個体を観察単位としたコーパス分析の有効性
著者
森 秀明
雑誌名
文化
巻
84
号
1,2
ページ
121-133
発行年
2020-10-31
URL
http://hdl.handle.net/10097/00129709
令和 2 年 10 月 31 日発行
個体を観察単位としたコーパス分析の有効性
個体を観察単位としたコーパス分析の有効性
森 秀 明
1.研究の目的 コーパスを使用した研究では、コーパスを構成している出版媒体ごとのグルー プや日本語学習者の習熟度別のグループなどの集団で頻度を集計し、その頻度を 比較する分析がよく行われている。例えば『現代日本語書き言葉均衡コーパス』 (Balanced Corpus of Contemporary Written Japanese:BCCWJ,山崎誠(編), 2014)を使用した助詞の研究では、宮内(2012)、丸山(2015)などの研究があ る。これらの研究では、レジスター(以下、本稿では媒体と呼ぶ1)ごとに単語 頻度を集計して比較し、媒体ごとの助詞の使い方の特徴がまとめられている。学 習者コーパスの『KYコーパス』(鎌田,2006)を使用した研究では、山内(2009, 2015)などの研究がある。これは、学習者の習熟度別に集計した機能語の頻度を 比較し、日本語教育における初級シラバスを再考した研究である。 これに対し、森(2017,2018)では、媒体や学習者の習熟度別で集計した単 語頻度は、ある媒体にどのような文書2がどのように分布しているかや、ある 学習者グループにどのような学習者がどのように分布しているかなどによって 決まるため、集団を構成している個々の文書や学習者を観察単位として分析す る方法が有効であることを指摘した。前者は集団レベル、後者は個体レベルの 分析である。 本稿の目的は、集団を観察単位とした分析では、後に述べる生態学的誤謬を 犯す危険性があるため、これまで広く行われてきた集団レベルの分析に替え 1 BCCWJは、国立国語研究所によって 2011 年に公開された約 1 億語のコーパスで ある。BCCWJ では、書籍、新聞、白書などの媒体別に集積されているデータの 種類をレジスター(言語使用域)と呼んでいるが(山崎誠(編),2014: 23)、本 稿では一般的な区分がイメージしやすいようにこれを媒体と呼ぶ。 2 本稿では、BCCWJ におけるサンプル ID 別のテキストを「文書」と呼ぶ。て、個体レベルの分析を行う方が有効であることを主張することにある。ただ し、個体レベルの分析を行ったとしても、分割相関を見逃すことによって新 たな誤謬を犯す危険性があるため、どのような場合に群を分割して分析する べきなのかについて、BCCWJ の分析例と大規模な学習者コーパスである『多 言語母語の日本語学習者横断コーパス』(International Corpus of Japanese as a Second Language:I-JAS,迫田(編),2016)の分析例とを比較して検討する。 次の第 2 節では、先行研究の例を引いて、生態学的誤謬と分割相関という概 念の説明を行う。第 3 節では、BCCWJ を使用して、名詞と格助詞「の」の頻度 で相関分析を行い、これらの誤謬が起きる例を示す。第 4 節では I-JAS を使用し て、日本語能力テストの得点と接続助詞「と」の頻度で相関分析を行い、ここ でも同様に生態学的誤謬が生じることを確認する。ただし、この分析の場合、 日本語能力別の群ごとに分割相関を分析するべきかどうかを再検討し、分割相 関についての理解を深める。最後に第 5 節で、まとめと今後の課題を述べる。 2.生態学的誤謬と分割相関の説明 生態学的誤謬は Robinson(1950)によってはじめて指摘され、社会学や政 治学の分野で多くの議論を巻き起こした(森,1987: 23;北居,2014: 133;清 水,2014: 1-2)。Robinson(1950)が取り上げたのは黒人の人口比率と文盲率 などの相関で、これを地域別に集計したデータ(生態学的データ)で分析する と高い相関があるのに(図 1)、黒人や白人などの人間を観察単位にした個人 データで分析すると低い相関しか見られない例などを挙げ(表 1)、相関分析 においてカテゴリーの合計値や平均値、比率などの生態学的データを使用して 個体レベルの関係を推測する危険性を指摘した。 図 1 黒人比率と文盲率の散布図(Robinson(1950: 338)図 1より引用) 表 1 人種と文盲のクロス表 (Robinson(1950: 338)表 1より引用)
図 1は、アメリカの九つの地域の黒人比率と文盲率を使用して描いた散布図 で、ピアソンの積率相関係数は =.946 と高い。表 1 は、図 1 と同様の分析を 個体レベルで行った分析で、クロス表に使用されているのは人数である。この クロス表から計算された四分点相関係数φは、数学的には積率相関係数 と同 じ意味を持つ。個体レベルで分析すると、黒人と文盲率にはφ =.203 という低 い相関しか見られない。図 1 の集団レベルの分析結果から、「黒人は文盲率が 高い」という個体レベルの推論を行うのは誤りである。黒人が住んでいる地域 の文盲率が高いからといって、黒人自体の文盲率が高いわけではない。このよ うに地域で集約された割合のような生態学的データ(集団レベルのデータ)の 相関に基づいて個体レベルの推論を行った結果、誤った推測を犯してしまうこ とを生態学的誤謬という。 生態学的誤謬と同様に、相関分析で注意するべき現象に分割相関がある。次 の引用は、森・吉田(1990: 228)による分割相関の説明である。 各ケースをいくつかの群に分けた時に,いずれか一方または両方の 平均値や,両変数間の関係が,群間で異なっている場合(図 5-1-7) には,一般に群ごとに両者の関係を吟味する必要がある。このよう な群(層)別の相関を,分割相関(split correlation)または層別相関 (stratified correlation)という。 (森・吉田,1990: 228) 森・吉田(1990: 228)図 5-1-7より一部引用。平均値の印と直線は筆者が加えた。 図 2 分割相関の例 (a) (b)
図 2の(a)は、数学の成績と英語の成績の相関散布図の概念図である。男女 別で見ると、この二つの成績には相関があるが、男子生徒には数学の成績がよ い生徒が多く、女子生徒には英語の成績がよい生徒が多いため、男女を合わせ た全体では無相関になっている。男子と女子の平均値で回帰直線を描くと、負 の相関が現れる。直線(負の相関)と全体(無相関)の関係が生態学的誤謬、 全体(無相関)と男女別の楕円(正の相関)の関係が分割相関である。分割相 関による誤謬は、個体レベルで相関関係を観察しているものの、その個体を適 切な群に分割しないで全体で分析した結果、有効ではない分析結果となる誤謬 である。 (b)は、身長と計算力の相関を小学 3 年生から 6 年生のデータを使って描い たグラフである。一般に、身長と計算力に相関があるとは考えにくいが、学年 が上がるにつれて身長は高くなり、同時に計算力も上がっていくため、学年を またいで分析すると相関が現れる。 しかし、身長も計算力も一定の範囲に限定される同学年に分割して相関を求 めると、それぞれの学年では無相関となる。(b)の場合は、学年の平均値で描 いた回帰直線と、学年を混合した相関の傾向は一致しており、狭い意味での生 態学的誤謬には当たらないが、分割相関を見過ごして分析を行った結果、身長 と計算力に相関があると考えると不適切な推論となる。 3.生態学的誤謬と分割相関の例 1:BCCWJ の場合 第 2 節の例のように集団レベルの分析だけを行った場合、生態学的誤謬を犯 したり、分割相関に気づかないまま誤った推論を犯す可能性がある。これは、 コーパスを使用した言語分析においても、十分に起こりうる危険性である。本 節では BCCWJ 固定長・長単位を使用して名詞と格助詞「の」の頻度で相関分析 を行い、これらの誤謬が起きる例を示す。 丸山(2015)では名詞と「の」の関係について簡易的な分析が行われ、白書 は名詞が多いことから「の」が多くなるという推論が述べられている(丸山, 2015: 139)。「の」は、「コーパスの研究」のように、体言と体言をつなげる助詞 であるため、体言(名詞)が多くなれば、「の」の頻度も多くなるのは、ごく妥 当な推論のように思われる。 表 2は丸山(2015)と同様の分析を行った分析結果である。調整頻度は 1 文 書当たりの語数に近い 500 語当たりの頻度で調整している。表 2 の名詞と「の」
の調整頻度を見ると、最も名詞が少ない図書館書籍から白書にかけて徐々に頻 度が増加し、これに連動して「の」の頻度も基本的に増加している様子がうか がえる。 これを散布図で確認すると図 3 のように高い相関がある( =.844, =3, =.072)。 はピアソンの積率相関係数、 は自由度、 は 値である。図 3 の 集団レベルの結果では丸山(2015)の記述は支持される。しかし、図 4 のよう に白書単体で個体レベルの相関分析を行うと、名詞と「の」の相関係数は( =.021, =1,498, =.441)と無相関になる3。 表 2 BCCWJ 固定長・長単位における名詞と格助詞「の」の頻度 図 3 名詞と「の」の相関:媒体平均値 図 4 名詞と「の」の相関:白書 3 図 4の の 値は, = 441 で非有意であった。相関係数の検定は =0 を帰無仮 説としているため,これを棄却できないということは実質的に無相関であること を意味している。
個体レベルで分析すると、白書は名詞が多いことから「の」が多くなるわけ ではない。図書館書籍や雑誌に比べて、白書の平均値で名詞や「の」頻度が高 いことは事実だが、白書の文書を一つ一つ見ると、名詞が多く使われているか らといって「の」が多く使われているとは限らない。図 4 の白書では、多種多 様な文書が存在しており、名詞と「の」の間に何らかの関連性を見出すことは 困難である。 「の」は、先に述べたように「体言+の+体言」の形で使用されるため、名詞 に連動して「の」が増えるのはごく当然のように思われる。しかも図 3 のよう に媒体間で明瞭な傾向性を持っている場合は、個体レベルでも名詞と「の」の 関連性を推測したくなる。しかし、このように当然と思われる現象でも、個別 に分析してみるまで本当の状態は分からない。図 5 ∼図 8 は図書館書籍、出版 書籍、雑誌、新聞を対象に、名詞の個別調整頻度と「の」の個別調整頻度で描 いた散布図である。 図 5 名詞と「の」の相関:図書館書籍 図 7 名詞と「の」の相関:雑誌 図 6 名詞と「の」の相関:出版書籍 図 8 名詞と「の」の相関:新聞
これらの中で中程度の相関を示すのは図書館書籍( =.591, =10,549, =0)、 出 版 書 籍( =.545, =10,115, =0)、 新 聞( =.329, =1,471, =0)の 3 媒体で、雑誌( =.202, =1,994, =0)にはそれほど相関がない。 次の図 9 は白書を含めた 5 媒体から各 1,400 文書を再サンプリングし、合計 7,000 文書で描いた散布図である。5媒体を混合して個体レベルで分析した図9の場合、 相関は( =.480, =6,998, =0)で、図 3 の集団レベルの相関係数の =.844 から半分程度の =.480 に下がる。集団レベルの相関の強さから、個体レベルで も同程度の相関の強さを持っていると考えると生態学的誤謬を犯すことになる。 しかし、この例の場合、データの性質が異なる媒体を混合して図 9 のような 分析を行うこと自体が、不適切な分析になっている。図 10 は分割相関が分か りやすいように、媒体数を三つに絞って描いた図である。図 9 のように媒体を 混合して全体で分析すると相関が見られるが、これは適切な分析ではない。図 10のように群ごとに分けて描くと、群ごとに異なった性質を持っていること が分かる。特に図 10 で、白丸で示した白書では、先に図 4 で確認したとおり ( =.021, =1,498, =.441)と無相関になる。 図 3のように集団レベルで相関分析を行った結果、白書などの個体でも同程 度の相関があると考えるのは生態学的誤謬、図 9 のように個体レベルの分析を 行ってはいても、異なる性質を持った群をまとめて分析した結果、適切な分析 にならないのが分割相関を見逃したことによる誤謬である。生態学的誤謬を犯 したり、分割相関を見逃して不適切な推論を犯すことを避けるためには、個体 レベルで群ごとに分けた相関分析を行う必要がある。 図 9 名詞と「の」の相関:5 媒体 図 10 名詞と「の」の分割相関:3 媒体
4.生態学的誤謬と分割相関の例 2:I-JAS の場合 本節では、第 3 節で観察した生態学的誤謬が特殊な現象ではなく、学習者 コーパスを使用した分析でも、容易に観察されることを確認する。その上で、 本節の分析例の場合、分割相関とみなして良いかどうかを検討し、分割相関に 関する理解を深める。 調査する学習者コーパスには I-JAS4を使用し、日本語能力試験の J-CAT5
(Japanese Computerized Adaptive Test)の合計得点と接続助詞「と」の頻度 との相関を調査する。 接続助詞「と」は、「たら」「ば」「なら」とともに日本語の条件表現を作る 際に使用される機能語で、日本語教育において重要な教育項目の一つとなって いる。しかし、「たら」が習得されやすい一方で、それ以外の接続助詞は習得 が困難で、「と」は初級では教える必要がないとする考え方が提案されている (田中,2005: 80;山内,2009: 45;庵,2017: 24-25)。学習者コーパスにおけ る「と」の頻度が日本語能力の向上と強い関連性があるのなら、日本語能力が 向上すれば、いずれは「と」の頻度も増加することを意味するため、「と」の 教育時期は特に初級にこだわる必要がなく、もっと後にずらすことを考えてよ いかも知れない。しかし、この両者に弱い相関しかないのであれば、日本語能 力が向上しても「と」が使いこなせるようにはなっていない学習者が大勢存在 することになり、「と」をめぐる議論は、教える時期だけでなく、どのように 教えるかを中心に議論していく必要が出てくると思われる。問題は、集団レベ ル(平均値)で分析した相関係数の値(図 11)と、個体レベルで分析した値 (図 12)が大きく異なることにある。 4 I-JASは、2020 年に国立国語研究所で完成された学習者コーパスで、12 言語の日 本語学習者 1,000 名と日本語母語話者 50 名に対し、インタビューやロールプレ イ、ストーリーテリングなど複数の課題を施して、およそ 360 万語のデータを集 積している(迫田(編),2016;迫田ほか,2016)。データは形態素解析が施され、 検索アプリケーション『中納言』を利用して Web 上で検索できるため、今後の日 本語教育研究で使用される中心的な学習者コーパスとなることが見込まれている。 5 J-CATは、Web 上で受験できる適応型日本語能力テストで、聴解、文字・語彙、 文法、読解の 4 分野、各 100 点の合計 400 点で学習者の日本語能力を判定する (https://j-cat.jalesa.org/)。
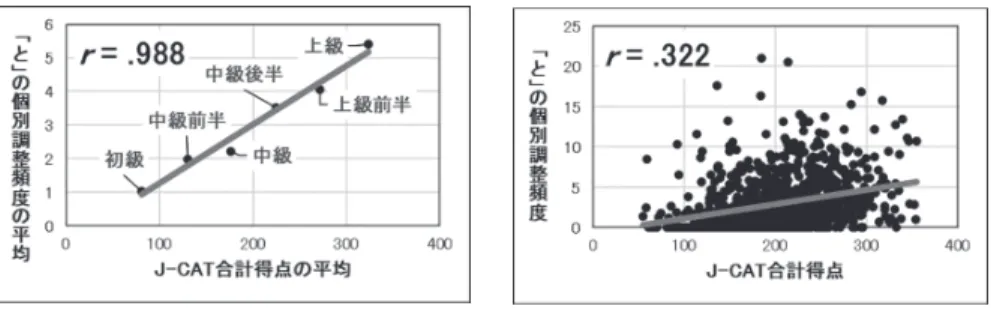
図 11は、J-CAT の合計得点を 100 点以下:初級、101 ∼ 150:中級前半(中 前)、151 ∼ 200:中級、201 ∼ 250:中級後半(中後)、251 ∼ 300:上級前半(上 前)、301 以上:上級の 6 種類6に区分し、それぞれの群の平均得点と、「と」の 平均頻度で回帰直線を描き、相関係数を表示した集団レベルの散布図である。 図 11のように、学習者の日本語能力レベルごとの平均値で分析すると、相関 係数は( =.988, =4, =0)と、非常に強い相関がある。一方、図 12 のよ うに個体レベルで分析すると( =.322, =998, =0)と弱い相関しかない。 これは、第 3 節で観察された生態学的誤謬と同じ現象で、図 11 の分析から学 習者は日本語能力が向上するにつれて、ほぼ全員の「と」の頻度も多くなると 考えると、誤った推論を犯すことになる。図 12 を見ればわかるように、上級に なってもほとんど「と」を使用しない学習者も数多く存在しており、全般的な 日本語能力が向上したからと言って、「と」が適切に使用できているとは言えな い可能性が考えられる。これまで、学習者コーパスを使用した分析では、ほと んどが学習者の日本語能力別に分けた頻度合計で比較が行われてきた。このよ うな集団レベルの分析では生態学的誤謬を犯す可能性があるため、個体レベル で分析する分析法が有効だと考えられる。 ただし、個体レベルの分析法では、分割相関にも留意する必要があった。そ 6 J-CATでは、351 点以上を「日本語母語話者相当」として区分しているが、I-JAS の 1,000 名の学習者のうちこのレベルに当たるのは、352 点、354 点、355 点の 3 名しかいないため、この 3 名で 1 群を構成するより、上級の 39 名とまとめて上 級として扱う方が適切だと考え、この 6 区分で分析した。 図 11 J-CAT 合計得点と「と」:平均値 図 12 J-CAT 合計得点と「と」:個体レベル
こで図 13 で、学習者の日本語能力別に散布図を描き、表 3 でこの群ごとの相関 係数を示した。 表 3を見ると、日本語能力別の群ごとの相関はほとんどなく、初級に至って は負の相関になっている。これは、どのように考えればよいのであろうか。第 3 節で行った、BCCWJ の媒体別の分析のように、これを分割相関と見なすな ら、図 12 の分析自体が不適切だったことになる。 ここで重要になるのが群というものの性質である。森・吉田(1990: 228)の 分割相関の説明で用いられていた例は、男か女かという群の分け方と、小学3 年生から 6 年生という学年別の群の分け方であった。これらは、アプリオリに 区分されている群であり、分析者が恣意的に分けた群ではない。BCCWJ の媒体 も、書籍、新聞、雑誌、白書などのように、それ自体で別々の性質を持ってい る群である。 これに比べ、J-CAT の総合得点による区分は、テストの制作者によって恣 意的に分けられた区分であり、わずか 1 点の差で異なる群に区分されること からも分かるように、群ごとに明確な性質の違いを持っているわけではない。 この区分がいかに人工的なものであるかは、図 13 の散布図を見れば明白で、 BCCWJの 3 媒体を描いた図 10 のように、各群が独自の性質を持って分布して いるわけではない。図 13 は、本来全体で分析するべき分析対象を、一定の区間 で切断して群に分けており、このような分析を行うと、「切断効果」によって相 関係数の値が小さくなることが知られている(森・吉田,1990: 227)。このた め、ここで取り上げた分析では、分割相関を考慮に入れて分析すると、かえっ て誤謬を犯す結果になる。 図 13 日本語能力別の散布図 表 3 日本語能力別の相関
このように、生態学的誤謬を避けるために個体単位で分析することが有効で あるのは確かだが、機械的に個体単位で相関分析を行うのではなく、分析対象 の個体を群に分けるべきか否かをという分割相関の可能性を検討して分析する ことが重要である。 5.まとめと今後の課題 コーパスを使用した研究では、サブコーパスや日本語学習者の習熟度別グ ループなどの集団レベルの頻度を比較する分析が多い。しかし、集団レベルの 相関分析では、個体レベルの分析結果とは大きく値が異なる場合があり、集団 レベルで得られた分析結果を個体レベルに当てはめて解釈してしまう過ちを生 態学的誤謬という。また、相関分析を行う際には、群ごとに区分して相関を分 析した場合と、群を区分せずに混合して分析した場合では、分析結果に大きな 違いが生じる分割相関の問題がある。相関分析を行う際には、観察対象を群に 分けて分析するべきか、混合して分析するべきかを十分に検討しておく必要が ある。 本稿では BCCWJ 固定長・長単位のデータを使用して、名詞と格助詞「の」 の頻度の相関分析と、I-JAS を使用して日本語能力テストの総合得点と接続助 詞「と」の頻度の相関分析を行い、この両者で生態学的誤謬が起きる実例を示 した。また、BCCWJ 固定長の場合は、書籍、雑誌、新聞、白書といった群でそ れぞれ異なる性質を持っているため、これらを混合するのではなく、分割相関 で分析するべきであるが、I-JAS の日本語能力テストの総合得点で区分した学 習者レベルは、恣意的な区分であり、これらを群に分けて分析すると切断効果 によって誤った解釈を行う危険性があることを示した。従来のコーパス分析の 多くは、集団レベルで分析が行われているため、生態学的誤謬を回避したり、 分割相関を適切に観察するためにも、個体を観察単位としたコーパス分析が有 効である。 本稿では、生態学的誤謬と分割相関という計量的分析法にかかわる内容を中 心に論じたため、BCCWJ の媒体間で、なぜこれほど相関係数の違いが見られる のかや、I-JAS の学習者で、接続助詞「と」がどれぐらい適切に使用されてい るかといった、内容面に関する研究を行うことはできなかった。これらの分析 は今後の課題としたい。
謝辞 本研究は、JSPS 科研費 JP19K23033 の助成を受けたものです。また、本研 究には森秀明(2018)「コーパス分析における生態学的誤謬」『計量国語学会第 六十二回大会予稿集』19-24、および、森秀明(2019)『コーパスの計量的分析 法再考』(博士論文,東北大学)の一部が含まれています。 使用データ 本研究では『現代日本語書き言葉均衡コーパス』国立国語研究所および、 『多言語母語の日本語学習者横断コーパス』(中納言 2.4.5 データバージョン 2020.03)国立国語研究所を使用しました。 参考文献 庵功雄(2017)『一歩進んだ日本語文法の教え方 1』くろしお出版 . 鎌田修(2006)「KYコーパスと日本語教育研究」『日本語教育』130,42-51. 北居明(2014)『学習を促す組織文化―マルチレベル・アプローチによる実証分析』有 斐閣.
Robinson, W. S. (1950) Ecological Correlations and the Behavior of Individuals, , 15(3), 351-357. 清水裕士(2014)『個人と集団のマルチレベル分析』ナカニシヤ出版. 丸山直子(2015)「コーパスにおける格助詞の使用実態 ―BCCWJ・CSJにみる分布―」 『計量国語学』30(3),127-145. 宮内小夜香(2012)「接続助詞とジャンル別文体的特徴の関連について ―『現代日本語 書き言葉均衡コーパス』を資料として―」『国立国語研究所論集』3,39-52. 森秀明(2017)「コーパス間における単語使用率の比較 ―観察単位(ケース)は単語か 文書か―」『計量国語学』31(3),205-221. 森秀明(2018)「学習者コーパスを使用したレベル別頻度比較の方法」『Learner Corpus Studies in Asia and the World』3,303-322.
森敏昭・吉田寿夫(編著)(1990)『心理学のためのデータ解析テクニカルブック』北大 路書房 .
森幸雄(1987)「生態学的データ利用における誤謬の問題 ―ロビンソンの生態学的誤謬 問題を中心として―」『Sociologica』12(1),23-38.
迫田久美子(編)(2016)『海外連携による日本語学習者コーパスの構築 ―研究と構築 の有機的な繋がりに基づいて― I-JAS 構築に関する最終報告書 (International Corpus
東京:国立国語研究所 .
迫田久美子・小西円・佐々木藍子・須賀和香子・細井陽子(2016)「多言語母語の日本 語学習者横断コーパス International Corpus of Japanese as a Second Language」
『国語研プロジェクトレビュー』 (3), 93-110. 田中真理(2005)「学習者の習得を考慮した日本語教育文法」野田尚史(編)『コミュニ ケーションのための日本語教育文法』くろしお出版,63-82. 山内博之(2009)『プロフィシェンシーから見た日本語教育文法』ひつじ書房 . 山内博之(2015)「話し言葉から見た文法シラバス」庵功雄・山内博之(編)『現場に役 立つ日本語教育研究 1 データに基づく文法シラバス』くろしお出版,47-66. 山崎誠(編)(2014)『講座日本語コーパス2.書き言葉コーパス ―設計と構築―』朝倉 書店 .
The Effectiveness of Corpus Analyses with
Individuals as Units of Observation
Hideaki MORI
Research using corpora frequently carries out analyses with frequency aggregated at the group level, such as sub-corpora or Japanese language learners grouped at different proficiency levels. However, in correlation analyses at a group level, values may greatly differ from the results of analyses at an individual level. Mistakes where analysis results attained at a group level are applied and interpreted at an individual level are known as ecological fallacies. Moreover, where correlation analysis is carried out with categorization by group and with mixed groups without categorization, the problem of split correlation arises, meaning a substantial difference occurs in the analysis results. When carrying out correlation analysis, ample consideration is required on whether to analyze the subjects of observation by dividing them into groups or by mixing them.
This paper uses the fixed-length data of the Balanced Corpus of Contemporary Written Japanese (BCCWJ) for correlation analysis of nouns with the frequency of the case-marking particle “no.” It also uses the International Corpus of Japanese as a Second language (I-JAS) for correlation analysis of total scores on Japanese language proficiency tests and the frequency of the conjunction particle “to,” and gives examples of ecological fallacies within both of these analyses. Moreover, the paper shows that as the fixed-length data of the BCCWJ includes groups such as books, magazines, newspapers, and white papers, the different properties of these groups requires analysis via split correlation rather than mixed. However, the I-JAS levels of learners classified by total scores on Japanese language proficiency tests are categorized arbitrarily; therefore, analysis in groups risk misinterpretation because of the breakage effect. Many conventional corpus analyses are carried out at a group level; therefore, to avoid ecological fallacies and properly observe split correlations, corpus analyses with individuals as units of observation are effective.