パケット処理キャッシュに特化した低回路コストなキャッシュエントリ制御手法の実現
8
0
0
全文
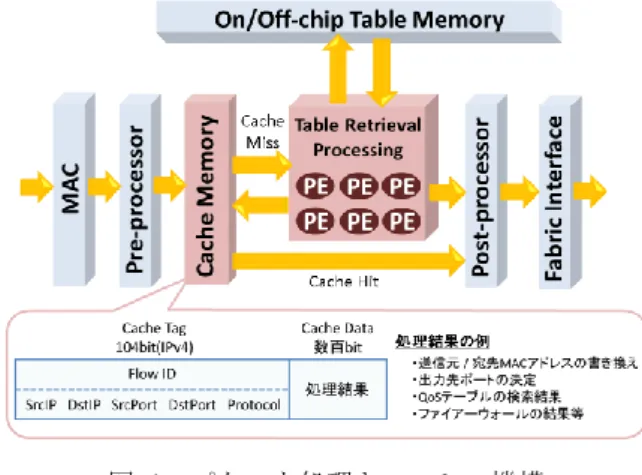
(2) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2014-ARC-211 No.10 2014/7/28. ッシュを用いた高速な処理を可能とする.一般的にキャッ シュの性能は,キャッシュメモリ中に該当するデータが存 在しないキャッシュミスの発生率に大きく左右される.パ ケット処理キャッシュにおいても,テーブル検索処理速度 はキャッシュミス率により決定されるため,処理速度の向 上にはキャッシュミスの削減が重要な課題であった[5].本 論文では,まずパケット処理キャッシュにおけるキャッシ ュミス削減の足掛かりとして,パケット処理キャッシュ特 有のデ-タアクセス傾向の分析を行う.分析結果をもとに, キャッシュミス削減に効果的なキャッシュ手法の提案を行 い,実ネットワークトラフィックのトレースを用いたソフ トウェアシミュレーションによって手法の評価を行う.. 2. パケット処理キャッシュ機構 ルータは IP フォワーディングやファイアウォール,NAT,. 図 1 Figure 1. パケット処理キャッシュ機構. Architecture of Packet Processing Cache.. 検索結果をキャッシュメモリへと保存する.そして,以降. QoS 制御といった様々なネットワークアプリケーションを. の同一フローのパケットはキャッシュ内のテーブル検索結. ワイヤレートで処理しなければならない[7][8].当初これら. 果を適用することで高速に処理を行う.このようなヘッダ. の処理は,DRAM 等のメモリに格納されたフォワーディン. 値の等しい同一フローのパケットは,短時間に連続して訪. グテーブルやフィルタリングテーブルといった各種テーブ. れるという時間的局所性が存在することが知られており,. ルに対し,パケットヘッダの特定フィールドの値を用い,. キャッシュを用いることで効率的に処理を行うことが可能. 検索を行うという手法であった.DRAM のアクセス速度が. となる[13].本手法の概要を図 1 に示す.本手法では,従. 遅いことや,最長一致検索(Longest Prefix Match: LPM)[9]. 来 PE を割り当て行っていたテーブル検索処理に対し,事. を行うために複数回のメモリアクセスを要することから,. 前にキャッシュ検索を行う.当該フローの処理結果が存在. このようなテーブル検索処理はパケット処理の中でもボト. するキャッシュヒット時には,キャッシュの内容を適用す. ルネックとなりうることが知られている[8][10][11].特に,. ることで,PE の割り当てやテーブルメモリの検索を省略し,. ネットワークの高度化に伴いルータでは単純なルーティン. 高速に処理を完了することが可能となる.一般的なキャッ. グテーブルのみならず,QoS テーブル等,複雑なテーブル. シュに用いる SRAM は数 ns オーダでのメモリアクセスが. 検索処理が増加しており,テーブル検索処理の高速化は重. 可能であり,数十から数百 ns オーダのアクセス遅延を要す. 要な課題となっている.テーブル検索を高速に行う手法と. る DRAM に比べ,10 倍以上テーブル検索処理遅延を短縮. しては,CAM(Content Addressable Memory)を用いること. することが可能である.. でメモリアクセス回数を削減する手法が提案されてきた. このようなパケット処理キャッシュ機構では,該当フロ. [12].しかしながら、CAM の回路コストは DRAM に比べ. ーの処理結果がキャッシュに存在しないキャッシュミスが. 遥かに大きく,経路数の増大に対し、半導体技術の成長速. 発生すると,従来通り処理遅延の大きいテーブル検索処理. 度が停滞していることから回路規模は増加する一方である。. を行わなければならない.従って,本手法の処理遅延はキ. 更に、近年標準化のなされた 100G Ethernet が普及した場合. ャッシュミス率に左右され,処理遅延の改善にはキャッシ. には、CAM であってもアクセス速度が不足することが考. ュミスの削減が重要であった.キャッシュにおいて最も一. えられる。そのような中で,近年ではキャッシュを用いた. 般的なキャッシュミス削減手法は,メモリ容量を大きくし,. テーブル検索の高速化手法が提案されている[3][4][5].. キャッシュ可能なエントリ数を増やすことである.しかし. パケット処理におけるテーブル検索では,パケットヘッダ. ながら,メモリ容量とアクセス遅延の間にはトレードオフ. 中の一つ又は複数のフィールドの値をもとにテーブル内の. の関係があり,容量を増やすことでキャッシュミスの削減. 検索が行われる.従って,このフィールドの値が等しいパ. を行っても全体的な遅延が改善されない場合がある.そこ. ケット群では同一のテーブル検索結果が返される.例えば,. で,まず我々は実ネットワークトレースを用いたシミュレ. ルーティングテーブル検索では,宛先 IP の等しいパケット. ーションにより,パケット処理キャッシュにおける最適な. 群に対し,同一の検索結果が返されることになる.この事. メモリ容量を検討した.図 2 は,後述するパケット処理キ. 実を利用し,パケット処理キャッシュでは,多くのテーブ. ャッシュシミュレータを用いた,メモリ容量毎のキャッシ. ル検索で用いられる 5 つのフィールド(Source IP,. ュミス率の測定結果を示している.シミュレーションでは,. Destination IP,Source Port#,Destination Port#,Protocol#). WIDE(Widely Integrated Distributed Environment)とアメリカ. の組をフローと定義し,フローの初回パケットのテーブル. 間の 150Mbps 国際回線で取得された WIDE トレース及び日. ⓒ2014 Information Processing Society of Japan. 2.
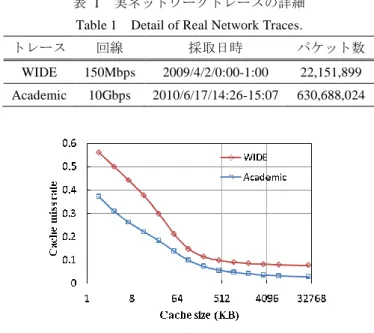
(3) 情報処理学会研究報告 IPSJ SIG Technical Report 表 1. Vol.2014-ARC-211 No.10 2014/7/28. 実ネットワークトレースの詳細. Table 1. 4way キャッシュにおけるキャッシュ追い出しアルゴリズ. Detail of Real Network Traces.. ムとして,Least Frequently Used(LFU)やラウンドロビン. トレース. 回線. 採取日時. パケット数. より Least Recently Used(LRU)を用いることで,高い性. WIDE. 150Mbps. 2009/4/2/0:00-1:00. 22,151,899. 能を得られることを示している.. Academic. 10Gbps. 2010/6/17/14:26-15:07. 630,688,024. 大阪市立大学の阿多らは,パケット処理キャッシュにお ける 5 属性のフロー情報が IPv4 でも 104bit と大きくなる問 題点に着目し,フロー情報の圧縮手法を提案した[14].阿 多らによると,多くのテーブル検索で用いられるのは送信 元 IP,宛先 IP,小さいほうのポート番号の 3 属性であると し,メモリ使用の効率化を図っている.しかしながら,近 年におけるテーブル検索は複雑性を増しており,例えば QoS テーブルでは一般的に前述した 5 属性の値が使われて いる.このことからも,今後のテーブル検索処理を高速化 するためには 3 属性の値では不十分であると考えられる. 同様のキャッシュミス削減手法として,OHSU の Chang. 図 2 Figure 2. キャッシュ容量とミス率の関係. Relation of Cache Size and Cache-miss Rate.. らは,104bit のフロー情報を 32bit のハッシュ値へと圧縮す ることで,同メモリ容量でのエントリ数を増やす Digest Cache の提案を行っている[6].Digest Cache では,32bit の. 本国内の大規模ネットワークの 10Gbps 回線で取得された. ハッシュ値を生成する回路や,フロー情報を圧縮したこと. Academic トレースの二つを用いた.各トレースの詳細は表. による衝突への対策が必要となり,全体的なハードウェア. 1 に示す.図 2 によると,ネットワークに依らず 64KB 程. コストが一概に削減されるとは言えない.このように,フ. 度まではメモリ容量を増加することで,キャッシュミスが. ロー情報を圧縮することでエントリ数を増やすことを目的. 線形に改善されていく.しかしながら,これ以上のメモリ. とした手法は,圧縮により弊害を生じる可能性がある.. 容量の増加では僅かなキャッシュミス改善しか得られない.. 一方で,キャッシュエントリを効果的に管理することで. 上記のことから,パケット処理キャッシュでは近年のプロ. キャッシュミスの削減を行う研究がある.多くのキャッシ. セッサの L1 キャッシュと同程度である 32KB または 64KB. ュは,一つのキャッシュインデックスに対し複数のキャッ. の高速なメモリを用いることが効果的であると考えられる.. シュデータを割り当てるセットアソシアティブ方式を採用. 本論文での議論は,L1 キャッシュメモリを想定したパケ. していることが一般的である.上述したように,パケット. ット処理キャッシュにおいて生じる 15%~20%程度のキャ. 処理キャッシュにおいても,本方式はキャッシュミス削減. ッシュミスを,メモリ容量を増やすことなく削減すること. に有効であることが知られている.本方式のキャッシュに. である.. おいて新たなデータを格納する場合,既に格納されている. 3. 関連研究. 複数のデータから一つを選んで追い出さなければならない. このような追い出しエントリの決定アルゴリズムは,キャ. 従来からパケット処理の高速化を目的としたキャッシュ. ッシュ追い出しアルゴリズムと呼ばれており,最適な追い. におけるキャッシュミス削減の研究は数多くなされてきた.. 出しアルゴリズムを適用することで,少ないハードウェア. しかしながら,その多くはルーティングテーブル検索結果. の変更に対し,キャッシュミスを削減できることが知られ. のみを保存するキャッシュに関する研究[4][13]であり,近. ている.Akamai Technologies の Girish らはパケット処理キ. 年研究のなされているフローを用いたパケット処理キャッ. ャ ッ シ ュ に お い て 最適 な 追い 出 し ア ル ゴ リ ズ ムと し て. シュに関する研究は少ない.以降では,フローを用いたパ. Saturating Priority Cache を提案している[15].また,Girish. ケット処理キャッシュのキャッシュミス削減手法の方向性. らは L1 キャッシュ程度のメモリを想定したパケット処理. について,主な研究をまとめる.. キャッシュシミュレーションにおいて,本手法により 7%. Georgia Institute of Technology の Li らは,パケット処理キ. 程度キャッシュミスを改善可能であることを示している.. ャッシュにおける最適なキャッシュ構成について検討を行. このように,追い出しアルゴリズムの改善はキャッシュミ. った[11].Li らによると,キャッシュの連想度は 4way がパ. ス削減に有効な手法ではあるが,Girish らも示しているよ. フォーマンスと実装コストの両面から見て最適であるとし,. うにトラフィックの種類やエントリ数の違いにより効果も. キャッシュインデックス生成のためのハッシュ関数は実装. 大きく異なり,また大幅なキャッシュミスの改善を望むこ. が容易な XOR ベースを用いることで,複雑な SHA-1 と同. とはできない.キャッシュミスの大幅な削減には,新たな. 程度のキャッシュヒット率を得られると述べている.また,. 方向性を見つけることが必要であると考えられる.. ⓒ2014 Information Processing Society of Japan. 3.
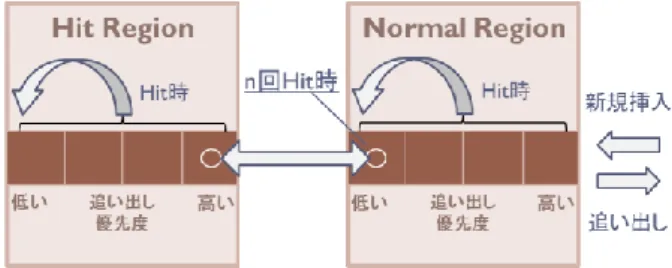
(4) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2014-ARC-211 No.10 2014/7/28. 4. キャッシュミス削減手法の検討 従来,CPU キャッシュやページキャッシュといった様々 なキャッシュにおいて,キャッシュミス削減の研究がなさ れてきた[16,17].しかしながら,これらの研究により提案 された手法を,そのままパケット処理キャッシュに適用す ることは,アクセスパターンの違いから良い手段とはいえ ない.CPU キャッシュやページキャッシュに利用されるデ ータアクセスの局所性とは異なり,パケットは独特の局所 性を有している.そこで本報告では,まずネットワークト ラフィックに存在するパケット処理キャッシュ特有の傾向 図 3. を分析することで,キャッシュミス削減の足掛かりとする. 4.1 パケット処理キャッシュのデータアクセス分析. Figure 3. フロー構成パケット数の分布. Distribution of the Number of Packets per Flow.. パケット処理キャッシュにおいてキャッシュミスを増大 させる要因の一つに,少数パケットで構成されるフロー(以 降ではショートフローと呼んで扱う)によるキャッシュ汚 染の問題がある.特に 1 パケットで構成されるフローはキ ャッシュヒットの機会がなく,不要にキャッシュエントリ を圧迫する[18].図 3 は実ネットワークトラフィックの解 析により得られた,フロー構成パケット数の分布を示して いる.図 3 によると,大部分のパケットが 10 パケット以下 で構成されていることがわかる.また,トラフィックに依 るが,1 パケットで構成されるフローはフロー全体の半数 程度であり,このようなフローがキャッシュに与える影響 は大きい.パケット処理キャッシュでは,ショートフロー を早く追い出すことが重要となる. 一方で,ネットワークには動画トラフィックのような多 数のパケットにより構成されるフロー(以降ではロングフ ローと呼んで扱う)も存在する.図 3 に示したトラフィッ ク解析では,1 時間で 10 万パケットを超えるフローが複数 存在している.このような,多数のショートフローと少数. 図 4. キャッシュにおけるロングフローの挙動. Figure 4. Behavior of Long Flow in Cache.. のロングフローがネットワークトラフィックを占める傾向 は,Elephant and Mice Phenomenon として知られている[19]. ロングフローは少数ではあるが,パケット数の観点から見 るとトラフィックの大部分を占めており,ネットワークへ 大きな影響を与えている.上記の知見をもとに,我々はパ ケット処理キャッシュにおけるロングフローの挙動に着目 した.図 4 は,パケット処理キャッシュシミュレーション における,ロングフローのヒット状況の一例を示している. 多くのロングフローでは一連のパケット群全てがヒットし. 4.2 Hit Priority Cache の提案 ネットワーク解析で得られた結果を基に,本報告ではシ ョートフローエントリを迅速に排除し,なおかつ,ロング フローエントリを優先的にキャッシュに残す Hit Priority Cache (HPC)の提案を行う.ロングフローを決定することは 困難であるため,HPC では連続的にヒットするエントリを ロングフローであると推測し優先的に残す.HPC の概要を 図 5 に示す.. ているわけではなく,途中にキャッシュミスが発生してい る.これは即ち,キャッシュ内でロングフローエントリの 追い出しと再登録が繰り返され,キャッシュにとって効率 の悪いアクセスが頻繁に発生しているということである. パケット処理キャッシュでは,ショートフローの排除と同 時に,ロングフローを優先的にキャッシュに残す手法が必 要である. 図 5 Figure 5. ⓒ2014 Information Processing Society of Japan. Hit Priority Cache の処理概要. Processing Outline of Hit Priority Cache.. 4.
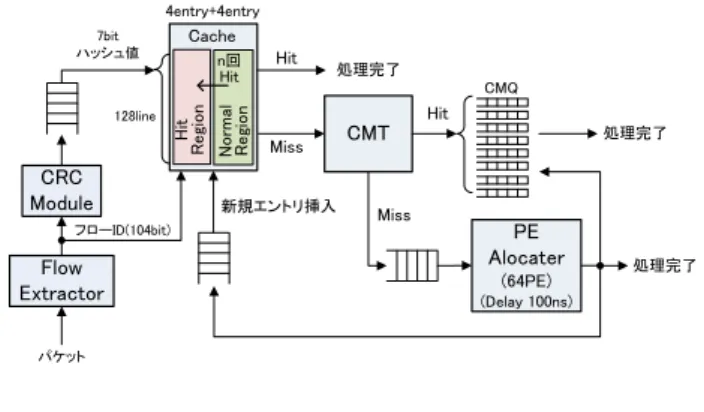
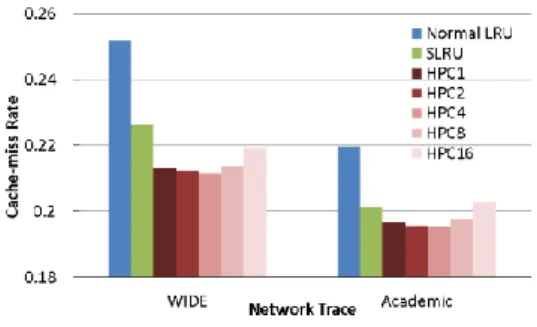
(5) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2014-ARC-211 No.10 2014/7/28. 本手法はキャッシュメモリを半分に分け,通常領域とヒ. 更に,フローID は CRC により 7bit にハッシュ化され,キ. ット領域とし,通常領域で一定回数キャッシュヒットした. ャッシュインデックスとして用いられる.得られたハッシ. エントリをヒット領域に移動することで複数回ヒットした. ュ値とフローID からパケット処理キャッシュの検索が行. エントリを優先的に残す.一方で,新規エントリ挿入時に. われる.キャッシュメモリ容量は 32KB とし、総エントリ. は,通常領域の最も追い出されやすい位置へと挿入するこ. 数を 1,024 エントリとした。ここでは,キャッシュヒット. とでショートフローを迅速に追い出すことを可能とする.. した場合には PE に処理が割り当てられず,当該パケット. 通常領域とヒット領域のエントリ入れ替えは,通常領域で. の処理が完了になると仮定している.一方で,キャッシュ. n 回目のキャッシュヒットをし,最も追い出し優先度が低. ミスした場合には,Cache Miss Table(CMT)へと処理が送. くなったエントリと,ヒット領域の最も追い出し優先度の. られる.CMT は,キャッシュミスしたパケットの PE 処理. 高いエントリ間で行われる.これにより,領域間でのエン. が完了する前に同一フローの後続パケットが到着した際,. トリ入れ替え時にヒット領域の追い出し順位が変わること. 連続してキャッシュミスが発生してしまうことを防ぐため. なく,本手法の実装コストを削減することが可能となる.. に,PE で処理中のパケットを CMT にリストし,PE 処理が. 実装コストの検討については第 5 章で後述する.. 完了するまで後続パケットを Cache Miss Queue(CMQ)に 蓄えておく機構である[22].CMT にリストされていないフ. 5. 性能評価. ローは,PE への処理の割り当てが行われ, PE の処理遅延. 本章では HPC のキャッシュミス削減効果及び実装コス. が課される.本報告では PE の数を 64 個,PE のテーブル. トに関して検討を行う.従来多くのキャッシュにおいて,. 検索遅延を 100ns としている.遅延分の時間が経過した後,. ヒットしたエントリに特別な優先度を設けることでキャッ. 当該パケットの処理は完了となり,同時に CMQ 内の同一. シュミス削減を行う手法が提案されてきた[20].本報告で. フローパケットの処理も完了となる.更に,この時当該フ. は,HPC と同様にヒットしたエントリを特別な領域へ移動. ローのキャッシュエントリを新規エントリとしてキャッシ. する Segmented LRU(SLRU)を比較対象として用いる[21].. ュに挿入する.本シミュレータにおけるキャッシュミスは. SLRU の概要を図 6 に示す.SLRU では,新規エントリは. キャッシュ及び CMT でミスをしたパケットとなる.. 追い出し優先度の最も低い MRU ポジションに挿入される.. 本シミュレーションによる,WIDE 及び Academic トレー. そして,キャッシュヒット時には Protected Segment の MRU. スを用いたパケットミス率の測定結果を図 8 に,4way LRU. ポジションへと移動が行われる.SLRU はキャッシュを二. キャッシュに対するパケットミスの改善率を図 9 に示す.. つの領域に分けてはいるが,キャッシュの挙動としては. HPC のシミュレーションでは,通常領域からヒット領域へ. 8way キャッシュにおいて新規エントリの挿入位置を 4 番. エントリを移動するために必要なヒット回数を 1,2,4,8,. 目に追い出されやすい位置へと変更した,LRU の改良手法. 16 に設定し,それぞれを HPC1~HPC16 と呼ぶことにした.. に等しい.. シミュレーション結果によると,HPC のキャッシュミス削. 5.1 キャッシュミス削減性能のシミュレーション. 減効果は,同様にヒットエントリを特別に扱う SLRU より. まず,HPC におけるキャッシュミス削減性能を評価する. も高く,WIDE トレースでは 15%程度,Academic トレース. ため,C++で作成したシミュレータによるパケット処理キ. では 11%程度のキャッシュミスが改善されている.また,. ャッシュシミュレーションを行った.シミュレータの構成. HPC における通常領域とヒット領域のエントリ移動は,ト. を図 7 に示す.本シミュレータはネットワークトレースの. ラフィックに依らず 4 回が最も効果的であり,これ以上の. タイムスタンプ値をもとに,時間経過をシミュレートし処. 回数ではミスが増大することがわかった.本シミュレーシ. 理を行う.経過時間がタイムスタンプ値と一致したパケッ. 4entry+4entry. 128line. CRC Module. n回 Hit. Hit. 処理完了 CMQ. Miss. 新規エントリ挿入. フローID(104bit). Flow Extractor. Cache. Normal Region. 7bit ハッシュ値. Hit Region. トは,Flow Extractor によりフローID の抽出が行われる.. CMT. Miss. Hit 処理完了. PE Alocater (64PE). 処理完了. (Delay 100ns). パケット. 図 6 Figure 6. Segmented LRU の処理概要. Processing Outline of Segmented LRU.. ⓒ2014 Information Processing Society of Japan. 図 7 Figure 7. パケット処理キャッシュシミュレータの構成 Composition of Packet Processing Cache Simulator.. 5.
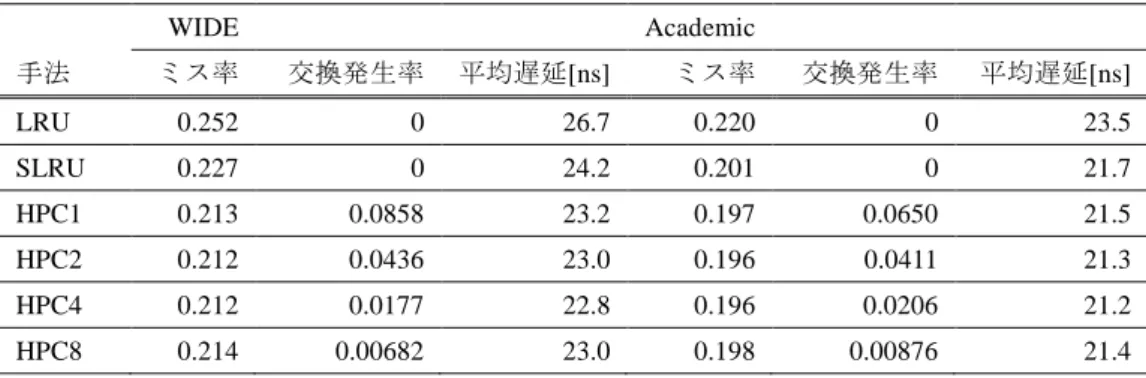
(6) 情報処理学会研究報告 IPSJ SIG Technical Report. 図 8 Figure 8. Vol.2014-ARC-211 No.10 2014/7/28. キャッシュミス率の測定結果. Measurement Results with Cache-miss Rate.. 図 10 Figure 10. HPC4 の優先度管理の例. Example of Priority Management on HPC4.. 優先度管理の例を図 10 に示す.HPC では通常領域とヒッ ト領域を分け,それぞれ 4way として優先度を付ける.更 に,通常領域のエントリにヒットカウンタを設け,ヒット 領域とのエントリ交換に用いる.ヒットカウンタは HPC2 図 9 Figure 9. キャッシュミス改善率の測定結果. Measurement Results with Improvement Rate of Cache-miss.. では 1 エントリあたり 1bit,HPC4 では 2bit となり,例え ば 1K エントリを持つ HPC8 では 3bit のカウンタを 512 エ ントリ分で 192Byte が必要となる.通常領域のエントリが ヒットし,カウンタが溢れた時に,通常領域とヒット領域. ョンにより,パケット処理キャッシュの性質に特化した. それぞれのキャッシュメモリ内のデータを入れ替える(図. HPC4 を用いることで大幅にキャッシュミス削減が可能で. 10 中のフローA とフローG).この際,エントリ優先度の遷. あることが示せた.. 移は通常領域のみで起こり,ヒット領域の優先度順位を変. 5.2 実装コストの検討. 更する必要はない.ヒット領域でキャッシュヒットが起こ. キャッシュのハードウェア実装における実装コストは,. った際には,ヒット領域のみ優先度の遷移を行う.また,. メモリ容量による回路規模とエントリ優先度の管理コスト. 新規エントリの挿入は,通常領域の優先度の最も低いエン. が大部分である.HPC は一つのキャッシュインデックスに. トリとキャッシュデータを入れ替えるだけであり,優先度. 対し,8 つのデータが入った疑似的な 8way キャッシュ構造. の遷移は起こらない.このように,HPC におけるエントリ. である.一般に 8way キャッシュは,得られるキャッシュ. 優先度の遷移は,キャッシュヒットのあった領域で 4way. ミス削減効果に対する実装コストが高いことが知られてい. キャッシュと同様に遷移を行うだけで良く,優先度管理に. る[23].近年の 4way 以下のキャッシュにおける LRU 実装. かかる実装コストは LRU を用いた 4way キャッシュと同等. は,キャッシュライン毎のエントリ優先度の順位を優先度. である.. 管理メモリに格納しておき,ヒットがあった際に当該ライ. 5.3 平均検索遅延の検討. ンの優先度順位を遷移させ,優先度管理メモリを更新する. パケット処理キャッシュによるテーブル検索処理では,. 手法が用いられている[24].8way キャッシュではエントリ. 処理遅延はキャッシュミス率に左右される.State University. 優先度の順位が 40,320 通りであり,更に,各 way でヒット. of New York の Gopalan らによると,キャッシュミス率を m,. することによる遷移パターンは 322,560 通りである.この. L1 キャッシュのアクセス遅延を th,テーブル検索処理の遅. ように,8way 以上のキャッシュではエントリ優先度管理の. 延を tm としたとき,平均検索遅延は th×(1-m)+tm×m に. ための実装コストが大幅に増加する.SLRU も上記の問題. より計算される[5].また,カリフォルニア大学の Talbot ら. を解決する手法ではなく,ハードウェアへの実装が必要な. によると,th を 2ns,tm を 100ns とすることができる[25].. キャッシュには向いていない.パケット処理キャッシュで. 本節では,上記の手法をもとに HPC の平均検索遅延につい. は,キャッシュミス削減効果だけでなく実装コストについ. て検討を行う.. ても検討を行う必要がある. HPC は疑似的な 8way 構造のエントリ優先度を 4way と 等しい実装コストにより管理することができる.HPC4 の. ⓒ2014 Information Processing Society of Japan. HPC は,通常のキャッシュ機構とは異なり,通常領域の エントリが複数回ヒットした時にヒット領域のエントリと 交換が行われる.このようなキャッシュ更新は,パケット. 6.
(7) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2014-ARC-211 No.10 2014/7/28. 表 2 Table 2. エントリ交換発生率と平均検索遅延の測定結果. Measurement Results with Rate of Entry Change and Average Lookup Delay.. WIDE. Academic. 手法. ミス率. 交換発生率. 平均遅延[ns]. ミス率. 交換発生率. 平均遅延[ns]. LRU. 0.252. 0. 26.7. 0.220. 0. 23.5. SLRU. 0.227. 0. 24.2. 0.201. 0. 21.7. HPC1. 0.213. 0.0858. 23.2. 0.197. 0.0650. 21.5. HPC2. 0.212. 0.0436. 23.0. 0.196. 0.0411. 21.3. HPC4. 0.212. 0.0177. 22.8. 0.196. 0.0206. 21.2. HPC8. 0.214. 0.00682. 23.0. 0.198. 0.00876. 21.4. 到着に余裕がある時は次パケットの到着までに行うことで. HPC では,新規エントリは通常領域の LRU ポジション. 遅延とならないが,キャッシュに対して待ち行列ができて. へと挿入され,複数回ヒットすることでヒット領域へと移. いる際には遅延となる.ここで,エントリ交換にかかる遅. 動する.これにより,ロングフローに高い優先度を充て,. 延を 4ns と仮定した場合,HPC によるエントリ交換を含め. 尚且つ,ショートフローを積極的に追い出すことが可能と. た平均検索遅延は次式により計算される.. なり,15%程度のキャッシュミスを改善できることがシミ ュレーションにより示された.また,本手法のハードウェ ア実装コストは,一般的な 4way キャッシュにヒットカウ. 式中の c は,エントリ交換が発生する割合である.HPC で. ンタの数百 Byte を追加した程度であり,比較的容易に実装. は,エントリ交換を行うためのヒット回数 n によって,エ. 可能である.HPC では,連続してパケットが到着した際に,. ントリ交換の発生率が異なるため,n の値が大きい程エン. エントリ交換に伴うメモリ読み書きのための遅延が生じる.. トリ交換遅延の影響は少なくなる.これらの議論をもとに,. この遅延の影響は,エントリ交換するためのヒット回数を. エントリ交換の発生率をシミュレーションにより測定し,. 多く設定する程小さくなるが,キャッシュミス率を考慮す. 平均検索遅延の計算を行った結果を表 2 に示す.WIDE と. ると,4 回のヒットによりエントリ交換する HPC4 を用い. Academic トレースでは,共に HPC4 によるパフォーマンス. ることが最適である.HPC4 を用いることで,テーブル検. が最も高い.WIDE トレースでの平均検索遅延は 22.8ns で. 索処理の平均遅延は一般的な LRU を用いた 4way キャッシ. LRU に対し 14.5%遅延を改善している.また,Academic. ュに対し,10%以上改善できることが示された.. トレースでの平均検索遅延は 21.2ns で LRU に対し 9.71% 遅延を改善している.これらの結果から,パケット処理キ. 謝辞. ャッシュではトラフィックに依らず HPC4 を用いることで,. この研究は、文部科学省. 10%以上のテーブル検索遅延の改善を見込めることが示さ. 一体的推進気候変動に対応した新たな社会の創出に向けた. れた.. 社会システムの改革プログラム「グリーン社会 ICT ライフ. 6. 結論 近年のネットワークトラフィックの増加に対し,ルータ. 社会システム改革と研究開発の. インフラ」、文部科学省科学技術研究費補助金基盤研究 B 「機能維持性を高める建物・複数機器の協調制御」 (24360230)ならびに「コンテンツベース・スマートコミュ. は,従来の PE 集積度向上による並列処理手法のみでスル. ニティインフラの構築と展開」(25280033)、の一環として. ープットを向上することは困難となっている.そこで,パ. なされた。. ケット処理においてボトルネックとなるテーブル検索の処 理結果をキャッシュすることで,テーブル検索処理を高速. 参考文献. 化するパケット処理キャッシュが提案されてきた.パケッ. 1) 我が国のインターネットにおけるトラヒックの集計・試算 http://www.soumu.go.jp/main|_content/000279409.pdf 2) Crowly, P. and Onufryk, P.Z.: Network Processor Design: Issues and Practices, vol.1, Morgan Kaufmann (2003). 3) Ceuppens, L. and Kharitonov, D.: Power Saving Strategies and Technologies in Network Equipment Opportunities and Challenges, Risk and Rewards, International Symposium on SAINT, pp.381-384 (2008). 4) Feldmeier, D.C.: Improving gateway performance with a routing-table cache, In Proceedings of IEEE INFOCOM,. ト処理キャッシュにおける処理遅延はキャッシュミス率に 左右され,容易にキャッシュ容量を向上できないパケット 処理キャッシュにとって,エントリの適切な制御によりキ ャッシュミスを削減することは重要であった.本報告では, パケット処理キャッシュの性質に特化したエントリ制御手 法である Hit Priority Cache(HPC)を提案することでキャ ッシュミス削減を行った.. ⓒ2014 Information Processing Society of Japan. 7.
(8) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2014-ARC-211 No.10 2014/7/28. pp.298-307(1988). 5) Gopalan, K. and Tzi-cker, C.: Improving Route Lookup Performance Using Network Processor Cache, In Proceedings of ACM/IEEE SC, pp.16-22 (2002). 6) Francis, C. and Kang, L.: Efficient Packet Classification with Digest Caches, In HPCA Workshop on Network Processors (NP3 (2004). 7) Baer, J.L., Low, D., Crowley, P., and Sidhwaney, N.: Memory Hierarchy Design for a Multiprocessor Look-up Engine, In Proceedings of PACT, p.206 (2003). 8) Taylor, D.E.: Survey and taxonomy of packet classification techniques, In Proceedings of ACM Computing Surveys, Vol.37, No.3, pp.238–275 (2005). 9) Douglas, E.C.: Network Systems Design using Network Processors, Pearson Education Inc., p.68(2004). 10) Gupta, P. and McKeown, N.: Algorithms for packet classification, IEEE Network, Vol.12, No.2, pp.24-32 (2001). 11) Kang, L. et al.: Architectures for packet classification caching, In Proceedings of ICON, pp.111-117 (2003). 12) Kobayashi, M. et al.: A longest prefix match search engine for multi-gigabit IP Processing, In Proceedings of IEEE ICC, Vol.3, pp.1360-1364 (2000). 13) Chvets, I. L. and MacGregor, M.H.: Multi-zone caches for accelerating IP routing table lookups, IEEE Workshop on HPSR, pp.121-126 (2002). 14) Ata, S. et al.: Efficient cache structures of IP routers to provide policy-based services, In Proceedings of IEEE ICC, vol.5, pp.1561-1565(2001). 15) Girish, C. and Govindarajan, R.: Improving performance of digest caches in network processors, In Proceedings of HiPC, pp.6-17(2008). 16) Moinuddin, K.Q. et al.: Adaptive insertion policies for high performance caching, In Proceedings of ACM ISCA, pp.381-391(2007). 17) Chuanjun, Z. and Bing, X.: Divide-and-conquer: a bubble replacement for low level caches, In Proceedings of ACM ICS, pp.80-89(2009). 18) Yamaki, H. and Nishi, H.: An Improved Cache Mechanism for Cache-based Network Processor, Journal of Communication and Computer, Vol.10, No.3, pp.277-286 (2013). 19) Tatsuya, M. et al.: Identifying elephant flows through periodically sampled packets, In Proceedings of ACM SIGCOMM IMC, pp.115-120 (2004). 20) Guangdeng, L. et al.: A new IP lookup cache for high performance IP routers, In Proceedings of ACM/IEEE DAC, pp.338-343(2010). 21) Ramakrishna, K. et al.: Caching strategies to improve disk system performance, Journal of Computer, Vol.27, No.3, pp.38-46(2004). 22) Okuno, M. and Nishi, H.: Network-Processor Acceleration-Architecture Using Header-Leraning Cache and Cache-Miss Handler. In Proceedings of SCI2004, Vol.3, pp.108-113(2004). 23) Hassan, G. and Fatemi, S.O.: Pseudo-FIFO Architecture of LRU Replacement Algorithm, In Proceedings of IEEE INMIC, pp.1-7 (2005). 24) Hassan, G. et al.: Modified pseudo LRU replacement algorithm, International Symposium and Workshop on IEEE ECBS, pp.376-381(2006). 25) Talbot, B. et al.: IP caching for terabit speed routers, In Proceedings of GLOBECOM, Vol.2, pp.1565-1569 (1999).. ⓒ2014 Information Processing Society of Japan. 8.
(9)
図
+3
関連したドキュメント
This paper presents an investigation into the mechanics of this specific problem and develops an analytical approach that accounts for the effects of geometrical and material data on
As in 4 , four performance metrics are considered: i the stationary workload of the queue, ii the queueing delay, that is, the delay of a “packet” a fluid particle that arrives at
We will study the spreading of a charged microdroplet using the lubrication approximation which assumes that the fluid spreads over a solid surface and that the droplet is thin so
Equivalent ISs This paper mentions several particular ISs that describe a given Moore family, more or less small with respect to their size: The full IS Σ f that contains an
Wro ´nski’s construction replaced by phase semantic completion. ASubL3, Crakow 06/11/06
For the image-coding applications, we had proposed an efficient scheme to organize the wavelet packet WP coefficients of an image into hierarchical trees called WP trees 32.. In
A compact set in the phase space is said to be an inertial set inertial set inertial set inertial set (or a fractal exponential attractor) if it is positively invariant ,
Keywords: probability inequalities; large deviations; Rademacher random variables; sums of independent random variables; Student’s test; self-normalized sums; Esscher–Cramér tilt
