrm{d}\mathrm{o}\mathrm{c}\mathrm{o}\mathrm{d}\mathrm{e}\mathrm{o}\mathrm{f}\mathrm{s}\mathrm{i}\mathrm{m}\mathrm{u}1\mathrm{t}\mathrm{a}\mathrm{n}\mathrm{e}\mathrm{o}\mathrm{u}\mathrm{s}\mathrm{t}\mathrm{r}\mathrm{i}\mathrm{d}\mathrm{i}\mathrm{a}\mathrm{g}\mathrm{o}\mathrm{n}\mathrm{a}1\mathrm{i}\mathrm{z}\mathrm{a}\mathrm{t}\mathrm{i}\mathrm{o}\mathrm{n}}{1:\mathrm{G}\mathrm{i}\mathrm{v}\mathrm{e}\mathrm{n}\mathrm{t}\mathrm{w}\mathrm{o}n-\mathrm{b}\mathrm{y}-n\mathrm{s}\mathrm{y}\mathrm{m}\mathrm{m}\mathrm{e}\mathrm{t}\mathrm{r}\mathrm{i}\mathrm{c}\mathrm{m}\mathrm{a}\mathrm{t}\mathrm{r}\mathrm{i}\mathrm{c}\mathrm{e}\mathrm{s}A,B,\mathrm{a}\mathrm{n}\mathrm{d}\mathrm{s}\mathrm{c}\mathrm{a}1\mathrm{a}\mathrm{r} $\alpha$;1\mathrm{e}\mathrm{t}Q=I;}}
2:
Compute
the LDL^{}
ofA- $\alpha$ B or inverse N:=(A- $\alpha$ B)^{-1}
;3: for k=1 :n-2 do
4:
Compute
x and y forL_{k}
; \triangleright \mathrm{L}\mathrm{e}\mathrm{v}\mathrm{e}\mathrm{l}-2 BLAS5:
Compute
\overline{A}^{(k-1)}
and\overline{B}^{(k-1)}
; \triangleright \mathrm{L}\mathrm{e}\mathrm{v}\mathrm{e}\mathrm{l}-2 BLAS6:
Compute
u forH_{k}
; \triangleright \mathrm{L}\mathrm{e}\mathrm{v}\mathrm{e}\mathrm{l}-2 BLAS7:
Compute
A^{(k)}
andB^{(k)}
; \triangleright \mathrm{L}\mathrm{e}\mathrm{v}\mathrm{e}\mathrm{l}-2 BLAS8:
Update
N andQ=QL_{k}H_{k}
;(if
necessary)
\triangleright \mathrm{L}\mathrm{e}\mathrm{v}\mathrm{e}\mathrm{l}-2 BLAS9: end for
Weknow that almost all modern
computers
have thestructure ofmemoryhierarchy.
Computation
timeofanalgorithm mainly depends
onthe arithmeticoperations
(FLOPs)
and data movement
(memory access).
A basic rule fordevising
fastalgorithms
is toreduce memory access as more as
possible.
The ratios of FLOPs to memory accesscorresponding
todifferent leveloperations
aregiven
in Table 1.Table 1: Ratios of arithmetic
operations
to memory access. Denote $\alpha$,$\beta$\in \mathbb{R},
x,y\in \mathbb{R}^{n}
and
A, B,
C\in \mathbb{R}^{n\times n}.\displaystyle \frac{\mathrm{F}\mathrm{L}\mathrm{O}\mathrm{P}\mathrm{s}\mathrm{m}\mathrm{e}\mathrm{m}\mathrm{o}\mathrm{r}\mathrm{y}\mathrm{a}\mathrm{c}\mathrm{c}\mathrm{e}\mathrm{s}\mathrm{s}\mathrm{R}\mathrm{a}\mathrm{t}\mathrm{i}\mathrm{o}}{y= $\alpha$ x+y(\mathrm{L}\mathrm{e}\mathrm{v}\mathrm{e}1-1)2n3n2/3}
y= $\alpha$ Ax+ $\beta$ y
(Leve1‐2)
2n^{2}
n^{2}
2C= $\alpha$ AB+ $\beta$ C
(Leve1‐3)
2n^{3}
4n^{2}
n/2
From Table
1,
wesee that analgorithm
that is abletoimplemented by higher
levelBLAS
operations
maybe
show betterperformance,
whichinspires
us to extend the tridi‐agonalization algorithm
and devise a newalgorithm
that can takeadvantage
of theLeve1‐3 BLAS
operations.
3
An
algorithm
for simultaneous band reduction
In this
section,
we extend the ideas in Section 2 and propose analgorithm
for simulta‐neous band reduction. Similarto the simultaneous
tridiagonalization,
thecomputations
of band reduction will be also divided two
stages.
We first processt(t :=(s-1)/2
hereafter)
steps
like thestage
1 ofAlgorithm
1 tomaketpairs
ofvectors collinear. Thenwe continue to do t
steps
like thestage
2 ofAlgorithm
1 to eliminate theoff‐diagonal
nonzeroentries for all
|i-j|>t.
As there are different variants for simultaneous
tridiagonalization,
in whatfollows,
our
strategy
of band reduction ismainly
based on the first variant that y= O. Forsimplicity,
we take t=2 and discuss the twostages
of simultaneous band reduction asAssuming
thattwosteps
of band reduction of A and B have beencomplete.
MatricesA^{(1)}
andB^{(1)}
obtained are asfollows,
3.1
Stage
1: constructmatrix
L_{2}
The aim of this
stage
is to construct amatrixL_{2}
which makes tpairs
ofvectors corre‐sponding
to\overline{A}^{(1)}
:=L_{2}^{T}A^{(1)}L_{2}
and\overline{B}^{(1)}
:=L_{2}^{T}B^{(1)}L_{2}
arecollinear. When t=2, we canconstruct
L_{2}
asfollows,
The unknown entries of
L_{2}^{(1)}
andL_{2}^{(2)}
aredeterminedby
the similarstrategy
in section2.1. Wenote that the unknown entries of
L_{2}^{(2)}
will be determined after that ofL_{2}^{(1)}.
Applying
L_{2}^{(1)}
andL_{2}^{(2)}
toA^{(1)}
successively,
wecould obtain thefollowing
twomatriceswith thesame
pattern,
respectively.
Thenonzeroentries denoted\mathrm{b}\mathrm{y}\otimes
arewhatwe careabout.
and
\displaystyle \overline{A}^{(1)}=L_{2}^{(2)T}\overline{A}^{(1)}L_{2}^{(2)}=(*** **** \otimes\otimes\bigotimes_{\otimes}^{\otimes***} \otimes\otimes\bigotimes_{\otimes}^{\bigotimes_{*}^{*}} \bigotimes_{*}^{\otimes}*** \bigotimes_{*}^{\otimes}*** \bigotimes_{*}^{\otimes}*** \bigotimes_{*}^{\otimes}***)
Similarto
\overline{A}^{(1)}
,we canalso obtain\overline{B}^{(1)}
.Congruent
transformationsby
L_{2}^{(1)}
make\overline{A}^{(1)}(4
:8,
3)
and\overline{B}^{(1)}(4:8, 3)
be collinear.Congruent
transformationsby
L_{2}^{(2)}
make\overline{A}^{(1)}(5:8, 4)
andB^{(1)}(5:8,4)-
be collinear andkeep
thecollinearity
of\overline{A}^{(1)}(4:8,3)
and\overline{B}^{(1)}(4:8,3)
.3.2
Stage
2:
constructmatrix
H_{2}
In this
stage,
we eliminate nonzero entries of\overline{A}^{(1)}
and\overline{B}^{(1)}
in columns 3 and 4 forthe band form. We construct the matrix
H_{2}
asfollows,
aproduct
of two Householdermatrices
H_{2}^{(1)}
andH_{2}^{(2)},
where u_{4} and u_{3} can be determined
by
\overline{A}^{(1)}
(5
:8,
3 :4).
Then we can obtainA^{(2)}=
H_{2}^{T}\overline{A}^{(1)}H_{2}
andB^{(2)}=H_{2}^{T}\overline{B}^{(1)}H_{2}.
As the
product
ofH_{2}^{(1)}
andH_{2}^{(2)}
can berepresented
as followsby
thecompact
WYrepresentation
[14],
H_{2}=\left(1 & 1 & 1 & 1 & I-VTV^{T}\right),
where V is a 4 \mathrm{x}2
matrix,
and T denotes a 2\times 2 uppertriangular
matrix. Inpractice,
sub‐matrices
A^{(2)}
(5
:8,
5 :8)
andB^{(2)}(5
:8,
5 : 8)
can beeffectively computed by
thisrepresentation,
Leve1‐3 BLASsuch as \mathrm{D}\mathrm{S}\mathrm{Y}\mathrm{R}2\mathrm{K}, DSYMM canbeemployed.
We summarize discussion above and
give
thepseudocode
of band reduction inAlgo‐
rithm 2.
Remark 3.1. If s=3,
Algorithm
2 is consistent with theAlgorithm
1corresponding
tovariant
(i).
We note that thestrategy
discussed in this section can be alsoapplied
to\displaystyle \frac{\mathrm{A}1\mathrm{g}\mathrm{o}\mathrm{r}\mathrm{i}\mathrm{t}\mathrm{h}\mathrm{m}2\mathrm{P}\mathrm{s}\mathrm{e}\mathrm{u}\mathrm{d}\mathrm{o}\mathrm{c}\mathrm{o}\mathrm{d}\mathrm{e}\mathrm{o}\mathrm{f}\mathrm{b}\mathrm{a}\mathrm{n}\mathrm{d}\mathrm{r}\mathrm{e}\mathrm{d}\mathrm{u}\mathrm{c}\mathrm{t}\mathrm{i}\mathrm{o}\mathrm{n}}{1:\mathrm{G}\mathrm{i}\mathrm{v}\mathrm{e}\mathrm{n}\mathrm{s}\mathrm{y}\mathrm{m}\mathrm{m}\mathrm{e}\mathrm{t}\mathrm{r}\mathrm{i}\mathrm{c}\mathrm{m}\mathrm{a}\mathrm{t}\mathrm{r}\mathrm{i}\mathrm{c}\mathrm{e}\mathrm{s}A,B,Q=I\mathrm{a}\mathrm{n}\mathrm{d}\mathrm{s}\mathrm{c}\mathrm{a}\mathrm{l}\mathrm{a}\mathrm{r} $\alpha$;}
2: Given bandwidth s, let
t=(s-1)/2
;3:
Compute
the LDL^{}
ofA- $\alpha$ B or inverse N:=(A- $\alpha$ B)^{-1}
; \trianglerightInverse4: for
k=1:\displaystyle \mathrm{L}\frac{n-t}{t}\rfloor
do5: for
i=(k-1)t+1
: kt do6:
Compute
x_{n-i} forL_{k}^{(i-(k-1)t)}
; \triangleright \mathrm{L}\mathrm{e}\mathrm{v}\mathrm{e}\mathrm{l}-2 BLAS7:
Compute
\overline{A}^{(k)}(:, i)
and\overline{B}^{(k)}(:, i)
; \triangleright \mathrm{L}\mathrm{e}\mathrm{v}\mathrm{e}\mathrm{l}-2 BLAS8:
Update
N andQ=QL_{k}^{(i-(k-1)t)}
;(if
necessary)
\triangleright \mathrm{L}\mathrm{e}\mathrm{v}\mathrm{e}\mathrm{l}-2 BLAS9: end for
10:
Compute
theQR decomposition
of\overline{A}(kt+1 : n, (k-1)t+1 : kt)
and
compact
WY‐representation
ofH_{k}
; \triangleright \mathrm{L}\mathrm{e}\mathrm{v}\mathrm{e}\mathrm{l}-2 BLAS11:
Compute
A^{(k)}=H_{k}^{T}A^{(k-1)}H_{k}
; \triangleright \mathrm{L}\mathrm{e}\mathrm{v}\mathrm{e}\mathrm{l}-3 BLAS12:
Compute
B^{(k)}=H_{k}^{T}B^{(k-1)}H_{k}
; \triangleright \mathrm{L}\mathrm{e}\mathrm{v}\mathrm{e}\mathrm{l}-3 BLAS13:
Update
N andQ=QH_{k}
;(if necessary)
\triangleright \mathrm{L}\mathrm{e}\mathrm{v}\mathrm{e}\mathrm{l}-3 BLAS14: end for
4
Numerical
experiments
Inthis
section,
wegive
somenumerical results to show theperformance
of theproposed
algorithm.
We alsoapply
thealgorithm
forsolving generalized
shifted linearsystems.
Test matriceswere initialized
by
random values andtwodifferent sizes(n=1000, 3000)
.The
computer
specifications
are Red HatLinux,
AMDOpteron(tm)
processor, 2.5\mathrm{G}\mathrm{H}\mathrm{z}(1 core)
with 32\mathrm{G}\mathrm{B} of RAM. Thealgorithm
wasimplemented
inthe Fortran 90language
and
compiled
with ifort(ver.
13.1.1)
using
the Intel MKL for LAPACK and BLAS. Inthe
implementation,
we didnotcompute
theQ explicitly,
but the inverse of A- $\alpha$ B.In
Figure
1,
we compare thecomputation
time of band reductioncorresponding
toAlgorithm
2withdifferent bandwidth. Weseethat the totalcomputation
time isreducedwith
greater
bandwidth.Compared
with s=3, thealgorithm
took less than half timewhen s=17. In
Figure
2, symmetric
band linearsystems
Kx=bweresolvedby calling
the
Lapack
function DGBSV. Thecomputation
timealmost increasedlinearly
with theincreasing
of bandwidth. We alsocomputed
the solution ofgeneralized
shifted linearsystems
(A+$\sigma$_{i}B)x=b
for i=1,2,
...,Lby using
band reduction and DGBSV. Thetotal
computation
time is denotedby
T_{total} :=T_{bandreduction}+L\cdot T_{DGBSV}
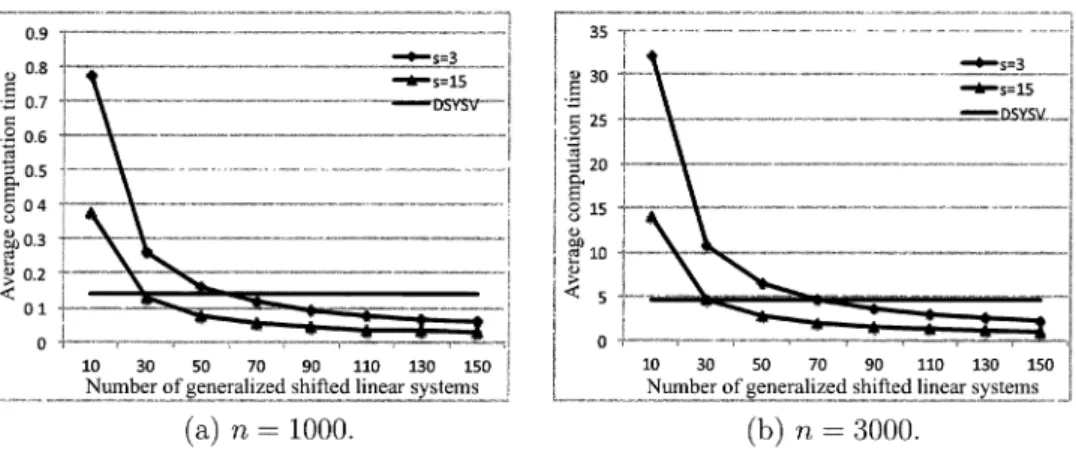
. InFigure
3,
we show the average
computation
time for one linearsystem,
i.e.,
T_{total}/L
.Compared
to
DSYSV,
band reduction shows itsadvantages
when the bandwidths and number ofshifted linear
systems
L aregreater.
5
Conclusions and future work
In this paper, we
proposed
analgorithm
for simultaneous band reduction oftwo densesymmetric
matrices.Although
our discussions are based on real‐valuedmatrices,
thealgorithm
can beeasily
extended tocomplex‐valued
Hermitian matrices. We also gave(a)
n=1000.(b)
n=3000.Figure
1:Computation
timeof band reduction(in seconds)
versus matrix bandwidth.(a)
n=1000.(
\mathrm{b})
n=3000.Figure
2:Computation
time of band linearsystems
(in seconds)
versus matrix band‐width.
(a)
n=1000.(
\mathrm{b})
n=3000.Figure
3:Average
computation
time per linearsystem
(in seconds)
versus the numberwidth andan
application
ofsolving generalized
shifted linearsystems.
The
topics,
suchasother
algorithms
for bandreduction,
simultaneously
reduce band formtotridiagonal form,
accelerate the
computing using
GPUetc.,
will be considered as our future work.
Acknowledgments
This research was
partially supported by Strategic Programs
for Innovative Research(SPIRE)
Field 5 (Theorigin
of matterand theuniverse,
JST/CREST
project
Devel‐opment
ofanEigen‐Supercomputing Engine using
aPost‐Petascale Hierarchical Modeland KAKENHI
(Nos.
25870099,
25104701,
25286097).
References
[1]
B.Adlerborn,
K. Dackland and B.Kagström,
Parallel and BlockedAlgorithms
for Reduction ofa
Regular
Matrix PairtoHessenberg‐Triangular
and GeneralizedSchur
Forms,
inApplied
ParallelComputing,
Lecture Notes inComput.
Sci.2367,
Springer, Berlin, Heidelberg,
757-767(2006)
.[2]
M.A.Brebner,
and J.Grad, Eigenvalues
ofAx = $\lambda$ Bx for RealSymmetric
MatricesA and B
Computed by
Reduction toaPseudosymmetric
Formand the HRprocess,Linear
Algebra Appl.,
43,
99-118(1982)
.[3]
C.H.Bischof,
B.Lang
and X.B.Sun,
A framework forsymmetric
bandreduction,
ACM Trans. Math.
Software,
26(4), 581-601(2000)
.[4]
K. Dackland and B.Kagström,
Blockalgorithms
and software for reduction of aregular
matrixpair
togeneralized
Schurform,
ACM Trans. Math.Software,
25(4),
425-454(1999)
.[5]
L.Elsner,
A. Fasse and E.Langmann,
Adivide‐and‐conquer
methodfor thetridiago‐
nal
generalized eigenvalue problem,
J.Comput. Appl. Math.,
86(1),
141-148(1997)
.[6]
S.D.Garvey,
F.Tisseur,
M.I.Friswell,
J.E.T.Penny
and U.Prells,
Simultaneoustridiagonalization
of twosymmetric matrices,
Int. J. Numer. Meth.Eng.,
57(12),
1643-1660(2003)
.[7]
B.Kagström,
D.Kressner,
E.S.Quintana‐ortí
and G.Quintana‐ortí,
Blockalgo‐
rithmsfor the reductionto
Hessenberg‐triangular
formrevisited,
BIT Numer.Math.,
48(3), 563-584(2008)
.[8]
L.Kaufman,
AnAlgorithm
for the BandedSymmetric
Generalized MatrixEigen‐
[9]
K.Li,
T.Y. Li and Z.Zeng,
Analgorithm
for thegeneralized
symmetric
tridiagonal
eigenvalue problem,
Numer.Algorithms,
8(2), 269-291(1994)
.[10]
K.Li,
Durand‐Kernerroot‐finding
method for thegeneralized tridiagonal eigen‐
problem,
Missouri J. Math.Sci.,
33-43(1999)
.[11]
R.S. Martin and J.H.Wilkinson,
Reduction of thesymmetric
eigenproblem
Ax =$\lambda$ Bx and related
problems
tostandardform,
Numer.Math.,
11(2), 99-110(1968)
.[12]
C.B. Moler and G.W.Stewart,
Analgorithm
forgeneralized
matrixeigenvalue prob‐
Iems,
SIAM J. Numer.Anal.,
10(2), 241-256(1973)
.[13]
G. Peters and J.H.Wilkinson, Eigenvalues
of Ax = $\lambda$ Bx with bandsymmetric
Aand
B,
Comput. J.,
12(4), 398-404(1969)
.[14]
R. Schreiber and C. vanLoan,
Astorage‐efficient
WYrepresentation
forproducts
of householder
transformations,
SIAMJ. Sci. Stat.Comput.,
10(1),
52-57(1989)
.[15]
R.B.Sidje,
On the simultaneoustridiagonalization
oftwosymmetric
matrices,
Nu‐mer.
Math.,
118(3),
549-566(2011)
.[16]
F.Tisseur, Tridiagonal‐diagonal
reduction ofsymmetric
indefinitepairs,
SIAM J.Matrix Anal.