Fast Dereverberation for Hands-Free Speech Recognition
4
0
0
全文
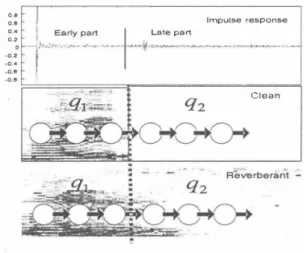
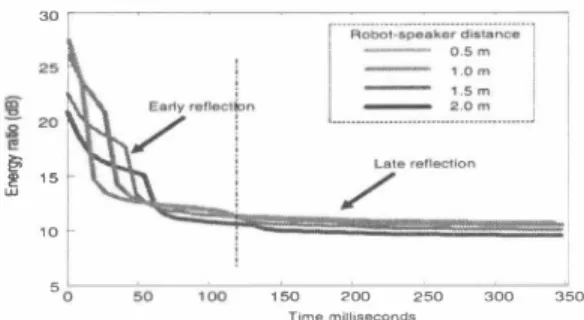
(2) 30. お認認.. 電B Re,∞gmzer. E唱5. /. 10 5. Fig. 3. Practical impl巴mentation of the ideal fast dereverber0-------50. 唱。o. 150 200 250 TI"、."、iIIiseconds. 300. 350. 2. Energy ratio of the early and late components of the impulse response.. Fig.. vious speech coinciding at HMM q1 to q2・ As m巴ntioned earlier, reverberant sp巴巴ch signal contains both the effects of the early and late re自民tions (wh巴n refer ring to early reflection we include by definition出巴 direct sig nal). Although there exists a s甘ong correlation due to artic ulatory constraints between the speech and the effects of the reverberant environment condition (i.巴. early, and late reflec tions) this s位ong correlation is lost due to articulatory move ments [4]. Thus, we can write + xL(η) ,. Fig. 4. Late Reflection Boundary Identification. 3. PROPOSED METHOD. 、E EJ l (. X(π) = xE(n). Imp山e ÆSp即時cut. wher巴XE(n), xL(η)紅巳 the uncorrelated early and late re flection components of the reverb巴rant signal x(η). Given s(η) as clean speech, and measured r∞m impulse h(η) = [hEhLl where its early coefficients hE and late coefficients hL are identified in advance, Equation 1 becomes x(n) = s(π)*hE + s(π)*hL.. (2). Since XE(η),xL(n) are uncorrelated to some constraint [4], we can use SS [3] to remove xL(η). After SS, the early re flection is given as. IXE(f,叩= IX(f,7W -IXL(f,7W,. Figure 3 shows出e proposed online dereverberation. In this figure, we use白巴 reverb巴rant signal x(π) in estimating the approximate late reflection企L(n). Note that the exact xL(n) can only be estimated using clean sp巴民h s(η) which is not available.百us, we use a crud巴 estlmat巴xL(n) instead of the exact xL(n) for SS. Altho暗h this would result to a significant 巴stImatlOn e汀or, we can co汀巴ct this by using multi-band SS wher巴 multi-band coefficients ð = {81,..., 8K } 紅巴汀凶凶a創m巴d O仔仔削L斗line 巴 tωo rninirr甘i described in Section 3.3.. 3.1. Late Component Boundary hL. (3). where IX(f,7W and IXL(f,7)12 are the power spectra of the reverberant signal and its late reflection respectively. Our o句ective is to recov巴rむ(n). It is theoretically possible to remove not just the late reflection, but the early as well. How ever, th巴 latter is sensitive to rnicrophone-speaker locations. Figure 2 shows the energy ratio of出巴 late and early com・ ponents of the impulse response measured at 0.5m, 1.0m, 1.5m, and 2.0m away from出e rnicrophone. This graph shows that robustness in microphone-speaker location can only be achieved when removing only the late reflection since it is static over time. This m巴ans also that, it is possible for us to use only as single impulse response m巴asurement which will cover all of the distances. Thus, it is better remove only the later reflection. We will show later that ind巴巴d, a single measurement is sufficient. Moreover, the early reverberation effects in target signal XE(π) can be handled by the 3-state HMM archit制限伽ough Cepstral Mean Norrnalization and adaptation techniques [5].. We need to id巴ntify hL from the measured room impulse re sponse h(η). To achieve this goal, we check the recognition perforrnanc巴 of th巴 generated reverberant test sets in which the length of the impuls巴 response are varied. Figure 4 shows the recognition result, where the horizontal axis denotes the variation of耐length of出巴 impulse response in a from of impulse response cut, while the vertical axis shows th巴 word accuracy. Significant decrease in perfoπnance is apparent at 70 ms onwards, this coincides the e仔'ect of th巴 late reflection xL(η). He民自e recogmzer pe巾rrns poo均with the effects of reverberation that falls outside 出e 3-state 1-部品1: frame work. On the con甘ary, the recognizer is robust to出e effects of the 巴arly part hE which causes the early reflections XE(π).. 3ムEstimating企L(n) instead of xL(n) We assume出at we c加estimate xL(n) = x(n)* hL using the observed reverberant時nal x(n) as shown in Figure 3. We note that in real scenario, it is not feasible to estimate xL(n) because s(n) is not available. To counter出e effect of the approximation eπor as a consequence of the assumption,. 14 1. - 142 -.
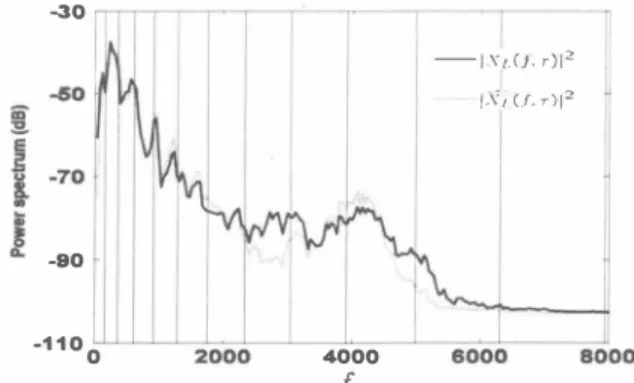
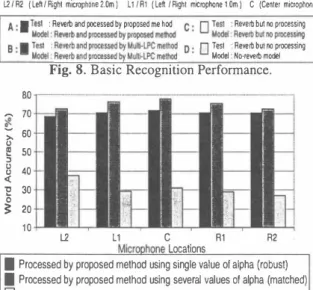
(3) -30. 一一一 IXdf. r)12 1.\',U.r)12. .ー。. -唱唱。. 。. 4000. f we employ multi-band SS similar to that in [6]. The single band SS needs a good estimate of xL(n) which is not avail able. Moreover, we introduced an off-line training scheme in computing出e multトband coefficients that minimize the eπ'Or betw巴en XL(π) and出巴 crude estimat巴:h (n) which is dis cussed in Section 3.2.. 6. Power spectral densities of the real late reverberant component XL(f) and estimated late reverberant component. Fig.. XL(f).. IJ ; m. 3.3. Acquiring M叫討・band Coe箇cients We have clean speech utterance s(η) in our training database. Th巴r巴fore, it is possible to optimize the values of the multi band coefficients off-line in a form of training to minimize the error betw巴en xL(n) and i;L(η). We show in Figure 5 the b10ck diagram of the training which is done off-line. The real late reflection is xL(n) = hL* s(n) and the crude estimate late reflection i;L(η) = hL本h*s(n)紅e computed using the late p訂t of 白e impulse response and the clean speech in the database. Power spectral densities (PSD) XL(f) and XL(f) of both signals are estimated using Welch's method. An example of the PSDs of both signal is shown in Figure 6. For a given set of bands B = {B1' . . . , BK } , the coefficients Ó = {Ó1,'・・, ÓK } are determined by minimizing the squared e汀or in each band k. Ek = 乞IXL(f) - ókXL(fW. Fig. 7. Microphone-speak巴r set-up in acquiring room impulse response using TSP and to simulate reverberant utterances for both the training and test data in the same manner as [ 1]. In this experiment we use microphone創Tays. The room set-up is shown in Figure 7 with source/sp巴aker locations of 0.5m, 1.0m, 1.5m, and 2.0m respectively. Microphones are located with positions L2, Ll , C, R2, and R 1 respectively. Movable panels are used to con・ trol reverberation, and measured 500ms and 600ms reverber ation time impulse response. Since real recording signals are limited, we also generated synthetic reverberant signals ob tained using 6000-tap filter for the test data. Phonetically Tied Mixture (PTM) [9] model is used, with Jl江IUS [8] as the recognizer having a 20K-word Japanese newspaper dictation task from JNAS [10]. A total training sp巴akers of 56 1 (male and female), and an open test set of 200 utterances from 44 (ma1巴 and female) speak巴rs.. (4). fEBk. Thus, in the actual multi-band SS online using the optimiz巴d Ó,出e target signal XE(J) in仕巴quency domain is given as,. nu. Aリ仏. > 7 7 7. L FJ' L』lH' 《 XA A 一 一7 7 7 ) 7) T. Aリ仏 仏 民 x11 h E t- 4 F t 可J J P3 1 ( | l ぃ ・1 9 e , E E ・ E ・ J 、 . • E E E E 、 一 一. 、、,., 7,, 214 E A X. (5). for fεBk with βthe flooring coefficient and γthe power exponent as in conventional SS. The resulting Ó coeffi cients from training which is used in the actua1 multi-band SS are { 3.430, 1.913, 1.647, 0.780, 0.664, 2.743, 2.655, 1.995, 1.699, 1.232, 1.794, 1.324 } . 4.. 4.1.. Recognition Performance. In Figure 8, we show the recognition results at 5 microphone 紅ray positions R2, R l, C, Ll, and L2 (refer to Figure 7). This figure shows the average performance at 0.5m, 1.0m, 1.5m, and 2.0m speaker-microphone distanc巴s. Figure 8 shows白at. EXPERIMENT AND RESULTS. We use the Time Stretched Puls巴 (TSP) method [7] to obtain the measurement of the actual room impulse response h(η). 142. qJ AUτ 噌EA.
(4) 回. time-consuming blind estimation. Although the multi-LPC [1) is novel in a sense that it can adaptively estimate xL(n), real-time derl巴verberation for real-time speech recognition is not feasible. Mor巴ov巴r, we have shown that the proposed method is robust to speaker-microphone locations. This im plies that w巴 only need a single room impulse response mea surement to cover all locations in the room. Roustness is achieved since we only remove the lat巴 reflection. In our futur巴 works, we will combine the proposed d巴reverb巴ration approach with noise supression.. 75 � 70. �. 55 却 �5 12. Rl. L1. R4. 6.. t.ticrophone Arra y Locati側、s UIR2 (LehlRighl. m蜘叩hone2.0ml. L1IRl (L凶l同ghl microp同ne 1.0m 1. A: 圃 Te sl : R開巾and陣ess回by pro附edmelh剖 ・ Model:Re附and附閥均pro抑制同州. 8 : . T阿 Reverband仰関白,ed旬Mu品印Cmelh凶 国 Model:Reve巾制d pro四ssedb甲MuhトLPCmelh剖. Fig.. C (Cenler. micro凶加el. This work is supported by the Japanese MEXT e-Society project of NAIST, and ACCMS, Kyoto University.. . 円 T醐: R帥巾M間pr間四時 r. ・ L..J M叫Re帥b凶問問削噌 ・ D. :. n Tesl. :Reve巾bu1間pro骨SSl吋. "・ L..J Mode: No-re帽命mo制. 7. REFERENCES. 8. Basic Recognition Performance.. ぶ. ロ. u. c. Microohone Locations. �. �. • Processed by proposed methαj using single value 01 alpha (robust) • Pr百cessed by proposed melhod using several values 01 alpha (matched) 日 Reve巾閑1凶川thoul proωsSlngれ". Fig. 9. Robustness of the Proposed Method. the proposed method(A) outperforms the multi-LPC approach (B) in all cases. The increase may not be signi白cant, but the proposed method can b巴 巴xecut巴d in real-time. Mor巴over, der巴verberation using the proposed method is really perform ing better than(C) matched model without dereverb巴ration and(D) clean model. 4.2.. K. Kinoshita, T. Nakatani, and M. Miyoshi“Spectral Subtraction Steered By Multi-step Forward Linear Pre diction For Single Channel Speech Dereverberation" ln PI町eedings ollCASSP, 2006 [2) R. Gomez, 1. Even, H. Saruwatari, and K. Shikano, “Distant-talking Robust Speech Recognition Using Late Reflection Compon巴nts of Room Impulse Response" To be published in lCASSP, March 2008 [3) S.F Boll“Suppression of Acoustic Noise in Sp巴ech us ing Spectral Subtraction" lEEE Trans. on ASSP, vol. 27(2), pp. 113-120, 1979 [4) K. Kinoshita, T. Nakatani, and M. Miyoshi“Efficient Dereverberation Framework For Automatic Sp巴巴ch Recognition" ln Proceedings ollCSLP, Vol 1, pp 92-95, 2005 [5] C.J.Legget巴r and Woodland“Maximum Likelihood Lin ear Regression for Speaker Adaptation of Continu ous Density Hidden Markov Models" ln Proceedings 01 Computer Speech and Language, voI.9,pp.171-185, 1995 [6] S. Kamath, and P. Loizou“'A Multi-Band Spec町al Sub traction Method for enhancing Spe巴ch co汀upted by col ored Noise" ln Proceedings ollCASSP, 2002 [7) Y. Suzuki, F. Asano, H.-Y. Kim, and Toshio Sone, "An optimum computer-generat巴d pulse signal suitable for th巴 measur巴ment of very Iong impuIse responses"よ Acoust. Soc. Am. V<フ/'97(2), pp.-1119-1123, 1995 [8] “Julius, an Open-Source Large Vocabulary CSR Engine - http://julius.sourceforge.jp'' [9] A. Lee, T. Kawahara, K. Tak巴da and K. Shikano,“A New Phonetic Tied-Mixtur巴 Model For Efficient Decod ing" ln Proceedings 011CASSP , pp. 1269-1272 2000. 日0] K. Ito, M. Yamamoto, K. Takeda, T. Takezawa, T. Matsuoka, T. Kobayashi, K. Shikano and S. Itahashi, “JNAS: Japanese Speech Corpus for Large Vocabulary Continuous Speech Recognition Res巴arch" T he Journal 01 Acoustical Society 01 Japan, vol. 20, pp. 199・206, 1999 [1). 80 � 70 三60 0 e 50 コ g 40 4 'E 30 0 � 20 10. Robustness to Microphone-Speaker Positions. A variation in speaker location would imply a variation of ó. We randomly selected different speaker-n廿crophone Ioca. tions and rev巴rberation tim巴(500ms or 600ms). Th巴 result shown in Figure 9 shows the performance of the proposed me出od with matched ó and robust ó. The latt巴r us巴s o叫y on巴 S巴t of ó measured at th巴 farthest microphone distance at 2.0m (we refer to this as robust ó), the r巴cognition perfoロnance does not vary much as compared to using several matched ó. This points to the fact that xL(n) does not vary much as well, and this justifies our hypothesis in Section 2. 5.. ACKNOWLEDGMENT. CONCLUSION. We have proposed a fast dereverberation approach extended to rnicrophone a灯ay. This is made possible through the uti lization of the measured impulse response and avoiding the. 143. -144.
(5)
図
関連したドキュメント
In order to estimate the noise spectrum quickly and accurately, a detection method for a speech-absent frame and a speech-present frame by using a voice activity detector (VAD)
朱開溝遺跡のほか、新疆維吾爾自治区巴里坤哈薩 克自治県の巴里坤湖附近では、新疆博物館の研究員に
patient with apraxia of speech -A preliminary case report-, Annual Bulletin, RILP, Univ.. J.: Apraxia of speech in patients with Broca's aphasia ; A
In particular, we consider a reverse Lee decomposition for the deformation gra- dient and we choose an appropriate state space in which one of the variables, characterizing the
Keywords: continuous time random walk, Brownian motion, collision time, skew Young tableaux, tandem queue.. AMS 2000 Subject Classification: Primary:
n , 1) maps the space of all homogeneous elements of degree n of an arbitrary free associative algebra onto its subspace of homogeneous Lie elements of degree n. A second
This paper presents an investigation into the mechanics of this specific problem and develops an analytical approach that accounts for the effects of geometrical and material data on
The object of this paper is the uniqueness for a d -dimensional Fokker-Planck type equation with inhomogeneous (possibly degenerated) measurable not necessarily bounded
