平易なコーパスを用いないテキスト平易化
梶原 智之
†・小町 守
†難解なテキストと平易なテキストからなる大規模な単言語パラレルコーパスを用い て,テキスト平易化が活発に研究されている.しかし,英語以外の多くの言語では平 易に書かれた大規模なコーパスを利用できないため,テキスト平易化のためのパラレ ルコーパスを構築するコストが高い.そこで本研究では,テキスト平易化のための 大規模な疑似パラレルコーパスを自動構築する教師なし手法を提案する.我々の提 案するフレームワークでは,リーダビリティ推定と文アライメントを組み合わせる ことによって,生コーパスのみからテキスト平易化のための単言語パラレルコーパ スを自動構築する.統計的機械翻訳を用いた実験の結果,生コーパスのみを用いて 学習した我々のテキスト平易化モデルは,平易に書かれた大規模なコーパスを用い て学習した従来のテキスト平易化モデルと同等の性能で平易な同義文を生成できた.
キーワード:テキスト平易化,疑似パラレルコーパス,リーダビリティ推定,文アライメント
Text Simplification without Simplified Corpora
Tomoyuki Kajiwara† and Mamoru Komachi†
Several studies on automated text simplification are based on a large-scale monolin- gual parallel corpus constructed from a comparable corpus comprising complex text and simple text. However, constructing a parallel corpus for text simplification is expensive as large-scale simplified corpora are not available in many languages other than English. Therefore, we propose an unsupervised method that automatically builds a pseudo-parallel corpus to train a text simplification model. Our framework combines readability assessment and sentence alignment and automatically constructs a text simplification corpus from only a raw corpus. Experimental results show that a statistical machine translation model trained using our corpus can generate simpler synonymous sentences performing comparably to models trained using a large-scale simplified corpus.
Key Words: Text Simplification, Pseudo-parallel Corpus, Readability Assessment, Sen- tence Alignment
† 首都大学東京, Tokyo Metropolitan University
1 はじめに
難解なテキストの意味を保持したまま平易に書き換えるテキスト平易化は,言語学習者や子ど もをはじめとする多くの読者の文章読解を支援する.近年,テキスト平易化を同一言語内の翻 訳問題と考え,統計的機械翻訳を用いて入力文から平易な同義文を生成する研究(Specia 2010;
Zhu, Bernhard, and Gurevych 2010; Coster and Kauchak 2011a, 2011b; Wubben, van den Bosch, and Krahmer 2012; ˇStajner, Bechara, and Saggion 2015a; ˇStajner, Calixto, and Saggion 2015b;
Goto, Tanaka, and Kumano 2015)が盛んである.しかし,異言語間の機械翻訳モデルの学習に 必要な異言語パラレルコーパスとは異なり,テキスト平易化モデルの学習に必要な単言語パラ レルコーパスの構築はコストが高い.これは,日々の生活の中で対訳(異言語パラレル)データ が大量に生産および蓄積されるのとは異なり,難解なテキストを平易に書き換えることは自然 には行われないためである.そのため,公開されておりテキスト平易化のために自由に利用で きるのは,English Wikipedia1とSimple English Wikipedia2から構築された英語のパラレルコー パス(Zhu et al. 2010; Coster and Kauchak 2011b; Hwang, Hajishirzi, Ostendorf, and Wu 2015) のみであるが,Simple English Wikipediaのように平易に書かれた大規模なコーパスは英語以外 の多くの言語では利用できない.
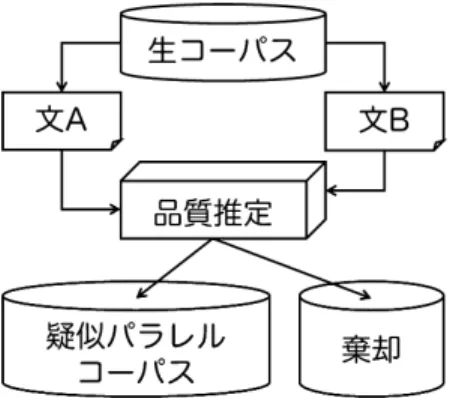
そこで本研究では,任意の言語でのテキスト平易化を実現することを目指し,生コーパスか ら難解な文と平易な文の同義な対(テキスト平易化のための疑似パラレルコーパス)を抽出す る教師なし手法を提案し,獲得した疑似パラレルコーパスと統計的機械翻訳モデルを用いて英 語および日本語でのテキスト平易化を行う.図1に示すように,我々が提案するフレームワー クでは,リーダビリティ推定と文アライメントの2つのステップによって生コーパスからテキ スト平易化のための疑似パラレルコーパスを構築する.大規模な生コーパスには,同一の(あ るいは類似した)イベントや事物に対する複数の言及や説明が含まれると期待でき,それらか らは同義や類義の関係にある文対を得ることができるだろう.さらに我々はリーダビリティ推 定によって難解な文と平易な文を分類するので,生コーパスから難解な文と平易な文の同義な 対を抽出することができる.
我々は2つの設定で提案手法の効果を検証した.まず先行研究と同様に,難解なテキストと 平易なテキストのコンパラブルコーパスからテキスト平易化のためのパラレルコーパスを構築 した.我々の提案する文アライメント手法は難解な文と平易な文のアライメント性能を改善し,
高品質にテキスト平易化コーパスを構築できた.さらに,我々のコーパスで学習したモデルは 従来のコーパスで学習したモデルよりもテキスト平易化の性能も改善できた.次に,コンパラ ブルコーパスを利用しない設定で,生コーパスのみからテキスト平易化のための疑似パラレル
1 http://en.wikipedia.org
2 http://simple.wikipedia.org
図 1 疑似パラレルコーパスと統計的機械翻訳モデルを用いたテキスト平易化
コーパスを構築し,フレーズベースの統計的機械翻訳モデルを用いてテキスト平易化を行った.
平易に書かれた大規模コーパスを使用しないにも関わらず,疑似パラレルコーパスで学習したモ デルは従来のコーパスで学習したモデルと同等の性能で平易な同義文を生成することができた.
本研究の貢献は次の2つである.
• 単語分散表現のアライメントに基づく文間類似度を用いて,難解な文と平易な文の文ア ライメントを改善した.
• 生コーパスのみから教師なしで擬似パラレルコーパスを自動構築し,これがコンパラブ ルコーパスから得られる従来のパラレルコーパスと同等に有用であることを確認した.
これまでは,人手で構築された難解な文と平易な文のパラレルコーパス3(Xu, Callison-Burch, and Napoles 2015),平易に書かれた大規模なコーパス(Simple English Wikipedia),文間類似度のラベ ル付きデータ4(Agirre, Cer, Diab, and Gonzalez-Agirre 2012; Agirre, Cer, Diab, Gonzalez-Agirre, and Guo 2013; Agirre, Banea, Cardie, Cer, Diab, Gonzalez-Agirre, Guo, Mihalcea, Rigau, and Wiebe 2014; Agirre, Banea, Cardie, Cer, Diab, Gonzalez-Agirre, Guo, Lopez-Gazpio, Maritxalar, Mihalcea, Rigau, Uria, and Wiebe 2015),言い換え知識5(Ganitkevitch, Van Durme, and Callison- Burch 2013; Pavlick, Rastogi, Ganitkevitch, Van Durme, and Callison-Burch 2015; Pavlick and
Callison-Burch 2016)などの言語資源が豊富に存在する英語を中心にテキスト平易化の研究が進
3 https://newsela.com/data/
4 http://ixa2.si.ehu.es/stswiki/index.php/Main Page
5 https://www.seas.upenn.edu/˜epavlick/data.html
められてきたが,本研究ではこれらの外部知識を利用することなく生コーパスのみからテキス ト平易化のための疑似パラレルコーパスを自動構築し,統計的機械翻訳を用いたテキスト平易 化における有用性を確認した.生コーパスは多くの言語で大規模に利用できるので,今後は本 研究の成果をもとに多くの言語でテキスト平易化を実現できるだろう.
本稿の構成を示す.2節では,関連研究を紹介する.3節では,生コーパスから擬似パラレル コーパスを構築する提案手法を概説する.4節では,テキスト平易化のための文アライメント として,単語分散表現のアライメントに基づく文間類似度推定手法を提案する.続いて,5節か ら7節で実験を行う.まず5節では,4節の提案手法を評価し,テキスト平易化のための最良 の文アライメント手法を決定する.6節では,3節から5節に基づき,英語の疑似パラレルコー パスを構築し,テキスト平易化を行う.7節では,同様に日本語の疑似パラレルコーパスを構 築し,テキスト平易化を行う.最後に8節で,本研究のまとめを述べる.
2 関連研究
2.1 統計的機械翻訳を用いたテキスト平易化
2010年以降,統計的機械翻訳を用いたテキスト平易化の研究が盛んである.特に英語では,
English WikipediaとSimple English Wikipediaをコンパラブルコーパスと考え,ここから抽出 された単言語パラレルコーパス(Zhu et al. 2010; Coster and Kauchak 2011b; Hwang et al. 2015) とフレーズベースの統計的機械翻訳モデルを用いたテキスト平易化 (Zhu et al. 2010; Coster and Kauchak 2011a, 2011b; Wubben et al. 2012; ˇStajner et al. 2015a)が盛んに研究されてい る.Coster and Kauchak (2011b)は,標準的なフレーズベースの統計的機械翻訳ツールMoses (Koehn, Hoang, Birch, Callison-Burch, Federico, Bertoldi, Cowan, Shen, Moran, Zens, Dyer, Bojar, Constantin, and Herbst 2007)を用いて英語のテキスト平易化を行った.
本研究でも,同じくMosesを用いてテキスト平易化を行うが,我々は任意の言語でのテキスト 平易化を実現することを目的に,Simple English Wikipediaに頼ることなくEnglish Wikipedia のみから構築する疑似パラレルコーパスでモデルを学習する.
2.2 テキスト平易化のための単言語パラレルコーパス
これまでに3 種類の英語のテキスト平易化のための単言語パラレルコーパスが,English WikipediaとSimple English Wikipediaの文アライメントによって構築されている.Zhu et al.
(2010)は,文をTF-IDFベクトルとして表現し,そのベクトル間のコサイン類似度を用いて初め
てテキスト平易化のための単言語パラレルコーパス6を構築した.Coster and Kauchak (2011b)
6 https://www.ukp.tu-darmstadt.de/data/sentence-simplification/simple-complex-sentence-pairs/
は,TF-IDFベクトル間のコサイン類似度に加えて文の出現順序を考慮することで,より高精度 にテキスト平易化コーパス7を構築した.しかし,Zhu et al.やCoster and Kauchakの手法では,
異なる単語間の類似度を考慮していない.難解な表現から平易な表現への書き換えが頻繁に行 われるテキスト平易化タスクにおいては,異なる単語間の類似度も適切に測定したい.Hwang
et al. (2015)は,国語辞典の見出し語と定義文中の単語の共起を用いて,異なる単語間の類似度
も考慮してテキスト平易化コーパス8を構築した.
本研究では,単語分散表現を用いることで辞書などの外部知識に頼らず異なる単語間の類似 度を考慮する文アライメントを行う.
2.3 文間類似度推定
文間の意味的類似度を計算するSemantic Textual Similarity (STS)タスク(Agirre et al. 2012,
2013, 2014, 2015)では,単語分散表現の成功を受け,異なる単語間の類似度を考慮する手法が提
案されている.SemEval-2015のSTSタスク(Agirre et al. 2015)では,word2vec (Mikolov, Chen, Corrado, and Dean 2013a)の単語分散表現やPPDB: paraphrase database (Ganitkevitch et al.
2013)の言い換えを用いた単語アライメントに基づく教師あり学習の手法(Sultan, Bethard, and Sumner 2015; H¨anig, Remus, and de la Puente 2015; Han, Martineau, Cheng, and Thomas 2015) が上位を独占している.同じくword2vecの単語分散表現のアライメントに基づく教師なしの文 間類似度計算手法(Song and Roth 2015; Kusner, Sun, Kolkin, and Weinberger 2015)も提案さ れている.
文間類似度のラベル付きデータを必要としないこれらの教師なし手法は,テキスト平易化の ための単言語パラレルコーパスの自動構築にも応用できる.
2.4 リーダビリティ推定
テキストの可読性を評価するリーダビリティ尺度としては,Flesch Reading Ease Formula (Flesch 1948)やFlesch-Kincaid Grade Level (Kincaid, Fishburne Jr., Rogers, and Chissom 1975) がよく知られている.これらはいずれも,単語数と音節数を用いてリーダビリティを計算する.
また,単語数に加えて難解な表現が出現する割合を考慮するDale-Chall Readability Formula (Chall and Dale 1995)や言語モデルに基づく手法(Collins-Thompson and Callan 2004)も提案 されている.これらの研究は英語を対象としているが,リーダビリティ尺度は言語ごとに開発 されており,例えば日本語では柴崎,玉岡(2010),佐藤(2011),藤田,小林,南,杉山(2015) の研究がある.
本研究ではシンプルなリーダビリティ尺度を採用するが,我々の提案するフレームワークに
7 http://www.cs.pomona.edu/˜dkauchak/simplification/
8 http://ssli.ee.washington.edu/tial/projects/simplification/
基づいて,リーダビリティ推定のステップには任意のリーダビリティ尺度を適用できる.
2.5 テキスト平易化の評価
統計的機械翻訳を用いたテキスト平易化(Specia 2010; Zhu et al. 2010; Coster and Kauchak 2011a, 2011b; Wubben et al. 2012; ˇStajner et al. 2015a, 2015b; Goto et al. 2015)では,機械翻訳 のための評価尺度であるBLEU (Papineni, Roukos, Ward, and Zhu 2002)による自動評価が一 般的である.BLEUではリファレンスとの比較によって出力文の意味や文法の正しさを評価す るが,テキスト平易化では入力文よりも平易な文を出力したいため,入力文と出力文の比較も 行いたい.
本研究では,テキスト平易化のために新たに提案されたSARI (Xu, Napoles, Pavlick, Chen, and Callison-Burch 2016)による自動評価も行う.SARIは入力文と出力文とリファレンスの3 つを用いる自動評価尺度であり,特に平易さの観点でBLEUよりも人手評価との相関が高いこ とが知られている.
3 生コーパスから疑似パラレルコーパスを構築するためのフレームワーク
本研究では,生コーパスからテキスト平易化のための疑似パラレルコーパスを自動構築する フレームワークを提案する.これは,より一般的には図2のように説明できる.生コーパスか ら無作為に抽出した2つの文に対して,タスクに応じた品質推定を行い,一定以上の尤度を持 つ文対を擬似パラレルコーパスとして抽出する.品質推定(ˇStajner, Popovi´c, Saggion, Specia,
and Fishel 2016)とは入力文と出力文の比較によってリファレンスなしで出力文を評価する技
術の総称であり,テキストからのテキスト生成タスク,特に機械翻訳(Callison-Burch, Koehn, Monz, Post, Soricut, and Specia 2012; Bojar, Buck, Callison-Burch, Federmann, Haddow, Koehn,
図 2 品質推定を用いた生コーパスからの疑似パラレルコーパス構築
Monz, Post, Soricut, and Specia 2013; Bojar, Buck, Federmann, Haddow, Koehn, Leveling, Monz, Pecina, Post, Saint-Amand, Soricut, Specia, and Tamchyna 2014; Bojar, Chatterjee, Federmann, Haddow, Huck, Hokamp, Koehn, Logacheva, Monz, Negri, Post, Scarton, Specia, and Turchi 2015; Bojar, Chatterjee, Federmann, Graham, Haddow, Huck, Jimeno Yepes, Koehn, Logacheva, Monz, Negri, Neveol, Neves, Popel, Post, Rubino, Scarton, Specia, Turchi, Verspoor,
and Zampieri 2016)を中心に研究されている.図2に戻ると,品質推定のステップでは言い換
え生成であれば2文間の同義性を評価し,文圧縮であれば2文間の同義性および文Aに対する 文Bの圧縮率を評価し,応答文生成であれば文Aを質問文として文Bの応答文らしさを評価す る.このように,タスクごとの品質推定を高精度に実現できれば,このフレームワークを用い てタスクに応じた疑似パラレルコーパスを生コーパスから抽出できる.
本研究では,テキスト平易化のための疑似パラレルコーパスを構築したい.テキスト平易化 は意味を保持したまま平易に書き換えるタスクなので,図2における品質推定のステップでは,
各文の難易度および2文間の同義性を評価する.我々は文の難易度を評価するために,各言語 で開発されているリーダビリティ尺度を用いる.各文に対してリーダビリティ推定を行い,絶 対的あるいは相対的なリーダビリティの高低がわかれば,続いてリーダビリティの低い難解な 文とリーダビリティの高い平易な文の同義性を評価する.一般に長い文よりも短い文の方が読 みやすいので,テキスト平易化では難解な表現から平易な表現への言い換えの他に,重要では ない表現の省略も頻繁に行われる(Xu et al. 2015).そのため,テキスト平易化における同義性 は,言い換えタスクのような相互に置換可能な「同義性」には限定されない.そこで我々は,4 節で説明する意味的文間類似度を用いて2文間の同義性を評価する.最終的に,難解な文と平 易な文の対であり,かつ類似度が高い文対のみをテキスト平易化のための擬似パラレルコーパ スとして採用する.
4 単語分散表現のアライメントに基づく文間類似度を用いた文アライメント
難解な文と平易な文の同義性を評価するために,我々は単語分散表現のアライメントに基づ く4種類の文間類似度の計算手法を提案する.4.1節から4.3節で説明する手法は,Song and
Roth (2015)によって提案された単語分散表現のアライメントに基づく文間類似度の計算手法を
本タスクに応用するものである.4.4節のWord Mover’s Distance (Kusner et al. 2015)も,単語 分散表現のアライメントに基づく文間類似度の計算に用いることができる.
4.1 Average Alignment
文xと文yの間の全ての単語の組み合わせについて単語間類似度を計算し,それらの|x||y|個 の単語間類似度を平均して文間類似度Save(x, y)を求める.
Save(x, y) = 1
|x||y|
|x|
∑
i=1
|y|
∑
j=1
ϕ(xi, yj) (1)
ここで,xiおよびyjは,それぞれ文xおよび文yに含まれる単語を表す.また,ϕ(xi, yj)は単 語xiと単語yjの間の単語間類似度を表し,本研究ではコサイン類似度を用いる.
4.2 Maximum Alignment
Average Alignmentは単語分散表現に基づく文間類似度として直感的であるが,同義の文対を
考えても全ての単語の組み合わせについて単語間類似度が高くなるとは考えにくく,多くの単 語間類似度は0に近い値を取るノイズになると考えられる.そこで文xに含まれる各単語xiに 対して最も類似度が高い文y中の単語yjを選択し,それらの|x|個の単語の組み合わせについ てのみ計算した単語間類似度ϕ(xi, yj)を平均してSasym(x, y)を求める.Sasym(x, y)は非対称 なスコアであるため,Sasym(x, y)とSasym(y, x)の平均値を用いて対称な文間類似度Smax(x, y) を計算する.
Sasym(x, y) = 1
|x|
|x|
∑
i=1
max
j ϕ(xi, yj) (2)
Smax(x, y) = 1
2(Sasym(x, y) +Sasym(y, x)) (3)
4.3 Hungarian Alignment
Average AlignmentおよびMaximum Alignmentは,それぞれ多対多および多対一の単語アラ イメントに基づく文間類似度である.本節ではxおよびyの2文を単語をノードとする2部グ ラフとして考え,一対一の単語アライメントに基づく文間類似度を定義する.この2部グラフ は,単語間類似度ϕ(xi, yj)を重みとする重み付きの辺を持つ重み付き完全2部グラフである.
この完全2部グラフの最大マッチングを求めることで,単語間類似度の総和を最大化する一対 一の単語アライメントを得ることができる.2部グラフの最大マッチング問題は,Hungarian法 (Kuhn 1955)を用いて解くことができる.そこで文xに含まれる各単語xiに対してHungarian 法によって文y中の単語h(xi)を選択し,それらの|x|個の単語の組み合わせについて計算した 単語間類似度を平均して文間類似度Shun(x, y)を求める.
Shun(x, y) = 1 min(|x|,|y|)
|x|
∑
i=1
ϕ(xi, h(xi)) (4)
4.4 Word Mover’s Distance
Word Mover’s Distance (Kusner et al. 2015)も,単語の分散表現を用いた多対多の単語アライ メントに基づく文間類似度の計算に用いることができる.Word Mover’s Distanceは,文xから 文yへと単語を輸送する輸送問題を解くEarth Mover’s Distance (Rubner, Tomasi, and Guibas
1998)の特殊な場合に相当する.
Swmd(x, y) = 1−WMD(x, y) (5)
WMD(x, y) = min
∑n
u=1
∑n
v=1
Auvψ(xu, yv) (6)
subject to :
∑n
v=1
Auv = 1
|x|f req(xu)
∑n
u=1
Auv = 1
|y|f req(yv)
ここで,ψ(xu, yv)は単語xuと単語yvの間の単語間非類似度(距離)を表し,本研究ではユー クリッド距離を用いる.また,Auvは文x中の単語xuから文y中の単語yvへの輸送量を表す 行列であり,nは語彙数,f req(xu)は文x中での単語xuの出現頻度である.
5 実験 1: 難解な文と平易な文のアライメント
本節では,難解な文と平易な文の組に対してパラレルおよびノンパラレルの2値分類を行い,
単語分散表現のアライメントに基づく文間類似度の有効性を評価する.
5.1 実験設定
Hwang et al. (2015)は,English WikipediaとSimple English Wikipediaから抽出した67,853 文対に対して以下の4つのラベルを人手で付与したデータを公開している.
• Good:2文間の意味が等しい(277文対)
• Good Partial:一方の文が他方を含意する(281文対)
• Partial:部分的に関連する(117文対)
• Bad:無関係(67,178文対)
我々はこの評価用データセットを用いて,以下の2つの設定で,文間類似度によって各文対 をパラレルデータとノンパラレルデータに2値分類する.
• G vs. O:Goodのラベル付きデータのみをパラレルデータとする
• G+GP vs. O:GoodとGood Partialの2つのラベル付きデータをパラレルデータとする 評価には,Hwang et al.と同じく以下の2つの尺度を用いる.
• MaxF1:F1スコアの最大値
• AUC-PR:Precision-Recall曲線(PR曲線)上のArea Under the Curve
比較手法には,English WikipediaとSimple English Wikipediaからテキスト平易化のための パラレルコーパスを構築するZhu et al. (2010),Coster and Kauchak (2011b)およびHwang et al.の3つの先行研究に加えて,Additive Embeddings (Mikolov, Sutskever, Chen, Corrado, and Dean 2013b)を用いる.Additive Embeddingsは,単語アライメントを使用しない比較手法であ り,単語の分散表現を足し合わせることによって文の分散表現を構成し,コサイン類似度によっ て文間類似度を計算する.
単語分散表現に基づく文間類似度計算のために,我々は公開されている学習済みの単語分散 表現9を用いる.これは,Google News dataset上でword2vec (Mikolov et al. 2013a)のCBOW モデルによって学習された300次元の単語分散表現である.
提案手法のうち,Average Alignment,Maximum AlignmentおよびHungarian Alignmentに ついては,Song and Roth (2015)にならって単語アライメントのノイズ除去を行った.4.2節で も述べたが,同義の文対(x, y)を考えても全ての単語対について単語間類似度が高くなるとは 考えにくく,どの単語アライメントの手法を用いても単語間類似度が低いにも関わらず対応付 けられてしまう単語対が存在する.このようなノイズとなる単語対の影響を抑えるため,我々 はϕ(xi, yj)> θの単語間類似度を持つ単語対(xi, yj)のみを用いて単語アライメントを行った.
この閾値θはMaxF1を最大化するように選択し,Average AlignmentについてはG vs. Oの分 類時に0.89,G+GP vs. Oの分類時に0.95,Maximum AlignmentについてはG vs. Oの分類 時に0.28,G+GP vs. Oの分類時に0.49,Hungarian AlignmentについてはG vs. Oの分類時 に0.98,G+GP vs. Oの分類時に0.98を採用した.
5.2 実験結果
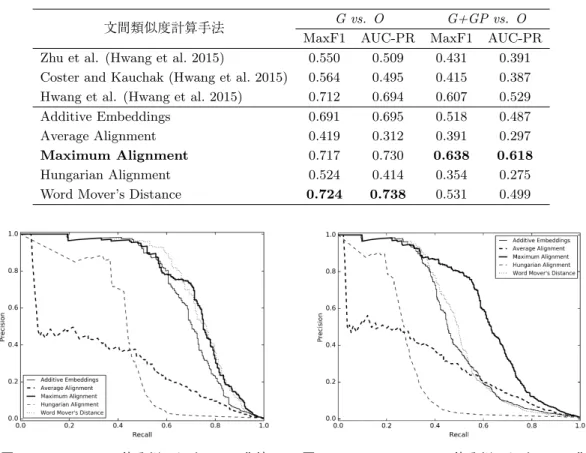
パラレルデータとノンパラレルデータの2値分類の結果を表1に示す.Goodとその他の2値 分類においては多対多の単語アライメントに基づくWord Mover’s Distanceが最も高い性能を 示した.また,Good+Good Partialとその他の2値分類においては多対一の単語アライメント に基づくMaximum Alignmentが最も高い性能を示した.なお,Maximum AlignmentはGood とその他の2値分類においても3つの先行研究よりも高い性能を示した.
図3および図4に,パラレルデータとノンパラレルデータの2値分類におけるPrecision-Recall 曲線を示す.図 4 のGood+Good Partialとその他の 2値分類において,太実線のMaximum
Alignmentが他の単語分散表現に基づく文間類似度計算手法よりも高い性能を示した.
3節で述べたように,テキスト平易化タスクでは省略も頻繁に行われる.そこで,テキスト
9 https://code.google.com/archive/p/word2vec/
表1 パラレルデータとノンパラレルデータの2値分類精度
文間類似度計算手法 G vs. O G+GP vs. O MaxF1 AUC-PR MaxF1 AUC-PR Zhu et al. (Hwang et al. 2015) 0.550 0.509 0.431 0.391 Coster and Kauchak (Hwang et al. 2015) 0.564 0.495 0.415 0.387 Hwang et al. (Hwang et al. 2015) 0.712 0.694 0.607 0.529
Additive Embeddings 0.691 0.695 0.518 0.487
Average Alignment 0.419 0.312 0.391 0.297
Maximum Alignment 0.717 0.730 0.638 0.618
Hungarian Alignment 0.524 0.414 0.354 0.275
Word Mover’s Distance 0.724 0.738 0.531 0.499
図3 G vs. Oの2値分類におけるPR曲線 図 4 G+GP vs. Oの2値分類におけるPR曲線
平易化のための単言語パラレルコーパスには,対応する難解な文と平易な文が同義であるGood の文対だけでなく,難解な文が平易な文の意味を含意するGood Partialの文対も含めることが 重要である.そのため,Good+Good Partialとその他の2値分類において最も高い性能を示す
Maximum Alignmentが,テキスト平易化のための単言語パラレルコーパス構築に最も適した文
間類似度の計算手法であると言える.
図5および図6から,Maximum Alignmentでは(genus, genus)と(species, genus)のような多 対一の単語アライメントが可能であるが,Hungarian Alignmentには(as, genus)や(tree, is)のよ うな誤った単語アライメントが見られる.機能語は色々な単語とある程度の単語間類似度を持 つため,Hungarian Alignmentにおける一対一の制約は厳しすぎる.また,Maximum Alignment は多対一の単語アライメントを許すので,フレーズと単語の言い換えも上手く捉えられる.
図5 Maximum Alignmentによる単語アライメント図6 Hungarian Alignmentによる単語アライメント
6 実験 2: 英語のテキスト平易化
Simple English Wikipediaのような平易に書かれた大規模コーパスは英語以外の多くの言語
では利用できないため,本研究では生コーパス(English Wikipedia)からテキスト平易化のため の疑似パラレルコーパスを構築し,それを用いてフレーズベースの統計的機械翻訳モデルを訓 練することによってテキスト平易化を実現する.
本節では,平易に書かれた大規模コーパスが利用できる英語での実験によって,文アライメ ント手法の改善によるテキスト平易化の性能の変化を確認する.また,平易なコーパスに頼ら ない疑似パラレルコーパスから訓練されたモデルが,既存のパラレルコーパスから訓練された モデルに匹敵する性能を発揮できることを示す.
6.1 疑似パラレルコーパスの構築
3節で述べたように,我々はリーダビリティ推定と文アライメントによって各文対に対して テキスト平易化のための品質推定を行い,コーパスに含める文対を選抜する.
6.1.1 生コーパス
まず,生コーパスを用意する.本研究では,English Wikipedia10の各記事に対してWikiExtrac- tor11を用いた本文抽出とNLTK 3.2.112を用いたトークナイズを行い,10単語以上の6,283,703 文を対象とした.
10https://dumps.wikimedia.org/enwiki/20160501/
11https://github.com/attardi/wikiextractor/
12http://www.nltk.org/
6.1.2 リーダビリティ推定
次に,英文のリーダビリティ推定のために,我々は英語のテキスト平易化(Zhu et al. 2010;
Bingel and Søgaard 2016)でよく利用されるFlesch Reading Ease Formula (Flesch 1948)を用い る.Flesch Reading Ease Formulaでは,αを単語数,βを1単語あたりの平均音節数として,文 のリーダビリティを次のように定義する.
F leschReadingEase= 206.835−1.015α−84.6β (7) Flesch Reading Ease Formulaで計算されたリーダビリティスコアは,おおよそ0以上100以下 の値を取り,[60,70)を標準レベルとして,高いほど読みやすい平易な文であることを意味する.
そこで我々は,English Wikipediaから抽出した6,283,703文を以下のように分割した.
• 難解なサブコーパス:[0,60)のリーダビリティスコアを持つ3,689,227文
• 平易なサブコーパス:[60,100]のリーダビリティスコアを持つ2,358,921文
• リーダビリティを測定不能として棄却:数百単語の長文や箇条書きなど,0未満または 100を超えるリーダビリティスコアを持つ235,555文
6.1.3 文アライメント
我々は5節で最も高い性能を示したMaximum Alignmentを用いて全ての難解な文と平易な 文の組み合わせに対して文間類似度を計算した.単語分散表現には,5節と同じく公開されて いる学習済みのCBOWモデル13を使用した.ノイズを軽減するために単語間類似度が0.5以上 の単語対のみを単語アライメントに使用し,文間類似度が0.5以上である2,072,572文対を抽出 して英語のテキスト平易化のための疑似パラレルコーパスを構築した.
6.2 疑似パラレルコーパスの妥当性
図7に,English WikipediaとSimple English Wikipediaの文のリーダビリティの分布を示す.
縦軸は各リーダビリティスコアの文数を正規化したものであり,各ヒストグラムの面積が1と なる.Flesch Reading Ease Formulaに基づくリーダビリティスコアの60未満の範囲では,難解 なコーパスであるEnglish Wikipediaの文が出現する割合が高い.同じく,60以上の範囲では平 易なコーパスであるSimple English Wikipediaの文が出現する割合が高い.よって,本研究で難 解な文と平易な文を分割した閾値60の基準も妥当であると言える.また,English Wikipediaに は難解な文が多いとは言え,全ての文が難解なわけではないこともわかる.そのため,English
Wikipediaから平易な文を抽出することで,平易な文書に頼ることなく平易なサブコーパスを
得ることができる.
13https://code.google.com/archive/p/word2vec/
図8に,我々が構築した疑似パラレルコーパスの文間類似度ごとの同義性の品質を示す.Good,
Good Partial,PartialおよびBadの各ラベルは,5節の実験設定と対応しており,Hwang et al.
(2015)に準ずるものである.文間類似度の範囲ごとに100文対を無作為抽出し,合計500文対
を2人のアノテータが評価した.各文対に4つのラベルのうちの1つを割り当てたところ,ア ノテータ間の一致率はピアソンの相関係数で0.629と十分に高かった.この同義性に関する人 手評価から,文間類似度が高くなるにつれて無関係なBadの文対が減少し,同義なGoodの文 対が増加していることがわかる.また,一方の文が他方を含意するGood Partialの文対は文間
類似度[0.9,1.0)の範囲でのみ減少しているが,これは難解な文と平易な文の文長に関係してい
る.文間類似度[0.8,0.9)の範囲では,難解な文の平均文長は平易な文の平均文長よりも約3語 長い.しかし,文間類似度[0.9,1.0)の範囲では,その差は1語未満である.文長の近い文対で は意味的な包含関係が成立しにくく,文間類似度の高い文対は同義になりやすいと考えられる.
表2に,我々が構築したテキスト平易化のための疑似パラレルコーパスの例を示す.Goodの
図 7 リーダビリティの分布 図 8 疑似パラレルコーパスの品質
表 2 English Wikipediaから構築したテキスト平易化のための疑似パラレルコーパスの例
ラベル 難解な文 平易な文
Good
Climate in this area has mild differences be- tween highs and lows, and there is adequate precipitationyear round.
Climate in this area has mild differences between highs and lows, and there is ad- equaterainfallyear round.
Good Partial
The new German Empire included 25 states (three of them, Hanseatic cities)and the imperial territory of Alsace-Lorraine.
The new German Empire included 25 states, three of them Hanseatic cities.
Partial
In 1996, she received the Primetime Emmy Award for Outstanding Supporting Actress in a Comedy Series, an award she was nom- inated for on seven occasions.
In 2006 and 2008, she received Emmy nominations for Outstanding Supporting Actress in a Drama Series.
文対には,難解な語句から平易な語句への言い換え(precipitation→rainfall)の例が見られる.
Good Partialの文対には省略の例が見られる.Partialの文対は,同義関係や含意関係ではない
が,共通する語句や関連する語句を含み,関連する内容について書かれている.
English Wikipediaを分割した難解なサブコーパスと平易なサブコーパスの組は,English
WikipediaとSimple English Wikipediaの組とは異なりコンパラブルコーパスではない.そのた め,図8に示したように,同義や含意の関係にある文対の割合は多くはない.しかし,本研究 ではフレーズベースの統計的機械翻訳を用いてテキスト平易化を行うため,以下の3つの理由 でこの問題の影響は少なく,雑音の多い文対からでも重要な知識を獲得できる.
• テキスト平易化は同一言語内の翻訳問題であるため,入力文に含まれる多くの単語をそ のまま出力できる(変換しないことが正解である).そのため,異言語間の翻訳問題とは 異なり,適切な変換対が少量しか得られないことが致命的な問題にはならない.
• フレーズベースの統計的機械翻訳では,フレーズ単位の変換対を学習する.難解なフレー ズとその言い換えである平易なフレーズの組は,同義や含意の関係にある文対からだけ ではなく,類義の関係にある文対からも得ることができる.
• フレーズベースの統計的機械翻訳では,最終的に言語モデルによるリランキングを行う ため,雑音の多いフレーズペアを獲得していても,平易な言い換えとして適切なフレー ズペアをその中に含むことができれば適切な平易文が得られる.
6.3 実験設定
我々は生コーパスのみから構築したテキスト平易化のための疑似パラレルコーパスの有効性 を調査するために,フレーズベースの統計的機械翻訳を用いてテキスト平易化モデルを学習し,
Simple English Wikipediaを使って構築された既存のテキスト平易化のためのパラレルコーパ
スを用いて学習したモデルとの比較を行う.本研究では,テキスト平易化を難解な文から平易 な文への翻訳問題と考え,対数線形モデルを用いてモデル化する.
ˆ
s= argmax
simple
P(simple|complex)
= argmax
simple
P(complex|simple)P(simple)
= argmax
simple
∑M
m=1
λmhm(simple, complex)
(8)
対数線形モデルではM個の素性関数hm(simple, complex)および各素性の重みλmを考え,翻
訳確率P(simple|complex)をモデル化する.テキスト平易化の場合は,入力の難解な文に対して
素性関数の重み付き線形和を最大化する平易な文sˆを探索する問題を考える.素性関数として は,フレーズの平易化モデルlogP(complex|simple)や言語モデルlogP(simple)などを用いる.
我々はフレーズベースの統計的機械翻訳ツールであるMoses 2.1 (Koehn et al. 2007)を使用 し,パラレルコーパスからの単語アライメントの獲得にはGIZA++ (Och 2003)を用いた.ま た,KenLM (Heafield 2011)を用いて各パラレルコーパスの平易側の文から5-gram言語モデル を構築した.テストデータには,Xu et al. (2016)によって公開されているマルチリファレンス のパラレルコーパス14を使用した.これは,English Wikipediaから抽出された難解な350文に 対して,それぞれ8人が平易な同義文を付与したものである.本研究では,このマルチリファ レンスのパラレルコーパスを用いてFlesch Reading Ease (FRE),BLEU (Papineni et al. 2002)
およびSARI (Xu et al. 2016)による自動評価を行った.なお,トレーニングデータからはテス
トデータに含まれるEnglish Wikipediaの文を除外した.
6.4 実験結果
表3および表4にフレーズベースの統計的機械翻訳を用いたテキスト平易化の実験結果を示 す.Baselineは,書き換えを行わず入力文をそのまま出力する弱いベースラインである.Zhu et al. corpus15,Coster and Kauchak corpus16およびHwang et al. corpus17は,我々の実験設 定と同じくフレーズベースの統計的機械翻訳ツールMosesによってテキスト平易化を行うが,
表3 英語のテキスト平易化の実験結果
パラレルコーパス 文対数 難解側の 語彙数
平易側の 語彙数
難解側の 平均文長
平易側の
平均文長 平易化規則数 FRE BLEU SARI
Baseline 0 0 0 0 0 0 54.5 99.4 25.9
Zhu et al. corpus 108,016 181,459 149,643 21.2 17.4 7,441,535 59.7 84.7 34.7 Coster and Kauchak corpus 137,362 132,567 120,620 23.6 21.1 11,871,929 59.8 86.4 34.1 Hwang et al. corpus 284,738 212,138 164,979 26.0 19.8 25,482,261 61.0 81.3 34.5 Our parallel corpus 492,993 274,775 198,043 25.3 17.9 34,370,284 61.7 78.4 34.9 Our pseudo-parallel corpus 2,072,572 174,310 156,271 43.5 32.7 146,522,360 58.9 78.0 34.0
表 4 疑似パラレルコーパスの文対数と性能の変化 疑似パラレルコーパスの
文間類似度の閾値 文対数 難解側の 語彙数
平易側の 語彙数
難解側の 平均文長
平易側の
平均文長 平易化規則数 FRE BLEU SARI Smax≥0.94 100,000 10,965 24,598 33.9 35.0 2,443,146 54.9 94.9 29.1 Smax≥0.79 500,000 38,912 54,749 34.1 31.3 10,888,446 55.3 92.7 31.1 Smax≥0.64 1,000,000 87,002 95,764 36.3 30.3 32,368,746 56.9 88.0 33.7 Smax≥0.55 1,500,000 134,852 129,604 39.7 31.2 77,426,785 58.2 83.2 34.4 Smax≥0.51 2,000,000 169,629 153,307 43.1 32.5 138,102,965 59.2 79.1 34.1 Smax≥0.50 2,072,572 174,310 156,271 43.5 32.7 146,522,360 58.9 78.0 34.0
14https://github.com/cocoxu/simplification
15https://www.ukp.tu-darmstadt.de/data/sentence-simplification/simple-complex-sentence-pairs/
16http://www.cs.pomona.edu/˜dkauchak/simplification/
17http://ssli.ee.washington.edu/tial/projects/simplification/
難解なコーパス(English Wikipedia)と平易なコーパス(Simple English Wikipedia)の両方を用 いて構築されたパラレルコーパスをトレーニングに使用する.Our parallel corpus18は,同じく English WikipediaとSimple English Wikipediaのコンパラブルコーパスを用いるが,4.2節の
Maximum Alignmentによって構築したテキスト平易化のためのパラレルコーパスをトレーニン
グに使用する強いベースラインである.Our pseudo-parallel corpusは我々の提案手法であり,
生コーパスのみを用いて構築したテキスト平易化のための疑似パラレルコーパスを使用する.
6.4.1 語彙数
我々のパラレルコーパスや既存の他のパラレルコーパスでは,難解なコーパスの方が平易な コーパスよりも語彙数が多い.これは,Simple English Wikipediaが850語の基本語彙を用いる というガイドラインに従って書かれているためである.850語の制約が厳密に守られているわ けではないとはいえ,Simple English Wikipediaの語彙の方が少なくなっている.しかし,我々 の疑似パラレルコーパスでは,文間類似度の高い100万文対までは難解なコーパスの語彙数の 方が少ない.これは,文間類似度を用いて貪欲に文アライメントを取るため,同じ文が繰り返 し使用される場合があるからである.例えば10万文の疑似パラレルコーパスでは,平易なコー パスの異なり文数が25,817であるのに対して,難解なコーパスの異なり文数は3,674である.
6.4.2 平均文長
我々のパラレルコーパスは既存の他のパラレルコーパスよりも難解なコーパスと平易なコーパ スの文長の差が大きく,English WikipediaとSimple English Wikipediaの全体の平均文長(25.1
および16.9)に近い.これは,Maximum Alignmentが文長に関わらず適切に文間類似度を計算
できていることを意味する.
6.4.3 平易化規則数(フレーズテーブルのエントリ数)
10万文や50万文の部分に注目すると,我々の疑似パラレルコーパスは得られる規則が少な い.これは類似度の低い文対ほど多くの平易化が実施されるためである.例えば,Zhu et al.
corpusや我々のパラレルコーパスには,0.5以上の類似度の文対が含まれている.一方,疑似パ
ラレルコーパスには,10万文で0.94以上,50万文で0.79以上の類似度の文対しか含まれてい ない.同じ10万文や50万文で比較したときには我々の疑似パラレルコーパスでは類似度の高 い文対が多くなり,平易化のバリエーションは少ない.しかし,疑似パラレルコーパスは大量 に用意できるため,最終的には十分な量の規則を獲得することができる.
18https://github.com/tmu-nlp/sscorpus
6.4.4 FRE: Flesch Reading Ease(リーダビリティ)
疑似パラレルコーパスを用いて学習したモデルでも,入力文よりもリーダビリティの高い文 を出力できた.平易な大規模コーパスを使用していないにも関わらず,文間類似度の上位200 万文を用いて学習した場合には,Simple English Wikipediaを使って学習した場合と同等の59 を超えるリーダビリティを持つ文を出力することができた.
6.4.5 BLEUおよびSARI
FREが出力文のみを用いてリーダビリティのみを評価するのに対して,BLEUは出力文とリ ファレンスの両方を,SARIは入力文と出力文とリファレンスの全てを用いて文法や意味も評価 する.Xu et al. (2016)は,BLEUがGrammarやMeaningの観点で人手評価との相関が高く,
SARIがSimplicityの観点で人手評価との相関が高いことを報告しており,テキスト平易化のた
めに提案されたSARIはGrammar/Meaning/Simplicityの全てのバランスが取れた自動評価尺 度であると結論付けている.表3によると,BLEUはBaselineが最も高い.これは,入力文を 何も変換しない場合には意味も文法も損なわれないためである.完全に意味を保持することは できないため,平易化の操作を加えることによってリーダビリティが向上する一方でBLEUは 低下してしまう.BLEUを高く保ちつつリーダビリティのより高い文を出力することが良い平 易化である.
我々のパラレルコーパスを用いて学習したモデルは,SARIで最高性能を達成した.他の先行研 究との違いは文アライメントの手法であり,5節の内的評価の結果と同様にMaximum Alignment の有効性が確認できた.
疑似パラレルコーパスを用いて学習したモデルでは,文間類似度の上位150万文を使った場 合にSARIが最大となった.平易な大規模コーパスを利用しないにも関わらず,先行研究のパラ レルコーパスを用いて学習したモデルと同等の性能を発揮することができた.また,このとき のBLEUも先行研究と同等であり,入力文の文法や意味を保持した文を出力することができた.
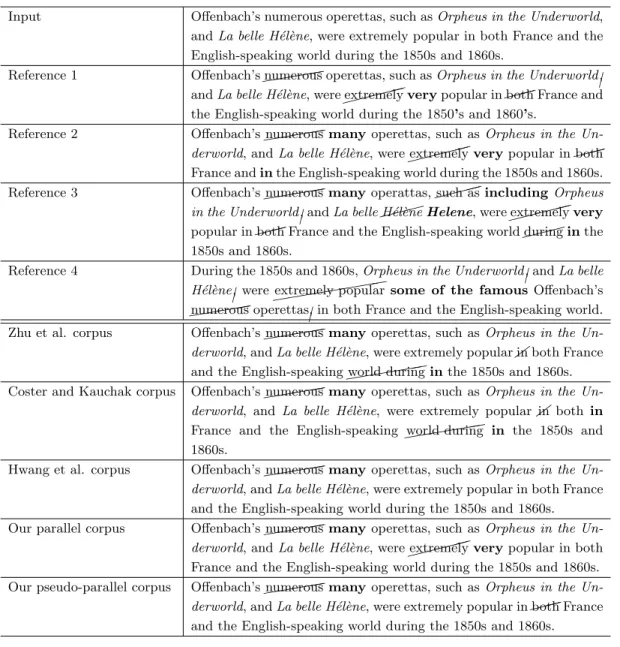
6.4.6 テキスト平易化の例
表 5に,フレーズベースの統計的機械翻訳を用いたテキスト平易化の例を示す.疑似パラ レルコーパスを用いて学習したモデルは,Reference 1と同様に不要な表現“both”を省略し,
Reference 2や3と同様に難解な表現“numerous”を平易な表現“many”に言い換えた.比較手 法の中には,難解な表現“extremely”から平易な表現“very”への言い換えも見られた一方で,
“world”など必要以上の省略も見られた.
表5 英語のテキスト平易化の例
Input Offenbach’s numerous operettas, such asOrpheus in the Underworld, andLa belle H´el`ene, were extremely popular in both France and the English-speaking world during the 1850s and 1860s.
Reference 1 Offenbach’s((((numerous operettas, such as( Orpheus in the Underworld, andLa belle H´el`ene, wereextremelyverypopular inboth France and the English-speaking world during the 1850’s and 1860’s.
Reference 2 Offenbach’s((((numerous(manyoperettas, such as Orpheus in the Un- derworld, andLa belle H´el`ene, wereextremelyverypopular inboth France andinthe English-speaking world during the 1850s and 1860s.
Reference 3 Offenbach’s((((numerous(manyoperattas,such asincludingOrpheus in the Underworld, andLa belleH´el`eneHelene, wereextremelyvery popular inboth France and the English-speaking world duringinthe 1850s and 1860s.
Reference 4 During the 1850s and 1860s,Orpheus in the Underworld
, andLa belle H´el`ene, were((((extremely popular((((some of the famous Offenbach’s ((((numerous operettas( , in both France and the English-speaking world.
Zhu et al. corpus Offenbach’s((((numerous(manyoperettas, such as Orpheus in the Un- derworld, andLa belle H´el`ene, were extremely popularin both France and the English-speaking((((world during((inthe 1850s and 1860s.
Coster and Kauchak corpus Offenbach’s((((numerous(manyoperettas, such as Orpheus in the Un- derworld, andLa belle H´el`ene, were extremely popularin both in France and the English-speaking ((((world during(( in the 1850s and 1860s.
Hwang et al. corpus Offenbach’s((((numerous(manyoperettas, such as Orpheus in the Un- derworld, andLa belle H´el`ene, were extremely popular in both France and the English-speaking world during the 1850s and 1860s.
Our parallel corpus Offenbach’s((((numerous(manyoperettas, such as Orpheus in the Un- derworld, andLa belle H´el`ene, wereextremelyverypopular in both France and the English-speaking world during the 1850s and 1860s.
Our pseudo-parallel corpus Offenbach’s((((numerous(manyoperettas, such as Orpheus in the Un- derworld, andLa belle H´el`ene, were extremely popular inboth France and the English-speaking world during the 1850s and 1860s.
7 実験 3: 日本語のテキスト平易化
提案手法が言語やコーパス(English Wikipedia)に依存しないことを確認するために,本節で は日本語の均衡コーパスを用いた実験を行う.
7.1 疑似パラレルコーパスの構築
6.1節と同じく,リーダビリティ推定と文アライメントによって生コーパスからテキスト平易 化のための疑似パラレルコーパスを構築する.生コーパスには現代日本語書き言葉均衡コーパ ス(BCCWJ) (Maekawa, Yamazaki, Maruyama, Yamaguchi, Ogura, Kashino, Ogiso, Koiso, and
Den 2010)を,リーダビリティ推定には文中の各単語の単語難易度19 (梶原,小町2017)の平均
値をそれぞれ使用した.この単語難易度は,571,023語の日本語の単語に3段階(1:初級,2:中 級,3:上級)の難易度が自動的に付与されたものである.Maximum Alignmentの文アライメ ントに使用する単語分散表現は,word2vec (Mikolov et al. 2013a)のCBOWモデルをBCCWJ 上で学習した.ノイズを軽減するために単語間類似度が0.5以上の単語対のみを単語アライメ ントに使用し,文間類似度が0.6以上である470,885文対を抽出して日本語のテキスト平易化の ための疑似パラレルコーパスを構築した.
7.2 実験設定
6.3節の英語の実験と同じ設定で,フレーズベースの統計的機械翻訳モデルを用いてテキス ト平易化を行った.テストデータには,Web20から収集した2,000文対を使用した.収集した データは難解なテキストと平易なテキストからなるコンパラブルコーパスである.Maximum Alignmentの文間類似度が[0.75,1.0)の範囲の各文対について,2人のアノテータがHwang et al.
(2015)に準ずる4つのラベル(Good,Good Partial,Partial,Bad)のうちの1つを割り当てた ところ,アノテータ間の一致率はピアソンの相関係数で0.769と十分に高かった.テストデー タとして使用するのは,2人のアノテータがいずれもGoodまたはGood Partialのラベルを付与 した2,000文対である.
7.3 実験結果
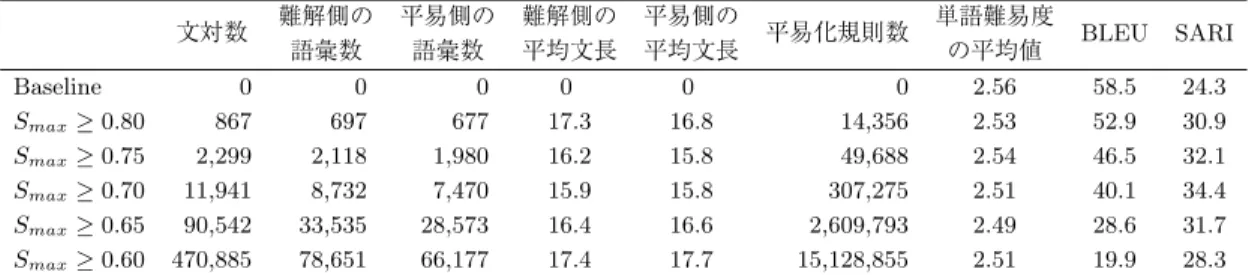
表6に,フレーズベースの統計的機械翻訳を用いた日本語のテキスト平易化の実験結果を示 す.日本語ではテキスト平易化のためのパラレルコーパスが公開されていないため,書き換え を行わず入力文をそのまま出力する弱いベースラインのみと比較する.疑似パラレルコーパス を用いて学習したモデルは,いずれもSARIにおいてBaseline(入力文)よりも高い性能を示し た.英日の実験結果から,我々は提案手法が言語やコーパスに依存せず有効であることを確認 できた.なお,表3の英語の実験結果に比べて全体にBLEUが低いのは,シングルリファレン スのテストデータで評価を行っているためである.
表7に,日本語のテキスト平易化の例を示す.疑似パラレルコーパスで訓練したテキスト平 易化モデルは,難解な表現“定休日”から平易な表現“休みの日”などの言い換えを漏らしてい
19https://github.com/tmu-nlp/simple-jppdb
20https://matcha-jp.com/
表 6 日本語のテキスト平易化の実験結果
文対数 難解側の 語彙数
平易側の 語彙数
難解側の 平均文長
平易側の
平均文長 平易化規則数 単語難易度
の平均値 BLEU SARI
Baseline 0 0 0 0 0 0 2.56 58.5 24.3
Smax≥0.80 867 697 677 17.3 16.8 14,356 2.53 52.9 30.9
Smax≥0.75 2,299 2,118 1,980 16.2 15.8 49,688 2.54 46.5 32.1
Smax≥0.70 11,941 8,732 7,470 15.9 15.8 307,275 2.51 40.1 34.4
Smax≥0.65 90,542 33,535 28,573 16.4 16.6 2,609,793 2.49 28.6 31.7
Smax≥0.60 470,885 78,651 66,177 17.4 17.7 15,128,855 2.51 19.9 28.3
表 7 日本語のテキスト平易化の例
Input このまま飾っても可愛いですね。
Reference このまま飾っても可愛いかわいいですね。
Output このまま飾っても可愛いかわいいですね。
Input 定休日:行く前に一度電話で聞いてみてください。
Reference 定休休みの日:行く前に一度電話で聞いしてみてください。
Output 定休日:行く前に一度電話で聞いをしてみてください。
Input しばらく進むと、下谷神社が右側に見えてきます。
Reference しばらくそのまま進むと、右に下谷神社が 右側に見えてきます。
Output しばらく進むと、右側に下谷神社が右側に見えてきます。
るものの,難解な表現“電話で聞く”から平易な表現“電話をする”などの言い換えや,ガ格と ニ格の並び替えに成功した.
8 おわりに
本稿では,フレーズベースの統計的機械翻訳モデルを用いる生コーパスのみからのテキスト 平易化について述べた.提案手法では,平易に書かれた大規模なコーパスや言い換え知識など の外部知識に頼らず,生コーパスのみを用いてリーダビリティと文間類似度によってテキスト 平易化のための疑似パラレルコーパスを構築する.我々が提案した単語分散表現のアライメン トに基づく文間類似度は,外部知識に頼ることなく難解な単語と平易な単語の単語間類似度を 考慮することができ,従来の文間類似度よりも文長に頑健なため,テキスト平易化コーパスを 構築するための文アライメントに適した手法である.フレーズベースの統計的機械翻訳を用い たテキスト平易化の実験結果は,疑似パラレルコーパスを用いて学習したモデルが,平易な大 規模コーパスを用いて学習する先行研究のモデルと同等の性能で入力文を平易な同義文に変換 できることを示した.
これまでは,豊富な言語資源が存在する英語を中心にテキスト平易化の研究が進められてき
たが,生コーパスは英語以外の多くの言語でも大規模に利用できるので,今後は多くの言語で テキスト平易化が実現できるだろう.
また,パラレルコーパスは文圧縮や応答文生成などの他のテキストからのテキスト生成タス クにおいても有用な言語資源である.日本語など,英語以外の言語の単言語パラレルコーパス が不足している現状を考えると,本研究で提案した疑似パラレルコーパスの自動構築手法は,こ れらのタスクにおいても有望である.
謝 辞
本研究は首都大学東京傾斜的研究費(全学分)学長裁量枠戦略的研究プロジェクト戦略的研 究支援枠「ソーシャルビッグデータの分析・応用のための学術基盤の研究」から部分的な支援 を受けた.
参考文献
Agirre, E., Banea, C., Cardie, C., Cer, D., Diab, M., Gonzalez-Agirre, A., Guo, W., Lopez- Gazpio, I., Maritxalar, M., Mihalcea, R., Rigau, G., Uria, L., and Wiebe, J. (2015).
“SemEval-2015 Task 2: Semantic Textual Similarity, English, Spanish and Pilot on In- terpretability.” InProceedings of the 9th International Workshop on Semantic Evaluation, pp. 252–263.
Agirre, E., Banea, C., Cardie, C., Cer, D., Diab, M., Gonzalez-Agirre, A., Guo, W., Mihalcea, R., Rigau, G., and Wiebe, J. (2014). “SemEval-2014 Task 10: Multilingual Semantic Tex- tual Similarity.” InProceedings of the 8th International Workshop on Semantic Evaluation, pp. 81–91.
Agirre, E., Cer, D., Diab, M., and Gonzalez-Agirre, A. (2012). “SemEval-2012 Task 6: A Pilot on Semantic Textual Similarity.” In*SEM 2012: The 1st Joint Conference on Lexical and Computational Semantics – Volume 1: Proceedings of the Main Conference and the Shared Task, and Volume 2: Proceedings of the 6th International Workshop on Semantic Evaluation, pp. 385–393.
Agirre, E., Cer, D., Diab, M., Gonzalez-Agirre, A., and Guo, W. (2013). “*SEM 2013 shared task: Semantic Textual Similarity.” In2nd Joint Conference on Lexical and Computational Semantics, Volume 1: Proceedings of the Main Conference and the Shared Task: Semantic Textual Similarity, pp. 32–43.
Bingel, J. and Søgaard, A. (2016). “Text Simplification as Tree Labeling.” InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics, pp. 337–343.
Bojar, O., Buck, C., Callison-Burch, C., Federmann, C., Haddow, B., Koehn, P., Monz, C., Post, M., Soricut, R., and Specia, L. (2013). “Findings of the 2013 Workshop on Statistical Ma- chine Translation.” InProceedings of the 8th Workshop on Statistical Machine Translation, pp. 1–44.
Bojar, O., Buck, C., Federmann, C., Haddow, B., Koehn, P., Leveling, J., Monz, C., Pecina, P., Post, M., Saint-Amand, H., Soricut, R., Specia, L., and Tamchyna, A. (2014). “Findings of the 2014 Workshop on Statistical Machine Translation.” InProceedings of the 9th Workshop on Statistical Machine Translation, pp. 12–58.
Bojar, O., Chatterjee, R., Federmann, C., Graham, Y., Haddow, B., Huck, M., Jimeno Yepes, A., Koehn, P., Logacheva, V., Monz, C., Negri, M., Neveol, A., Neves, M., Popel, M., Post, M., Rubino, R., Scarton, C., Specia, L., Turchi, M., Verspoor, K., and Zampieri, M.
(2016). “Findings of the 2016 Conference on Machine Translation.” In Proceedings of the 1st Conference on Machine Translation, pp. 131–198.
Bojar, O., Chatterjee, R., Federmann, C., Haddow, B., Huck, M., Hokamp, C., Koehn, P., Logacheva, V., Monz, C., Negri, M., Post, M., Scarton, C., Specia, L., and Turchi, M.
(2015). “Findings of the 2015 Workshop on Statistical Machine Translation.” InProceedings of the 10th Workshop on Statistical Machine Translation, pp. 1–46.
Callison-Burch, C., Koehn, P., Monz, C., Post, M., Soricut, R., and Specia, L. (2012). “Find- ings of the 2012 Workshop on Statistical Machine Translation.” InProceedings of the 7th Workshop on Statistical Machine Translation, pp. 10–51.
Chall, J. and Dale, E. (1995). Readability Revisited: The New Dale-Chall Readability Formula.
Cambridge, MA: Brookline Books.
Collins-Thompson, K. and Callan, J. P. (2004). “A Language Modeling Approach to Predicting Reading Difficulty.” In Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, pp. 193–200.
Coster, W. and Kauchak, D. (2011a). “Learning to Simplify Sentences Using Wikipedia.” In Proceedings of the Workshop on Monolingual Text-To-Text Generation, pp. 1–9.
Coster, W. and Kauchak, D. (2011b). “Simple English Wikipedia: A New Text Simplification Task.” In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pp. 665–669.
Flesch, R. (1948). “A New Readability Yardstick.” Journal of Applied Psychology, 32, pp. 221–233.