Recognition on Specific Domains from the Web
Keiji Shinzato1, Satoshi Sekine2, Naoki Yoshinaga3, and Kentaro Torisawa4
1 Graduate School of Informatics, Kyoto University
2 Computer Science Department, New York University
3 Japan Society for the Promotion of Science
4 Graduate School of Information Science, Japan Advanced Institute of Science and Technology [email protected], [email protected],
{n-yoshi,torisawa}@jaist.ac.jp
Abstract. This paper describes an automatic dictionary construction method for Named Entity Recognition (NER) on specific domains such as restaurant guides. NER is the first step toward Information Extrac- tion (IE), and we believe that such a dictionary construction method for NER is crucial for developing IE systems for a wide range of domains in the World Wide Web (WWW). One serious problem in NER on specific domains is that the performance of NER heavily depends on the amount of the training corpus, which requires much human labor to develop. We attempt to improve the performance of NER by using dictionaries auto- matically constructed from HTML documents instead of by preparing a largeannotated corpus. Our dictionary construction method exploits the cooccurrence strength of two expressions in HTML itemizations calcu- lated from average mutual information. Experimental results show that the constructed dictionaries improved the performance of the NER on a restaurant guide domain. Our method increased the F1-measure by 2.3 without any additional manual labor.
1 Introduction
The methodologies to choose necessary information from a huge number of doc- uments in the World Wide Web (WWW) and to provide it to a user in a concise manner are very important in these days. Although Information Extraction (IE) can be regarded as one of such methodologies, the diversity of the domains found in the WWW does not allow us to adapt existing IE methods in the WWW. A major problem is that an existing Named Entity (NE) tagger, which is a key component for conducting IE, cannot be applied to a wide range of domains in the WWW, and that developing a new NE tagger for a new domain is a time-consuming task.
A variety of methods have been so far proposed for NE Recognition (NER) [1– 4]. These studies aimed at NER for a rather small number of predefined NE categories for competitions [5, 6], and achieved high accuracies by relying on
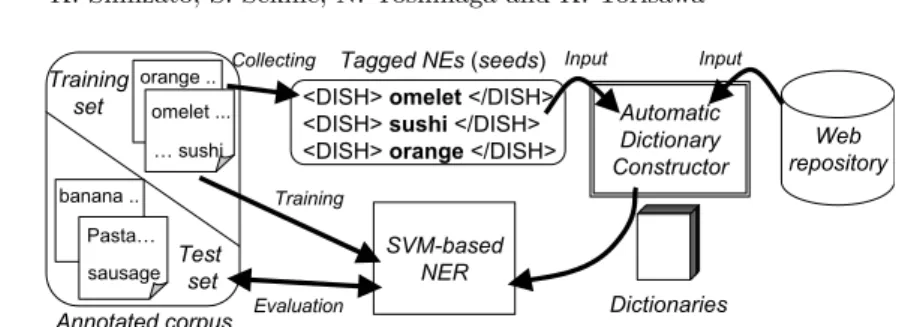
Fig. 1. A procedure flowchart for constructing domain-specific dictionaries a large amount of annotated corpora prepared for the competitions. However, if one tries to develop NE taggers for a new domain with new NE categories, the costs of preparing annotated corpora for the categories are quite large, and it is still quite difficult to achieve high performance without much labor for annotating a large number of documents.
One possible way to solve this problem is to define general-purpose fine- grained NE categories and develop large annotated corpora for them. Sekine et al. have tried to define 200 fine-grained NE categories including PRODUCT NAME and CONFERENCE, and are developing NE taggers by using annotated corpora [7]. Although their set of NE categories may look like a sufficiently detailed classification, it is still too coarse to conduct IE on specific domains such as a restaurant domain, which is addressed in this work. For instance, Sekine’s categories do not contain names of dishes or ingredients. Another method of developing NE taggers for new domains is to employ existing generic handcrafted dictionaries, such as WordNet [8]. Nevertheless, handcrafted dictionaries often fail to cover domain specific expressions, such as names of dishes and restaurants. The aim of this work is to improve the performance in NER for a new do- main with small costs by using a WWW-based automatic dictionary construc- tion method for NE categories on the domain. In other words, we are trying to achieve higher performance in NER by using automatically constructed dic- tionaries from the WWW instead of by enlarging an annotated corpus, which requires high developmental costs. (Note that a use of a small annotated corpus is unavoidable anyway. The point is that we can achieve higher accuracy without enlarging the corpus.) As a basic method for NER, we follow an existing machine learning based approach, and major contribution of this work is in a method of automatic construction of dictionaries for specific domains and use of them in NER. Our dictionary construction algorithm uses the NEs in the annotated cor- pus as seeds, which are expanded by using a large number of HTML documents downloaded from the WWW. More specifically, our method uses itemizations in HTML documents to obtain expressions that are semantically similar to the seeds, as depicted in Figure 1. A similar idea has been proposed for hyponymy relation acquisition [9]. One difference is that we consider the frequency of cooc- currences in itemizations and try to clean up erroneous dictionary entries. We show that NER performance on the restaurant domain can be improved by using the automatically constructed dictionaries.
ADDRESS (248), AREA (251), ATMOSPHERE (364), BGM (26), BUSINESS STYLE (27), CARD (223), CHEF (76), CHILD CARE (39), CLEANNESS (16), CUISINE (307), C DAY (31), C EVALUATION (140), C NUMBER (107), C PROFILE (47), C PURPOSE (193), DAY (397), DISH MATERIAL (974), DISH QUALITY (1,188), DISH (2,064), DISTANCE (212), DRESS (2), EMAIL (13), EMPLOYEE (103), ENTERTAINMENT (17), EQUIPMENT (211), EXAM- PLE (2), EXTERIOR (43), FAX (51), FORM (260), HANDICAPPED CARE (0), HIS- TORY (81), HOW TO EAT (261), IF POSSIBLE (1), ILLUMINATION (23), INTERIOR (69), LIKE (2), LINE (162), LOCATION (68), MANAGER (99), MEDIA (15), NAME (736), NEAR FACILITY (79), NOT (124), OK (0), OR (0), OTHER SPECIALITY (24), PARK- ING (35), PET CARE (13), POPULARITY (90), PRICE (474), QUIETNESS (7), REGU- LAR CUSTOMER (182), RESERVATION (55), SERVICE OTHER (159), SMOKING CARE (5), SPACE (43), STATION (230), STOCK (156), TABLES (63), TABLEWARE (22), TEL (247), TIME (373), URL (47), VIEW (2)
Fig. 2. NE categories for the restaurant domain (# of instances.)
In the remainder of this paper, Section 2 describes existing machine learning based Japanese NER methods and our small annotated corpus for the restaurant domain. Section 3 explains an automatic dictionary construction method using HTML documents. Section 4 gives an overview of our NE tagger that utilizes the automatically constructed dictionaries. Section 5 gives experimental results.
2 Background
2.1 Machine Learning Based Japanese Named Entity Recognition Several machine learning techniques, such as Support Vector Machines (SVMs) [10] and the Maximum Entropy model [11], have been employed for IREX [6], Japanese NER competition [12, 3, 13, 14]. The SVM-based approach, originally proposed in [3], showed the best performance [14]. We followed the method proposed by Yamada et al. [3], briefly overviewed below, in implementing our NE tagger, and augment it with automatically constructed dictionaries.
Yamada’s method decomposes a given sentence into a sequence of words by using an existing morphological analyzer, and then deterministically classi- fies subsequences of words into appropriate NE categories from the end of the sentence to the beginning. For the annotation of NE categories, Yamada et al. employed IOB2 [15] as a chunk tag set for eight categories defined in the IREX competition. The utilized feature set includes the word itself, part-of-speech tags, character types, and the preceding and succeeding two words. The information of succeeding NE tags is also used since the NE tagger has already determined them and they are available. See [3] for details.
As for use of dictionaries in machine learning based NER, NTT goitaikei [16], a manually tailored large-scale generic dictionary, has been already employed for the IREX competition in some studies [13, 14]. The improvements were around 1.0 in F1-measure, and were less than the improvement achieved by our method. 2.2 Restaurant Corpus
Although our aim is to achieve high performance in NER without a large anno- tated corpus, a use of a small annotated corpus is unavoidable. The small corpus
(A) An <DISH><DISH MATERIAL> apple </DISH MATERIAL> tart </DISH> was
<DISH QUALITY>good taste </DISH QUALITY>.
(B) <RESERVATION>If you are going to visit our restaurant, please make reservations so we can give you better service. We have a webpage for your convenience, or you can contact us by telephone or fax.</RESERVATION>
Fig. 3. Examples of annotated sentences in the restaurant corpus
is used not only for training classifiers for NER but also for collecting seed ex- pressionsfor automatically constructing dictionaries. This section describes the corpus we used in this work.
Since our main objective is to extract from the specific domain (restaurant, in this paper) the information that are useful to people, we predefined 64 NE categories that roughly correspond to aspects of restaurants that are addressed by frequently asked questions about restaurants. We collected inquiries about restaurants posted on Internet bulletin boards (http://oshiete.goo.ne.jp/ and http://d.hatena.ne.jp/), and defined a set of NE categories. The defined NE categories are listed in Figure 2. Note that most of the categories in the figure have not been considered in the existing NE categories [5–7].
To develop an NE tagger in the restaurant domain, we collected documents that describe restaurants, and annotated them with the NE tags. We call this corpus restaurant corpus. We simply collected names of restaurants located in Jiyugaoka (one of the popular shopping area in Tokyo) from a certain web site (http://www.gnavi.co.jp/). We gave each restaurant name as a search query to a commercial search engine for gathering HTML documents that describe the restaurant. We then manually extracted sentences that describe the restaurant from the gathered HTML documents.
We obtained 745 documents including 6,080 sentences and 118 restaurant names. One person spent six weeks for annotating the documents with tags cor- responding to the 64 NE categories for the restaurant domain. Some examples of annotated sentences are shown in Figure 3. An important point is that the anno- tated corpus for the IREX consists of 1,174 documents, including about 11,000 sentences [6], and that the restaurant corpus is smaller than this. Note that IREX assumed only eight NE categories. Considering that our task has many finer grained NE categories and that a data sparseness problem is more likely to occur, achieving high accuracy in our task is expected to be more difficult than in the IREX competition. This is the motivation behind the introduction of automatically constructed dictionaries for our NE categories.
3 Automatic Dictionary Construction from HTML
documents
We automatically constructed dictionaries from HTML documents according to the following hypothesizes. Hypothesis 1 is the same as the one proposed in [9], while Hypothesis 2 is newly introduced in this study.
<UL><LI>LOVE Food!</LI>
<OL><LI>Canlis Steak</LI>
<LI>Sushi</LI>
<LI>Pan Fried Dumpling</LI>
<LI>Chocolate Cake</LI>
</OL></UL>
Fig. 4. Sample HTML code of an itemization.
Hypothesis 1: Expressions included in identical itemizations are likely to be semantically similar to each other.
Hypothesis 2: Expressions that frequently cooccur with many instances of an NE category in itemizations are likely to be proper dictionary entries of the category.
Our dictionary construction procedure consists of three steps.
Step 1: Extract expressions annotated as instances of each NE category from the annotated corpus. Note that the extracted expressions include not only single words but also multiword expressions, and even a sequence of sentences such as those shown in Figure 3 (B).
Step 2: Extract sets of expressions listed in each itemization from HTML doc- uments. We call the extracted set an Itemized Expression Set (IES). Step 3: For each NE category, select from among the IESs extracted by Step 2
those expressions that cooccur with many instances of the each NE category extracted in Step 1 in the IESs, and regard them as dictionary entries. In Step 3, the procedure tries to select from the extracted IESs in Step 2 expres- sions that can be regarded as proper dictionary entries of an NE category. The detailed explanation of Steps 2 and 3 are described below.
3.1 Step 2: Extracting IESs
We follow the approach described in [9] to extract IESs from HTML documents. First, we associate each expression in an HTML document with a path that spec- ifies both the HTML tags enclosing the expression and their order. Consider the HTML document in Figure 4. The expression “LOVE Food!” is enclosed by tags
<LI>,</LI> and <UL>,</UL>. If we sort these tags by nesting order, we obtain a path (UL,LI) that specifies the information regarding the expression’s loca- tion. We write h(UL, LI), LOVE Food!i if (UL,LI) is a path for the expression
“LOVE Food!”. We then obtain the following paths for the expressions from the document.
h(UL, LI), LOVE Food!i, h(UL, OL, LI), Canlis Steaki, h(UL, OL, LI), Sushii, h(UL, OL, LI), Pan Fried Dumplingi, h(UL, OL, LI), Chocolate Cakei
Our method extracts a set of expressions associated with the same path as an IES. In the above example, we obtain the IES {Canils Steak, Sushi, Pan Fired Dumpling, Chocolate Cake}.
3.2 Step 3: Selecting Dictionary Entities Based on Average Mutual Information
Let us assume constructing a dictionary regarding the DISH category. We refer to the set of DISH category instances extracted from the restaurant corpus in Step 1 as IDISH. The procedure collects IESs including at least one element of IDISH from all extracted IESs. We denote the set of expressions included in the collected IESs as EDISH. Note that we discarded expressions included in only one IES and expressions that cooccurred with only one element in IDISH
from EDISH since such expressions are less likely to be proper dictionary entries. Although we can regard each element of EDISH as an entry in the dictionary of the DISH category, the dictionary erroneously includes a large number of non-dish-names. We thus filter out such expressions by using a score, which is the average mutual information among each expression included in EDISH and instances in IDISH. This score reflects Hypothesis 2. We sort the EDISH entries according to the scores, and use only the top N entries in NER. The score for expression e ∈ EDISH is defined as follows.
scoreDISH(e) = ∑
i∈IDISH
P(e, i) log2 P(e, i) P(e) · P (i),
where P (x) is the probability of observing expression x in all extracted IESs gathered in Step 2, and P (x, y) is the probability of observing expressions x and y in the same IES. The score gives a large value to expressions that frequently cooccur with many instances of the NE category in IDISH and that infrequently cooccur with expressions other than the instances.
A problem with the above score is that it tends to give large values to expres- sions that frequently appear in itemizations. This has an undesirable effect on the quality of resulting dictionaries. Although we prefer to include such specific dish descriptions as “baked cheesecake” in the dictionary, the score tends to give a higher score to more generic dish names such as “cheesecake,” and top entries tend to include only generic single words, which are often inappropriate as dish names. This is because the frequency of a single word tends to be larger than those of multiword expressions and our score is likely to give a large value to sin- gle word. We therefore increase the score of each multiword expression by using the score value of its head (e.g., “cheesecake” in the case of “baked cheesecake”). We finally used the following score:
score′DISH(e) = scoreDISH(e) + scoreDISH(ehead),
where ehead is the head of e. In Japanese, the head of a multiword expression e is usually its suffix substring. We thus collected the other expressions in EDISH
that were included in e as its suffix substring, and regarded these expressions as candidates of the e’s head. We then assumed that the longest expression among these expressions was the head of e. When e did not include any other expressions in EDISH as its suffix, we used 0 as the value of scoreDISH(ehead).
4 Named Entity Taggers for the Restaurant Domain
Now, we describe our NE tagger for the restaurant domain. As mentioned before, we basically follow Yamada’s method in implementing our NE tagger.
Our NE tagger first decomposes a given sentence into a word sequence by using MeCab (http://mecab.sourceforge.jp/). Next, it obtains feature vectors including the word itself, part-of-speech tags, character types defined in [3], NE tags of the two succeeding words, and the preceding and succeeding two words for each word.
Then, the tagger sets the feature values concerning dictionary entries that have been automatically constructed by the method described in Section 3 as follows. Basically, it gives a chunk tag to all words in subsequences of dictionary entries according to the method proposed in [13]. As chunk tags, we employed a Start/End tag model [12]. For example, assume that the sentence “I ate a Kobe hamburger steak as a light meal.” is given as input and “Kobe hamburger steak” and “hamburger” are included in a dictionary regarding the DISH category; the features are set as below.
features I ate Kobe Steak Hamburger as...
DIC DISH-S 0 0 0 0 1 0
DIC DISH-B 0 0 1 0 0 0
DIC DISH-I 0 0 0 1 0 0
DIC DISH-E 0 0 0 0 1 0
Note that the feature DIC DISH-S means that a word is a single word entry in the dictionary for the DISH category. The values of DIC DISH-B and DIC DISH-E indicate if the words are the beginning and the end of a dictionary entry respec- tively. DIC DISH-I is assigned to a word in an entry other than its beginning and end.
The NER gives the obtained feature vectors to an SVM and deterministically assigns the tags according to the IOB2 scheme from the end of the sentence to its beginning. We chose TinySVM (http://chasen.org/˜taku/software/TinySVM/) as an SVM implementation. We used the polynomial kernel of degree 1 pro- vided in TinySVM according to the observations obtained in experiments using the development set. Another important point is that, although Yamada et al. employed a pairwise method for extending SVMs to multi-class classifiers, we employed a one-vs-rest method to extend SVMs. According to [13], there is no significant difference between the performances of the two methods. In addition, the one-vs-rest method requires fewer classifiers than the pairwise method does. This is crucial for our NER because the number of categories is rather large.
5 Experiments
5.1 Setting
In our experiments, we disregarded the following tags from the restaurant corpus because it was difficult to recognize these by current NER methodologies.
Table 1. Size of constructed dictionaries
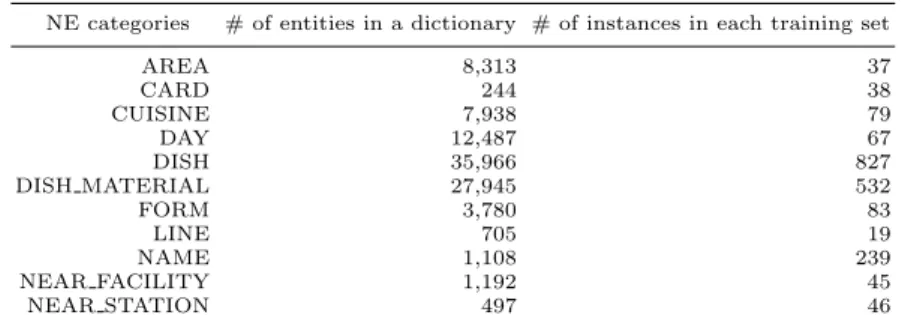
NE categories # of entities in a dictionary # of instances in each training set
AREA 8,313 37
CARD 244 38
CUISINE 7,938 79
DAY 12,487 67
DISH 35,966 827
DISH MATERIAL 27,945 532
FORM 3,780 83
LINE 705 19
NAME 1,108 239
NEAR FACILITY 1,192 45
NEAR STATION 497 46
These numbers are the average numbers of instances and dictionary entities in each evaluation.
DISH:八宝菜(shop suey),エビフライ(fried shrimp),抹茶(powdered green tea),*ウ スターソース(worcestershire sauce),*インゲン(kidney bean),キャラメル(caramel),米 (rice),*砂糖(sugar),*よしみ寿司(name of a sushi bar),*卵(egg),*通勤時間(rush hour), DISH MATERIAL:にんじん(carrot),ピーマン(green pepper),牛乳(milk),こしょう (pepper),*サラダ油(cooking oil),しょうゆ(soy sauce),小麦粉(wheat),*材料(material), オマール海老(lobster),お豆腐(tofu),*アイスコーヒー(iced coffee)
Expressions starting with “*” are inappropriate entries. Fig. 5. Examples of entries in constructed dictionaries
– NE tags annotated across a period (See Figure 3(B)). – NE tags representing logical conditions (e.g., NOT and OR). – NE tags whose total frequency is less than 10.
After removing these tags, we conducted experiments for remaining 53 tags and evaluated the performance of our NE taggers by 5-fold cross-validation on the restaurant corpus described in Section 2.2.
For constructing dictionaries, we downloaded 1.0 × 107 HTML documents (103 GB with HTML tags) and extracted 3.01 × 106 IESs including 8.98 × 106 individual expressions by the method described in Section 3.1. We constructed the dictionaries for 11 categories listed in Table 1 from these IESs. We selected these NE categories because their instances were likely to be noun phrases and that they frequently appeared in the restaurant corpus. For each NE category, our dictionary construction method can collect more than 10 times as many expressions as those annotated as its instances. In other words, our method can generate a large number of dictionary entries from the given instances of each NE category. Some examples of dictionary entities are listed in Figure 5.
5.2 Contribution of Constructed Dictionaries
We investigated the contribution of the dictionaries automatically constructed from HTML documents. We checked the NER performance when we increased the size of the dictionaries of each NE category by 10%. Note that when the size
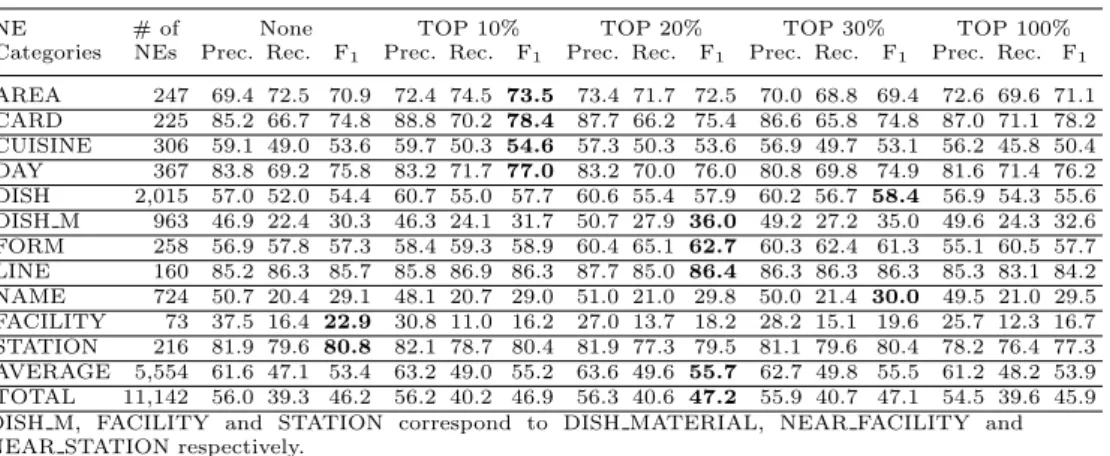
Table 2. The performances of NE taggers by using different-sized dictionaries.
NE # of None TOP 10% TOP 20% TOP 30% TOP 100%
Categories NEs Prec. Rec. F1 Prec. Rec. F1 Prec. Rec. F1 Prec. Rec. F1 Prec. Rec. F1 AREA 247 69.4 72.5 70.9 72.4 74.5 73.5 73.4 71.7 72.5 70.0 68.8 69.4 72.6 69.6 71.1 CARD 225 85.2 66.7 74.8 88.8 70.2 78.4 87.7 66.2 75.4 86.6 65.8 74.8 87.0 71.1 78.2 CUISINE 306 59.1 49.0 53.6 59.7 50.3 54.6 57.3 50.3 53.6 56.9 49.7 53.1 56.2 45.8 50.4 DAY 367 83.8 69.2 75.8 83.2 71.7 77.0 83.2 70.0 76.0 80.8 69.8 74.9 81.6 71.4 76.2 DISH 2,015 57.0 52.0 54.4 60.7 55.0 57.7 60.6 55.4 57.9 60.2 56.7 58.4 56.9 54.3 55.6 DISH M 963 46.9 22.4 30.3 46.3 24.1 31.7 50.7 27.9 36.0 49.2 27.2 35.0 49.6 24.3 32.6 FORM 258 56.9 57.8 57.3 58.4 59.3 58.9 60.4 65.1 62.7 60.3 62.4 61.3 55.1 60.5 57.7 LINE 160 85.2 86.3 85.7 85.8 86.9 86.3 87.7 85.0 86.4 86.3 86.3 86.3 85.3 83.1 84.2 NAME 724 50.7 20.4 29.1 48.1 20.7 29.0 51.0 21.0 29.8 50.0 21.4 30.0 49.5 21.0 29.5 FACILITY 73 37.5 16.4 22.9 30.8 11.0 16.2 27.0 13.7 18.2 28.2 15.1 19.6 25.7 12.3 16.7 STATION 216 81.9 79.6 80.8 82.1 78.7 80.4 81.9 77.3 79.5 81.1 79.6 80.4 78.2 76.4 77.3 AVERAGE 5,554 61.6 47.1 53.4 63.2 49.0 55.2 63.6 49.6 55.7 62.7 49.8 55.5 61.2 48.2 53.9 TOTAL 11,142 56.0 39.3 46.2 56.2 40.2 46.9 56.3 40.6 47.2 55.9 40.7 47.1 54.5 39.6 45.9 DISH M, FACILITY and STATION correspond to DISH MATERIAL, NEAR FACILITY and NEAR STATION respectively.
of a dictionary becomes larger, coverage also becomes larger, but inappropriate entries in a dictionary increase.
The performance of NE taggers is shown in Table 2. This table shows the performance of NE taggers without the dictionaries and with the top 10%, 20%, 30% and all dictionary entries (i.e., top 100%) in terms of the precision, recall and F1-measure. Basically each row shows the performance of the NE tagger on an NE category. The row “AVERAGE” refers to the average performance of the NE tagger only on the NE categories for which we constructed dictionaries. The column “TOTAL” is the average performance for all the NE categories (i.e., 53 categories) no matter whether we prepared dictionaries for them or not.
The table shows that we successfully improved the performance of NE tag- gers by using dictionary entries as features. When we used dictionary entries whose scores were in the top 20%, the performance of NE taggers was 55.7 in F1-measure of “AVERAGE”. The improvement from the tagger without the dic- tionaries is 2.3 in F1-measure. In the “TOTAL” row, the maximum improvement is 1.0 with F1-measure. The improvement may not be so large, but if we look at the categories such as “DISH” and “DISH M”, the improvement reaches from 3.5 to 5.7.
Note that one may expect that the overall performance of NER can be im- proved by determining an optimal size of a dictionary for each category and by combining the classifiers with the dictionaries with the optimal size. However, because the performance of an NE tagger for each category heavily depends on the NE taggers for the other categories, we cannot independently determine an optimal size of each dictionary. This means that even if we combine NE taggers with dictionaries with size that performed best in our experiments (e.g., the NE tagger for CARD with top 10 % dictionary etc.), this will not necessarily lead to a better overall performance.
6 Conclusion
We proposed an automatic dictionary construction method for Named Entity Recognition (NER) on specific domains. The method expanded seed expressions extracted from an annotated corpus using itemizations in HTML documents. We showed that constructed dictionaries improved NER accuracy through a series of experiments on a restaurant domain. The dictionaries increased F1-measure by 2.3 without any additional manual labor, such as additional corpus annotation. We will apply our dictionary construction method to NER in other domains. In addition, we are going to directly evaluate the constructed dictionaries by hand. We will also compare dictionaries built by our method with those built by existing methods [17] in terms of their impact on the performance of NER.
References
1. Bikel, D.M., Miller, S., Schwartz, R., Weischedel, R.: Nymble: a high-performance learning name-finder. In: Proc. ANLP ’97 194–201
2. Collins, M., Singer, Y.: Unsupervised models for named entity classification. In: Proc. EMNLP ’99 189–196
3. Yamada, H., Kudoh, T., Matsumoto, Y.: Japanese named entity extraction using support vector machine. IPSJ Journal 43(1) (2002) 44–53 (in Japanese)
4. Sekine, S., Nobata, C.: Definition, dictionaries and tagger for extended named entity hierarchy. In: Proc. LREC ’04 1977–1980
5. Grishman, R., Sundheim, B.: Message understanding conference – 6: A brief his- tory. In: Proc. COLING ’96 466–471
6. IREX Committee editor: IREX workshop. (1999)
7. Sekine, S., Sudo, K., Nobata, C.: Extended named entity hierarchy. In: Proc. LREC ’02 1818–1824
8. Miller, G.A., Beckwith, R., Fellbaum, C., Gross, D., Miller, K.J.: Introduction to wordnet: An on-line lexical database. In: Journal of Lexicography. (1990) 235–244 9. Shinzato, K., Torisawa, K.: Acquiring hyponymy relations from web documents.
In: Proc. HLT-NAACL ’04 73–80
10. Vapnik, V.: The Nature of Statistical Learning Theory. Springer (1995)
11. Berger, A.L., Pietra, S.A.D., Pietra, V.J.D.: A maximum entropy approach to natural language processing. Computational Linguistics 22(1) (1996) 39–71 12. Uchimoto, K., Ma, Q., Murata, M., Ozaku, H., Utiyama, M., Isahara, H.: Named
entity extraction based on a maximum entropy model and transformation rules. Natural Language Processing 7(2) (2000) 63–90 (In Japanese).
13. Asahara, M., Matsumoto, Y.: Japanese named entity extraction with redundant morphological analysis. In: Proc. HLT-NAACL ’03 8–15
14. Nakano, K., Hirai, Y.: Japanese named entity extraction with bunsetsu features. IPSJ journal 45(3) (2004) 934–941 (in Japanese).
15. Tjong Kim Sang, E., Veenstra, J.: Representing text chunks. In: Proc. EACL ’99 173–179
16. Ikehara, S., Masahiro, M., Satoshi, S., Akio, Y., Hiromi, N., Kentaro, O., Yoshi- humi, O., Yoshihiko, H.: Nihongo Goi Taikei – A Japanese Lexicon. Iwanami Syoten (1997)
17. Thelen, M., Riloff, E.: A bootstrapping method for learning semantic lexicons using extraction pattern context. In: Proc. EMNLP ’02 117–124