論 文
論文特集 ■ ヒューマンインタフェースとバーチャルリアリティバーチャルスタジオ撮影における実演での 3 次元仮想物体提
示のための適応的レジストレーション
Use of Adaptive Registration for Improving Presentation of
Three-Dimentional Virtual Objects in a Virtual Studio
尾 原 秀 登
†,
松 村晋 吾
*
†,
角 所
考
††,
美 濃 導 彦
†† Hideto Obara†, Shingo Matsumura†, Koh Kakusho†† and MiChihiko Minoh††Abstract We propose a studio system called an “interactive virtual studio”, in which an actor looks directly at virtual objects and manipulates them in a virtual studio. In a conventional virtual studio, such as that often used for recent TV programs, real images of actors are taken by cameras in a studio and superimposed with three dimensional (3D) virtual objects created by computer graphics (CG), so that they are presented to the viewers. However, the actors in the studio cannot see the virtual objects nor manipulate them directly. We introduced augmented reality (AR) to the virtual studio in order to enable them to do this. In our interactive virtual studio, the actors wear wearable displays (WD) so they can see the virtual objects. The actors are thus able to manipulate the virtual objects directly by using a pointer with a three-dimentional sensor on its end. To make this system, it is necessary to maintain a spatial relationship among the different coordinate systems that describe the real space, the virtual space, and the video images presented to the viewer. In the previous work, this geometric registration was made by setting several sample points and collecting errors between the coordinate systems. In contrast, we carry out the geometric registration adaptively with the following process. The actor manipulates virtual objects based on the constraints between three positions: that of the virtual objects, that of the pointer used for manipulating the objects in the virtual space and that of the image presented to the viewers.
キーワード:レジストレーション,マニピュレーション,バーチャルスタジオ,アウグメンテッドリアリティ
1.
ま え が き近年,e-learningの普及により,Course Management
System(以下CMS)を用いた教育が盛んになってきてい る1)2).CMSでは,テキストだけでなく,静止画や動画, 3次元(3D)仮想物体に対する視点移動・操作に至るまで, 様々な表現を用いた視覚的にわかりやすい教材が提示でき る3) .一方,従来から行われてきた講義による教育では, 用いられる教材自体はスライドや板書などに限定されるも のの,講師自身がそのような教材を,スライドのページを めくる,板書を書き加える,指示棒で指示する等の実演に 2005 年 10 月 31 日受付,2007 年 3 月 14 日最終受付,2007 年 4 月 26 日 採録 † 京都大学 大学院 情報学研究科, *現在 KOEI (京都市左京区吉田二本松町 京都大学学術情報メディアセンター南館) †† 京都大学 学術情報メディアセンター (京都市左京区吉田二本松町 京都大学学術情報メディアセンター南館)
† Graduate School of Infomatics ,Univ. of Kyoto
(Kyoto, sakyou-ku, yoshida-nihonmatsu-tyou, Academic Center for Computing and Media Studies)
†† Accademic Center for Computing and Media Studies
(Kyoto, sakyou-ku, yoshida-nihonmatsu-tyou, Academic Center for Computing and Media Studies)
よって提示しながら,説明を行うため,迫真性や訴求力の 点でCMSに大きく勝る.このため,講義を基本として,そ の予復習用にCMSを利用するというように,両者が相補 的な形で利用されることが多い.ただし講義はCMSとは 異なり,受講できる時間・場所が限定されることから,近 年特に大学等の高等教育では,講義をアーカイブ化して, 時間・場所の制約なく提供する試みが始まっている4)∼6). 上述のように講義や講義アーカイブでは,講師の実演に基 づく教材提示が行える点が特徴であるが,その対象となる 教材自体は,前述のようにスライド板書等,講義室のスク リーンや黒板で提示可能な2次元(2D)のものに限定され る.そこで本研究では,CMS用教材と講義との利点を兼ね 備えた教育用コンテンツとして,CMS用に作成された3D 仮想物体による教材を使用し,これを講師が実演に基づい て提示しながら説明するような映像を作成することを目標 とし,そのための映像撮影環境を実現することを目的とす る.ただし,ここで“3D仮想物体による教材の実演に基づ く提示”とは,具体的には,講師が現実物体の指示棒を用 いて3D仮想物体の教材を指示し,その指示操作によって, 説明の対象となる仮想物体上の領域を視聴者に伝えるとと
図 1 VS のシステム構成 The composition of VS. もに,その領域に対して,引き出し線による説明表示や着 色などの視覚効果を自在に用いることができるような教材 提示のことを意味する. 本研究では,まず,実物の演者と仮想物体とが重畳した 映像を撮影するために,従来から放送局などで用いられて いるバーチャルスタジオ(VS)7)を基盤として,これに拡 張現実感(AR)8)の技術を導入することによって,上のよ うな教材提示を伴う映像撮影が可能な“インタラクティブ なVS(IVS)”を実現することを提案する.次に,そのよう なIVSで実演に基づく教材提示を実現する上で障害となる レジストレーション誤差の問題に焦点を当て,この誤差を, 映像撮影の際に行われるリハーサルの過程を利用して適応 的に補正するための手法を提案する. 以下まず2章では,3D仮想物体による教材の実演に基づ く提示を行う上で,VSの持つ問題点について説明し,それ を解決するためのIVSの構成方法を提案する.さらにこの ようなIVSで実演に基づく教材提示を実現する上で障害と なるレジストレーション誤差の問題について説明するとと もに,この問題に対する従来研究の問題点や,それに対して 本研究で新たに導入するアプローチについて述べる.この アプローチに基づくレジストレーション誤差補正の具体的 な手続きについて説明するために,続く3章においてIVS における教材提示のための幾何学的なレジストレーション の問題を定式化し,この定式化に基づいて4章で適応的な レジストレーションの具体的な手続きについて述べる.5章 では,この手続きの有効性を確認するための実験結果を示 し,最後に6章でまとめと今後の課題について述べる.
2.
映像撮影における3
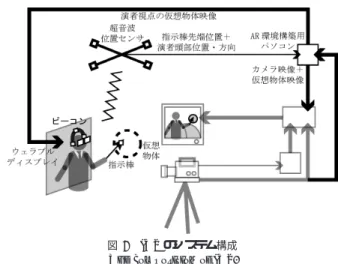
次元仮想物体の実演提示 2. 1 バーチャルスタジオ(VS)の問題点 実物の演者と3D仮想物体とが融合した映像を撮影する ためのシステムとして,従来から放送局などで用いられて いるVSがある(図1) . 通常のVSでは,演者は仮想物体が直接視認できないた め,フロアモニタで合成画像を確認しながら演技を行うこ とが要求される.しかし,1章で述べたような講師の実演 に基づく教材提示による映像コンテンツを作成する場合, 演者となるのは一般の講師であり,演技の素人であるため, 図 2 IVS のシステム構成 The composition of IVS.フロアモニタを視認しながら教材への指示動作を行うこと は簡単ではない. また,VSでは,演者の動きを計測する機能がないため, 演者が指示棒で仮想物体を指示しても,それに合わせて引 き出し線の表示や着色などの視覚効果を生成することはで きない.このため,VSを用いて演者と仮想物体がインタ ラクションしているような映像を撮影する場合には,副調 整室にいるオペレータが演者の動きを見ながらそれに合わ せて,仮想物体の視覚効果を付与するという方法が採られ る.しかし,このような方法では,通常の講義でスライド やアニメーションを提示する場合のように,演者である講 師自らが自分のペースで主体的に教材提示を行うことがで きない. 2. 2 インタラクティブバーチャルスタジオ そこで本研究では,AR技術を導入してVSを図2に示 すような形で拡張することにより,演者が仮想物体を直接 視認しながら,それを実演に基づいて提示できるIVSを構 築することを提案する(図2).図中の濃い部分がVSから 拡張された所である. 通常のAR環境において,演者の頭部の動きに追随する 形で3D仮想物体を提示するには,ヘッドマウントディス プレイ(HMD)が利用される場合が多いが,スタジオ撮影 の場合,仮想物体を提示する相手となるユーザは演者であ り,映像撮影の被写体でもあるため,仮想物体提示のため に通常のAR環境と同様にHMDを装着させると,それを 撮影した映像は,視聴者にとっては非常に見苦しいものと なってしまう.このため本研究では,日常生活での常時装 着を想定して設計されているため,見苦しさの問題が少な いウェラブルディスプレイ(WD)を利用する(図3(a)). WDはHMDとは違い単眼ディスプレイのものが多く, 両眼視差の提示ができないが,仮想物体画像がもう一方の 眼から得られる現実世界の視点情報と重なって見えるため, 仮想物体の表示サイズや透視変換を利用することにより,仮 想物体が3D空間中でそれに応じた位置に存在するように 見せることができる. WDに表示する仮想物体画像は,AR環境構築用PCに
(a)WD (b)Wireless movie transceiver
(c)Rod with a beacon (d)Headset with beacons
(e)The aspect
図 3 IVS に利用した機器およびその様子 The items of equipment of IVS.
より描画するが,このPCをモバイル型にして演者に装着 させると,演者の負担になるばかりでなく,モバイルPC の描写性能の点でも問題がある.一方,PCをタワー型に してWDとディスプレイケーブルで接続すると,ケーブル が映像中に映り込んでしまうだけでなく,演者の行動を阻 害する.そこで本研究では,描画にはタワー型PCを利用 し,この映像信号をアナログ変換したものを無線映像送信 機を用いてWDに無線伝送する一方,WDでは無線映像 受信機から得られたアナログ映像信号を利用して映像を表 示するという方法を採る.これにより,演者は腰に小型で 軽量の無線映像受信機だけを装着すれば充分となる. 映像撮影の際,演者は説明に応じて身体の位置や頭部の 向きを変化させる.このことから,WDを用いて演者に仮 想物体を提示する際には,演者の頭部の動きに応じてWD の表示内容を変化させる必要がある.このための演者の頭 部の位置・姿勢の計測方法として,本研究では超音波セン サを利用する.超音波センサは,超音波を発するビーコン の位置をワイヤレスで計測できるため,演者が装着する必 要があるのは小型のビーコンのみであり,演者の動きに対 する制約が少ない.ただし1個のビーコンでは3次元位置 図 4 教材提示における指示動作 The kind of pointing at a lecture.
のみしか計測できず,頭部の向きも計測するために,演者 の頭部に3個のビーコンが必要となる.本研究では撮影の 際,副調整室からの縁者への指示と演者の音声の収録を行 うために,演者にワイヤレス式のヘッドセットを装着して もらうことが想定されることから,このヘッドセットに対 して3個のビーコンを装着する.この3個のビーコンの3 次元位置から求められる演者の頭部の位置・姿勢をもとに, 演者の視点位置・視線方向での仮想物体画像をAR環境構 築用PCで描写し,WDに無線伝送する. また,実演による教材提示のためには,演者が用いる指 示棒の動きも計測する必要がある.このために指示棒の先 端にも前述の超音波センサのビーコンを装着してその3次 元位置を計測する.
以上で述べたIVSを,Vizrt社のVSであるINCA2100
に以下の機器を追加することで構築した(図3).
•超音波センサ: 産業技術総合研究所U3DTracker
•WD: Micro Optical社EG-8(図3(a)右上)
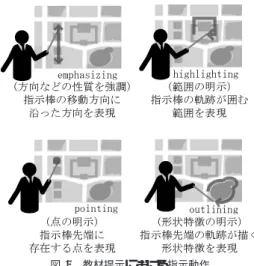
•無線映像送受信機: COMPAL社 V-Catapult2(受信 機は図3(a)中央,送信機は図3(e)右上) •AR環境構築用PC: PentiumIV1.5GHzのCPUを搭 載(図3(e)右) •ビーコンを取り付けた指示棒(図3(c)) •ビーコンを取り付けたヘッドセット(図3(d)(f)) 2. 3 IVSにおけるレジストレーション誤差 教材提示における指示動作には,pointing・highlighting・ outlining・emphasizingの4種類があり15),それぞれの種 類によって指示棒の先端が指し示す対象領域は図4のよう に変化する. このような指示動作によって対象物体上に定まる領域を, 本研究では指示対象領域と呼ぶことにする.実演に基づく 教材提示の特徴は,このような指示対象領域が,演者自身 の動かす指示棒の動きによって表現され,視聴者に伝えら れることであるから,2. 2で提案したIVSによる映像撮影 でも,これを実現することが目標となる. これに対して,2. 2で述べたIVSでは,処理に関わる様々
な位置情報が,異なる空間・平面内の位置として得られる. すなわち,演者の頭部や指示棒はスタジオ内の実世界中( 現実空間 Rとするに存在し,仮想物体はPC内に表現さ れた3次元仮想世界中(仮想空間 V とする) に存在する. さらに演者がWDに基づいて仮想物体を知覚する位置は, 演者自身が知覚する空間(知覚空間 M とする)に存在し, 視聴者に提示される合成画像は,スタジオカメラの画像平 面を基準とした合成画像の描写用の画像平面(合成画像平 面Sとする)上に存在する.以下では,これらの空間や平 面同士の間で互いに対応する点の位置や,誤差による位置 ずれを表すために,それぞれの記号の右肩に,空間・平面 を表す記号R, M, V, Sを付ける. 上のような複数の空間を介して,演者が現実空間中の指 示棒で仮想空間中の仮想物体上の点qV の指示操作を実現 するには,図5(a)の折れ線矢印AのようにqV が知覚空 間・現実空間の対応点qM, qRへと順次対応付けられなけ ればならない. さらに,その指示操作が視聴者にも正しく伝わるために は,qV とqRが同図矢印Bのように,合成画像平面上にお いて同一の対応点qS に対応付けられなければならない. しかし,演者がWDを用いて仮想空間を知覚する際や, 現実空間中の指示棒をセンサで計測する際には,誤差(それ ぞれ知覚誤差ε1,センサ誤差ε2とする)が生じる.このよ うな誤差のため図5(b)の矢印A0のように,qMがqM+εM1 へ,さらにそれに対応するqV + εV1 がqV + εV1 + εV2 へと ずれ,その結果,もともとqV に対して意図された操作が qV + εV 1 + εV2 に対して実行されたように,システムに伝 わるという操作誤りが起きる.さらに,仮想カメラをモデ ル化するためのスタジオカメラのキャリブレーションに誤 差(キャリブレーション誤差ε3とする)が含まれた場合に は,同図矢印B0のように,現実空間の点qR+ εR1 が合成 画像平面上でqS+ εS 1 とはさらに異なる点qS+ εS3 に表示 されてしまう表示誤りが起きる.以下ではこれら知覚誤差・ センサ誤差・キャリブレーション誤差を合わせてレジスト レーション誤差と呼ぶ. 2. 4 レジストレーション誤差に対する従来研究 上述のレジストレーション誤差の問題のうち,センサ誤 差や知覚誤差,およびそれに起因する操作誤りについては, IVSだけではなく,通常のAR環境における仮想物体操作 においても生じる問題である.このための幾何学的レジスト レーションの方法として,従来のARの研究では,qM+εM1 をqM に,qV + εV 2 をqV に補正するといったように,そ れぞれの誤差ε1, ε2を個別に補正するアプローチがとられ てきた9)∼11).ところが,このような補正を行うには補正 先の正しい位置qM, qV を知る必要がある.しかし,qMは 知覚空間内の点のため,正しい位置は演者にしかわからな い.また,qM を得るために現実空間においてqRの位置 を誤差なく計測するのは困難である.そこで従来研究では, いくつかの基準点の位置を予め何らかの方法で獲得してお (a)No error (b)Established methods (c)Adaptive registration 図 5 IVS における空間同士の関係 The relationship of the space in IVS.
き,その点を基準にして空間全体の誤差を操作に先立って 補正するというアプローチがとられてきた. これに対し,著者らの先行研究では,AR 環境におけ る現実物体のポインタを用いた仮想物体操作において, qV + εV 1 + εV2 として得られるポインタ位置に対して,こ
れが仮想物体上に存在しないなど,仮想物体操作が成立す るための条件が満たされない場合に,その条件が満たされ るように位置を補正することにより,操作の過程を通じて 適応的にレジストレーション誤差を補正する手法を提案し ている(図5(c)).この方法では,知覚誤差,センサ誤差の それぞれが直接補正されるわけではないが,従来研究のよ うに基準点を設定することなく,操作の実現に必要な精度 での誤差補正を実現できる12). 2. 5 IVSにおける適応的レジストレーションの課題 (1) 表示誤りの補正 IVSに上のような適用的なレジストレーションを適用す る場合,qR+εR 1 は変化しないため,その結果としてqS+εS1 とqS+ εS3 もずれたままとなり表示誤りの問題は解決され ない.すなわち,IVSでは操作誤りの補正に加えて,何ら かの方法で表示誤りを補正する手法が必要となる. 表示誤りの適応的補正において,qS+ εS3の補正先となる qS+ εS 1 は,システムには獲得されていないため,本研究 では,指示棒の先端を赤くマーキングすることにより,合 成画像平面上で指示棒の先端を検出し,これをqS+ εS1 と して獲得する(図5(c)(1)).この点を補正する際,先行研究 では,ポインタは仮想物体の表面に位置するといった制約 を用いたが,合成画像平面は3次元空間の投影像であるた め,ポインタが3次元空間内で物体表面に存在しても,画 像平面上ではポインタの先端が仮想物体領域に入ることも 起こりうるため,このような制約は用いることができない. この問題に対して本研究では,一章で述べたように仮想物 体として用いるCMS教材では,その利用のために指示対 象となる領域は既知であることから問題を解決できる.こ こで先行研究と同じ方法で表示誤りの適応的補正を行う場 合は,表示誤りの生じている合成画像平面上で位置ずれを 補正することになるが,合成画像平面上での接触関係に基 づいて表示誤りを補正すると,3次元空間の投影像である 合成画像平面では,空間内の任意の2点間の距離関係が保 持されないため,視聴者に適切でない位置に補正されてし まう.そこで本研究では仮想空間内の位置関係に基づいて 表示誤りを補正することを考える.このとき,qS+ εS1 の 位置は合成画像平面上でしか得られていないため,これを 仮想空間内に逆投影TS−1することにより(同図(c)(2)),前 述のCMS教材での既知の指示対象領域に基づいて,補正 先となるべき点の位置を求める(同図(c)(3)).それを合成 画像平面に再投影することにより表示誤りの補正を行う. (2) 指示対象領域の獲得 2. 6 演者の頭部の動きへの対応 文献12)の手法は,AR環境においてHMDを装着した ユーザが,椅子に座った状態で仮想物体を操作する状況を 想定しているため,頭部の動きは考慮していない.これに 対して,本稿のIVSでは演者の頭部の動きを計測し,それ によってWDの表示内容が変化する.このような場合に, 演者がWDの表示内容を基に仮想物体の位置を知覚する際 の知覚特性は,一律不変とは限らず,WDの表示内容の変 化に伴って変化する可能性がある.特にWDはHMDと は異なり,両眼視差のような比較的安定的な立体を把握の ための手掛かりが利用できないため,この危険性が高いと 考えられる.操作誤り,表示誤りいずれの補正においても, 演者の知覚特性の変化に対応できるように補正方法を拡張 する必要がある. そこで本研究では,補正を実現する際に,各空間・平面 内での位置の次元に加えて,演者の頭部の位置・姿勢の次 元を追加し,仮想空間や合成画像平面の同一位置に対して, 頭部の位置・姿勢毎に異なる補正先qV が設定できるよう に拡張する.これにより,演者が同じ指示対象領域を同じ 指示棒先端位置で指示した場合でも,そのときの頭部の位 置・姿勢に応じて,異なる補正先qV への補正が行われる ことになる. 以上のような補正は,リハーサル撮影時の演者による物 体指示過程を通して実行し,得られた補正内容を本番の撮 影時に適用する.このための具体的な処理内容について説 明するために,まず次章で,2. 3で述べたIVSにおける幾 何学的レジストレーション誤差の問題を定式化し,これを 基に,その次の章で,上のアプローチによる操作誤りと表 示誤りの補正処理の具体的な実現手続きを改めて説明する.
3. IVS
におけるレジストレーションの定式化 3. 1 IVSにおける教材提示の過程 IVSにおける幾何学的レジストレーション誤差の問題は 次のように定式化できる. いま,R中での指示棒の先端位置pRがスタジオカメラ によって撮影され,S上の点pSに投影されたとする.ま た,V 中の点qVが仮想カメラによって撮影され,S上の 点qSに投影されたとする.これらの過程を,それぞれR, V からSへの写像TC,TSで表すことにすると,pR,qV の各点とqSとの関係はそれぞれ次式で表現できる(図5). pS = T C(pR) (1) qS = T S(qV) (2) ここで,現実空間R中の指示棒の先端位置pR,および 仮想空間V 中の仮想物体上の点qVが,それぞれM 中の 点pM,qMとして知覚されるものとする.このときの演 者による現実物体,仮想物体の知覚過程を,RとV それぞ れからM への写像UR,UV で表すと,pRとpM,およ びqVとqMの関係は次式で表される(図5). qM = UV(qV) (3) pM = UR(pR) (4) このとき,演者はpM,qMに基づいて指示棒を動かすこ とになる.このときのR中での指示棒の先端位置pRは,超 音波センサで計測され,V 中の位置pVに対応付けられる. このようなセンサの計測過程をRからV への写像Lで表すと,pRとpVの関係は次式で表される(図5). pV= L(pR) (5) 2. 3で述べたように,実演に基づく教材提示における指 示動作の目的は,指示棒の動きによって指示対象領域を表 現・伝達することであるから,知覚空間M中における仮想 物体上の目標位置qMに指示棒の先端位置pMを動かそう と意図したとき,そのqMはあくまで提示対象領域を表現 するためのものに過ぎない.このとき,演者はpMがqM と厳密に一致するほど注意深く指示棒を動かす必要はなく, pMがそのときの指示対象領域内に収まるように注意すれ ば充分である.一方,このときのM 中での指示対象領域 は当然,qMを含んでいるはずであるから,この指示対象 領域をΩM(qM)で表すと,演者は教材指示において,次 式が成立するように指示棒を動かすことになる. pM∈ ΩM(qM) (6) 3. 2 幾何学的レジストレーションの要件 上述の定式化において指示対象領域は,演者による指示 動作における指示棒の先端位置の正確さに関する要求精度, あるいは許容誤差を定めるものとなる.いま,演者が知覚 空間M中の目標位置qMを含む指示対象領域ΩM(qM)に 対して指示動作を行ったときに,ΩM(qM)に対応する仮想 空間V,合成画像平面S中の指示対象領域は,qMに対し て式(2),(3)を満足する点qV,qSを含む領域ΩV(qV), ΩS(qS)となり,これらは式(2),(3)と同様,ΩM(qM)と の間に次式のような関係を持つ. ΩM(qM) = U V(ΩV(qV)) (7) ΩS(qS) = TS(ΩV(qV)) (8) したがって,演者が式(6)を満たすように指示動作を行っ ている場合,演者自身が動かす指示棒の動きに応じてシス テムが指示対象領域に対する視覚効果の生成等を正しく実 行できると同時に,その指示棒の動きを介して視聴者に指 示対象領域が正しく伝わるような視聴者用映像が得られる には,現実空間Rにおける指示棒の先端位置pRから式 (1)(5)で定まるV,S中の指示棒の先端位置pV,pSが, 次式を満足しながら,pRの連続的な動きに応じてV,S 中で連続的に動くことが必要となる. pV∈ ΩV(qV) (9) pS∈ ΩS(qS) (10) ここで式(9)の左辺に式(4)(5),右辺に式(7)を代入し, 式(10)の左辺に式(1)(4),右辺に式(7)(8)を代入すると, それぞれ次式が得られる. LU−1 R (pM) ∈ UV−1(ΩM(qM)) (11) TCUR−1(pM) ∈ T SUV−1(ΩM(qM)) (12) 演者の指示動作において式 (6) は成立しているので, UV = UR,TS = TC,かつLが恒等写像であれば,上 式から式(9)(10)も成立する.しかし,実際は,2. 3で述べ たセンサ誤差により,Lは恒等写像とはならない.また知 覚誤差により,演者によるWDでの仮想物体の知覚特性は, 現実物体の知覚特性と同一にはならないので,UV = UR とはならない.これらの誤差によって式(9)が成立しない 場合が,2. 3で述べた操作誤りである. 一方,スタジオカメラのカメラパラメータの計測データ にキャリブレーションに誤差が含まれる場合には,TS |= TC となる.通常のVSでは,キャリブレーション誤差は視聴 者用画像を合成する上で問題ない程度のものが実現されて いるが,IVSの実現のためにARを導入した結果,新たに 知覚誤差が生じてUV = URとならないときには,式(10) は成立しない.これが,2. 3で述べた表示誤りである. 3. 3 指示対象領域に対する仮定 3. 2で述べた定式化における操作誤り,表示誤りを補正 するため,式(7)∼(10)が成立するように,現実空間Rか ら仮想空間V への写像Lと,仮想空間V から合成画像平 面Sへの写像TS を補正する. この補正は,仮想物体指示の実演に先立って,本番と同 じ指示動作で実演に基づく教材提示を行うリハーサルの過 程を利用して実施し,得られた補正結果を本番の映像撮影 に利用する.以下では,リハーサル時の演者のt番目の指 示動作において,演者が指示棒の先端を動かそうとしてい る知覚空間M中の目標位置をqMt で表し,qMt と式(3)の 関係を持つ仮想空間V 中の位置をqV t で表すことにする. なお,2. 6で述べたように,上の補正において,指示対 象領域は既知である.これは,任意のtに対して,そのと きのV 中の指示対象領域ΩV(qV t )が既知であることに相 当する.ただし,この指示対象領域を演者が指示棒の動き によって表現する際に,指示棒を動かしている目標位置qVt は未知である.また,同じtに対するqVt であっても,リ ハーサルと本番でその位置が同一となるとはかぎらない. 本章の以下では,このような補正のための具体的な手順 について述べる. 3. 4 操作誤りの補正 まず,操作誤りの補正については,基本的に文献12)の 手法が適用できるので,以下に述べるように,この手法の 手続きを利用して補正を行う.ただし,2. 6で述べたよう に,文献12)の手法では頭部の動きを考慮していないので, これに対応できるような拡張を施す. 3. 2で述べたように,演者が動かす指示棒の動きに応じて システムが指示対象領域に対する視覚効果の生成等を正し く実行できるには,現実空間Rにおける指示棒の先端位置 pRから式(5)によって定まる仮想空間V での指示棒の先 端位置pVが,式(9)を満足しながら,pRの連続的な動き に応じてV 中で連続的に動くことが要求される.そこでV 中において,pVから次式を満足する点pˆVへの写像Cを
考え,L0= CLと定義して式(5)の代わりにpˆV= L0(pR) を用いることにより,pRをpˆVに対応付け,上の要求を 満足する. ˆ pVt ∈ ΩV(qVt ) (13) ここで,Cはリハーサル撮影時の仮想物体操作の過程を 利用して,次のように漸進的に決定する.t回目の指示動 作が発生したときに,その時点で暫定的に定まっているC をCtとすると,このCtによって与えられる仮想空間V 中 でのt回目の指示位置はCt(pVt ) = CtL(pRt )となる.3. 3 で述べたように,任意のtに対してΩV(qVt )が前提知識と して与えられるため,このCt(pV t )がΩV(qVt )の内部に存 在しない場合は,ΩV(qVt )の内部でCt(pVt )に最も近い点 としてpˆVt を定める. このとき,操作誤りの補正ベクトル∆C(pV t )を次式で定 義する. ∆C(pV t ) = ˆpVt − pVt (14) このように,V 中の点pVt に対して∆C(pVt )が定義さ れているとき,pVt を指示誤り補正の事例点と呼び,t番 目の指示動作が発生するまでに獲得された事例点の集合を EC t = {pV1, · · · , pVnt}(nt:事例点数)で表す.一方,p V t が 事例点でない場合,pVt に対するCtは,pVt からEtCに含 まれる各事例点までの距離を重みとした補間を用いて以下 のように定義する. Ct(pVt ) = pVt + Σnt k=1e−α||p V k−pVt ||∆C(pV k) Σnt k=1e−α||p V k−pVt|| (15) ただし,αは補間処理における近傍の重みの大きさを決め る定数である. t回目の指示動作が発生したときに,そのときのCt(pV t ) がΩV(qVt )の内部に存在しないことが検出されるたびに, 式(14)を用いて∆C(pVt )が定まり,その結果,事例点が 増加して,以降の指示動作におけるCt(pV t )が更新される ことになる. 3. 5 頭部の動きへの対応 文献12)と異なり,本研究のIVSでは,演者の頭部の位 置・方向は撮影中に変化し得る.このとき,WDによる演 者の仮想物体の知覚特性UV は,演者の頭部の位置・方向 に影響されるので,上述の∆C やCtは,pVt だけではな く,演者の頭の位置・向きにも依存することになる. そこで本研究では,この点について文献12)の手法をさ らに拡張し,t番目の指示動作を行った際に,超音波センサ によって計測される演者の頭部の位置・向きを,6次元ベ クトルhtで表し,∆CおよびCtがhtとpVt の両方に依 存するように,∆C, Ctを式(14)(15)に代えて次式のよう に定義し直す. ∆C(pV t , ht) = ˆpVt − pVt (16) 図 6 表示誤りの補正 The compensation of display falut.
Ct(pVt , ht) = pVt + Σnt k=1e−α √ ||pV k−pVt||2+||hk−ht||2∆C(pV k, ht) Σnt k=1e−α √ ||pV k−pVt||2+||hk−ht||2 (17) 3. 6 表示誤り補正表現における問題点 3. 4で述べた処理では,センサ誤差と知覚誤差をひとま とめにして,LをCで修正することによって式(13)を成 立させるため,操作誤りは補正されるが,UV = URが実 現されるわけではないため,2. 5(1)で述べたように,表示 誤りは解決されない. そこで本研究では,任意の t に対して指示対象領域 ΩV(qV t )が既知であることを再び利用し,表示誤りにつ いても,演者の仮想物体操作過程を利用して適応的に修正 することを考える. 3. 2で述べたように,演者が動かす指示棒の動きを介し て視聴者に指示対象領域が正しく伝わるような視聴者用映 像が得られるには,現実空間Rにおける指示棒の先端位置 pRから式(1)で定まる合成画像平面S上での指示棒の先 端位置pSが,式(10)を満足しながら,pRの連続的な動 きに応じてS上で連続的に動くことが要求される.このた めには,リハーサルの各時刻tにおいて,式(10)が満足さ れない場合に,そのときの合成画像中での指示棒の先端位 置pSt に対して,次式を満たすようなS上での正しい指示 棒の先端位置p0St を補正先として対応付ける必要がある. p0S t ∈ ΩS(qSt) (18) この処理を,3. 4で述べた文献12)と同じ考え方をその まま単純に適用して実現しようとすると,3. 4におけるpVt ,ˆpVt ,ΩV(qV)をそれぞれpSt,p0St ,ΩS(qSt)に置き換え,pSt に最も近いΩS(qSt)内の点をpt0Sと考えて,pSt をp0St に 対応付けることになる.ところが,2. 5でも述べたように, このような方法では表示誤りの問題は解決できない. すなわち,まずpSは現実世界の指示棒の先端位置pR がスタジオカメラの画像に映った位置であるため,操作誤 りの補正の際のpVt とは異なり,それがシステム内で直接 得られてはない.pRが超音波センサで計測され,仮想空 間V の位置pVに対応付けられていることから,このpV を仮想カメラで合成画像平面上に投影した位置TS(pV)は 求めることができるが,センサ誤差やキャリブレーション 誤差のために,これはpSと同一ではない. また,pSt に対する合成画像平面上での正しい指示棒先端
位置p0St は,視聴者に仮想物体上の指示対象領域ΩV(qVt ) を正しく伝えるものでなければならないから,2. 5で述べた ように,合成画像平面上で2次元的にpSt に最も近いΩS(qSt )の点としてこれを定めることは適当でなく,p0St とΩS(qSt )から把握されるそれらの3次元的な近接関係を考慮して p0S t の位置を定める必要がある.具体的には,次式のよう に,p0St を合成画像平面S上への投影像とするような仮想 空間V 中の点p0Vt が存在し,これが指示対象領域ΩV(qVt )に含まれていなければならない. p0S t = TS(p0Vt ) (19) p0Vt ∈ ΩV(qVt ) (20) 3. 7 表示誤りの補正先の算出 上の問題に対し,本研究では,2. 6の(a)で述べたよう に,指示棒の先端に赤色のマーカを装着し,スタジオカメ ラの画像中からこのマーカ位置を抽出することにより,ま ずpSt を獲得する.さらに,このようにして得られたpSt に 対して,p0St を次のようにして求める. 上のpSt は,式(1)に従って,現実空間R中の指示棒の 先端位置pRt からの写像TCによって定まっているが,この pS t に対して,次式を満たすような仮想空間V 中の点p00Vt を考える. pS t=TS(p00Vt ) (21) このp00Vt に対して,もしp00Vt ∈ ΩV(qVt )ならば,p00Vt とΩV(qV t )を式(8)(21)を用いてS上に投影することによ り,式(10)に相当するpSt ∈ ΩS(qSt)が成立しなければな らない.ところが,p00Vt ∈ Ω/ V(qVt )である場合には,S上 に投影してもpS t ∈ Ω/ S(qSt)となるから,そのようなpSt を 用いて視聴者にΩV(qVt )を正しく伝えることはできない. そこで,p00Vt ∈ Ω/ V(qVt )の場合には,3. 3で述べたよう に,任意のtに対してV での指示対象領域ΩV t (qVt )が既 知であることを利用して,ΩV(qVt )の内部でp00Vt に最も 近い点としてp0Vt を定め,これに対して式(19)を用いる ことにより,合成画像平面S上での正しい指示棒の先端位 置p0St を定めることを考える. 上のような処理を実現するには,p00Vt が得られる必要が ある.ところが,式(21)より,p00Vt = TS−1(pSt)であり, TS−1は,3次元から2次元への投影変換の逆写像であるか ら,p00Vt を仮想空間V 中の1点として一意に求めること は不可能である.この問題に対処するため,本研究では以 下のような方法でp0S t を定める. TS−1(pS)は,pSとTS の投影変換におけるカメラのレ ンズ中心を結んだ直線となる(図6).一方,合成画像平面 上での2次元の指示対象領域ΩS(qS t)が表示される元とな る3次元空間での指示対象領域は,仮想空間V でΩV(qVt ) として与えられているから,V 中において,このTS−1(pSt) 上で指示対象領域ΩV(qV t )に最も近い点をp00Vt とみなし, このようなp00Vt とpSt の関係を写像T˜S−1を用いて次式の ように表す. p00V t =T˜S−1(pSt) (22) このようなp00Vt に空間上で最も近いΩV(qVt )中の点を p0V t とし,このp0Vt に対して式(19)を用いてp0St を定め ると,このp0St ,p0Vt は式(18)∼(20)を満たすから,合成 画像平面上のp0S t とΩS(qSt)から把握されるそれらの空間 上の近接関係を考慮した表示誤りの補正が可能となる. 3. 8 仮想空間を利用した表示誤り補正の補間 以上のようにして得られるp0St が,さらにpSt から把握 される3次元の連続的な動きに応じて連続的に変化するよ うにするためには,合成画像平面全体にわたって,pS t に 対するp0St が,ΩS(qSt)との間で,それぞれの3次元的な 位置に対して,正しい近接関係を持っていなければならな い.そこで本研究では,2. 6の(a)で述べたように,pSt か らp0St への補正を表現するための補間を,2次元の合成画 像平面S上ではなく,3次元の仮想空間中V で定義する. このために,V 中のp00Vt からp0Vへの写像を定める.こ の写像は,操作誤り補正のために定めた写像Cと同じ仮想 空間V 内部での写像となるが,操作誤りの補正と表示誤り の補正は同じ仮想空間中の点に対する補正先が異なるため, Cによってp00V t からp0Vへの写像を実現することはでき ない.このため,全く同じ仮想空間V 内で,Cとは異なる 写像Dを次のように定め,演者の指示棒操作による視覚効 果の発生等の処理では写像Cを用いて操作誤りを補正する 一方,視聴者用合成画像の生成にあたっては,写像Dを用 いて表示誤りを補正する. p0S t = TS0(p00Vt ) (23) = TS0T˜S−1(pSt) (24) 3. 4と同様,Dもリハーサル撮影時の仮想物体操作の過 程を通じて漸進的に決定する.t回目の指示動作が発生し たときに,その時点で暫定的に定まっているDをDtとす ると,このDtによって与えられる合成画像平面S上でのt 回目の指示棒の先端位置は,TSDt(p00V t ) = TSDtT˜S−1(pSt) となる.これが,そのときのS上での指示対象領域ΩS(qSt) の内部に存在しない場合は,上述の方法でp0Vt を定め,こ れに基づいて∆D(p00Vt )を次式で定義する. ∆D(p00V t ) = p0V− p00V (25) 仮想空間V 中の点p00V t に対してこのような∆D(p00Vt ) が定義されているとき,p00Vt を表示誤り補正の事例点と呼 び,t番目の指示動作が発生するまでに獲得された事例点の 集合をED t = {p00V1 , · · · , p00Vmt}(mt:事例点数)で表す.一 方,p00Vt が事例点でない場合,p00Vt に対するDtは,p00Vt からEtDに含まれる各事例点までの距離を重みとした補間 を用いて以下のように定義する. Dt(p00V t ) = p00Vt +
Σmt k=1e−β||p 00V k −p00Vt ||∆D(p00V k ) Σmt k=1e−β||p 00V k −p00Vt || (26) ただし,βは補間処理における近傍の重みの大きさを決め る定数である. 式(12)からわかるように,操作誤りだけではなく,表示 誤りも演者の知覚特性の影響を受ける.この知覚特性は, 3. 5で述べたように演者の頭部の位置・方向に影響されるの で,上述の∆D, Dtは,操作誤りにおける∆C, Ctと同様, p00V t だけではなく,演者の頭の位置・向きhtにも依存す る.このため,3. 5と同様に,∆DおよびDtを式(25)(26) に代えて次式のように定義し直す. ∆D(p00V t , ht) = p0V− p00V (27) Dt(p00V t , ht) = p00Vt + Σmt k=1e−β √ ||p00V k −p00Vt ||2+||hk−ht||2∆D(p00V k , ht) Σmt k=1e−β √ ||p00V k −p00Vt ||2+||hk−ht||2 (28) 3. 4で述べた指示誤り補正の事例点と,3. 6で述べた表示 誤り補正の事例点は,互いに独立に蓄積され,それぞれの 誤り補正のための写像C,Dも,現実空間Rおよび合成画 像平面S中の指示棒の先端位置pRt ,pSt から式(5),(22) によって定まる仮想空間V 中の位置pV t ,p00Vt に対してそ れぞれ独立に定義・適用される.このため,C,Dによっ て補正される指示棒の先端位置は,互いに同一の点に補正 されるわけではないが,教材提示に必要な指示位置の精度 を決める指示対象領域については,演者,システム,視聴 者の3者の間で同一の指示対象領域が共有されることにな る.このようなC,Dの独立性により,表示誤りの補正は 演者に提示される仮想物体画像には影響せず,逆に操作誤 りの補正は視聴者に提示される合成画像には影響しない. 3. 9 表示誤り補正の利用方法 なお,表示誤りの補正においては,S上での補正位置p0St が求まっても,R中で演者が動かしている指示棒の先端位 置をシステムが変えることはできないので,その合成画像 への投影像であるpSt をp0St に修正することはできない.し かし,p0St が求まっていることと,上記のようなC,Dの 独立性により,演者に提示する仮想物体画像には影響を与 えずに,視聴者用合成画像中の仮想物体と指示棒の位置の 表示内容を教材の性質に応じた方法で修正することが可能 となる.例えば,最も単純な方法はpSからp0Sへの引き 出し線を表示するというものである(図7(a)).また,分子 模型を提示する場合のように,対象物体間の位相構造のみ が説明対象となり,物体の位置自体には自由度がある場合 や,太陽系の惑星の配置を提示する場合のように,物体の位 置が重要な一方大きさは任意であるような教材では,p00V の位置がp0Vになるように物体の重心位置を動かしたり, 物体全体を相似変形したりするといった方法も考えられる (同図(b)(c)).さらに物体形状もあまり重要でない場合は, (a) 引出線の表示による補正 Leading line compensation
(c) 移動による補正 Shift compensation (b) 拡大による補正 Expansion compensation (d) 歪曲による補正 Distortion compensation 図 7 表示誤りの補正の仕方の例
Examples of the compensation for the display fault.
(a)Radius 7.5cm
(b)Radius 6cm
(c)Radius 4.5cm 図 8 操作誤りの変化 The transition of manipulation fault.
(a)Radius 7.5cm
(b)Radius 6cm
(c)Radius 4.5cm 図 9 表示誤りの変化 The transition of display fault.
V 中でp00Vの位置をDによって定まるp0Vに補正するこ とにより,物体を直接変形させることも可能である(同図 (d)).
4.
実 験 4. 1 実験方法 3. 4,3. 6で述べた手法によって,実際に,操作誤りと表 示誤りが,指示対象領域の大きさに応じたものとなるかど うかを調べるために,指示対象領域を球形として,その中 心を目標位置とした場合の仮想物体の指示動作を,IVSを 用いて撮影した.通常,対象領域はCMS用教材を作成する 時点で決められており,演者である講師はそれを確認した 上で指示を行うものであるため,指示対象領域自体が表示(a)Radius 7.5cm (b)Radius 6cm (c)Radius 4.5cm 図 10 補正前後での指示点の変化 The change of the point by our proposed method.
図 11 合成画像の具体例 An example of composite image.
されることはない.しかし,この実験では被験者に指示対 象領域の大きさがわかるように球面を表示し,その直径を 9cm,12cm,15cmの3種類とすることで,異なる大きさ の指示対象領域に対して指示を行う状況を実現した.さら に視点移動による影響も含めるために,リハーサル時,こ の指示対象領域に対して,指示位置を3箇所に変更しなが ら,同じ指示対象領域の中心を指示する動作を合計15回 行ってもらった.なお,指示誤り補正と表示誤り補正におけ る補間の係数である式(15)(26)のα,βは共に0.2とした. 4. 2 操作誤り補正の結果 15回の指示動作のそれぞれをt = 1, · · · , 15として,各々 のtに対して3. 4で述べた方法で写像Ctを求める.15回 の指示動作における現実空間R中の指示棒の先端位置pRt を超音波センサで計測して求まる仮想空間V 中の位置pV t に対してこのCtを用い,V での補正後の指示棒の先端位置 ˆ pV t を求める.そして,pˆVt とΩV(qVt )の表面との距離の 平均値を操作誤り補正の誤差の大きさとして評価した.こ のとき,tの増加によってCtが更新されていったときのこ の誤差の大きさの変化を,図8に示す. 指示対象領域の大きさの違いにより,被験者の指示動作 の精密さも異なるため,補正を全く行っていない段階にお ける誤差の大きさの初期値も異なるが,いずれの場合でも 指示動作を続けることで誤差の大きさが減少し,それぞれ の指示対象領域の大きさに応じた大きさに収束していく適 応的なレジストレーションが実現されている.したがって, この結果の場合,10回目程度までをリハーサルにすれば後 は本番として利用できる. 4. 3 表示誤り補正の結果 4. 2と同様に,15回の指示動作のそれぞれをt = 1, · · · , 15 として,各々のtに対して3. 6で述べた方法で写像Dtを 求める.15回の指示動作における合成画像平面S上の指 示棒の先端位置pS t から式(22)によって復元される仮想空 間V 中の位置p00Vt に対して,このDtを用い,Sでの補 正後の指示棒の先端位置p0St を求める. いま,指示対象領域ΩV(qVt )は球形であり,指示動作の 目標位置qVt はその中心であるから,合成画像平面Sにお ける指示対象領域の投影像ΩS(qSt)は円形,指示動作の目 標位置qSt はその中心となる.このとき,p0St とΩS(qSt)の 中心との距離は,スタジオカメラから見て指示棒の先端位 置が仮想物体の手前に位置するときに小さくなり,上下左 右に位置するときに大きくなる.そこで,15回の指示動作 におけるp0S t とΩS(qSt)の中心との距離のうち,その大き さがΩS(qSt)の半径より大きいものの平均値を表示誤り補 正の誤差の大きさとして評価した.このとき,tの増加に よってDtが更新されていったときのこの誤差の大きさの 変化を,図9に示す.この結果から,表示誤りについても, 指示動作を続けることで誤差が減少していくことが分かる. ただし,直径15cm,12cm,9cmの球を,合成画像上に投 影した際のピクセル数は,それぞれ119画素,93画素,70 画素となった. これらの結果から,表示誤りについても,指示動作を続 けることで大きさが減少し,それぞれの操作領域の大きさ に応じた大きさに収束していくことが確認できた.さらに 図10には,このときの事例点として得られた各点に対し, 補正前の点を矢印の根本,補正後の点を矢印の頭として, 補正前後の点を結び表示したものである.また,図11は, 実際の演者と仮想物体,そして引き出し線による補正を合 成した結果の例である.このように合成することで,視聴 者への表示誤りを補正した.
5.
む す び 本研究では,3D仮想物体による教材を,講師が講義と同 様に,指示棒を用いた実演によって提示可能な教育用映像 撮影環境の実現を目標として,演者が仮想物体を視認・直接 指示可能なIVSを構築した.また,このようなIVSのため の幾何学的レジストレーションにおいて,指示棒を用いた 実演による教材提示を目的とする場合には,指示棒の先端 位置に許容される誤差が,指示動作の内容や対象物体の大 きさによって異なる.そこでこのことを考慮し,教材指示 映像撮影では指示対象領域が前提知識として与えられるこ とを利用して,演者・システム・合成画像の三つの間で,指 示棒の先端位置の誤差が同一の指示対象領域の範囲内に収 まりながら,演者が動かす指示棒の動きに応じて指示棒の 先端位置が連続的に変化するような幾何学的レジストレー ションを,リハーサル撮影時の演者による物体指示の過程 を通して適応的に実現するための手法を提案した.さらに, この手法の有効性を確かめるために,実際のVSを用いて IVSシステムを構築し,異なる大きさの球形の指示対象領 域に対する指示動作を撮影する実験を行った結果,指示対 象領域の大きさに応じた操作誤りや表示誤りの誤差補正が 適応的に実現できることを確認した.今後の課題としては,本研究では既知とした指示対象領域 を,演者の身体や指示棒の動きから認識することにより13), 指示対象領域を与えなくても本手法が適用できるようにす ることや,3. 9で述べたような表示誤差補正結果の様々な 表示方法を,教材の内容に応じて自由に選択・利用できる ようにすることなどが挙げられる. なお,本研究や文献12)で議論している適応型のレジス トレーションの有用性をより客観的に示す上では,従来行 われてきた事前レジストレーションとの定量的な比較を行 うことが理想的ではあるが,次のような理由により,現時 点ではその実現は難しい.すなわち,事前レジストレーショ ンでは,センサ誤差や知覚誤差,キャリブレーション誤差 といった各種類の誤差毎に個別に補正を行うが,2. 4で述 べたように,この補正において,基準点の計測等を精密に すればする程,その精度は向上する反面,そのための技術 的難易度も増加するというトレードオフが存在するため, どの程度の精度を事前レジストレーションの一般的な精度 と考えるかは一概にはいえない.一方,適応型のレジスト レーションでは,各種類の誤差を個別に補正するのではな く,これらの誤差が操作誤りや表示誤りといった複合した 形で現れたものを直接補正し,その結果実現される精度は, タスクに依存して適応的に決まる.ところが,操作誤りや 表示誤りは,センサ誤差や知覚誤差,キャリブレーション 誤差の複合的な影響によって起こるものであるため,ある 操作タスクで必要となる操作誤りや表示誤りの要求精度が 決まったとしても,それを達成するためのセンサ誤差や知 覚誤差,キャリブレーション誤差の個々の要求精度を逆算 することは難しいため,その要求精度に対応する事前レジ ストレーションを比較対象として実施してみることができ ない. この問題に対する方策として,様々な技術的難易度や精 度のレベルを設定してセンサ誤差や知覚誤差,キャリブレー ション誤差といった各種類の誤差を事前レジストレーショ ンで補正しておき,これらの結果としてどの程度の操作誤 りや表示誤りが起こるのかを実験的に調査し,操作誤りや 表示誤りの精度と,そのための事前レジストレーションの ための技術的難易度のレベルの関係を分析することにより, 適応型レジストレーションが有用となるタスクとはどのよ うなものかを明らかにするといったアプローチが考えられ る.ただ,これは本論文の目的であるIVSの実現とは独立 の,幾何学的レジストレーション自体に関する研究として の性格を帯びたものとなるため,今後の研究課題としたい. 本研究の一部は科学研究費補助金基盤研究(B)16300055 によった. 〔文 献〕
1)Ong Siew Siew, Shepherd J.: ”WebCMS: a Web-based course management system”, Database and Expert Systems Applica-tions, 2002. Proceedings, 13th International Workshop on 2-6, pp.345–350 (Sept. 2002)
2)Craig M. Kapp: ”Implementation and evolution of a course man-agement system”, November 2002 Proceedings of the 30th annual ACM SIGUCCS conference on User services.
3)K.Kakusho, Y.Minekura, M.Minoh, S.Mizuta, T.Nakatsu, K. Sh-iota: ”Computer Graphics to Illustrate Development of a Hu-man Embryo for Professional Medical Education”, ACM SIG-GRAPH2002 Conference Abstracts and Applications, pp.159 (2002) 4)西口 敏司, 亀田 能成, 角所 考, 美濃 導彦: ”大学における実運用の ための講義自動アーカイブシステムの開発”, 信学論, J88-D-II, 3, pp.530–540 (2005) 5)大西 正輝, 泉 正夫, 福永 邦雄: ”情報発生量の分布に基づく遠隔撮影の 自動化”, 信学論, J82-D-II, 10, pp.1590–1597 (1999) 6)先山 卓朗, 大野 直樹, 椋木 雅之, 池田 克夫: ”遠隔講義における講義状 況に応じた送信映像選択”, 信学論, J84-D-II, 2, pp.248–257 (2001)
7)Simon Gibbs, Costas Arapis, Christian Breiteneder, Vali Lalioti, Sina Mostafawy, Josef Speier: ”Virtual Studios: An Overview”, IEEE Multimedia, 4, 1, pp.18–35 (1998)
8)R.T.Azuma: ”A Survey of Augmented Reality”, Presence: Tele-operations and Virtual Environments, 6, 4, pp.355-385 (1997)
9)大石峰士, 舘 : ”シースルー型 HMD における視覚パラメータの補正 法”, 日本ロボット学誌, 12, 6, pp.911–918 (1994)
10)吉田俊介, 宮崎慎也,星野俊仁, 大関徹, 長谷川純一,安田孝美,横井茂 樹: ”ステレオ視表示における高精度な奥行き距離補正の一手法”, 日本 バーチャルリアリティ学論, 5, 3, pp.1019–1026 (2000)
11)Mihran Tuceryan, Nassir Navab: ”Single point active alignment method(SPAAM) for optical see-through HMD calibration for AR”, Proceedings of the IEEE and ACM International Sympo-sium on Augmented Reality, Munich, Germany, pp.149–158 (Oc-tober 2000) 12)角所 考, 萩原 史郎, 美濃 導彦: ”拡張現実感による仮想物体操作過程を利 用した適応的レジストレーション”, 信学論, J85-D-II, 11, pp.1701– 1723 (2002) 13)丸谷 宜史, 西口 敏司, 角所 考, 美濃 導彦: ”講義コンテンツのための教 材指示情報の抽出”, 画像の認識・理解シンポジウム (MIRU2004) 講演 論文集, II, pp.323–328 (2004)
14)Marcelo Kallmann,Daniel Thalmann: ”Direct 3D Interaction with Smart Object”, Proceeding of the ACM symposium on Vir-tual Reality Software and technology, pp.124–130 (1999)
15)Lilian Leivas Pozzer-Ardenghi, Wolff-Michael Roth: ”Gestures: Helping Students to Understand Photographs in Lectures”, CON-NECTIONS, pp.1–30 (2003)