九州大学学術情報リポジトリ
Kyushu University Institutional Repository
アノテーションに基づく画像検索の改善に関する研 究
陳, 華
https://doi.org/10.15017/1931930
出版情報:Kyushu University, 2017, 博士(工学), 課程博士 バージョン:
権利関係:
A Study on Improving
Annotation Based Image Retrieval
Hua Chen
Graduate School of Information Science and Electrical Engineering Kyushu University
A thesis submitted for the degree of Doctor of Philosophy
January 2018
This thesis is dedicated to my father and mother who have always encouraged me to
enroll for my doctoral degree
Abstract
With the growing use of computers, mobile devices and other digital prod- ucts, a great amount of digital images is being generated very rapidly.
Consequently, how to quickly and accurately find relevant images has be- come a very hot research topic.
There are many image retrieval solutions have been introduced to browse and retrieve images from large image databases. These solutions are typ- ically classified into two types: content based image retrieval (CBIR) so- lutions and annotation based image retrieval (ABIR) solutions. Basically, the CBIR solutions use visual features (such as color, texture, shape and object location) to retrieve images. Because the visual features are of- ten low-level and cannot accurately represent the complicated images, the CBIR solutions suffer from “the semantic gap problem”. On the other hand, the ABIR solutions are an attempt to incorporate more efficient semantic content into both text-based queries and image textual descrip- tions, which are developed for the purpose of bridging the semantic gap that exists between low-level image features represented by digital devices and the profusion of high-level human perception used to perceive images.
As can be seen in many of today’s image retrieval systems, the ABIR solutions are considered more practical. However, the results of previ- ous image retrieval systems are often inaccurate for semantically complex
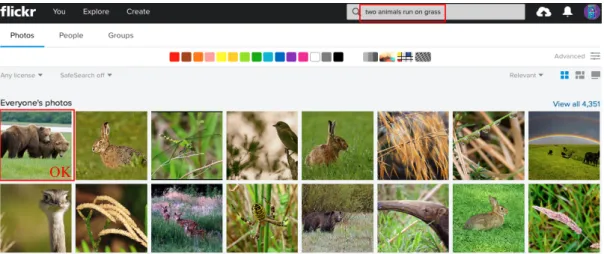
queries. For example, when searching images with a query “two animals run on grass”, retrieval systems cannot understand the exact meaning of this query and cannot return accurate results. Therefore, it is necessary to find better solutions to solve this problem and then improve the results of image retrieval.
By analyzing the previous image retrieval systems, we find that natural language processing (NLP) technologies are not well leveraged for image retrieval. For example, the object counts are often represented as general attributes of objects, but not the actual numbers of objects. Therefore, previous solutions cannot support image retrieval by counting objects.
However, recent approaches in NLP field can easily deal with counting problems by using concepts and instances to represent information. This motivates us to combine image retrieval processing with new NLP solu- tions for improving the retrieval results.
In this thesis, we aim at improving ABIR for complex queries by using NLP technologies, Semantic Web technologies and other related technolo- gies.
First of all, we propose an image annotation model based on the notions of concept and instance. With this model, the properties of objects, the relations of objects and the numbers of objects can be expressed in RDF (Resource Description Framework) to describe the detail information of
images. It can support image retrieval by counting objects with SPARQL queries.
Second, we design our proposed ABIR system based on our image anno- tation model for complex queries by using a semantic parser (Knowledge Parser or K-Parser). From text written in natural language, the K-Parser extracts a graphical semantic representation of the objects involved, their properties as well as their relations. We analyze both the image textual descriptions and the natural language queries with the K-Parser. As a technical solution, we leverage RDF in two ways: (1) we store the parsed image captions as RDF annotations; (2) we translate image queries into SPARQL queries to query RDF annotations for image retrieval. When applied to the Flickr8k dataset with a set of custom queries, we notice that the K-Parser exhibits some biases that negatively affect the accuracy of the queries.
Finally, we propose two optimization techniques to address the weak- nesses: (1) we introduce a set of rules to transform the output of K- Parser and fix some basic, frequent mistakes that occur on the captions of Flickr8k dataset; and (2) we leverage commonsense knowledge databases (e.g., ConceptNet) to raise the accuracy of queries on broad concepts.
We conduct two experiments with our proposed ABIR system: (1) search- ing images with a set of custom complex queries; and (2) searching images by counting objects. The experimental results show that our approach can
achieve highly satisfactory accuracy with complex queries. Especially, it excels in advanced domains such as counting objects in images (e.g., “two animals run on grass”), finding images with fuzzy description queries (e.g.,
“animal wearing something runs”).
Contents
1 Introduction 1
1.1 Background . . . 1
1.2 Objectives . . . 5
1.3 Contributions . . . 7
1.4 Structure of the Thesis . . . 8
2 Image Annotation, Query and Natural Language Processing 10 2.1 Feature of Annotation and Image Annotation . . . 10
2.2 Textual Query . . . 12
2.3 Natural Language Processing . . . 14
2.4 Summary . . . 14
3 Related Technologies and Preliminaries 16 3.1 Related Technologies . . . 16
3.1.1 Semantic Web . . . 16
3.1.1.1 History of the World Wide Web . . . 16
3.1.1.2 Semantic Web and Its Architecture . . . 18
3.1.1.3 Summary . . . 21
3.1.2 RDF . . . 21
3.1.3 SPARQL . . . 23
3.1.4 Triple Store . . . 24
3.1.5 Commonsense Knowledge Base . . . 24
3.1.6 Knowledge Parser (K-Parser) . . . 27
3.2 Preliminaries . . . 29
3.2.1 The Flickr8K Dataset . . . 29
3.2.2 Jena TDB . . . 30
3.2.3 Improving the RDF Expressions of ConceptNet . . . 31
3.2.3.1 The Structure of ConceptNet . . . 32
3.2.3.2 Conversion Process . . . 34
3.2.3.3 Use Case . . . 37
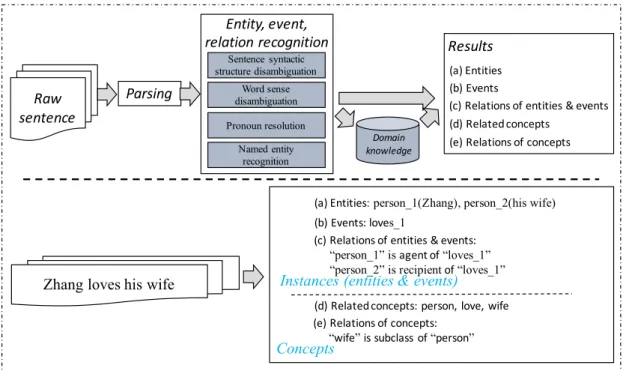
4 Proposed Annotation Model for Counting Objects 38 4.1 Related Work . . . 38
4.1.1 Image Annotation Model . . . 38
4.1.2 Information Extraction with NLP Techniques . . . 40
4.2 An Annotation Model for Counting Objects . . . 46
4.2.1 Concepts and Instances . . . 46
4.2.2 Proposed Image Annotation Model . . . 49
4.3 Use Case . . . 53
4.4 Summary . . . 55
5 Implementation of the Proposed Approach 56 5.1 Related Work . . . 56
5.2 Preliminary Implementation . . . 59
5.2.1 Annotation Generation . . . 59
5.2.2 Preliminary System Design . . . 63
5.2.2.1 Data Pre-processing Module . . . 63
5.2.2.2 Image Query Module . . . 64
5.2.3 Preliminary Experiments and Results . . . 67
5.3 Re-implementation . . . 68
5.3.1 Optimization Techniques . . . 69
5.3.1.1 Classification of Concepts . . . 69
5.3.1.2 Rule-based Method . . . 70
5.3.2 A New ABIR System for Complex Queries . . . 72
5.4 Summary . . . 73
6 Experiments 74 6.1 Experiment 1 . . . 74
6.1.1 Experimental Methodology . . . 74
6.1.1.1 Natural Language Queries . . . 74
6.1.1.2 Experiment Design . . . 76
6.1.1.3 Test Environment . . . 76
6.1.2 Experimental Results . . . 76
6.1.3 Conclusions . . . 80
6.2 Experiment 2 . . . 80
6.2.1 Experimental Methodology . . . 80
6.2.1.1 Natural Language Queries . . . 80
6.2.1.2 Experiment Design . . . 81
6.2.2 Experimental Results . . . 81
6.2.3 Conclusions . . . 83
6.3 Summary . . . 83
7 Conclusions and Future Work 84 7.1 Summary of the Thesis . . . 84
7.2 Future Work Direction . . . 86
7.2.1 Optimization Techniques for Our Proposed System . . . 86 7.2.2 Multilingual Image Retrieval . . . 86 7.2.3 Image Description Generation . . . 87
Bibliography 89
A Published Papers 105
List of Figures
1.1 Typical framework of two image retrieval solutions. . . 4
1.2 Retrieval results with Flickr for “two animals run on grass”. . . 6
2.1 Four common kinds of annotations to describe images. . . 11
3.1 Semantic Web layered architecture. . . 19
3.2 An RDF triple graph (subject, predicate, object). . . 21
3.3 RDF triples expressed in Turtle. . . 22
3.4 An example of SPARQL query. . . 23
3.5 Concepts and their relations from ConceptNet. . . 27
3.6 An example of the parsed results with K-Parser. . . 28
3.7 An image with five descriptions in Flickr8K. . . 29
3.8 An example to query RDF triples with Jena TDB. . . 30
3.9 A partial view of the ConcetptRDF. . . 32
3.10 Same information in ConceptNet expressed with two formats. . . 33
3.11 RDF expressions of concepts and their relation. . . 37
4.1 A general ontology-based image annotation model. . . 40
4.2 Information extraction in natural language processing. . . 41
4.3 A solution to address algebra word problem. . . 43
4.4 Image annotation generation with NLP solution. . . 44
4.5 Parsing result for “a boy eats dinner with a girl”. . . 45
4.6 Parsing result for “a dog holds a stick while it runs through snow”. . 46 4.7 The relationships between concepts illustrated with RDF triples. . . . 47 4.8 Concepts and instances expressed in RDF. . . 49 4.9 Main steps of image annotation generation. . . 50 4.10 Image annotations based on RDF descriptions. . . 52 4.11 SPARQL queries used to find images with counting expressions. . . . 54 4.12 Some images with sentence descriptions. . . 54 5.1 Generate RDF annotations from natural language sentences. . . 61 5.2 Improved RDF annotations for “two lizards fight in the water”. . . . 62 5.3 Overview of the preliminary implementation. . . 64 5.4 RDF annotations represent “a brown and white dog is running”. . . . 65 5.5 A SPARQL query generated by SPARQL query generator. . . 66 5.6 Retrieval results with a query “a white animal runs through water”. . 68 5.7 Some semantic graphs generated by K-Parser. . . 69 5.8 A SPARQL query improved with rule 4 for “a dog wears something”. 71 5.9 Overview of the new ABIR system. . . 73 6.1 Image retrieval results with the proposed ABIR system . . . 79
Chapter 1 Introduction
Intelligent and effective image retrieval with semantically complex queries has at- tracted the attention of researchers from many different communities. Nowadays, many solutions have been proposed to support complex queries. For example, using the properties of objects and the relations between objects, users can get specific im- ages from large image collections. However, users still cannot get satisfactory results with previous solutions when retrieve images with some more complex queries (e.g., searching images by counting objects with “two animals run on grass”). This the- sis describes a solution to improve annotation based image retrieval for semantically complex queries (especially for queries that intend to find images by counting objects) by using NLP technologies, Semantic Web technologies and other related technologies.
1.1 Background
With the proliferation of digital cameras, mobile phones, and SNS services, the num- ber of images being generated is rapidly increasing [64]. These images are often very important and play a crucial role in our daily life within a wide range of applications and fields (such as medical care, education, criminal investigation, weather forecast-
ing, journalism, art designs, advertising, social media, and entertainment) [7]; hence, there is an urgent need for finding intelligent and effective methods to manage, store, analyze and retrieve them.
In the field of digital image processing, image content can be seen as a collection of channels of information. Some of these information channels are low-level and can be derived from the content itself (e.g. color, shape, and texture). However, other channels encode higher-level semantics that cannot be derived from the image content without external knowledge [27, 100]. The current state of the art in automatic image analysis and understanding supports in many cases the successful detection of semantic concepts, such as animals, persons, buildings, actions, natural scenes vs.
manmade scenes [42]. However, in some cases people want to search for very specific images with semantically complex queries: this is still a major challenge to image retrieval systems. As a consequence, intelligent and effective image retrieval with semantically complex queries has attracted the attention of researchers from many different communities, such as computer vision (CV), natural language processing (NLP) and robotics.
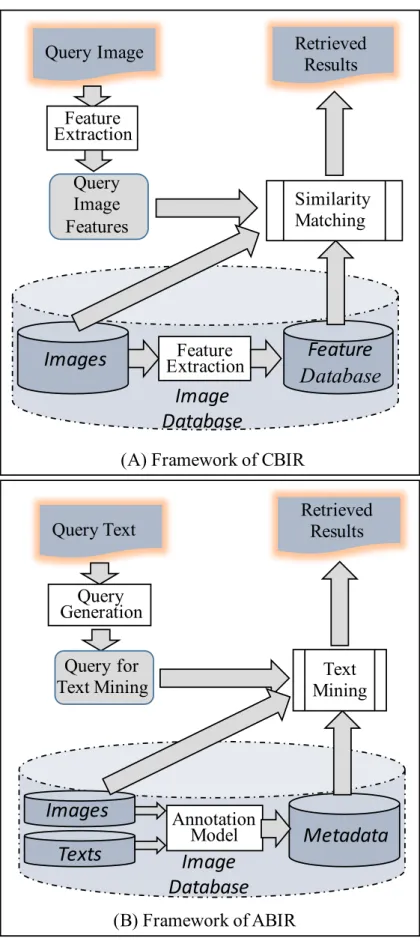
In recent years, there are many image retrieval solutions have been introduced to browse and retrieve images from large image databases. These solutions are typically classified into two types: content based image retrieval (CBIR) solutions and annota- tion based image retrieval (ABIR) solutions. Basically, the CBIR solutions use visual features (such as color, texture, shape and object location) to retrieve images. This technology has been widely used in many applications such as fingerprint identifica- tion, digital libraries, medicine and historical research, among others [44, 35]. All these applications are similar: with a query image submitted by a user, they extract features from the query image and compare them to the database of image features for finding similar images (the typical framework of an CBIR system is shown in Figure
1.1A). However, because the visual features are often low-level and cannot accurately represent the complicated images, the CBIR solutions suffer from “the semantic gap problem” [123]. For example, an image with content “sunset”, the CBIR systems can extract the features such as “red”, “round” from the image, but may cannot extract the meaning of “sunset” from the image1.
On the other hand, the ABIR solutions are an attempt to incorporate more effi- cient semantic content into both text-based queries and image textual descriptions, which are developed for the purpose of bridging the semantic gap that exists between low-level image features represented by digital devices and the profusion of high-level human perception used to perceive images [7]. Generally, the ABIR systems allow users to add textual descriptions (image annotations) as image metadata and support image retrieval by using text mining techniques. As can be seen in many of today’s image retrieval systems, the ABIR solutions are considered more practical [31]. There are often two main challenges that must be solved when designing an ABIR system for finding images accurately and intelligently: (1) design an appropriate image an- notation model and use it to express the content of images with image annotations;
(2) understand image queries (sometimes, these queries need to be translated into an appropriate format) and access large image databases to find the results. The typical framework of an ABIR system is shown in Figure 1.1B.
It is well known that Flickr2 is a popular image-sharing website which gathers bil- lions of photos shared by people from all over the world. There are enough different images on Flickr to fulfill the needs of virtually any user (Flickr has more than five billion images with millions of newly uploaded photos per day). These images are often accompanied by some natural language descriptions (such as titles, descriptions or tags), which can be used to support many different kinds of queries for finding
1With some other new solutions, CBIR may can recognize “sunset”.
2http://www.flickr.com
Metadata Image
Database
Text Mining Query Text
Annotation Model
Retrieved Results
Images
Feature Database Image
Database
Similarity Matching Query Image
Feature Extraction Feature
Extraction Query Image Features
Retrieved Results
Images
Texts
Query Generation
Query for Text Mining
(A) Framework of CBIR
(B) Framework of ABIR
Figure 1.1: Typical framework of two image retrieval solutions.
images with ABIR solutions. Users can retrieve images on Flickr easily and conve- niently based on these natural language descriptions. However, when users query images by describing their contents with some semantically complex queries such as
“people on horse”, “people with horse”, “two animals run on grass” and “animal wearing something runs”, the results are often inaccurate (Figure 1.2 illustrates an example). The reason is that Flickr cannot understand those complex queries: it has no ability to understand the differences between “on” and “with”; it cannot retrieve images by counting objects with “two animals”; furthermore, it does not know the exact meaning of “animal wearing something”.
Recently, several solutions [68, 102, 1, 2, 121] have been proposed to support complex queries. For example, Schuster et al. [102] parsed image descriptions to extract the properties of objects and relations between objects to construct scene graphs [68] for image retrieval with semantically complex queries. With their method, queries such as “people on horse” and “people with horse” can be differentiated to improve the retrieval results. However, users still cannot get satisfactory results with these solutions when searching with some more complex queries–especially, for queries with counting objects (e.g., “two animals run on grass”)–there is less evidence that any of previous solutions can retrieve images by counting objects [8, 41, 110]. Therefore, it is necessary to find better solutions to solve this problem and then improve image retrieval for complex queries.
1.2 Objectives
In this thesis, the research aims at improving ABIR for semantically complex queries3 by using NLP technologies, Semantic Web technologies and other related technolo- gies. It focuses on combining image retrieval processing with NLP solutions and
3Especially for complex queries that intent to find images by counting objects.
OK
Figure 1.2: Retrieval results with Flickr for “two animals run on grass”.
knowledge-based methods. The basic ideas are (1) proposes an image annotation model to express images with detail descriptions (including the properties of objects, the relations of objects, and the numbers4 of objects); (2) leverages commonsense knowledge bases to raise the accuracy of image queries on broad concepts; (3) stores image annotations as RDF (Resource Description Framework) [83] triples and queries them with SPARQL (SPARQL Protocol and RDF Query Language) [37] for image retrieval; (4) understands natural language with a semantic parser (Knowledge Parser or K-Parser) [103] to improve image retrieval results. In particular, the research has been done on the following aspects.
(1) Proposing an image annotation model based on RDF to express images with detail descriptions. In this model, the properties of objects, the relations of objects, and the numbers of objects are all expressed with RDF annotations.
(2) Designing of an ABIR system based on the proposed image annotation model for semantically complex queries. The system supports image retrieval for complex
4For the purpose of counting objects in images.
natural language queries by using the K-Parser.
(3) Improving the image retrieval results in two aspects: improving the parsing results of the K-Parser, and leveraging commonsense knowledge bases to raise the accuracy of image queries on broad concepts.
1.3 Contributions
The main contributions of this thesis were the design, implementation, and optimiza- tion of ABIR system to improve image retrieval for semantically complex queries, especially for complex queries that intend to find images by counting objects. In this view, this thesis made three major contributions.
First, an image annotation model was proposed to improve the expressions of images. Different from other image annotation models that just expressed the prop- erties of objects and the relations of objects in images, the proposed image annotation model also expressed the numbers of objects in images for the purpose of counting objects. The annotations were all stored as RDF triples and could be easily queried by SPARQL queries.
Second, the design of an ABIR system for semantically complex queries was pre- sented. It aimed at improving text-based image retrieval for complex natural language queries by using the K-Parser. From text written in natural language, the K-Parser extracted a graphical semantic representation of the objects involved, their properties as well as relations among them. Both the image textual descriptions and the complex natural language queries were analyzed with the K-Parser: (1) the image descriptions were parsed and stored as RDF annotations; (2) the complex queries were parsed
to generate SPARQL queries to query RDF annotations for image retrieval. The experimental results showed that this ABIR system could support complex natural language queries for image retrieval efficiently. However, the K-Parser exhibited some biases that negatively affected the accuracy of the image queries.
Third, two techniques were proposed to improve the image retrieval results. (1) A set of rules were introduced to transform the output of the K-Parser and fixed some basic, frequent mistakes that occurred on the image textual descriptions; (2) large commonsense knowledge bases were leveraged to raise the accuracy of image queries on broad concepts. The experimental results showed that those two techniques fixed most of the initial errors of the K-Parser; furthermore, it could also increase the flexibility of ABIR system (e.g., counting objects in images, finding images with fuzzy description queries).
1.4 Structure of the Thesis
This section provides a chapter-wise organization of the rest of this thesis.
Chapter 2 briefly introduces the feature of image annotations, textual queries and natural language processing.
Chapter 3 covers the preliminaries and describes the related technologies used in this thesis.
Chapter 4proposes an image annotation model based on RDF to express images with detail descriptions for image retrieval.
Chapter 5describes the implementation of our proposed approach based on the image annotation model introduced in Chapter 4.
Chapter 6 performs some experiments with the proposed ABIR system and presents the experimental results.
Chapter 7 concludes with a summary of contributions made in this thesis and describes future direction.
Chapter 2
Image Annotation, Query and Natural Language Processing
This chapter introduces the feature of image annotations, textual queries and natural language processing.
2.1 Feature of Annotation and Image Annotation
This section introduces four common kinds of image annotations [77, 53, 15, 93] and analyzes their features.
Image annotation has been a topic of ongoing research for more than two decades and several solutions have been proposed [82, 54, 29, 74, 120, 64, 6, 81, 112]. Four common kinds of annotations used to describe images are as follows (as shown in Figure 2.1).
(1) Objects: there are often many “things” in images, these “things” called
“objects”. Object names (also called object labels, concepts or classes) can be used to describe images [54]. For example, the image1shown in Figure 2.1 can be annotated
1Images illustrated in this thesis are sampled from Flickr8K [59].
(1) Objects:"dog, beach, collar, water, wave, sea.
(2),Properties,+,Objects:brown dog, crashing waves, large white dogs, red collar.
(3),Properties,+,Objects,+,Relations:dogs run on beach, dog in a red collar, brown dog running along the beach.
(4),Semantically,complex,descriptions:,three dogs run on beach, two white dogs and one light brown dog running along the beach.
Figure 2.1: Four common kinds of annotations to describe images.
with objects such as “dog”, “beach”, “collar”, “water”, “wave” and “sea”.
(2) Properties + Objects: for better express the objects in images, the proper- ties (also called attributes) of objects are also used to describe images. In Figure 2.1, the colors of dogs are “brown” and “white”, the features of dogs and waves are “large”
and “crashing”, respectively. So, the image can also be annotated with “brown dog”,
“crashing waves” and “large white dogs”.
(3) Properties + Objects + Relations: in order to specify the relative config- uration between pairs of objects, the relations between objects are added to describe images [102, 106]. In Figure 2.1, considering the relations between dogs and beach, the image can be annotated with “dogs run on beach” or “brown dog running along the beach”.
(4) Semantically complex descriptions: semantically complex descriptions are considered as complex natural language descriptions [93]. In Figure 2.1, “three dogs run on beach” and “two white dogs and one light brown dog running along the beach” are annotations to describe image with semantically complex descriptions.
FeatureImage annotations have the feature that they are often expressed with single words, short phrases or simple sentences; their grammatical constructions are not very complicated, which makes it possible to improve image retrieval with some NLP techniques.
2.2 Textual Query
Textual queries for image retrieval can be divided into two categories: simple queries and complex queries.
A simple query consists of a single word representing an object name (e.g., “dog”),
a short phrase representing an object with particular properties (e.g., “large white dog”), or a simple description representing relations between objects (e.g., “dog in a red collar”). Many solutions [14, 47, 71, 105, 54] have been proposed to improve image retrieval with simple queries. For example, object names (e.g., “dolphin”, “frog”) are used for image retrieval in [14, 47]; objects with particular properties (e.g., “dark- haired people”) or relations (e.g., “young Asian woman wearing sunglasses”) are used for image retrieval in [71, 54, 105].
A complex query is defined as a natural language query and consists of objects, properties and their complex relations (e.g., “two animals run on grass”, “animal wearing something runs”). Complex queries are becoming more and more popular in recent years [93]. Recent approaches such as [46, 106, 102, 93] have been done on improving image retrieval with complex queries.
Analysis The grammatical constructions of textual queries for image retrieval are also not very complicated. However, there are some problems may negatively affect the accuracy of image retrieval: (1) subconcept matching: “dog” is a subcon- cept of “animal”, an image with annotation “dog” can be found with query “dog”, but may not be found with query “animal”; (2) synonyms: query “TV” and query
“television” have the same meaning, but retrieval systems may not understand; (3) homonyms: it is unknown whether query “apple” represents a kind of fruit or a company name; (4) counting objects: it is unable to retrieve images by counting objects (e.g., with query “three animals”). The first three problems have been ad- dressed with some recent approaches (e.g., an ontology-based method was proposed in [114] to address the subconcept matching problem; WordNet [87] was used in [6]
to address the synonyms problem; DBPedia [10] was used in [64] to facilitate seman- tic link between image annotations for addressing the homonyms problem); but the
fourth problem has not been solved with previous solutions [8, 41, 110].
2.3 Natural Language Processing
NLP is a way for computers to analyze, understand, and derive meaning from human language in a smart and useful way.
Early approaches in NLP field mainly view text analysis as a word matching task and try to ascertain the meaning of a piece of text by processing it at word-level; later approaches try to exploit semantics more consistently (text analysis at concept-level) and get denotative and connotative information commonly associated with real world objects, actions, events, and people [26]. Now, with the improvements in artificial intelligence, NLP techniques can solve many problems intelligently and efficiently.
For example, a new approach proposed in [72] can automatically solve an algebra word problem as follows.
“An amusement park sells 2 kinds of tickets. Tickets for children cost$1.50. Adult tickets cost$4. On a certain day, 278 people entered the park. On that same day the admission fees collected totaled $792. How many children were admitted on that day?
How many adults were admitted?” [72].
Analysis NLP provides a smart way for computers to understand human language.
It can not only ascertain the meaning of a piece of text, but also exploit the semantics more consistently; furthermore, it has the ability to calculate when needed.
2.4 Summary
This chapter briefly introduces the feature of image annotations, textual queries and NLP technologies.
In image retrieval, previous solutions cannot support a textual query that intends to retrieve images by counting objects. However, in NLP field, recent approaches can easily deal with these calculation problems. This motivates us to combine image retrieval processing with new NLP solutions for improving the retrieval results.
Chapter 3
Related Technologies and Preliminaries
This chapter describes the related technologies and covers the preliminaries of our research.
3.1 Related Technologies
Because our image retrieval system is based on RDF, which is a basic model to describe Semantic Web resources; we first introduce Semantic Web and its basic com- ponents (such as RDF and SPARQL), and then describe other related technologies.
3.1.1 Semantic Web
3.1.1.1 History of the World Wide Web
The World Wide Web is an information space where many different documents and other web resources are identified by Uniform Resource Locators (URLs), interlinked by hypertext links, and can be accessed via the Internet [65]. The World Wide Web is the largest transformable-information construct, which was introduced by Tim
Burners-Lee in 1989 [69]. The goal of the World Wide Web is to create an appropri- ate expression of information to facilitate the communication between humans and computers.
In the past three decades, much progress has been made about the World Wide Web and other related technologies. Web 1.0 as a web of cognition, web 2.0 as a web of communication and web 3.0 as a web of data are introduced since the advent of the web [3].
Web 1.0 is the first generation of the web which according to the innovator of World Wide Web, Tim Berners-Lee; could be considered as a “read-only” web and also as a system of cognition [3]. Web 1.0 was mainly used as “information portal”
and focused on company homepages to broadcast information to users. However, Web 1.0 has some limitations: (1) it supports very little interaction between different users and information creators; (2) it only allows users to use keyword-based search;
(3) computers cannot understand anything about the information content.
Web 2.0 was proposed by Dale Dougherty in 2004 as a “read-write” web [16]. It is the second generation of the web and also called Social Web [34]. Web 2.0 provides a platform for users to contribute information and interact with other users. In the era of Web 2.0, people often consume as well as contribute information through different APIs, blogs or Web sites (e.g., Facebook, Flickr and YouTube). Web 2.0 also has some limitations: (1) it still only supports keyword-based search; (2) information content in each Website is separate but not shared; (3) computers still understand nothing about the information content.
Web 3.0 is one of current and evolutionary topics associated with the following initiatives of Web 2.0. It was first introduced by John Markoff of the New York Times and was suggested as the third generation of the web in 2006 [108]. Web 3.0 is a “read-write-execute” web; the basic idea is to define structure data and link them
for effective discovery, integration, automation, and reuse across various applications [57]. Web 3.0 desires to decrease human’s tasks and decisions and leave them to machines by providing machine-readable contents on the web [56]. It can improve the management of web data, enhance users’ satisfaction, support high-level accessibility of mobile internet and help to optimize the collaboration in Social Web.
3.1.1.2 Semantic Web and Its Architecture
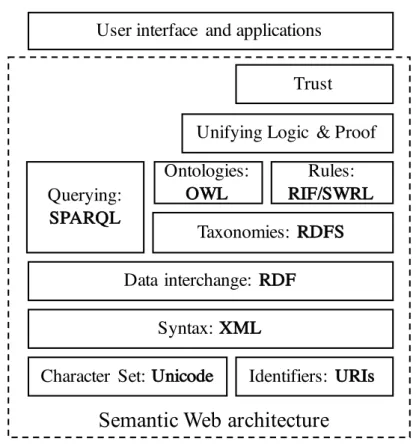
Web 3.0 is also called Semantic Web, which was thought up by the innovator of World Wide Web, Tim Berners-Lee. There is a dedicated team at the World Wide Web consortium (W3C) working to improve, extend and standardize the system, languages, publications and tools have already been developed [95]. According to the W3C,
“The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries” [70].
The goal of the Semantic Web is improving the current Web by enabling users and machines to share, find and combine information more easily. The Semantic Web was originally expressed by Tim Berners-Lee as follows:
“If HTML and the Web made all the online documents look like one huge book, RDF, schema, and inference languages will make all the data in the world look like one huge database” [17].
Thus, the Semantic Web is also considered as the web of data. It hosts a variety of data sets that include encyclopedic facts, drug and protein data, metadata on music, books and scholarly articles, social network representations, geospatial information, and many other types of information in some ways like a global database that most its features are included Semantics of content and links are explicit and the degree of structure between objects is high based on RDF model [34].
Character Set: Unicode Identifiers: URIs Syntax: XML
Data interchange: RDF
Rules:
RIF/SWRL Unifying Logic & Proof
Trust
Semantic Web architecture
User interface and applications
Taxonomies: RDFS Ontologies:
Querying: OWL SPARQL
Figure 3.1: Semantic Web layered architecture.
Tim Berners-Lee also proposed a layered architecture for the Semantic Web, a typical representation of this layered architecture is shown in Figure 3.1. The layers of the Semantic Web architecture are briefly introduced as follows.
• Unicode and URIs Unicode is used to represent of any character uniquely whatever this character was written by any language and Uniform Resource Identifiers (URIs) are unique identifiers for resources of all types [18, 4], they provide methods to identify different objects within the Semantic Web.
• XMLXML (Extensible Markup Language) is a markup language which defines a set of rules for encoding documents in a format that can be understood by both humans and machines.
• RDF RDF is a simple language for expressing data models, which refer to ob-
jects (“web resources”) and their relationships. RDF is a fundamental standard of the Semantic Web [5].
• RDFS RDFS (RDF Schema) [22] extends RDF to describe conceptual models in terms of classes and properties. RDFS provides a vocabulary for describing properties and classes of RDF-based resources, with semantics for generalized hierarchies of such properties and classes [23].
• OWLOWL (Web Ontology Language) provides a more expressive vocabulary for describing the semantic qualities of classes and properties [43]. It describes relations between classes (e.g. disjointness), cardinality (e.g. “exactly one”), equality, richer typing of properties, characteristics of properties (e.g. symme- try), and enumerated classes [23].
• RIF/SWRLRIF (Rule Interchange Format) is an XML language for express- ing Web rules that computers can execute; SWRL (Semantic Web Rule Lan- guage) is a proposed language to express rules for the Semantic Web [60].
• SPARQL is a protocol and query language for RDF data sources.
• Unifying Logic and ProofUnifying Logic and Proof are on top of the ontol- ogy structure and can make new inferences with automatic reasoning solution.
The agents are able to make deductions as to whether particular resources sat- isfy their requirements by using such the reasoning systems [51].
• TrustTrust provides a quality assurance of the information on the web and a degree of confidence in the resource providing this information.
Semantic Web is not limited to publish data on the web; it is also about making links to connect related data. Tim Berners-Lee introduced a set of rules have become
known as the Linked Data principles to publish and connect data on the web in 2007 [20]. According to the Linked Data principles, data providers can add their data to a single global data space for publishing and sharing data on the web.
3.1.1.3 Summary
Semantic Web technologies enhance data integration by standardizing formats to link and exchange information among diverse applications. It can facilitate the search of heterogeneous data, promote natural language processing for intelligent data query- ing, and support automated reasoning from data [23]. Therefore, we plan to improve image retrieval based on Semantic Web technologies: using RDF to express images and querying them with SPARQL queries.
3.1.2 RDF
RDF, as a cornerstone of the Semantic Web, is a family of W3C specifications de- signed as a standard data model to univocally identify Web resources and describe the relations between the Web resources in terms of named properties and values.
Using RDF, it can define and use metadata vocabularies to make statements about resources; furthermore, it can also create links between different resources. A resource can be anything that is identifiable by a URI, the statements describe the properties of resources, and the links indicate the relationships between resources. RDF uses a
predicate
subject object
Figure 3.2: An RDF triple graph (subject, predicate, object).
Figure 3.3: RDF triples expressed in Turtle.
graph data model, an RDF graph can be illustrated as a directed labeled graph (as shown in Figure 3.2) as well as a triple of the form (subject, predicate, object) (it means that<subject> has a property <predicate>, whose value is <object>).
There are several common serialization formats that have been developed, includ- ing:
• Turtle (Terse RDF Triple Language) [13], a compact, human-friendly format.
• N-Triples [12], a very simple, easy-to-parse, line-based format that is not as compact as Turtle.
• N-Quads [40, 30], a superset of N-Triples, for serializing multiple RDF graphs.
• JSON-LD [38], a JSON-based serialization.
• N3 (Notation3), a non-standard serialization that is very similar to Turtle, but has some additional features, such as the ability to define inference rules.
• RDF/XML [49], an XML-based syntax that was the first standard format for serializing RDF.
Turtle can display triples in a concise format; thus we use Turtle to express RDF
prefix foaf: <http://xmlns.com/foaf/0.1/> . select ?age ?name where
{Image URI Creator ?person.
?person foaf:name ?name.
?person foaf:age ?age}
Creator
?person Image
URI
?name
?age
Figure 3.4: An example of SPARQL query.
triples in this thesis. An example for some RDF triples1 in Turtle format is shown in Figure 3.3.
3.1.3 SPARQL
SPARQL is the standardized query language for RDF, which is also recommended by the W3C. It can be used to express queries across diverse data sources, whether the data is stored natively as RDF or viewed as RDF via middleware.
SPARQL contains capabilities for querying required and optional graph patterns along with their conjunctions and disjunctions. A SPARQL query consists of triple patterns, each of which is a triple that contains variables in the subject, predicate or object. A SPARQL query can also be illustrated as a directed graph. Thus, executing a SPARQL query often involves graph pattern matching, with the purpose of finding all matches of a query graph pattern and each match is a subgraph of the RDF graph [62]. For example in Figure 3.4, given an image URI, the query returns the age and the name of the image’s creator. SPARQL allows the definition of prefixes to make queries concise, in Figure 3.4, the prefix “foaf” stands for “http://xmlns.com/foaf/0.1/”.
1RDF data sampled from ConceptRDF [91].
3.1.4 Triple Store
RDF triples can be stored in a type of database called triple store, which provides a mechanism for the storage and retrieval of RDF graphs.
There are many kinds of triple stores have been developed: some of them are built as database engines from scratch, while others are built on top of existing commercial relational database engines (such as SQL-based) or NoSQL document- oriented database engines. Some popular triple stores are as follows.
• Sesame [11], is an open source RDF database with support for RDFS inferencing and querying. It contains implementations of an in-memory triple store and an on-disk triple store, offers a large scale of tools to developers to leverage the power of RDF and RDF Schema.
• Jena TDB [52], is a persistent graph storage layer of Jena [85] for RDF storage and query. It works with the Jena SPARQL query engine to provide complete SPARQL together with a number of extensions, and can be used as a high performance RDF store on a single machine.
• Virtuoso [45], is a multi-purpose data server that supports RDBMS, RDF, and XML. It provides a triple storage solution for RDF on RDBMS platforms. Vir- tuoso also supports SPARQL as well as limited RDFS and OWL inference, and can be run on both standalone and clustered machines [117].
As Jena TDB can be used as a high performance RDF store on a single machine, we use it as our triple store for experiments in the research of this thesis.
3.1.5 Commonsense Knowledge Base
Commonsense knowledge is a collection of facts and information that an ordinary person is expected to know. For example, “tiger is an animal” or “dog can smell
drugs”. It can be used to make inferences about the ordinary world. A commonsense knowledge base is a database containing all the general knowledge that most people possess.
Several approaches have been proposed to develop large knowledge bases for in- telligent applications. Cyc [76] is an oldest artificial intelligence project for gathering information from everyday commonsense knowledge. Parts of the project are released as OpenCyc2, which provides an API, SPARQL endpoint, and data dump under an open source license. NELL (Never Ending Language Learning) [28] is another ap- proach for gathering information. It consists of two steps: 1) information extraction from Web and other resources; 2) measuring the confidence level on correctness of the information. The information in NELL is expressed in CSV format and can grad- ually expand over time. Freebase [21] is a practical, scalable tuple database used to structure general human knowledge. It can be accessed through an HTTP-based graph-query API using the MQL (Metaweb Query Language) [48] as a data query and manipulation language. DBpedia [10] is a community effort to extract structured in- formation from Wikipedia and make this information available on the Web. It can be either imported into third party applications or can be accessed online using a variety of user interfaces. YAGO (Yet Another Great Ontology) [109] is another project that extracts information from Wikipedia, WordNet (a knowledge base of English words, will be introduced later) [87] and GeoNames [115]. YAGO can be queried through various browsers or through a SPARQL endpoint.
The knowledge bases mentioned above are almost focused on gathering “facts”
in different fields, similar to encyclopedias. On the other hand, there are some ap- proaches that focus on presenting meaning and description for different words, similar to dictionaries [91]. A well-known approach in this field is WordNet. It is a general-
2As of 2017, OpenCyc is no longer available, details can refer to http://www.opencyc.org.
purpose semantic knowledge base of words, which covers most English nouns, adjec- tives, verbs and adverbs. The current version of WordNet is 3.1, which is available for download and online public use. For better use in Semantic Web applications, version three of WordNet is available in RDF format [86]. WordNet’s structure is a relational semantic network. Each node in the network stands for a specific “sense”
and is expressed by a lexical unit called “synnet” that consists of several synonyms.
Synsets in WordNet are linked by a small set of semantic relations such as “IsA”
hierarchical relations and “PartOf” relations. For its simple structure with words at nodes, WordNet’s success comes from its ease of use [61]. Another approach similar to WordNet, but with European languages is BabelNet [92]. Besides including synsets of BabelNet for different terms, it includes relevant images to clarify the concepts for each term. BabelNet is also available for download in RDF format.
In addition to considering the factual perspective of information or the meaning of words, there are some approaches focusing on other aspects of knowledge. Con- ceptNet is a freely available commonsense knowledge base, which provides a large semantic graph that describes general human knowledge and how it is expressed in natural language. The scope of ConceptNet includes words and common phrases in any written human language. These words and phrases are related through an open domain of predicates, describing not just how words are related by their lexical defini- tions, but also how they are related through common knowledge [107]. For example, the knowledge of “cat” includes not just the properties that define it , such as “IsA”
(“cat” is a type of “animal”); it also includes incidental facts, such as “CapableOf”
(“cat” is capable of “eat fish”) ,“AtLocation” (“a zoo” can be a location of “cat”) and “UsedFor” ( “cat” can be used for “keep the mice away”). Figure 3.5 shows a cluster of related concepts and the ConceptNet assertions that connect them. Sentic- Net [25] is another approach, which is similar to the ConceptNet but mainly focuses
tiger animal CapableOf
hunt for food
zoo cat
south china tiger
IsA
rabbit
IsA fish
lizard
hunt mice CapableOf
move fast CapableOf
cold blooded
warm blooded
humans
Figure 3.5: Concepts and their relations from ConceptNet.
on sentiment values of the knowledge. For each information item, SenticNet tries to assign polarity values to different terms which extracted from ConceptNet or other knowledge bases. It includes a sub-work called IsACore [24], which exploits reasoning techniques for inferring general conceptual and affective information.
3.1.6 Knowledge Parser (K-Parser)
The K-Parser is a semantic parser that translates any English sentence into a directed acyclic semantic graph. The nodes in the graph represent the actual words in the input text and the conceptual classes of those words. The edges represent the dependencies between different nodes, and the labels of the edges represent the semantic relations between the nodes.
The semantic representation of the input text generated by the K-Parser has the following properties [103].
• Has an easy human-readable acyclic graphical representation for input text written in English.
• Has a rich ontology (Knowledge Machine [36] ontology) to express semantic re- lations (Event-Event relations such ascauses, caused by; Event-Entity relations such as agent, and Entity-Entity relations such as related to).
Figure 3.6: An example of the parsed results with K-Parser.
• Has special relations (e.g.,instance of) to represent entities and their conceptual classes.
• Has two levels of conceptual class information for words. For example, with a word “pandas”, “panda” (the conceptual class of “pandas”) and “animal” (the father conceptual class of “panda”) are returned in the graphical representation.
• Accumulates semantic roles of entities based on PropBank framesets3 [94].
• Has tenses of the verbs in the input text.
• Has other features such as an optional Co-reference resolution, Word Sense Disambiguation and Named Entity Tagging.
Figure 3.6 illustrates an example of semantic graph generated by the K-Parser for “a fat panda plays in the grass”. It extracts the event “play”, agent “panda”,
3Refer to https://verbs.colorado.edu/propbank/framesets-english/
•The iguanas wrestled along the rocky water bank.
•The two reptiles are standing on their back legs near deep water.
•Two lizards fighting.
•Two lizards fight in the water.
•Two oriental lizards are fighting for dominance in a small pond.
Sentences Image
Figure 3.7: An image with five descriptions in Flickr8K.
location “grass” and trait “fat” respectively, as a set of entity nodes and event nodes connected by meaningful labels (events correspond to verbs, entities represent nouns or modifiers); it also represents commonsense knowledge such as “semantic role” of entity participating in the sentence.
3.2 Preliminaries
3.2.1 The Flickr8K Dataset
The Flickr8K dataset contains about 8000 images that extracted from the Flickr website [59].
The dataset can be downloaded with a request through a website4. Figure 3.7 illustrates an image from the Flickr8K dataset. For each image, it is annotated with five different captions. These captions consist of natural language English sentences, which are generated by means of crowdsourcing (using Amazon Mechanical Turk).
The images were manually selected to focus on people or animals performing some specific actions. The dataset also contains graded human quality scores for 5,822 captions, with scores ranging from 1 (the selected caption is unrelated to the image)
4http://nlp.cs.illinois.edu/HockenmaierGroup/Framing Image Description/KCCA.html
An#RDF#file#
A#SPARQL#query
Query#RDF#triples
Results
Figure 3.8: An example to query RDF triples with Jena TDB.
to 4 (the selected caption describes the image without any errors). Each caption was scored by three expert human evaluators sourced from a pool of native speakers. All evaluated captions were sourced from the dataset, but association to images was per- formed using an image retrieval system [8]. This dataset is widely used by researchers as a benchmark for image retrieval, understanding and analysis.
3.2.2 Jena TDB
Jena TDB is a component of the Apache Jena Semantic Web framework and available as open-source software released under the BSD license [55].
Apache Jena can be downloaded from a website5. The version of Apache Jena used in this thesis is 3.0.1. Before the querying process, the RDF dataset should be
5Refer to https://jena.apache.org/index.html
connected first. There are two ways for an application to specify the dataset: (1) with a directory name; (2) with an assembler file. In this thesis, image annotations are stored as RDF files; when a SPARQL query is generated, all RDF files are loaded and queried for searching images. Figure 3.8 illustrates an example to query RDF triples with Jena TDB.
3.2.3 Improving the RDF Expressions of ConceptNet
ConceptNet is a commonsense knowledge base, providing a large semantic graph to describe human knowledge. It can be used to find concept features or infer concept names, thereby allowing the development of many intelligent applications.
When designing ABIR system in our research, we consider using the ConceptNet as a knowledge base to raise the accuracy of image retrieval on broad concepts. How- ever, because the ConceptNet is available in only two formats: CSV and JSON [39]; it cannot be directly used to develop intelligent applications based on RDF. Therefore, it is necessary to convert the ConceptNet into RDF format, suitable for use in many intelligent applications.
Some works have suggested to convert the ConceptNet into RDF format. For example, Grassi et al. [50] proposed to encode ConceptNet in RDF to make it directly available for Semantic Web applications; Najmi et al. first proposed ConceptOnto [90]: an upper ontology based on the ConceptNet, then expanded their work and presented ConceptRDF [91]: a representation of ConceptNet in RDF.
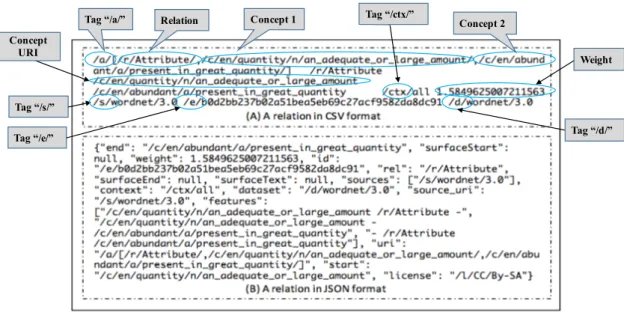
The dataset of ConceptRDF consists of 50 RDF files, which can be downloaded from a website6. A partial view of the ConcetptRDF is shown in Figure 3.9 (omitting prefix definitions): these RDF triples are used to express the concept of “quantity”.
By examining the RDF files, we find that the expression of ConceptRDF has some
6http://score.cs.wayne.edu/resultl
<http://conceptnet5.media.mit.edu/web/c/en/quantity>
COnto:hasContext "all" ;
COnto:hasDataset "site", "wordnet" ; COnto:hasSource "verbosity", "wordnet";
COnto:hasPOS "n", "a";
COnto:hasSense "present_in_great_quantity";
COnto:isA "amount";
COnto:hasAttribute "abundant";
COnto:isRelatedTo "bulk".
Figure 3.9: A partial view of the ConcetptRDF.
mistakes. For example, with the RDF triples in Figure 3.9, the mistakes are as follows: (1) it has two POS tags: “n” and “a”, it cannot know which one is correct;
(2) it has two datasets (“site” and “wordnet”) and two sources (“verbosity” and
“wordnet”), it cannot know where this information is extracted from; and (3) the sense of “present in great quantity” should be the value of concept “abundant” but not“quantity” (this will be shown later in Figure 3.10). In this context, it is necessary to find a way to improve the RDF expression of ConceptNet.
3.2.3.1 The Structure of ConceptNet
The ConceptNet can be seen as a data graph with a set of nodes and edges (each node and edge has a unique URI): the nodes represent concepts and the edges represent the relations between concepts7.
There are two formats available to download the whole dataset of ConceptNet:
one is CSV, each line in the CSV files represents one relation between two different concepts, separated by comma and tab (as shown in Figure 3.10A); the other is JSON, which containing the same information as CSV but in a better human-readable way (as shown in Figure 3.10B). Considering that the information presented in these two
7Structure of ConceptNet is summarized from [91].
Tag “/a/” Relation Concept 1 Tag “/ctx/” Concept 2
Tag “/d/”
Tag “/s/”
Tag “/e/”
Weight Concept
URI
Figure 3.10: Same information in ConceptNet expressed with two formats.
formats are practically the same, we use the CSV format to describe the structure of ConceptNet. For each line in CSV format, it starts with an assertion tag “/a/”;
other tags and their meanings are as follows:
• /r/: the relation between concepts;
• /c/: language-independent concept with a term or a phrase;
• /ctx/: the context of the relation, e.g. /ctx/all;
• /d/: marks where the relation has been extracted from;
• /s/: presents the source of the information;
• /e/: shows the edge ID (each edge can be identified by an edge ID);
• /and/: marks the conjunctions of sources.
• /or/: marks the disjunctions of sources.
Besides the tags mentioned above, there is a number following the tag “/ctx/all”, it represents the weight of an edge. We also note that each concept URI in ConceptNet consists of up to 4 parts; we separate the concept URI with “/” (omitting the “/c/”) and then it can get several smaller parts: (1) language mark, e.g. en for English, ja for Japanese; (2) its normalized text; 3) its part-of-speech (POS) tags (e.g., n for noun, v for verb); (4) the sense of the concept (often available for the information gathered from WordNet).
With the explanations above, we can know the meaning of the information pre- sented in Figure 3.10: “quantity (written in English) is a noun, has the meaning of
‘an adequate or large amount’, isattribute ofabundant, which is an adjective with the meaning of ‘present in great quantity’; the context of the edge is ‘all’; the weight of the edge is 1.5849625007211563; the source and the edge are extracted from WordNet version 3.0; its edge ID is b0d2bb237b02a51bea5eb69c27acf9582da8dc91”.
3.2.3.2 Conversion Process
We use the CSV files of ConceptNet to generate the RDF files. For each line in CSV, it represents a triple of subject, object and predicate: the subject and the object are mainly concepts; the predicate is the relation between concepts. They can be converted into RDF expressions with definitions as follows.
Definition 1 For each concept, it consists of up to 4 parts: language mark, normalized text, POS tag andconcept sense; they can be expressed with RDF triples as follows:
{(ConceptURI, rdfs:label8, normalized text@language mark);
(ConceptURI, hasPOS, POS tag);
8A predefined property, refer to http://www.w3.org/TR/rdf-schema
(ConceptURI, hasSense, concept sense)}.
Definition 2 For each relation, it has many properties, they can be expressed with RDF triples as follows:
{(EdgeID, rdfs:label, Relation@en9);
(EdgeID, hasContex, Contex value);
(EdgeID, hasDataset, Dataset value);
(EdgeID, hasSource, Source value);
(EdgeID, hasWeight, Weight value)}.
Definition 3For each relation between two concepts, they can be expressed with the following two RDF triples:
{(EdgeID, hasSubject, sub Concept);
(EdgeID, hasObject, obj Concept)}.
With these definitions, the information presented in Figure 3.10 can be expressed with RDF expressions (as shown in Figure 3.11).
Conversion processThe conversion process is similar to [91]: it is very simple. We download the dataset of ConceptNet from the public website10 and read them line by line to extract all information items (e.g., concept, relation, edgeID). Then, we model the information items with our definitions. Finally, we generate a set of files with RDF expressions of the ConceptNet. Algorithm 1 shows the algorithm used in the converting process for extracting information items.
9The labels of relations in the ConceptNet are all expressed in English.
10http://conceptnet5.media.mit.edu/downloads/current
Algorithm 1Extracting information items from CSV flies of ConceptNet.
1: Get CSV file list F ileList;
2: for each file Fn∈F ileList do
3: Read each line Ln;
4: Separate bycomma;
5: while line Ln available do
6: find /r/;
7: extract the relation as Relation;
8: find the first concept as Subject;
9: find the second concept as Object;
10: if Subjectavailable then extract language marks, normalized texts;
11: if P OS tag available then extract P OS tags ;
12: end if
13: if concept sense available then extract concept senses ;
14: end if
15: end if
16: if Objectavailable then extract language marko,normalized texto;
17: if P OS tag available then extract P OS tago ;
18: end if
19: if concept sense available then extract concept senseo ;
20: end if
21: end if
22: extract context as Contex value;
23: extract dataset as Dataset value;
24: extract source as Source value;
25: extract weight as W eight value;
26: extract edge ID as EdgeID;
27: end while
28: end for
</c/en/quantity/n/an_adequate_or_large_amount>
RDFS:label "quantity"@en;
hasPOS "n";
hasSence "an_adequate_or_large_amount".
</c/en/abundant/a/present_in_great_quantity>
RDFS:label "abundant"@en;
hasPOS "a";
hasSence "present_in_great_quantity".
<b0d2bb237b02a51bea5eb69c27acf9582da8dc91>
RDFS:label "Attribute"@en ; hasContext "all";
hasDataset "wordnet";
hasSource "wordnet";
hasWeight "1.5849625007211563";
hasSubject </c/en/quantity/n/an_adequate_or_large_amount>;
hasObject </c/en/abundant/a/present_in_great_quantity>.
Figure 3.11: RDF expressions of concepts and their relation.
3.2.3.3 Use Case
The RDF expressions of ConceptNet can be used to infer concept names. For example,
“find something that can smell scent”, which can be expressed with SPARQL as follows.
SELECT ?s WHERE {
?Sub rdfs:label ?s.
?Object rdfs:label “smell scent”@en.
?edgeId rdfs:label “CapableOf ”@en.
?edgeId hasSubject ?Sub.
?edgeId hasObject ?Object.}
With this SPARQL query, “human” and “dog” can be found as answers.
Chapter 4
Proposed Annotation Model for Counting Objects
This chapter proposes an image annotation model based on the notions of concept and instance. With this model, the properties of objects, the relations of objects, and the numbers of objects can be expressed in RDF to describe the detail information of images. Because this model contains the numbers of objects in images, it can support image retrieval by counting objects.
4.1 Related Work
4.1.1 Image Annotation Model
As introduced in Chapter 1, designing an appropriate image annotation model is very important for image management and retrieval.
Keyword-based Annotation ModelMost common search engines (e.g., Flickr, Google and Bing) use keyword-based search techniques. This approach is based on keyword annotations; each image is annotated by having a list of keywords associated with it [98]. With these keywords, images can be retrieved in an effective way. How-
ever, it has the significant disadvantage that keyword-based retrieval systems only use text matching method without understanding the meaning of words, which may affect the accuracy of the retrieval results. For example, when searching with “ani- mal”, images annotated with “animal” can be found, but with “dog” cannot be found;
because the retrieval systems cannot understand that “dog” is a kind of “animal”.
Tag-based Annotation Model A tag annotation element is a non-hierarchical keyword or free-from term assigned to a resource [9]. Tag-based image retrieval so- lutions [66, 118, 96, 79, 6, 64] can be considered as special keyword-based solutions, which allow various users to easily annotate images with a free-text term (tags) and find them based on tags. Tag-based image retrieval systems have the same disadvan- tage that they cannot know the meaning of words.
General Ontology-based Annotation Model This model is based on the no- tion of semantic annotation, the term coined in early 2000s [9, 111]. Ontology is a specification of a conceptualization, it basically contains concepts and their rela- tionships. In practice, ontology-based annotation model is based on the following elements [9]: concepts (e.g., “animal”, “dog”), instances of these concepts (e.g., an individual “dog” in an image), properties of concepts and instances (e.g., “dog” can
“smell scent”), relations between concepts and instances (e.g., “dog” is a kind of “an- imal”) [43]. Ontology-based annotation model allows users to describe images with detail descriptions based on concepts, instances, their relations and properties [9].
Figure 4.1 shows an example of an ontology-based annotation model. With ontology- based annotations, images can be found with more accuracy [101, 63, 80, 84, 97, 99].
Using the same example above, when searching with “animal”, because “dog” can be recognized as a kind of “animal”, images annotated with “dog” can be found.
Ontology-based solution can also be used in other image retrieval systems to improve the accuracy of retrieval results. For example, Alves et al. [6] combined existing
(1)Concepts
“animal”
“dog” is_subconcept_of is_subconcept_of “cat”
capableof
“smell scent”
(2)Image Annotation
Figure 4.1: A general ontology-based image annotation model.
linked open data ontologies with image tag-based search to allow image retrieval by high-level concepts and solved the problem of synonyms. However, because the pre- vious annotation models cannot well express the numbers of objects in images, they are unable to support image retrieval by counting objects.
4.1.2 Information Extraction with NLP Techniques
NLP and text mining are research fields that aim at exploiting rich knowledge re- sources with the goal of understanding, extraction and retrieval from texts [78].
Figure 4.2 (top) shows an overview of information extraction in natural language processing. Given a sentence, it will be parsed into a list of words and linked to knowledge bases to get extra information (e.g., synonyms from WordNet); finally, it can get detail information with concepts and instances1 (“entity” and “event” are
1Events are extracted from verbs; entities are extracted from nouns or pronouns.