大規模データベースの主要クラスタ
.
二次クラスタの探索小林メイ, 青野雅樹 (日本IBM. 東京基礎研)
〒
242
-8502
神奈川県大和市下鶴間1623
-14Exploring Major
and
Minor
Clusters
in
Massive
Databases
Mei
Kobayashi and Masaki Aono{
mei,aono}@jp.ibm.com, IBMResearch, TokyoResearch Laboratory1623-14, Shimotsuruma,Yamatoshi, Kanagawa-ken
242-8502
JapanWe present anovel search and cluster mining system based
on
vector space model-ingthat addressessome
issues that have been neglected byconventionalsystems for database analysis. Novel featuresofour
search andclusterminingengineare:
discov-ery of both major and minor clusters,accommodation of cluster overlap,automatic labelingof clusters basedon
their document contents, andadvanced visualization of search and mining results. Implementation studies using adata set withover
100,000news
articles demonstratethe effectiveness ofour
system. 1. IntroductionThe proliferation massivedatabases has createdunforeseenchallengesfor manyenterprises. Oneof these challenges is to develop tools for analyzing massive repositories of heterogeneously formatted documents, generated by many peopleand machines. Some successfulmethods for retrieving and analyzing information have been developed by the data mining $\infty \mathrm{m}\mathrm{m}\mathrm{u}\mathrm{n}\mathrm{i}\mathrm{t}\mathrm{y}^{1}$
,
however, there is significantroomfor improvement. Wepresentanovelsystemforexploring the
contentsofmassivedatabases that improves upon conventionalmining systems inseveral ways. First, most dataminingsystemsconsider numericaldata of homogeneous format and target major cluster discovery and analysis,
even
though major topicsare
often already well-known by personnelfiomon-the job experience. However, informationon
minor
clusters is usually not known, and until recently, their discovery and analysis have been neglected, although it may be justas
valuable for business andgovernment planning [8]. For example, minor clustersina
customer surveydatabasemayrepresentemerging trendsor
long-term,minorconcerns
that mayleadto customer dissatisfaction. Or minorclustersmayrepresent loyal, s0-calledgold customers
or
very badcustomers who may defaulton
aloan. Inscientific databases, minorclusters may aidinthe accurate diagnosis of diseasesor
predictionof natural disasters.Second, whereas most conventional clustering systems
are
partition-based,ours
does not Par-tition thedocumentset. We recognizethatclusteroverlapisanaturallyoccurringphenomenoninvery large databases. Moreover, preservationof overlap information is essential for analysis of database contents andpreservationof essential documents[4]; portions ofvery small clusters that have substantial overlap with other clusters might be trimmed
so
much by partitioning1vvut.kdnuggeta.$eam$
数理解析研究所講究録 1320 巻 2003 年 250-260
algorithms that thetiny fraction ofthecluster that remains maybe mistaken for noise and dis-carded. Finally, very few mining systems have anadvanced graphical user interface (GUI) and
system to aidselectionof good coordinate
axes
and angles in 3-D spacefor visualizing results.In this paper
we
present anovel cluster mining system with an advanced GUI to aid in the understanding of contents of massive databases. Thesystemfindsandautomaticaly labels both major and minor clusters. The remainder of this paper is organizedas follows.
In the next sectionwe
review work related toours.
The third section is adescription ofthe maincomponents of
our
system. Results from implementation studies using avery large set ofover
100,000
news
articles ffom theTREC benchmark $\mathrm{s}\mathrm{e}\mathrm{t}^{2}$are
given in the penultimatesection. We conclude withasummary of findings and discuss possible directions forfuture research.
2. Related Works
Vector spacemodeling (VSM) ofdatabaseshasbecomeastandardtoolinsearch and
cluster-ingsystemssince itsintroductionbySalton
over
three decadesago $[2],[9]$.
One of the advantagesofthemethodisitenablesrelevance ranking of documentsofheterogeneous formatwith respect to
user
input queriesas
longas
theattributesare
well-definedcharacteristicsofthe documents. In Boolean vector modelseach coordinate of the vector is$\mathrm{n}\mathrm{a}\mathrm{u}\mathrm{g}\mathrm{h}\dot{\mathrm{t}}$(when the correspondingat-tribute isabsent)
or
unity (whenthe correspondingattribute ispresent). Inour
implementation studieswe
used afairlycommon
typeof$tern$frequency inverse document frequency weighting(tf-idf) to take into account the fiequency of their appearance in each document
as
wellas
inthe document set as awhole. The weight of the $\mathrm{i}$-th term in the $j$-th document, denoted by
weight(i,$j$) is defined by:
$\mathrm{w}\mathrm{e}\mathrm{i}\mathrm{g}\mathrm{h}\mathrm{t}(:,j)=\{$
$(1+tf_{,j})\log_{2}(N/dfj)$, if $tf_{\dot{|}i}\geq 1$ ,
0, if $tf_{\dot{1}_{1}j}=0$
,
where $tf_{\dot{|}i}$ is defined
as
the number ofoccurrences
of the $\mathrm{i}$-th term within the $j$-th document$dj$
,
and $dfi$ isthe number of documentsinwhich the termappears. Each queryis modeledas a
vector using the
same
attributespaceas
the documents. The relevancy ranking ofadocument with respect to aquery dependson
its “distance” to the queryvector. Inour
experimentswe
use
thecosineofthe angle defined by the query and document vectorsas
thedistancemetric. Many databasesare
so massivethat the similarity ranking methoddescribed aboverequires too many computations and comparisons for real-time $\mathrm{o}\mathrm{u}\mathrm{t}\mathrm{p}\mathrm{u}\mathrm{t}^{3}$.
One approach tosolving thisproblemis to reduce the dimensionofmathematical modelsbyprojecting intoasubspaceof$\mathrm{s}\mathrm{u}\mathrm{f}rightarrow$
ficientlysmall dimension to enable fastresponsetimes, but large enoughto retain characteristics for distinguishing contents of individual documents. Two algorithms for carrying out dimen-sionalreduction
are:
latent semantic inde xing (LSI) [3],andavariation ofprincipal component analysis (PCA), whichwe
refer to hereafteras
covariance matrix analysisor
$COV[7]$.
$3\mathrm{U}.\mathrm{S}$
.
NationalInstitute ofStan&r&&Ibchnolog Text REtrievalCompetition: $h\mathrm{W}//tr\mathrm{e}e$.niat.gov Scalability of relevancy ranking methods to massive databases is aserious concern $u$ users consistentlyselect the most important feature of IR engines to be fast, real-time rmpom to their queries in the
an-nual Graphics, Visualzation, and Usability Center of Georgia Institute of Technology’s Web users’ survey:
$h\# p//www.gv\mathrm{u}$.gaetch.$edu/us$er-surveys.
Let$A$be the M-b y-N
document-attribute
matrixrepresenting adatabase with$M$documentsmodeled by $N$ attributes, withentry$a(i,j)$ representing the importance of the $i$-th term inthe
$j$-th document. The main idea inLSIis to reduce the dimension of the IR problem to$k$
,
where$k\ll M,N$, byprojecting the probleminto the space spannedby the
rows
ofthe closestrank-fcmatrixto$A$ inthe Probenius
norm.
Projection is performed by computing the largest severalhundredsingular values andtheir corresponding left singularvector of$A$
, so
LSI isnot scalableto massive databases. The scalability issue is resolved by the
COV
algorithm, whichprojects theprobleminto the subspace spanned by the$k$ largest principal componentsof thesymmetric,positive semi-definiteattribute attributecovariance matrix $C$
:
$C \equiv\frac{1}{M}\sum_{\dot{|}=1}^{M}d_{i}d_{\dot{1}}^{T}$$-\overline{d}\overline{d}^{T}$
,
(1)where$d\iota$ represents the$i$-thdocument vector and$\overline{d}$
is the component-wise
average
over
the set of all document vectorsAsecond approach for tackling the scalability issue with search systems is to identify sets ofdocuments that
cover
similar topics, knownas
clusters,so
theycan
be retrieved together to reduce the query response time. Cluster analysiscan
also be used to understand topics addressed by documents in massive databases. Implementation studies show that LSI andCOV
can
successfully find majordocument clusters [5]. However, both algorithmsare
notas
successful at finding smaller, minor document clusters, because major clusters dominate the
process.
Duringthedimensional
reduction step inLSI and COV, documents in minorclustersare
oftenmistaken fornoiseandare
discarded.Recently, two algorithms for identifying (possibly overlapping) multiple major and minor document clusters
were
reported [5]. The first, which is basedon
LSI,can
only be applied to small databases. The second, which is basedon
COV, is scalable to large databases. The ideainboth algorithms is to prevent major themes from dominating basisvector selection (for subspaceprojection) by introducing weighting. The weighting (or negative bias) decreases the relative importance ofattributes represented by subspace basis vectors that have already been computed. The weighting is dynamically controlled toprevent deletion of informationon
major clusters. Bothalgorithmsare
refinementsof asimplerone
byAndo [1] proposed foravery small set of683 TREC documents.LSI-rescale (minor clustermining based on $\mathrm{L}\mathrm{S}\mathrm{I}$ and
re-scaling)
for $(i=1;i\leq k;\dot{\iota}++)\{$
$t_{\mathrm{m}\mathrm{x}}=\mathrm{w}\mathrm{a}\mathrm{x}(|r_{1}|, |r_{2}|, ..., |r_{M}| )$;
$q=\mathrm{f}\mathrm{u}\mathrm{n}\mathrm{c}$ $(t_{\mathrm{m}\mathrm{x}})$ ;
$R_{\theta}=[|r_{1}|^{q}r_{1}, |r_{2}|^{q}r_{2}, ..., |r_{M}|^{q}r_{M}]^{T}$ ;
SVD $(R_{s})$ ; (thesingularvaluedecomposition)
$y_{\dot{1}}$ $=\mathrm{t}\mathrm{h}\mathrm{e}$first
row
vector of$V^{T}$:
$b_{:}=\mathrm{M}\mathrm{G}\mathrm{S}$ $(\theta_{i})$ ; (modified Gram-Schmidt)
$R=R-Rb_{j}ffl_{}$ ; (residualmatrix
The inputparametersfor these algorithms
are
the document-attribute matrix$A$, the re-scalingfactor $q$ (usedfor weighting), andthe dimension $k$to which the problem willbe reduced. The
residual matricesare denoted by $R$and Rs. Initially, $R$is set to be$A$
.
After each iterativestepthe residual vectors
are
updatedto take into account the most recently computed basis vector$b_{i}$
.
After the $k$-th basis vector is computed, each document vector$d_{j}$ in the original problemis
mapped to its counterpart $\hat{d}_{j}$ in the $k$-dimensional subspace: $\hat{d}_{j}=$ $[b_{1}, b_{2}, ..., b_{k}]^{T}d_{j}$
.
Thequeryvector is mapped to the $k$-dimensional subspacebefore relevance rankingisperformed.
The LSI-rescalealgorithmis based
on
the ideathat $\mathrm{r}\mathrm{e}$-scaling document vectors afteroom-putation of each basisvector
can
beuseful, but the weighting factorshould be$\mathrm{r}\mathrm{e}$-evaluatedaftereach iterativestep to take into account the length of the residual vectors to prevent decimation from over-reduction. Morespecifically, inthe first step of the iteration, we compute the
maxi-mum
length of the residual vectors anduse
it to define the scaling factor$q$that appears in thesecond step. $q=\{$ $t_{\max}^{-1}$ if $t_{\mathrm{m}\mathrm{x}}>1$ $1+t_{\max}$ if $t_{\max}\approx 1$ $10^{\mathrm{h}\overline{\mathrm{n}}^{2}\mathrm{m}}$ if $t_{\max}<1$
The second algorithm,COV-rescale, for minorclusteridentification isamodificationofCOV, analogous to LSI-rescaleandLSI.In COV-rescale, theresidualof thecovariance matrix(defined
by equation 1) is computed. Our implementation studies indicate that COV-rescale is better than LSI, COV, andLSI-rescaleatidentifyinglarge and multipleminorclusters. InSection5,
we
introduce selectivescaling, afurther improvement uponthe weighting processintheLSI-rescaleandCOV-rescale algorithms.
COV-rescale (minorclustermining based
on
re-scaling&COV)for$(: =1;i\leq k; : ++)\{$
$t_{\max}= \max(|r_{1}|, |r_{2}|, ..., |r_{M}|)$ ;
$q=\mathrm{f}\mathrm{u}\mathrm{n}\mathrm{c}$ $(t_{\max})$ ;
$R_{\theta}=[|r_{1}|^{q}r_{1}, |r_{2}|^{q}r_{2}, ..., |r_{M}|^{q}r_{M}]^{T}$ ;
$\mathrm{C}=\mathrm{C}\mathrm{O}\mathrm{V}$ $(R_{\epsilon})$ ; (covariance matrix)
SVD (C) ;(singular valuedecomposition)
$\mathrm{y}_{\dot{1}}$ $=\mathrm{t}\mathrm{h}\mathrm{e}$ first
row
vector of$V^{T}$ ;
$b_{j}=\mathrm{M}\mathrm{G}\mathrm{S}$ $(d_{\dot{1}})$ ; (modified Gram-Schmidt)
$R=R-Rb_{*}.b_{\dot{1}}^{T}$ ; (residual matrix)
$\}$
3. Our Mining System
Our prototype system consists ofsearch and clusteringengines based
on
VSM, PCA, andrandom sampling. Since it is
uses
VSM, withthe exception ofkeyword labeling, its search and clusteringenginescan
be applied toheterogeneous documentsets (e.g., multilngual text,image audio,video),as
longas
thecharacteristics forthe attributesare
welldefined. Notablefeatures includeits abilitytomineand automaticalylabelboth majorandminor clusters and to displaglobal and localviews ofthe resultsfrom cluster mining. We introduce several
new
technologiesthat
we
have developedsinceour
earlierreporton amore
primitiveversionofourcurrent system [5]; these include: arefinement of the clusteridentificationalgorithms to facilitatemore
efficient miningof small clusters; introduction of automatic cluster labeling; randomsampling ofdocu-ments to increase scalability of clustermining; and addition of
an
advanced, user-friendly GUI.TheGUIfeatures: charts of retrieved documents and theirrelevancyrankings;multidimensional slicesof attributespace, including asystemtorecommend slice angles based
on
theuser’s input queryterms;an
interface for browsing the collection of all retrievedclusters;options forselecting asubsetofthecollectionand displaying only thoseclusters and topics coveredbydocuments in those clusters; and keyword labels ofretrievedclusters and titles of documents in clusters.$3\mathrm{a}$
.
Selective Scaling and Random Sampling for Basis Vector ComputationOur system
uses
the basic COV algorithm to mine major clusters. COV-rescalewas
de-veloped to
overcome
difficulties with mining minor clusters using COV [5]. In this subsectionweintroduce selective scaling (SS),
amore
computationalyefficient minor cluster miningalgorithm. Like COV-rescale, COV-SS allows
users
to skipover
iterations that find major clusters and jump toiterations to find minor clusters. However, COV-rescale requires too many com-putations during the $\mathrm{r}\triangleright$-scalingstep to be practical for massive databases. Selective re-scalingreducescomputationalcostsby testing whether$\mathrm{r}\mathrm{e}$-scalingis necessary after eachstep and
Per-formingthe procedure only whennecessary. Although the savingsismeasurable,it isnot enough toenable mining frommassivedatabases,so
we
combine COV-SS with random sampling toin-crease
itsscalabilitybyseveralorders of magnitude. Tosummarize,our
systemCOV is usedtofind major clusters then
COV-SS
isusedto findminorclusters for largedatabases, andCOV-SS with random sampling formassive databases.When random sampling of documents is used,
concerns
about the lkelihood of selecting unrepresentativesamplesare
often raised in anegative context. Thisconcern
is justified forour
algorithm for extremely skewed, unrepresentative samples, suchas
sampling fromonlyone or
justafewclusters
or
samplingonlynoise. However, drawingaseries ofslightly unrepresentativesamplesisthemostlikelyoutcomeofrandom sampling, and this liesatthe heartofthe
success
ofour
algorithm. Analysisof slightly unrepresentativesamplestendstolead to better identification resultssincesome
minorclusters willappear to be larger than their actualsize (when theyare
over-representedinthesample). Repetitionofthesamplingprocessincreasesthechance that all minorclusters will be over-represented, and consequently identified, at leastonce.
This proposed algorithm belongs to clam of randomized algorithms which output many ofthe clusters with appropriatelabels most ofthe time, however, the probability ofarriving atan
incompleteset of clustersor
misclassified (eitheras
minor, mediumor
major)or
mislabeled (keywordlabelsare
misleading)existsregardless of thenumberand ffequency of samples
are
drawn sinceaseriesofunrepresentative samples might be drawnfiom the large pool of data
The input parameters for$\mathrm{C}\mathrm{O}\mathrm{V}rightarrow \mathrm{S}\mathrm{S}$
are
denotedas
follows. Aand$k$axe
definedas
above,$\rho$isthresholdparameter,and$\mu$isthe scalingoff-set. Initially, theresidual matrix
$\mathrm{R}$is set tobe A.
$R$does not be kept in the main memory; it suffices to keep just the the $\mathrm{N}$
-dimensional
residualvector$\mathrm{r}_{i}$ during each oftheM loops. The outputisthe set of basisvectors $\{\mathrm{b}_{i}$: i $=1,$2,
\ldots ,
k}
for the $k$-dimensionalsubspace. M is eitherthe total number ofdocuments in the databaseor
thenumber of randomly sampled documents from avery large database. COV-SS $(\mathrm{A},k, \rho,\mu, \mathrm{b})$
for (int $h=1$
,
$h\leq k$,
$h++$) $\{$if(! first) for (int $i=1$, $i\leq M$,$i++$) $\{$
$t=|\mathrm{r}_{j}|$; (length ofdocument vector)
if$(||\mathrm{P}[\mathrm{i}]||>\rho)$
{(dot
productgreaterthanthreshold)$w$ $=(1-||\mathrm{P}[\mathrm{i}]||)^{(t+\mu\}}$ ; (computescalingfactor)
$\mathrm{r}_{i}=\mathrm{r}_{j}w$ ; (selective scaling)
continue;
$\}$
$\}$
$\mathrm{C}=(1/\mathrm{A}\mathrm{f})\sum_{i=1}^{M}\mathrm{r}_{\dot{2}}\mathrm{r}_{}^{T}-\overline{\mathrm{r}}\overline{\mathrm{r}}^{T}$; (compute comianoematrix)
$\mathrm{b}_{h}$ $=$ PowerMethod(C) ; (compute$\lambda_{\max}$ anditseigenvector)
$\mathrm{b}_{h}$ $=$ $\mathrm{M}\mathrm{G}\mathrm{S}(\mathrm{b}_{h})$; (Modified Gram-Schmidt)
for (int $:=1$
,
$i\leq M$, $:++$) $\{$ $\mathrm{Q}[\mathrm{i}]=\mathrm{r}_{i}\cdot$$\mathrm{b}_{h}$ ; $\mathrm{P}[\mathrm{i}]=||\mathrm{r}_{\dot{1}}||^{2}$ ;$\mathrm{P}[\mathrm{i}]=\mathrm{Q}[\mathrm{i}]/\sqrt{\mathrm{P}[\mathrm{i}]}$; (storedot product $=\mathrm{s}\mathrm{i}\mathrm{m}\mathrm{i}\mathrm{l}\mathrm{a}\mathrm{r}\mathrm{i}\mathrm{t}\mathrm{y}$measure)
$\}$
for (int $:=1$, $:\leq \mathrm{A}\mathrm{f}$, $:++$) ; $\mathrm{r}_{*}$. $=\mathrm{r}:- \mathrm{Q}[\mathrm{i}]\mathrm{b}_{h}$ ; (residual matrix)
if(first) ffist $=\mathrm{f}\mathrm{a}\mathrm{l}\mathrm{s}\mathrm{e}$ ;
$\}$
Here: $\mathrm{P}$and$\mathrm{Q}$
ae
$M$-dimensional vectors; $\mathrm{R}$istheresidual matrix (whichexists
intheory, butisnot allocated, inpractice); $\mathrm{r}_{i}$ is the$i$-th document vector of
$\mathrm{R}$ (an $N$-dimensionalvector); $\overline{\mathrm{r}}$
isthe component-wise average ofthe set ofall residualvectors $\mathrm{r}$
,
i.e.,$\overline{\mathrm{r}}=(1/M)\sum_{\dot{|}=1}^{M}\overline{\mathrm{r}}$; $\mathrm{C}$ is
theN-by-N square covariancematrix; $w$and$t$ aredouble-precision floatingpoint numbers; and
first
isaboolean expressionequivalent to true.COV-SS
selectively scalesdocument (residual) vectors according to the most recently com-puted similaritymeasure
$\mathrm{P}[\mathrm{i}]$ (i.e.,thedot product oftheprevious basisvector and the documentvector). The user-specifiedthreshold and ofbt parameters control the number ofminorclusters
that will be associated with each basis vector. Asmall threshold and large offiet value tend to lead to basis vectors associated with alarge number ofminor clusters. Conversely, alarge thresholdandasmall oflit value tend to lead tobasisvectors with fewminor clusters.
The computationalwork associatedwith the COV-based$\mathrm{r}\mathrm{e}$-scalingalgorithms(COV-rescale
and COV-SS)is significantly greater than thebasicCOValgorithm. $\mathrm{R}\triangleright$-scalngiscomputational
ally expensive for large databases. COVhas
no
rescaling costs,butituses
amoderatelyexpensive eigenvalueeigenvector solver for large,symmetric positivesemi-definite matrices. COV-rescale andCOV-SSuse
theaccurate and inexpensivepower method to find the largest eigenvalue and its corresponding eigenvector after each round of (possible) $\mathrm{r}\mathrm{e}$-scalingof residual vectors. Ananalogous selectivescaling algorithm for LSI (denoted by LSI-SS)
can
be constructedstraight-forwardly[6]. The computational trade offs
are
similarforLSIwithandwithout$\mathrm{r}\mathrm{e}$scaling LSIrequires
no
$\mathrm{r}\mathrm{e}$-scaling of residual vectors, however, amoderately expensive solver (suchas
theLanczos algorithm) must be used to determine left singular vector-value pairs ofavery large,
sparsedocument-attribute matrix. LikeitscounterpartCOV-basedalgorithm, LSI-SS
uses
mostof its computational
resources
to $\mathrm{r}\mathrm{e}$-scale someresidual vectors after finding eachnew
singularvalu -vector pair, andit
can
partiallyoff-settheadditionalcost by using thepowermethod. LSI cannot beappliedtomassivedatabases withoutspecializedhardware since itrequires storage ofall
non-zero
entriesofdocument vectors. LSI-SS iseven
less scalable, because thesystem mustcopewith adense matrix with the
same
dimensionas
the originaldocument-attribute
matrix after only afew steps; the originaldocument-attribute
matrix is typically only 0.2% to 0.3% dense.$3\mathrm{b}$
.
Cluster Mining: Findingand Labeling ClustersOursystem
uses
informationfrom basisvector computationstofindand labelclustersusingan
embodiment of the Label Algorithm given below. The input consists of: basis vector $\mathrm{b}_{\dot{1}}$output by
COV or
COV-SS; the number ofcluster labels forextrinsic andintrinsic keywords(defined below),$\cdot$
thresholdforseparatingclusters; and keyworddataextracted from the original document data. WeimplementedtheLabel Algorithm
as
two separate twosubprogram
:afterkeyword generationand cluster merging andlabeling.
The cluster keyword generation program computes the similarity
measure
between each basis vectorandallthe document vectors in the original document-keywordmatrix. It produces extrinsicandintrinsickeywords if the similaritymeasure
between abasis vector anddocument vector is greater than agiventhreshold $\delta$.
Extrinsic keywordsare
the top$p(e)$ keywords that
contribute towards making the similarity
measure
between abasis vector and the document vectorgreaterthan the threshold6.
Intrinsickeywordsare
the top$p(\dot{\mathrm{s}})$ keywordsthatcorrespondto the largest$p(i)$ TF-IDF weights of the originaldocument vector. Note that, unlikek-means
and k-menoid clustering,
our
clustering method is not partition-based. In other words,we
allow adocument vector to be classified intomore
thanone
clusteras
longas
the extrinsic keywords of the document vector for two basis vectors haveno
keywords incommon.
Since database contents may be minedffom differentuser
perspectives allowing clusters to overlapis essential. Furthermore, informationonoverlapsbetween clusterscan
yieldvaluableinformationon
relationshipsbetween clusters and topics inthedocuments.Label Algorithm: Cluster detectionand labeling Input: $\{\mathrm{b}_{j} : i=1,2, \ldots,k\}$ basis vectors
output: $\{s:i:j=1,2, \ldots,qj\}$clusters associated with$\mathrm{b}_{t}$
,
where:
$s_{*\dot{o}}.=$ $\{$(cluster label)(cluster type)(document
$\mathrm{I}\mathrm{D}1\mathrm{i}\mathrm{s}\mathrm{t}\rangle\}_{i\mathrm{j}}$,
$q=\mathrm{n}\mathrm{u}\mathrm{m}\mathrm{b}\mathrm{e}\mathrm{r}$ofclusters associatedwith $\mathrm{b}_{\dot{1}}$
,
{cluster label}
$=\mathrm{k}\mathrm{e}\mathrm{y}\mathrm{w}\mathrm{o}\mathrm{r}\mathrm{d}$ set$p(|.)$Up(e),\langle cluster union
}
$=major$, minoror
noise, and(document IDlist
}
$=\mathrm{l}\mathrm{i}\mathrm{s}\mathrm{t}$ofIDs for documents in the cluster.4. Cluster Analysis Studies
We conducted numerical experiments with LSI, COV, COV-rescale and Cov-SS using a Reuters and LA Times TREC
news
databases with 21,578 and 127,742 articles, respectively. Inour
experiments, theLSIandCOV algorithmsfound major clusters, but they usualy failed tofind allminor clusters. Thealgorithms deleted information insome
minorclusters, because major clusters and their large sub clusters dominated the subjects thatwere
preserved during dimensional reduction. For mediumsizedatabases,major clusters should be mined using basic COVandminor clusters using COV with selective re-scaling.Rble 1: $\mathrm{C}\mathrm{o}\mathrm{m}\mathrm{p}\mathrm{a}\mathrm{r}\dot{\mathrm{u}}$onofLSI- and COV-based cluster analysis algorithms:
scalabilties,bottlenedcs, abilityto identity majorandminorclusters.
for clusters found: $++++=\mathrm{m}\mathrm{o}\mathrm{s}\mathrm{t}$, $+++=\mathrm{m}\mathrm{a}\mathrm{n}\mathrm{y}$ , $++=\mathrm{s}\mathrm{o}\mathrm{m}\mathrm{e}$, $+=\mathrm{f}\mathrm{e}\mathrm{w}$
Major cluster identificationresults from
LSI
andCOV
are
usuallyidentical, however, COV usuallyrequires 20%-30% feweriterations
to findmajorclusters
because itcan
find clusters in boththenegative andpositive directionsalong each basis vectorsincetheoriginis shiftedduring dimensional reduction. The shift parameter isthe second terminthe LHSofequation (1). LSIcan
only find clusters either in the positive directionor
in the negative direction of each basis vector, but notboth. For massive databases, major clusters should be mined using basicCOV,
followed by COV withselective scaling and samplingto find minorclusters. Selective gcalng ispreferable to (complete) $\mathrm{r}\mathrm{e}$-scalingsincetheresults frombothshould be similar, butselectivescalingis
more
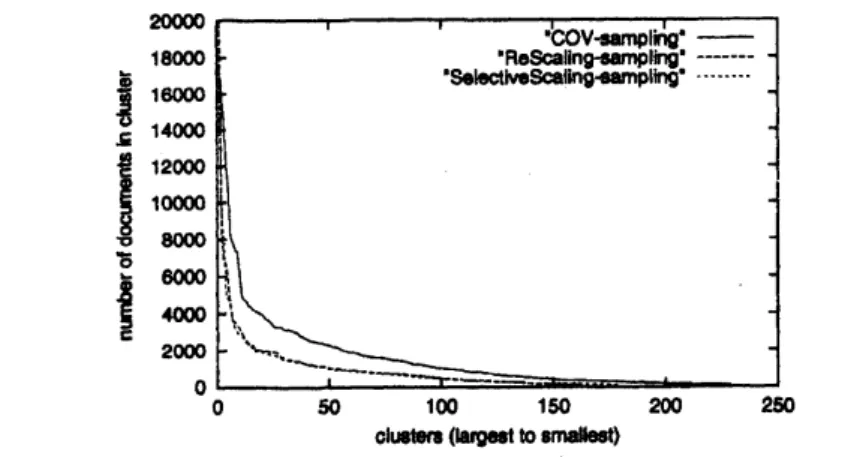
computationally efficient.Figures 1and 2and showresultsfrom
our
clusteridentificationexperiments with basicCOV and itsvariationsand the LA Times database. 2000 documentswere
sampledeach time during$\overline{\frac{\pi\Phi 3}{\mathrm{o}}}$
$.\subseteq$
B\S
$\ovalbox{\tt\small REJECT}\underline{5\xi\in}$
Figure 1: Graph
of
size and number clustersidentified
by $S$mining methods: $COV$,
$COV$usingsampling, and $COV$using sampling $\theta$ selectivescaling.
$\overline{\Xi\not\in\ovalbox{\tt\small REJECT} \mathrm{o}}$
$\frac{\mathrm{w}}{\xi\circ}\epsilon$
.
Figure 2: Graph
of
size and numberof
cluste$rs$identified
by $S$ mining methods: $COV$usingsampling, garnpling&complete $\mathrm{r}e$-scaling, and sampling
&selective
scaling.atotal of 3random samplings. Identified clusters
are
sorted according to size to determine algorithms thatare
effective. The results show that both $\mathrm{r}\mathrm{e}$-scaling and sampling skipover
major clusters and
more
quickly discoverminor
clusters. Figure 2confirms that results from complete and selective scaling are similarso
that themore
computationa lly efficient selective scaling should be used in practice. Table 1summarizes the strengths and limitations of the algorithms.Figure 3shows
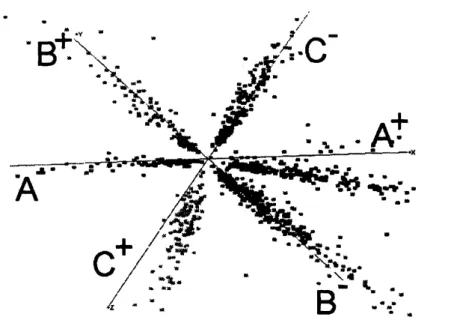
ascreen
image fromour
system. The coordinateaxes
for the subspaceare
the first three basis vectors output by the COV algorithm. The 3major clusters $\mathrm{A}$, $\mathrm{B}$and $\mathrm{C}$ shown
are
comprisedof articles about{Bush,
US, Soviet,Iraq},
{team,
coach, league,inning}, and{police, digest, county, officer}, respectively. A$\mathrm{t}\mathrm{r}\mathrm{a}\mathrm{c}\mathrm{e}$ofminorcluster$\mathrm{D}$
on
{Zurich,
Swiss, London,
Switzerland}
can
beseen
in the background. This minor clustercan
beseen
more
clearly whenother coordinateaxes are
used for visualization and display. Thisexample shows that carefulanalysisisneeded beforedeciding whetherafaint cloudof points is noiseor
Figure3: Identification, labeling, and display
of
major clusters in theLA Times database.part ofacluster. Examples ofminor clusters identified by
our
systemare
shown in Figure 4, where the basis vectorsare
58, 63 and 104. Note that two clusters may lie alongacoordinate axis-one
each inthe positive and negative directions. The clustersare
comprised of articleson
{abrtion,
anti-abortion, clinic,Roe},
{lottery, jackpot, California,ticket},
{A
$IDS$, disease,virus, patientt, {gang, school, youth,
murder},
{Cypress, Santiago, team,tournament},
and {jazz, pianist, festival, saxophonist}, respectively. Aplus or minus sign is used to mark thedirection in which clusters lie.
5. Conclusions and Future Work
We mention anumber of interesting questions and and
open
problems that have arisen in thecourse
of developingour
system. Theyinclude:.
Howcan
we determine the optimal reduced dimension $k$ (the $\epsilon 0$-called“intrinsicdimen-sion”)
of
the attribute space $q$$\bullet$ Hoev
can we
determine whethera
massive database issuitablefor
randomsampling 9 Canwe
developsimple tests to determine whether there isan
abundance of witnessesor
if the databaseconsistsentirely ofnoiseor
documentson
completelyunrelatedtopics ?$\bullet$ How
can one
devisea
reliablemeans
for
estimating the optimal sampling sizefor
a
given database $p$Factorsto consider
are
the cluster structureof the database (the number and sizesof theclusters andthe amount ofnoise) and the trade off between samplesizes and thenumber of samples. Arethereany advantages tobe gained from dynamically changingthe samplesizesbasedon clusters that have already been identified?
.
What isa
good stopping criterionfor
sampling 9 When is it appropriate forauser
todecide that it is likely that mostof the major
or
minorclustershave beenfound?Figure 4: Identification, labeling, and display
of
minor clusters in theLATimes database..
Howcan
the $GUI$effectively mapidentified
clusters and their inter-relationships(subclus-ters
of
larger clusters, cluster overlap, etc.) $p$Although many open issues and possibilities for improvements remain,
our
prototype system demonstrates that the COV algorithms with selective scalng and random samplingcan
be effective for exploring contents of very largedatabases.Acknowledgements: Theauthors wouldliketothank E. Brown for providing
access
toTREC dataand M. Houle, H. Samukawa andK. Takedafor helpfulconversations.[1] R. Ando,Latent semantic space,Proc.
of
$ACM$SIGIR, Athens, Greece, 213-223, July2000.[2] M. Berry,
S.
$\mathrm{D}\mathrm{u}\mathrm{m}\mathrm{a}\mathrm{i}\mathrm{s}_{f}$ G. O’Brien, Usinglinear algebrafor intelligent informationretrieval,SIAMReview, 37(4), 571-595, Dec. 1995.
[3] S. Deerwester et al., Indexing by latent semanticanalysis, Journal
of
the American Societyfor Information
Science, 41(6), 391-407, 1990.[4] M. Houle, private communication, June2002, (manuscript submittedforpublication).
[5] M. Kobayashi, M. Aono, Major and outlier cluster analysis using dynamic re-scaling of
documentvectors, Proc.
of
SIAMText Mining Workshop, Arlington, VA, 103-113, 2002. [6] M. Kobayashi, M. Aono, Major and minor cluster mining using selective $\mathrm{r}\mathrm{e}$-scaling andrandomsampling, $IBM$
Research
Report,$\mathrm{f}\mathrm{f}\Gamma$-0491, July 1, 2002, declassifiedNov. 12, 2002.[7] M. Kobayashi, L. Malassis, H. Samukawa,
Retrieval
and ranking of documents froma
database, patent, filed June
2000
in Japan, March 14,2002
in$\mathrm{U}.\mathrm{S}.$.
[8] Sakano,K.Yamada,Horrorstory: the
curse
ofdimensionality,Information
ProcessingSocietyof
Japan (IPSJ) Magazine, 43(5), 562-567, May2002 (in Japanese).[9] G. Salton (ed.), The SmartRetrieval System, Prentice-Hall, Englewood C16,$\mathrm{N}\mathrm{J}$,