Musical-noise-free speech enhancement based on iterative Wiener filtering
6
0
0
全文
(2) 自Itering, are recursively applied to the noise signal: (1) The average power spectrum of the input noise is estimated. (11) We apply weak Wiener創tering to the input signal using the estimated noise prototyp巴. (ill) We then retum to step (1) and substitute the resultant output (partially noise reduced signal) for the input signal. C. Modeling of input signal. In this paper, we assume that the input signal x in the power spectral domain is modeled using the gamrna distribution as. P (x). =. zα-lexp( -x/(J) f(α)θ白. (4). where x三0,α> 0, and (J> O. Here, αis the shape parameter, (J is the scale parameter, and f(α) is the gamma function, defined as. 町←100 t. "'-l州の. (5). D. Mathematical metric of musical noise generation and amount of noise reductiol1 via higher-order statistics for. 11011-. f(b,α) and γ(b,α ) are the upper and lower incomplete gamma functions defined as 町b,←f門xp州t, γ(b,←. f. fW叩t,. (11) (12 ). respectively. From (7), (9), and (10), the kurtosis after Wiener filtering c佃 be expressed as. kurt(α,ß,TJ)=M(α,ß,η,4)/ルt2 (α,ß,η,2). (13). Using (6) and (13), we also express the kurtosis ratio as. M(α,ß,η,4)/M2(α,ß,η,2) kurtosis ratio= M(α,O,O,4)/M2(α,0,0,2) .. (14). AIso, as a measure of noise reduction performance, the noise reduction rate (NRR), the output SNR minus the input SNR in dB, can be given in terms of a Ist-order moment as [7] NRR =. 1010 g1o. U. α M(α,ß,η, 1). (15). iterative Wiener filtering. E. Analysis of behavior of iterative Wiener filtering. In this study, we apply the kurtosis ratio to a noise-only tlmeてfrequel1cy period of the subject signal for the assessment of musical noise [8], [9]. Note that the kurtosis ratio recently b巴comes to be us巴d in 0切ective evaluation of musical noise generation because 出ere is a good agreement in human perception on the amount of musical noise; which has been repo目.ed in many studies [10], [11], [12 ], [13], [14]. This meas町.e is defined as. In this subsection, we formulate the amount of musical noise generated in the iterative Wiener filtering method using the analytical results obtained in Sect. 11・D. Here w巴 conduct a recursively applied analysis of kurtosis in 出e following manner, where the subscript i repres巴nts the value in 出e ith IteratlOn:. kurtosis ratio= ku内roc/ kurtorg. ,. (6). where kurtproc is the kurtosis of the processed signal and kurtorg is the kurtosis of the observed signal. Kurtosis is defined as kl川 = μ4 / μ23. (7). where μm is the mth-order moment, given by. μ = 100 xmP(x m. (8 ). and P(x) is the probability density function (p.d.f.) of the random variable X. A kurtosis ratio of unity co汀巴sponds to no musical noise. This measure increases as the amount of generated musical noise increas巴s. Themth・order moment after Wi巴ner filtering, μ� F, is given by [15], [16] μご F=(JmM(α,ß,η,m), where. M(α,ß,η,m). (9). = JIßα (t - ßα?mt",-m-l exp( -t)dt +主こγ(α+m,ßα) f(α). (10). (1) First, model the input noise p.d.f. as a gamma distribution with shape parameterαi (initially i = 0). '. (11) Ne;t, �pply Wien�r filteri�g to 血e signal using the. oversubtraction parameter ß and flooring p紅ameter η. We calculate the kurtosis using (9); this is considered as the result of the ith iteration. (111) Next, approximately remodel the resultant processed signal as a garnma distribution with出e modifi巴d shape parameter αi+l co汀esponding to the resultant kurtosis obtained in step (11) (see Fig. 1). Then retum to step (1) with the updated value orα.. � 1 ー 叶A Note 出at this analysis includes an approximation of the p.d.f. modification in wruch the p.d.f. is always remodeled as a gamrna distribution in each iteration. This is necessary because it is difficult to de吋ve an exact analytical expression for the change in kurtosis of the non-gamma distribution. The proposed approximation is, however, still valid if the Wiener filtering process in each step is weak and thus does not change the p.d.f. significantly. In the following, full details of the iterative analysis are glven.百1e kurtosis in the ith iteration is obtained via steps (乃 and (11) using (13) withα=向as kurt(αi,ß,η). In step (111), a new αi+ 1 is calculat巴d using the following relation between the kurtosis and the shape param巴ter:. kurt(αi,ß,η)=. (αi+l+3)(α叶1+2) (αi+l + 1)αi+l. (16).
(3) Step (11). Step (1). Step (111) ,P.d.f. after ith iteration. Gamma-distribution p.d.f. before ith iteration. 園田申炉. This results in a closed-forrn estimate of the shape parameter from the given kurtosis as. - - vkurt(ai' ß,η)2+14 kurt(α"β,η)+1 5. = A(kurt(αi,ß,η)).. 2 -2 kurt(αi,ß,η). (17). By applying the updatedαi+l to the new gamma distribution, we can obtain the following recursive equation for the kurtosis in the (i + 1 )th iteration. kurt(αi+l,ß,η). _ M2( :ル1 ..1',,(A(kurt(αi,ß, ';:\;�.... � ".\;�' �� η)),ß,η,4) 'IJ:,'''''� ::, A(ku吋(αi,ß,η)),ß,η,2) '/). .. (18). 。. + 1 )th即日tion,wh凶has. l. P.d.f. deformation and approximated gamma-distribution p.d.f. for (i. αi+l kurt(αゎβ,η). 、:h. + 一一 t a--a' --. 州t. Approximat叫ammadistribution p.d.f. for (i+ 1 )th iteration, 1 / which has same / kurtosis as that after iteration. ,\. 幽圃噌炉. AO. Fig. 1.. 1\. 可 ,,刊叶 α n円ド nu. 。. r. _____ P.d.f. after ith iteration. same kurtosis of p. d.f. as that after ith山間tion.. 3. 2.5 2 皐 国 』 ul. Gaussian noise case (α。=1.0) Standard Wiener filter Flooring parameterη=0.0 一一Flooring parameterη=0.9. ー-. /ゴププ,. � 1.5. 亡 コ ::.::. 1 0.5 。. 。. \ミご Musical-noise-free con dition 1 1 5 2 Noise reduction rate [dB]. .. 2.5. 3. Thus, we can calculate the resultant kurtosis ratio as. kurtosis r atio = kurt(αi+l,ß,η)jkurt(α0,0,0) αo(α0+ 1) M(A(kurt(αi,ß,η)),ß,η,4) (α0+2)(,α0+3)M2(.バ(kurt(ai,ß,η)),ß, 7],2) 111.. Fig. 2. NRR and kurtosis ratio obtained from theoretical analysis with mcreasmgβNote that hysteresis loop exists when η= 1.0.. ( 19). THEOREM ON MUSICAL-NOISE-FREE CONDITlONS. A. Overview. As indicated by (18), it巴rative Wiener fi1tering theory has an interesting domino-toppling phenomenon as follows. Given a specific p釘ameter setting, if we are fortunate enough to obtain. the same kurtosis as that of th巴input noise, i.e.,. after the 1 st iteration, i.e.,. kurt(αo,ß,η)= kurt(α0,0,0)=. kurt(α0,0,0),. (αo十3)(α。+2) 、 , ( 2 0) (ao + 1)αo. then from (17) we hav巴α1-α0・Obviously, this leads to the relation. kurt(α1,ß,η). =. kurt(αo,ß,η)= kurt(α0,0,0),. (21). proving that the kurtosis in the 2 nd iteration is also identica!. The inductiv巴 r巴sult is that the kurtosis ratio never chang巴s even at a large number of ( ideally “infinite") iterations, where sufficient noise reduction is gained even if出e NRR improve ment in each iteration is smal!. This co汀esponds to musical noise-free noise reduction.. In summary, we can formulate a new theorem on musical noise-free conditions as follows. (1) Fixed-point kurtosis condition: The kurtosis should be equal before and after Wiener filtering in each iteration. This corresponds to a fixed point for 血e 2 nd- and 4出ーorder 灯10m巴nts. (II) NRR growth condition: The amount of noise reduction is larger than 0 dB in each iteration, relating to a change in th巴 1st-order moment. This theorem should be of great interest if such conditions hold in existing signal processing. We have found a hysteresis loop in the relation between the NRR and kurtosis ratio in non iterative Wiener filtering (calculated by ( 14)佃d (15)) with a specific p紅姐1eter setting ( see Fig. 2 ), showing the ex.istence of a fixed point in the kurtosis. In出巴 following subsections, we math巴matically derive more general solutions for musical noise-free conditions. B. Fixed-point kurtosis condition. Although the parameters to be optimized are η and ß, we hereafter derive the optimal η given a fixed ß for ease of.
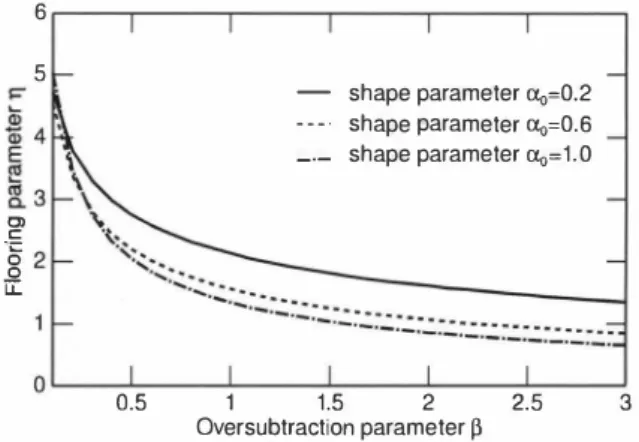
(4) 6. c1osed-form analysis. First, we change (13) to. kurt(αo,ß,η). =. F(αo,ß,m). =. (S(α0,ß,2) + η4F(α0,ß,2)). I. Jß<>. (t- ßα0?mt<>-m-1 exp(- t )dt,. γ(αo + m,ßα0) r(α。). 5. (22) ( 23) (24). Next, the fixed-point kurtosis condition ∞rresponds to 白e kurtosis being equal before and after Wiener filtering, thus. S(α0,ß,4) + η8F(α0,ß,4). っ =. (S(α0,ß,2) + η4F(α0,ß,2))2. (α0 \ -v + 3)(α0 -�\�-\V + 2) -, (α0 + 1)α。. m冗.. (F(α0,ß,4)(α。 + 1)αo _F2(α0,ß,2)(α。 + 3)(α0 + 2))冗2 - 2S(α0,ß,2)F(α0,ß,2)(α0+3)(α0 + 2)冗 + S(α0,ß,4)(α0 + 1)α0- S2(α0,ß,2)(α0+3)(α0 + 2) =0.. 。. (25). Let 1í =η4, then (25) yields the following quadratic equation. �. Thus, we can derive a c1osed-form estimate of勾from the giv巴n oversubtraction parameter as ?土 =. 1 1� 2 Oversubtraction parameter ß. �5. 3. D. Example of parameters satisfying musical-noise-free con dition. According to the previous analysis, we can calculate com binations of the oversubtraction param巴ter ß and the ftooring parameterηthat satisfy the musical-noise-fr巴巴 condition under the three types of shape p訂ameterα. Figure3 shows examples of traces, where the shap巴 parameter α is set to 0.2 ,0.5, and 10 . . From Fig. 3, our theory can provide wide-range solution. IV. A. S(α0 幻)F(α0仇,ß,2 幻)(α0 + 3)(ao 3司)( α0 + 2) 2幻) ß,2)F(ao, ß,2)(ao s(ao,仇,ß,2. O�. shape parameterα。=0.2 shape parameterα。=0.6 shape parameterα。=1.0. Fig. 3. Example of oversubtraction parameterβ岨d lIooring parameterη that satisfy musical-noise-free condition. {F(α0仏,ß,4刈4め)(α0 + 1吋)α0一F2(α0,ß,2幻)(α0 + 3司)(α0 + 2)リ} -1. [. 一一 -- _. _.-. 。,』 回 C E D D 一H-. S(α0,ß,m) =. S(α0,ß,4) + η8F(α0,ß,4). EVAL山UATION EXP陀ERIMENTS AND RESUL口TS. 均旬伽Experiバ…i. We conducted objective and subj配tive evaluation experiments to confirm 白巴 validity of 白E 出巴oretica1 ana1ysis r r,,-,/ n ...... '\ "'T"" / A .-..'\ I "\ I {S(α0,ß,2)F(α0,ß,2)(α0 + 3)(αo + 2)}"2 described in the previous鉛ction. The input SNR of 印刷 data was副to 0 dB. The target speech signals were the } 1 - {F(α0,ß,4)(α0 + )α。 F2(α0,ß,2)(α0+3)(αo + 2) ,1 utterances of two male and two female sp巴akers in Japanese . �伽r sentences). The noise signal was wh出Gaussian noise {S(α0,ß,4)(α0 + 1)α0- S2(α0,ß,2)(α0 + 3)(α0 + 2)} J I (αo = 0.97), babble noise (αo = 0.21) consisting of 36 (27) voices that simulate a crowded plac巴, railway station noise (α。 = 0.33), or museum noise (α。 = 0.21). Each signal Finally,η- 1í1/4 is the resultant f100ring parameter 出at was sampled at 16 kHz. In these experiments, the number satisfies the fixed-point kurtosis condition. of it巴rations is five in iterative Wiener filtering.. .... \. 士1. r>\. ド1. B. Objective evaluation. C. NRR growth condition. In 出is subs巴ction, we r,巴veal the range of th巴 伺ooring parameter η that increases the NRR. From (1 5), the NRR growth condition is expressed as NRR = 10 1 o !!; l n. ロw. αo � A . \ > O. A . \ --V �� , , S(αo,ß,l) + η2F(αo,ß,l). (28). =. J 的一 S一向 一一尺. α一. 月 一 局μ. Here, sinc巴η > 0, we can solve the inequality as. く η, < nu. In 出is subsection, we compare iterative Wiener filtering with other commonly used noise reduction methods under th巴 same NRR condition. Figures 4 and 5 show the kurtosis ratio and cepstral distortion obtained from the experiment with real noisy speech data for white Gaussian noise, babble noise, railway station noise and museum noise, where we evaluate 10-dB-NRR ( i.e., output SNR 10 dB) signals proc巴ssed by five methods, namely, conventiona1 non-iterative spec 凶1 subtraction, non-iterative Wiener filtering, MMSE STSA estimator, iterative spectral subtraction and iterative Wiener filtering wi白 血巴 optimal par;但neter settings. Here, we use白e decision-directed approach for a priori SNR estimation in both non -iterative Wiener filtering and MMSE STSA estimator. In this experiment, we calculate the kurtosis ratio using ( 6) in. (29). In summary, we can choose the parameters simultaneously satisfying the fìxed-point kurtosis condition and NRR growth condition using (27) and (29)..
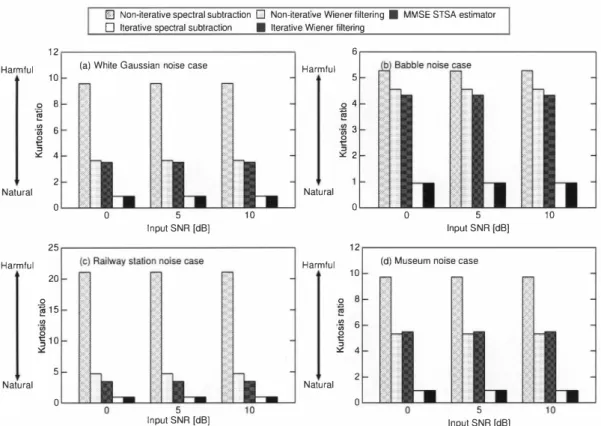
(5) 図Non-iterative spectral subtraction口Non-iterat附Wiener filtering • MMSE STSA estimator • Iterative Wiener filtering. o Iterative spectral subtraction. 12. 6 (a) White Gaussian noise case. 2. Natural. 5 0宮町』ωmot2uL. 。一 H m』盟 mOZコ出. oo cU 必件. 10. Harmful. Natural. 。. 5. 。. 内4 内d 4“マ. Harmful. 。. 10. 10. Input SNR [dB]. 12. 25 Harmful. 5. 。. Input SNR [dB]. Harmful. 20. 10. 5. 2. Natural. Natural. 。. 4. u>. 6. 0=e』ωBotコ¥. 盟 。. 言10 ¥. 8. 告15 』. (d) Museum noise case. 。. 5. 5. Input SNR [dB] Fig. 4.. Input SNR [dB]. Kurtosis ratio obtained from experiment with real noisy speech data under 10-dB-NRR condition 図Non-i恰r剖ive spectral 印刷旧ction口Non-iterative Wiener filtering・MMSE STSA estimator DIterative spectral subtraction • Iterative Wiener filtering. 8. 8. (a) White Gaussian noise case. 号6 E. 。 亡 。. 亡 。. 窃4. 窃4. τ3 百 』 m. τ3 B 』. 曹. 52. ιJ. 守. Good. Good. 。. 2. 5. 5. Input SNR [dB]. B. 8. '86. 号6. 5. 5. てヨ '". τコ m. 0. 0. :ø 4. ω. ,. 3". Input SNR [dB]. ];4. Good. 3" 2 。 Fig. 5.. (b) Babble noise回目. {宅6 c. ' Good. 。. 5. Input SNR [dB]. 10. g2 。. 。. 5. Input SNR [dB]. Cepstral distortion obtained from experiment with real noisy speech data under 10・dB-NRR condition.
(6) 出e first 1 s frames, where we assurne speech absence in a11 noise reduction methods. From Fig. 4 , we can confirm that iterative spectra1 sub traction and iterative Wiener fìltering outperform 出e other conventional methods in terms of the amount of musical noise generation. In particula丸山e kurtosis ratio of iterative spectral subtraction and iterative Wiener fìltering is closest to 1.0. Since non-iterative Wiener filtering and白e MMSE STSA estimator are often ref,巴rred to as methods producing less musical noise, this result greatly emphasizes the advantageousness of iterative Wiener filtering, i.e., its no・musical-noise proper,η, as th巴oret ically predicted in Sect. IIl-A. Also, Fig. 5 indicates that th巴 speech distortion of iterative Wiener fìltering is lower than伽t of conventional methods. In particular, even compared with iterative spectral subtraction, the scores of cepstral distortion of iterative Wien巴r創tering 紅e always lower. In conc1usion, iterative Wiener filtering is a good m巴thod白紙has the lower sp田ch distortion and no musical noise generation. V.. CONCLUSION. In this paper, We derived the optimal parameters satisfying 出e musica1-noise・f民e condition in iterative Wiener fìltering. From objective evaluation experirnents, iterative Wiener filter ing method with th巴 optimal parameter settings is advanta g巴ous to the conventional methods in te口ns of the amounts of musical noise generation and speech distortion. As our on-going work, we ar巴 now developing the extension of出is musical-noise巴仕ee theory by applying the iterative noise reduction into blind multichannel signal processing [17], [18 ], [19], [2 0] to deal with non-stationary noise [2 1], [22 ]. For this purpose, we believe that the proposed iterative Wiener filtering becomes an prornising candidate because of its low speech distortion property. ACKNOWLEDGMENT. This work was support巴d by the恥nc SCOPE, and JST Core Research of Evolution Science and TI巴chnology (CREST), Japan. REFERENCES [1] S. F. 8011, “Suppression of acoustic noise in speech using spec廿al sub廿action," IEEE Transactions on ACOllStics, Speech, and Signal Pro. cessing, voI.27,nO.2,pp.113-120,1979 [2] P. C. Loizou, Speech Ellhancement Theoryαnd Practice, CRC Press, Taylor & Francis Group,FL,2007 [3] Y. Ephr剖m and D. Malah, “Speech enhancement using a minimum mean-square eπor short-time spectral amplitude estimator," IEEE TI即日 actiolls 011 ACOIlStics, Speech, alld Signal Processing, voI.32, no.6, pp.1 109-1121, 1984 [4] M. R. Khan,T. Hasan and M. R. Khan,“lterative noise power subtraction technique for improved speech quality," Proceedillgs o[ Intemational Con[erence on Electrical and Compllter Systems (ICECS2008), pp.391394,2008. [5] J. S. Lim and A. Y. Oppenheim,“All-pole modeling of degraded speech," IEEE Transactions on ACOIlStics, Speech, and Signal Processing, voI.26, no.3, pp.197-210,1978 [6] J. H. Hansen and M. A. Clements, hanc訓nent with application to speech recognition," IEEE Trallsactions on Signal Processing, voI.39,no.4,pp.795-805,1991. [7] R. Miyazak:i, H. Saruwatari, T. lnoue, Y. Takahashi,K. Shikano, and K. Kondo,“Musical-noise-free speech enhancement based on optimized iterative spectral subtraction," IEEE Transactions on Audio, Speech and Langllage Processing, voI.20,No.7, pp.2080-2094, 2012 [8] Y. Uemura, Y. Takahashi, H. Saruwatari, K. Shikano, and K. Kondo, “Automatic optimization scheme of spectral subtraction based on musト cal noise assessment via higher-order statistics," Proceedings o[ Intema tiollal Workshop on Acollstic Echo and Noise Control (IWAENC2ω8),. 2008. [9] Y. Uemura,Y. Takahashi,H. Saruwatari,K. Shikano,Kazunobu Kondo, “Musical noise generation analysis for noise reduction methods based on spec回1 sub回ction and mmse stsa estimation," Proceedings o[ IEEE International Con[erence on ACOIlStics, Speech, and Signal Processing (ICASSP2009), pp.4433-4436,2009 [10] Y. Takahashi, H. Saruwatari, K. Shikano, K. Kondo,“Musical-noise analysis in methods of integrating microphone array and spectral subtraction based on higher-order statistics," EURASIP JOllmal 011 Advanced Signal Processing, voI.2010, Article lD 431347, 25 pages, 2010 [11] H. Saruwatari, Y. Ishikawa, Y. T:紘ahashi, T. lnoue, K. Shikano, K Kondo,“Musical noise controllable algorithm of channelwise spec甘al subtraction and adaptive beamforrning based on higher-order statistics," IEEE Transactions on AlIdio, Speech and Langllage Processing, vo1.I9, no.6,pp.1457-1466,2011 [12] H. Yu, T. Fingscheidt,“A自思Jre of metric for instrumental optimization of noise reduction algorithms," Proceedings o[ DSP in vehic/es 201人 pp.I -8,2011 [13] H. Yu, T. Fingscheidt, “Black box measurement of musical tones produced by noise reduction system," Proceedings o[ International Con[erence on ACOllStics, Speech, and Signal Processing (ICASSP2012),. pp.4573-4576,2012. [14] R. Miyazaki, H. Saruwatari, K. Shikano, “Theoretical analysis of amounts of musical noise and speech d目tortion in structure-generalized parametric blind spatial sub甘action array," IEICE Transactions on FlIlldamelltals o[ Electronics, Commllnications alld Compllter Sciences,. voI.95-A,no.2,pp.586-590,2012 [15] T. Inoue,H. Saruwatari,K. Shikano,and K. Kondo,“Theoretical analy sis of musical noise in Wiener fiItering fa皿ily via higher-order statistics," Proceedings o[ International COII[erellce 011 ACOIlStics, Speech, and. Signal Processing (ICASSP20J 1), pp.5076-5079, 2011 [16] T. Inoue,H. Saruwatari,Y. Takahashi,K. Shikano,K. Kondo,“Theoret ical analysis of musical noise in generalized spectral subtraction based on higheトorder statistics," IEEE Transactiolls 011 AlIdio, Speech and Language Processing, vol. I 9, no.6,pp.1770-1779, 2011 [17] S. Araki, R. Muk剖, S. Makino, T. Nishikawa, H. Saruwatari, “The fundamental limitation of frequency domain blind source separation for convolutive mixtures of speech," IEEE Transactiolls 011 Speech and Audio Processing, vol. l I, no.2, pp.109-116, 2003. [18] H. Saruwatari,T. Kawamura,T. Nishikawa,A. Lee,K. Shikano,“8lind source separation based on a fast-convergence algorithm combining ICA and beamforrning," 1EEE 7トansactions on Speech and Audio Processing, voI.I4,no.2,pp.66ふ-678,2006. [19] Y. Takahashi, T. Takatani, H. Saruwatari, K. Shikano,“81ind spatial subtraction a町ay with independent component analysis for hands-free speech re∞gnition," Proceedings o[ International Workshop on Acollstic Echo and Noise Control (IWAENC2006), 2006. [20J Y. Takahashi,T. Takatani,K. Osako,H. Saruwatari,K Shikano,“Blind spatial subtraction array for speech enhancement in no日y environment," IEEE Transactions 011 Audio, Speech al1d Lal1guage Processing, vo1.l7, no.4,pp.65仏-664,2009. [21J R. Miyazak:i,H. Saruwatari,K. Shikano,K. Kondo,‘、�usical-noise-free blind speech extraction using ICA-based noise estimation and iterative spectral subtraction," Proceedings o[ IlIIematiol1al COI砕rellce 011 Infor mαtioll Sciellce, Signal Processing and their Applications (ISSPA20J2),. pp.322-327,2012 [22] R. Miyazaki,H. Saruwatari,K. Shikano,K. Kondo,.‘Musical-noise-free blind speech extraction using ICA-based noise estimation with channel selection," Proceedillgs o[ Il1Iernatiollal Workshop 011 Acollstic Signal Enhαncement (IWAENC20J2), 2012..
(7)
図

関連したドキュメント
If white noise, or a similarly irregular noise is used as input, then the solution process to a SDAE will not be a usual stochastic process, defined as a random vector at every time
Key words and phrases: White noise space; series expansion; Malliavin derivative; Skorokhod integral; Ornstein-Uhlenbeck operator; Wick prod- uct; Gaussian process; density;
In order to predict the interior noise of the automobile in the low and middle frequency band in the design and development stage, the hybrid FE-SEA model of an automobile was
In this study, it is also observed that the value of kurtosis coefficients for the independent components, which represents the noise component, can be further reduced
しかし、 平成 21 年度に東京都内の公害苦情相談窓口に寄せられた苦情は 7,165 件あり、そのうち悪臭に関する苦情は、
If the Output Voltage is directly shorted to ground (V OUT = 0 V), the short circuit protection will limit the output current to 690 mA (typ).. The current limit and short
フロートの中に電極 と水銀が納められてい る。通常時(上記イメー ジ図の上側のように垂 直に近い状態)では、水
排水槽* 月ごとに 1 回以上 排水管・通気管* 月に 1
