Improvement of Acoustic Model for Hands-Free Speech Recognition Using Spatial Subtraction Array
4
0
0
全文
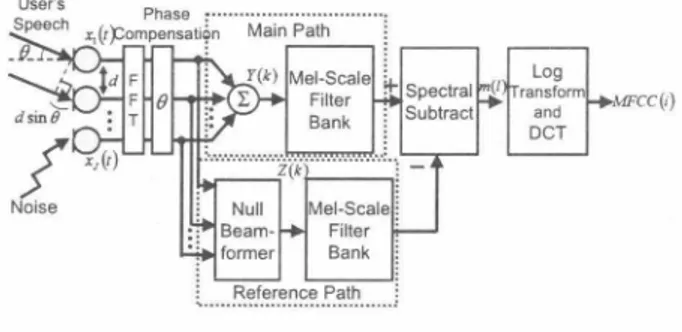
(2) 2. Proposed method 2.1. SSA. Figure ! shows a configuration of the proposed SSA. SSA includes mel-scale filter bank analysis, and outputs mel frequency cepstrum coe伍cient (MFCC ). The triangular win dow W(k; f) (1 = 1" L) to perform mel-scale filter bank anal ysis is designated as follows: k - k1o(乃. t. khi (f) - kc(乃. 一一 | 一一 o 乃 句 ポ k | 一一( 一一一. �. (k1o (乃5,k 5,kc(乃), (kc(悩仇(乃),. where k1o(乃, kc(乃and khi (f) are the lower, center , and higher frequency bins of each triangle window respectively. They satisfシthe relation among adjacent windows as (2) kc(乃= khi(l- 1) = k1o(l + 1) , Moreover, kc(乃IS aπanged in re伊lar intervals on mel 合equency domain. Mel-scale 合equency Mel九(() for kc(乃 is calculated as. -. kc(f) ・!S) f, +• 一一一 一é.:: k el.mリ (3) 山 = 2595102,n� ロ1V t 1 700・KJ' where !s is the sampling合equency and M is the DFT size. In the proposed SSA, noise reduction is achieved by sub tracting the estimates noise power spec汀um 合om the target speech power spectrum to be enhanced in the mel-scale filter bank domain. This 0仔'ers a realization of error-robust noise reduction with few computational complexities because the parameters are oPUTTIized in the small number of mel-scale filter banks. This procedure is given by. m(l, T) = klU(乃. L:W(川\lYos(か) 12ーα(りβIZNBF(わ)12} t,. k=k,o(乃 kh,(乃. Figure 2: SSA matched acoustic model with SSA.. ) l (. W(川=. (. (if IYDs (k, T)12ーα(f)・β.IZNBF(k, T)12と0),. (4). 2エ; W例(川{けY'Iげ陥Y均恥D凶附s. k=k,o(乃. where k is the合equency bins,k1o (f) and klバf) are the lower and higher frequency bins of each triangle windows respectively, T is the number of filter, m(l, T) is the output合om the mel scale白lter bank, W(k, 乃is the triangular window to perform mel-scale filter bank analysis. YDs (k ) is the output signal from DS, i.e., the partly enhanced speech signal, and YNBF (k ) is the output signal from NBF in which the directional null steers in DOA of the user, i.e., the estimated noise signal. The system switches in two equations depending on the conditions in (1). m (乃is a function of the subtraction coefficientβand the pa rameterα (乃which is detennined during a speech break. On the other hand, if the power spectrum take a negative value,. m(l) is obtained by using flooring processing whereγis the flooring coefficient. Since a common speech recognition is not so sensitive against phase information, the proposed SSA which in ap plic�ble �or th� :�e�? reco� ition. ?J req����s the a dap . , tive leaming of FIR-filters of thousands or millions ofr taps. On the other hand, in general, the order of filter bank 1 is set to 24, and consequently the proposed method optimizes only 24-parameters. Moreover, the proposed method is per.・ formed in the mel-scale filter bank domain and the transform into MFCC as follows:. WCC(h. G 5 M州(l- j) Z ). (5). 2.2. ACOUS6c model improvement for SSA. In the speech recognizer part, the conventional researches have introduced a simple acoustic model which was trained under noise-less and distortion幽less conditions, so called clean model. However there exist the following problems es pecially in SSA applications: (a ) SSÁ's noise r�cÎuction performance is limited to some ex tent, and consequently there are still some residual noise com・ ponents in the SSA's output. (b ) SSA involves highly nonlinear signal processing, and this leads to creation of sound distortion in the enhanced target speech. The above-mentioned deviations 合om ideal clean conditions give us a mismatch of acoustic model in the speech recognizer, and this yields heaηr deterioration in word recog nition score. To solve this problem, in this work we propose to construct a noise- and distortion-specific acoustic model which reflects prospective conditions in the actual use of SSA. The仕aining of the acoustic model is carried out by con・ sidering the characteristics on the sound distortion and noise residuals, which can be done with handling of SSA in an in put speech. This strategy can really make distortions of SSA used at the time of recognition agree with the acoustic model. - 474- 232-.
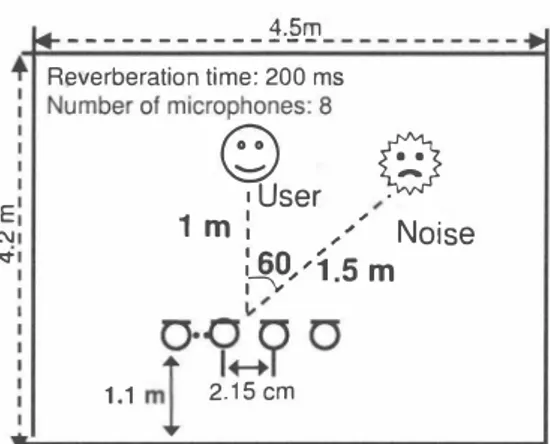
(3) |.. _ _ _ _ _ _ _ _ _ _ _ 1 ._ê'I1. Table 1: Experirnental conditions. +1 Reverberation time: 200 ms. Oatabase. EN寸. qser 務 1m ; Noise /. Task. '. ;勾�'1.5m. 1.1. User angle Noise Noise angle Noise supenmposJtlOn Acoustic model. ?tpo. ml. 2.15cm. Figl.lre 3: Layol.lt of reverberant 200-ms reverberation room used in experiments. Oecoder Filter size Fram巴slze Sampling freql.lency Known noise Amol.lnt of supe1'lmposltlon β(SSA) γ(SSA). 3.33 m. 今I Reverberation time: 260 ms 川 Number01 microphones : 8. E守∞. N. qser必. 1m: 刀叶サoise l貝0,,'1m. JNAS [ ]、 speakers (150 sentences / 1 speaker) 20-k newspaper dictation 。. 。. cIeaner 600 10 dB PTM [ ] (2000 stats, 64 mixture size) clean, matched, clean & reverberation, matched & reverberation JuIius ver.3. 4. 2 [ ] 32 ms (512 taps) 25 111S (400 samples) 1 6 kHz Office room noise 3 0 dB 0.5,1.0、2.0 0. 2. 。00。 2.15cm. Figure 4: Layout of reverberant 260-ms reverberation room used in experiments.. trained in advance. Figure 2 depicts an overview of the pro posed method for creating SSA・matched acoustic model. A flow of concrete processing is as follows: 1. We convolute an impulse response measured beforehand by microphone a汀ay in a speech database. 2. In a speech database made with 1, we sl.lperimpose ex cellence of an exterior noise of a fixed quantity. 3. An SSA dispense for 2. And it is an expression by a case(1). We perform known noise excellence after sub traction we am similar, and to be able to put [ ]. 4. We leam it with EM algorithm and make an SSA matched acoustic model. 5. We give SSA for an input evaluation speech and perform known noise superimposition excellence after spectral subtraction by a case. We do speech recognition it with 4. SSA-matched models.. 3. Experiments and results. ln this section, we evaluate our proposed noise and reveト beration robust speech recognition. 3.1. Conditions. Figures -' and:l show layouts of the reverberant rooms used in the experiment and Tàble 1 shows the experimental con ditions. ln the experiment, we use the following signals as testing data: the original speech convoluted with the impulse responses which are recorded in the actual environrnent, and added with exterior noise and office noise which is included in the actual environrnent. ln this paper, we compare clean model, reverberation and known noise matched model, rever beration and exterior noise matched model, Oelay-and-Sum (OS ) matched modeI and SSA matched model. We construct each model under the conditions of260・ms reverberation and 200-ms reverberation. Regarding the recorder,尺JLIUS is used. We use a Phonetic Tied Mixture[2] model from JNAS database. The evaluation task is the JNAS newspaper dic tation task with 20k vocabulary size. The baseline speaker independent acoustic models are trained 合om 260 仕aining speakers' data in JNAS speech database. PTM, phonetic tied mixture models. are used. The PTM training speech database includes 260 speakers (39000 sentence u口erances in total).. - 475 - 233 -.
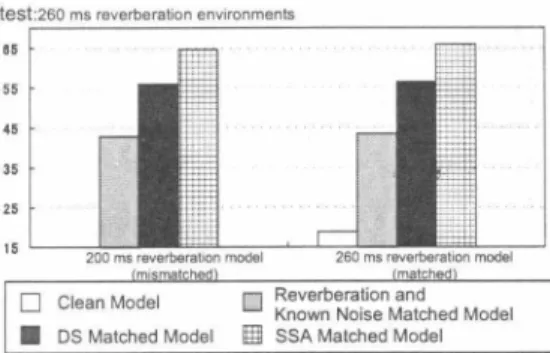
(4) 65 率 三55. υ. 5 45 � 百35 0 ;;: 2 5. 口SSA Matched. Model. ß = 1.0国SSA Matched. Model. ß = 2.0. Figure 6: Result of SSA matched model and mismatched model. Figure 5: Result ofSSA matched model. among environment changes. The test set consists of another 46 speakers from汁-JAS. Each test speaker utters 4 or 5 newspaper article sentences (200 test sentence utterances in total ). The distance between the microphone aηay and the loudspeakers is 1.0m. The experi ment conditions are sumrnarized in Table 1.. Acknowledgments. Part of this work is supported by MEXT (Ministry of Edu cation, Culture, Sports, Science and Technology ) e-Society leading project. References. 3.2. ResuIts. First compare same environments acoustic models that clean model, reverberation and known noise matched model, reverberation and exterior noise matched model, Delay-and Sum (DS ) matched model and SSA matched model on the basis of word accuracy scores. Figureラshows all acous・ tic models and the SSA in word accuracy score results. The SSA-matched acoustic model shows a higher recognition per formance than the other models which include no (or less ) considerations of residual noise and distortion effects. From the results, it is speculated that the word accuracy depends on quantity of characteristics to be considered when we really use SSA for speech recognition processing, and our proposed a coustic model with SSA is well matched to it. T he difference by a subtraction parameter of SSA was not seen very much. Figure () show mismatched environments model and the SSA in word accuracy score results. An SSA-matched model led the best result. In addition, the SSA-matched acoustic model is still a good model for recognition even if acoustical envi ronments change. The difference by a subtraction parameter of SSA was not seen very much. 4. Conclusion. In this paper, to address the acoustic model problem in non linear a汀ay signal processing, SSA, we proposed to construct SSA・matched acoustic model. We showed the experimen tal evaluation of our model, and revealed an e仔ectiveness of SSA-matched acoustic model. SSA-matched acoustic model provided a higher word accuracy score than the other conven tional models. We also show the robustness against difference. [1] H. Saruwatari, S. Kurita, K. Takeda, F. Itakura, T, Nishikawa, K. Shikano,“Blind source separation combining independent component analysis and beamforming," EURASIP Journal on Applied Signal Processing, voJ.2003, no.11, pp.1135-1146, 2003. (2) L. 1. Gri伍th,and C. W. Jim,“An a1temative approach to linearly constrained adaptive beamfoロning," IEEE Trans. Antennas Propagation, vo1.30,no.1, pp.27-34, 1982 [3] Y. Ohashi, T. Nishikawa, H. Saruwatari, A. Lee, K. Shikano, “Noise-robust hands-free speech recognition based on spatial subtraction a汀ay and known noise superimposition," Proc IEEE/RSJ International Conlerence on Intel/igent Robots and Systems,. [4]. pp.533-537,2005.. S. B. Davis, and P. Me口ne1stein,“Comparison of parametric. representations for monosyllabic word recognition in contin uously spoken sentences," IEEE Trans. Acoustics, Speech, Signal Proc., voJ.ASSP-28, no.4,pp357-366,1982 [5] S. Yamade, A. Lee, H. Saruwatari, and K. Shikano,“Unsu pervised speaker adaptation based on HMM sufficient in vari ous noisy environments," Proc. EUROSPEECH, pp.II-1493 1496,2003. [6] K. Ito, M. Yamamoto, K. Takeda,T. Takezawa,工Matsuoka,T. Kobayashi, K. Shikano, and S. Itahashi“JNAS:Japanese Speech Corpus for Large Vocabulary Continuous Speech Recognition Research," Journal 01 the Acoustical Society 01 Japan (E), voJ.20, pp.199-206, 1999. [ï] A. Lee,T. Kawahara, K目Takeda,K. Shikano,“A new phonetic tied-mixture model for efficient decoding," Proc. ICASSP, voJ.III, pp.1269-1272, 2000 [8] A. Lee, T. Kawahara, and K. Shikano, “Julius - An open source real-time large vocabulary recognition engine," Proc. EUROSPEECH, pp.1691-1694, 2001. - 476- 234-.
(5)
図

関連したドキュメント
The excess travel cost dynamics serves as a more general framework than the rational behavior adjustment process for modeling the travelers’ dynamic route choice behavior in
According to expert experience, characteristic data of driver’s propensity includes headway, relative speed, deceleration frequency, acceleration frequency, performance reaction
In this paper, for the first time an economic production quantity model for deteriorating items has been considered under inflation and time discounting over a stochastic time
To overcome the drawbacks associated with current MSVM in credit rating prediction, a novel model based on support vector domain combined with kernel-based fuzzy clustering is
It is suggested by our method that most of the quadratic algebras for all St¨ ackel equivalence classes of 3D second order quantum superintegrable systems on conformally flat
At the same time, a new multiplicative noise removal algorithm based on fourth-order PDE model is proposed for the restoration of noisy image.. To apply the proposed model for
Abstract: By using subtraction-free expressions, we are able to provide a new proof of the Turán inequalities for the Taylor coefficients of a real entire function when the zeros
In this work, we present a new model of thermo-electro-viscoelasticity, we prove the existence and uniqueness of the solution of contact problem with Tresca’s friction law by
