應用資料擷取於Web小工具開發之研究–
多個資料源之資料整合
楊士鋒
中央大學資訊工程所
tomelf2002@gmail.com
張嘉惠
中央大學資訊工程所
chia@csie.ncu.edu.tw
摘要
隨著網路使用量快速地增加,網路行為日益頻 繁,個人化資訊整合與管理漸漸受到重視。從早期 My Yahoo 到近期的 iGoogle、Netvibes 所提供的個 人化首頁服務,這類型個人入口網站結合軟體即服 務的概念,應用 AJAX 等 Web 技術,提供使用者隨 時新增刪減所需的小工具(Gadget),加以接受使用 者自行開發的小工具,因此成為個人資訊整合的最 佳 平 台 。 不 過 使 用 者 雖 然 可 以 自 行 選 擇 現 有 的 Gadget,但自行設計 Gadget 仍不是一件平易近人的 任務。因此本論文提出一個線上 Gadget 製作網站, 目的是希望讓使用者僅需簡單的操作,就能夠達到 監控網頁更新和多樣的資料呈現方式。同時透過所 設計的頁面擷取流程規劃,讓使用者能將網頁資料 轉成多資料源,擷取所需資訊,進行個人化資料整 合。最後透過 Gadget 平台,更可將產生的模組分享 給網路上的使用者。
1. 前言
在Web 2.0概念產品逐漸流行,如Wikipedia、 Blog、個人化首頁,將更多人群拉進了網路世界, 使網路用戶可輕易地向全世界分享自己的資訊。然 而這類型入口網站僅提供大眾化的資訊,無法滿足 網路使用者的個人喜好,一般網路用戶每天大都例 行性地瀏覽幾個特定網站,取得最新資訊,這些工 作常常是繁瑣且耗時的。隨著網路使用量快速地增 加,網路行為日益頻繁,個人化資訊整合與管理儼 然已成為重要的研究領域。
一般網路使用者管理資料的方式,大致可分為 以下幾種:1)書籤, 2)電子郵件, 3)多重首頁, 4)個人 化首頁。書籤可替使用者記錄網頁位址,然而無法 監控每個網頁的更新狀況,若網站內容、網址改 變,使用者須逐一瀏覽後才能發現;電子郵件雖可 記錄並監控網路資訊的更新,然而當資料來源太過 繁雜,每日管理大量的電子郵件將是沈重負擔;多 重首頁可讓使用者在開啟瀏覽器時同時顯示多個 頁面,然而當資料來源、頁面複雜時,也難滿足使 用者的需求。
在 Web 2.0 的概念逐漸成熟後,網路產品的設 計模式逐漸重視個人化需求,個人化首頁也逐漸成 為個人資訊管理的新方案。以 Google 為例,他們在
2007 年 4 月推出 iGoogle,提供互動介面讓人們透 過簡易步驟管理個人化首頁,並允許開發人員自行 在其平台上設計小工具,因此個人化首頁的概念開 始改變網路用戶的行為模式。使用者可快速管理個 人化首頁版面,放置個人所需的 Google Gadget。 Gadget 是一種使用者網路互動介面,人們可透過使 用 Gadget,將新聞、股市、行事曆、電子郵件、和 許多有用的功能放置於個人化首頁,輕易地達到個 人資訊整合。
現今許多大型網站都有支援 Gadget 功能,例如 Google、Yahoo!和 Microsoft。以 Google 為例,Google Gadget 是一種以 XML 標籤為基礎的軟體介面,其 中主要分為 XML 標籤和 HTML 版面程式碼兩個部 分。XML 標籤中記錄了 Gadget 的資訊,包括 Gadget 名稱、敘述、作者和使用說明等等。HTML 版面程 式碼用來定義 Gadget 畫面,並以內嵌 Javascript 程 式碼來處理動態網頁控制,因此開發者僅需製作一 個 Gadget 的 XML 檔案,就可以分享到網路上讓世 界各地的使用者套用。
雖然使用者可以選擇現有的 Gadget,但自行設 計 Gadget 仍不是一件平易近人的事。設計 Gadget 有幾個挑戰:首先、Gadget 設計者必須要懂 XML 標籤和 HTML、Javascript 程式、AJAX 等技術,對 於 不 懂 程 式 語 言 的 使 用 者 而 言 是 難 以 跨 越 的 藩 籬。其次、目前的 Gadget 設計大多作法是將特定網 站中的資訊取出,簡化後以 Gadget 平台呈現網站資 訊,因此必須針對特定網頁撰寫程式,或利用該網 站所提供的函式工具庫來擷取網頁資訊。一般使用 者再使用 Gadget 時,沒有辦法自行設定資訊來源。 且因為僅部分網站有提供函式工具庫,對於沒有提 供的網站,其網頁內容改變時,必須要有因應機制 能即時改變 Gadget 內容,否則沒有更新的 Gadget 就失去用處了。這些挑戰都需要較專業的技術才能 完成,顯然不是一般使用者能在短時間內完成的。 本 篇 論 文 中 提 出 一 個 網 頁 互 動 式 的 線 上 Gadget 產生流程,讓無程式背景的使用者,也能夠 擷取目標網頁中的資訊,並透過簡單的步驟將網頁 資訊以 Gadget 方式呈現。希望僅需簡單的操作,就 能夠達到監控網頁更新和以 Gadget 呈現的功能。系 統有兩種方式讓使用者指定擷取資料的來源頁面: 1)網址; 2)表單查詢。在網頁資料處理上,為了能夠 讓系統順利擷取使用者所需資料,提升網頁變動時 資 料 擷 取 的 正 確 性 , 所 以 必 須 使 用 樣 版 歸 納
(Wrapper Induction)技術。另外,系統提供了頁面擷 取流程,使用者可以從網頁中擷取所需資訊,同時 可以利用網頁中的網址資訊,進行新的資料源的網 頁資料擷取。在資料呈現的模組上,目前提供下列 幾種模組: 清單, 表格, 地圖, 月曆, RSS。經過上述 的 Gadget 產生流程後,就可以立即發佈上線,分享 給所有網路上的使用者。
2. 相關研究之探討
2.1 網路資訊整合Andreas Thor 等人在 2007 年提出一個架構,讓 網路服務開發者能夠快速將不同來源或不同服務 的資料,整合成為新的服務[3]。此系統主要是延 伸自 iFuice,由相同作者在先前所發表的資料整合 系統。一般資料整合系統常使用 Schema Matching 作為資料來源整合的方式,iFuice 改以找尋相異資 料來源間的相同資料作為整合的方法。
Jin Yu 等人在 2007 年以傳統的企業軟體整合 (EAI)為基礎,針對混搭工具提出 Presentation Level Integration (PI) 的 資 料 整 合 [9] 。 相 較 於 傳 統 的 Application Level 資料整合,PI 的特色有 2 點:1. 完全不修改應用程式本身內容,而為既有的服務撰 寫敘述檔案,將單一服務轉成可重用式元件。2.利 用 Composition 語法敘述來整合所有元件,描述各 個元件間的參數傳遞方式及型態,並建立元件監聽 者,用以處理不同元件間的事件呼叫和監聽。同時 為了方便元件間溝通,降低元件開發環境不同所造 成的整合困難度,作者也建立了轉化器(Adapter) 的機制,並為當下主流的幾種開發環境設計了轉化 器(.NET, Java Applet, ActiveX 等)。
2.2 區塊追蹤
Jie Han 等 人 在 2007 年 提 出 Homepage Live[7] , 目 標 是 提 供 使 用 者 個 人 首 頁 服 務 , 與 iGoogle 相似,該系統以小工具做為個人首頁的元 件。Homepage Live 重點在於系統在目標網頁版本 更新後,如何正確地抓取目標區塊,作者利用一個 網頁樹比對演算法來比對新舊網頁,計算新舊網頁 的最小編輯距離,判斷新舊網頁中目標區塊的對應 關係。
Sandeep Lingam 等 人 在 2007 年 提 出 Web Clip[12],設計一個適用於 Microsoft Frontpage 的網 頁設計元件,讓網站開發者不須寫程式,就能夠在 網頁中加入即時擷取網頁資訊的工具模組。Web Clip 可將網頁中特定區塊擷取出來,著重於網頁區 塊擷取的正確性。對於特定目標網頁,作者設定了 數個可擴充式的網頁資料擷取規則,並透過使用者 對有效規則進行標記,定義出目標網頁中使用者所 想 要 的 區 塊 , 然 後 透 過 有 效 規 則 對 目 標 網 頁 作 Filtering 及 Assessment 以擷取網頁中的目標區塊。
2.3 Gadget 的建立
隨著個人入口網站的發展,Gadget Creation 成 為了一個相關的研究方向。最早的相關研究是來自 於網路服務的自動產生。Yi-Hsuan Lu 等人在 2005 年提出 Pollock[14],設計一個快速產生網路服務的 流程。Pollock 中提供一個介面,讓使用者手動選取 目 標 網 站 的 資 訊 , 進 行 樣 本 歸 納 。 Pollock 以 XWRAP[10]作為系統 Wrapper,是一種手動建立式 IE 系統,使用者透過網頁資料標記的過程,讓系統 產生資料擷取規則。系統最後將資訊包裝成 WSDL 格式,並且可直接發佈到 UDDI 註冊為可用的網路 服務。
在商業網站中,Dapper[19]提供服務讓使用者 將特定網頁中的資訊轉成 RSS、Google Gadget、 Netvibes Gadget 等不同的顯示模組。Dapper 的流程 首先讓使用者指定一個要擷取資料的目標網頁,透 過他們所建立的虛擬瀏覽器,讓使用者在”所見即 所得”的設計下收集樣本網頁。之後 Dapper 以監督 式 IE 系統,讓使用者標記網頁中哪些項目是需要 的,在標記過程中 Dapper 會修改擷取規則,使用者 必須不斷地增加刪減項目,直到所有項目皆為使用 者預期項目為止。
Openkapow[20]提供服務讓使用者將網頁資訊 轉為 RSS 及網路服務。Openkapow 提供一個必須下 載 安 裝 的 工 具 RoboMaker , 使 用 者 可 透 過 Robomaker,將網頁資訊轉為 RSS、網路服務和 Web Clip 三種形式。RoboMaker 提供了許多功能項目, 他能夠透過流程圖的設計,從不同網頁中取得資 訊、或從單一網頁中取出不同格式的資訊,將設計 後的流程轉成機器人(Robot)。RoboMaker 中的資料 擷取方式是手動建立式 IE 系統,讓使用者利用標籤 搜尋器來定義所需網頁區塊,使用者必須定義網頁 區塊的標籤路徑,並且輔以標籤中的屬性內容,來 擷取出正確的資料。
總結以上關於 Gadget Creation 的研究,發現在 技術層面上最主要的兩個問題在於 1) 網頁抓取的 研究,以及 2) Wrapper Induction 的研究。
2.4 網頁抓取
Lage 等人在 2004 年的研究[8],設計對 Deep Web 進行網頁爬行,對於某個特定主題,自動收集 有關的網頁;而 Crescenzi 等人在 2004 的研究[14] 則著重在對於各式各樣不同的主題,系統如何能正 確進行網頁爬行。這些研究主要目的在於如何讓系 統自動爬行某些主題的網頁,和這些研究相比,我 們著重於系統和使用者的互動,特別是如何讓使用 者能夠透過互動介面,指定網頁中的資料作為新的 網頁抓取來源。
過去也有相關研究設計抓取工具來輔助監督 式 IE 系統進行網頁抓取,如 Laender 等人在 2002 年所發表的 DEByE (Data Extraction By Example)
圖 2 以查詢表格抓取網頁
[1]和 Lage 等人在 2004 年所發表的 ASByE (Agent Specification By Example) [8]。然而這些研究皆針對 監督式 IE 系統設計,至今我們仍未發現針對非監督 式 IE 系統所設計的網頁抓取。我們系統首次設計了 一個輔助非監督式 IE 系統進行網頁抓取的流程,讓 使用者能夠操作簡單的介面進行網頁抓取,執行 Wrapper Induction 並選取所需的資料欄位。
2.5 Web 資料擷取
在深網的概念中,動態網頁的組成是將動態資 料嵌入一個網頁樣版中。一般來說,網頁的樣版部 分都是固定不變,因此分析一個網頁,將內容切割 為資料及樣版兩個部分,並擷取出資料是可能做到 的。根據張嘉惠教授等人在 2006 年的研究[4],資 料擷取系統可分成 4 種類別:
1. 手動建立式:針對特定網站撰寫 Wrapper 語言 擷取網頁內容,使用者須有撰寫程式語言的能 力。
2. 監督式:需要一組的樣本當輸入,而樣本中具 有使用者所需要的資料項目。
3. 半監督式:針對使用者選擇的區塊產生擷取規 則。
4. 非監督式:不需任何標記資料過程以及使用者 互動介面就能夠執行樣本歸納。
接下來,第 3 節將介紹系統架構,討論我們如何設 計 Gadget 產生流程,以及如何讓使用者進行多資料 源的資料整合。
3. 系統架構
本系統設計的目標是讓使用者透過簡單的介 面操作,選擇若干網頁,並將網頁中所需資訊擷取 出來,快速製作個人化的小工具。使用者可透過以 下四個步驟來建立 Gadget:
1. 設定資料來源:首先,使用者可以透過此步 驟指定欲擷取資料的網頁,我們讓使用者以 網址及表單查詢兩種方式來獲取目標頁面。 接著,將所有目標頁面進行資料擷取,產生
網頁 Schema 以及樣版,同時將頁面中的動態 資料欄位擷取出來。接著我們以工作表的方 式呈現資料,讓使用者選取工作表中所需的 資料欄位。最後使用者也可選擇包括網址的 資料欄位做資料的延伸,並由系統進行整合。 2. 撰擇資料呈現模式:目前系統提供表格、清
單、地圖、月曆以及 RSS 等五種資料呈現模 式。清單和表格可將資料分別以巢狀和二維 的方式表達。地圖及日曆則可針對有空間屬 性及時間屬性的資料有更好的呈現方式。而 RSS 則可進一步做為其他 RSS Reader 軟體來 讀取。
3. 模組發佈:使用者可以將選擇好的資料以不 同的顯示模組呈現,並可以發佈到個人化首 頁或部落格等網頁。
圖 1 . 系統流程圖
接下來的小節中將討論我們如何提供一個介 面讓使用者取得相關網頁,以及我們所應用的資料 擷取技術,同時將資料以工作表呈現的方式。
3.1 網頁抓取
我們讓使用者以網址或表單查詢兩種方式來 取得所需的資料頁面。使用者可以直接輸入多個網 址,讓系統自動下載頁面;而當使用者選擇表單查 詢時,系統會先下載使用者指定的網頁,並將網頁 中的表單擷取出來。使用者可以選擇一個 HTML 表 單,並填入參數,如同實際在網頁中查詢的動作。 以圖 2 為例,左方的網頁中共嵌有三個表單,右方 系統介面中,使用者選取了第三個表單,並且填入 查詢的參數。為了讓系統得到回傳頁面,並記錄使 用 者 輸 入 的 參 數 , 系 統 已 事 先 修 改 表 單 中 屬 性 ACTION(查詢目標網址)和 METHOD(的通訊協定 類型),將使用者的查詢導向系統伺服器,再由系統 伺服器查詢目標網頁並擷取回傳頁面。據此做為日 後資料更新及模組重建的參考。
3.2 資料擷取
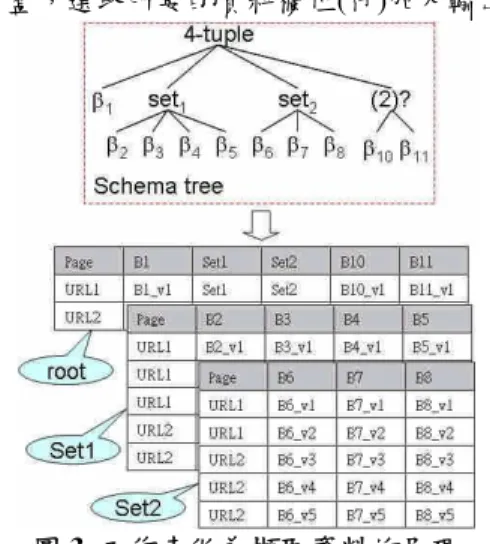
當使用者指定一組同樣版的網頁之後,系統即 可藉由歸納(Wrapper Induction)產生這類型網頁的 Schema 及內嵌的資料檔, Schema 中記錄了網頁的 架構,以及樣版和動態資料的位置,而每一個資料 檔中則記錄了一個網頁中動態資料的內容。本篇論 文中採用 FivaTech[11]作為資料擷取的技術,此為 非監督式 IE 系統,透過 Tree Merging 和 Schema Detection 分析網頁架構,系統能夠自動過濾動態網 頁中的樣版,建立 Schema 並抓出網頁中的動態資 料(XML 擷取檔)。在分析過程中,系統需要 2 個以 上的樣本 DOM 樹作為輸入,透過 DOM 樹的比對 將網頁樣版及資料分開,擷取出 DOM 樹中的動態 資料,並產生對應 Schema。FivaTech 對所有輸入網 頁進行樣本歸納後會輸出為 1 個 Schema 和若干個 擷取檔,對應到所有輸入的網頁。
FivaTech 所產生的 Schema 和擷取檔皆是 XML 樹狀結構。Schema 中每節點都有 id 屬性作為資料 編號。資料的型式包括有樹葉節點所對應的基本屬 性(Basic)以及中介節點所對應的集合(Set)及序列 (Tuple)型態。Basic 節點中包含文字資訊;Tuple 節 點與其子節點定義資料區塊,每個資料區塊亦是樹 狀架構,包含若干 Basic、Set 及 Tuple;Set 和 Tuple 的架構相同,差別在於以 Set 所定義的區塊,在擷 取檔中其所屬的標籤下可能會出現多次,而以 Tuple 在擷取檔中其所屬的標籤下僅會出現一次。資料檔 同 樣 是 以 XML 樹 狀 結 構 , 每 節 點 皆 有 一 個 instanceof 屬性,記錄其屬性值對應到 Schema 中節 點 id 屬性。
3.3 擷取資料呈現
資料擷取後的結果,系統會根據 FivaTech 所產 生的 Schema 建構工作表,並將所有對應資料檔中 的 資 料 放 到 表 格 中 , 再 由 使 用 者 進 行 操 作 。 因 Schema 本身為複雜的樹狀結構,若想將所有資料顯 示於一表格內,將造成選取及視覺上的不便。因此 以分頁工作表的方式呈現資料,除了根節點所對應
的一頁工作表,每一個集合型態的節點亦會對應一 頁的工作表。
以圖 3 的樹狀結構為例,這個 schema 包括二 個集合,因此我們可以 2+1 個共三個 spreadsheet 來 呈現擷取的資料。之後使用者可勾選表格欄位上方 的核對盒,選取所要的資料欄位(行)加入輸出。
圖 3 工作表做為擷取資料的呈現
3.4 延伸網頁的資料整合
當資料集中存在網址欄位時,使用者可選取該 欄位,並以此產生新資料源,此時系統將會自動抓 取欄位中所有網址所在的網頁,並進行樣版歸納產 生新資料集。透過這層機制,讓使用者可以進一步 地擷取每個頁面底下所包含的資訊。
如圖 4 所示,除了第一個資料集是由使用指定 用網址或是查尋表格取得網頁之外,其餘的網址均 是由系統建構的資料集中所包含的網址欄位去抓 取到的網頁,因而形成新的資料集。來自不同資料 集的資料,則需要透過資料合併流程整合成輸出結 果。考慮使用者不一定會在每一個資料集中選取資 料欄位,因此我們採用由下而上資料合併法,先檢 查每一個資料源中是否有選取的欄位,當資料源中 有被選取的欄位,系統對資料源進行中介資料源建 立流程。
圖 4. 網頁抓取流程(Page Fetch Plan)
資料合併原則上可採一階段或二階段的方 式。一階段過程是在每個資料源產生的同時,建立 資料間父子階層的關係,並在使用者於資料源中選 取每個資料欄位後,直接將使用者所選取的資料欄 位記錄下來;二階段的合併流程則會將合併過程延
後到使用者選取所有資料欄位後才進行。若使用者 在多個資料源間來回切換時,反而會增加許多無謂 的工作,因此我們採用二階段合併流程,待使用者 將所有資料欄位選取後,再一次將所有資料源進行 合併。
3.4.1 前置處理
在新資料源產生時,系統會建立新舊資料源間 雙向的對應記錄。必須建立雙向對應關係的理由是 為了多資料源由下而上合併時,每個樹葉資料源皆 能找到其父資料源,因此需建立向上的對應關係, 同時在之後的網頁抓取及資料重建過程也需要有 向下的對應記錄,讓每個父資料源能夠重建底下所 有的子資料源。
記錄內容包含新資料源來自舊資料源哪個欄 位,及新資料源中擷取檔來自舊資料源哪個擷取檔 的哪個項目。對應規則如下:假設舊資料源 DS1 中 的 C 欄位(簡寫為 DS1:C)為新資料源 DS2 的來源網 址欄位,則在舊資料源的 Schema 中,系統會在 DS1:C 欄位中新增屬性 dsChild,記錄對應的新資料 源編號;同時在新資料源的 Schema 根節點中,新 增 src 屬性,記錄來源資料源名稱及欄位編號。
另外對於擷取檔中的資料,因為舊資料源中的 擷取檔會有多個 instanceof 屬性相同的欄位,為了 標明新資料源中每個擷取檔來自於舊資料源擷取 檔中的那個網址欄位,因此我們必須將舊資料源擷 取檔中每個網址欄位增加一個辨識編號。在舊資料 源擷取檔中有被選取的網址欄位皆會新增 fetchId 屬性,屬性值的規則為<欄位編號_遞增序號>,遞 增序號是依照網址欄位在擷取檔中的出現順序而 定,假設擷取檔中有 N 個網址欄位,則遞增序號為 1~N。同時在新資料源擷取檔中,在其根節點新增 src 屬性,記錄來源資料源名稱、來源擷取檔名稱、 欄位編號及遞增序號。
3.4.2 由下向上的合併
當使用者選完資料欄位後,新的資料結構將僅 保留使用者選取的節點,及用來進行網頁抓取的網 址欄位,並將結果另存成中介資料源。中介資料源 的目的在於過濾資料源中未選取項目,為資料源合 併作準備。對於每一個資料源,首先檢查 Schema 中是否具有使用者所選取的欄位,或用來產生新資 料源的網址欄位,並將使用者未選取的欄位過濾 掉。在檢查的同時,我們將所有未過濾掉的欄位 id 記錄在一個 SelectedList 清單中。接下來對於所有對 應的擷取檔,刪除所有 instanceof 屬性值不存在 SelectedList 中的節點。
建立中介資料源後,進行合併演算法將所有 資料源合併,如圖 5 所示。所有的中介資料源會先 放入一個容器中,透過迴圈運算,將容器中所有樹 葉資料源連結到父資料源的對應網址欄位,當容器 中僅剩一個資料源時,即合併完成。
以圖 6 為例,假設現在有一個樹狀資料源架 構,其中包含了 DS1 和 DS2,而 DS1 底下有一個 子資料源 DS2。若使用者希望將 DS1 和 DS2 的內 容進行合併。則 DS2 之 Schema 根節點 src 屬性將 為” DS1:4:12”,因此相對應可以找出 DS1 的 Schema 中的欄位 12,並將 DS2 之 Schema 複製並 取代 DS1 中的 12 欄位。同理,DS2 之每一個擷取 檔根節點 src 欄位也將對應 DS1 某一個擷取檔,其 src 屬性記錄方式為 DS1:xml_dom1:12_1”,代表擷 取檔的來源是父資料源 DS1 擷取檔 xml_dom1 中 fetchId 屬性為 12_1 的網址欄位,如此即可把整個 DS2:xml_dom1 擷 取 檔 內 容 複 製 並 取 代 DS1:xml_dom1:12_1 欄位。依此類推到所有其他的 擷取檔。
圖 5. 由下而上的合併演算法
圖 6.資料源合併範例。
3.5 Gadget 之重建與維護
在 Gadget 產生後,我們必須探討如何更新對 應網頁的資料,讓 Gadget 確實能為使用者監控網頁 更新,以及正確的資料擷取。當 Gadget 所對應的目 標 網 頁 更 新 時 , 若 網 頁 樣 版 維 持 不 變 , 可 利 用 FivaTech Extractor 擷取網頁中的動態資料;而當網 頁樣版改變時,代表既有的 Schema 無法正確地從 網頁中擷取資料,此時對新網頁重新進行樣版歸納 產生新的 Schema,並對新舊版本的 Schema 進行 Schema Matching。
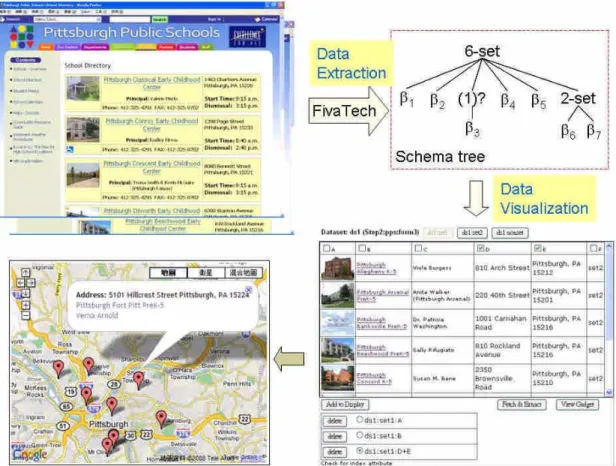
圖 8. Pittsburgh Public Schools 地圖工具建置流程
為了系統更新時能夠重新模擬使用者的頁面 擷取流程,我們採用寬度優先演算法來重建使用者 最初所建立的樹狀資料源架構。此概念根據舊資料 源集合和新資料源集合比對,找出兩集合中對應資 料源,接著利用對應關係,在新資料源集合中重建 舊資料源集合的架構。
4. 案例討論
本節中我們以實例展示系統如何將網頁轉為 顯示模組,同時展示使用者如何透過系統,對網頁 資料進行重複查詢動作,和網頁資料整合。我們以 Pittsburgh Public Schools (http://www.pps.k12.pa.us /pps/site/default.asp)為例,如圖 9 所示。該網站中提 供了學校目錄查詢功能,分門別類顯示各個學校資 訊清單,並可進入每個學校查看詳細資訊。假設現 在使用者希望從學校目錄中,取得每個學校的校 名、校長姓名、學校地址,並將其標示在地圖上學 校所在的位置。由於學校目錄中每頁只顯示 8 個學 校項目,如果使用者手動操作的話,必須一個個拷 貝每個學校的地址,將其輸入如 Google Map 的網 站,相當不便利。若是以我們所設計的系統,則只 需以下的操作即可產生相同結果:
1. 輸入 Pittsburgh Public Schools 學校目錄網 址,並以表單查詢的方式,收集目錄中的所 有分頁(見圖 2)。接著系統會自動對所有分 頁進行樣版歸納,產生資料源。
2. 透過工作表,選取資料源中的校名、校長姓
名、學校地址欄位。
3. 撰取地圖為輸出模式,並連結學校地址欄位 做為 Google Map 標示的輸入。
如圖 8 所示,左上角顯示依圖 2 操作之後所得 的兩個目標網頁。接著系統據此執行 FiVaTech 得到 這個資料源的樣版及 schema(如圖右上方),並且 以工作表的形式呈現給使用者(如圖右下方),最 後使用者只需選擇所要的資料欄位,即可快速整合 資料。圖 8 左下方顯示的即是以地圖模組做為輸出 呈現模式的結果。另外,我們可以選擇清單表格或 是 RSS 等輸出形式(如圖 9)。
圖 9. 表格及清單輸出模組。
5. 比較
本篇提到數個相關研究,這些研究著重於如何
建立一個資訊整合的架構、平台或是能夠產生混搭 工具、網路服務的流程。他們大部分是基於各種不 同的領域,包含軟體開發、系統整合和網路應用。
5.1 網路資訊整合
Andreas Thor 等人[3]研究和我們的相同處在於 皆設計一套流程產生新的服務。但在目標用戶上, [3]研究主要是為了企業資料整合而作,需要有開發 背景人員才能有效使用;相較於我們目標用戶為一 般網路使用者,讓無專業背景的使用者也能操作, 因此我們注重於如何透過互動介面讓使用者進行 資料整合。
Jin Yu 等 人 [9] 所 提 出 的 Presentation Level Integration。在目標上,[9]和我們比較不同,我們 希望能夠針對某個網站中的網頁資料進行擷取、整 合,並以顯示模組將資料包裝為混搭工具;在模組 的重用性上,[9]和我們研究在顯示模組上皆具良好 的重用性;而[9]的元件來源可為不同網站,進行異 質網站間的資料整合,雖與我們所設定的目標不 同,但是異質網站間的資料整合將是我們未來的研 究方向之一。
5.2 區塊擷取
Jie Han 等人[7]製作了他們自己的個人化首 頁,Sandeep Lingam 等人[12]製作一個網頁設計的 擴充元件來擷取網頁資訊,兩篇研究重點皆在於提 供能夠擷取網頁區塊的功能。我們認為僅是網頁區 塊的擷取並不足以滿足使用者對於資料的需求,若 能為使用者擷取出更細部的資訊,可輔助使用者將 資料進行更多應用。相較於我們研究,讓使用者擷 取出網頁中的資料文字,進行進階的資料處理。
5.3 小工具建立
Pollock[14]在系統架構規劃上與我們類似,但 系統目標和樣版歸納的選擇上有不同的考量。在樣 版歸納的選擇,Pollock 選擇了 XWRAP,根據[4] 的研究,屬於手動建立式 IE 系統,遭遇文章內容改 變時適應性不佳,常需要人工重新介入。我們系統 選擇的 FiVaTech 屬於非監督式,當網頁內容改變時 能夠自動產生新版本的 Schema,與舊版本 Schema 進行 Schema Matching。
Dapper[19]的設計目的和我們最為相似,在使 用者介面上 Dapper 提供了虛擬瀏覽器,讓使用者對 於所需資料能夠以「所見即所得」方式點選。在 IE 系統的使用上,根據[4]的研究,我們認為 Dapper 所使用的 IE 系統特性應該是監督式 IE 系統,不瞭 解樣版歸納過程的使用者,標記過程容易困惑究竟 自己選了哪些資料;而我們使用非監督式 IE 系統進 行樣版歸納,使用者不需參與標記過程,在選取資 料欄位時,使用者可明確知道自己選取了哪些內 容,避免標記樣本所造成的困惑。另外, Dapper
不具多資料源的資訊擷取功能,相較於我們的系 統,透過頁面擷取流程,可對頁面中的網址欄位進 行網頁抓取,進行樣版歸納產生新資料源,讓使用 者選取所需項目。
Openkapow[20]主要目的是將網頁資訊轉為網 路服務和 RSS 兩種形式。在設計目的上,我們著重 於如何製作一個使用者能看得到並直接可用的模 組;而 Openkapow 則著重如何將網頁資料轉換為可 自由操作的資料。在目標客戶上,我們希望讓大眾 皆能使用,並且透過最少步驟產生所需的模組;而 Openkapow 的開發工具 RoboMaker,功能性複雜, 不適用於一般使用者。而就資料擷取技術討論, Openkapow 所使用的 IE 系統,必須要完整的 HTML 標籤資訊才能順利擷取出所需資料,若目標頁面的 HTML 標籤有任何變動,所產生的機器人就無法使 用,根據[4]的研究,我們認為 Openkapow 所使用 的 IE 系統特性應該是監督式;相較於我們的非監督 式 IE 系統,我們在網頁更新問題較具彈性及強度。
表 1. Gadget Creation 相關研究比較
最後,以四個方向來比較我們研究和 Pollock、 Dapper、Openkapow 的相異,如表 1 所示。在資料 源,Pollock 和 Dapper 只處理單一資料源的資訊, Openkapow 與我們研究皆能處理多資料源的資訊。 我們研究是以資料源中的網址欄位來產生新資料 源,和 Openkapow 比起來,我們系統能夠快速連結 具有相關性的資料源。Dapper 和我們研究都著重以 網頁介面呈現。在資料擷取技術,Pollock 須使用者 自行撰寫 wrapper 語言;Dapper 和 Openkapow 都是 使用監督式技術,讓使用者參與樣本標記,進行樣 版歸納;而只有我們以非監督式技術,讓使用者可 避 免 參 與 樣 本 標 記 。 在 發 佈 方 式 , Pollock 和 Openkapow 主要輔助使用者將網站資料轉為網路服 務;Dapperm 與我們較著重於將資料直接轉為圖形 化模組。
6. 結論與未來展望
本論文中我們提出一個可運行的系統架構,應 用 Web 資料擷取技術,幫助使用者快速地產生小工 具。相較於其他現有的研究,我們採用非監督式的 資料擷取方法 FiVaTech 使得系統操作減少相當多 使用者的標示動作。另外藉由延伸的網頁抓取及資 料擷取,使得深度的資料整合可以順利達成,也是 本系統的特色之一。然而想讓系統有更好的可用性
和強度,未來還有許多必須改進的挑戰:
1. 許多網頁的資料,須經過登入動作,或是安全 性認證後才能取得。想要擷取這類型的頁面, 往往需要在網頁瀏覽過程中捕捉 Cookies,或是 解決網頁可能自動重新導向的問題。這些問題 不是取得網頁 HTML 原始碼就能解決,需要更 多複雜的處理動作。
2. 在抓取網頁時,目前我們以網址和表單查詢兩 種方式讓使用者取得目標網頁,雖然功能性已 足夠,但使用者介面上仍不夠人性。未來我們 會加強實作,設法建立虛擬瀏覽器,讓使用者 能夠以”所見即所得”的方式收集所需的網頁。 3. 隨著 AJAX 的盛行,漸漸開始有網站放棄傳統
的表單查詢,將所有網頁行為以 Javascript 呈 現。依照我們的作法,目前 Javascript 行為仍無 法監控。未來我們必須設法處理的問題。
致謝
本研究由國科會計畫(96-2221-E-008-091-MY2) 所贊助。
參考文獻
[1] A. H. F. Laender, B. Ribeiro-Neto, A. S. da Silva, " DEByE - Data Extraction By Example," Data & Knowledge Engineering, Vol. 40, No. 2, 2002. Pages: 121-154
[2] A. Jhingran, Enterprise information mashups: integrating information, simply, 2006.
[3] A. Thor, D. Aumueller, E. Rahm, "Data Integration Support for Mashups," Sixth International Workshop on Information Integration on the Web, IIWeb, 2007..
[4] C.H. Chang; M. Kayed, M.R. Girgis, K.F. Shaalan,
"A Survey of Web Information Extraction Systems," IEEE Transactions on Knowledge and Data Engineering, 2006.
[5] F. Daniel, J. Yu, B. Benatallah, F. Casati, M. Matera, R. Saint-Paul "Understanding UI Integration: A survey of problems, technologies and opportunities," IEEE Internet Computing, 2007.
[6] J. Fujima, A. Lunzer, K. Hornbæk, Y. Tanaka,
"Clip, connect, clone: combining application elements to build custom interfaces for information access," Proceedings of the 17th annual ACM symposium on User interface software and technology.
[7] J. Han, D. Han, C. Lin, H.J. Zeng, Z. Chen, Y. Yu, ”Homepage live: automatic block tracing for web personalization," Proceedings of the 16th international conference on World Wide Web, 2007.
[8] J. P. Lage, A. S. da Silva, P. B. Golgher, A. H. F. Laender, "Automatic generation of agents for
collecting hidden Web pages for data extraction," Data & Knowledge Engineering, Vol. 49, No. 2, 2004. Pages: 177-196.
[9] J. Yu, B. Benatallah, R. Saint-Paul, F. Casati, F. Daniel, M. Matera, "A framework for rapid integration of presentation components," Proceedings of the 16thinternational conference on World Wide Web, 2007.
[10] L. Liu, C. Pu, W. Han, “XWRAP: An XML-Enabled Wrapper Construction System for Web Information Sources,” 16th International Conference on Data Engineering, ICDE, 2000. [11] M. Kayed, C.H. Chang, M.R. Girgis, K.F.
Shaalan, "FiVaTech: Page-Level Web Data Extraction from Template Pages," Workshops on Data Mining in Web2.0 Environment, 2007 [12] S. Lingam, S. Elbaum, "Supporting end-users in
the creation of dependable web clips," Proceedings of the 16thinternational conference on World Wide Web, 2007.
[13] V. Crescenzi, G. Mecca, and P. Merialdo. "An Automatic Data Grabber for Large Web Sites," Proceedings of the Thirtieth international conference on Very large data bases, VLDB 2004. Pages: 1321 - 1324.
[14] Y.H. Lu, Y. Hong, J. Varia, D. Lee, "Pollock: automatic generation of virtual web services from web sites," Proceedings of the ACM symposium on Applied computing, 2005.
[15] iGoogle, "http://www.google.com.tw/ig". [16] Netvibes,
http://www.netvibes.com/errors/migration.php. [17] Google Map API,
http://code.google.com/apis/maps/. [18] Google Gadget Developer’s Guide,
http://code.google.com/apis/gadgets/docs/dev_g uide.html.
[19] Dapper: The Data Mapper, http://www.dapper.net/.
[20] Openkapow, http://openkapow.com/.
![圖 2 以查詢表格抓取網頁 [1]和 Lage 等人在 2004 年所發表的 ASByE (Agent](https://thumb-ap.123doks.com/thumbv2/123deta/5785836.33513/3.892.173.723.106.359/lage-asbye-agent.webp)