Semi-Blind Speech Extraction for Robot Using Visual Information and Noise Statistics
6
0
0
全文
(2) for canceling out the signal coming from (). The update rule. W1CA(f,θ). of. is. _. _. S TATIS TICS DIFFERENCE. 1)'\ ., / . _1_1 r _ H円(J, , r \ = , T 11)めθ \)T げj, , T I'l\\ 8め))O 川T)W;正��(f,)め8 の(}) μ[_ げ_ f I一〈旬ψ(何o( Wl 臼C�" (f,. fp+ l 1 1 r. +. W;�� (J, ()), [p]. III. PERMUTATION SOLVER BASED ON SOURCE. A. Motivation and strategy. l u,f p. (3). ln the context of the pe口nutation problem in the ICA study, there exist many methods for solving permutation,. whereμis the step-size parameter, [p) is used to express the value of the pth step in iterations, and 1 is the identity. such as source-DOA-based method [6) and its combination. denotes a lime-averaging operator, MH denoles co町ugate transpose of matrix M, and cp(・) is an appropriate nonlinear v氏lor function.. often fail to solve the permutation problem in real envi. matrix. Moreover,. (・)T. Next, the estimated targel speech signal is discarded as it is not r,叫uired because we want to estimate only the nois巴 component. lnstead,assuming o u (J,T,8) as the sp巴巴ch q(J,T,θ) as. component, we construct a noise-only vector. •. )(} q(J,, T= [01 (J, T,8),. . ,OU-1 (f,T,θ),0, OU+1(J,T,θ),..,OK(J,T,θ)f. (4). •. Following this, we apply the projection back operation to remove the ambiguity of amplitude, and we have. q(J,, T = の [éÌ! (J,, T )θ ,...,(/JCj,T , θ))T WtCA(J,(})q(f, , T θ),. =. (5). with subband correlation [7). These approaches, however,. ronments because of the inherent problem that noise is sometimes diffuse and has no discriminable property on DOA. Therefore, in this paper, we introduce a new cue for 出e classificatioo of sources, i.e., source statistics diff,巴rence, instead of DOA information. We assume that the input signal X in the power spectral domain can be modeled using the gamma distribution as. x""-1 exp( -�). P(X) =. this permutation problem will be discussed in Sect. III.. postprocessing for target speech extraction. We can obtain a channelwise spectral gain function in WF using the noise. gj(f,T, (}). where gj(j,. T,)(}. estimated by ICA, as =. _. T め 12 l Xj(f,, ',,: x T θ)12 + βlê/j(J,T,め12' I j(j, , , .. tr. _•. _. _. X j C!,T,θ) WF ). , ,. r ,(\'d / r I'l '\ () Fl'\ r 'j1U_ J (J, S仰は '" T, -8)"lxj(j, , T= T, θ) F一一一一 (}) Jgj J'" • " I Xj(j,T,θ)1'. (7). F (f A θ) is the jth・channel estimation of 叫et sp巴ech. Finally, we conduct delay-and-sum (DS ) beamform lng for s 勺 , T め , 陀sult時in the叫et speech酬ma剖1 S s (J , T) giv巴n by. where s. o. W. j. ). f(α) =. I. JO. sos (J,= T). WoS(川)TIsjw円λT,θ),..., sナF)(J, T,θ))T,. ;. w DS)(μ)ニ. j. velocity.. N. (12). �. well modeled by very spiky distribution as (11) with α= 0.1 0.2, but that of diffuse noise is typically mor巴Gaussian (i.e., α'" 1) owing to the center limit theorem. Therefore, we can discriminate the sources and solve the permutation. B. Algorithm Next, we describe in full detail a method of estimating the α parameter. Here, we apply th巴 maximum likelihood (ML) approach to this estimation problem. The logarithmic likelihood function L(α,θ) of ( l l) for N-sample data is given. by. L(Iα,8'】 In. (8). ,w. T刊 μW,. 州一阿川dj sin 8 /c). (9). (10). 日 P(X ) ;. ;=1. ( α一 l ). N. Z. N. ln叶. 57. - N α叫. ( 13). =α , θ i.e., the /(Nα) L�, X;. Thus,. In the gamma distribution, we have E[x) estimated scale parameter is ê A L(α,)θ results in. where wos (J,8) is the coefficient of DS,λis the sampling frequency, dj = (j 1, . . ,J) is the position of th巴 micro. phones,. tαー1 exp( - t) dt .. The shape parameter is most important in this study be cause we want to discriminate multiple sources on the basis. jw. wos (J ,8 ) = [川Dめ(μ)ぃ. (11). problem using this di仔er巴nce in statistical property (6). is the gain in the j channel, and βis the parameter for controlling the strength of noise reduction. By applying gj(j,T,θ) to the jth-channel observed signal, we obtain. ,. that the subband power spectrum component of speech is. In this study, we apply Wiener fiItering (\\明 [4) as a. q(J,, T )θ. U'. of their statistical properties. For example, it is well known. B. Target speech extraction. ∞mponent. ". wher巴 αis the shape parameter co汀esponding to the type of sources (巴.g.,α= 1 is Gaussian and α< 1is super-Gaussian ) , θis the scale parameter of the gamma distribution, and r(α) is the gamma junction, defined as. where M+ is the Moore-Penrose generalized inverse matrix of M. AIso, we should remove the ambiguity of the source order, i.e., solve the permutation problem. The solution of. ��:. θαr(α). .. is the size of DFT, and c represents th巴 sound. L(α). N. =. I. f .. N. \. = い ) 5 剛一Nα - Nα Inl 右�X; J - N ln f(α).. 978・1-4673-0753-6パ1/$26.00 @2011 IEEE. 000239. 一137-. (1 4).
(3) To estimate the shape parameter α based on the ML criterion, we partially di仔erentiate L(α) by α, putting the result as zero to be solved in α, as. 。L(α) θα. =. 会l叫ん)- (培) N 1n. +N1n α - Nψ ( α ). ( 15) where ψ(α) is the digamma function defined as. = 一一一 . r(α) r'(α). ψ(α). ( 16). Since we unfortunate1y have no cJosed-form solution of ( 15), the Newton's method is app1ied instead. We iterative1y update the estimated shape parameter â from the given data Xj in the following manner,. âj+1 (x). =. L'(âj(x)) âj(x) 一一ーニ一一 L吋âj(x)) ー ψ(âj(x)) Cx l'j(X) - ln âj(x) :� _: (âj(x)) 一 ψ, (1/âj(x)) +. 1__". .. ,. (17). where I/I(âj(x)) is called trigamma functioll, and C is a x constant determined with the observation Xj given by C.t. =. 占t. 1n(xj) - ln. (ゆ). (18). In our method, the digamma and trigamma functions in ( 17), which cannot be exp1icit1y expressed by ana1ytic functions, can be caJcu1ated via po1ynomia1 expansions as. ψ(âj(x)) ψ'(âj(x)). =. 1n( âi (X)). ". .". 一一 一 〉 - 2âj(x) ヤ Z崎ア(X) ::::-. ー. "". 一. Bo... _.,-- ー. Bo 1 1 "" 一一 +一一一+ ) →4一,. âj(x). 判(X)ヤ &j'山(X). , ( 1 9) (20). where B" (11 =0, 1 , 2,…) are the Bernoulli numbers given by. 一l 引 。=I, B" = 一一一 〉 n+1. �. い +I)!. 一一一一一一一一 B". i ! (1I + 1 - i)!. Appearance of hands-free spoken-dialogue. robot. separation prob1em for early utterances, which is described in the next section, is ignored in this experiment.. J". 11. Fig. 1.. (21). Using (17)ー(21), we can estimate the shape parameter â for each subband component separated by ICA. We consider 出e specific component that has the smaIlest shape par溜neter as speech, and the others as noise. On the basis of this rule, we cJassify the separated components into speech or noise in every frequency subband, solving the permutation prob1em. C. Pre/imillary experimel1t for eva/uatiol1 of pennutatiol1. so/ver. To confirm the applicability of the proposed permutation solver, we conducted a pre1iminary experiment on source separation by ICA. Since our main interest here is to eva1uate the net efficacy of the proposed method, this experiment was carried out in batch (nonrea1-time) fashion; the separation matrix given by (3) is u凶ated using all the observed signa1s of severaI seconds,and is filtered with x ( f , T). Thus, the p∞r. A two-e1ement microphone a汀ay with an intere1ement spacing of 2.15 cm was installed in our hands-free spoken dia10gue robot system (see Fig. 1) [5), and the direction of the target speech is set to be normal to the array. The distance between the microphone aπay and the target speech is 1.0 m. The reverberation time (RT) of the experimenta1 room is 430 ms. AlI the signa1s used in this experiment are 16・kHz samp1ed signa1s with 16・bit accuracy. The observed signa1 consists of the target speech signa1 se1ected from six speakers recorded in this room and rea1-recorded rai1way station noise. The input SNR is set to 1 0 dB. Figure 2 shows the result of the experiment, where we compare the following four permutation solving methods:. •• • •. No permutation is solved (unpr舵essed). Source-DOA-based method [6) (DOA-based). Proposed statistica1 di仔erence-based method (pro・ posed).. Ideally processed result with sp田ch reference signal. (ideal).. We define出e noise reductiol1 rate (NRR) as a measure of the noise reduction performance, which is defined as the output SNR in dB minus the input SNR in dB [3). This result reveals that the accuracy of solving permutation by the proposed method is considerab1y superior to those of the conventiona1 methods. Although the proposed method provides a promising re sult, one big drawback is the requirement of huge compu tations. The proposed a1gorithm performs many caJcu1ations in estimating a shape parameter via the iterative Newton's method, corresponding to severa1-dozen-fold caJcu1ations compared with that of the conventiona1 DOA-based permu tation solver. This will prevent the proposed method from being applied to rea1-time processing needed in a robot dia10gue system. The solution to this prob1em is proposed in Sect. IV-C. 978・1-4673-0753-6/11/$26.00 @2011 IEEE. 000240. -138 -.
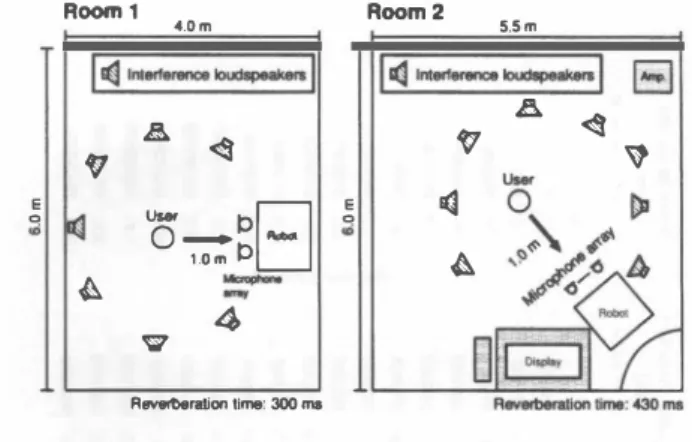
(4) Room1. et・ 唱A 『,‘ 内υ ,A 、,‘ 喧3 a匂 r3 po '' 0o E S SE E S 包 3 3 2 a a. ロunpro世話回. ロ DOA.ba.ed .ideai. .向。剖. 口. |吋M… £込. 宅F E o “'. M駒山. 電�. 5.5m. 1113 1耐閉山崎町|回. |. E弘. 匂. ぐ省. ht日. 国 �. 日. 円∞m2. 4.0m. E o •. 司. 、. 時 4込. 4. Rovor回岨i開ijme耳)0"・. Fig. 2. Resul! of preliminary experimenl for permulalion solving under d仔"use noise condilion.. IY. SEMI-BLIND SPEECH EXTRACTION W ITH VIDEO INFORMATION FOR SAVING EARLY UTTERANCE A. Motivation and strategy. Owing to the huge computational load, ICA cannot pro vide any effective separation matrix in real-time, especially for the first segment of user utterance. This causes a serious problem of poor recognition accuracy for the first word that often conveys important messages of the user, such as commands, user decision, and greetings. To improve the speech recognition accuracy for the early utterances,we introduce a rapid ICA initialization approach combining video image inforrnation given by robot eyes 佃d a prestored initial separation filter bank. If tags of the prestored ICA filters in the bank do not coincide with the cu汀ent user's DOA detected by image infom】ation, the system moves to the training phase; a new separation filter is updated by ICA and added to the filter bank wi白 the detected-DOA tag. Otherwise, if白e system can find the DOA tag that co汀esponds to the cu汀ent user's DOA, the immediate detection of the user's DOA enables ICA to choose the most appropriate prestored separation matrix for saving the user's early utterances. B. Filter length and generality It should be of great interest to most researchers if such a prestored separation filter has generality because the updated ICA filter is over台tted to the specific acoustical environment 白紙the system con合onted before. To confirm the generality of the prestored TCA filter, we conducted a preliminary experiment on ICA separation under two different acoustical environments, namely Room 1 (RT=3oo ms) and Room 2 (RT=430 ms) shown in Fig. 3 with real-recorded railway station noise (input SNR is set to 1 0 dB). In this experiment, first, ICA opt出lÌzes the separation fìlter W'CA(!,φ) for the specifìc user in DOA ofφ in Room 1 (or Room 2),and stores the filter bank with the W'CA(!,Iþ); thus, these procedures are for training. Next, in Room 2 (or Room 1), we perform extraction of the user's voice in the same DOA of Iþ using the presto児d W'CA(f,φ) as open test.. Layoul of IWO reverberanl rooms used in our 日mulalion. Fig.3.. The result is shown in Fig. 4, where we show the average of two users' DOAs, φ = 00 (norrnal to the 町ay) and 6 00 (right-hand side of the町ay). We plot two perforrnance indications, NRR and cepstral distortion (CD) , by changing the .filter si'l.e that co汀esponds to the truncation length of the original (prestored) ICA filter. The filter truncation operation is conducted as W'CA 仏 φ刈)ヰ),Jv f= D 打吋lいw叫川川川"附川,,(刈'パ( l. (22). where DFf[日.j and IDFf日ar,陀e operations of DFf and its in verse transforrn, respectively, {・}i.j is an operation of picking up the ith row and jth column entry, and w叫"川, window 仇釦mに削cωtion in which the firs鈍tmt山h entries have a nonzeroo value and the la瓜tt旬er路s smoothly c∞onver略ge on zero (t白hu凶s, m is the effective filter size), as wm(t) =. �. 1. 0 .5 - 0 .5 cos (止炉型) 0. (t = 1 ,…,m),. (t = m,…,m+ IO), (t. >. m+ 10).. (23). A very small filter size of less than 40 taps indicates白紙出e truncated filter only deals with direct-wavefront separation ignoring robot働body di仔raction and room reverberation. A moderate filter size of 40-200 taps indicates白紙the filters take into account direct-wavefront and robot-body diffractive components,組d a large filter size of more山間2∞taps indicates full consideration of direct-wavefront, robot-body di仔'ractive, and room-reverberation components. As can be S回n in由e NRR results , the truncated filte路of more than 40 taps can maintain the separation perfo口nance to some extent,創ld beyond this filter size, the NRRs創定 almost saturated. 百lÌs means白紙血e 2oo-tap truncated filter c卸 be used for any type of room acoustic condition because source separation with the direct-wavefront and robot-body diffractive component is inherent in the robot itself and not affected by the r∞m reverberation conditions. Therefore, hereafter, we sto間出e 2∞-tap truncated ICA filter while making the filter bank. C. Algorithm. The complete details of the proposed method are described below (see Fig. 5). 978・1-4673・0753-6/11/$26.00 @2011 lEEE. 000241. -139.
(5) 同 SH 。。白 E E E 園 S E E Z h 口口 h ロロ 8 E-E 唱 -EDO岨 -E・E・・5SE 凶 。。 8 凶 oo 004可 5 11 問 。白 m Co ・・ ・E E ・・ 川 as 岡 O白 H 。白 8 ・a・田園 ES -BE 口 -BE h R ロ唱 --EO岨 -的 。 H N 口守 問 '骨札 口 問 口 吋 曾a N D N O JR O O nu 唱A 司4 『3 A句 唱 【圃 a s z -S 冒色 -E 宣 告 宣 zE 。 星 E恒 冒s E. t+l. t+2. ••. F11悟rSI韓I日mpl・1. xt(f, T): iuput data at time block t. W{CA (/,8): optimized filter at time bl凹kt. Fllter SI.. [姐mple) Fig.4. Fig. 5.. Result of preliminary experiment 2. Step 1: Advance IDter tagging and c1assification (ofJ・line procωsing). In this algorithm, we quantize the user's DOA into 13 directions with 150 wise from -900 (1eft-hand side) to 90。 (right-hand side), where 00 is normal to the robot. The nearest DOA (} of the user's DOA estimated via image information is used as a tag of WICA(f,θ),which has already been iteratively optimized.. Step 2: Permutation solving and IDter storing (ofJ-line processing). We store the permulation-solved and truncated W1CA(f,θ) in the filter bank as follows. W1CA(f,θ). ‘一. TRN [P(f)W1CA(f,θ)],. (24). where TRN[.] represents the truncation operation for each entry of the matrix,described in (22),and P(f) is the permu tation matrix that sorts the row of W1CA(f,θ) in order of the shape parameter α estimated using ( 17) with the separated signal's power spectrum time sequence IOk(f,T,θ)12. P(f) is defined as. [P(ハ)kli'.i. =. =. [, otherwise 0,. (25). where k(i) ( 1,…, K) is the integer-valued function repre senting the permuted order so that â ( IOk-'(} )(f,T,(})12 ). � �. â (IOk-'(2)(f,T,(})12 ). ... . � â ( IOk-'(K,u,T,(})12 ) . (26). Thus, the signal component that has the smal1est shape parameter, which is assumed to be speech, should be placed in白e first row. Step 3: User's DOA estimation by image information (on・ line processing). A new user's DOA is estimated by image information when the robot cameras (eyes) detect the prospective user's face. Step 4: Enhancement of early utterance (on-line process ing). We load W1CA(j,(}) according to (} estimated in Step 3. Then, we apply the separation matrix to the cu町ent block segment. ". SignaJ flow of updating ICA自lter in real-time simulation.. of x(f,T). First, the noise-only vector ij(f,T,θ) defined in (5) is calculated as. = ーー. 。(f,T,(}) W iCA(j,(})diag[O, 1,1,…,I)W1CA(f,(})x(f,T), (27) where diag[O,1,…,1 ) represents a diagonal matrix in which the first row en佐Y is zero and the others釘'e unity; this acts as a removal of the sp田ch component. Final1y, by inserting (27) into (6),we obtain the resultant speech-enhanced output based on (8). Note that this step does not include any iterative operations of ICA, and consequently we can immediately output the resultant speech-enhanced signal in real-time.. Step 5: Enhancement after 2nd-block utterances (on-line processing). After 2nd・block utterances of the user, we perform ICA and speech enhancement processing as described in Sect. 11 in a blockwise batch manner (see Fig. 5), where白e first initialization of ICA is done by wi忠 (f,θ)←. W1CA(f,(}). (28). Note that we do not solve the permutation in each block to save the computations and carry out real-time processing.. Step 6: End of user utterance and filter bank update (off・line processing). When the user's uuerance ends, the current W1CA(f,(}) is overwritt巴n in 出e filter bank for preparing the next fu制民 user. Then, go back to Step 1 It is worth mentioning that the proposed algorithm can work in real-time even including a huge amount of permutation-solving calculations (17) because the calcula tions are conducted in the 0仔'-line fashion in Step 2 and we omit the on-Iine permutation solving as described in Step 5. V.. SPEECH RECOGNITION EXPERIMENT. A. Experimental conditions. We conduct a speech recognition experiment to evaluate the etfectiveness of the proposed method, where we compare the fol1owing three speech enhancement systems. Conventional BSSA initialized by 00-steered NBF with conventional DOA-based permutation solver (6) (Con. •. ventional).. 978-1-4673-0753・6/11/$26.00 @2011 IEEE. 000242. - 140.
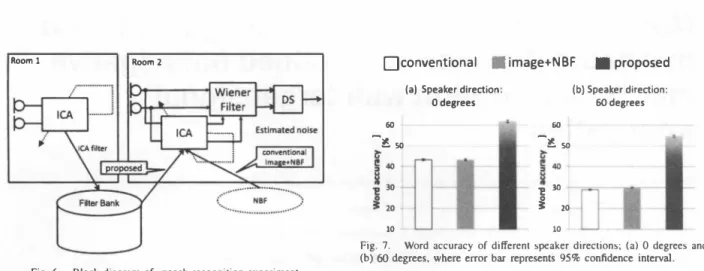
(6) Room 1. ロconventional • image+NBF. Room 2. 【. (a) Speaker direction o degrees 同. 望L盟. (b) Speaker direction: 60 degrees. ー. 60. 注目. J 10. 圃proposed. 却20 10. Fig. 7.. Word accuracy of di宵'erent speaker direclions; (a) 0 degrees and (b)ωdegrees, where eπor bar represents 95% confidence interval Fig. 6.. Block diagram of sp田ch recognilion experimenl TABLE. sentence can be considerably improved; this indicates the importance of血e recognition of the first utterance. AIso, it is shown that the speech recognition results of two conventional methods (Com仰tional and Image+NBF) are almost the same. This indicates that a simple NBF, which ignores the e仔"ect of robot-body di仔'raction, cannot provide any valid source separation even if we accurately give DOA of the target speaker, showing the efficacy of the proposed ICA filter bank with considering robot-body diffraction.. I. EXPERIMENTAl CONDITIONS FOR SPEECH REC∞NITION. VI. CONCLUSIONS. • •. BSSA initialized by user's DOA・adapted NBF via im age information with conventional DOA・based戸rmu・ tation solver [6] (Image+NBF) Proposed method (Proposed).. A two-element microphone aπay with an interelement spacing of 2.15 cm was installed in the spoken-dialogue robot system (see Fig. 1). The block diagram of the experi ment is shown in Fig. 6. In the proposed method, we assume 白紙the ICA filter bank is constructed under the condition of Room 1 shown in Fig. 3, and then speech enhancement and recognition experiments are conducted in Room 2. In both rooms, we created血e target speech signal by filtering JNAS clean speech database with the impulse responses measured in the rooms, and we added real railway-station noise signal to the speech signal with the input SNR of 10 dB. In the ICA p制, the size of the time block is 3 s, and the number of iterations is set to 1 00. The strength parameterβis optimized so that we obtain the best speech recognition performance in each of the methods. The rest of the experimental conditions is summarized in Table 1.. In this paper, first, a novel signal -statistics-based permu tation solving approach is proposed. Next, to save the user's first utterance, we introduce a new rapid ICA initialization method combining robot video information and a p陀stored initial separation filter bank. The experimental results show that the proposed approaches can markedly improve the word recognition accuracy in the real-time ICA-based noise reduction developed in the robot dialogue system. ACKNOWLEDGEMENT This work was supported by MIC SCOPE and 1ST Core Research of Evolutional Science and Technology, 1apan.. B. Results. Figure 7 shows the experimental results of speech recogni tion for two speaker directions, 00 and 600, evaluating l1:ord accuracy as an indication of speech recognition performance. From 出is figure, we can confirm that the proposed method significantly outperforms the convention必methods. In par・ ticular, although the proposed method is aimed to only save the user's early utterance, total word accuracy for the full. REFERENCES. [1J R. Prasad. el al.. "Robots lhal can hear. undersland and lalk."' Ad.'anced Robot;cs. vol.l8.pp.533--564‘2∞4. [2J P. Comon."'Independent component analysis.a new concept,'" S;gna/ p'υcessing, vo1.36,pp.287-314. 1994. [3J Y. Takahashi. H. Saruwalari.el al.."Blind spalial sublraclion aπay for noisy environment. " ' IEEE Trans. Alldio. Speれh. and wngllage Process;ng. vol.l7.nO.4. pp.65仏.{i64,2∞9 [4J P. Loizou. Spe自由Enhancelllent: Theon- and Pract;ce, CRC P ress. 2∞7. [5 J H. Saruwalari. el al.“Hands-free speech recognilion challenge for問aト world speech dialogue systems. " ' PmιICASSP, pp .37 29-3782.2009 [6J H. Saruwatari.el al.."'Blind source separalion combining independent component analy日s and beamforming:・EURASIP JOllma/ on App/ied S;gna/ Pr,山白川8・vol.2∞3.nO.II. pp.1I35-1146. 2∞3 [7J H. Sawada. el al.. " 'A robusl and precise melhod for solving lhe permulalion problem of frequency-domain blind source separalion:' IEEE Transact;ons on Speech and Alldio Pr,υcess;ng, vol.l 2. nO.5. pp.530-538,2ω4. [8J A. Lee. el al.. "Julius -An open source reallime large vocabulary recognition engine:' Pmc. Ellr. Cωif. Speech COlllllllln. Techno/.. pp.169 1-1694.2∞1.. 978-1 -4673-0753-6/1 1 /$26.00 @2011 IEEE. 000243. - 14 1.
(7)
図

関連したドキュメント
Segmentation along the time axis for fast response, nonlinear normalization for emphasizing important information with small magnitude, averaging samples of the brain waves
In order to estimate the noise spectrum quickly and accurately, a detection method for a speech-absent frame and a speech-present frame by using a voice activity detector (VAD)
Bae, “Blind grasp and manipulation of a rigid object by a pair of robot fingers with soft tips,” in Proceedings of the IEEE International Conference on Robotics and Automation
In this work we apply the theory of disconjugate or non-oscillatory three- , four-, and n-term linear recurrence relations on the real line to equivalent problems in number
T. In this paper we consider one-dimensional two-phase Stefan problems for a class of parabolic equations with nonlinear heat source terms and with nonlinear flux conditions on the
We introduce a parameter z for the well-known Wallis’ inequality, and improve results on Wallis’ inequality are proposed.. Recent results by other authors are
This paper considers a possibility of decision whether the robot hand is having a correct work or not by using the analysis of the mechanical vibration of robot that is doing
6 Scene segmentation results by automatic speech recognition (Comparison of ICA and TF-IDF). 認できた. TF-IDF を用いて DP
