The 28th Annual Conference of the Japanese Society for Artificial Intelligence, 2014
- 1 -
LS-Q
学習
探索
停滞
回避
Exploration and Stagnant Loop Avoidance by LS-Q Learning
浦
大輔
*1
高橋
達二
*2高橋
優太
*2 Daisuke Uragami Tatsuji Takahashi Yuta Takahashiワン
*3
松尾
芳樹
*1 Ali Alalwan Yoshiki Matsuo
*1
東京工
大学
ン
ュ
ン
学部
*2
東京電機大学理工学部
School of Computer Science, Tokyo University of Technology School of Science and Technology, Tokyo Denki University
*3
東京工
大学大学院
情報
研究
Tokyo University of Technology Graduate School
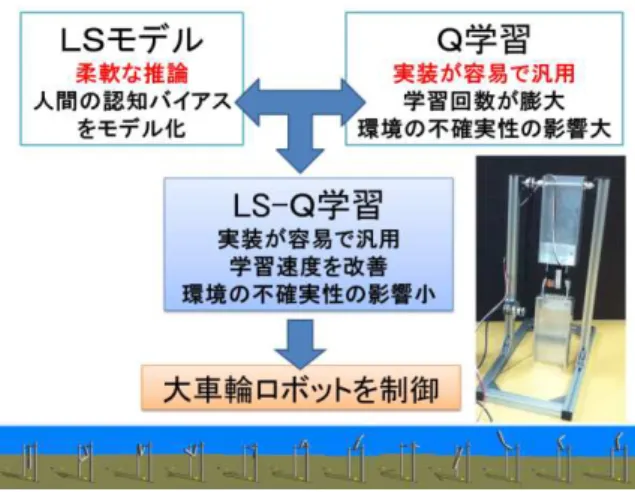
In a previous study, we proposed a novel reinforcement learning architecture LS-Q that applies human cognitive biases to action selection in Q-learning. It has become clear that LS-Q learning adaptively searches in the environment with large uncertainty. In this study, we analyze the aspect in which LS-Q learning adeptly escapes from local optima, avoids stagnant loops through states with little rewards, and return to efficient motion learning.
1.
じめに
環境 相互 作用 基 学 習 キ ク 強
学習 注目 い 強 学習 未知 環境 い
試行錯誤的 探索 多 報酬 得 目的
い 有 限回 試 行 錯誤 い 探索 環 境
知 識 蓄 積 優 先 既 得 い 知 識 従
報酬 獲得 優先 断 い わえ
報 酬 遅 延 探 索 知識 利用 遥 択 困
う 課 題 え 々 人 間 推 論 傾 向 論 理 階層 混
同 傾向 模 Q学習 応用 強 学習
LS-Q 提案 い [Uragami 2014] LS-Q学習 不確
実 性 大 い環 境 い 適 応 的 探 索 行 う いう 明
あ
本研究 大車輪 運動獲得 例 LS-Q 学
習 報 酬 少 い 状 態 停 滞 巧 回
避 様 相 解 析 普 遂 的 探 索 理 論 局 性 や 論
理階層 混同[高橋 2013] あ い 部観測[松 2000] 意
義 効用 考察
2. LS-Q
学習によ
大車輪ロボット
実現
人間 知 推論や意思決定 偏
p ば q q ば p 推論 傾向性 対称性
あ う 推 論 論 理 的 必
い 経 験的 ば ば 有用 あ 人間 知 能 柔軟
関係 い 考え [服部2008] LS 人間 対
称 性 定 的 再 現 一 方 1 状 態 強 学 習
課題 あ n本腕 ン 問題 い 優
ン 示 知 い [篠原 2007]
々 状態数 N個 あ 一般的 強 学習課題
適応可能 強 学習手法 あ Q学習 行動遥択 LS
応用 手法 LS-Q学習 提案 い Q学習 実
装 容 易 多 学 習 対 象 適 用 可 能 あ 学 習 要
試 行 回 数 膨 大 あ や 環 境 不 確 実 性 影 響 大
い 課題 あ LS-Q学 習 学習 速度 改善 且 環
境 不 確 実 性 影 響 小 大 車 輪
制御 ュ ョン い 図1
2.1 LS-Q学習
LS-Q学習 行 動遥択 学習 簡単 述
図2 詳細 文献[Uragami 2014] LS-Q学習
C-table 基 い 行動遥択 行う C-table greedy 行動
Q 最大 行動 遥択 回数 以外 行動 遥択
回数 状態 記録 あ C-table 次式
う LS 評価
( |行動 )
⁄
⁄ ⁄ 連 絡 先 : 浦 大 輔 東 京 工 大 学 ン ュ ン 学
部 東京都八王子市 倉 1404-2 [email protected]
2N5
-
OS
-
03b
-
1
The 28th Annual Conference of the Japanese Society for Artificial Intelligence, 2014
- 2 - LS(greedy|行動 A) LS(greedy|行動 B) 計算 大 い
方 行 動 LS-greedy 行 動 学 習 遃 程 ε
-greedy行動遥択 LS-greedy 行動 以外 行動
定 確率 遥択 Q 更新 通常 Q学習
同様 手続 行う
2.2 大車輪ロボットへ 適用
大車輪 図 1中 写真 う 体操 鉄棒競技
模 あ 鉄棒 接続部 ョ ン
腰部 関節 能動的 稼働
振 運動 行う 鉄棒 接続部 第 ョ ン
腰部 関節 第 ョ ン 呼 第 ョ ン
角度 角速度 第 ョ ン 角度 割 散
LS-Q学習 Q 学習 状態 定義
行動 第 ョ ン 曲 A0 伸ば A1 停 A2 通
あ 報 酬 鉄 棒 対 先 第 ョ ン 先 端
振 角 度 比 例 う 定義 先 鉄棒 真
位置 場合 1 最大 先 鉄棒 真 位置
場 合 0 最 小 う 設 定 本 研 究 ODE
(Open Dynamics Engine) 用い ュ 構築 実験
行
3.
停滞ループ
回避
研究 果 状 態 割 粗 不確定性 大
い環境 い LS-Q学習 Q学習 良い ン
示 明 い [Uragami 2014] え
本 研究 状 態 割 極 端 粗 第 ョ ン 角 度
6状態 P0, P1, P2, P3, P4, P5 第 ョ ン 角速度 3
状 態 W0, W1, W2 第 ョ ン 角 度 3状 態 R0, R1,
R2 合計 6×3×3=54 状態 状態数 少 い 不確定
性 大 学習時間 短縮 いう実用 利点
わえ 状態遤移 可視 易 いう解析 利点 あ
図 3 ュ ョン結果 100 試行 均 あ 0.2
1 行動遥択 Q びC-table 更新
行う 横軸 学習時間 1000 1
状 態 初 期 状 態 戻 い 縦 軸 1 毎 獲 得 報
酬 合計 あ 学習 初期 完全 ン 行動 遥択
1 毎 LS-greedy greedy 行 動 遥 択 確 率
0.02増や 最後 10 完全 LS-greedy greedy
行動 遥択 LS-Q 学習 Q学習 比較 学習
開始 徐々 LS-Q学習 獲得報酬 Q学習 回
い わ Q学習 学習 終盤 ン 行
動遥択 割合 小 獲得報酬 減少 い 一方
LS-Q 学習 獲得報酬 一 減少 い 後回
復 学習 終了時 高い獲得報酬 得 い
図2:LS-Q学習の行動 択と学習のア ゴ ズム
図3:学習曲線
図4:回転角の変化
The 28th Annual Conference of the Japanese Society for Artificial Intelligence, 2014
- 3 -
学習 終盤 獲得報酬 減少 現象 報酬 少 い状
態 停滞 [坂井2010] 原因 あ 図4
ン 行動遥択 割合 0 51 目 最初 127
い 第 ョ ン 回 転角 変
あ Q学習 回転角 0.5 ン 0.5
ン 間 振動 い わ 一方 LS-Q 学習 停
滞状態 5~45 付近 遃渡状態 45~70 付
近 経 回転 至 い
図5 52 127 状態遤移図 あ
同心 54 割 区 P0, P1, P2, P3, P4,
P5 × W0, W1, W2 × R0, R1, R2 指定 状態
割 当 い 直 線 状 態 間 遤 移 表 遤
移回数 多いほ 線 太 い Q学習 図 場合 同
心 中心側 R2 P3 P4 間 遤移 中 い
第 ョ ン 曲 姿 勢 第 ョ ン 回 転角 小
い状態 留 い 停滞 意味 い 多
報 酬 得 一 見 不 適 あ い 遠 回 見
え 一 第 ョ ン 伸 ば 報 酬 小 い状 態 経
必要 あ いわゆ 報 酬 遅 延 問 題
Q 学習 原理的 環境 性 満 条件
報酬 遅延 換算 多 報酬 得 う 行動
遥 択 最 適 本 研 究 学 習 環 境 状 態 割
粗 環 境 不 確実 性 大 い 最 適 行動 得
い い 一方 LS-Q学習(図 5 ) 第 ョ ン 伸
ば 姿勢 R0 経 第 ョ ン 回転角 大 い状
態 P0, P1, P5 至 い LS-Q学習 停滞
回避 い
LS-Q学習 う 停滞 回避 い
う ?図6 停滞 中 あ 状態 P3, W1, R2
LS 図 びC 図 わ C-table
変 あ 状 態 第 ョ ン 曲 先 振
状態 R2 あ 行動 A1 伸ば 遥択
先 振 必要 あ 図 初期
A0 A2 LS 最大 い
状態 留 A0 A2 LS 降 一方
遥択 い い 関わ 相対評価[高橋 2013] 通
A1 LS 昇 A1 LS A0 A2 LS
逆転 結果 A1 遥択 停滞状態 脱出
注目 C 図 ほ 変 い い
あ 図中 A1-greやA2-not A1 遥択
行動 Q 最大 あ 回数 や A2 遥択
行動 Q 最大 回数 あ 図中 0
段階 既 1000 ×50 学習時間 経 い
0~40 あ 連続 A0 び
A2 遥択 A0-not びA2-not 増 い 比率
僅 あ 間 A1 遥 択 い い
A1-gre び A1-not 変 い い わ LS
図 急激 変 い LS 式(1)
効 果 あ 人 間 推 論 柔 軟 効 用 あ 考 え [高橋2013]
図7 通常 Q学習 図 LS-Q学習 図 Q
変 あ 通常 Q学習 A2 Q 最大
A2 遥択 続 A2 Q 減少 い
他 逆 転 至 い い 一 方 LS-Q学 習 前 半
複数 行動 入 替わ 最大 い 後半 A1
最大 Q い 適 学習 い わ
通常 Q学習 LS-Q学習 図 Q 至
十 回数 Q 更新 行 い 適 Q
図6:LS-QにおけるLS値とC値の変化
The 28th Annual Conference of the Japanese Society for Artificial Intelligence, 2014
- 4 - 束 い い 原因 環境 非 性 あ
考え 詳細 解析 今後 課題 あ
4.
おわ
に
本 研 究 人 知 特 性 応 用 強 学 習
探 索 効 率 高 且 停 滞 回 避 様 相 解 析
停滞 要因 環境 不確実性 非 性 あ
考え 非 的 環境 い 学習可能 強 学
習 い 提 案 い 基 本 潜
ク 再 構 あ 時 系 列
十 記 憶 且 時 系 列 見 渡
必要 あ 工学的 う 方法 遥択肢 あ う
人間 知特性 触発 キ ク 開発
あ い 人 間 知 能 理 解 い 問 わ う
記憶 起源 あ =脳 中 小人 不 あ
い 創発 あ 太 1 計算 中 包
遃 去 部 的 真 意 味 並 列 再 構築 人工 知 能
あ い 脳 学 最 要 問題 掲 い [太
2014] 本 研 究 文 脈 い 太 主 張
非 的 環 境 ク =1
計 算 中 包 遃 去 = 真 意
味 並列 部 的 再構 あ う 本研究 果
LS わ 人間 対称性 記
再構 あ い 再現前 [Deleuze 1968] 関係 い 考
え う 視点 再現前 =表象あ い 記号 再
考 記号創発 ク [谷口 2000] 部観測 繋
断 補助線 あ う
謝辞
本研究 一部 25 度東 大学電気通信研究 共同
ク 研究H25/A12 不定 環境 適応能 階層
横 断 的 解 明 工 学 的 応 用 東 京 電 機 大 学 総 合 研 究 研 究 Q13K-03, Q11K-02 本 学 術 振 興 会 学 研 究 費 補 助 金 25730150 .
参考文献
[Uragami 2014] Uragami, D., Takahashi, T., Matsuo, Y.: Cognitively inspired reinforcement learning architecture and its application to giant-swing motion control, BioSystems, 116, 1-9, 2014.
[高 橋 2013] 高 橋達 二: 論 理的 階 層 縮 部観 測
乗 越え, 2013 度人工知能学会全国
大会(第27回)予稿 , 1L3-OS-24a-2, 2013.
[松 2000] 松 孝一郎: 部観測 何 青土社 2000
[服部 2008] 服部 史: 推論 断 等確率性仮説:思考 対
称性 適応的意味, 知 学, 15, 3, 408–427, 2008.
[篠原 2007] 篠原修二 口亮 桂 浩一 新 恒 : 因果性
基 信念形 N本腕 ン 問題 応用
人工知能学会論文 22巻1号G pp.58-68 2007
[坂 井 2010] 坂 井 直 樹 川 辺 直 人 原 之 豊 希 薮 哲
郎: 強 学 習 用 い 大 車 輪 運 動 獲
得 行 動 形 態 考 察 計 測 自 動 制 御 学 会 論 文 Vol.46 No.3 pp.178-187 2010
[太 2014] 太 宏之: 性 前提 い情報処理
向 第 25回計測自動制御学会 SI部門共創
部会研究会 第8回 部観測研究会 共同開催 , 2014.3.8
口頭講演 予定
[Deleuze 1968] Deleuze, G., Différence et repetition, P.U.F.,
1968 ( 差異 復 財津理訳 河出書 新社 1992).
[谷口 2010] 谷口忠大: ュ ケ ョン 創