意味表現を活用する
文生成モデルの検討
タスク : Abstractive Summarization
At least two people were killed in a suspected bomb attack on a passenger bus in the strife-torn southern
Philippines on Monday, the military said.
入力文
At least two dead in southern Philippines blast
出力 ( 要約文 )
生成
( 復習 ) Encoder-Decoder って何 ?
https://github.com/google/seq2seq
素の Decoder はよく間違える
Seq2Seq + Attention
の出力文[See+ 2017]
モデルのついた”ウソ”
双方向 Encoder-Decoder [Tu+ 2016]
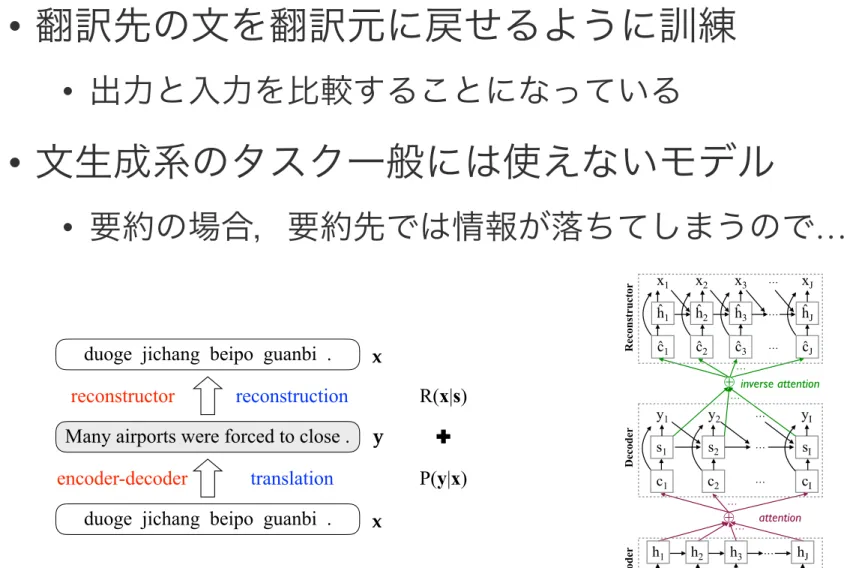
Neural Machine Translation with Reconstruction
Zhaopeng Tu † Yang Liu ‡ Lifeng Shang † Xiaohua Liu † Hang Li †
† Noah’s Ark Lab, Huawei Technologies, Hong Kong
{ tu.zhaopeng,shang.lifeng,liuxiaohua3,hangli.hl } @huawei.com
‡ Department of Computer Science and Technology, Tsinghua University, Beijing [email protected]
Abstract
Although end-to-end Neural Machine Translation (NMT) has achieved remarkable progress in the past two years, it suffers from a major drawback: translations generated by NMT sys- tems often lack of adequacy. It has been widely observed that NMT tends to repeatedly translate some source words while mistakenly ignoring other words. To alleviate this problem, we propose a novel encoder-decoder-reconstructor frame- work for NMT. The reconstructor, incorporated into the NMT model, manages to reconstruct the input source sentence from the hidden layer of the output target sentence, to ensure that the information in the source side is transformed to the target side as much as possible. Experiments show that the proposed framework significantly improves the adequacy of NMT out- put and achieves superior translation result over state-of-the- art NMT and statistical MT systems.
Introduction
Past several years have observed a significant progress in Neural Machine Translation (NMT) (Kalchbrenner and Blunsom 2013; Cho et al. 2014; Sutskever, Vinyals, and Le 2014; Bahdanau, Cho, and Bengio 2015). Particularly, NMT has significantly enhanced the performance of translation between a language pair involving rich morphology predic- tion and/or significant word reordering (Luong and Manning 2015; Bentivogli et al. 2016). Long Short-Term Memory (Hochreiter and Schmidhuber 1997) enables NMT to con- duct long-distance reordering, which is a significant chal- lenge for Statistical Machine Translation (SMT) (Brown et al. 1993; Koehn, Och, and Marcu 2003).
Unlike SMT which employs a number of components, NMT adopts an end-to-end encoder-decoder framework to model the entire translation process. The role of encoder is to summarize the source sentence into a sequence of latent vectors, and the decoder acts as a language model to gen- erate a target sentence word by word by selectively lever- aging the information from the latent vectors at each step.
In learning, NMT essentially estimates the likelihood of a target sentence given a source sentence.
However, conventional NMT faces two main problems:
1 Translations generated by NMT systems often lack of ad- equacy. When generating target words, the decoder often Copyright © 2017, Association for the Advancement of Artificial Intelligence (www.aaai.org). All rights reserved.
duoge jichang beipo guanbi . Many airports were forced to close .
duoge jichang beipo guanbi .
translation reconstruction
x y x
P(y|x) R(x|s)
✚ encoder-decoder
reconstructor
Figure 1: Example of NMT with reconstruction. Our idea is to leverage reconstruction score R(x | s) as an auxiliary objective to measure the adequacy of translation candidate, where s is the target-side hidden layer in decoder for gen- erating the translation y. Linear interpolation of likelihood score P (y | x) and reconstruction score is used to (1) improve parameter learning for generating better translation candi- dates in training, and (2) conduct better rerank of generated candidates in testing.
repeatedly selects some parts of the source sentence while ignoring other parts, which leads to over-translation and under-translation (Tu et al. 2016b). This is mainly due to that NMT does not have a mechanism to ensure that the information in the source side is completely transformed to the target side.
2 Likelihood objective is suboptimal in decoding. NMT utilizes a beam search to find a translation that maxi- mizes the likelihood. However, we observe that likeli- hood favors short translations, and thus fails to distin- guish good translation candidates from bad ones in a large decoding space (e.g., beam size = 100). The main rea- son is that likelihood only captures unidirectional depen- dency from source to target, which does not correlate well with translation adequacy (Li and Jurafsky 2016;
Shen et al. 2016).
While previous work partially solves the above prob- lems, in this work we propose a novel encoder-decoder- reconstructor model for NMT, aiming at alleviating these problems in a unified framework. As shown in Figure 1, given a Chinese sentence “duoge jichang beipo guanbi .”, the standard encoder-decoder translates it into an English sen- tence and assigns a likelihood score. Then, the newly added
arXiv:1611.01874v2 [cs.CL] 21 Nov 2016
⨁
h
1h
2h
3 …h
J…
c
1c
2 …c
Is
1s
2 …s
Iĥ
1ĥ
2ĥ
3 …ĥ
Jĉ
1ĉ
2ĉ
3 …ĉ
J⨁ inverse attention
Encoder
…
…
…
DecoderReconstructor
attention
x
1x
2x
3 …x
Jy
1y
2 …y
Ix
1x
2x
3 …x
JFigure 2: Architecture of NMT with reconstruction, which introduces a reconstructor to map from the hidden layer at the target side to the original input.
• Added reconstructor reads the hidden state sequence from the decoder and outputs a score of exactly reconstructing the input sentence, which we will describe below.
Reconstructor As shown in Figure 2, the reconstructor re- constructs the input. Here we use the hidden layer at the tar- get side as the representation of the translation, since it plays a key role in generation of the translation. We aim at encour- aging it to embed complete source information, and in the meantime to reduce the complexity of model and make the training easy.
Specifically, the reconstructor reconstructs the source sen- tence word by word, which is conditioned on the inverse context vector c ˆ
jfor each input word x
j. The inverse context vector ˆ c
jis computed as a weighted sum of hidden layers s at the target-side:
ˆ c
j=
X
I i=1ˆ
↵
j,i· s
i(4) The weight ↵ ˆ
j,iof each hidden layer s
jis computed by an added inverse attention model, which has its own parameters independent from the original attention model. The recon- struction probability is calculated by
R(x | s) = Y
Jj=1
R(x
j| x
<j, s)
= Y
J j=1g
r(x
j 1, ˆ h
j, ˆ c
j) (5)
Figure 3: Illustration of testing with reconstructor.
where h ˆ
jis the hidden state in the reconstructor, and com- puted by
ˆ h
j= f
r(x
j 1, ˆ h
j 1, ˆ c
j) (6) Here g
r( · ) and f
r( · ) are softmax function and activa- tion function for the reconstructor, respectively. The source words x share the same word embeddings with the encoder.
Training
Formally, we train both the encoder-decoder P(y | x; ✓) and the reconstructor R(x | s; ) on a set of training examples { [x
n, y
n] }
Nn=1, where s is the state sequence in the decoder after generating y, and ✓ and are model parameters in the encoder-decoder and reconstructor respectively. The new training objective is:
J (✓, ) = arg max
✓,
X
N n=1⇢
log P (y
n| x
n; ✓)
| {z } likelihood + log R(x
n| s
n; )
| {z } reconstruction
(7)
where is a hyper-parameter that balances the preference between likelihood and reconstruction.
Note that the objective consists of two parts: likelihood measures translation fluency, and reconstruction measures translation adequacy. It is clear that the combined objective is more consistent with the goal of enhancing overall trans- lation quality, and can more effectively guide the parameter training for making better translation.
Testing
Once a model is trained, we use a beam search to find a trans- lation that approximately maximizes both the likelihood and reconstruction score. As shown in Figure 3, given an input sentence, a two-phase scheme is used:
1 The standard encoder-decoder produces a set of transla-
tion candidates, each of which is a triple consisting of
a translation candidate, its corresponding hidden layer at
the target-side s, and its likelihood score P.
イメージ : 出力と入力を比較したい
At least two people were killed in a suspected bomb attack on a
passenger bus in the strife-torn
southern philippines on monday , the military said .
入力文
At least two dead in southern philippines blast
出力
生成
イメージ : 出力と入力を比較したい
At least two people were killed in a suspected bomb attack on a
passenger bus in the strife-torn
southern philippines on monday , the military said .
入力文
At least two dead in southern philippines blast
出力 生成
何か処理 何か処理
比較
スコアリング
入力文の 意味表現
出力文の
意味表現
Q1: 文の意味表現には何を使うのか?
At least two people were killed in a suspected bomb attack on a
passenger bus in the strife-torn
southern philippines on monday , the military said .
入力文
At least two dead in southern philippines blast
出力 生成
何か処理 何か処理
比較
スコアリング
ここに何を使う?
入力文の 意味表現
出力文の
意味表現
Q2: 比較・スコアリングをどうモデル化するのか?
At least two people were killed in a suspected bomb attack on a
passenger bus in the strife-torn
southern philippines on monday , the military said .
入力文
At least two dead in southern philippines blast
出力 生成
何か処理 何か処理
比較
スコアリング
ここをどうやってモデル化する?
入力文の 意味表現
出力文の
意味表現
クエスチョンのまとめ
At least two people were killed in a suspected bomb attack on a
passenger bus in the strife-torn
southern philippines on monday , the military said .
入力文
At least two dead in southern philippines blast
出力 生成
何か処理 何か処理
比較
スコアリング
入力文の 意味表現
出力文の 意味表現
• Q1: 文の意味表現には何を使うのか?
• Q2: 比較・スコアリングをどうモデル化するのか?
この2つについて考えていることを話します
Q1: 文の意味表現には何を使うのか?
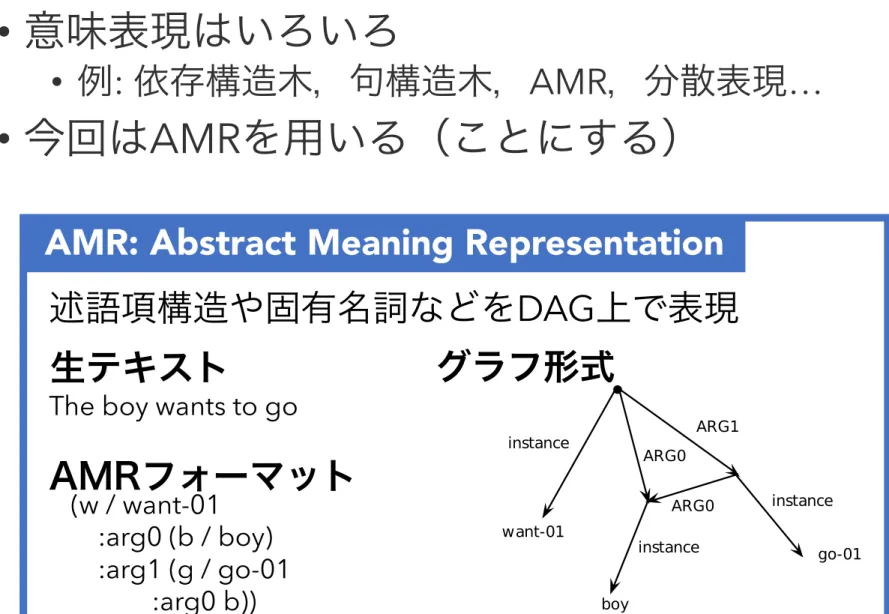
AMR: Abstract Meaning Representation
The boy wants to go
(w / want-01
:arg0 (b / boy) :arg1 (g / go-01
:arg0 b))
生テキスト
AMRフォーマット
グラフ形式
tions or provide alignments that reflect such rule sequences. This makes sembanking very fast, and it allows researchers to explore their own ideas about how strings are related to meanings.
• AMR is heavily biased towards English. It is not an Interlingua.
AMR is described in a 50-page annotation guide- line. 1 In this paper, we give a high-level description of AMR, with examples, and we also provide point- ers to software tools for evaluation and sembanking.
2 AMR Format
We write down AMRs as rooted, directed, edge- labeled, leaf-labeled graphs. This is a completely traditional format, equivalent to the simplest forms of feature structures (Shieber et al., 1986), conjunc- tions of logical triples, directed graphs, and PEN- MAN inputs (Matthiessen and Bateman, 1991). Fig- ure 1 shows some of these views for the sentence
“The boy wants to go”. We use the graph notation for computer processing, and we adapt the PEN- MAN notation for human reading and writing.
3 AMR Content
In neo-Davidsonian fashion (Davidson, 1969), we introduce variables (or graph nodes) for entities, events, properties, and states. Leaves are labeled with concepts, so that “(b / boy)” refers to an in- stance (called b) of the concept boy. Relations link entities, so that “(d / die-01 :location (p / park))”
means there was a death (d) in the park (p). When an entity plays multiple roles in a sentence, we employ re-entrancy in graph notation (nodes with multiple parents) or variable re-use in PENMAN notation.
AMR concepts are either English words (“boy”), PropBank framesets (“want-01”), or special key- words. Keywords include special entity types (“date-entity”, “world-region”, etc.), quantities (“monetary-quantity”, “distance-quantity”, etc.), and logical conjunctions (“and”, etc).
AMR uses approximately 100 relations:
• Frame arguments, following PropBank con- ventions. :arg0, :arg1, :arg2, :arg3, :arg4, :arg5.
1 AMR guideline: amr.isi.edu/language.html
LOGIC format:
∃ w, b, g:
instance(w, want-01) ∧ instance(g, go-01) ∧ instance(b, boy) ∧ arg0(w, b) ∧
arg1(w, g) ∧ arg0(g, b)
AMR format (based on PENMAN):
(w / want-01
:arg0 (b / boy) :arg1 (g / go-01
:arg0 b))
GRAPH format:
Figure 1: Equivalent formats for representating the mean- ing of “The boy wants to go”.
• General semantic relations. :accompa- nier, :age, :beneficiary, :cause, :compared- to, :concession, :condition, :consist-of, :de- gree, :destination, :direction, :domain, :dura- tion, :employed-by, :example, :extent, :fre- quency, :instrument, :li, :location, :manner, :medium, :mod, :mode, :name, :part, :path, :po- larity, :poss, :purpose, :source, :subevent, :sub- set, :time, :topic, :value.
• Relations for quantities. :quant, :unit, :scale.
• Relations for date-entities. :day, :month, :year, :weekday, :time, :timezone, :quarter, :dayperiod, :season, :year2, :decade, :century, :calendar, :era.
• Relations for lists. :op1, :op2, :op3, :op4, :op5, :op6, :op7, :op8, :op9, :op10.
AMR also includes the inverses of all these rela- tions, e.g., :arg0-of, :location-of, and :quant-of. In addition, every relation has an associated reification, which is what we use when we want to modify the relation itself. For example, the reification of :loca- tion is the concept “be-located-at-91”.
述語項構造や固有名詞などを DAG 上で表現
Q2: 比較・スコアリングをどうモデル化するのか?
At least two people were killed in a suspected bomb attack on a
passenger bus in the strife-torn
southern philippines on monday , the military said .
入力文
At least two dead in southern philippines blast
出力 生成
AMR Parse AMR Parse
比較
スコアリング
入力文の AMR
出力文の AMR
• Q1: 文の意味表現には何を使うのか?
• A1: AMRを使う
• Q2: 比較・スコアリングをどうモデル化するのか?
Q2: 比較・スコアリングをどうモデル化するのか?
比較
スコアリング
入力文の AMR
出力文の AMR
①述語項構造の一致
入力 shrink-01
deficit
:Arg01
出力 narrow-01
deficit
:Arg01
Entity
まわりの構造は一致して欲しい②出力は入力の部分グラフ 入力文の
AMR
出力文のAMR
「部分グラフっぽさ」を設計する必要
ここをどう作る?
入力と出力のAMRに満たして欲しい関係の例
入力文・出力文の AMR を確認してみた
Libyan leader Moamer Kadhafi Monday promised wide political and economic reforms that he said would see ministries dismantled and oil revenues going directly into the pockets of the people.
Kadhafi promises wide political
economic reforms
入力文・出力文の AMR を確認してみた
Libyan leader Moamer Kadhafi Monday promised wide political and economic reforms that he said would see ministries dismantled and oil revenues going directly into the pockets of the people.
Kadhafi promises wide political economic reforms
AMR-Parse AMR-Parse
(v5 / promise-01 :ARG0 "monday"
:ARG0 (v3 / person
:name (v4 / name :op1 "moamer"
:op2 "kadhafi")
(v2 / promise-01
:ARG2 (v1 / kadhafi)
:ARG1 (v6 / reform-01 :ARG1 (v5 / economy) :mod (v4 / politics)
:ARG1-of (v3 / wide-02) :ARG0 v1))
パーザの間違いが原因で述語項は一致しない
パーザの間違いを許容してモデルを考える
①述語項構造の一致
入力 shrink-01
deficit
:Arg01
出力 narrow-01
deficit
:Arg01
②出力は入力の部分グラフ 入力文の
AMR
出力文のAMR
これらの制約をハードに組み込むことは難しそう
案 1: N-Best のリランキング
At least two people were killed in a suspected bomb attack on a passenger bus in the strife-torn southern…
Beam search
Encoder-Decoder
At least two dead in
southern philippines blast
N -Be st
MAX
案 1: N-Best のリランキング
At least two people were killed in a suspected bomb attack on a passenger bus in the strife-torn southern…
Beam search
Encoder-Decoder
リランカー
At least two dead in
southern philippines blast
N -Be st Re -ra nk ed
MAX
案 2: 正しい AMR を当てるように訓練
At least two people were killed in a suspected…
< , < Encoder-Decoder < Two people dead , <
At least two… At least two… At least two… At least two… At least two… At least two… At least two… Two people dead
適当にサンプリング 要約文の集合
Two are alive and
< , <
① 正解のAMRを用意(正例)
② 要約文の集合から適当にAMRをサンプリング(負例)
③ 正例と負例を区別できるように適当なネットワークを訓練
何かネットワーク 何かネットワーク
• Graph Convolution
• Tree-LSTM
•
線形化してLSTM
, ,
を最適化する
何かネットワーク