INVITED PAPER
Special Section on Frontiers of Internet of ThingsComparison of Access Pattern Protection Schemes and Proposals for E ffi cient Implementation ∗
Yuto NAKANO†a), Shinsaku KIYOMOTO†, Yutaka MIYAKE†,andKouichi SAKURAI††,Members
SUMMARY Oblivious RAM (ORAM) schemes, the concept intro- duced by Goldreich and Ostrovsky, are very useful technique for protecting users’ privacy when storing data in remote untrusted servers and running software on untrusted systems. However they are usually considered im- practical due to their huge overhead. In order to reduce overhead, many im- provements have been presented. Thanks to these improvements, ORAM schemes can be considered practical on cloud environment where users can expect huge storage and high computational power. Especially for private information retrieval (PIR), some literatures demonstrated they are usable.
Also dedicated PIRs have been proposed and shown that they are usable in practice. Yet, they are still impractical for protecting software running on untrusted systems. We first survey recent researches on ORAM and PIR.
Then, we present a practical software-based memory protection scheme ap- plicable to several environments. The main feature of our scheme is that it records the history of accesses and uses the history to hide the access pat- tern. We also address implementing issues of ORAM and propose practical solutions for these issues.
key words: access pattern protection, oblivious RAM, private information retrieval
1. Introduction
The emergence of Internet of Things (IoT) and cloud com- puting bring new problems in accessing to remote untrusted servers and running software on untrusted systems. The leakage of information and its protection arising from both running software on untrusted systems, as well as storing data in remote untrusted servers have attracted much atten- tion. Encryption can ensure the confidentiality, however, sometimes confidentiality is not enough as the pattern of accesses to servers can leak important information. In the data storing environment, one can identify the main moti- vation for protecting access pattern to the storage: the ac- cess pattern may leak which data is important for the user, as the important data will typically be accessed more of- ten. The traditional solution for memory access pattern pro- tection is known as Oblivious RAM (ORAM) [3], [4]. The similar solution is called private information retrieval (PIR), which enables the client to hide his/her access pattern from thehonest-but-curiousservers [5]. Both schemes required huge overheads and were considered unpractical. After the
Manuscript received January 15, 2014.
Manuscript revised July 9, 2014.
†The authors are with KDDI R&D Laboratories Inc., Fujimino-shi, 356–8502 Japan.
††The author is with Kyushu University, Fukuoka-shi, 819–
0395 Japan.
∗Part of this paper was presented at CARDIS 2012 [1] and ISA 2014 [2].
a) E-mail: [email protected]
DOI: 10.1587/transinf.2013THP0007
first proposals, a lot of improvements have been proposed.
In this paper, we first introduce a series of related works on ORAM and PIR, and compare their overhead. The tar- get of both schemes is the same: how to efficiently pro- tect the pattern of accesses. ORAM supports both the read and write operations to RAM (or server) while PIR usu- ally consider the read operation. We then introduce our lightweight scheme and consider practical implementation of the scheme. The main feature of our scheme is based on the history of accesses. We also propose three techniques for the higher performance.
2. Related Works
We briefly introduce below some of the main research re- sults related to our work.
2.1 Oblivious RAM
Software piracy has been a major concern for all software developers as it is very easy to copy software and use copied software. Many software protection mechanisms have been proposed such as licence management mechanisms, obfus- cation mechanisms and combination of secure hardware.
Many of those mechanisms are, however, ad-hoc and not based on theoretical foundations. Goldreich [3], later ex- tended by Goldreich and Ostrovsky [4], proposed software protection mechanism called Oblivious RAM. By using ORAM schemes, one can execute a program in a way that a polynomial-time adversary can only know how long it takes to finish the program even if the adversary can alter mem- ory contents during execution. The application of ORAM to realise a private access to remote servers has also been considered, for example [6], [10]. Goldreich and Ostrovsky proposed two main constructions, calledhierarchical solu- tionandsquare root solution.
The square root solution attaches area calledshelter, which can contain √
N blocks, to main memory and adds
√N dummy blocks. Then originalN data blocks and √ N dummy blocks are permuted by the secret permutation π.
When the client accesses to data blockx, one first scans en- tire shelter to confirm ifxis inside the shelter. One accesses to dummy location in memory ifxis in the shelter, accesses to π(x) to copy the block xto the shelter, otherwise. As one block is copied to the shelter at each access, the shel- ter gets full after √
N accesses. Once the shelter gets full, new permutationπis chosen and all blocks are re-shuffled Copyright c2014 The Institute of Electronics, Information and Communication Engineers
according toπ, which causes huge overhead. The security of this scheme is based on an one-way function. The one- way function is a function which can be easily computed in one-way, that is computingy = f(x) for givenx, however, computing the other way, that is f−1(y) for giveny, is com- putationally infeasible.
In the hierarchical solution for RAM withNitems, the data structure is organised inn=O(logN) levels consisting of hash-tables with 2ibuckets (1≤i≤n), each bucket con- tainingO(logN) items. The storage requirement is therefore O(NlogN). Data is mapped into the levels using different secret hash functionshi, known by the client only.
An elementris read with theread(r) operation as fol- lows:
1. Scan the entire first level.
2. If the element is not found, then for each leveli(2 ≤ i ≤n), compute j = hi(r) and read the j-th bucket in the levelibuffer, until the requested element is found.
3. Once the element is found (including during the scan of the first level), continue with the procedure in step 2. by reading a dummy location in each level igiven byhi(dummy◦t), wheretis a counter.
4. The entire first level is scanned again, and the element ris written to the first level.
When we wish to update an elementrwith thewrite(r,x) operation, we perform theread(r) procedure as above, but insert the new value xinto the first level at the step 4. It follows that the number of access operations for a data item request (eitherreadorwrite) isO(log2N).
Because of the writing in step 4, buffer levels eventu- ally overflow with data. Indeed, after 2irequests, the buffer at leveliwill be full, and its full contents are moved down to leveli+1. Every time content is moved to a lower level, all data in both levels are permuted and a new random hash function is chosen. This process requires the re-shuffling of data, which needs to be doneobliviously. This is the most complex component of the construction, and is the main fac- tor in its (amortised) complexity overhead.
Based on the constructions above, the original scheme from [4] requires O(NlogN) in storage, and has amor- tised computation overhead ofO(log3N) per query using the AKS algorithm for the oblivious sorting [7]. Due to the very large constants, the complexity is consideredO(log4N) in practice (by using Batcher’s sorting network [8]).
In the past few years, several improvements have been proposed and many applications using ORAM schemes have been proposed, for example [6], [9]–[20]. Improve- ments typically arise from the use of different data struc- tures and hash function schemes, more efficient sorting al- gorithms (for the oblivious shuffling), and the use of secure local (client) memory. Currently, the best amortised over- head isO(log2N/log logN) presented in [16] whose secu- rity is based on the one-way function.
One can show that the combination of the scanning method described above, and frequent oblivious re-shuffling can provide a high level of memory access pattern privacy
protection. In particular, the re-shuffling following level overflow ensures that a data item is not visited twice in the same level (for 2≤i≤n) using the same hash functionhi. We note however that it was shown in [16] that the choice of hash function may still leak information to adversaries.
Despite much recent progress, where the asymptotic ef- ficiency as well as the constant terms of ORAM solutions have been improved (making it particularly attractive for re- mote storage access pattern protection), current solutions re- main inefficient for preventing leakage of relatively limited- in-size memory access pattern. In these cases, the constant terms involved in the computational complexity make the overhead unacceptably high. This motivates the proposal of other methods, which while not achieving the same level of protection as ORAM, offer low computation (and storage) overheads, and may therefore achieve both security and per- formance levels acceptable in practice.
Suppose that we are accessing the data ‘a’ several times in the ORAM. TheRead(a) process searches for ‘a’ in the set of (At ∪Pt) where At indicates all element in the top level and Ptindicates the path which is determined by the hash functionh(a) andh(dummy). At the next access to ‘a’, the read operation searches for ‘a’ in the set of (At+1∪Pt+1).
Here, we have to consider two cases: 1) re-shuffle has been done or 2) re-shuffle has not been done.
1. Since the re-shuffle has not been done, we are using the same hash functions. But, ‘a’ must be in the top level, and search dummy location for the lower levels. Hence PtandPt+1have no correlation.
2. Since the re-shuffle has been done, new hash functions are chosen. ThereforePtandPt+1have no correlation.
As shown, Pt andPt+1 are indistinguishable. AndAt and At+1are also indistinguishable, since the all data always is accessed in the top level. Therefore the adversary cannot tell if ‘a’ is being accessed more than once. Re-shuffling the elements is critical for the security of ORAM, but it is also critical for the cost of ORAM. The best amortised overhead isO(log2N/log logN) presented in [16].
Williams et al. [21] introduced a collection of new tech- niques, which are supporting parallel queries and a new de-amortisation construction, to improve their performance.
By applying the collection to ORAM proposed in [22], they implemented which is called PD-ORAM (“Parallel De- amortised ORAM”). Supporting parallel queries from mul- tiple client can decrease a response time, especially when the client is accessing the database through a relatively high latency network. A new de-amortisation construction en- abled the database to process queries simultaneously with re-shuffling. As the re-shuffling process is one of the heavi- est task of ORAM, this new construction contributed for the improvement.
Recently the third construction called the tree construc- tion is proposed by Shi et al. [14]. It has an N-element database in a binary tree of depth logN. Each node in the tree has a bucket which can storekdata items. Their scheme usesO(NlogN) storage at the server. The client needsO(1)
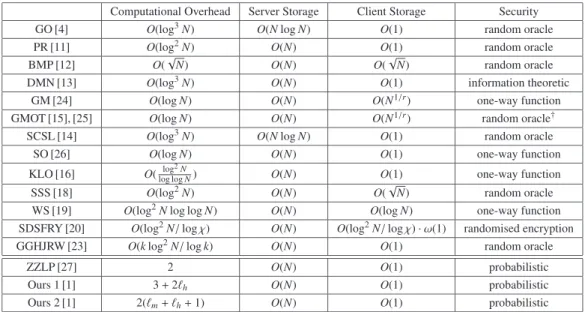
Table 1 Comparison of ORAM and related schemes. ris a small constant ofr>1. Bis a size of data block (B=χlogN).mandhare respectively the size of buffer and history table.kis the security parameter whose typical setting may bek∈[50,80].
Computational Overhead Server Storage Client Storage Security
GO [4] O(log3N) O(NlogN) O(1) random oracle
PR [11] O(log2N) O(N) O(1) random oracle
BMP [12] O(√
N) O(N) O(√
N) random oracle
DMN [13] O(log3N) O(N) O(1) information theoretic
GM [24] O(logN) O(N) O(N1/r) one-way function
GMOT [15], [25] O(logN) O(N) O(N1/r) random oracle†
SCSL [14] O(log3N) O(NlogN) O(1) random oracle
SO [26] O(logN) O(N) O(1) one-way function
KLO [16] O(log loglog2NN) O(N) O(1) one-way function
SSS [18] O(log2N) O(N) O(√
N) random oracle
WS [19] O(log2Nlog logN) O(N) O(logN) one-way function
SDSFRY [20] O(log2N/logχ) O(N) O(log2N/logχ)·ω(1) randomised encryption
GGHJRW [23] O(klog2N/logk) O(N) O(1) random oracle
ZZLP [27] 2 O(N) O(1) probabilistic
Ours 1 [1] 3+2h O(N) O(1) probabilistic
Ours 2 [1] 2(m+h+1) O(N) O(1) probabilistic
†This can be realised without a random oracle by using [13]
memory and computation complexity is O(log3N). The scheme is proven secure given the access to a random or- acle. Later, the tree construction is optimised by Gentry et al. [23]. The optimisations can reduce the storage over- head by anO(k) factor and computation complexity by an O(logk) factor, wherekis a security parameter.
Comparison of computation overhead, storage over- head and security is summarised in Table 1. As shown in Table 1, the security of SDSFRY [20] is based on the ran- domised encryption. It is an encryption algorithm which uses randomness on the encryption and resulting ciphertexts correspond to the same plaintext are indistinguishable from one another.
2.2 Private Information Retrieval
Emerging of cloud storage services enables users to store and access their data very easily. Moreover, users can store huge data which is too large to store locally. However, it also raises a new security challenge, which is how to pro- tect user’s privacy. When the user request data to the server, the server will notice which data the user wants. The server might be curious about the user’s request and try to extract user’s private information. Encryption can provide confi- dentiality of data, however, sometimes it is not sufficient.
For instance, if the particular file is accessed very often, it implies that file is more important for the user than the ones accessed less often. An adversary may try to delete those files.
Private Information Retrieval is a technology that al- lows clients to query a database in a way that even the database cannot learn anything about the clients’ queries. A trivial solution is to download everything every query. This solution, however, is impractical due to a high communica-
tion overhead and a high storage overhead at the client side.
There are two PIR schemes: computational PIR (CPIR) [28], [29] and information theoretic PIR (IT- PIR) [30]. In the CPIR, the client queries the database an encrypted query and the server returns the encrypted result to the client in order to prevent the computationally lim- ited server from learning anything about the query. For example, Chor and Gilboa’s scheme [28] and Kushilevitz and Ostrovsky’s scheme [29] require O(N) server storage for storing data of sizeN, the same as evaluated in ORAM schemes, and communication overhead isO(N). We eval- uate the efficiency of PIR schemes in terms of the commu- nication cost, not the computational cost, as the efficiency is generally measured by the communication cost. The se- curity of Chor and Gilboa’s scheme is based on an one-way function and Kushilevitz and Ostrovsky’s one is based on the hardness of deciding quadratic residuosity. An integer qis called quadratic residue (QR) if there exists an integer xsuch thatx2 = q modn, andqis called quadratic non- residue (QNR) otherwise. It is considered hard to predicate ifqis QR or QNR whennis a product of two distinct prime numbers of equal length. On the other hand, the ITPIR can offer perfect security, that is, the server cannot acquire any information about the client’s query even if the server has unlimited computational resources and unlimited time. In order to achieve the ITPIR, we usually need multiple servers and an assumption that these servers do not collude. The t-private-server PIR can information theoretically guaran- tee the privacy of the query even if up totout ofservers collude. Beimel and Stahl [31] introduced a notation called t-privatek-out-of-PIR in whichkout ofservers need to respond and up tot servers may collude without compro- mising the security. In addition they examined a situation that vout ofkservers can return incorrect answers, due to
a malicious servers or database failure, which is termed as t-privatev-Byzantine-robustk-out-of-PIR. Chor et al. [5], [30] have proposed several schemes. Their proposals enable the client to retrieve one bit withO(√
N) communication cost in a simple-server scheme,O(N1/) communication in a general-server scheme and13(1+o(1))·log2N·log log(2N) communication cost in 13logN +1-server scheme. Their scheme is information theoretic secure.
After the first proposal of PIR in [5], several im- provements in terms of communication cost have been shown [10], [31]–[37]. The scheme proposed in [35] re- quiresO(N) server storage andO(1) communication over- head, and is information theoretic secure. This scheme was implemented as an open-source project on Source- Forge [38]. Smith et al. [32], [33] proposed a scheme with a tamper-proof device. The client sends the secure coproces- sor (SC) with encrypted query. The SC receives the query and decrypt it. Then the SC reads the entire database and get the requested data item. When returning the data item to the client, the SC encrypts the item and send it back to the client. Williams and Sion [10] proposed a single-server PIR with an ORAM and a secure coprocessor. The commu- nication and computational complexities of their scheme is O(log2N) andO(√
N) client storage is required. The secu- rity of their scheme is proven when it has the access to a random oracle. Devet et al. [37] improved the scheme pre- sented by Goldberg [35] and evaluated the performance of the scheme. They showed that their implementation was several thousands times faster than the scheme of [35].
Bao et al. [39] and Schnorr et al. [40] independently proposed similar PIR schemes using homomorphic encryp- tion. Their schemes requires onlyO(1) computation to be done on-line. The idea of the schemes is to do as many operations as possible off-line to achieve practical on-line overhead. However, because of heavy off-line computation, the client has to wait until the server is ready to be queried, and this latency may make the schemes less practical. The schemes work as follows: When the client wants to obtain a data item, which is encrypted with the servers secret key and publicly available, first the client download the item and encrypts it with the client’s secret key. After the encryption at the client, the client sends the item to the server and asks to remove the server’s encryption. Finally, the client obtain the data item by decrypting one’s own encryption.
Asonov and Freytag’s scheme [34] also assumes the SC inside the server and SC first shuffles the entire database ac- cording to a random permutationπ. When the client request the data itemi1, the SC fetches the item from π(i1). This only requiresO(1) of computation and communication. For the second query of requesting the itemi2, the SC first has to readπ(i1) and then readπ(i2). Wheni1 =i2(the second and the first query request the same data item), the SC reads π(i1) and a random item in order to hide the fact that the client is reading the same data item twice. Therefore, for then-th query, the SC has to read all previously read items before readsπ(in). At a certain point, the SC has to pick a
new permutationπand shuffle the database withπ. The PIR schemes can protect user’s privacy from an honest-but-curious servers. However, PIR schemes can not offer a protection from a dishonest user. Gertner et al. [41]
proposed a symmetric private information retrieval (SPIR) that prevents the user from learning additional informa- tion. Henry et al. [42] considered an application of SPIR for e-commerce and proposed a protocol that extended the PIR scheme [35] to a priced symmetric private informa- tion retrieval (PSPIR). Their PSPIR scheme maintain user’s anonymity and does not leak any information about the record of user’s purchases.
Recently implementations of CPIR and evaluating per- formances on real environments are attracting more atten- tions. Melchor and Gaborit [43], [44] proposed a lattice- based new scheme with a reasonable communication cost and with computational complexity being improved by a factor of one hundred. Later, Olumofin and Goldberg [45]
implemented the lattice-based scheme and evaluated the performance. They demonstrated that the overhead of Olumofin and Goldberg’s scheme was 10 to 1000 times smaller than the trivial scheme (i.e. downloading entire database).
Recent schemes can outsource the database to un- trusted servers and yet can protect both the privacy of the database owner and clients. Huang and Goldberg [46] pro- posed a scheme for outsourcing Private Information Re- trieval. Their scheme requiresO(√
N) computational over- head and the server storesO(√
N) data. The security of the scheme is proven when it has the access to a random ora- cle. They also implemented their scheme and evaluated the performance. When the client updates 1MB record in the 1 TB database, an amortised end-to-end latency is smaller than 300 ms.
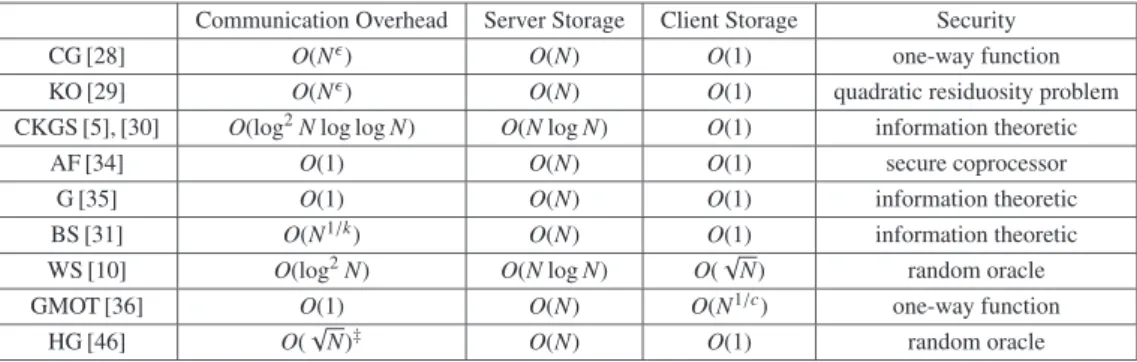
The comparison of PIR schemes is summarised in Ta- ble 2. In Table 2, we compared communication overhead of schemes since they are generally evaluated by commu- nication overhead†, while ORAM schemes are evaluated by computational overhead.
2.3 Hardware-Assisted Control Flow Obfuscation ORAM constructions remain too expensive to be imple- mented on embedded processors. In [27], Zhuang et al. pro- posed a practical, hardware-assisted scheme for embedded processors, with low computational overhead. Theircontrol flow obfuscationscheme for embedded processors employs a small secure hardware obfuscator (calledshuffle buffer) to hide program recurrence. We give a brief description of the scheme below; for more details, refer to [27].
Letnbe the size (in blocks) of memory, andmnbe the size of the shuffle buffer. The shuffle buffer is within the CPU trusted boundary, i.e. it is considered secure local stor- age (cache), and an adversary is not able to observe access
†All literatures referred in Table 2 evaluate their own scheme in terms of the communication overhead, except Huang and Goldberg’s scheme [46].
Table 2 Comparison of PIR.is the total number of servers andkis the minimal number of servers which are available at the time of retrieval.cis a constant ofc≥2 andis a small constant of≥0.
Communication Overhead Server Storage Client Storage Security
CG [28] O(N) O(N) O(1) one-way function
KO [29] O(N) O(N) O(1) quadratic residuosity problem
CKGS [5], [30] O(log2Nlog logN) O(NlogN) O(1) information theoretic
AF [34] O(1) O(N) O(1) secure coprocessor
G [35] O(1) O(N) O(1) information theoretic
BS [31] O(N1/k) O(N) O(1) information theoretic
WS [10] O(log2N) O(NlogN) O(√
N) random oracle
GMOT [36] O(1) O(N) O(N1/c) one-way function
HG [46] O(√
N)‡ O(N) O(1) random oracle
‡They evaluated the scheme in terms of computational overhead.
pattern in the shuffle buffer. As in other parts of this paper, we assume that data is stored encrypted and access opera- tions consist of sequentialreadandwriteoperations. A random permutation is initially applied to data before load- ing it to RAM. The scheme then works as follows.
1. The firstmblocks in memory are moved to the shuffle buffer.
2. When making a request for a data item, if the block is found in the shuffle buffer, access the block.
3. If the block is not found in the shuffle buffer, pick a random block in the shuffle buffer and swap it with the requested data block in memory (the accessed data item is now in the shuffle buffer).
4. When the program finishes its entire process, the full contents of shuffle buffer are written back into memory.
Note that item 3. implies that the permutation used to map data in memory isdynamicallymodified as the program runs. Although the dynamic secret permutation helps to pro- tect the privacy of individual items being accessed (or being repeatedly accessed), it also means that the scheme needs to make use of a block address table to map data items into memory (describing the permutation at timet). As a re- sult there is the storage requirement of sizeO(n) within the trusted environment to represent this mapping (albeit with constant<1).
The scheme trades security for low overhead. Besides the costs of having a secure on-chip buffer, the scheme triv- ially leaks information about access of data items during ex- ecution of program. In fact, the lack of memory access in step 2 indicates that when step 3 is executed, one knows the exact block being accessed (the one in memory, be- ing brought into the buffer). Thus a step 2 followed by a step 3 indicates that the data items being accessed are defi- nitely distinct (i.e. there is no 2-recurrence at this particular stage). Likewise, a step 3 followed by a step 2 indicates a 2-recurrence with probability 1/m. Furthermore, an access in memory to a data item which was previously swapped out from the buffer indicates with high probability the exis- tence of repeated access to a particular data. These could be confirmed by running the program several times.
Despite the limitations of the proposal, it adds a very low overhead to the program execution (besides the
read/write and encryption/decryption overhead, only an ex- tra read/write operation due to cache misses). We will adapt some of the ideas from this scheme in our proposal.
2.4 Lightweight Memory Access Pattern Protection Scheme
We first defined a new security notion called δ-length - security[1].
Definition 1 We say that an access pattern protection scheme is δ-length -secure if the probability that an ad- versary identifies any d-distance access in A(y)is at most for every d≤δ.
Then we proposed a practice-oriented scheme for protecting RAM access pattern and considered two instances, which satisfy δ-length-security. The first instance is similar to the proposal by Zhuang et al. [27], and relies on the use of a secure (trusted) hardware buffer. However it achieves higher security by adapting ideas from Goldreich and Ostrovsky’s square root solution, yet without the expensive (re-)shuffling of buffers. The second instance requires no special hardware and can offer the same level of security as the first instance, but as a result leads to a higher overhead.
The main feature of the proposal in [1] is to main- tain the historyof access, which together with the access of dummy data, helps one to hide data access pattern with- out frequent oblivious re-shuffling. The history tableH is stored inside secure memory, in case of the first instance, along with the bufferMand random permutationE. As we do not require secure memory for the second instance, all of them are stored in unsecured memory.
When the program is invoked, our scheme first ran- domly permutes all data blocks according to the permuta- tion E. Note that unlike ORAM, this permutation is done only once. As different mapping is chosen every time the program is invoked, our scheme has to hold the mapping table inside the secure region. After the shuffling, the pro- gram starts accessing data blocks on RAM. The scheme swaps data blocks between the secure buffer and main mem- ory for every access. The buffer temporarily holdsM data blocks and corresponding addresses, which were recently
accessed. As the size of buffer is limited, the buffer will be full at some time, thereafter every time the program ac- cesses a data block, two blocks should be removed from the buffer and kicked back to memory. The addresses of those blocks, which are kicked out from the buffer, are stored in the history table. The history table can hold up toH ad- dresses. When the history table gets full, two random entries are overwritten by new entries.
Let us explain the scheme using an example in which the program accesses the data block ‘a’ stored in the address ia. The scheme always brings two blocks from memory into the buffer and evict two blocks instead. Which blocks should be evicted can be randomly determined. The choice of which blocks should be brought is described as follows:
1. if ‘a’ is in M, we replace two random elements (not
‘a’) fromMby a random element ‘r’ from main mem- ory and a random element ‘p’ from main memory which had already been accessed before (as recorded in the history table), and we access ‘a’.
2. if ‘a’ is not inM, and its address is in the history table, we replace two random elements fromMby a random element ‘r’ from main memory and ‘a’ (as recorded in the history table). Note thatH holds only addresses and data itself is stored in main memory.
3. if ‘a’ is not inM, and its address is not in the history table either, we replace two random elements fromM by ‘a’ and a random element ‘p’ from main memory which had already been accessed before (as recorded in the history table).
In words, the choice is determined as one of the blocks al- ways looks randomly chosen and the other always looks one in the history table. Let us take the case 2 as an example, two blocks (r,a) are copied to the buffer. The block ‘r’ looks as it is randomly chosen, and it is indeed. The block ‘a’ looks as if it is chosen not because it is requested, but because its address is registered in the history table from the adversary’s view point. As the first instance of their scheme assumes se- cure hardware, the program can access the block ‘a’ directly after bringing two blocks. In the second instance, the pro- gram has to access all data blocks in the buffer otherwise the adversary might be able to notice which block is actually the program is accessing. We have a pseudocode of our scheme in Algorithm 1.
2.5 Difference between ORAM and PIR
The target of both ORAM and PIR is the same: how to efficiently protect the pattern of accesses. The main dif- ference is that ORAM supports both theread andwrite operations to RAM (or server) while PIR usually consider only thereadoperation. As the functionality of PIR is lim- ited compared to ORAM, PIR tends to be more practical, in terms of communication and storage cost, than ORAM.
PIR works very well when one server or cloud operator pro- vides a large database and many clients want to download part of the database in a privacy preserving manner. How-
Algorithm 1 Pseudocode of access pattern protection scheme
1: scanMfor ‘a’
2: if‘a’∈ Mthen
3: replace two random elements (not ‘a’) inMwith two random blocks inL, one of them is chosen from the historyHand the other is randomly chosen fromL
4: else
5: scanHfor ‘ia’ 6: if‘ia’∈ Hthen
7: replace two random blocks inMwith a random block inLand
‘a’
8: else
9: replace two random blocks inMwith ‘a’ and a random block whose address is registered inH
10: end if 11: end if
12: choosehelements fromh+2 to update history tableH 13: access ‘a’
ever, as PIR does not supportwriteoperation, it does not work well in some services for example file hosting services where clients upload their files and they often update part of their files. Neither does PIR work well when a software developer wants to protect his/her software from reverse en- gineering. ORAM is usually less practical than PIR in terms of performance, however, ORAM supports both readand writeoperations. Hence ORAM is suitable for protecting access pattern in a database which is often updated and a software protection.
PIRs usually offer less functionality than ORAMs, hence they are lighter than ORAMs and oppose smaller overhead. Because of their lightweightness, PIRs are more attractive for users who wish to hide only their reading pat- tern. Some ORAM schemes are practical and their applica- tions to realise a private access to remote servers have also been considered. Our scheme is as light as one of the most efficient PIRs, our scheme can be used instead of PIRs with- out sacrificing performance.
3. Implementation Issues of ORAM
Considering the practical implementation of ORAM, there were several questions to be addressed and improvements to be achieved. We propose practical solutions for these issues.
The issues are;
• Management of data blocks in the buffer
• Construction of a secure area
• Size of each block.
In Sect. 3.1, we propose a better management of data blocks.
The construction of secure area based only on software is discussed in Sect. 3.2. Finally we discuss better use of each block for saving storage in Sect. 3.3.
3.1 Managing Data in Buffer Using Flags
The square-root based solutions first scan all data blocks in order to know if the accessing block is in the shelter or not
at the beginning of the process. If the accessing block is in the shelter, the block from a dummy location will be fetched into the shelter. When the dummy block is being fetched, there is a chance that the block which is already in the shel- ter is chosen again. If this block is the dummy one, it is not a problem. However, if the block is the real one, which is the one actually accessed by the program, we cannot distinguish which block is newer. As the result, the program may mis- behave in the software protection scenario and the database may be ruined in the database access protection scenario.
Therefore, we must ensure that all blocks in the shelter are the latest and there is no duplication.
The trivial solution to ensure that is to scan the entire shelter before fetching the data block, which impose large overhead. We can omit this scan by usingn1-bit flags Fi
indicating whether the data block is in the buffer or not. We setFi = 1 when data stored in address i is stored in the buffer andFi=0 otherwise. When bringing two blocks into the buffer, we check flag of each block. If it is 0, we bring the block into the block. If it is 1, we pick different block and check the flag again.
The same situation can happen in the lightweight scheme proposed in [1]. Their scheme always fetches two blocks in to the shelter, the chance of the block which is al- ready in the shelter being chosen is higher than the square- root solution. We have confirmed that this solution can im- prove the performance by roughly 3 times in many parame- ter settings with a prototype implementation. When the hier- archical solution is applied, there is no need for the manage- ment of newer data as newer data blocks are always upper level. The scheme proposed in [27] does not either require this management as their scheme swaps two blocks between the shelter and main area.
3.2 Constructing Secure Region
ORAM of square-root solution has a shelter of size√ Nand the scheme has to access all data blocks in the shelter at least twice per one access. As the size of the program or database grows, the size of the shelter also grows, which increase the computational overhead of the implementation. ORAM of hierarchical solution also has the same problem as it also has to access all data blocks in the top level buffer. Though it may not be serious as square-root solution, as the size of top level buffer is fixed and usually smaller than √
The cost of accessing shelter or top leverl buffer can beN.
reduced by using secure hardware where only the client can access as done in [1], [27]. Though this is looks promising, requiring secure hardware may compromise the practical- ity. The third option is to construct a secure region with obfuscation. Letaccess(K) be the complexity of accessing Kblocks andob f(V) be the complexity of obfuscating vari- ablesV. Also letX be the variables after the obfuscation.
Then the obfuscation can offer higher performance than ac- cessing all data blocks in the buffer when the following in- equation holds;
access(K)≤ob f(V)+access(X).
In the square root construction, the size of the shelter tends to large as its size is √
N. Therefore, it is likely that we can improve the performance of ORAM scheme with this method. Depending on the size of the top level buffer for hierarchical solution and the complexity of obfuscation ob f(V), this method is also applicable to the hierarchical solutions. It is also applicable and for the scheme of [1].
We use the scheme proposed in [47] for obfuscation.
By using obfuscation with the memory protection scheme, we only need to protect the shelter (square-root), top level buffer (hierarchical) or buffer and history table ([1]), which are much smaller than N. As described in the following, we divide the buffer and history table into smaller ones and apply the obfuscation repeatedly. Hence we can further de- crease the overhead due to obfuscation.
By obfuscating data blocks inside the secure region, the accesses to memory is also “obfuscated”, that is, the ac- cess to a certain data block is transformed into the access(es) to obfuscated block(s). When the protection scheme needs to access one of data blocks, it accesses obfuscated blocks and unlock the obfuscation in order to obtain the real value.
As the correspondence between the original access and the
“obfuscated” access(es) is secret, an adversary cannot un- derstand which block is actually accessed. The obfuscation does not affect any operation done by the protection scheme as it only encodes the data blocks. The obfuscation also re- alise less access overhead than that of accessing all blocks in the buffer by appropriately choosing the parameters, which we discuss later this section. Thus, by using obfuscation for data blocks, we can construct a secure area without hard- ware, and less overhead than accessing all blocks in the buffer.
Each block which requires to be secret is implemented as variables, and these variables are encoded into obfuscated variables. The following is a small example of the obfusca- tion from a set of variables{v1, v2, v3}into a set of obfuscated variables{x1,x2,x3,x4,x5};
⎛⎜⎜⎜⎜⎜
⎜⎜⎜⎜⎜
⎜⎜⎜⎜⎜
⎜⎜⎝
x1
x2 x3
x4 x5
⎞⎟⎟⎟⎟⎟
⎟⎟⎟⎟⎟
⎟⎟⎟⎟⎟
⎟⎟⎠=
⎛⎜⎜⎜⎜⎜
⎜⎜⎜⎜⎜
⎜⎜⎜⎜⎜
⎜⎜⎝
1 0 0 1
0 1 0 1
0 0 1 1
1 1 0 1
0 1 1 1
⎞⎟⎟⎟⎟⎟
⎟⎟⎟⎟⎟
⎟⎟⎟⎟⎟
⎟⎟⎠
⎛⎜⎜⎜⎜⎜
⎜⎜⎜⎜⎜
⎜⎜⎝
v1
v2
v3
d
⎞⎟⎟⎟⎟⎟
⎟⎟⎟⎟⎟
⎟⎟⎠⊕
⎛⎜⎜⎜⎜⎜
⎜⎜⎜⎜⎜
⎜⎜⎜⎜⎜
⎜⎜⎝
y1
y2
y3
y4
y5
⎞⎟⎟⎟⎟⎟
⎟⎟⎟⎟⎟
⎟⎟⎟⎟⎟
⎟⎟⎠, (1)
where the matrix is chosen as its rank to be the same as the number of elements in the original variables (in this exam- ple, it is 4). Each element of the matrix is randomly chosen except the rightmost column, which is set to all 1s. A ran- dom variable d is generated by a pseudo-random number generator and it is attached to the original variables. Finally a secret vector{y1, y2, y3, y4, y5}is exclusive-ORed, this op- eration acts like random masking. We repeatedly apply the same obfuscation for the multiple sets of the original val- ues until we obtain enough size of the secure region. In this example, we obtain the secure region of size 4 per one iter- ation.
Fig. 1 Constructing secure area using obfuscation.
When one ofvis, sayv1, is requested, we first determine which set of obfuscated variables to access depending on the index ofv1, then access allxis to decodev1. Supposev1is updated tov1after the operation, then we apply the same ob- fuscation as given in Eq. (1) with newly generated random numberd. We use different random numbers every time the program accesses to the secure region. As the correspond- ing column todis set to all 1s, the change ofdwill cause the changes of all variables of{xi}even if none of variables{vi} are changed (i.e.readoperation). Moreover, as the encod- ing applies the secret matrix, the adversary cannot detect the correspondence between{vi}and{xi}. Though the adversary may be able to detect which one of{xi}is being accessed, one cannot understand which one of{vi}is being accessed.
Thus, we can construct a secure region using obfuscation.
There is, however, a limitation to use obfuscation for constructing secure area, which is the size and number of all variables must be pre-determined. In order to overcome this limitation, we divide the secure region into smaller units.
Figure 1 shows an example when 8 blocks to be obfus- cated into 16 blocks with one random number. We can of course use different matrices and vectors for each obfusca- tion unit, which makes obfuscation more difficult to be anal- ysed, though this will increase the code size. We also note that we can of course choose arbitrary size for the unit of obfuscation.
3.3 Reducing Storage Overhead
In the scheme of [27], the uniform unit of data was defined as a block of size 128-bit. However, some programs uses a byte block or smaller as the smallest unit. When one byte data is allocated to 16 byte block, it wastes remaining 15 bytes. For the better management of storage, we modify the scheme so that one block can store multiple smaller blocks.
This modification not only saves storage, but also im- proves the performance for operations such as data copy and move. When a program copies for example four integer-type blocks, the original scheme requires four copy operations.
On the other hand, our proposal only requires one copy op- eration when these four blocks are in the same 128-bit block.
By carefully choosing smaller blocks on storing them into a large block, we can expect speed-up and saving storage at the same time.
3.4 Implementation Result
We implemented our scheme to which three modifications are applied. Then we measured the required time to write
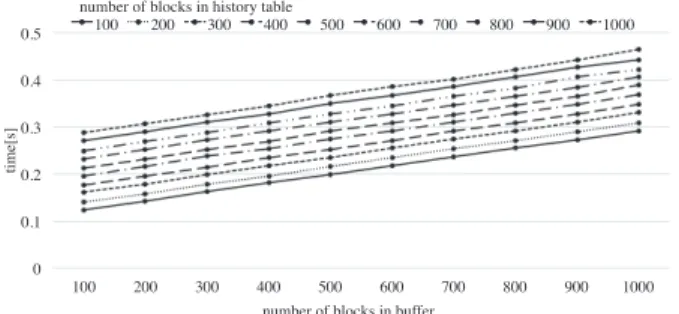
Fig. 2 Performance evaluation in various settings.
1MB data on RAM using the protection scheme. The evalu- ation was done on the PC of CPU: Intel Core i7 3930K and RAM: 8 GB which runs Ubuntu 13.04 x64 and gcc 4.7.3. As our scheme has two parameters (e.g. number of blocks in the buffer and history table) which affects the performance, we measured the required time while we change the number of blocks in the buffer and the history table from 100 to 1000.
Figure 2 shows the relation between parameters and perfor- mance of our efficient implementation. The x-axis denotes the number of blocks (from 100 to 1,000 for every 100) in the secure buffer, the y-axis denotes required time to load 1 MB data to the protection scheme and each curve corre- sponds to each size of the history table. In the fastest setting, our scheme only requires 0.125[s] to write 1 MB data. As shown in the figure, the overhead grows linear to the size of buffer and history table. This is because more time required to scan the entire buffer and history table as their size grow.
However, growth of overhead is very slow compared to that of size of buffer and history table thanks to the efficient im- plementation of scanning process.
4. Conclusion
In this paper, we summarised series of researches on ORAM and PIR, and compared the overhead of each scheme. We also introduced two lightweight scheme. Then discussed three general implementation issues, namely management of data blocks in the buffer, construction of a secure area and size of each block, and their solutions. The solutions can be widely used for implementing ORAM and improv- ing the performance.
Acknowledgement
The last author is partially supported by JSPS-Kaken No.23300027.
References
[1] Y. Nakano, C. Cid, S. Kiyomoto, and Y. Miyake, “Memory ac- cess pattern protection for resource-constrained devices,” CARDIS, LNCS, vol.7771, pp.188–202, 2012.
[2] Y. Nakano, S. Kiyomoto, and Y. Miyake, “Evaluation of memory access pattern protection in a practical setting,” ISA, ASTL, vol.48, pp.1–6, 2014.
[3] O. Goldreich, “Towards a theory of software protection and simula- tion by oblivious RAMs,” STOC, pp.182–194, 1987.
[4] O. Goldreich and R. Ostrovsky, “Software protection and simulation on oblivious RAMs,” J. ACM, vol.43, no.3, pp.431–473, 1996.
[5] B. Chor, O. Goldreich, E. Kushilevitz, and M. Sudan, “Private infor- mation retrieval,” FOCS, pp.41–50, 1995.
[6] J.R. Lorch, J.W. Mickens, B. Parno, M. Raykova, and J. Schiffman,
“Toward practical private access to data centers via parallel ORAM,”
IACR ePrint, vol.2012, p.133, 2012.
[7] M. Ajtai, J. Koml´os, and E. Szemer´edi, “AnO(nlogn) sorting net- work,” STOC, pp.1–9, 1983.
[8] K.E. Batcher, “Sorting networks and their applications,” AFIPS Spring Joint Computing Conference, AFIPS Conference Proceed- ings, vol.32, pp.307–314, 1968.
[9] M. Ajtai, “Oblivious RAMs without cryptographic assumptions,”
STOC, pp.181–190, 2010.
[10] P. Williams and R. Sion, “Usable PIR,” NDSS, 2008.
[11] B. Pinkas and T. Reinman, “Oblivious RAM revisited,” CRYPTO, LNCS, vol.6223, pp.502–519, 2010.
[12] D. Boneh, D. Mazieres, and R.A. Popa, “Remote oblivious stor- age: Making oblivious RAM practical,” Tech. Rep. MIT-CSAIL- TR-2011-018, Massachusetts Institute of Technology, 2011.
[13] I. Damgård, S. Meldgaard, and J.B. Nielsen, “Perfectly secure obliv- ious RAM without random oracles,” TCC, LNCS, vol.6597, pp.144–
163, 2011.
[14] E. Shi, T.H.H. Chan, E. Stefanov, and M. Li, “Oblivious RAM withO((logN)3) worst-case cost,” ASIACRYPT, LNCS, vol.7073, pp.197–214, 2011.
[15] M.T. Goodrich, M. Mitzenmacher, O. Ohrimenko, and R. Tamassia,
“Privacy-preserving group data access via stateless oblivious RAM simulation,” SODA, pp.157–167, 2012.
[16] E. Kushilevitz, S. Lu, and R. Ostrovsky, “On the (in)security of hash-based oblivious RAM and a new balancing scheme,” SODA, pp.143–156, 2012.
[17] E. Stefanov and E. Shi, “ObliviStore: High performance oblivious cloud storage,” IEEE Symposium on Security and Privacy, pp.253–
267, 2013.
[18] E. Stefanov, E. Shi, and D.X. Song, “Towards practical oblivious RAM,” NDSS, 2012.
[19] P. Williams and R. Sion, “Single round access privacy on outsourced storage,” ACM Conference on Computer and Communications Se- curity, pp.293–304, 2012.
[20] E. Stefanov, M. van Dijk, E. Shi, C.W. Fletcher, L. Ren, X. Yu, and S. Devadas, “Path ORAM: An extremely simple oblivious RAM protocol,” ACM Conference on Computer and Communications Se- curity, pp.299–310, 2013.
[21] P. Williams, R. Sion, and A. Tomescu, “PrivateFS: A parallel obliv- ious file system,” ACM CCS, pp.977–988, 2012.
[22] P. Williams, R. Sion, and B. Carbunar, “Building castles out of mud:
Practical access pattern privacy and correctness on untrusted stor- age,” ACM Conference on Computer and Communications Security, pp.139–148, 2008.
[23] C. Gentry, K.A. Goldman, S. Halevi, C.S. Jutla, M. Raykova, and D.
Wichs, “Optimizing ORAM and using it efficiently for secure com- putation,” Privacy Enhancing Technologies, LNCS, vol.7981, pp.1–
18, 2013.
[24] M.T. Goodrich and M. Mitzenmacher, “Privacy-preserving access of outsourced data via oblivious RAM simulation,” ICALP (2), LNCS, vol.6756, pp.576–587, 2011.
[25] M.T. Goodrich, M. Mitzenmacher, O. Ohrimenko, and R. Tamassia,
“Oblivious RAM simulation with efficient worst-case access over- head,” CCSW, pp.95–100, 2011.
[26] S. Lu and R. Ostrovsky, “Distributed oblivious RAM for secure two- party computation,” IACR ePrint, vol.2011, p.384, 2011.
[27] X. Zhuang, T. Zhang, H.H.S. Lee, and S. Pande, “Hardware as- sisted control flow obfuscation for embedded processors,” CASES, pp.292–302, 2004.
[28] B. Chor and N. Gilboa, “Computationally private information re- trieval (Extended abstract),” STOC, pp.304–313, 1997.
[29] E. Kushilevitz and R. Ostrovsky, “Replication is NOT needed:
SINGLE database, computationally-private information retrieval,”
FOCS, pp.364–373, 1997.
[30] B. Chor, E. Kushilevitz, O. Goldreich, and M. Sudan, “Private infor- mation retrieval,” J. ACM, vol.45, no.6, pp.965–981, 1998.
[31] A. Beimel and Y. Stahl, “Robust information-theoretic private infor- mation retrieval,” J. Cryptology, vol.20, no.3, pp.295–321, 2007.
[32] S.W. Smith and D. Safford, “Practical private information retrieval with secure coprocessors.” Technical Report, IBM Research Divi- sion, 2000.
[33] S.W. Smith and D. Safford, “Practical server privacy with secure co- processors,” IBM Systems Journal, vol.40, no.3, pp.683–695, 2001.
[34] D. Asonov and J.C. Freytag, “Almost optimal private information re- trieval,” Privacy Enhancing Technologies, LNCS, vol.2482, pp.209–
223, 2002.
[35] I. Goldberg, “Improving the robustness of private information re- trieval,” IEEE Symposium on Security and Privacy, pp.131–148, 2007.
[36] M.T. Goodrich, M. Mitzenmacher, O. Ohrimenko, and R. Tamassia,
“Practical oblivious storage,” CODASPY, pp.13–24, 2012.
[37] C. Devet, I. Goldberg, and N. Heninger, “Optimally robust private information retrieval,” Proc. 21st USENIX Conference on Security Symposium, Security ’12, Berkeley, CA, USA, 2012.
[38] I. Goldberg, “Percy++project,” SourceForge, http://percy.sourceforge.net/
[39] F. Bao, R.H. Deng, and P. Feng, “An efficient and practical scheme for privacy protection in the E-commerce of digital goods,” ICISC, LNCS, vol.2015, pp.162–170, 2000.
[40] C.P. Schnorr and M. Jakobsson, “Security of signed ElGamal en- cryption,” ASIACRYPT, LNCS, vol.1976, pp.73–89, 2000.
[41] Y. Gertner, Y. Ishai, E. Kushilevitz, and T. Malkin, “Protecting data privacy in private information retrieval schemes,” STOC, pp.151–
160, 1998.
[42] R. Henry, F.G. Olumofin, and I. Goldberg, “Practical PIR for elec- tronic commerce,” ACM Conference on Computer and Communi- cations Security, pp.677–690, 2011.
[43] C.A. Melchor and P. Gaborit, “A fast private information retrieval protocol,” ISIT, pp.1848–1852, 2008.
[44] C.A. Melchor, G. Castagnos, and P. Gaborit, “Lattice-based homo- morphic encryption of vector spaces,” ISIT, pp.1858–1862, 2008.
[45] F.G. Olumofin and I. Goldberg, “Revisiting the computational prac- ticality of private information retrieval,” Financial Cryptography, LNCS, vol.7035, pp.158–172, 2012.
[46] Y. Huang and I. Goldberg, “Outsourced private information re- trieval,” WPES, pp.119–130, 2013.
[47] K. Fukushima, S. Kiyomoto, T. Tanaka, and K. Sakurai, “Analy- sis of program obfuscation schemes with variable encoding tech- nique,” IEICE Trans. Fundamentals, vol.E91-A, no.1, pp.316–329, Jan. 2008.
Yuto Nakano received B.E. and M.E in Electrical and Electronic Engineering from Kobe University, Japan in 2006 and 2008, re- spectively. He joined KDDI and has been en- gaged in the research on hash functions and stream ciphers. He is currently a researcher at the Information Security Lab. of KDDI R&D Laboratories Inc.
Shinsaku Kiyomoto received his B.E. in engineering sciences and his M.E. in Materi- als Science from Tsukuba University, Japan, in 1998 and 2000, respectively. He joined KDD (now KDDI) and has been engaged in research on stream ciphers, cryptographic protocols, and mobile security. He is currently a senior re- searcher at the Information Security Laboratory of KDDI R&D Laboratories Inc. He was a visiting researcher of the Information Security Group, Royal Holloway University of London from 2008 to 2009. He received his doctorate in engineering from Kyushu University in 2006. He received the IEICE Young Engineer Award in 2004.
He is a member of JPS.
Yutaka Miyake received the B.E. and M.E.
degrees of Electrical Engineering from Keio University, Japan, in 1988 and 1990, respec- tively. He joined KDD (now KDDI) in 1990, and has been engaged in the research on high- speed communication protocol and secure com- munication system. He received the Dr. degree in engineering from the University of Electro- Communications, Japan, in 2009. He is cur- rently a senior manager of Information Security Laboratory in KDDI R&D Laboratories Inc. He received IPSJ Convention Award in 1995 and the Meritorious Award on Radio of ARIB in 2003.
Kouichi Sakurai received his B.S. de- gree in Mathematics from Faculty of Science, Kyushu University and his M.S. degree in Ap- plied Science from the Faculty of Engineering, Kyushu University in 1986 and 1988, respec- tively. He was engaged in research and develop- ment on cryptography and information security at the Computer and Information Systems Lab- oratory at Mitsubishi Electric Corporation from 1988 to 1994. He received his Doctorate in En- gineering from the Faculty of Engineering, Kyu- shu University in 1993. From 1994, he worked for the Department of Com- puter Science of Kyushu University in the capacity of associate professor and became a full professor in 2002. His current research interests are in cryptography and information security. Dr. Sakurai is a member of the In- formation Processing Society of Japan, the Mathematical Society of Japan, ACM, IEEE and the International Association for Cryptologic Research.