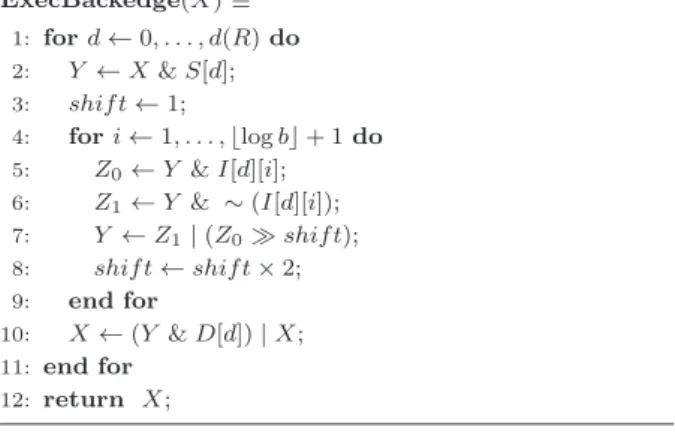社団法人 電子情報通信学会
THE INSTITUTE OF ELECTRONICS,
INFORMATION AND COMMUNICATION ENGINEERS
信学技報
TECHNICAL REPORT OF IEICE.
効率良い正規表現照合のための
並列ビット分配にもとづいたハードウェア指向アルゴリズム
金田 悠作
†吉澤 真吾
†湊 真一
†有村 博紀
†宮永 喜一
††
北海道大学 大学院情報科学研究科〒
060–0814
札幌市北区北14
条西9
丁目E-mail: †{ y-kaneta,minato,arim,miya } @ist.hokudai.ac.jp, †† [email protected]
あらまし 本稿では,重要なデータストリーム処理問題の一つである正規表現パターン照合に対して,ビット並列 型パターン照合手法に基づいた高速なハードウェア指向アルゴリズムを提案する.並列ビット分配と呼ぶ新しい ビット並列手法を用いて,文字と,連接,和,Kleeneプラスから構成される非消去的正規表現のクラスに対して,
O(mdlogb+m|Σ|)前処理時間とO(mdlogb/w+m|Σ|/w)領域を用いて,O(mdnlogb/w)実行時間の効率的な正規 表現照合アルゴリズムを与える.これはd, b,|Σ|が定数の場合に,O(mn/w)実行時間とO(m/w)領域の高速なアル ゴリズムを与える.ここで,nは入力長を表し,mと,d,bは,それぞれ,パターンの長さと,深さ,最大戻り幅を,
wは計算機のワード長,|Σ|はアルファベットの要素数を表す.さらに,このアルゴリズムを用いて,回路の再構成を 伴わずにパターンの変更を可能なハードウェア実装のアーキテクチャを示す.
キーワード ビット並列アルゴリズム,正規表現,パターン照合,ハードウェアアルゴリズム
An efficient hardware-oriented algorithm for regular expression matching based on parallel bit-distribution
Yusaku KANETA
†, Shingo YOSHIZAWA
†, Shin-ichi MINATO
†, Hiroki ARIMURA
†, and Yoshikazu MIYANAGA
†† Graduate School of Information Science and Technology, Hokkaido University N14 W9, Sapporo 060–0814, Japan
E-mail: †{ y-kaneta,minato,arim,miya } @ist.hokudai.ac.jp, †† [email protected]
Abstract In this paper, we study the regular expression matching problem for fast data stream processing. We present an efficient algorithm for based on new bit-parallel methods, called parallel scatter and gather exploiting bit–
parallelism in a computer word. Finally, we show an architecture for a hardware implementation of our algorithm.
The architecture can change its regular expression patterns on-the-fly without expensive reconfiguration.
Key words Bit-Parallel algorithm, Regular expression, Pattern matching, Hardware algorithm
1.
は じ め に1. 1 背 景
センサーデータやネットワークデータのような大規模かつ高 速なデータストリームに対する処理,すなわち,大規模データ ストリーム処理が注目されている.この種のデータストリーム に対する正規表現照合は,大規模データストリーム処理におい て重要な要素技術だが,一方で,処理全体の負荷が大きく,汎 用CPU上のソフトウェアによる実時間処理が難しい.そのた め,ハードウェアによる処理が注目されている[5], [7], [8].
これまでに著者らは,再構成可能ハードウェアのひとつであ るFPGA (Field Programmable Gate Array)を主な対象とし,
正規表現の部分クラスである線形正規表現に対して,良く知ら れたビット並列手法であるSHIFT-AND照合手法[4]にもとづ いたオンライン正規表現照合ハードウェアアルゴリズムを与え ている[7].本稿の目標は,より一般的な正規表現のクラスに対 して,これらの結果を拡張し,高速なハードウェアアルゴリズ ムを与えることである.さらに,その手法は,FPGA等のハー ドウェアにおいて,再構成を伴わずに動的にパターンを変更で きることが望ましい.
1. 2 本稿の結果
本稿では,正規表現の部分クラスである非消去的正規表現
(non-erasing regular expression)のクラスに対し,高速なハー ドウェアアルゴリズムを与える.非消去的正規表現は,文字 α∈Σと,連接·,和|, Kleeneプラス+からなる正規表現の部 分クラスである.アルゴリズムは,前処理として,入力の正規 表現を等価なNFAに変換し,これを一連のビットマスクにコ ンパイルする.実行時には,このビットマスクを用いて,論理 演算と加減算によってNFAの遷移計算を模倣する.
現在,一般の正規表現照合に対する理論上最速のアルゴリ ズムの一つとして,モジュール化DFA法[3]があるが,表引 き技法の多用により実装に適さないと考えられる.そこで,
本稿では,高速なビット並列手法であるSHIFT-AND手法を 拡張して,ビット分配(Scatter-Gather)と呼ばれるビット並 列手法とバレルシフタ(barrel shifter)と呼ばれるビット並列 手法を導入する.これらの手法は,FPGA等のハードウェア 実装にも適している.以上の技法の導入により,非消去的正 規表現のクラスに対して,O(mdlogb+m|Σ|)前処理時間と O(mdlogb/w+m|Σ|/w)領域を用いた,O(mdnlogb/w)時間 の照合アルゴリズムを与える.これは,d, b,|Σ|が定数の場合 に,O(m/w)領域とO(mn/w)時間であり,この制限の下で現 在最速のアルゴリズムを与える.
上記の結果は,非消去的正規表現のThompson NFAがε辺 の長い鎖を持たないという性質を利用している.任意のε辺を 許した一般の正規表現に対する本稿の手法の拡張は今後の課題 である.
1. 3 ハードウェア実装のアーキテクチャ
図1に,提案アルゴリズムのハードウェア実装のアーキテク チャを示す.アーキテクチャは,大きく分けてホスト(Host)と ハードウェア(Hardware)からなる.任意の非消去的正規表現 Rに対して,以下のように動作する.
(1) Rに対応するビットマスク集合を計算する(ホスト側)
(2) ビットマスク集合を設定する(ハードウェア側)
(3) パターン照合を実行する(ハードウェア側)
このアーキテクチャでは,パターンに依存する情報は,ビッ トマスク集合として表現され,回路構成はパターンに対して独 立である.したがって,パターンの変更する場合は,ビットマ スク集合のみを変更すればよく,回路の再構成は不要である.
パターンを実行時に動的に設定可能な手法としては,他に永 山らの手法[8]が提案されている.本手法,および永山らの手法 は,従来のパターンを実行前に静的に設定する手法[5]と比較 して,パターンが頻繁に変更される応用に適していると言える.
1. 4 関 連 研 究
正規表現照合問題の関連研究を示す.以下では,パターン長 をm=|R|とし,nをテキスト長,wを計算機のワード長と おく.最も基本的な仕事として,Thompson [6]は,正規表現を NFAへの変換を用いて,O(m)遅延時間とO(m)領域のアル ゴリズムを与えた.Myers [3]は,モジュール化DFA法と呼ぶ ビット並列手法を用いてこれを拡張し,O(1)遅延時間とO(2m) 領域のアルゴリズムを与えた.この手法は,ビットパターンの
図1 ハードウェア実装のアーキテクチャ
表引き計算を多用しているため,現実には大きな領域を必要と するという問題が指摘されている.
Bille [2]は,パターン長がm <=wを満たすとき,SHIFT- AND 法 と 再 帰 的 計 算 を 組 み 合 わ せ た O(mlogm/w) = O(logm)遅延時間とO(m/w)領域のアルゴリズムを与えた.
さらに,m <=w0.5を満たすとき,乗算とブール演算を用いた O(m/w) =O(1)遅延時間とO(m/w)領域のアルゴリズムを 与えた.
定数文字列のクラスに対して,SHIFT-AND手法[1]は,ビッ トシフトと論理積のブール演算のみを用いたO(m/w)遅延時
間とO(m/w)領域のアルゴリズムを与えている.この手法は,
文字クラス,無限長/有限長ギャップ,オプション文字などを 許すパターンに拡張されている[4].金田ら[7]はこれをFPGA 上のハードウェアアルゴリズムに適用している.
2.
準 備2. 1 文 字 列
N={0,1,2, . . .}で非負整数全体の集合を表す.記法[i..j]で 整数区間{i, i+ 1, . . . , j}を表す.もしi > jならば[i..j] =∅ とする.Σを文字のアルファベットとする.|Σ|でΣの要素数 を表す.Σ∗とΣ+ で,それぞれ,Σ上のすべての有限長文字 列の集合とすべての空でない有限長文字列の集合を表す.
長さ0の文字列を空文字列といい,εで表す.S=s1· · ·sn∈ Σ∗を任意の文字列とする.Sの長さを|S|=nと定義する.任 意の1<=i <=j <=nに対して,S[i]でSのi番目の文字を表し,
S[i..j] =si· · ·sjでi番目からj番目の文字からなる部分文字 列を表す.もしi > jならばS[i..j] =εとする.
2. 2 正 規 表 現
正規表現(regular expression)は,文字α∈Σおよび空語ε と,連接·,和|,Kleeneスター∗,Kleeneプラス+の演算か ら構成される表現である.本来,連接と和の演算子は二項関係 だが,これらに結合性を仮定し,((R1|R2)|R3) = (R1|R2|R3) のように書く.本稿では,このような非限定分岐(unbounded branching)を許した正規表現を考える.
[定義1] 正規表現Rを次のように帰納的に定義する.
(1) 空文字列εは正規表現である.
(2) 任意の文字α∈Σは正規表現である.
(3) も し R1· · ·Rn が 正 規 表 現 な ら ば ,(R1· · ·Rn) と (R1| · · · |Rn)は正規表現である.
(4) もしR1が正規表現ならば,(R∗1)と(R+1)は正規表現 である.
Σ上の正規表現全体のクラスをREGで表す.正規表現に対し ては,括弧を省略しないとする.これにより例えば,(A|B|C|D) と((A|B)|(C|D))は異なる正規表現と見なす.正規表現Rの 言語をL(R)⊂=Σ∗で表す.
本研究では,次の非消去的正規表現のクラスを考察する.
[定義2] 非消去的正規表現またはNE正規表現(non-erasing regular expression)は,α∈Σと,·,|, +のみからなる正規表 現である.
すなわち,NE正規表現は,空語εとKleeneスター∗を明示 的に含まない.N EREGで非消去的正規表現のクラスを表す.
2. 3 パターン照合問題
以下に,本稿で考察する正規表現照合問題を述べる.長さ n >= 0のテキストは文字列T =t1· · ·tnであり,パターンは 任意の正規表現R ∈ REG である.パターンRがテキストT 中に終端位置qで出現するとは,ある1 <=p <= nに対して,
T[p..q]∈L(R)が成立することをいう.
[定義3] 正規表現照合問題とは,入力として,長さn >= 0の テキストT =t1· · ·tnとパターンR∈ REGを受け取り,Rの T中のすべての終端出現位置を出力する問題である.
我々の目標は,正規表現照合問題を解く効率よいアルゴリズ ムを与えることである.本稿のアルゴリズムは,オンラインで ある.すなわち,任意のi= 1, . . . , nに対して,アルゴリズム は現在の入力T[1..n]の末尾のRの出現を出力可能である.
2. 4 ビットマスク
B =bm· · ·b1 ∈ {0,1}m を長さmのビットマスクとする.
bkでk個の連続するb∈ {0,1}からなるビットマスクを表す.
これをビットマスクの指数表現と呼ぶ.整数区間S= [0..m−1]
に対して,Bit(S)∈ {0,1}mでSのビットマスク表現を表す.
本稿では,計算モデルとして定数時間のブール演算と数値演 算をもつRAM機械を仮定する.ブール演算とは,ビットごと の論理積 & と,論理和 |,否定∼,排他的論理和∧,左ビッ トシフト,右ビットシフト ,であり,数値演算とは,加 算+と減算−である.これらの演算は,m <=wのとき,O(1) 時間で実行可能であり,m > wのとき,O(m/w)時間で実 行可能である.領域はレジスタ数ではかる.
3.
正規表現照合アルゴリズムの概要3. 1 アルゴリズムの概要
入力として与えられた非限定NE正規表現R∈ N EREGに 対して,アルゴリズムは次のように動作する.
(1) Rを構文解析してその構文木P(R)を構築する.
(2) 構文木P(R)から,RのTNFAN(R)を構築する.
(3) N(R)から,ビットマスク集合を構築する.
(4) 入力テキストTに対して,ビットマスク集合を用いた ビット並列計算によってN(R)のT上の動作を模倣する.
図2に,アルゴリズムの疑似コードを示す.
3. 2 構文木の構築
NE正規表現R∈ N EREGの構文木は,内部頂点のラベル
に演算子op∈ {·,|,+}をもち,葉のラベルに文字α∈Σをも つような根付き木である.アルゴリズムは与えられたRを構文 解析してその構文木P(R)を構築する.
Globalビットマスク集合;
Algorithm RegMatch(StringT,RegExpR) 1: //Preprocessing
2: 非限定正規表現Rに対する構文木P(R)を構築する;
3: ビットマスク集合を構築する;
4: //Searching 5: ExecMatch(T);
図2 提案アルゴリズムRegMatch
P(R)の深さd(R)を,その頂点の最大深さと定義する.Rの 各部分表現に対して,そのレベル(level)を,P(R)における対 応する部分木の根の深さ0<=d <=d(R)と定める.同じ形であっ ても,R中の出現位置が異なる部分表現は異なるレベルをもつ.
任意のレベルを0<=d <=d(R)とおく.レベルdに属するすべ ての部分表現の集合REG(d) ={Rd,1, . . . , Rd,n(d)}⊂=N EREG を,d番目の階層(layer)と呼ぶ.ここに,n(d) =|REG(d)|で あり,部分表現Rd,1, . . . , Rd,n(d)は,Rにおける左から右の出 現順に並んでいる.このとき,部分表現の出現Rd,jにおける 添え字jを,Rd,jのレベルdにおける順位(order)と呼ぶ.
3. 3 Thompson NFA
Thompson [6]は,与えられた正規表現から等価な言語を受
理するNFAを構築するアルゴリズムを示した. ここでは,NE 正規表現に限定した構成を与える.一般の構成に関しては,[6]
等を参照のこと.NFAは,N= (V, E, I, F)である.ここに,
• V は状態集合である.
• E⊂=V ×(Σ∪ {ε})×V は,Σ∪ {ε}の要素でラベル づけされた有向辺の集合で,N の遷移関係と呼ばれる.任 意 のβ ∈ Σ∪ {ε}に 対 し て ,β を ラ ベ ル に も つ 辺 の 集 合 Eβ = {(x, y)|(x, β, y) ∈ E}を定義する.文字α ∈ Σに 対して,Eαをα遷移(または文字遷移)と呼ぶ.Eεをε遷移
(または空遷移)と呼ぶ.
• IとF ∈V は,それぞれ,ただ一つずつの初期状態と終 状態である.
遷 移 関 係と は V 上 の 二 項 関 係 G⊂=V ×V で あ る .1 = {(x, x)|x ∈ V } を恒等関係という.任意の状態集合Q⊂=V に対して,Gの適用をG(Q) ={y ∈V|x∈Q,(x, y) ∈G} で定義する.遷移関係G, Hの合成を,G◦HまたはG·Hで表 し,G◦H={(x, z)|(x, y)∈G,(y, z)∈H}で定義する.Eε
の反射的推移閉包(Eε)∗⊂=V ×V をε閉包(ε-closure)と呼ぶ.
[定義4] 非限定NE正規表現R ∈ N EREGのThompson NFA(TNFAと略す)は次のように帰納的に定義される.
(1) R=α(∈Σ)に対応するTNFAは図3のとおり.
(2) R= (R1· · ·Rn)に対応するTNFAは図4のとおり.
(3) R= (R1| · · · |Rn)に対応するTNFAは図5のとおり.
(4) R= (R+1)に対応するTNFAは図6のとおり.
図3 R=α∈Σに対応するTNFA
図4 R= (R1· · ·Rn)に対応するTNFA
図5 R= (R1| · · · |Rn)に対応するTNFA
図6 R= (R+1)に対応するTNFA
正規表現Rが和R = (R1| · · · |Rn)の場合またはKleeneプ ラスR= (R+1)の場合を考える.RのScatter遷移関係(単 にScatter遷移)とは,Es[R] ={(I, Ii)|i= 1, . . . , n}と定 義される扇型のε遷移関係である.以後,Es[R]の任意の要素 をScatter辺と呼ぶ.RのGather遷移関係(単にGather遷 移)とは,Eg[R] ={(Fi, F)|i= 1, . . . , n}と定義される逆扇 型のε遷移関係である.以後,Eg[R]の任意の要素をGather 辺という.Rが上記以外の形の場合は,Es[R] =Eg[R] =∅と 定義する.
次に,正規表現RがKleeneプラスR= (R+1)の場合を考 える.RのBackedge遷移関係(単にBackedge遷移)とは,
Eb[R] ={(F1, I1)}で定義される逆向きのε遷移関係である.
以後,Eb[R]の任意の要素をBackedge辺という.Rが上記 以外の形の場合は,Eb[R] =∅と定義する.
正規表現RのTNFAをN(R)とする.Rの状態数=(R) をN(R) の状態数と定義する.Rの任意の部分表現R の TNFAをN(R) = (V, E, I, F)は,その状態集合が連続区 間V = [I..F]⊂=[1..]となるように構成する.さらに,文字遷 移は常に状態i−1から状態i(i∈[1..])となるように構成す る.この性質は,次節のアルゴリズムで重要である.
[定義5] 非 限 定 NE 正 規 表 現 R ∈ N EREG の戻 り 幅(backedge width)b(R)>= 0を次のように帰納的に定める.
(1) R=α(∈Σ)のとき,b(R) = 0.
(2) R = (R1· · ·Rn)またはR = (R1| · · · |Rn) のとき,
b(R) = maxni=1b(Ri).
(3) R= (R+1)のとき,b(R) =(R1)−1.
非限定NE正規表現Rに対して,そのTNFAN(R)はε遷 移を含む.しかし,その言語L(R)は空文字列εを含まないこ とが言える.さらに,NE正規表現RのTNFAN(R)に対し て,次の補題が成立する.
[補題1] R ∈ N EREGを任意の非限定NE正規表現とし,
N(R) = (V, E, I, F)をそのTNFAとする.このとき,Iから Fへのε路は存在しない.
[証明] TNFAN(R)の構造に関する帰納法によって示され
る.詳細は略する. 2
4.
並列ビット分配本節では,NE正規表現のクラスに対する遷移関係Esと, Eg,Ebを用いた効率よいε閉包の計算法を与える.
4. 1 空遷移の効率的計算
任意の0 <= d <= d(R)に対して,第d階層をREG(d) = {Rd,1, . . . , Rd,n(d)}とおき,その任意の部分表現をR=Rd,j∈ REG(d)とおく.前節の定義にしたがって,RのScatter遷 移関係と,Gather遷移関係,Backedge遷移関係をEs[R]と,
Eg[R],Eb[R]とおく(図5と図6).
任意のタイプをτ ∈ {s, g, b}とおく.このとき,第d階層 REG(d)内のタイプτの遷移関係を次で定義する.
Eτd=Eτ[Rd,1]∪ · · · ∪Eτ[Rd,n(d)]
入力の正規表現Rにおいて,全階層のEτdの和を
Eτ =Eτ0∪ · · · ∪Edτ
と定義する.で直和を表す.次の補題は,TNFAN(R)のε 遷移は,
[補題2] Eε=EsEgEb.
上の補題より,N(R)のε閉包は,(Eε)∗= (Es∪Eb∪Eg)∗ となる.しかしこの定義通りの|V|回の計算では効率が悪い.
そこで,TNFAの構成に従った順序で評価することで効率よい 計算を行うことを考える.
[補題3] 任意のNE正規表現Rに対して,次が成立する.
(Es)∗= (Es0◦ · · · ◦Esd(R)) ∪ 1.
[証明] 左辺⊂=右辺の方向を示す.反対向きは自明である.ま ず,Scatter辺だけで状態xから状態yへ到達可能であると仮 定する.このとき,Scatter辺の構成より,このxからyまで の路で,部分正規表現の初期状態だけを通るものがある.さら に,この路のレベル(深さ)は,真の増加列であることが示せ る.これより,レベルd= 0, . . . , d(R)で,トップダウンに各 階層の遷移Esdを実行すれば,xからyへ到達可能である.2
[補題4] 任意のNE正規表現Rに対して,次が成立する.
(Eg)∗= (Edg(R)◦ · · · ◦Eg0) ∪ 1.
[証明] Gather辺は,レベルd+ 1の終状態からレベルdの 終状態へ向かう性質を用いると,Scatter遷移に関する先の補
題と同様に証明可能である. 2
[補題5] 任意のNE正規表現Rと0, . . . , d(R)の任意の並べ 替えπ(0), . . . , π(d(R))に対して,次が成立する.
(Eb)∗= (Ebπ(0)◦ · · · ◦Eπb(d(R))) ∪ 1.
[証明] Rの異なる場所に出現するすべて部分式R, R に対して,それらのBackedge辺同士は,互いに状態を共有 しない.これより,Backedge辺だけからなる長さが1より 真に長い辺は存在しない.よって,任意のn >= 1に対して,
(Ebd(R)∪ · · · ∪Eb0)n= (Ebd(R)◦ · · · ◦E0b)n= (Edb(R)◦ · · · ◦E0b) が成立する.よって主張を示すことができる. 2
次の定理は本節の主結果である.
[定理1] 任意の非限定NE正規表現RとそのTNFAN(R)の ε閉包(Eε)∗に対して,次が成立する.
(Eε)∗=
⎛
⎜⎝
Egd ◦ · · · ◦ Eg0
◦Ebd ◦ · · · ◦ Eb0
◦Es0 ◦ · · · ◦ Esd
⎞
⎟⎠
ここに,d=d(R)である.ただし,Backedge遷移は,任意の 順番で実行した場合にも成立する.
[証明] 非限定NE正規表現Rにおいて,状態xから状態y へ(Eε)∗で到達可能ならば,ある頂点zが存在して,xからz へ(Eg)∗で到達可能であり,さらに,(i)zからyへ(Es)∗で到 達可能であるか,(ii)ある頂点wが存在して,zからwへEb
で到達可能であり,wからyへ(Es)∗で到達可能であるかのい ずれかである.これより題意が示された. 2
この定理より,ε遷移関係をレベル毎に分割し,さらに,こ れらを適切な順番で実行することで,ε閉包を効率よく計算で きることがわかる.
5.
ビット並列による模倣5. 1 構成の概要
トップレベルの正規表現RのTNFAをN(R)とし,=|V| をその状態数とする.N(R)の任意の状態集合Q⊂=V は,幅 のビットマスクX∈ {0,1} で表現される.Rの構文木P(R) の階層をREG(0), . . . , REG(d(R))とおく.
前処理では,任意のタイプM ∈ {S, D, I}とレベル0<=d <= d(R)に対して,まず,第d階層内の各正規表現Rd,j∈REG(d) に対応する断片ビットマスクM[Rd,j]を構築する.第d階 層のビットマスクは,これらの断片ビットマスクの論理和 M[d] =|j=1,...,n(d)M[Rd,j].で定義する.
実行時には,各0<=d <=d(R)に対して,構築したビットマ スク集合を用いた更新式を用いて,第d階層REG(d)に対応 するRの状態遷移を模倣する.
以下では,次の記法を用いる.処理対象の第d階層内の要素正 規表現R=Rd,j∈REG(d)のTNFAをN(R) = (V, E, I, F) とおく.Rがn >= 0個の子を持つならば,i= 1, . . . , n番目の 子RiのTNFAをN(Ri) = (Vi, Ei, Ii, Fi)とおく.以下に,演 算子の種類ごとに,任意の部分表現R=Rd,j∈REG(d)に対 するビットマスクの構成を与える.
5. 2 α 遷 移
部分表現Rが,文字遷移R=α ∈Σの場合は,
CH[α][Rd,j] =Bit({I+ 1})
と定義し,それ以外の形の正規表現Rの場合か,異なる文字
による文字遷移R =β(α=β)の場合には,CH[α][Rd,j] = Bit(∅) = 0と定義する.第d階層のビットマスクは,上記の とおりに定める.
[補題6] Rを任意の非限定NE正規表現とする.このとき,
任意のα∈ΣとQ⊂=V に対するα遷移Eα の計算を,以下の 更新式で模倣できる.
ExecMove(X, α)≡
1: X←((X1)|0−11) &CH[α];
2: return X;
5. 3 Scatter遷移
部分表現R がR = (R1| · · · |Rn)またはKleeneプラス R= (R+1)の形の正規表現である場合は,
S[R] = Bit({I}), D[R] =Bit({I1, . . . , In}), I[R] = Bit({F})
と定義する.それ以外の場合は,S=D=I=Bit(∅) = 0と 定義する.
[補題7] 任意のQ⊂=V に対するEs0◦ · · · ◦Esd(R)の計算を,以 下の更新式で模倣できる.
ExecScatter(X)≡ 1: ford←0, . . . , d(R)do
2: X←((I[d]−(X&S[d])) &D[d])|X; 3: return X;
5. 4 Gather遷移
部分表現R がR = (R1| · · · |Rn)またはKleeneプラス R= (R+1)の形の正規表現である場合は,
S[R] = Bit({F1, . . . , Fn}), D[R] =Bit({F}), I[R] = Bit(V1∪ · · · ∪Vn)
と定義する.それ以外の場合は,S=D=I= 0と定義する.
[補題8] 任意のQ⊂=V に対するEgd(R)◦ · · · ◦Eg0の計算を,以 下の更新式で模倣できる.
ExecGather(X)≡ 1: ford←d(R), . . . ,0do
2: X←((I[d] + (X&S[d])) &D[d])|X; 3: return X;
5. 5 Backedge遷移
Backedge遷移の模倣は,他のε遷移と異なり,加減算では
困難な上位から下位への逆位のビットコピーが必要である.こ
のため,Backedgeでは,論理回路の「バレルシフタ」のアイ
ディアを借用して,任意幅bの逆位のビットコピーを,2のべ き乗幅の右シフトに分解することで実現する.
部分表現RがKleeneプラスR= (R+1)の形の正規表現で ある場合は,
S[R] =Bit({F1}), D[R] =Bit({I1})
と定義する.それ以外の場合は,S=D=I= 0と定義する.
長さのビットマスクの二次元配列I[0..d(R)][1..logb+ 1]
ExecBackedge(X)≡ 1: ford←0, . . . , d(R)do 2: Y ←X&S[d];
3: shif t←1;
4: fori←1, . . . ,logb+ 1do 5: Z0←Y &I[d][i];
6: Z1←Y & ∼(I[d][i]);
7: Y ←Z1|(Z0 shif t);
8: shif t←shif t×2;
9: end for
10: X←(Y &D[d])|X; 11: end for
12: return X;
図7 Backedge遷移の更新式
は,各i= 1, . . . ,logb+ 1に対して,
I[R][i] =
Bit(V1), ((b (i−1)) mod 2 = 0), Bit(∅), (otherwise).
と定義する.ここに,b=b(R)はRの戻り幅である.これ以外 のときは,I[R][i] = 0と定め,I[d][i] =|j=1,...,n(d)I[Rd,j][i]
と定める.
次の補題に,上で構築したマスクを用いたBackedge遷移の 模倣アルゴリズムを示す.
[補題9] 任意のQ⊂=V に対するEb0◦ · · · ◦Ebd(R)の計算を,図 7の更新式で模倣できる.
5. 6 パターン照合アルゴリズム ExecEpsCloを次の手続きとする.
ExecEpsClo(X) ≡
1: X←ExecScatter(ExecBackedge(ExecGather(X)));
2: return X;
図8にパターン照合の実行時アルゴリズムを示す.これは,
前節までに構築したマスクを用いて,テキストT =t1· · ·tnに 対する正規表現Rのパターン照合を行う.
Algorithm ExecMatch(StringT =t1· · ·tn) 1: X←0−11; //Initialize
2: X←ExecEpsClo(X); //Simulate (Eε)∗ 3: fori←1, . . . , ndo
4: X←ExecMove(X, ti); //SimulateEα 5: X←ExecEpsClo(X); //Simulate (Eε)∗ 6: ifX= 10−1then
7: output1; //match found 8: end for
図8 Matchアルゴリズムの枠組み
以上から,次の定理が成立する.
[定理2] 非限定NE正規表現のクラスN EREG に対する 正 規 表 現 照 合 問 題 は ,O(mdlogb +m|Σ|) 前 処 理 時 間 と O(mdlogb/w+m|Σ|/w)領域を用いて,O(mndlogb/w)時間 で解ける.ここに,d=d(R)はRの深さであり,b=b(R)は 戻り幅である.
実用的観点から,次の系は重要である.
[系3] 正規表現の深さdと戻り幅b,|Σ|,|Σ|が定数のとき,
NE正規表現のクラスに対する正規表現照合問題は,O(m)前処 理時間とO(m/w)領域を用いて,O(m/w)遅延時間で解ける.
6.
お わ り に本稿では,ビット並列型パターン照合手法にもとづいた正規表 現照合アルゴリズムを提案した.このアルゴリズムは,正規表現 の部分クラスREG[Σ,·,|,+]に対して,O(mdlogb+m|Σ|)前処 理時間と,O(mdlogb/w)遅延時間,O(mdlogb/w+m|Σ|/w) 領域で動作する.ここで,mと,d,bは,それぞれ,パターンの 長さと,深さ,戻り幅を表す.dとbが定数の場合は,O(m|Σ|) 前処理時間と,O(m/w)遅延時間,O(m|Σ|/w)領域で動作 する.
また,提案アルゴリズムのハードウェア実装のアーキテク チャを与えた.このアーキテクチャでは,パターンに依存する 情報は,ビットマスク集合として表現される.そのため,ハー ドウェア側に設定するビットマスク集合を変更することで,回 路の再構成を伴わずにパターンの変更が可能である.
本稿では,主に提案アルゴリズムの計算機ワード上での実現 について考察した.ハードウェア上の回路への拡張は,今後の 課題である.
文 献
[1] R. Baeza-Yates and G. H. Gonnet. A new approach to text searching. Communications of the ACM, Vol. 35, No. 10, pp. 74–82, 1992.
[2] P. Bille. New algorithms for regular expression matching.In Proc. of the 33rd International Colloquium on Automata, Languages and Programming(ICALP), pp. 643–654, 2006.
[3] E. W. Myers. A four-russian algorithm for regular expres- sion pattern matching.Journal of the ACM, Vol. 39, No. 2, pp. 430–448, 1992.
[4] G. Navarro, and M. Raffinot. Flexible Pattern Matching in Strings: Practical On-Line Search Algorithms for Texts and Biological Sequences. Cambridge University Press 2002.
[5] R. Sidhu and V. K. Prasanna. Fast regular expression matching using FPGAs. In The 9th Annual IEEE Sym- posium on Field-Programmable Custom Computing Ma- chines(FCCM 2001), pp. 227–238, 2001.
[6] K. Thompson. Programming techniques: regular expression search algorithm. Communications of the ACM, Vol. 11, No. 6, pp. 419–422, 1968.
[7] 金田悠作,吉澤真吾,湊真一,有村博紀,宮永喜一.高速スト リーム処理のための文字列パターン照合手法とそのFPGA設 計.電子情報通信学会2009年総合大会,2009.
[8] 川中洋祐,若林真一,永山忍.パターンを実行時に設定可能な 正規表現ストリングマッチングマシンとFPGAによる実装.情 処研究報告,2008-SLDM-133,pp. 61–66,2008.