深層学習を用いた視覚運動モデルの異なる 入出力情報によるロボット動作生成の比較
Comparing the Effect of Various Vision and Motor Information on Visuomotor Control Models Using Deep Neural Networks
1W153135-4 松本 昇 指導教員 尾形 哲也 教授
MATSUMOTO Noboru Prof. OGATA Tetsuya
概要: 近年,ロボットの動作生成に深層学習を使った,画像の入力から動作を生成する視覚運動モデル(Visuomotor control models) を用いる研究が増加しており,学習モデルの性能を向上するために入出力情報や学習方法の工夫がなされてきた.従来の深層学習を使っ た視覚運動学習モデルによるロボットの動作生成研究の多くでは学習方法に重点が置かれていて,入出力情報が学習に与える違いに焦点 をあてた研究は少ない.そこで本研究では,視覚運動モデルによるロボット動作生成の学習を行う際の,入出力情報の違いによる学習と,
実環境における動作生成の精度の違いを明らかにすることを目的とする.ここでは物体に触れるタスクの動作を用いて,入出力情報を変 えながら視覚運動モデルを複数回学習させ,それぞれの学習済みモデルを未学習位置の物体に触れる動作を記録したテストデータに対す る損失と,実環境における動作生成でタスクの精度を比較した.学習の比較の結果,画像特徴量を入出力に用いる視覚運動モデルは画像 を直接入力に用いるものよりも大きなバッチサイズを使用できた.また,実環境におけるタスクの精度の比較実験からは,画像や画像特 徴量を予測する視覚運動モデルは,それらを予測しないものよりもタスクの目的にあった動作生成が表れやすいことが推測される.さら に,画像を直接扱う学習モデルの方が画像特徴量を扱う学習モデルよりも目的のタスクの精度が良かった.
キーワード: 深層学習,視覚運動モデル,ロボット動作生成
Keywords: Deep Learning, Visuomotor Control Models, Robot Motion Generation
1 はじめに
ロボットの制御手法には,人間による特徴量の分析に基 づく作り込みがある.この手法は,既知の環境では高い精 度で動作する一方,未知の環境に適応した動作生成が難し いという問題点がある.対して深層学習器を用いたロボッ トの制御手法は,環境の特徴量を自動的に抽出できるため 人間の設計が不要であり,未知の環境に高い汎化性能を示 すことから関連研究が増加している[1].深層学習器を用い たロボットの動作生成モデルは,カメラや触覚センサ等か ら得られた環境の情報を入力に用いて動作を生成する.そ の中でも画像の入力から動作を生成する視覚運動モデルを 用いた手法が多く研究されている[2].
視覚運動モデルでロボットにタスクを実行させる場合,画 像のみの入力ではなく,触覚センサ,動作情報を入力に用い ることでタスクの精度を上げることができることが報告さ れている[3, 4].しかし,研究やタスクによって入出力情報 の扱い方が異なり,学習方法の違いに着目した研究はある ものの,入出力の組み合わせを網羅的に変え,学習に与える 変化に着目した比較をした研究はない.そこで本研究では,
画像と動作情報の組み合わせによる入出力情報を変化させ,
複数の視覚運動モデルを学習させる.その時に(1)学習に 必要な回数とメモリのコストの違いと,(2)実環境における 動作生成の精度の違いを明らかにすることを目的とする.
2 比較する視覚運動モデル
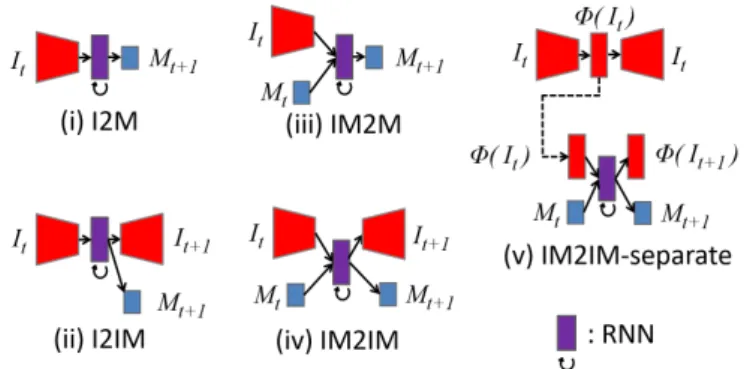
本研究で用いる比較する視覚運動モデルの概略を図1に 示す.Recurrent Neural Networks(RNN)は,現在の入力 情報と共に過去の入力情報を用いることができる構造を持 つため,時系列データを扱うことが可能である.本研究で は視覚運動モデルのすべてに,RNN の一種である Long Short-Term Memory network(LSTM)を用いる.
図1 比較する視覚運動モデルの概略図
視覚運動モデルの名前のIはImage,MはMotionに対 応している.例えば(ii) I2IMは画像のみを入力して,次の ステップの画像と動作情報を出力するモデルであり,(iii) IM2Mは入力に画像と動作情報を持ち,次のステップの動 作情報のみを出力とするモデルである.また,(v) IM2IM- separateは,画像をRNNに直接入力する(i)–(iv) とは異 なり,事前にAutoencoder (AE)の学習によって画像特徴 量を抽出する.RNNはAEで抽出した画像特徴量と運動情
報を入力として受け取り,将来の画像特徴量と運動情報を出 力する.本研究では,図1に示す(i)–(v)の視覚運動学習モ デルを実装したロボットが同一のタスクを実施した場合の,
学習コストやタスクの精度を比較することで,入出力の差 異が視覚運動モデルの学習に与える影響を明らかにする.
3 視覚運動モデルの比較実験
3.1 タスクデザイン本研究では物体に触れるタスクを学習に用いる.ロボッ トは机の左右に一つずつ置かれた二種類の物体のうちの一 つの正面まで片腕を動かし,物体に触れる.
図2 実験に用いたタスクの例:ロボットが左のアームを 箱の前に移動させ、箱に触れている
3.2 学習データ
学習する時系列データとして産業用ロボットNextageの 両腕関節角12次元,128×128のRGB画像を記録する.
(v) IM2IM-separateのAEによって抽出する画像特徴量は 20次元とした.学習データは物体の位置,物体に触れる速 度,動作する腕の違いから,972パターンのデータセットと なる.学習モデル内で,動作する腕の違いはRNNの持つ内 部状態の初期値に指定される.
3.3 実験結果
それぞれの視覚運動モデルで,5GBのGPUメモリ上で 取りうる最大のバッチサイズを指定して,100,000回の学 習をパラメータを変えながら12回実施した.学習後,学習 データに含まれない物体の位置での動作を記録した時系列 をテストデータとして,テストデータの推論において損失 が最小となる学習回数を計測した.学習回数で明確な差は 認められなかったものの,(v) IM2IM-separateは他のモデ ルと比較して大きなバッチサイズを指定可能であることが わかった.実環境における動作生成では,それぞれの視覚 運動モデルにおいて,12種類の学習済みモデルの中から物 体に触れることができないものを比較に用いる学習済みモ デルから除外した.その結果残った学習済みモデルの数が 表1の通りになった.その後物体に触れた時のロボットの 手先位置の座標と,物体に触れる時の理想的なロボットの
表1 比較に用いる視覚運動モデルそれぞれの学習済みモ デルの数
I2M I2IM IM2M IM2IM IM2IM-separate 学習モデル数 10 9 9 7 3
手先位置の座標を比較して,ロボットの正面に対して交差 する方向の誤差を測定した.それぞれの学習モデルの平均 誤差を集計したものが図3であり,中央値で比較をすれば,
図3 物体に触れた時の平均誤差
画像や画像特徴量を予測する(ii) I2IM,(iv) IM2IM,(v) IM2IM-separateは,画像情報を予測しない(i) I2M,(iii) IM2Mに比べ平均誤差が小さくなり,画像情報の予測も学 習させることでタスクの目的に合った動作生成が表れやす いことが推測される.そして,画像を直接扱う(ii) I2IM, (iv) IM2IMは画像特徴量を扱う(v) IM2IM-separateより も平均誤差が小さくなり,直接画像を扱うことで目的のタ スクを学習しやすいことが推測される.
4 まとめ
本研究では,視覚運動モデルを用いたロボットの動作学 習において,入出力情報の差が学習のコストと実環境にお ける動作生成の精度に与える影響を調査した.今後の研究 計画として,それぞれの学習済みモデルのLSTMの内部状 態や,画像特徴量の抽出の解析を行うことで,視覚運動モデ ルの内部の表現における比較を行うことを検討している.
参考文献
[1] Lei Tai, Jingwei Zhang, Ming Liu, Joschka Boedecker, and Wolfram Burgard. A Survey of Deep Network Solutions for Learning Control in Robotics: From Reinforcement to Imitation. Vol. 14, No. 8, pp.
1–19, 2016.
[2] Javier Ruiz-del Solar, Patricio Loncomilla, and Naiomi Soto. A Survey on Deep Learning Methods for Robot Vision. pp. 1–43, 2018.
[3] Roberto Calandra, Andrew Owens, Dinesh Jayaraman, Justin Lin, Wenzhen Yuan, Jitendra Malik, Edward H. Adelson, and Sergey Levine. More Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch. No. 1, pp. 1–8, 2018.
[4] Sergey Levine and Chelsea Finn. End-to-End Training of Deep Vi- suomotor Policies. Vol. 17, pp. 1–40, 2016.