1.は じ め に
1990年代,「未知の環境」における行動獲得の手段 として強化学習 [Sutton 98, Watkins 92] が注目された. ここでの「未知」とは,対象とする環境のモデル*1を エージェントも,その設計者ももたない.したがって逐 次的な教師信号は期待できないことを指す.唯一,ゴー ルとなる状態に対して報酬というスカラ量さえ定義でき れば,後は試行錯誤に委ねられる設計者フリー,モデル フリーであることが強化学習の最大の売りであった.当 時の進化計算アルゴリズムをはじめとする創発志向アル ゴリズム研究の一端を担い,その後の 10 年は学習性能 の向上を目指した階層化,モデルの導入,あるいは,状 態観測の不完全性(Partiall Observability)[木村 97], マルチエージェント系での収束性 [Hu 03, Littman 94, Littman 01, Wang 02]などのシナリオで研究が進められ てきた. 1998年,強化学習で所与とされる「報酬」,「状態空 間」の設計が案外難しいということに人々が気付き始 めた頃,U. C. Berkeley の Stuart Russell [Russell 98],Ng [Ng 00]らによって,モデルから報酬を推定する逆 強化学習の考え方が示された.さらに 2004 年には同グ ループの Abbeel [Abbeel 04] らが,行動軌跡から報酬 を推定する見まねベースの逆強化学習,2004 年以後は さまざまな逆強化学習が提案され,2011 年には Levine [Levine 11]らが逆強化学習を用いて報酬と特徴*2空間 設計を相互に改善する FIRL の提案が相次いだ. この流れに相まって,深層学習がにわかに注目され, そこに強化学習を導入した深層強化学習による Atari [Mnih 15a, Mnih 15b]の成功を受けて,再度強化学習が 注目されている.しかし,教師なし・教師ありで二分さ れてきた機械学習のうち,強化学習はその立ち位置が明 らかではなく,機械学習の解説書においても,AlphaGo [Silveret 16]や Atari など深層学習に付随する形で 1990 年代の創発志向の強化学習が紹介されている.深層強化 学習として話題の DQN(Deep Q network)は,代表的 な強化学習の一つである Q 学習 [Watkins 92] の関数近 似器として深層学習を導入している.これらの基本形は Linら [Lin 92] であり,多層のニューラルネットワーク による関数近似を用いた強化学習は柴田ら [Shibata 09] が適用例を示している. 従来,パターン分類などの診断型とプランニングに代 表される合成形の問題解決は人工知能研究の両輪として 位置付けられてきた.認識精度とプランの最適性は相互 に影響し,切り離すことは難しい.前者に対しては,深
強化学習における脱創発志向の潮流
試行錯誤〜見まね〜目的理解へ
Trend Away from a Bottom-Up to a Top-Down
荒井 幸代
千葉大学大学院工学研究院都市環境システムSachiyo Arai Department of Urban Environment Systems, Graduate School of Science and Engineering, Chiba University. [email protected]
石川 翔太
(同 上)Shota Ishikawa [email protected]
中田 勇介
(同 上)Yusuke Nakata [email protected]
北里 勇樹
(同 上)Yuki Kitazato [email protected]
Keywords:
inverse reinforcement learning, apprenticeship learning, behavior cloning, generative adversarial networks.「深層学習周辺の最新動向」
層学習が認識精度を飛躍的に向上させたが,後者に対し ては強化学習が期待されている.その理由は,教師なし であることや,報酬の遅れ(delayed reward)を許容す ることがあげられる.しかし,前述のとおり「報酬」と 「状態空間」の設計問題が実問題適用におけるボトルネッ クである.状態空間に関しては Atari [Mnih 15a, Mnih
15b]のように何も考えずにそのまま画像を入力すること も可能であるが,画像のどんな特徴が状態を表象するの かに対する方策の説明可能性(explainablity)という新 たな課題を生んでいる. 一方,報酬設計問題とは,「試行錯誤によってゴール を実現したときに限り,報酬を与える」という強化学習 の基本形は,大規模な環境に対して限界があることを指 す.AlphaGo にしても「勝ち」というゴール状態に至る 行動(手の)系列は長大であるし,ゴールに着く前に負 け続ければ方策を得ることはできない.実際,人間と同 様に過去の名人の棋譜に基づいた強化を行っている.囲 碁と同様に実問題は,望ましい軌跡が既知であることが 多く,試行錯誤だけによってプランニング問題を解くわ けではなさそうである.それでは,この挙動を逐一コピー すればよいのか? エキスパートの軌跡をまねる方法として Behavioral cloning [Pomerleau 91]があるが,エキスパートの行動 軌跡が再現できても,(1)エキスパートの目指すゴール (状態)の価値を知ることはできない.また,図らずも (2)エキスパートの辿る軌跡(状態系列)を踏み外した ら,途方にくれるしかない.(1)に対しては報酬関数を 求めること,(2)に対しては各状態に対する方策を求め ておくことが必要になる.逆強化学習によって得られる 報酬関数はこの課題に対する一つのアプローチである. 本稿では,報酬設計に焦点を当て,報酬関数を同定す る逆強化学習を取り上げる.2 章では準備として必要な 記号と基本概念を整理し,3 章で逆強化学習の考え方と 課題を示す.続く 4 ~ 6 章で各課題に対して提案されて いるアルゴリズムを概観し,7 章でまとめる.
2.準 備
本稿の理解に必要なマルコフ決定過程,強化学習の基 礎理論に加え,代表的な逆強化学習である Ng [Ng 00] と Abbeel [Abbeel 04] の方法を説明する.表 1 に必要な 記号の定義をまとめる. 2・1 マルコフ決定過程マルコフ決定過程(Markov Decision Process :MDP) は,エージェントの行動による状態遷移にマルコフ性を 仮定した数学モデルである. 本稿の対象とする有限マルコフ決定過程は S, A, Pa ss′, γ, R からなる.S は有限状態集合,A は行動集合,Pa ss′ は状態 s ∈ S で行動 a ∈ A ととったとき,次状態 s∈ S に遷移する確率である状態遷移確率,γは割引率,R:S R は状態 s ∈ S に遷移したときに報酬 r を返す報酬関数 を表す. 2・2 強 化 学 習 強化学習 [Sutton 98] は,状態遷移確率など環境モデ ルを所与とせずに,最適な方策を獲得する方法である. 学習主体であるエージェントには,状態入力に対する正 しい出力を明示した教師信号はなく,報酬と呼ばれるス カラ量によって学習する.一般に,エージェントはこの 報酬の期待総和を最大化する方策を学習する. 本研究の対象とする強化学習では,環境モデルを S, A, R, π とする.ここで方策πは状態 s から可能な行動 aを選択する確率である.エージェントは時刻 t におい て状態 st∈ S を観測し,自身の方策πtに基づいて行動 at∈ A を選択する.その後,時刻( t+1)では st,atによっ て確率的に次状態 st+1に遷移し,報酬 rtを得る.獲得 した報酬から価値関数 V(s)または行動価値関数 Q(s, a) を生成し,その値を用いて方策の評価と改善を行う.価 値関数 V(s),行動価値関数 Q(s, a)は方策πが与えら れたとき,それぞれ式(1),式(2)を満たす. Vπ(s) = R(s) + γ s Pssπ(s)Vπ(s ) (1) Qπ(s, a) = R(s) + γ s Pssa Vπ(s ) (2)
3.逆強化学習の基本アルゴリズム
逆強化学習は,エージェントが学習すべき所望の軌跡, あるいは利用可能な環境モデル(状態遷移確率)を所与 として報酬関数を推定する枠組みである.逆強化学習は その目的の違いから reward learning と apprenticeship learningに大別される [Ramachandran 07].前者は所 与とした軌跡の報酬関数を推定することにより,その軌 跡が何を目的に生成されたかを発見しようとする立場 で,Russell ら [Hadfield-Menell 16, Ng 00, Russell 98] はこの立場である*3.これに対して [Abbeel 04, Babes表 1 主な記号の定義
11, Neu 07, Syed 08a, Ziebart 08]は軌跡から方策を獲得 しようと後者の立場である.ここでは前者から [Ng 00] を,後者から [Abbeel 04] のアルゴリズムをそれぞれ紹 介する. 3・1 Ng の逆強化学習:reward learning [Ng 00]では逆強化学習を下記の二つに大別してい るが,ii)の問題については 3・2 節に委ね,本章では reward learningとして位置付けられ,離散化された状 態に対する定式化を紹介する. i)全状態の最適行動が所与. ● 離散化された状態空間(方策はテーブル表現). ● 連続の状態空間(関数近似). ii)軌跡が所与. Ngら [Ng 00] は,MDP から報酬関数 R を除くS, A, Pa ss′, γ と各状態 s における最適行動 a1を所与とし,報 酬関数 R を推定する問題を,式(3)に示す線形計画問 題として定式化した. 目的関数:maximize M i=1 min a∈a2,··· ,ak − {(Pa1(i)− Pa(i))(I− γPa1)−1R} λ||R||1 (3) 制約条件:subject to :
(Pa1− Pa)(I− γPa1)−1R≥ 0, ∀a ∈ A\a1 |Ri| ≤ Rmax, i = 1,· · ·, M (4) ここで,状態遷移行列 Paは状態遷移確率 Pi, ja の(i, j) 成分を要素とする M×M 行列,状態遷移ベクトル P(i)a は Paの第 i 行ベクトルを表す.M は全状態数である.λ はペナルティ係数で報酬の総量を調節するパラメータで ある. 式(4)は各状態の最適行動 a1から導かれる報酬の期 待値(Q 値)が,最適行動以外の行動の Q 値より大き くなることを保証する制約条件である.その導出を式(5) から式(9)に示す.最適行動 a1は各状態において最大 の Q 値を獲得することから,式(5)となる. ∀s ∈ S, a1≡ π(s) ∈ arg max a∈A R(s) + s Pssa Vπ(s ) (5) 各状態において,(最適行動 a1の Q 値)>(他行動の Q値)であるため,式(2)の比較により式(6)が導か れる. ∀s ∈ S, a ∈ A, s Pa1 ss V π(s ) ≥ s Pssa Vπ(s ) (6) 状態価値関数ベクトル Vπ={V(sπ i)}Mi=0,報酬関数ベク トル R={R(si)}Mi=0を定義すれば,式(6),式(1)はそれ ぞれ式(7),式(8)と書き直せる. Pa1Vπ ≥ PaVπ (7) Vπ = R + γPa1V π (8) 式(8)を Vπについて解き,式(7)に代入した後に整 理すると,制約条件である式(9)が導かれる. (Pa1− Pa)(I− γPa1)−1R≥ 0 (9) 式(3)に示す目的関数の第 1 項は最適方策と 2 番目に良 い方策から導かれる Q 値との差を最大化に供し,式(10) と等価である.第 2 項は総報酬量を最小化する項で,複 雑な報酬関数より単純な報酬関数のほうが望ましいとの 考えに基づく. s (Qπ(s, a1)− max a∈A\a1 Qπ(s, a)) (10)
3・2 Abbeel の逆強化学習:apprenticeship learning Abbeelらの逆強化学習 [Abbeel 04] は,エキスパート の状態遷移系列から特徴空間中での報酬関数 R を推定す る.状態空間 S が p 個の特徴を要素とした特徴ベクトル : S[0, 1]pを用いて表現可能であると想定すると,状 態 s ∈ S に与えられる報酬関数ベクトル R(s)は特徴ベ クトル (s)と重みパラメータ の内積式(11)で表さ れる. R(s) = θ· φ(s), θ∈ Rp (11) は特徴の重みを表し,その定義域は報酬の最大値を 1以下に保つために,∥∥2 ≤ 1とする.方策πのもと で観測される特徴の期待値を特徴期待値 (π)と呼び, 式(12)で定義される. µ(π) = E ∞ t=0 γtφ(st)|π ∈ Rp (12) 特に,エキスパートの U 個の状態遷移系列 {su 0, su1, 表 1
…}U u=1が与えられたとき,エキスパートの特徴期待値 E=(πE)は,式(13)によって求められる. µE= 1 U U u=1 ∞ t=0 γtφ(sut) (13)
Abbeelらの方法では Projection Method と呼ばれる 表 1(Algorithm1)の手続きを通して,エキスパートの 特徴期待値 Eと推定した特徴期待値 (π)の誤差を最 小化する特徴ベクトルの重み を繰返し計算によって推 定する. 3・3 逆強化学習の課題 3章で紹介した逆強化学習アルゴリズムの課題として 以下の三つをあげる. 課題 1:ある最適方策を導く報酬関数が複数存在する という不良設定問題(ill-posed problem). 課題 2:報酬を更新する過程で,推定報酬を用いた強 化学習によって方策を獲得し,エキスパートの方策 と比較する必要がある.この Inner Loop の強化学 習に要する計算量問題. 課題 3:環境のダイナミクスに関する事前知識の利用. 以下の章では各課題に対する提案を概観する.
4.報 酬 の 最 適 化
本章では,ある最適方策を導く報酬関数が複数存在し 得ることを示す.また,適切な一つの報酬関数の推定に 最適化法を導入した研究を取り上げ,各目的関数を紹介 する. 4・1 複数の報酬関数の存在 3・1 節において,Ng らは最適方策を導く報酬関数が式 (9)の制約条件を満たす必要があることを示した.この 制約条件を満たす報酬関数が複数存在することを,状態 数 |S|=2 の問題を例に,直観的に説明する.この問題 の制約条件を図 1 に示す.横軸が状態 1 の報酬値,縦軸 が状態 2 の報酬値である.塗りつぶされた実行可能領域 (Feasible region)に存在する報酬関数はすべて最適方策 を獲得する.すなわち,式(9)の制約条件を満たす報 酬関数は複数存在し得る.ここで制約を充足するだけで なく,何らかの目的関数を導入した報酬関数の最適化問 題として逆強化学習を拡張することが考えられる. 線形の目的関数を設定した場合,一般に線形計画問題 では制約条件の交点が解となるため,図 1 に示した複数 の最適解(multiple optimal solution)が得られる.一 方で,後述する Abbeel らの目的関数のような非線形の 目的関数では,multiple optimal solution として示した 点ではなく,実行可能領域内のいずれかの点が最適解と なる.そのため,目的関数が非線形の場合には,線形の 場合よりも不良設定問題における探索の指針を定めるこ とが困難となる. ここで,最適方策を導く報酬関数を見つけることと, 最適な報酬関数を見つけることを区別していることに注 意されたい. 4・2 報酬の最適化における目的関数 前述したとおり,最適方策を導く報酬関数が複数存在 することから,実際の問題に適用する場合は,報酬関数 を一本化する必要がある.既存の方法では複数の報酬関 数の中から,「所与とした最適行動の再現」という観点 から目的関数を定義し,最適化問題として解いている. 代表的な方法における目的関数を以下にまとめる. Ngらは 3・1 節で示したとおり,最適な行動の Q 値が 他の行動の Q 値よりも可能な限り大きくなる報酬関数を 推定する.この目的関数を用いることにより,各状態に おいて最適行動以外の行動は最適行動に比べ期待報酬が 小さくなることから,選ばれにくくなる. Abbeelら [Abbeel 04] の目的関数は式(14)となる. min θ ||µθ− µE||, s.t.||θ||2≤ 1 (14) 式(14)は推定した報酬関数により学習した特徴期待 値μθとエキスパートの特徴期待値μEの差を最小化す る.特徴期待値は遷移した状態と時間の要素を含んでお り,特徴期待値が一致する重みを選択することにより, エキスパートと同等の振舞いを実現する.Syed ら [Syed 08a]の目的関数は Abbeel らの方法の性能を改善するた めに提案されたもので,式(15)に示す. min θ θ(µθ− µE), s.t. θ≥ 0, θ = 1 (15) 式(15)において,重みと特徴期待値の積μθは平均期 待報酬値とみなせるため,エキスパートと同等の平均期 待報酬値となるような重みを推定する.特に,特徴期待 値のノルムの差をとるのではなく,平均期待報酬として 考えることにより,より正確な推定を行う. Neuら [Neu 07] の目的関数を式(16)に示す. 図 1 ある方策を再現する報酬の実行可能領域min θ s∈S,a∈A νE(s)(πθ(a|s) − πE(a|s))2 s.t. πθ= G(Q*θ) (16) ここでνE(s)=1/n・ N t=1 I(st=s)∀s∈S は各状態の 出現頻度,π(a|s)は状態 s において行動 a をとる確率, G(Qθ*)は重みで計算される最適 Q 値のボルツマン分布 に従った行動選択を表す.この目的関数はエキスパート の方策と推定方策の直接的な近似を行う.
Ziebartら [Ziebart 08] による Maximum Entropy IRL (以下,MaxEnt IRL)では,逆強化学習に最大エントロ ピーの原理を適用し,軌跡の確率分布のパラメータ(報 酬が確率分布のパラメータ)を最尤推定で求める問題と して再定式化している.その結果,特徴期待値が一致す る軌跡の分布が複数存在する,という解の曖昧さが解消 されている.具体的には,特徴期待値との一致の制約下 で式(17)に示す目的関数を最大化する. max θ − ζ∈Z P (ζ|θ) log P (ζ) s.t. ζ∈Z P (ζ)φ(ζ) =EPE(ζ)[φ(ζ)], ζ∈Z P (ζ) = 1 (17) ζは軌跡,Z は軌跡の全体集合を表す.上式をラグラ ンジュの未定乗数法で解けば,P(ζ|)∝ exp(T(ζ)) が得られる.ここで,ラグランジュ乗数θは報酬の重み に相当し,P(ζ|)は,重みθのもとで軌跡が得られる 確率を示す. 所与の軌跡集合 D に対する尤度関数を式(18)に示す. ζ∈D PE(ζ) ˙logP (ζ|θ) (18) 式(17)におけるラグランジュ乗数の推定は,式(18) の最大化と等価であり,対数尤度の最大化でθを求める ことができる.MaxEnt IRL は凸性,微分可能性など優 れた性質をもつ最適化問題とした学習であり,この研究 以後,MaxEnt IRL に基づいた各種最適化理論の適用 が試みられている.また,実装も比較的容易なため,論 文の比較実験に用いられることも多く,最近の代表的な 逆強化学習アルゴリズムといえる.ここでは報酬関数は 離散であるが,深層ニューラルネットで近似した Deep MaxIRL [Wulfmeier 15]もある.ただし,MaxEnt IRL は確率分布の分配関数を動的計画法で求めるため,対象 問題の状態行動空間が小さい問題に限られる.この課題 について 5 章の Inner Loop における計算の高速化法で 取り上げる. 以上,ここで紹介した方法は,それぞれ異なる目的関 数を導入することによって複数の報酬関数から最適な関 数を獲得しているが,いずれも複数の報酬関数のうち, エキスパートの行動の再現性を高める目的関数となって いる.しかし,他にもさまざまな目的関数を導入するこ とは可能で,例えば,収束効率を最大化するなど他の目 的関数の導入も考えられる [Kitazato 18].
5.推定報酬更新の効率化
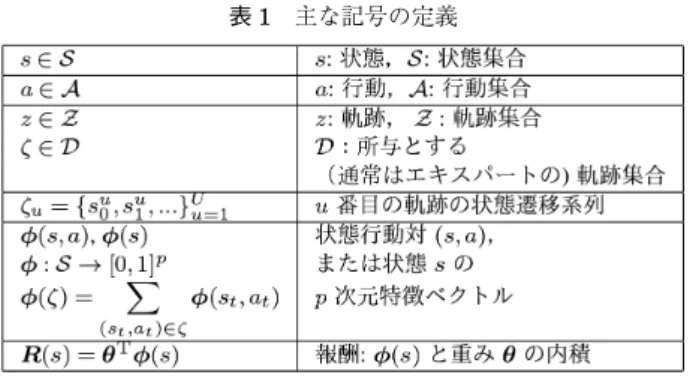
3・3 節の課題 2 であげたとおり,報酬関数を最適化す る過程で,推定報酬を用いた強化学習によって方策を獲 得しエキスパートの方策と比較する必要がある.この Inner Loopと呼ばれる段階にかかる莫大な計算コスト が逆強化学習のボトルネックになっている.本章では, はじめに,MaxEnt RL [Ziebart 08] における離散空間 でのグラフを用いた特徴期待値の計算法を整理し,次に, Inner Loopの強化学習を経ずに報酬や方策を推定する方法を紹介する [Boularias 11, Uchibe 16a, 内部 16b]. 5・1 状態遷移グラフに基づく特徴期待値の伝搬 MaxEnt IRLについて 4・2 節で報酬関数の最適化に関 して説明したが,基本的には, のときのある軌跡ζの 発生確率を P(ζ|)∝ exp(T(ζ))として,所与の軌 跡集合 D の対数尤度 L(D|)= i ln P(ζi|)を最大 化する重みベクトル *を推定する.*は式(19)で計 算される.このとき,L(D|)の勾配は式(20)の第 1 項(推定報酬の特徴期待値)と第 2 項:(所与の特徴期 待値)の差となる. θ*= argmin は正規化項. θ (L(D|θ) + Ω(θ)), Ω(θ) (19) ∂L(D|θ) ∂θ = s∈S,a∈A D(s)πθ(a|s)φ(s, a) − Ei[φ(ˆζi)] (20) この勾配計算に状態間の関係を示すグラフを用いたア ルゴリズムを以下に示す. 図 2 にグラフを用いた特徴期待値計算手順の概要を示 す.グリッド環境の各状態 s をノード,行動 a をエッジ, 状態遷移確率を接続関係として表したグラフを用いる. 伝搬はそれぞれ報酬の伝搬(Backward pass),方策の 推定(Policy estimation),状態訪問頻度の計算(Forward givenMDP\R = ,A, Pa ss, γ ,D 1. θ 2. . 3. (20) ∂L(D|θ)/∂θ ∂L(D|θ)/∂θ ≈ 0 (a),(b) (a) s D(s) πθ(a|s) (b) θ θ← θ +
pass)の各ステップから構成され図 3 に例をあげて示す. 以上のグラフに基づく報酬の伝搬法 [Ziebart 08] によ れば計算量は O(|S||A|)へと緩和できるが,離散空間 を対象とした高速化である.また,[Shimosaka 17] で は連続空間から Interval consistent を保証した状態遷移 グラフを生成する方法を提案している. 5・2 重点サンプリングによる分配関数の推定 報酬関数に関する分配関数(partition function)を, 重点サンプリングによって推定する Relative Entropy IRL(以下,RelativeEnt IRL)[Boularias 11] を紹介する. MaxEnt IRLおよび Deep MaxEnt IRL において式
(21)の対数尤度 L(θ)を勾配法によって最大化する計
算に時間を要する.式(22)に示す MaxEnt IRL では, エキスパートと「特徴期待値」を比較して重み w を,式 (23)に示す Deep Max IRL ではエキスパートと「状態 訪問頻度」の比較によって報酬を,それぞれ更新する. log P (ζ|θ) = R(ζ) − log Z ∇ log P (ζ|θ) = φ(ζ) − EP (ζ|θ)[φ(ζ)] (21) ∇L(θ) = ζ∈D ∇ log P (ζ|θ) = EPπE(ζ)[φ(ζ)]− EP (ζ|θ)[φ(ζ)] (22) ∂ ∂θlog P (ζ|θ) = s∈ζ µζ(s)− EP (ζ|θ)[µζ(s)] ∂ ∂θf (φ(s), θ) ∂ ∂θL(θ) = × s∈S EPπE(ζ)[µζ(s)]− EP (ζ|θ)[µζ(s)] ∂ ∂θf (φ(s), θ) (23)
MaxEnt IRLでは EP(ζ|θ)[φ(ζ)],Deep MaxEnt IRL
では EP(ζ|θ)[μζ(s)]を求めるために動的計画法や強化学
習を経なければならない.ここでに対する最適方策が不 要になればその計算量を減らすことができる.
RelativeEnt IRLでは,式(24)に示すとおり,エキ
図 2 Maximum Entropy IRL:特徴期待値の更新
スパートの軌跡の分布 Q(ζ)との相対エントロピーの最 小化問題に帰着する.これをラグランジュ未定乗数法で 解けば式(27)となり,求めたい EP(ζ|θ)[φ(ζ)]は式(26) の Z = ζ∈ZQ(ζ)exp(R(ζ))を重点サンプリングによっ て近似することによって得られる. 重点サンプリングは期待値を求めたい確率分布と,サ ンプリングする分布の比の計算を必要とする.ここでは, 「エキスパート方策のもとでの軌跡の生成確率 Q(ζ)」と, 「軌跡のサンプリングに用いた方策のもとでの軌跡の生 成確率 P(ζ)」の比がそれにあたる. 式(28)の P(ζ)は,ある軌跡が得られる確率,Q(ζ) はエキスパートの軌跡ζが得られる確率で,それぞれ式 (29)のように初期状態分布と「方策×状態遷移確率」 の総乗で表される.状態遷移確率 Pa ss′が共通のため相殺 され,状態遷移確率に依存しない式(30)が得られる. したがって,状態遷移確率を必要としない.エキスパー トの方策と,軌跡をプロットした方策の比を計算すれば, 分配関数の推定値が得られるため,動的計画法,強化学 習が不要で,比較的大規模な離散状態行動空間,連続空 間にも適用可能である. mini ζ∈Z P (ζ) logP (ζ) Q(ζ) s.t. ζ∈Z P (ζ)φ(ζ) =EQ(ζ)[φ(ζ)], ζ∈Z P (ζ) = 1 (24) P (ζ|θ) = Q(ζ) exp (R(ζ)) ζ∈ZQ(ζ) exp (R(ζ)) = Q(ζ) exp (R(ζ)) Z , whereR(ζ) = θ · s∈ζ φ(s) (25) EP (ζ|θ)[φ(ζ)] = ζ∈Z P (ζ|θ)φ(ζ) = ζ∈Z Q(ζ) exp (R(ζ)) Z φ(ζ) (26) ζ∈Z Q(ζ) exp (R(ζ)) =EQ(ζ)[exp R(ζ)] (27) =EP (ζ) Q(ζ) P (ζ)exp R(ζ) (28) = × EP (ζ) d0(s1) Ht=1πE(at|st)P (st+1|st, at) d0(s1) Ht=1π(at|st)P (st+1|st, at) exp R(ζ) (29) =EP (ζ) H t=1πE(at|st) H t=1π(at|st) exp R(ζ) (30) 分配関数と重点サンプリングを用いた研究として Guided Cost Learning(GCL)[Finn 16a] が あ る.GCL は
MaxEnt IRLと同じ問題設定にモデルベース強化学習を
組み合わせた手法で,重点サンプリングと深層学習を用 いて報酬関数を推定する.MaxEnt IRL の分配関数の 推定に重点サンプリングを適用した式を式(31)に示 す.MaxEnt IRL の分配関数 Z は,RelativeEnt IRL と 異なるため,式(31)の式(29)で消えた状態遷移確 率の項が残る.この状態遷移確率をモデルベース強化学 習(Guided Policy Search)[Levine 13] を用いて推定し,
P(ζ)を求め,近似した状態遷移確率の(環境モデルの) 下で最適な軌跡を生成する.軌跡の生成確率は,方策と 状態遷移確率の総乗(式(29))で表されるため,環境 のモデルを学習すれば,ある方策のもとでの軌跡の生成 確率が計算できる. また,GCL では,状態遷移確率から計算した軌跡の 生成確率の分布を,提案分布として重点サンプリングで 分配関数を計算する.軌跡の生成方策を Guided Policy Searchで更新するため,重点サンプリングに最適な分 布 P(ζ)∝exp R(ζ)から軌跡をサンプルできる.したがっ て,その結果,試行錯誤が大幅に削減される一方,近似 精度は高く,サンプル数が少なくても RelativeEnt IRL に比べて優れた学習性能が得られることがいくつかのタ スクを用いた実験によって示されている. Z = ζ∈Z exp (R(ζ)) =EP (ζ) 1 P (ζ)exp R(ζ) (31) 5・3 そ の 他 の 方 法 § 1 線形可解マルコフ決定過程による定式化 近 年 注 目 さ れ て い る 線 形 可 解 マ ル コ フ 決 定 過 程 (Linearly solvable Markov Decision Process:LMDP)
[Todorov 06]の定式化は,強化学習による問題依存の試 行錯誤とコスト関数(報酬)設計の問題に対して有効で あることが示されている [Uchibe 16b].強化学習や最適 制御では MDP のもとで導出される非線形のハミルトン・ ヤコビ・ベルマン(Hamilton-Jacobi-Bellman :HJB) 方程式を解かなければならないが,LMDP では即時のコ スト関数と,環境のダイナミクスを制限することによっ て HJB 方程式を線形化できる.最適制御問題を機械学習 におけるグラフィカルモデルの推論などの確率推論問題 に帰着できることが示され [Theodorou 12],最適制御理 論と機械学習や機械学習をつなぐ理論として注目されて いる.線形可解マルコフ決定過程を用いた強化学習およ び逆強化学習に関する解説は [Uchibe 16b] に委ねる. LMDPを用いた研究として,[Dvijotham 10, Uchibe 16a]がある.[Uchibe 16a] の提案した Deep IRL Logistic Regression(LogRegIRL)は RelativeEnt IRL とも重 点サンプリングの考え方を導入している点で類似してい る.RelativeEnt IRL が任意の方策でサンプルした状
図 4 凸関数最適化問題としての逆強化学習 態行動対を使って線形の報酬を推定するのに対して, LogRegIRLは任意の方策でサンプルした状態遷移(状 態と次状態の対)を使って非線形の報酬,状態価値を推 定する.報酬だけでなく,状態価値も推定できる点は, LMDPの IRL の売りの一つといえる.また,LogRegIRL と同様に離散状態行動空間を対象とする MaxEnt IRL,
MaxEnt Deep IRLがその莫大な計算量のために低次
元環境にその適用が限られるのに対し,LogRegIRL は順強化学習または DP 不要であるため,大規模な環境 への適用にも期待できる.
5・2 節で紹介した RelativeEnt IRL [Boularias 11] や
GCL [Finn 16a]はいずれもモデルフリーで,深層学習
によって報酬を非線形関数として推定する方法である. § 2 生成敵対型ネット:GANs の導入
深層学習と逆強化学習に関する興味深い話題に逆強化 学習と Generative Adversarial Networks(生成敵対型 ネット:以下では GANs)をはじめとする生成モデルと の類似性がある.逆強化学習は報酬と方策を交互に更新 するが,GANs は判別器と生成器を交互に更新する点で ある.また,MaxEnt IRL と,ある形式の GANs の等価 性が理論的に示されている [Finn 16b].時を同じくして
MaxEnt IRLで得られる方策と全く同じ方策を,GANs
を用いて学習する Generative Adversarial Imitation Learning(敵対生成形模倣学習:以下 GAIL)[Ho 16] が提案された.GAIL の特徴は以下である. ● 環境情報を必要としないモデルフリーアルゴリズム. ● コスト(報酬)を推定することなく方策を直接学習. ● Inner Loopの強化学習に要するコストを低減. ● 大規模,高次元の状態行動空間に適用可能.
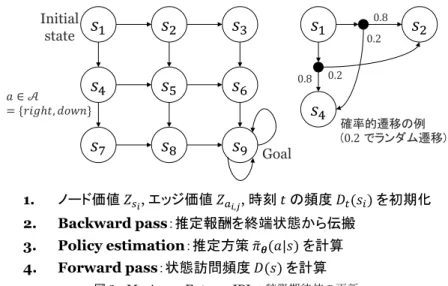
GAILは IRL に関する理論的な貢献も大きい.Ho ら
は,IRL の解が鞍点の座標であることを示し,IRL と双 対上昇法*4の関連性を明らかにした [Ho 16].図 4 左は 従来の逆強化学習,右は双対上昇法の概念図である.双 対上昇法は凸関数最適化が容易な問題に対して有用な手 法である.しかし,逆強化学習における凸関数最適化は 強化学習である,そのため計算量が多く非効率である. GAILは GANs の枠組みで鞍点を求めるため,既存の IRLと比べて効率的な手法である.
GAIL [Ho 16]は 2015 年に提案された Trust Region Policy Optimization(TRPO)[Schulman 15] が用いら れている.TRPO は深層強化学習の一つであり大規模状 態行動空間(離散,連続ともに)において安定的に方策 を学習するアルゴリズムである.その安定性が敵対学習 による方策の学習性能に貢献している.
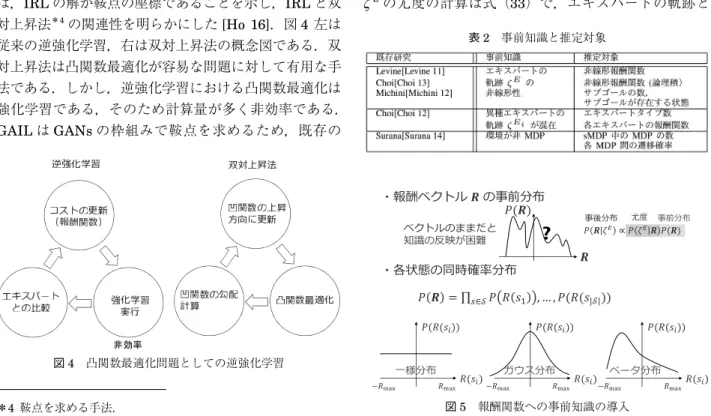
6.事前知識の導入
逆強化学習を考えるうえで,求めたい報酬関数や,エ キスパートの軌跡,および環境のダイナミクスに対する 非線形性や不完全性,マルコフ性などの前提が必要であ る.しかし,前提を置くにもかかわらず,報酬関数やエ キスパートの軌跡に関する事前の知識を明示的には導入 しない.これに対してベイズを導入した IRL(Bayesian IRL)は 2007 年の [Ramachandran 07] を皮切りにパラ メトリックな IRL と並行して研究が進められている.事 前知識を反映させた結果,確率モデルが複雑になったと しても MCMC などの近似解法によって推定が可能な点 にベイズを用いる優位性がある. これまで紹介した IRL の報酬関数の多くが f(, )= T,あるいはニューラルネットワークでは f(, )= f(f1 2(…(f(, n n), …), 2), 1)など,特徴ベクトルと パラメータによって記述されている.したがって,図 5 に示す各状態の同時確率分布などの知識を統合的に扱え ない. Bayesian IRLでは,報酬 R の事前分布 P(R)から式 (32)を用いた尤度計算によって報酬の事後分布 P(R|ζE) を得る.状態 si,行動 ai,および,エキスパートの軌跡 ζEの尤度の計算は式(33)で,エキスパートの軌跡と *4 鞍点を求める手法. 表 2 事前知識と推定対象 図 5 報酬関数への事前知識の導入同じ行動の Q 値が大きいほど尤度が大きくなるような更 新となる.
導入された事前知識は,1)報酬関数,2)エキスパー トの軌跡,3)環境に対してである.既存の Bayesian
IRLで導入された知識を表 2 にまとめた.
Bayesian IRLの基礎的論文 [Choi 11] ではベイズの事 後確率最大(maximum a posteriori :MAP)を式(34) に定義し,これを最大にする報酬を式(35)の勾配を用 いて計算可能であることを示した. 式(34)は,事後確率が所与のデータに対する適合 度合い(尤度)の項と,正則化の項に分けられることを 示しており,これにより,2010 年以前の IRL が,それ ぞれの解きたい問題に合わせて二つの項を仮定している ことを指摘している.これを表 3 で紹介する.合わせて 2016年までの IRL の系譜も図 6 にまとめたので適宜ご 参照いただきたい. P (R|ζE) =P (ζ E|R)P (R) P (ζE) ∝ P (ζ E |R)P (R) (32) P (ai|si, R) = exp(Q π*(si,ai,R)) b∈Aexp(Qπ*(si,b,R)) P (ζE|R) = i∈ζE exp(Qπ*(si,ai,R)) b∈Aexp(Qπ*(si,b,R)) (33) RMAP = argmaxRP (R|ζE) = argmaxRlogP (R|ζE)
= argmaxR[logP (ζE|R) + logP (R)] (34) Rnew← R + δt∇RP (R|ζE) (35)
7.お わ り に
本稿では脱創発志向と題して,試行錯誤だけによらず エキスパートの行動系列(軌跡)の観察に基づいて報酬 関数,あるいは方策を獲得する逆強化学習に焦点を当て, 近年の研究を紹介した.逆強化学習であげた三つ課題の うち,第一にあげた報酬の不良設定問題は,人間の徒弟 学習を考えればよくあることで,同じ行動を見せても, さまざまな弟子が育ったりするのは非常に興味深い.し かし,ロボットの学習など工学的立場からは,正確かつ 高速に方策を獲得させることは喫緊の課題である.一方, 第二,第三の課題については,人間は多くの時間を費や すことなく,また,事前知識も苦もなく導入しているこ とを思えば今後も新たな提案が見込まれる.人工知能研 究が,人間に学ぶものであるとすれば,人のやり方を腰 を据えて見直すことによって新たなブレークスルーがあ るかもしれない. また,本稿は強化学習の「報酬設計に対する困難」か ら出発して逆強化学習を概観したが,強化学習モデル が S, A, R であることからしても状態空間の設計は切 り離せない.多くの研究が認識の部分を深層学習でクリ アしているが,師の行動が「どの状態」で実行されてい るのかを適切に捉える,すなわち的確に特徴抽出できる 弟子はおそらく正確かつ高速に方策を獲得することは明 らかである.これに関する研究として FIRL [Choi 13, Levine 10]をはじめとして特徴空間と報酬関数を相互に 更新する枠組みが示されている.これに関しては別の機 会にまた紹介させていただきたい.◇ 参 考 文 献 ◇
[Abbeel 04] Abbeel, P. and Ng, A. Y.: Apprenticeship learning via inverse reinforcement learning, Proc. 21st Int. Conf. on
Machine Learning(ICML),pp. 1-8(2004)
[Babes 11] Babes-Vroman,M., Marivate, V., Subramanian, K. and Littman, M.: Apprenticeship learning about multiple intentions, Proc. 28th Int. Conf. on Machine Learning(ICML), pp. 897-904(2011)
[Boularias 11] Boularias, A., Kober, J. and Peters, J.: Relative entropy inverse reinforcement learning, Proc. 14th Int. Conf.
on Artificial Intelligence and Statistics(AISTATS),Vol. 15, pp. 20-27(2011)
[Choi 11] Choi, J. and Kim, K. E.: MAP inference for Bayesian inverse reinforcement learning, Advances in Neural
Information Processing Systems(NIPS),Vol. 24, pp. 1-9(2011) [Choi 12] Choi, J. and Kim, K. E.: Nonparametric Bayesian inverse reinforcement learning for multiple reward functions,
Advances in Neural Information Processing Systems(NIPS), Vol. 25, pp. 1-9(2012)
[Choi 13] Choi, J. and Kim, K. E.: Bayesian nonparametric feature construction for inverse reinforcement learning, Proc.
23rd Int. Joint Conf. on Artificial Intelligence(IJCAI),pp. 1287-1293(2013)
[Dvijotham 10] Dvijotham, K. and Todorov, E.: Inverse optimal control with linearly-solvable MDPs, Proc. 27th Int. Conf. on
Machine Learning(ICML),pp. 335-342(2010) 表 3 尤度と正則化項 [Choi 11] から引用
[Finn 16a] Finn, C., Levine, S. and Abbeel, P.: Guided cost learning: Deep inverse optimal control via policy optimization,
Proc. 33rd Int. Conf. on Machine Learning(ICML),pp. 49-58 (2016)
[Finn 16b] Finn, C., Christiano, P., Abbeel, P. and Levine, S.: A connection between generative adversarial networks, inverse reinforcement learning, and energy-based models, NIPS 2016
Workshop on Adversarial Training, pp. 1-10(2016)
[Fu 17] Fu, J., Luo, K. and Levine, S.: Learning robust rewards with adversarial inverse reinforcement learning, arXiv preprint arXiv:arXiv:1710.11248, pp. 1-13(2017)
[Goodfellow 14] Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B. Warde-Farley, D., Ozair, S., Courville, A. and Bengio, Y.: Generative adversarial nets, http://arxiv.org/ abs/1406.2661(access 2018.1.1)
[Hadfield-Menell 16] Hadfield-Menell, D., Dragan, A., Abbeel, P. and Russell, S.: Cooperative inverse reinforcement learning,
Proc. 30th Conf. on Neural Information Processing Systems
(NIPS)(2016)
[Ho 16] Ho, J. and Ermon, S.: Generative adversarial imitation learning, Advances in Neural Information Processing Systems, Vol. 29, pp. 1-9(2016)
[Hu 03] Hu, J. and Wellman, M.: Nash Q-learning for general-sumstochastic games, J. of Machine Learning Research, Vol. 4, pp. 1039-1069(2003)
[木村 97] 木村 元,Kaelbling, L. P.: 部分観測マルコフ決定過程 下での強化学習,人工知能学会誌,Vol. 12, No. 6, pp. 822-830 (1997)
[Kitazato 18] Kitazato, Y. Arai, S.: Estimation of reward function maximizing learning efficiency in inverse reinforcement learning, 10th Int. Conf. on Agents and Artificial Intelligence (ICAART),pp. 276-278(2018)
[Levine 10] Levine, S., Zoran, P. and Vladlen, K.: Feature construction for inverse reinforcement learning, Advances in
Neural Information Processing Systems, pp. 1342-1350(2010) [Levine 11] Levine, S., Popovic, Z. and Koltun, V.: Nonlinear inverse reinforcement learning with Gaussian processes,
Advances in Neural Information Processing Systems, Vol. 24
(NIPS),pp. 19-27(2011)
[Levine 13] Levine, S. and Abbeel, P.: Guided policy search, Proc.
30 th Int. Conf. on Machine Learning(ICML),pp. 1-9(2013) [Lin 92] Lin, L.: Self-improving reactive agents based on reinforcement learning, planning and teaching, Machine
Learning, Vol. 8, pp. 293-321(1992)
[Littman 94] Littman, M.: Markov games as a framework for multiagent reinforcement learning, Proc. 7th Int. Conf. on
Machine Learning, pp. 242-250(1994)
[Littman 01] Littman, M.: Value-function reinforcement learning in Markov games, Cognitive Systems Research, Vol. 2, No. 1, pp. 55- 66(2001)
[Michini 12] Michini, B. and P. How, J.: Bayesian nonparametric inverse reinforcement learning, Joint European Conf. on
Machine Learning and Knowledge Discovery in Databases
(ECML PKDD),pp. 148-163(2012)
[Mnih 15a] Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D. and Riedmiller, M.: Playing Atari with deep reinforcement learning, NIPS Deep
LearningWorkshop, arXiv:1312.5602 [cs.LG](2013)
[Mnih 15b] Mnih, V., et.al., Human-level control through deep reinforcement learning, Nature, Vol. 518, pp. 529-533(2015) [Neu 07] Neu, G. and Szepesv’ari, C.: Apprenticeship learning
using inverse reinforcement learning and gradient methods,
Proc. 23rd Conf. on Uncertainty in Artificial Intelligence
(UAI),pp. 295-302(2007)
[Ng 00] Ng, A. and Russell, S.: Algorithms for inverse reinforcement learning, Proc. 17th Int. Conf. on Machine
Learning(ICML),pp. 663-670(2000)
[Pomerleau 91] Pomerleau, D. A.: Efficient training of articial neural networks for autonomous navigation, Neural
Computation, Vol. 3, No. 1, pp. 88-97(1991)
[Ramachandran 07] Ramachandran, D. and Amir, E.: Bayesian inverse reinforcement learning, Proc. 20th Int. Joint Conf. on
Artificial Intelligence(IJCAI),pp. 2586-2591(2007) [Ratliff 06] Ratliff, N. D. and Bagnell, J. A.: Maximum margin
planning, Proc. 23rd Int. Conf. on Machine Learning(ICML), pp. 729-736(2006)
[Russell 98] Russell, S.: Learning agents for uncertain environments(extended abstract),Proc. 11th Annual Conf.
on Computational Learning Theory(COLT),pp. 101-103 (1998)
[Schulman 15] Schulman, J., Levine, S., Moritz, P., Jordan, M. and Abbeel P.: Trust region policy optimization, Proc. 31st Int.
Conf. on Machine Learning(ICML),pp. 663-670(2015) [Shibata 09] Shibata, K. and Kawano, T.: Acquision of Flexible
Image Recognition by Coupling of Reinforcement learning and neural network, SICE Journal of Control, Measurement, and
system Integration, Vol. 2, No. 2, pp. 122-129(2009)
[Silver 16] Silver, D., et al.: Mastering the game of go with deep neural networks and tree search, Nature, Vol. 529, pp. 484-503 (2016)
[Shimosaka 17] Shimosaka, M., Sato, J., Takenaka, K. and Hitomi, K.: Fast inverse reinforcement learning with interval 10 consistent graph for driving behavior prediction, Proc. 31st
AAAI Conf. on Artificial Ingelligence, pp. 1532-1538(2017) [Surana 14] Surana, A. and Srivastava, K.: Bayesian
Nonpara-metric inverse reinforcement learning for switched Markov decision processes, Proc. 13th Int. Conf. on Machine Learning
and Applications(ICMLA),pp. 47-54(2014)
[Sutton 98] Sutton, R. S. and Barto, A. G.: Reinforcement
Learning: An Introduction, MIT Press(1998)
[Syed 08a] Shed, U., Bowling, M. and Schapire, R. E.: Appren-ticeship learning using linear programming, Proc. 25th Int.
Conf. on Machine Learning(ICML),pp. 1032-1039(2008) [Syed 08b] Syed, U. and Schapire, R. E.: A game-theoretic
approach to apprenticeship learning, Advances in Neural
Information Processing Systems(NIPS),Vol. 21(2008) [Todorov 06] Todorov, E.: Linearly-solvable Markov decision
problems, Advances in Neural Information Processing Systems (NIPS), Vol. 19, pp. 1369-1376(2006)
[Theodorou 12] Theodorou, E. and Todorov, E.: Relative entropy and free energy dualities: Connections to path integral and KL control, Proc. 51st IEEE Conf. on Decision and Control, pp. 1466-1473(2012)
[Uchibe 16a] Uchibe, E.: Deep Inverse Reinforcement Learning by Logistic Regression, 23rd Int. Conf. on Neural Information
Processing(ICONIP),pp. 23-31(2016)
[内部 16b] 内部英治:線形可解マルコフ決定過程を用いた順・逆 強化学習,日本神経回路学会誌,Vol. 23, No. 1, pp. 2-13(2016) [Wang 02] Wang, X. and Sandholm, T.: Reinforcement learning to play an optimal Nash equilibrium in team Markov games,
Advances in Neural Information Processing Systems, Vol. 15,
pp. 1571-1578(2002)
[Watkins 92] Watkins, C. and Dayan, P.: Q-learning, Machine
Learning, Vol. 8, No. 3, pp. 279-292(1992)
[Wulfmeier 15] Wulfmeier, M., Ondruska, P. and Posner, I.: Maximum entropy deep inverse reinforcement learning, arXiv preprint arXiv:1507.04888, pp. 1-10(2015)
[Ziebart 08] Ziebart, B. D., Maas, A., Bagnell, J. A. and Dey, A. K.: Maximum entropy inverse reinforcement learning, Proc. 23rd
AAAI Conf. on Artificial Intelligence(AAAI),pp. 1433-1438 (2008)
![表 3 尤度と正則化項 [Choi 11] から引用](https://thumb-ap.123doks.com/thumbv2/123deta/8198471.1278260/9.892.99.431.427.1198/表3尤度と正則化項Choi11から引用.webp)
