技術論文
Microsoft Excelを用いたケモメトリクス計算(6)
– PLS回帰 –
吉村 季織
*,高柳 正夫
国立大学法人東京農工大学農学府, 〒183-8509東京都府中市幸町3-5-8
*e-mail: [email protected]
(Received: January 8, 2014; Accepted for publication: March 7, 2014; Advance publication: May 17, 2014)
近年,化学データを数学的・統計的手法により解析する「ケモメトリクス」が頻繁に用いられるよう になってきた.しかし,日本の大学の化学教育の場ではほとんど取り上げられていない.ケモメトリク スや数値計算の専用ソフトウェアを使うことなく,現在最も普及しているソフトウェアのひとつである Microsoft Excel (Excel)の基本機能を用いてケモメトリクス計算を行うことができれば,多くの教育・研究 機関で役立つものと思われる.シリーズ6回目は,ケモメトリクスの多変量による定量モデル作成におい て,最も頻繁に用いられるPLS (partial least squares) 回帰 (PLSR)を取り扱った.これまでと同様に,スペク トルの解析を例に挙げた.モデル構成試料および未知試料のスペクトルの生成,潜在変量を抽出するPLS1 (1化学種の場合) とPLS2 (多化学種の場合) の実行,PLSRによる濃度定量モデル作成を行うワークシート を作成した.生成したスペクトルを使いPLSRとPCRの定量性能について比較を行った.その結果,PLS1 によるPLSRでは特定の化学種の濃度データを用いるため,目的とする化学種に関して少ない因子数で良 好なモデルが得られた.一方PLS2によるPLSRでは,複数の化学種に対して安定して濃度予測できるモデ ルが得られることが分かった.少ない因子数においてPLSRがPCRと比較して優位であることは示された が,最適なモデルが得られるとは限らなかった.モデル化手法と因子数を変えて予測性能を比較しながら 最適なモデルを得る必要があることが示唆された.キーワード: Microsoft Excel, ケモメトリクス, partial least squares, PLS, PLSR
1 はじめに
実験的に得られた化学データを数学的・統計的手法に より解析する「ケモメトリクス」が近年盛んに用いられ るようになってきた.しかし,ケモメトリクスに関する 教科書類がいくつか出版 [1–4]されている一方で,大学 等の授業ではほとんど扱われていないのが実情である. そこで本シリーズは,より多くの学生や研究者がケモメ トリクスを用いることができるようにするために,最も 普及している計算ソフトMicrosoft Excel(以後Excelと記 す)によるケモメトリクス計算法を考案することを目的 としている.今回は,PLS回帰(partial least squares regression: PLSR) [5]をExcelワークシート上で実行する.PLSRはこれま
で扱ってきた,重回帰(multiple linear regression: MLR) [6] や主成分回帰(principal component regression: PCR) [7]と 同様に,多数の説明変量から目的変量を求める定量モデ ルを作成する手法である.しかし,MLRは説明変量の 数が測定数を超えるとモデルを求めることができなくな る,多重共線性の問題がある.このことを解決するため に,有効な説明変量を選択して,説明変量の数を減らす 変量選択を行う. PCRでは説明変量を減らす代わりに,主成分分析 (principal component analysis: PCA)を用いて説明変量を組 み合わせて新たな変量,すなわち潜在変量を作り出す. 潜在変量の数は必ず測定数以下となるため,潜在変量を 説明変量として回帰を行うことで定量モデルを作成する ことができる.
PLSRはPCRと同様に潜在変量を作り出して回帰を行 うことで,多重共線性を回避して定量モデルを作成する 方法である.PCRでは説明変量のみを使って潜在変量を 作り出すが,PLSRでは説明変量と目的変量を組み合わ せて潜在変量を作り出す.このことにより,潜在変量と 目的変量間の関係性がより強くなるため,PCRと比較し てPLSRのほうが良好な定量モデルが得られると期待さ れる.特に近赤外スペクトルの解析の例が多く,例えば 熟成中のブドウの皮中に含まれるフェノール化合物の定 量 [8],ナシ [9]やリンゴ [10]中の糖の定量といった果実 の分析,血糖の定量 [11],魚油中の脂肪酸量の定量 [12], 混紡繊維中の繊維混用率の測定 [13]など様々な分野に 渡っている.これらの研究ではPLSRを単独で用いるこ とは少なく,数値微分などによるスペクトルの前処理 や,解析波長領域の選択,PLSRを2段階に用いるなど の処理と組み合わせて用いられている.しかしPLSRは その中核となる手法であるため,PLSRを理解すること は重要である. ここで,PLSRとPLSという用語について本稿での用 い方を定義しておく.統計学的に正しい解釈ではない が,本稿ではPCAをPCRにおける潜在変量算出法とみ なすこととする.これに倣い,PLSRにおける潜在変量 算出法のことをPLS (partial least squares)と呼ぶことにす る.一般にはPLSとPLSRという用語は明確に使い分け られていないようであるが,本稿ではPLSRの手順の見 通しをよくするため,潜在変量作成部分をPLS,その後 の目的変量との回帰を合わせたところまでをPLSRと称 する. 本稿ではまず,既報 [6, 7]と同様に吸光スペクトルを 用いた定量分析を想定する.この報告で作成したPCA, PCRのワークシートに,PLSの実行およびPLSR検量モ デル作成および定量を行うためのワークシートを追加す る.さらにPCRとの比較を行う. 本稿の内容は,Microsoft Windows上のExcelを想定し ている.そのため,Mac OS上のExcelにより計算を行 う場合には,キー操作などを適宜読み替えてほしい.ま た,本稿中の図では,Excelのワークシートは列幅を初 期状態より狭い5.0 (45 ピクセル)にしてあるので,その 点に注意して計算値(最終桁の値など)の桁数を見てほし い.
2 PLSR
PLSRはMLRやPCRと同様には目的変量yを複数の説 明変量xmの線形結合で表される定量モデル, 1 M m m m y f x = ′ =∑
(1) を作成すること,すなわち係数 fmを求めることが目的 である (y' は y の予測値 ).PCR では PCA によって xmの 代わりに用いる潜在変量を見つけ,回帰を行う.PLS は PCA とは異なる原理によって潜在変量を得る.よって, 得られる潜在変量は PLS と PCA では異なっており,当 然これらを回帰して得られる PLSR と PCR は異なる定 量モデルとなる.2.1 PLSの概念-PCAとの差異
2次元(説明変量の数2)の4点(測定点4)の場合を図示 するとFigure 1のようになる.MLRでは各点のx1j, x2j座 標 (jはデータの番号: j = 1 ~ 4) が説明変量にあたる.1変 量のみ選択するということは,x1軸の座標であるx1jのみFigure 1. 2-dimensional image of relation between a new axis a1 and scores t1j used in PLS.
The scores t1j are the coordinates on the new axis a1. The
variance of t1j is found to be larger than that of x1j, which are
the coordinates on x1 axis. Therefore, a1 axis can explain the
を用いて(x2jは用いないで)回帰するということになる. しかしx1軸だけではこれら4点の情報を完全に捉えるこ とはできず,x2軸の座標 (各測定点からx1軸までの距離) だけ情報が残ることになる. そこでPCRやPLSRでは,まずPCAやPLSによって説 明変量の変動を強くとらえることができるa1軸を探す. このa1軸に対する4点の座標がFigure 1で示されるt1jに なる.PCAやPLSではこの座標t1jのことをスコアと呼 ぶ.そしてPCRや後述するPLSRでは,このスコアを潜 在変量として用いる.a1軸を考えることで,測定点の情 報を1つの軸だけでより多くとらえられていることが分 かる(各測定点からa1軸までの距離が,x1軸までの距離 と比較して短くなる傾向が見られる).またMLRではx2 軸の座標を完全に破棄することになる.しかし,PCAや PLSではa1軸自体がx1軸とx2軸両方の成分を持っている ので,a1軸の座標値である各スコアt1jも同様にx1軸の座 標,x2軸の座標の情報を持つことになる.つまり,測定 した情報を無駄なく使うことができる方法である. PCAではこのa1軸を求めるために,スコアの二乗和, つまりt1jの二乗和sPCA 2 PCA 1 1 n j j s t = =
∑
(2) の最大化を行う.PCA では a1軸方向の単位ベクトルを p1と記し,第 1 主成分ベクトル,または第 1 ローディン グベクトルと呼ぶ. これに対しPLSではa1軸を求める際にスコアと目的変 量との関係性が強くなるようにする.このことがPCAと の最大の差異である.PLSによるa1軸の求め方は,単一 の目的変量(たとえば単一の化学種の濃度情報)を用いて モデルを作成するPLS1と,複数の目的変量(複数の化学 種の濃度情報)を同時に用いて予測するPLS2の2種類で 異なる.PLS1では,スコアtijと目的変量yj間の共分散σty 1 1 n ty j j j t y σ = =∑
(3) を最大化する ( つまり tijの変動と yjの変動の同調性を高 くする ) ような a1軸を求める. PLS2では複数の目的変量全体を捉えるために,説明変 量に対して行ったFigure 1と同様の操作を目的変量のプ ロット内にも適用する.つまり目的変量をプロットした 空間に対し,新たにb1軸を考える.このb1軸に対する目 的変量のスコアをu とする.このu とt の間の共分散σ 1 1 1 n tu j j j t u σ = =∑
(4) を最大化する. PLSで得られるa1軸方向の単位ベクトルをウェイト (weight)ベクトルと呼び,w1で表す.w1はPLS1では T 1 ( )1 1 T 1 ( )1 l l = X y w X y (5), となることが分かっている.一方 PLS2 では T T 1 1 1 1 1=λ1 1 X Y Y X w w (6) を満たすベクトル,つまり T T 1 1 1 1 X Y Y X の固有ベクトルと なる.w1が求まれば,X1よりスコアが計算できるので, 得られたスコアを用いて目的変量および説明変量を回帰 し,各変量から今回のスコアでは捉えられなかった残差 部分を取り出す.この残差部分は,PCA では a1軸に直 交する空間への直交射影になるが,PLS では斜交射影に なっているということも両手法の相異の一つである.残 差部分に対し上述した操作を繰り返して,説明変量,目 的変量から情報を引き抜き,スコアを取り出していく.2.2 PLSの計算手順
PCAの場合と同様に吸光スペクトルを想定する.L種 の化学種(PCAの主成分と紛らわしいので,化学種と記 すことにする)が存在しているN個の試料を,M個の波 長(λ1 ~ λM)で測定してスペクトルを得たとする.試料nの スペクトルをan (列ベクトル),濃度情報ベクトルをcn (列 ベクトル)とする.スペクトルをまとめたM × N行列A を説明変量,濃度情報をまとめたL × N行列Cを目的変 量とする.Cの中から特定の化学種lに関する濃度デー タを取り出した行ベクトルをc(l)とする. {1} 検量モデル校正用試料 ( 以後校正用試料と記す ) を測定して得られたスペクトル行列 Acal,濃度情報行列 Ccalから平均ベクトル aavg, cavg,および平均行列
Aavg, Cavgを求める.また,化学種 l の平均濃度 c(l)avg,
および平均ベクトル c(l)avgを取り出しておく.これら を使って平均中心化した行列 X1, Y1及びベクトル y(l)1 を算出する.
(
)
(
)
(
)
1 1 avg 1 1 avg N N y y = = − = = − = = − X x x A A Y y y C C y c c (7)平均中心化されたX1が説明変量であり,PLS1の場合 はy(l)1,PLS2の場合はY1がそれぞれ目的変量となる. ウェイトベクトルなどを求める手順はPLS1とPLS2 で異なるため,分けて説明する. 【PLS1 の場合】 • i = 1 より始める PLS1 − {2} ウェイトベクトル wiを求める. T ( ) T ( ) i l i i i l i = X y w X y (8) PLS1 − {3} スコアベクトル tiを求める. T i= i i t w X (9) PLS1 − {4} Xiを tiに回帰して回帰係数ベクトル piを 求める. T T , i i i i i i i s s =X t = p t t (10) PLS1 − {5} y(l)iを tiに回帰して回帰係数 qiを求める. T ( )l i i i i q s =y t (11) {7}に進む 【PLS2 の場合】 • 前述したように wiはX Y Y Xi iT i Ti の固有ベクトルと して求めることができるが,直接 wiのみを求める のではなく,反復計算の過程で,ti, pi, qiが同時に求 まる方法を採用した.これは,式 (6) 左辺の一部を 分解して計算しているとも,一般的には用いられる nonlinear iterative partial least squares (NIPALS) [4] の一 部をまとめている計算法とも解釈することができる. • i = 1 より始める PLS2 − {2} ウェイトベクトル wi に適当な値を代入する ( ただし |wi| = 1). PLS2 − {3} スコアベクトル tiを求める T i= i i t w X (12) PLS2 − {4} Xiを tiに回帰して回帰係数ベクトル piを 求める. T T , i i i i i i i s s =X t = p t t (13) PLS2 − {5} Yiを tiに回帰して回帰係数ベクトル qiを 求める. T i i i i s = Yt q (14) PLS2 − {6} wiを求めなおす T T i i i i i i i ′ = X Y q w X Y q (15) 計算が収束していない場合は,wi=w′iとして PLS2 − {3} に戻る.収束している場合は {7} に進む. {7}Xi+1を求める 1 i+ = i− i i X X p t (16) この操作が前述したように,ウェイトベクトル wi(ai 軸方向の単位ベクトル ) に直行する空間への斜交射影 となる.この斜交射影は,ベクトル piに沿った方向 で行われる.つまり,PCA における piと同様に射影 の方向を決めるベクトルである.そのため,PLS で も PCA と同様に piを第 i ローディングベクトルと呼 ぶ.
{8}y(l)i+1, Yi+1を求める
【PLS1 の場合】 ( ) 1l i+ = ( )l i−qi i y y t (17) もしくは ( ) 1l i+ = ( )l i y y (17') 【PLS2 の場合】 1 i+ = i− i i Y Y q t (18) もしくは 1 i+ = i Y Y (18') • i = i+1 として PLS1 − {2} もしくは PLS2 − {2} に 戻る. • 式 (16), (17) および (18) は説明変量,目的変量か ら wiで説明できる情報を最小二乗法によって引き抜 く作業 ( デフレーションまたは減次などと呼ばれる ) である.しかし,スコアベクトルの直交性により, このデフレーションは必ずしも必要ではないことが 分かっている [14].そこで本稿では,ほかの計算に 支障がない目的変量のデフレーションを省略する. すなわち,式 (17), (18) の計算の代わりに,式 (17'), (18') の計算を用いる. このようにして順次wiを求めていく.M > Nならばwi
は多くてi = Nまでしか求まらない.これ以上求めよう としても,Xiの各要素が0(もしくはほぼ0)になってしま うため,もはやwiを正しく求めることができなくなる. また,化学種の数が少なく(L < N),スペクトルにノイズ が含まれていない場合などは,i = Lまでしか求まらない. 求まりうるウェイトベクトル(wi)の最大数を最大因子準
位(maximum factor level)と呼びFLmaxと表すこととする.
2.3 PLSRによる検量モデルの作成
一般にPLS1は単化学種専用,PLS2は多化学種同時定 量モデルを作成するために用いられるように示されて いる.しかし,PLSがlatent structure decomposition (LSD) [15]を基にした,latent variable regression (LVR) [16]の一 種であることを考慮すると,PLSは説明変量行列X1の分 解を行っているのであり,濃度予測モデルの作成におい てPLS1で注目していた化学種lのみに限定しなくてもよ いことが分かる.そこで本稿では化学種lに関して行っ たPLS1の結果を用いて,PLS2の場合と同様に,すべて の化学種の濃度を予測する検量モデルを構築する.する と検量モデル作成のPLSRはPLS1, PLS2に関係なく共通 した手順となる. {9}wi, ti, piを,i=1 から FL ( ≤ FLmax) までまとめた行 列 W, T, P を作成する. {10}T = RX1となるような X1と T を関連付ける行列 R を求める. T 1 T 1 ( )− = R W P W X (19) {11}Y1と T の回帰係数行列 Q を求める. Y1の予測値Y1′を T による回帰式 1′ = Y QT (20) を立てる.係数Qを重回帰により算出する. T 1 T 1 −, = = Q YT S S TT (21) {12} 係数行列 F を求める. = F QR (22) {13} 定数ベクトル f0を求める. 0= avg− avg f c Fa (23) ゆえに,スペクトル a と濃度情報 c の関係として, 0 = + c Fa f (24) というモデル式が得られる.
2.4 定量
{14} 濃度情報未知の試料 ( 以後未知試料と記す ) の スペクトル aunから,式 (21) を用いて,濃度情報の予 測値c′unを計算する. un un 0 ′ = + c Fa f (25) Nun個の未知試料のスペクトルをまとめた行列 Aunを 同時に計算する場合,f0を Nun列並べた行列 F0を用 意して, un un 0 ′ = + C FA F (26) とすることで未知試料の予測濃度行列C′un を求める ことができる.3 ExcelによるPLS計算
これまでのシリーズ同様スペクトルデータを取り扱う ことにする.そのためスペクトルの生成,PLS1, PLS2お よびPLSRを行うシートが必要となる.そこで本シリー ズ第4回のPCR [7]で用いたExcelブックに必要なシート を追加して用いる.このブックではSheet1をスペクトル 生成,Sheet2をPCA計算,Sheet3はPCRモデル作成およ び定量計算に用いた.本稿ではSheet4, Sheet5, Sheet6を 追加し,それぞれPLS1, PLS2, PLSRに用いることとす る.3.1 スペクトル生成
スペクトル生成を行っているSheet1とその作成手順を それぞれFigure 2とTable 1に示す.Sheet1はPCRのとき に作成したシートとほぼ同じであるので,シリーズ第4 回 [7]も参照してほしい. 化学種1, 2及び化学種3(汚染種)のスペクトルのパラ メータ(化学種lのピークの高さhl, 波長λl0, 幅wl)をC2:E4 に入力することで,それぞれの化学種の純スペクトル がC12:E32に算出される.モデル作成用試料中の化学種 1, 2および3の濃度CcalをI3:M3に指定することで,スペ
クトルAcalがI12:M32に求まる.さらにCcalおよびAcalを
平均中心化したデータY, XがそれぞれI8:M9, I35:M55と なる.PCRからの追加として,PLS1は単化学種の濃度
データを用いるため,Yを化学種1のy1と化学種2のy2 に分け,それぞれに対応するI8:M8およびI9:M9の範囲 に“y_1”,“y_2”という名前を付けた(Table 1手順18, 19). 未知試料の濃度Cunに関しては,化学種1と2の濃度 をP3:T4に任意に設定することができる.汚染種に関 してはT7で設定するcun3max(汚染種の最大濃度)を基にし て,P5:T5にランダムに設定される.未知試料のスペク トルAunは,CunとT9に設定するノイズレベルに基づいて P12:T32にノイズを含ませて生成することができる. 本論文では,検量モデル作成にXとYを用い,モデル の検証にAcalとCcalを使用する.
3.2 PLS1
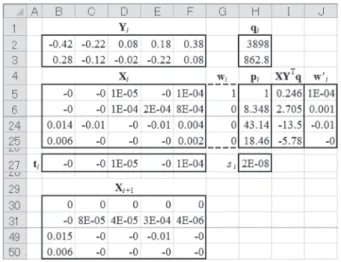
Figure 3にPLS1計算を行うためのワークシートSheet4 を示した.その作成手順はTable 2である.Figure 3では 第1ウェイト,スコア,ローディングベクトルを求めて いる.式(7)からわかるように,PLS1はPCAやPLS2の ように反復計算を必要としないため,X1とy1から直接w1 が求まる.Figure 3では,さらにt1, p1, q1, X2も同時に求 まるようになっている.PLSRで用いるw1, t1, p1をSheet6 の所定のセル(後述する)に保存したのち,X2である B29:F49をコピーし,B4:F24に値貼り付けすることでw2, t2, p2の各ベクトルが求まる.より高次の各ベクトルが必 要な場合は,上記作業を繰り返すことで得られる.3.3 PLS2
PLS2計算を行うためのSheet5をFigure 4,その作成手 順をTable 3にそれぞれ示した.第1ウェイトw1,スコア t1,ローディングp1を求めるための初期状態になってい る. Sheet5を用いて反復計算を行い,値を収束させるこ とでw1, t1, p1を求める.Excelによる反復計算法は既報 [17]にて示してあるので,ここでは簡単に解説する.(1) Figure 4の状態まで完成させたら,w′iであるJ5:J25を選 択してコピーする.(2)wiの先頭であるG5を選択し,値 貼 り 付 け(例:[Alt]→[E]→[S]→[V]→[Enter])を 行 う. Figure 2. Preparation of a worksheet (Sheet1) for generating the spectra for calibration and of unknown samples.The ranges surrounded by dashed lines have to be filled by values following this figure for getting the same results shown in this paper, but can be change arbitrary values. The values in the ranges surrounded by bold solid lines are calculated by formulas shown in Table 1.
Table 1. Procedures to construct worksheet (Sheet1) for simulating spectra.
Figure 3. Preparation of a worksheet (Sheet4) to get weight vectors (wi), loading vectors (pi) and score vectors (ti) by PLS1.
In this figure, w1, p1 and t1 related to the first chemical species,
i.e. l = 1, are obtained. By copying B29:F49 to B4:F24, the vectors of the second stage, w2, p2 and t2 can be obtained.
Figure 4. Preparation of a worksheet (Sheet5) to get weight vectors (wi), loading vectors (pi) and score vectors (ti) by PLS2.
This figure shows the initial state to get w1, p1 and t1. The
iteration calculation is proceeded by copying J5:J25 and pasting to G5:G25 as value. Then press [F4] key until reaching convergence.
(3)値が収束するまで[F4]キーを押し続ける.収束は数 式バーを観察することで判定できる. 収束したらwi, ti, piを,後述するようにSheet6にコピー し,結果を保存しておく.B30:F50に計算されているXi+1 をコピーし,B5:F25に値貼り付けする.wiを初期化し, 再度反復計算を行う. PLS1,PLS2ともに今回の例では第2因子(w2)まで求め ると,X3はすべての要素がほぼ0になるため計算を終了 する.試料数は5であったので第5因子まで求まる可能 性があったが,各試料中に存在する化学種が2種である うえ,スペクトルにノイズが含まれていないので,第2 因子までしか求まらなかった.化学種3を含めたり,ス ペクトルにノイズを設定したりすると第3因子以降も求 まるようになる.ただし,X1が中心平均化されているた め,第4因子までしか求まらない.
3.4 PLSR
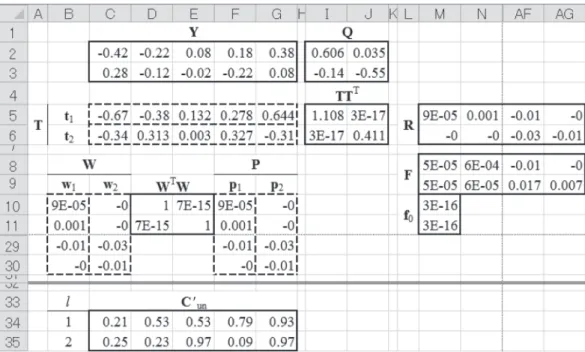
Figure 5にPLSR計算および未知試料の濃度予測を行う ためのSheet6を示した.因子順位は第2位まで用いた. この例では,Sheet4(Figure 3)で求めた化学種1に対する PLS1の結果を用いて,PLSRを行い両化学種の定量モデ ルを作成し,濃度予測を行っている.作成手順はTable 4に示した. PLS1は化学種1の濃度を用いて行ったが,化学種1, 化学種2双方の濃度を予測するモデルを作成するので, 目的変量であるY(C2:G3)には全目的変量を使うため “=Y”を入力した. Sheet6のW, T, Pに 該 当 す るC5:G6, B10:C30, F10:G30 には,Sheet4のそれぞれの因子順位ごとにwi, ti, piである B26:F26, h4:h24, I4:I24からコピーして値貼り付けして おく.D10:E11に求めているのはWTWで,この計算結果Table 2. Procedures to construct worksheet (Sheet4) of initial state for PLS1.
Figure 5. Preparation of a worksheet (Sheet6) to construct PLSR and predicting the concentrations.
In this figure, PLSR model using the results of PLS1 for chemical species 1 is obtained and the concentrations of both chemical species in unknown samples are predicted.
In the range above the double-solid line, PLSR model is constructed. The values of w1, w2, t1, t2, p1 and p2 are
copied from Sheet4 after convergence on each step. The concentrations of unknown samples are predicted in the range below the double-solid line.
Table 4. Procedures to construct worksheet (Sheet6) for PLSR using the result of PLS1 for the first chemical species and predicting the concentration of the unknown samples.
が単位行列になっていることを確認するためである.つ まり,ウェイトベクトルは互いに直交していることがわ かる.またI5:J6で求めているS = TTTが対角行列になっ ていることから,スコアベクトルも互いに直交している ことがわかる.これらのことは,PLSで一般に成り立つ ことが証明されている [5]ので,スコアを説明変量とし た重回帰は多重共線性を回避できることがわかる. I2:J3にはTによるYの回帰係数Qが求まる.2つの化 学種の係数が同時に求まっている.このワークシートの I2の値と,化学種1のi=1のときの係数{Figure 3(Sheet4) の中のI2の値}がどちらも0.606となっている.さらに i=2のときも同様にSheet4のI2とSheet6のJ2が0.035と等 くなることを確かめることができる.このことから,各 iのステップで回帰係数を求める式(13)での計算は必須 ではなく,式(21)によっても得られることがわかる.つ まりPLSRはPCRと同様,元の説明変量から作り出した 潜在的な変量であるスコアによる重回帰に帰着している ことが示される.これによって,目的変量YとスコアT の関係が求まったことになる. M5:AG6は式(19)で求められる行列Rで,説明変量X との積でスコアTを直接求めるために用いられる.すな わち説明変量とスコアを結びつける行列である. 行列QとRを用いることで,説明変量と目的変量が結 びつくこととなる.そのようにして求めた係数行列Fが M8:AG9である.さらに定数項のベクトルf0をM10:M11 に求めた.
3.5 定量計算
得 ら れ たFとf0を 使 っ て 未 知 試 料 の ス ペ ク ト ル Aun(Sheet1のP12:T32)か ら 濃 度 をSheet3のC34:G35に 推 定した(Figure 5).今回用いた校正用試料のスペクトル Acalと未知試料Aunは汚染成分やノイズを含ませていな かったので,算出されたCun′ はSheet1のP3:T4で設定し た値と等しくなった.4 PLSRとPCRの比較
ここまでの例では,汚染成分やノイズの無い校正用試 料および未知試料のスペクトルを用い,さらに得られた 第2因子まで使って予測モデルを構築したため,前章で 示したように完全な予測となった.しかし,これでは PLSRとPCRの性能の違いが判らないので,汚染やノイ ズを含ませた条件にて比較を行った. 校正用試料中の化学種1及び2の濃度はFigure 2(Sheet1 にのI3:M4)で示された状態を保持し,汚染成分の濃度を 0.03, 0.06, 0.09, 0.06, 0.03と想定しI5:M5に入力した.こ のようにして得られたスペクトルと濃度情報を用いて, PLS, PCAの各手法でウェイト(PCAではローディングと 等しい),ローディング,スコアの各ベクトルを求めた. 化学種3種でスペクトルにノイズが無いので,因子順位 は第3位(FLmax = 3)まで求まった.PLSR, PCRでは,第1 因子だけの場合から,第1と第2因子を用いた場合,第1 から第3因子までを使った場合のそれぞれについてモデ ル作成を行った. 未知試料に関しては汚染化学種を想定したうえで,さ らにスペクトルにノイズを含ませるため,cun3max (Sheet1 のT7)に0.1,noise (Sheet1のT9)に0.01を 設 定 し た. 汚 染種の濃度とスペクトルのノイズは,これらの値を基に 乱数で割り当てられる.この条件で1000通りの試行を 行った. k回目の試行における未知試料nの中の化学種lの濃度 を,想定濃度ではcunln,予測濃度ではc′unlnとする.cunlnを基準としたc′unlnの平均相対誤差(average of relative errors :
ARE)を以下の様に定義する. 1000 5 un , un , un , 1 1 ARE 1000 ln k ln k ln k k= n= c c c ′ − =
∑∑
(27) 各因子数での ARE をそれぞれのモデルで求めた. さらに,今回のSheet1では求められないが,校正用試 料のスペクトルAcalにもノイズを含ませた場合について も同様に解析を進めた.この場合,第4因子まで求まる (X1は中心平均化されているので,第5因子は求まらな い)ので,第1から4因子までを用いたモデルも作成し評 価を行った. 手法や因子数間の比較はAREの大小を見ればよい.し かし,例えばAREが最大である第1因子までを用いた化 学種2のPCRモデルであっても,AREが0.87078と小さ な値であるため,AREの大小が比較しづらくなってし まう.そこで,AREが最小である第3因子までを用いた 化学種1のモデル(手法によらずAREが等しくなる)の ARE(0.00363)を 基 準 値 と し, 相 対 的ARE(relative ARE: RARE),ARE RARE
0.00363
に変換した.RARE の値が小さいほど定量性能が高くな る.Table 5 に PLSR と PCR モデルの予測性能の比較を 示した.用いた因子数 ( 用いたローディングの順位の小 さいほうからの数 :factor level: FL) ごとに,化学種 1(C.S.1) と化学種 2(C.S.2) の結果を分けて示した. 手法と因子数が同じであれば,化学種1の方が化学種 2よりもRAREが小さい,つまり予測性能が高いことが わかる.この原因として,化学種1の方がバンド強度が 強い{Sheet1 (Figure 2)のC2とD2を比較}こと,校正用 試料の濃度範囲が化学種1のほうが広いこと,さらに化 学種2では未知試料の想定濃度が校正用試料の濃度範囲 を大きくはみ出していることなどが考えられる.このこ とより,予測したい濃度範囲を考慮したうえで校正用試 料の濃度を決定することの重要さがわかる. 第1因子のみを使ったモデル化では,化学種1に関す る予測は,校正用試料のスペクトル中の誤差の有無に 限らず,PLS2-R(PLS2でウェイト,スコア,ローディン グを求めてから,回帰モデルを作成するPLSRであるこ とを示す)でRAREが5程度と最も小さくなり,次いで PLS1(1)-Rの13程度となった(カッコ内の「1」は化学種 1の濃度データを用いてPLS1を行ったことを示す).さ らにPCRでは17程度であり,PLS1(2)-Rでは185程度と 桁違いに大きくなった. 化学種2に関しては,PLS1(2)-RでRAREが82程度で 最も小さく,PLS2-Rで231程度,PLS1(1)-Rで238程度, PCRで240程度という順になっていた.PLS1(l)-Rは一種 類の化学種lの濃度データのみを使ってモデルを構築す るため,化学種lに関して予測性能が高いものと期待さ れる.このことは化学種2においてPLS1(2)-RのRARE が最も小さかったことに関しては成立していたが,化学 種1の場合にはPLS2-Rが最も小さく成立していなかっ た.最適な定量モデルを得るためには,様々な手法間の 比較が必要であることがわかる. Figure 1に示したようにローディングベクトルは,ス ペクトルをプロットした高次元空間内の1つのベクトル として表わされる.そのため,スペクトルと同じように 表示することで,ローディングがどの化学種のスペク トルの影響を強く受けているかがわかり,そのローディ Table 5. Comparison of precisions of the results obtained by three PLSR's and PCR.
ングを用いて作成した定量モデルの性能を考察するこ とができる.Figure 6には各モデル化手法で得られた第 1ローディングを示した.特徴として,PLS1(1), PLS2, PCAでは化学種1のバンドであるλ=2994付近で正に大き なピークとなり,化学種2のバンドであるλ=3004付近で 負に小さなピークが見られた.つまりこれら3つの手法 によって得られた第1ローディングは,化学種2よりも 化学種1のスペクトルの影響を強く受けていることがわ かる. 一方PLS1(2)のローディングでは,λ=2994付近は他の 3手法の場合と差がなかったが,λ=3004付近で負により 大きなピークとなった.PLS1(2)は化学種2の濃度情報 を用いるので,他手法に比べて第1ローディングが化学 種2のスペクトルの影響を強く受けたものと思われる. これら4つの手法の第1ローディングはλ=2994付近 ではほぼ重なっており,λ=3004付近に差が見られた. λ=3004付 近 の 強 度 は,PLS1(2)-R, PLS2-R, PLS1(1)-R, PCRの順となった(PLS1(1)-RとPCRの差は小さくFigure 6で見て取ることはできない).この序列は,第1因子の みを用いた化学種2のRAREの昇順と一致する.つまり, 化学種2のバンドをより強くローディングに取り込むこ とで,化学種2の定量性能が高くなることが示されてお り,前述した「PLS1(l)-Rは一種類の化学種lの濃度デー タのみを使ってモデルを構築するため,化学種lに関し て予測性能が高い」という期待と一致していた.RARE が化学種1に比べ大きくなったのは,化学種1のバンド の影響が強いことによると考えられる. 一方,化学種1のRAREとλ=3004付近のピークの大き さの序列は一致していなかった.しかしこれらの結果は 次のように解釈することができる.Figure 6から読み取 ることができるように,化学種2のスペクトルは化学種 1と比較して幅が広く,化学種1のピークであるλ=2994 でも0.2程度の強度がある.これに対し,化学種2のピー ク位置λ=3004での化学種1の強度は0.01程度である.化 学種2の濃度変動の影響は,λ=2994に現れることが分 かる.そのため,化学種1に対して正しく情報を得る ためには,化学種1のピークであるλ=2994だけでなく, λ=3004にピークを持つ化学種2のスペクトルの情報を考 慮する必要がある.しかし,PLS1(2)-Rでは化学種2の情 報をローディングに強く取り込みすぎたため,化学種1 の定量性能が落ちている.PLS2-RがPLS1(1)-RやPCRと 比較してRAREが小さいのは,化学種2の影響を適度に 取り込んだためと思われる.このことは,第1ローディ ングのλ=3004において,PLS1(1)のほうがPCAに比べて わずかに負に大きく,つまり化学種2の影響をわずかだ が強く受けており,これに対応してPLS1(1)-RのRARE がわずかに小さいことと対応している. これらのことより,PLS1-Rは注目している化学種の 濃度情報のみを用いてモデルを作成するため,スペクト ルに化学種間の重なりがない場合にすぐれたモデルが作 成されること,PLS2-Rではすべての化学種の濃度情報 を使うので,スペクトルの重なりがある場合に有利であ ることが示された. 第2因子まで使った場合,化学種1のPLS2-Rの場合を 除き,どのモデル化手法でも定量性能が向上し,手法間 の差が小さくなった.Figure 7に各手法で得られた第2 ローディングを示した.PLS1(1), PLS2, PCAではλ=3004 付近に,PLS1(2)ではλ=2994付近にピークを持っている. これらは,それぞれ第1ローディングでは捉えられな かったり,過剰に捉えたりしていた情報の補正に役立っ ていると思われる. 第3因子までをモデル化に用いると,さらに定量性能 が向上した.汚染種を含めた3化学種系を想定している Figure 6. The spectrum-like representation of the first loading
vectors obtained by PLS and PCA. C.S.l: spectrum of chemical species l.
PLS1(l): loading obtained from PLS1 using the concentration of chemical species l.
ため,校正用試料のスペクトルにノイズが無い場合で は,すべての因子準位を用いることになり,どのモデル 化手法でも同じモデルが得られるためRAREが等しく なった. 校正用試料のスペクトルにノイズがある場合,第3因 子まででモデル化した場合のほうが,第4因子まで用い た場合よりも定量性能が高かった.これは3化学種系で あるために,第4因子はノイズなどの変動をとらえてお り,過剰な因子を組み込んだモデルができてしまった ため,定量性能が悪化したと考えられる.このように, PLSRやPCRでは得られた因子すべてを用いても最適な 定量モデルが得られるわけではなく,最適な因子数を決 定する必要があることがわかる. ここまで見てきたように,PLSRはPCRと比較してよ り少ない因子数でより良好な定量モデルが得られること が分かった.たとえば第1因子のみでモデルを作成した 場合,化学種1に関してはPLS2-Rが,化学種2に関して は PLS1(2)-Rが最も適しているといえる.しかし,第3 因子まで用いることができるのであれば,どの手法でも 同程度のモデルができることがわかる(あえて言うなら PCRが一番良い). このように,どの手法を用いるか,そしてどの因子準 位まで用いるかは定量性能を左右する重要な要因とな る.ローディングが定量性能を左右することもわかっ た.しかし,ローディングから定量性能を直接測ること は難しく,数値的なモデルの検証が必要となる.今回, 因子数や手法の比較を行うために,校正用試料とは別に 検証用の試料を用意し,その濃度を予測する外部検証を 用いた.外部検証は校正用と検証用の試料が分かれてい るため,客観性のあるモデル評価ができる.しかし,検 証用試料のスペクトルは,モデルに組み込まれないので モデル作成という意味からは無駄になってしまう.その ため,十分な数のスペクトルが得られないときなど,検 証用スペクトルの確保が難しく外部検証を適用すること が望ましくない場合がある.こういった場合に最も頻繁 に使われる方法として,校正用のスペクトルのみで内部 検証を行うクロスバリデーション(cross validation: CV)が ある(クロスバリデーションについては本稿末の付に記 した).因子数の決定だけでなく,さらには数値微分な どのスペクトルの前処理や,必要な波長領域を選び出す 波長選択などを組み込んで比較することが良好な定量モ デルを得るためには必要である.
5 おわりに
本稿ではまずPLSの概念をPCRと比較しながら述べ た.そして第5報のPCRのExcelブックに追加すること で,PLSRを実行する手法を示した.また,教科書では 述べられることが少ないウェイトベクトル同士やスコア ベクトル同士が互いに直交しているということを調べ た.この直交性もPLSの重要な点である.ローディング ベクトルをスペクトル表示することで,PLS1は注目化 学種の影響を強く受け,PLS2では考慮している化学種 全体からの影響を取り入れていることが考察できた. PLSはPCAと 異 な り 目 的 変 量 を 用 い て い る た め, PLSRはPCRと比較して少ない因子数で良好な定量モデ ルが得られることを示した.ただし,PLSRによって最 適なモデルが作成できることを保証するものではなく, 外部検証やクロスバリデーションなどを用いてPLS1-R, PLS2-R, PCRその他の手法を比較したうえで,どのモデ ルを用いるかを決める必要がある. PLSは多変量解析の1つであるが,PCAとは異なり一 般的な統計学の書籍で扱われていない.しかし,PLSで 扱う説明変量や目的変量が化学に関連したデータでなく てはならないという制限はなく,そしてPLSが元は計量 経済学から発展していることからも,化学の問題だけ でなく他の分野で重回帰モデルを得る手法の一つとし Figure 7. The comparison of the second loading vectors.て用いることも可能である.実際,さまざまな統計ソフ トウェアにもPLSが実装されている.こういったソフト ウェアを使うときなどにあたって「どんな計算をしてい るのか?」を理解するために本稿が役立てたらと思う. 本稿で示しているExcelのブックファイルは, http:// www.tuat.ac.jp/~mt2459/chemom/ にてダウンロードできる ので利用してほしい.
参考文献
[1] T. hasegawa, Supekutoru Teiryô Bunseki, kodansha Scientific Ltd. (2005)
[2] T. Mitsui, kemometorikkusu no kiso to Ôyô, – Bunseki kagakuto Tahenryô kaisekihô –, IPC Inc. (2003) [3] Y. Ozaki, A. uda, T. Akai, kagakusha no tameno Tahenryô
kaiseki, kodansha Scientific Ltd. (2002)
[4] Y. Miyashita, S. Sasaki, kemometorikkusu – kagaku Patân Ninsiki to Tahenryô kaiseki –, kyotitsu Shuppan Co., Ltd. (1995)
[5] J. Agnar höskuldsson, J. Chemometrics, 2, 211 (1988).
[CrossRef]
[6] N. Yoshimura, A. Shigetani, M. Takayanagi, J. Comput. Chem. Jpn. 9, 109 (2010). [CrossRef]
[7] N. Yoshimura, k. Fukuhara, k. Mitsuki, M. Takayanagi, J. Comput. Chem. Jpn. 10, 32 (2011). [CrossRef]
[8] R. Ferrer-Gallego, J. M. herández-hierro, J. C. Rivas-Gonzalo, M. Teresa Escribano-Balión, LWT –, Food Sci. Technol. (Campinas.), 44, 847 (2011).
[9] h. Xu, B. Qi, X. Fu, Y. Ying, J. Food Eng. 109, 142 (2012). [CrossRef]
[10] L. Yan-de, Y. Yi-bin, FuXiaping and Lu huishan, J. Food Engineering. 80, 986 (2007).
[11] Z.-M. Chuah, R. Paramesran, k. Thambiratnam, S.-C. Poh, Chemom. Intell. Lab. Syst. 104, 347 (2010).
[CrossRef]
[12] D. Cozzolino, I. Murray, A. Chree, J. R. Scaife, LWT –, Food Sci. Technol. (Campinas.), 38, 821 (2005).
[13] A. Shigetani, N. Yoshimura, M. Takayanagi, J. Spectrosc. Soc. Jpn. 58, 268 (2009).
[14] B. S. Dayal, J. F. MacGregor, J. Chemometr. 11, 73 (1997). [CrossRef]
[15] O. M. kvalheim, Chemom. Intell. Lab. Syst. 2, 283 (1987).
[CrossRef]
[16] O. M. kvalheim, Chemom. Intell. Lab. Syst. 8, 59 (1990).
[CrossRef]
[17] N. Yoshimura, A. Shigetani, M. Takayanagi, J. Comput. Chem. Jpn. 8, 183 (2009). [CrossRef]
Chemometrics Calculations with Microsoft Excel (6)
− PLS Regression −
Norio YOShIMuRA*, and Masao TAkAYANAGI
Graduate School of Agriculture, Tokyo university of Agriculture and Technology,
3-5-8 Saiwaicho Fuchu, Tokyo 183-8509 Japan
*e-mail: [email protected]
Although chemometrics has become widely used recently for analyzing experimental chemical data, there exist only a few instructions for the proper usage of chemometrics other than those in some introductory books. As the sixth step of chemometrics calculations with Microsoft Excel (Excel), the partial least-squares (PLS) regression (PLSR) is performed on worksheets. The worksheets were prepared for generating the spectra of model calibration samples and unknown samples, obtaining latent variables by PLS1 (single objective variable model) and by PLS2 (multi objective variable model), and constructing quantitative model by PLSR. The quantitative performances of PLSR and PCR were compared by using the generated unknown spectra. PLSR model with PLS1 has good performance with a small number of factors for the chemical species using objective variable. PLSR modeling with PLS2 computes stable results for each chemical species. These results indicate that PLSRs are superior to PCR, when a small number of factors are used. however, it is not obvious which method produces the best quantitative model. For getting the best model, it is necessary to compare the methods using various factors.
付:クロスバリデーション(CV)の手順
CVでは次のような手順で検証を行う(leave-one-out法の 場合). • n = 1より始める. {1}スペクトル行列Aと濃度情報行列Cから試料nの スペクトルanと濃度情報cnを抜いてA(−n), C(−n)を得る. {2}A(−n)とC(−n)をPLSやPCAを用いてウェイト,ロー ディング,スコアベクトルを求める. • f = 1より始める {3}第f因子までを用いて検量モデルを構築する. {4}構築した検量モデルにanを適用し,試料n中の化 学種lの濃度clnの予測値c′lnfを求める.{5}化学種lの予測濃度の相対誤差(relative error: RE) RElnf =clnf′ −c cln ln (I) を求める • 最大の因子数になるまでiを1つ増やし{3}に戻る • すべての試料について行われるまで,nを1つ増 やし{1}に戻る. {7}因子数ごとにAREを求める. 1 RE ARE N lnf n lnf = = N
∑
(N は試料数 ) (II). • AREが最小となる因子数の場合を最適モデルとし て採用する. ここでは,本文の内容と合わせるために評価基準 としてAREを用いたが,一般には予測残差二乗和 (prediction residual sum of squares: PRESS)2 1 PRESS N ( lnf ln) n c c = ′ =