DEIM Forum 2015 G3-3
LZE++:
共有辞書を用いた圧縮データに対する
ランダムアクセスの高速化
山室
健
†鬼塚
真
††本庄
利守
††
NTT
ソフトウェアイノベーションセンタ
〒 180–8585 東京都武蔵野市緑町 3-9-11
††
大阪大学大学院情報科学研究科
〒 565–0871 大阪府吹田市山田丘 1 − 5
E-mail:
†{
yamamuro.takeshi,honjo.toshimori
}
@lab.ntt.co.jp,
††
onizuka@ist.osaka-u.ac.jp
あらまし 入力データ列 T[0...N-1] を圧縮したデータに対して,任意位置の長さ m の部分データ列を高速に復元(ラ
ンダムアクセス)可能な LZE++を提案する.ランダムアクセスを O(m) の計算量で実現する LZ77 ベースの LZEnd が
先行研究として提案されている.LZEnd では再帰処理と簡潔データ構造を用いて部分データ列の復元を可能にするが,
O(m)
回の再帰処理に起因する CPU の実行命令数やキャッシュミス回数の増大が課題となる.そこで LZE++では共有
辞書を用いた再帰処理の枝刈りと,復元済みのデータを参照して O(m) 回の再帰処理を平均 mK/N+1 回(K は因子化
のブロック数で K<
=N)の while-loop で置換する最適化で LZEnd と同等以下の計算量かつ高速な復元処理を実現する.
評価実験では LZEnd の簡単な改良で,on-memory 上の処理にも関わらず 64 KiB 以下のデータの復元処理で 3.3∼58.2
倍の,64 KiB より大きなデータの復元処理で最大 1439.0 倍の大幅な改善が可能であることを示す.
キーワード データ圧縮,LZ77,簡潔データ構造
1.
研 究 背 景
データのサイズ削減という観点で圧縮は基本的でかつ重要な 要素技術として幅広い分野で活用されている.LZ77は可逆圧縮 手法の中で最も有名で,UNIXで用いられるgzip(注 1)や CPUに 最適化されたSnappy(注 2)などの代表的な実装が存在する.LZ77 では入力データ列を先頭から順番に処理し,現在符号化を行お うとしている位置から始まる部分データ列が,それ以前に出現 していたかを探索する.出現している場合は,過去の出現位置 を示す参照に置き換えることで圧縮を行う.列指向DBMS [1] や検索エンジン[2] [11]などの処理系では,圧縮技術はデータ サイズ削減に加えて処理速度の改善にも活用されている.特に 特定の条件を満たす部分だけを必要とする場合に,任意位置の 部分データ列だけを復元(ランダムアクセス)する操作は時間 と空間の両方の処理コストを改善可能である.例えば,以下の ようなユースケースが考えられる. • あるサービスがユーザの日々の活動(アクセス時間,ア クセスURI,ユーザが生成したコメントなどのデータ等)を圧 縮して管理していて,データ分析者が任意の期間内に特定の データ列を含むユーザ情報を抽出したい場合. • サーバがアクセス情報や負荷状況を圧縮して日々記録し ていて,障害は発生した場合に特定のエラー情報を含むログを 探索することで原因の究明したい場合. しかしLZ77を用いた場合には,圧縮前のデータ列と圧縮後 の符号列の位置情報に関する対応関係を保持していないため, 任意位置の部分データ列だけを復元するには先頭から復元対象 (注 1):http://www.gzip.org (注 2):http://code.google.com/p/snappy/ の部分データ列まで全てを処理する必要がある.そのため元の データ長をNとした場合にO(N)の計算量が必要になる. データ長Nに依存せずに圧縮データの効率的なランダムアク セスを実現するためには2つの異なるアプローチが考えられる. 1つ目の単純なアプローチは,圧縮対象のデータ列を固定長k のブロックに分割をして各ブロックを既存手法で圧縮を行う方 法(Block-based Compression,以下BC)である.データ列の先 頭からi番目に位置する部分データ列を復元する場合には,i/k 番目のブロックのみを復元してi%k番目に位置する部分データ 列を返却すれば良いため計算量はO(k)である.この手法は最も 単純であるため検索エンジンで有名なLuceneの内部データに も活用されている.2つ目のより洗練されたアプローチは,近 年提案された任意位置の長さmの部分データ列をO(m)で復元 可能なLZEnd [3]を用いる方法である.LZEndはLZ77を参考 にした手法で,簡潔データ構造を用いることでランダムアクセ スを可能にしている.簡潔データ構造は2000年以降に離散ア ルゴリズム分野で主に研究されている手法で,データ構造のサ イズを情報理論的下限に漸近させながら,データの明示的な復 元をせずに列挙や探索などの問い合わせを可能にする方法であ る. 木構造や索引など様々なデータ構造において活用する方法 が既に多く提案されている[5] [6] [7] [8]. しかし上記の既存手法は以下に挙げる課題が存在する. • BCにはよく知られたブロック長kにおける圧縮率と性 能のトレードオフが存在する.ブロック長kを大きくすれば圧 縮率は高くなるが,部分データ列の復元時間と空間コストが増 大する.一方kを小さくすると処理コストは小さくなるが,圧 縮率は低くなる.最適なkは利用用途に依存するため,圧縮す る際に最適値を決定することは一般的に難しい. • LZEndでは再帰処理と簡潔データ構造を用いて部分データ列の復元を行うが,O(m)回の再帰処理の毎に発生する簡潔 データ構造の問い合わせ処理によるCPUの実行命令数やキャッ シュミス回数増大が復元性能の課題になる. 図1にCPU(Xeon 5670)における参照パターンと参照速度 の関係を示す事前実験の結果を,図2に圧縮していないデー タの部分データ列の参照に対するLZEndの実行命令数とL1 キャッシュミス回数の相対値を示す.図1では参照サイズと間隔 をそれぞれ変化ながら評価を行った.L2キャッシュ(1.5 MiB) を超えた場合に,最大40倍の差(三角実線)が発生している. この事前実験の結果や先行研究による報告[10]により,CPUの 最適化の有無でon-memory上の処理にも関わらず2桁以上の性 能差が容易に起こることが分かる.図2は圧縮していないデー タ列の参照に対してLZEndでは2桁以上の実行命令数とキャッ シュミス回数が発生することを示している.次節2. 2では,こ れらの原因であるLZEndにおける再帰処理について詳述する. 図 1 Xeon 5670における参照パターンと参照速度の関係.Xeon 5670 における L1(data),L2,LL(Last Level)キャッシュはそれぞ れ 129 KiB,1.5 MiB,12 MiB である.最大の間隔(16 KiB)で ある三角実線が最もランダムな参照パターンを示している. 図 2 LZEndにおける実行命令数と L1 キャッシュミス回数の相対値. 横軸は参照サイズ m,縦軸は圧縮していないデータの同等の操 作に対する相対値をそれぞれ示している. 本研究の目的は,BCのように圧縮率や性能が用途に依存する パラメータを持たない高速な復元を可能にする手法(LZE++) を提案することである.LZE++では共有辞書を用いた再帰処理 の枝刈りと,復元済みのデータを参照してO(m)回の再帰処理 をwhile-loopで置換する最適化を行うことでLZEndと同等以 下の計算量かつ高速な復元処理を実現する.共有辞書は入力 データ列(長さN)から抜き出した固定長M(M<<N)の部分 データ列である.辞書作成時間が圧縮処理のオーバヘッドとな ることと,辞書サイズが復元処理時に集中して参照されること から性能に影響することが懸念される.そこで固定長kでサン プリングした部分データ列に対して頻出パターン列挙手法であ るPrefixSpan [12]を適用し,頻出語のみを共有辞書に含めるこ とで圧縮を行う.復元しようとしている符号列が共有辞書内の 部分データ列を示している場合に,以降の再帰処理を枝刈りす ることができる.また一定以上のデータ列を復元した場合に, 復元をしようとする符号が既に復元済みのデータ列を参照して いる場合がある.この場合に復元済みのデータ列を活用するこ とでO(m)回の重い再帰処理を平均mK/N+1回(Kは因子化の ブロック数でK<=N)の軽量なwhile-loopによる繰り返し処理 で置換することが可能になる.最長共通接頭辞の探索範囲を限 定し,限定した範囲を超えた処理は必ず復元済みのデータを参 照している特性を利用することでこの最適化を適用する. 本研究の貢献を以下に示す. • 圧縮されたデータ列に対して,用途に依存したパラメー タを持たず高速なランダムアクセスを可能にするLZE++を提 案する.共有辞書を用いた再帰処理の枝刈りと,平均mK/N+1 回の軽量な繰り返し処理によりLZEndと同等以下の計算量か つ高速な復元処理を可能にする. • LZEndに対する簡単な改良で,on-memory上の処理にも 関わらず64 KiB以下のデータの復元処理で3.3∼58.2倍の,64 KiBより大きなデータの復元処理で最大1439.0倍の大幅な改 善が可能であることを示す. • LZE++では最長共通接頭辞の探索範囲を限定したこと で一部の条件で圧縮率が悪化するが,圧縮率とランダムアク セス性能のトレードオフの観点でLZEndに対して依然として LZE++が有利であることを示す. 次節2. 1では,LZEndにおける因子化と実装を概説して,図 2の原因であるLZEndの再帰処理を示す.節3.では,提案手 法における共有辞書の作成方法,辞書を用いた再帰処理の枝刈 り方法,O(m)回の再帰処理を平均mK/N+1回の繰り返し処理 に置換する方法をそれぞれ説明する.節4.で実験結果を示し, 最後の節5.と節6.で関連研究と結論を述べる.
2.
前提知識
: LZEnd
LZEnd で は 入 力 デ ー タ 列 T[0...N-1]=t0t1...tN−1(ti ∈ Σ, 0<=i<N)(注 3) を因子化したZ[0...K-1]=z0z1...zK−1(Kは因子化 のブロック数でK<=N)の計算を次の手順で行う.T[0...i-1]を Z[0...p-1]と因子化済みであるとして,因子化済みの列を以降 ではhistoryと呼ぶ.Z[0...q] (q<p)の接尾辞と共通な最長接頭 辞T[i...i+l-1]をT[i...N-1]から探索する.結果としてT[i...i+l] をzp=zqti+lとする.ここでT[i...i+l-1]に対応したhistoryにおけるzqをsourceと呼ぶ.この変換処理をT[N-1]まで繰り 返すことで因子化を完了する.LZEndにおける因子化は最後の zK−1を除く全ての要素が異なるため,この因子化は粗く最適 (coarsely optimal)である.因子化が粗く最適である場合,以 下の定理が成り立ち,符号化後のデータサイズは情報理論下限 値に漸近することが知られている[13]. Theorem 1. データ列の因子化が粗く最適である場合,圧縮率 ρ(T )とk次経験エントロピーHk(T ) [14]との差は∥T ∥をパラ (注 3):Σ は任意のデータ集合で,文字データの場合には文字集合である.
メータとする式で表され,∥T ∥の値が大きくなると漸近的に 0になる.つまり∀kに対してlim∥T ∥→∞fk(∥T ∥)=0 s.t. ρ(T ) <= Hk(T )+fk(∥T ∥)を満たすfkが存在する. 2. 1 LZEndのデータ構造 LZEndでは因子化したZに対して,符号列の内部表現とし て以下の3つのデータ構造を保持する. • c[0...K-1]: Zの各要素における末尾記号列 • x[0...K-1]:参照するzq(source)の添字列 • B[0...N-1]: cに格納した記号の位置を記録したbit列 例えばzp=zqti+lを考えた場合,c[p]=ti+l,x[p]=qとして, B[i+l]のbitを立てることで表現される.Bは簡潔データ構 造で保持することで,次に説明するrankとselectの問い合
わせを実現する.rankB(i)はB[0...i]の範囲にあるbitの総数
を返し,selectB(i)はi+1番目に立てられたbitの添字を返す.
rankとselectをO(1)やO(logN)で効率的に処理する手法が
様々提案されている.例えば,立てられてたbitが疎なBに 対してNH0に圧縮が可能な手法[15]などが存在する.結果的 にzpの長さlはBに対してselectB を問い合わせることで, selectB(p+1)-selectB(p)-1として計算できる. 2. 2 LZEndの実装 Algorithm 1復元処理extract(base, m)の擬似コード
1:/* IN – base: start position to decompress */ 2:/* IN – m: length */
3:/* OUT – extracted symbols in T[base...base+m-1] */ 4:if n > 0 then 5: end = base + m - 1; 6: r = rankB(end); 7: if B[end] == 1 then 8: extract(base, m - 1); 9: Append c[r] to an output; 10: else 11: pos = selectB(r) + 1; 12: if base < pos then
13: extract(base, pos - base); 14: m = end - pos + 1 15: base = pos; 16: end if
17: ref = selectB(x[r+1]) - selectB(r + 1) + base + 1; 18: extract(ref, m);
19: end if
20:end if
LZEnd に お け る 復 元 処 理 をAlgorithm 1 に 示 す[3]. ex-tract(base, m) はT[base...base+m-1] の部分データ列を復元す ることができる.B[end]のbitが立っている場合(7行目),対
応する位置の記号は末尾記号であるためc[r]を出力する(9行
目).LZEndでは最長接頭辞T[i...i+l-1]がhistoryの接尾辞zq
(source)に対応するように因子化を行うため,参照している
sourceの位置を計算してextractを呼び出すことでT[i...i+l-1]
の復元を再帰的に行う(9∼16行目).1つの記号を復元するた めに1回以上のextractを呼び出す必要があるため,結果的に 任意位置の長さmの部分データ列を復元するためにはO(m)回 のextractの再帰処理が必要になる.
3.
提案手法
: LZE++
3. 1 設 計 概 要 この節ではLZE++における共有辞書を用いた再帰処理の枝刈 りと,復元済みのデータを参照してO(m)回の再帰処理を単純 な繰り返し処理で置き換える手法の概略を説明する.T[0...N-1] から固定長kでサンプリングした部分データ列に対して頻出パ ターン列挙手法であるPrefixSpan [12]を用いて圧縮する共有辞 書S[0...M-1](M<<N)の詳細は次節3. 2で説明する. 図 3 LZE++と LZEnd の復元処理の動作の概略.灰色の記号は過去の 出現位置を示す参照に置き換えられ,太字の記号は c に格納され ている.図中の矢印が復元処理関数 extract の 1 回の再帰的な呼 び出しをそれぞれ表している. データ列の因子化の際に最長共通接頭辞が共有辞書内で探索 された場合に,共有辞書内の出現位置を示す参照に置き換える ことで,この参照を復元する際に以降の再帰処理を枝刈りする ことが可能になる.この共有辞書を用いた再帰処理の枝刈りの 概要を図3に示す.図中右下の’abcd’をLZEndで復元する処 理を考える.’d’はcに格納されているためそのまま出力に書 き出し,’abc’は参照で置き換えられているためextractを再帰 的に呼び出す.参照先でも同様の処理を最後まで繰り返して, 最終的に3回のextractの再帰的な呼び出しを行う.LZE++で は,共有辞書上の’ab’への参照が含まれているため共有辞書内 のデータをそのまま出力することができる.そのため以降の再 帰処理を枝刈りすることができ結果的に2回の呼び出しで復 元を完了することができる.LZE++における共有辞書を考慮し た復元処理関数を以降ではextract’と呼ぶ.LZEndの再帰処理 ではxに記録されている参照を後方に辿る処理(ランダムアク セス)が繰り返し発生するため,CPUのキャッシュミス回数が 増大して復元速度の遅延が発生する可能性がある.LZE++では PrefixSpanで圧縮した共有辞書を用いることで再帰処理を枝刈 りしてランダムアクセスを抑制すること,さらに全ての復元処 理でCPUのキャッシュサイズ程度の辞書を共有することでCPU の実行効率改善を図ることができる. 図 4 単純な繰り返し処理による復元方法 (extract seq) の概略.先行 する長さ wlen の部分データ列を extract′で復元し,それ以降 の処理は再帰処理を用いず既に復元済みの部分データ列を参照し ながら繰り返し復元を行う. 一定以上のデータ列を復元した際に,復元をしようとする符 号が既に復元済みの部分データ列を参照している場合がある. そこでLZE++の因子化で最長共通接頭辞の探索範囲をwlenに 限定し,wlenを超えた処理は必ず復元済みのデータを参照し ている特性を利用して単純な繰り返しで復元処理を置き換える.この処理の概要を図4に示す.復元を行う部分データ列の 先頭からwlenの範囲はextract’で処理を行い,wlenを超えた 範囲のデータ列の復元処理は復元済みの部分データ列(図中で はagpxz)を参照しながら復元を行う.LZE++における再帰処 理を除いた復元処理関数を以降ではextract seqと呼ぶ.CPU命 令を活用することで復元済みの部分データ列の位置を計算する 処理の最適化も併せて行う.節3. 4では単純な繰り返しによる 符号列の復元方法とCPU命令を用いた最適化を詳述する. 3. 2 ランダムアクセス高速化のための共有辞書 LZE++で使用する共有辞書の作成方法を示す.前節3. 1で説 明した通り,共有辞書S[0...M-1](M<<N)は枝刈りが効率的 に行えるように頻出パターンを含みながら,CPUのキャッシュ サイズ程度に小さく構築する必要がある.また共有辞書の作 成時間は圧縮処理のオーバヘッドになるため,本手法では固定 長kでサンプリングしたデータ列に対してPrefixSpan [12]を適 用することで圧縮を行う.まず入力データ列T(長さN)から r%の領域B(長さL)を取得するために,位置0から等間隔で 0, kN/L, 2kN/L, ...とL/k回長さkの部分データ列をサンプリン グする.PrefixSpanは入力データ列から指定された条件(長さ がα以上でβ以下,かつ頻度がξ回以上)を満たすパターンを 高速に列挙する手法である.Algorithm 2にPrefixSpanを用い た共有辞書を作成するための擬似コードを,図5に入力データ 列’ababaac’を例に共有辞書を作成する具体例をそれぞれ示す. Iは入力データ列B(長さL)に対する接尾辞に対応した添字 の集合(B[i...L-1] (i∈I))を表し,{0, 1, ..., L-1}と初期化する. 7∼15行目のループ処理において,各データ集合Σ(s∈ Σ)の 要素s毎に深さ優先(13行目の再帰処理)で接尾辞間の共通接 頭辞の(対応する添字の)部分集合を探索する.結果的に長さ lengthがα以上でβ以下(10行目と4行目)かつ部分集合の 大きさがξ以上(9行目)となる部分集合I’sを計算する.結 果として得られたB[i...i+length](i∈I’s)をSに追加する(11 行目).また既にSに’abcde’が含まれている場合,最長共通接 頭辞を探索する因子化では’abcd’が冗長になるため9行目の条 件(B[i...i+length+1]∈/S)で不要なデータ列を排除することで共 有辞書のサイズ削減を行う.図5では長さが2以上で3以下 (α=2, β=3)かつ出現頻度が2以上(ξ=2)のパタンを探索する 具体例を示す.まず接尾辞に対応した添字の集合Iを{0, 1, ...,
6}と初期化して,深さ優先で’a’, ’aa’, ’aaa’, ’aab’, ...と探索を 行う.深さ1の’ab’に対応する接尾辞の添字は{0, 2, 4, 5}で部 分集合の大きさが2以上で,深さ2で条件を満たす接尾辞が存 在しなくなるため’ab’をSに追加する.同様に’ba’が条件を満 たすためSに追加してS={ab, ba}を得る.最終的に得られた 集合S内のデータを連結することで’abba’を共有辞書とする. 3. 3 LZE++のデータ構造 LZE++とLZEndの因子化(節2. 1)の違いは最長共通接頭辞 の探索でhisotryと共有辞書の両方を用いる点である.LZE++ では共有辞書内の部分データ列への参照を表現するために, LZEndと内部表現に加えて以下のデータ構造を保持する. • S[0...M-1]:共有辞書のデータ列 • x’[0...K-1]:対応する共有辞書Sの添字列
Algorithm 2共有辞書作成PrefixSpan(I, length)の疑似コード
1:/* IN – I: indices of T and initially I ={0...N-1} */ 2:/* IN – length: length of common prefixes among suffixes */ 3:/* OUT – S: set of frequent patterns (shared dictionary) */ 4:if length > β then
5: Return; 6:end if
7:while s∈ Σ do
8: I’s={i ∥ i ∈ I ∩ T[i + length] == s}; 9: if∥I’s∥ >= ξ then
10: if length > α && T[i...i + length + 1]∈/ S then
11: S = S∪ {T[i...i + length] ∥ i ∈ I’s}; 12: end if 13: PrefixSpan(I’s, length + 1); 14: end if 15:end while 図 5 ’ababaac’に対する PrefixSpan(α=2, β=3, ξ=2)の例.結果とし て条件を満たすパターン集合 S={ab, ba} を得る. • R[0...K-1]:共有辞書への参照を表すフラグbit列 例えばzpが共有辞書を参照している場合(zp=S[j...j+l-1]ti+l),
c[p]=ti+l,x’[p]=jとしてB[i+l]とR[p]のそれぞれにbitを立て
ることで表現される.結果的にLZE++では復元処理のはじめ
にzpが過去のsource(zq,q<p)であるZ[x[p]]と,共有辞書
S[x’[p]]のどちらを参照しているかRを使って判断することで
復元処理を行う.この処理に対応した簡単な改良(Algorithm 3)
を,LZEndのextract(Algorithm 1)の17∼18行目に加えるこ とで再帰処理の枝刈りを可能にする.
Algorithm 3 LZEndに対する改善のためのコード(extract’)
1:if R[r] == 1 then
2: ref = x’[rankR(r) + base - pos]; 3: Append S[ref...ref + m] to B; 4:else
5: ref = selectB(x[r + 1]) - selectB(r + 1) + base + 1; 6: extract(ref, m); 7:end if また共有辞書を用いたLZE++における因子化もLZEndと同 様に以下の定理が成り立つため粗く最適である. Theorem 2. Z[p]とZ[p’](p<p’)を考えた場合,Z[p’]は次の 2通りのいずれかの方法で因子化が行われる.最長共通接頭辞 がhistoryから探索されてZ[p]c(c∈Σ)となる場合と,共有辞 書から探索されてS[i...i+k-1]c(i+k-1<M)となる場合である. 前者ではZ[p’]はZ[p]より長く異なる要素になり,後者では最 長共通接頭辞が共有辞書で探索されるため全てのhistoryの要 素と異なることが保証される.結果として最後の要素を除き互 いに異なる因子化のブロックが得られる. 3. 4 復元済みのデータ列を利用した高速化 この節ではextract seqにおける単純な繰り返しによる符号列
の復元方法とCPU命令を用いた最適化を説明する.LZE++の
因子化で最長共通接頭辞の探索をwlenに限定して,wlenを超
えた復元処理は必ず復元済みのデータを参照していることを 利用して単純な繰り返しで復元処理を置き換える.結果として T[base...base+m-1](m>wlen)を復元する際に,T[base...wlen-1] をextract’で,T[base+wlen...base+m-1]をextract seqでそれぞ
れ復元する.また探索をwlenに限定したことで,LZE++のx
の値を絶対値ではなく最大値log(wlen)-bitの相対値で表現する
ことが可能になる.extract seqではCPU命令を活用すること
でLZE++の内部表現であるBとRのbit列から高速に対応す る復元済みの部分データ列の位置を計算することができる.こ
の最適化によりLZEndで記号単位の再帰処理が,因子化のブ
ロック単位で効率的に復元することが可能になる.
Algorithm 4にT[base+wlen...base+m-1]をextract seqで復元 する処理を示す.T[base...wlen-1]のデータ列はextract’で事前 に復元済みであることを前提とする.初期化処理として復元 処理の開始位置を示す変数(r1, r2, pos)を計算する(5∼7行 目).7∼21行目のwhile-loopの1回の繰り返しで1つの因子 化のブロックを復元する.まず始めに現在復元しようとしてい るブロック長を,B上の連続する0を数えることで計算する(8 行目).連続する0を数える処理は一般的なCPU上で広く実 装されているbit操作のための命令を活用することで効率的に 処理を行うことができる.今回の評価実験で使用する環境x64
のCPUでは,64bitのレジスタにB上のbit列をロードしてbsr
命令で連続する0を効率的に数えることができる.もし0が 連続する場合(l!=0),復元済みのデータ列か共有辞書のどち らかからデータ列を復元する.復元済みのデータ列を参照して いる場合(R[r2]==0),単純に参照しているデータ列を出力す る(14行目).ここでxは上述したように現在位置からの相 対的な位置で示される参照であるため,selectBで絶対値に変 換する処理が必要になる(13行目).共有辞書を参照している 場合(R[r2]=1),参照している共有辞書上のデータ列を出力 する(16∼17行目).最後に対応する末尾記号を出力すること で,1つのブロックの復元を完了する.この最適化により復元 処理におけるO(m)回の重い再帰処理を平均mK/N+1回の軽量 なwhile-loopで置き換えることが可能になる.結果として以下 の3つの改善が可能になる. • K/N<1である場合に繰り返し回数の削減 • 再帰処理の除去によるCPU効率の改善 • 1回の繰り返しでのrank/selectの呼び出し回数の削減
4.
評 価 実 験
この節ではLZE++とLZEndのランダムアクセス性能と圧縮 に関する基本性能(圧縮率と圧縮時間)の評価を行う.まず節 4. 1で評価に用いたLZE++とLZEndの実装に関して詳述し,節 4. 2で評価用データを含めた実験環境について説明する. 4. 1 評価実験で用いる実装 まずLZEndの各内部表現のデータ構造(節2. 2)について説 明する.cには末尾記号を格納するため1Bの配列,またxには 対応するsourceの添字を絶対値で格納するため4Bの配列でAlgorithm 4復元処理extract seq(base, m)の疑似コード
1:/* IN – base: start position to decompress */ 2:/* IN – m: length (m > wlen) */
3:/* OUT – extracted symbols in T[base + wlen...base + m - 1] */ 4:r1 = rankB(base + wlen);
5:r2 = rankR(r1); 6:pos = selectB(r1) + 1; 7:while pos - base < m do
8: l = Count leading zeroes from pos in B 9: if l != 0 then
10: if R[r2] == 0 then
11: r3 = r1 - x[r1] + 1; 12: ref = selectB(r3);
13: Copy T[ref...ref + l - 1] to an output; 14: else
15: ref = x’[r2++];
16: Copy S[ref...ref + l - 1] to an output; 17: end if 18: end if 19: Print c[r1++] to an output; 20: pos += l + 1; 21:end while それぞれ表現する.bit配列Bは疎であることから効率的に圧 縮できることが知られているため[3],rankとselectの問い合 わせが可能な圧縮表現であるRecRank [15]を用いる.結果とし てLZEndの因子化のブロック(c,x,B)の最大サイズは41bit である.圧縮処理はLZEndの論文を参考にSuffix Arrayを含む データ構造を事前に構築することでデータ列の因子化を行う. LZE++ではcとBはLZEndと同様の表現を用いる.xは節 3. 4で説明したようにlog(wlen)-bitの相対値で格納するため, wlenを65,536として2Bの配列で表現する.共有辞書のデータ 列Sは1Bの配列,因子化の各ブロックが参照する共有辞書S の添字列は絶対値で保持するため4Bの配列で表現する.節3. 2 で説明したPrefixSpanは入力データ列Tの1%(r=1)の領域 をk=1024の固定長でサンプリングを行った部分データ列Bに 対して適用した.またPrefixSpanの各パラメータは事前実験に よりランダムアクセス性能への影響が小さかったことから(α, β,ξ)をそれぞれ(8,256,8)と固定して評価実験を行った. LZE++の因子化のブロック(c,S,x,x’,B,R)の最大サイズ は58bitsであるため,8B(64bits)以上の部分データ列を参照 することができれば圧縮率に寄与できるためα=8と設定した. 圧縮処理では共通接頭辞の探索範囲をwlenに限定しているた め,LZ77系の実装で一般的に用いられるハッシュテーブルを 用いた.このことから最長接尾辞を探索できないため,実装上 はLZE++の因子化が粗く最適(節3. 3)にはならない.しかし 圧縮処理でLZEndと同様のSuffix Arrayを用いた処理とO(m)
回の再帰処理をwhile-loopで置換する最適化を除くことで粗く
最適な因子化を保証した実装が可能であるが,ランダムアクセ ス性能と圧縮時間を考慮した実装を本評価では選択した.
BとRの表現方法の違いでLZE++1とLZE++2の2つを評価 実験で用いた.LZE++1はLZEndの実装と同様のRecRankを BとRの表現に適用して,節3. 4で説明したwhile-loop内に存 在する1つのselectBの問い合わせを行った.事前実験より上 記のselectが復元性能への影響が大きかったためLZE++2では RはLZE++1と同様の表現を用いて,selectBの問い合わせ結 果だけを事前計算する最適化を適用した.この事前計算による 最適化は圧縮率と圧縮速度には影響しないことからLZE++2の
実装は節4. 3でのみ使用する.
4. 2 実 験 環 境
評価実験では以下9個のテストデータを使用した.
(1) DNAシーケンス(influenzaとEscherichia Coli)と自然 文(einstein.de.txtとworld leaders)(注 4)
(2) enwiki8(注 5) とgov2(注 6) (3) Hadoop(注 7), Cassandra(注 8), PostgreSQL(注 9)のログ (1)は冗長的で圧縮の行いやすい特徴をもつ圧縮手法のベンチ マークでよく利用されるデータである.(2)のenwiki8は2006 年3月3日の英語Wikipediaから先頭108Bを抜き出したデー タである.またgov2は2004年初期の.govドメインのWebサ
イトを収集して集めた集合から128 MiBのデータをランダムに
サンプリングしたものである.(3)は各行が似た情報を含むレ
コード集合で,先頭から128 MiBを抜き出したデータである.
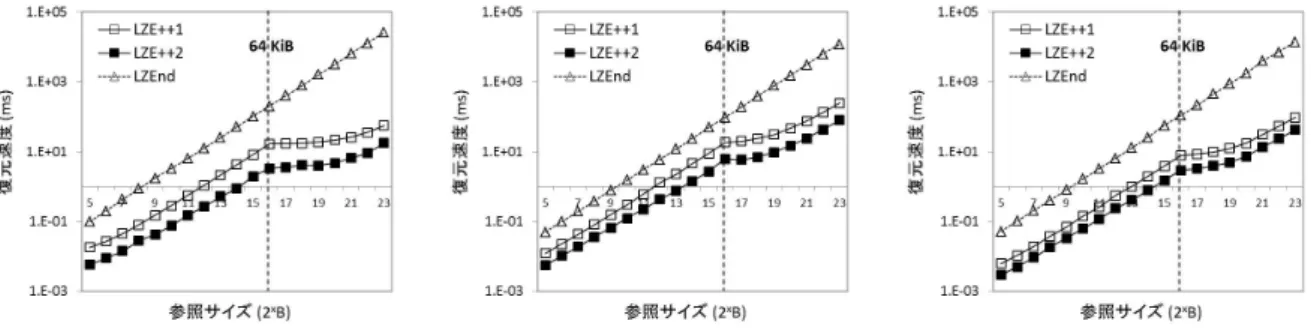
次節4. 3ではLZE++とLZEndのランダムアクセス性能を比較 する.紙面の都合で全ての結果を記載することができないため, LZE++の圧縮率が最も高いPostgreSQL,中央のeinstein.de.txt, 最も低いenwiki8の3つを選択した.これはLZE++の再帰処 理の枝刈りや平均mK/N+1回のwhile-loopによる処理が圧縮率 (因子化のブロック数K)に依存するためである. 節4. 5では圧縮に関する基本性能(圧縮率と圧縮速度)の 比較を行う.LZEnd以外に次の6つの既存手法を比較に用い た.gzip (Version 1.4)は広く使用されているLZ77の実装であ る.bzip2(注 10) (Version 1.0.6)はBurrows-Wheeler変換[14]によ るブロックソートを利用した圧縮手法である.gzipとbzip2 は圧縮率が最も高くなるオプション-9を指定して評価を行っ た.lzip(注 11)(Version 1.12)はスライド窓のサイズに制限のない LZ77(LZMA)で高い圧縮率で知られる実装である.評価では 入力データ列の長さをスライド窓のサイズに設定した.Snappy (Revision 73)とLZ4 (Revision 90)はLZ77の高速な実装である. 最後のRe-Pair(注 12) [16]は文法を考慮した圧縮手法で,冗長的な データの圧縮に向いた特性をもつ. 本評価はXeon5670のサーバを用いて実施した.Xeon5670は L1,L2,LLキャッシュにそれぞれ129 KiB,1.5 MiB,12 MiB を実装している.CPUの統計情報取得にはperf v3.6.9を使用し た.評価用コードは全てC++で記述し,gcc v4.7.1の“-O2”で コンパイルして評価を行った. 4. 3 ランダムアクセスの性能評価 4. 3. 1 64 KiB以下のデータ復元処理 図6(各図中の左部)に25B∼216Bの範囲におけるLZE++ とLZEndのランダムアクセス性能を示す.使用したテストデー タはそれぞれPostgreSQL(左図),einstein.de.txt(中央図), (注 4):http://pizzachili.dcc.uchile.cl/repcorpus.html (注 5):http://cs.fit.edu/ mmahoney/compression/textdata.html (注 6):http://cs.fit.edu/ mmahoney/compression/textdata.html (注 7):http://hadoop.apache.org/ (注 8):http://cassandra.apache.org/ (注 9):http://www.postgresql.org/ (注 10):http://www.bzip.org/ (注 11):http://www.nongnu.org/lzip/lzip.html (注 12):http://www.cbrc.jp/˜rwan/en/restore.html 図 7 T上の共有辞書で置き換えられた部分の俯瞰図.T[0...N-1] が正 方形の左上から右下にかけてに対応し,黒い領域が共有辞書 S で置き換えられた部分を示している. enwik8(右図)である.全ての条件においてLZE++の復元性能 はLZEndより高く,LZEndに対してLZE++1が3.3∼12.0倍, LZE++2が8.1∼58.2倍の性能差である.節4. 2で説明したよ うにselectBの問い合わせ性能がLZE++の復元速度に影響し, LZE++1に対して2.0∼5.1倍程度の差が発生している. 図7に各テストデータTが共有辞書でどの程度置換されて いるか示す.上側が固定長kでサンプリングしたデータ列Bを 共有辞書として使用した場合の,下側がデータ列Bに対して PrefixSpanで圧縮を行った共有辞書の俯瞰図である.T[0...N-1] が正方形の左上から右下にかけてに対応し,黒い領域が共有辞 書Sで置き換えられた部分を示している.つまりT[i...i + l]が 共有辞書内の部分データ列を参照している場合には,対応する 図中の領域が黒く示してある.PostgreSQLにおける置換割合が 44.57%から71.32%に変化し,共有辞書が63.8 KiBで4.83%に 圧縮されている.einstein.de.txtにおける置換割合が23.78%から 22.85%に変化し,共有辞書が124.3 KiBで13.07%に圧縮されて いる.enwik8における置換割合が66.20%から47.46%に変化し, 共有辞書が27.8 KiBで2.84%に圧縮されている.einstein.de.txt とenwik8は置換割合が0.93%と18.74%と悪くなっているもの の,全ての共有辞書が大きく圧縮されていることが分かる. 共有辞書を用いた枝刈りによる再帰処理回数と,CPUの実行 効率(実行命令数とL1/LLキャッシュミス回数)の変化を図8 に示す.それぞれの値はLZEndの値で正規化した相対値で表
し,図中の’baseline’がLZE++とLZEndが同じ値であること
を示している.再帰処理回数を削減したことで全体的なCPU の実行効率は改善されているが,参照サイズが小さい時にLL キャッシュミスがLZEndに対して悪化していることが分かる. しかし参照サイズが大きくなるとLLキャッシュミスは相対的 に改善し,最終的に16.01%,55.59%,39.37%となる.この結 果からLLキャッシュミス回数の削減はLZE++の性能の改善に あまり寄与していないことが,図6の参照サイズが小さい場合 のランダムアクセス性能の結果から判断できる. 4. 3. 2 64 KiBより大きなデータ復元処理 図6(各図中の右部)に217B∼223Bの範囲におけるLZE++ とLZEndのランダムアクセス性能を示す.結果から明らかなよ うに全ての条件においてLZE++の復元性能はLZEndより高く,
図 6 25B (32 B)∼223B (8 MiB)における復元性能の比較.使用したテストデータはそれぞれ PostgreSQのログ(左図),einstein.de.txt(中央図),enwik8(右図)である.
図 8 64 KiB以下の LZEnd に対する LZE++の実行効率の相対値.
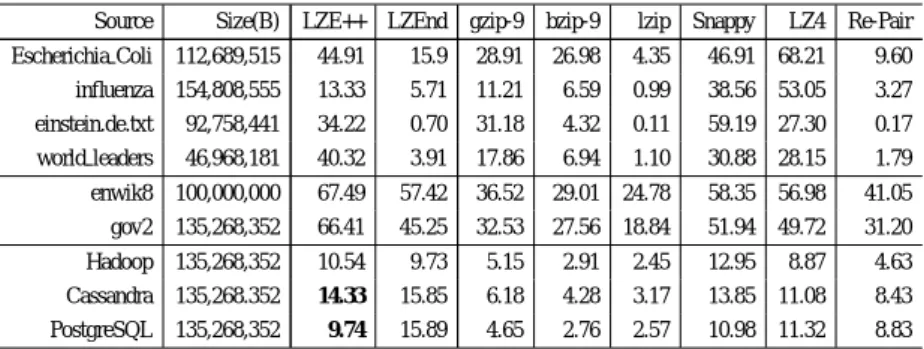
1439.0倍の性能差である.LZE++の64 KiB以下の復元処理の 改善と比較して非常に高く,節3. 3で説明したO(m)回の再帰 処理を平均mK/N+1回のwhile-loopで置き換える最適化を適用 することで復元性能を大幅に改善できることが結果から分かる. 4. 4 圧縮率と圧縮速度 この節では圧縮に関する基本性能の評価として圧縮率と圧縮 速度に関して,LZEndを含めた7つの既存手法と比較したも のを表1と表2にそれぞれ示す.データサイズが異なるため圧 縮速度に関しては1 MiBを復元するために要した時間を示す. 圧縮率に関してはCassandraとPostgreSQLのログ(図中の太 字)において,最長共通接頭辞の探索長をwlenに限定してい るのにも関わらずLZEndに対して圧縮率がそれぞれ1.52%と 6.15%だけ改善している.しかし他の条件では圧縮率は低く, world leadersで36.41%だけ悪化している.これはLZE++では
圧縮処理でSuffix Arrayを用いていない点と因子化のブロック
サイズが最大で17bit大きくなっている点が原因だと考えられ
る.他6つの既存手法を用いた評価結果は次に示す通りであ
る.gzip,bzip2,lzip,Re-Pairのそれぞれの結果はLZEndと LZE++の圧縮率より高く,これはLZEndとLZE++がランダム アクセスを行うためのデータ構造のオーバヘッドが原因だと考
えられる.Re-Pairは冗長なDNAシーケンスと自然文に対し
て,bzip2はenwik8とgov2に対してそれぞれ高い圧縮率を示
している.SnappyとLZ7は復元速度を重視した実装であるた
め,圧縮率はLZEndとLZE++に近い値を示している.
圧縮速度に関してはLZE++はハッシュテーブルを用いた実
装であるためLZ-Endに対して5.9∼126.8倍程度高速である. LZE++の圧縮速度はgzipと,Escherichia Coliとeinstein.de.txt におけるbzip2より悪い結果を示している.一方で上記の2つ を除くbzip2の圧縮速度とは近い値を示している.lzipは非常 に高い圧縮率である一方で,圧縮速度がLZE++に対しても非常 に悪い.SnappyとLZ4の圧縮速度は全条件の中でも非常に高 く,Re-Pairはテストデータに対して一貫しない結果となった. 4. 5 LZEndとLZE++のトレードオフ分析 図 9 LZEndと LZE++における圧縮率と性能のトレードオフ分析. 最後に節4. 3で使用した3つのテストデータを用いてLZEnd とLZE++の圧縮率と223Bのランダムアクセス性能のトレー ドオフ分析を図9に示す.図中の各値は最大値を用いることで 0.0∼1.0に正規化し,図中の左下側が圧縮率と性能ともに良い ことを意味している.図中左下(原点)からの距離という観点 で比較した場合にLZE++は全ての条件でLZEndよりも良い結 果となり,特にPostgreSQLの場合にはLZEndに対して圧縮率 と性能の両面で圧倒的に有利であることが分かる.
5.
関 連 研 究
圧縮は様々な処理系[1] [2] [11]における重要な要素技術とし て活用され,近年ではデータのサイズ削減だけではなく圧縮を 応用した処理速度の改善手法も広く研究されている.列指向 DBMSでは表を列(属性)方向に圧縮して格納し,明示的な復表 1 LZE++と既存手法との圧縮率の比較.Apache Cassandra と PostgreSQL のログ (太字) にお いて,最長共通接頭辞の探索長を wlen に限定しているのにも関わらず LZEnd に対して圧 縮率がそれぞれ 1.52%と 6.15%だけ改善している.
Source Size(B) LZE++ LZEnd gzip-9 bzip-9 lzip Snappy LZ4 Re-Pair Escherichia Coli 112,689,515 44.91 15.9 28.91 26.98 4.35 46.91 68.21 9.60 influenza 154,808,555 13.33 5.71 11.21 6.59 0.99 38.56 53.05 3.27 einstein.de.txt 92,758,441 34.22 0.70 31.18 4.32 0.11 59.19 27.30 0.17 world leaders 46,968,181 40.32 3.91 17.86 6.94 1.10 30.88 28.15 1.79 enwik8 100,000,000 67.49 57.42 36.52 29.01 24.78 58.35 56.98 41.05 gov2 135,268,352 66.41 45.25 32.53 27.56 18.84 51.94 49.72 31.20 Hadoop 135,268,352 10.54 9.73 5.15 2.91 2.45 12.95 8.87 4.63 Cassandra 135,268.352 14.33 15.85 6.18 4.28 3.17 13.85 11.08 8.43 PostgreSQL 135,268,352 9.74 15.89 4.65 2.76 2.57 10.98 11.32 8.83 表 2 1 MiBを復元するための要した時間(ms)の比較.LZE++はハッシュテーブルを用いた実 装であるため LZ-End に対して圧縮速度が 5.9∼126.8 倍程度高速である.
Source LZE++ LZEnd gzip-9 bzip-9 lzip Snappy LZ4 Re-Pair Escherichia Coli 855.22 84539.0 239.32 111.47 1387.66 5.21 3.56 855.41 influenza 248.52 15620.49 88.39 188.57 891.63 4.27 2.84 498.45 einstein.de.txt 2792.74 18365.53 600.26 177.03 420.00 6.56 2.49 466.31 world leaders 160.74 43079.97 31.26 77.69 890.91 3.35 2.68 0.45 enwik8 172.07 14611.31 66.90 108.84 886.63 58.35 56.98 41.05 gov2 152.26 27090.72 50.55 119.84 857.19 5.39 4.22 1444.45 Hadoop 205.26 14585.62 13.64 318.37 1624.11 454.80 1.71 1.01 Cassandra 171.47 15954.85 15.04 179.92 1859.69 1.94 12.40 481.16 PostgreSQL 151.62 12788.98 17.05 260.69 1552.79 1.71 1.08 470.92 元をせずに条件判定や集約などを直接処理可能な形式で保存す ることで効率化する様々な手法が提案されている[1].これら
の手法は連長圧縮(Run Length Encoding)やビットマップ圧縮 (Bitmap Encoding)などの古典的な手法を応用することが多く, 本研究が対象とする任意のデータ列に対して単純に適用するこ とが難しい.また簡潔データ構造[5] [6] [7] [8]を検索エンジン に応用する先行研究[2]も存在するが,結果として本研究が扱っ ているような課題によって現段階では性能の優位性を示すこと が難しいことが指摘されている.本提案手法と,LZEndに対す る圧縮索引構造[4]を応用することで,より高度で高速な処理 を明示的な復元をせずに実現できる.また離散アルゴリズム分 野でランダムアクセス可能な文法圧縮手法[17]が提案されてい るが,入力データ列Nに対して計算量がO(logN)であるため, 本提案手法より計算量が高く実用上の課題が存在する.
6.
終 わ り に
処理対象のデータが増大する場合に,圧縮を用いてサイズ削 減と性能改善を行うことは非常に重要である.本論文では,圧 縮データの長さmの部分データ列を高速に復元可能なLZE++ を提案した.LZE++では共有辞書を用いた再帰処理の枝刈りと, 復元済みのデータを参照してO(m)回の再帰処理をwhile-loop で置換する最適化を行った.圧縮されたデータに対するランダ ムアクセスは非常に一般的で汎用性があるため,様々な分野に おいて活用が期待される重要な要素技術である. 文 献[1] D. Abadi et al., ”The Design and Implementation of Modern Column-Oriented Database Systems”, Foundations and Trends c⃝in Databases, Vol. 5, No. 3, pp.197–280, 2013.
[2] P. Ferragina and G. Manzini, ”On Compressing the Textual Web”, Proceedings of WSDM, 2010.
[3] S. Kreft and G. Navarro, ”LZ77-like Compression with Fast Random Access”, Proceedings of DCC, 2010.
[4] S. Kreft and G. Navarro, ”Self-indexing based on LZ77”, Proceed-ings of CPM, 2011.
[5] K.Sadakane,”New Text Indexing Functionalities of the Compressed Suffix Arrays”, J. Algorithms, Vol. 48, No. 2, 2003.
[6] R. Grossi, A. Gupta, and J. S. Vitter, ”High-Order Entropy-Compressed Text Indexes”, Proceedings of SODA, 2003.
[7] R.Grossi and J.S.Vitter, ”Compressed Suffix Arrays and Suffix Trees with Applications to Text Indexing and String Matching”, SIAM J. Comput., Vol. 35, No. 2, pp.378–407, 2005.
[8] P. Ferragina and G. Manzini, ”Opportunistic Data Structures with Applications”, Proceedings of 41st FOCS, 2000.
[9] U. Manber and G. Myers, ”Suffix Arrays: a New Method for On-line String Searches”, Proceedings of SODA, 1990.
[10] C. Kim et al., ”Closing the Ninja Performance Gap through Traditional Programming and Compiler Technology”, techre-search.intel.com, 2011.
[11] C. Hoobin et al., ”Relative Lempel-Ziv Factorization for Efficient Storage and Retrieval of Web Collections”, Proceedings of VLDB Endow., Vol. 5, No. 3, 2011.
[12] J. Pei, et al., ”PrefixSpan: Mining Sequential Patterns Efficiently by Prefix-Projected Pattern Growth”, Proceedings of 17th ICDE, 2001. [13] Kosaraju, S.R. and Manzini, G., ”Compression of Low Entropy
Strings with Lempel-Ziv Algorithms”, Proceedings of CCS, 1997. [14] G. Manzini, ”An Analysis of the Burrows-Wheeler Transform” , J.
ACM, Vol. 48, No. 3, pp. 407-430, 2001.
[15] D. Okanohara and K. Sadakane, ”Practical Entropy-Compressed rank/select Dictionary”, Proceedings of ALENEX, pp. 60–70, 2006. [16] N. Larsson and A. Moffat, ”Offline dictionary-based compression”,
Proceedings of DCC, 1999, pp.296–305, 1999.
[17] B. Philip et al., ”Random access to grammar-compressed strings”, Proceedings of SODA, 2011