A uthor(s )
Z ielinski, K azimierz; Nielek, R adoslaw; W ierzbicki, A dam;
J atowt, A dam
C itation
Information Processing & Management (2018), 54(1): 14-36
Is s ue D ate
2018-01
UR L
http://hdl.handle.net/2433/230645
R ig ht
©
2017 T he A uthors. Published by E lsevier L td. T his is an
open access article under the C C B Y -NC -ND license.
(http://creativecommons.org/licenses/by-nc-nd/4.0/)
T ype
J ournal A rticle
T extvers ion
publisher
Contentslistsavailableat ScienceDirect
Information
Processing
and
Management
journalhomepage:www.elsevier.com/locate/infoproman
Computing
controversy:
Formal
model
and
algorithms
for
detecting
controversy
on
Wikipedia
and
in
search
queries
Kazimierz
Zielinski
∗,
Radoslaw
Nielek,
Adam
Wierzbicki,
Adam
Jatowt
Polish-JapaneseAcademyofInformationTechnology,Warsaw,Poland,KyotoUniversity,Kyoto,Japan
a
r
t
i
c
l
e
i
n
f
o
Articlehistory:
Received22January2017 Revised11August2017 Accepted23August2017 Availableonline22September2017
Keywords: Controversy Wikipedia Websearch
a
b
s
t
r
a
c
t
Controversyisacomplexconceptthathasbeenattractingattentionofscholarsfrom di-versefields.IntheeraofInternetandsocialmedia,detectingcontroversyandcontroversial conceptsbythemeansofautomaticmethodsisespeciallyimportant.Websearcherscould be alertedwhenthe contentstheyconsumearecontroversialorwhentheyattempt to acquireinformationondisputedtopics.Presentinguserswiththeindicationsand explana-tionsofthecontroversyshouldofferthemchance toseethe“widerpicture” ratherthan letting themobtainone-sided views.Inthiswork wefirstintroduceaformalmodelof controversyasthebasisofcomputationalapproachestodetectingcontroversialconcepts. Thenweproposeaclassificationbasedmethodforautomaticdetectionofcontroversial ar-ticlesandcategoriesinWikipedia.Next,wedemonstratehowtousetheobtainedresults forthe estimationofthecontroversy level ofsearchqueries.Theproposed methodcan beincorporatedintosearchenginesasacomponentresponsiblefordetectionofqueries relatedtocontroversialtopics.Themethodisindependentofthesearchengine’sretrieval andsearchresultsrecommendationalgorithms,andisthereforeunaffectedbyapossible filterbubble.
OurapproachcanbealsoappliedinWikipediaorotherknowledgebasesforsupporting thedetectionofcontroversyandcontentmaintenance.Finally,webelievethatourresults couldbeusefulforsocialscienceresearchersforunderstandingthecomplexnatureof con-troversyandinfosteringtheirstudies.
© 2017TheAuthors.PublishedbyElsevierLtd. ThisisanopenaccessarticleundertheCCBY-NC-NDlicense. (http://creativecommons.org/licenses/by-nc-nd/4.0/ )
1. Introduction
Controversy abounds inthe world. At timesit seems that almost anysubject canbe asource of controversysince it isvirtuallyimpossibleforeveryone toagreeonanysubjectofinterest.However, suchassumptionisafallacy:byfocusing onthepresence ofminordisagreements, weignorethe existenceofan organized,encyclopediccollectionofagreed-upon facts.Still,itisquiteclearthatcontroversialtopicsandcontroversialinformationexist,andcomparedwithnon-controversial topicsorinformation,they are usually moreprominentandeasilynoticeable inmedia andontheWeb. Eventopicsthat arewellsupportedbyfactsandevidencemaynotconstituteaguaranteedconsensus.Peopletendtoargueaboutopinions, interpretations,andpointsofview.Thesedisagreements arenotalwayscounterproductive;theymayallowparticipantsto
∗ Correspondingauthor.
E-mailaddress:[email protected] (K.Zielinski).
http://dx.doi.org/10.1016/j.ipm.2017.08.005
adjusttheirpointsofviewortoinspireasearch fortruthorcommonground.Yet,controversycanalsoimpedeorprevent cooperation.Thisproblemhasbeenrecognizedandaddressedbycommunitiesthatgeneratepeer-producedcontent,suchas Wikipedia,whichattemptstolimittheimpactandspreadofcontroversyandimprovethearticleeditingprocess.Therefore, detectionofcontroversymaybecrucialforensuringhigh-qualitypeer-producedcontentandmorebalancedviewpoints.
WhilebrowsingtheWebinsearchforinformationaboutatopicofinterest,individualsmayfindcontentthatsupports onlyonepointofview.Thethreatofreceivingbiasedinformationormisinformationisevenmoreseriouswiththepervasive personalization ofsearch engines andthe associated filterbubbleeffect (Nguyen, Hui, Harper, Terveen, & Konstan, 2014; Pariser,2011).Unlessuserspersevereintheirsearchforacquiringmoreinformationtocorroborateandtofindinformation fromdiverseviewpoints,theyarelikelytolearnaboutonlyone-sideofanyargumentregardingthetopicoftheirinterest. Consequently,apersonmaymake wrongdecisionsasaresultofbeingexposed tomisleading(orone-sided) information aboutacontroversialtopic,withoutevenrealizingthatcontroversyexists.Ifthepersonwasmadeawareofthecontroversy, she/hewould be ableto make more informed andbetter decisions basedon more comprehensiveknowledge about the topic.Thetruism’forewarnedisforearmed’alsoappliestothecontextofWebsearches.
Withtheaboveinmind,atimelywarningabouttheexistenceofcontroversycouldbebeneficialforuserswhomaybe unawareof itbeforethey trust incompleteorbiasedinformationonimportanttopics.In ourstudy,we focusonthe two mostwidelyused“startingpoints” foruserswhoarelookingforinformationontheInternet:Wikipediaandsearchengines. Withcloseto 500million unique visitors per monthWikipediais immenselypopular knowledge basethat haspowerful educationalimpactonoursociety.Oftenusersuseitasaspringboardwhenresearchingvarietyoftopicsincludingcomplex onesinscientificdomainsormoretrivialoneslikecelebrityinformation.Wikipediaisalsocommonlyusedforsupporting variousdataprocessingtasks.
SearchenginesaregatewaystotheInternet.Theyassistusersinlocatinganydesiredinformationorwebsites.Assuch,it wouldbebeneficialtosearchersiftheygotalertedontopiccontroversywheninteractingwithsearchengines– beforeeven seeingthereturnedresults.Inthisworkweconsideronlysearchqueriesandnottheresultsreturnedbysearchenginesto avoidtheneedtoaccountforthesearchenginetypeandlimitationsassociatedwithpersonalizingthesearchprogress.
1.1. Research objectives
Giventhedescribedimportanceandcomplexityoftheconcept ofcontroversy,we identifiedthefollowingresearch ob-jectives.
Whilepriorworkhasalreadydemonstratedmethodsofidentifyingcontroversy,thereisnounifiedframeworkthatwould define the problemand representit formally. We believe that a conceptual modelof controversy is necessary. It would providebasisforcomputationalapproachestowardsbuildingapplicationsaimingatdetecting,estimatingandunderstanding controversyintexts.Suchamodelwouldbeusefulforestablishingdetectionmethods,butitcouldalsoallowustocompare existingapproaches.
GiventheimportanceofWikipediaandsearchenginesinacquiringinformationandlearning,onewouldexpectastrong supportforonlineuserstopreventacquisitionofone-sidedinformation.However, nosuchsupporthasbeenexplicitly of-feredsofar,besidessolutionsthatrelyonmanualdetectionofcontroversyorfocusonrelatedtasks(e.g.,contentrelevance estimation).Toimplementsuchfunctionalities, thedevelopmentofeffectivealgorithmic approachesfortreatmentof con-troversyisrequired.
1.2. Contributions
Inthiswork,wemakethefollowingcontributions:
Definition and formal representation of controversy: We propose a definition of controversy to serve as the basis forourresearch. Thisdefinitionisbasedonthesocial sciencesandepistemology. Itmayalsobeusefulforresearchersin computerscience,asit drawsalinebetweencontroversialandnon-controversialcontentandtopics.Themain advantage ofthisdefinitionisthat thelevelofcontroversycanbequantified. Moreover,ourformalmodelclassifieserrorsashaving threemainsources;suchclassificationisindispensablewhenattemptingtopredictcontroversy.
Estimatingcontroversy ofWikipediaarticles andcategories: We develop newmethods foridentifying controversial articlesonWikipediabyanalyzingthesentimentsofdiscussionsonthearticletalkpages.Usingthesedetectionmethods,we canpinpointthesectionsofarticlesthatgeneratethegreatestcontroversy.Basedontheproposed classifiersofWikipedia articlecontroversy, we can estimate the levels ofcontroversy associated with topical categorieson the English-language Wikipedia.Thisapproachcanbethenusedtopredictthelevelofcontroversyinnewarticleswithinacategory.
different,personalizedresultstothesamequery.Thissituationismostsignificantforqueries relatedtocontroversial top-ics, because a usermayreceive search resultsthat reflect one side ofthe controversy (andanother usermayonly learn abouttheotherside).Incontrast,ourmethodproduces resultsthat areindependentofthepersonalizedrecommendation algorithmthatselectsauser’ssearchresults.
Theremainderofthisarticleisorganizedasfollows:inthenextsection,wereviewtheabundantliteratureonthetopic ofcontroversy andfocuson workrelevant todefining controversy andonalgorithmic methods forcontroversydetection orprediction.In Section3,weproposeourdefinitionofcontroversy.In Section4,wedescribetheWikipediadatasetused inour research.In Section 5,we introduceandevaluate ourmethods forpredictingcontroversy ofWikipediaarticles.In
Section6,weevaluateandrankthelevelofcontroversyoftopicalcategoriesinWikipedia. Section7introducesourmethod forpredictingthecontroversyinWebqueries.Finally,in Section8,wedrawconclusionsanddiscussthefuturework.
2. Relatedwork
2.1. Controversy in social science
Controversyisaubiquitousphenomenon.SincethetimesofancientGreecetothe20thcentury,thestudyonthenature ofcontroversywasa domainofgreatphilosophers. Itisusually definedaspublicargument/discussion aboutatopicthat has supporters on one side and many people who strongly disagree with them or are somehow shocked by this issue. Withrespect to time,controversy ischaracterized by the factthat no agreement orconsensus isreached onthe subject for a prolonged period oftime. Controversies range from fiercepolemicsto polite and orderlydiscussions. What makes controversyresearchanexcitingtopicisthatcontroversiesusuallystemfromissuesofhighsocialrelevance.
Today,the studyofcontroversyis carriedout mainly by philosophers,sociologists, andinformationscientists. Contro-versies areknownto existinall areaswherethereare disputes relevanttocurrentsocieties, includingeconomy,politics, art,religion,science,gender,sexualorientation,race,ethnicity,culture,immigration,educationandmanyotherareas. Con-troversy, by its verynature, isrelated toconflict.As early asin1956, thefunctionsof socialconflicts were describedby
Coser(1956),whoconsideredtheroleofconflictinestablishingandmaintaininggroupidentitiesandrelationshipsbetween them.Conflictsthatarisefromthefrustrationofspecificdemandsaremorepersistentandleadtoaggressivebehaviorbased onstrongsentiments.Inthoseindividualswhoaredeeplyinvolvedinthecontroversy,feelingsofattractionaswellas hos-tilityarelikelytoarise.Sometimespartiesviewthemselvesasrepresentativesofcollectivesorgroupswhoarefightingnot forthemselvesbutratherforthegoalsandideals ofthegroup.The eliminationofpersonalmotivations tendstointensify conflict.Conflictalsoleadstotheformationofcoalitionsandassociationsbetweenpreviouslyunrelatedparties.
SomeofCoser’sobservationsregardingsocialconflictsareparticularlymeaningfulintheInternetcontroversiesoftoday, whereinwefindthatideologicalconflicts,forexample,areoftenparticularlydifficultandleadtoongoingcontroversies.This isbecauseinsuch casesthecauseisnotrelatedtoanyreal-worldfactorincident,butrathertodiffering worldviewsor identities,whichcorrespondtoCoser’ssocialgroups. Currently,wealsofrequentlyobservetheexpressionofstrong senti-mentsandtheformationofcoalitionsbetweenpartiesinacontroversy.
Koutra,Bennett, andHorvitz (2015) examined the browsingbehavior of searcherson the controversialand polarizing topicofguncontrol,andinthisstudyfocusedontheinfluenceofasingledisruptiveandshockingnewsevent.Theauthors foundthat,overall,mostpeopleusetheWebtoaccessinformationwithwhichtheyagree.Whenanexternaleventthreatens to directly influence users, only then do they explore content outside their filter bubble.Otherwise, most users appear “narrow-minded” with respecttothenumberofvisitedWebdomains, andthesedomains presentmostlyone sideofthe issue,whichistypicalinideologicalconflict(andassociatedcontroversy),asdefinedbyCoser.
In1976, GurrandDuvall(1976)formulatedaformaltheoryofpoliticalconflict.Thistheory,developedinthepre-Internet era,focusesonthephysicalconfrontationbetweensocialcollectiveactorsandtheassociatedmaterialdestructionincurred. Whiletheauthors’mainpurposeindevelopingthetheorywastodescribe socialphenomenasuchasrebellionsandother physical confrontationsbetweenorganizedcollectives, itis applicable toInternet conflicts andcontroversies inthe sense thatthemagnitudeofaconflictstilldependsonindividual potentialsforaction,collectivedispositionstowardaction,and organizationalstrength– thelattertoalesserextentbecauseintheWeb2.0erawe aredealingwithinformalgroupsand coalitionsofInternetusers.
2.2. Role of controversy in media
Controversy plays very important role in media as it typically increases media popularity and coverage. Media pro-grams likereality TV were developed forthe purposeof sparking controversiesby creating moral panic,asdescribedin
Biltereyst(2004).TheMITCenterforCivicMediadevelopedaControversyMapper,whereinmajornewsstoriesare reverse-engineeredto visualize thespread ofideasandthe changeinmedia frames overtime, andto identifywhose voicesare dominating adiscussion. In their investigations ofa major national controversy inthe media,the MITresearchers found that broadcast media continues to be important as an amplifier and gatekeeper of news, but that it is susceptible to media activistsworkingthrough participatorymedia toco-create newsandinfluence theframing ofmajor controversies.
foundmany differencesbetweennewssources, thus enablingthe identificationofcontroversy basedon a comparisonof how the subjectis portrayed by different media groups. An unsupervised method for identifying controversial semantic categoriesinonlinemedia wasproposedby DeClercqetal.(2014).The authorsusedDBpedia toaggregateconcepts into categoriesandthenidentifiedcategoriescharacterizedbysignificantdeviationsinsentimentacrossdifferentonlinemedia.
2.3. Controversy in social media
As we will detail later, controversy needs appropriate community. Research on mining antagonistic communities in social networks was undertaken by Lo, Surian, Prasetyo, Zhang, and Ee-Peng (2013) who modeled direct antagonistic sub-communities using existing positive and negative links between members of Eopinions and Facebook . In Twitter, a widely used participatory media, controversies receive wide coverage very quickly. However, Smith, Zhu, Lerman, and Kozareva(2013)foundthatTwitterisprimarilyusedforspreadinginformationtolike-mindedpeopleratherthanfor debat-ingissues.Usersaremorelikelytorebroadcastinformationthantorespondtoacommunicationbyanotheruser. Individu-alstypicallytakeapositiononanissuepriortomakingpostsaboutitandareunlikelytochangetheiropinion. Yardiand Boyd(2010)observedgroupdynamicsonTwitterbetweenpro-andantiabortionrightsgroupsinrelationtoacertainevent anddiscovered bothhomophilyandheterogeneityinconversations aboutabortion.Althoughpeople todayareexposed to broaderviewpointsthantheywerepreviously,theyarelimitedintheirabilitiestoengageinmeaningfuldiscussion.
IntheirresearchoncontroversiesinvolvingknownentitiesinTwitter, PennacchiottiandPopescu(2010)usedtimelyand historicalscorestoclassifycontroversy.TheauthorsfoundthatmostcontroversiesonTwitterrelatetomicro-events(e.g.,TV shows,awardshows,orsportevents). Garimella,Morales,Gionis,andMathioudakis (2015)usedthesocialmedia network structureonTwittertodevelopanetwork-basedcontroversymeasureandfoundcontentfeaturestoberelativelyunhelpful inthistask. Laterthey focused their research on exploring thetopics ofdiscussion on Twitterandunderstanding which onesarecontroversial(Garimella,Mathioudakis,Morales,&Gionis,2016).
2.4. Controversy in Wikipedia
Wikipediaprovides aknowledge basethat has beenexploitedby researchers fromvariousscientific domains. The re-searchtrendsinareassuchasinformationretrieval,naturallanguageprocessing,andontologybuildinghadbeenreviewed anddescribedrecentlyby Mehdi,Okoli,Mesgari,Nielsen,andLanamaki(2017).
The first paper addressing the problem of cooperation and conflict between editors on Wikipedia was published in 2004 by Viégas, Wattenberg, and Dave (2004). The authors used the history of edits to develop a tool for visu-alizing patterns of conflict. Based on similar meta-information (i.e., number of edits, unique editors, and anonymous edits), Stvilia, Twidale, Smith, and Gasser (2005) measured article quality. Buriol, Castillo, Donato, Leonardi, and Mil-lozzi(2006)studiedconflictsinWikipediabyfocusingonentriescharacterizedbyaseriesofeditsrevertingthemto previ-ousversionsbetweenauthors.
Wikipediaedits are organized around the concept of revision . An editor will make changes to an articleand publish anewversion (aka revision). Acurrentrevisionmay alwaysbe reverted toan earlierversion (byanyone) andtheentire historyofrevisions isaccessible onWikipedia.Repetitive mutualreverts haveled toedit warsandtypically indicate the existenceofcontroversy(oratleastanargumentaboutsomefacts).Anin-depthstudyofeditwarshasbeenconductedby
Sumi,Yasseri,Rung,Kornai,andKertész(2011a)and Sumi,Yasseri,Rung,Kornai,andKertesz(2011b).Notalleditwars are necessarilynon-constructive.Intheir study, Yasseri,Sumi, Rung,Kornai,andKertész(2012) identified mutualrevertsthat haveledtoconsensusaswellasthosethathaveremainedinastateofpermanentcontroversy.Later Yasseri,Spoerri, Gra-ham,andKertész(2014) usededitwars to present,visualize andanalyzetopical overlapsofcontroversiesin 10different language versionsof Wikipedia.The authors concludedthat there are both globalcontroversial topicswith cross-culture resonanceandtopicswithmorenarrowinterestlimitedtolanguagecommunitiesorgeographicalareas.
Todetectcontroversialarticles,researcherscanaccessabroadspectrumofmetainformationregardingeditorial behav-iors.Vuongetal.proposedtwocontroversy-rankingmodelsforWikipediaarticles,drawnfromthehistoryofcollaboration andedits(Vuongetal.,2008). Kittur,Suh,Pendleton,andChi(2007)proposedaverygoodmethodbasedoneditdynamics andtalkpages.Recently, RadandBarbosa(2012)compareddifferentmethodsfordetectingcontroversy(someofwhichare basedonthepropertiesofcollaborationnetworks),whichconstitutedthebasisforoneofourrecentresearchefforts Predict- ing Controversy of Wikipedia Articles Using the Article Feedback Tool (Jankowski-Lorek,Nielek,Wierzbicki, &Zieli´nski,2014). FocusingonthecollaborationhistoryofpairsofeditorsSepehri-RadandBarbosaintroducedamodeltopredictcontroversy inasupervisedway(Sepehri-Rad&Barbosa,2015).
ofcollaborationthatincreasedthearticlequality. Laniado,Kaltenbrunner,Castillo,andMorell(2012)analyzedtheemotional stylesofWikipediaeditors.Finally, Dori-HacohenandAllan(2013)usedsentimentasbasisfordetectingcontroversyonthe WebandcomparedtheseresultswithamethodbasedonataggedcorpusofarticlesfromWikipedia.Wikipediahasreceived muchresearch attention, particularlyinthe fieldsofsocial behaviorandcontentquality.Incontrasttostudies ofconflict,
Borzymek, Sydow, andWierzbicki (2009), Turek, Wierzbicki, Nielek, Hupa, and Datta(2010), and Wierzbicki, Turek, and Nielek(2010)investigatedcollaborationandteamworkonWikipediasocialnetwork.
Wikipediahasbeensuccessfullyusedasdatasourceforretrievingsemanticinformationtoimproveresultsfromsearch engines andto categorize texts. Milne andWitten (2008) measured semanticrelatedness by the hyperlink structures of Wikipediaarticles.Theycounted term frequency-inverse document frequency (tf-idf)oflinksweighted bythe probabilityof eachlinkandthencomputedtherelatednessofeacharticle. HajianandWhite(2011)createdamulti-treeforeachentityin theWikipediacategoriesnetwork,combinedthem,andusedamulti-treesimilarityalgorithmtocomputethesimilarityof theentities.Recently, Han(2013)proposedamethodformeasuringsemanticsimilaritythatusesWikipediaasanontology. In additionto semanticsimilarity, the Wikipediacategorygraph (WCG)hasbeen usedin research toimprove adhoc documentretrieval(Kaptein,Koolen,&Kamps,2009),identifydocumentcategories(Schonhofen,2006),andacquire knowl-edge(Nastase&Strube,2008). Medelyan,Milne,Legg,andWitten(2009)publishedanextensiveoverviewofresearchwhich minedWikipedia.In2006, Voss(2006)coinedaterm collaborative thesaurus fortheWikipediacategorystructure.The struc-turedformofWikipediacategoriesallowedfortheautomatedlearningofontology(Yu,Thom,&Tam,2007). Kittur,Chi,and Suh (2009) used a WCG of annotated data to detect contentious topics in Wikipedia. Recently, Biuk-Aghai, Pang, and Si(2014)attemptedtovisualizehumancollaborationinWikipediabyvisualizingWCGsubtreesassimpletrees.
IntheirsearchforcontroversialtopicsinWikipediaarticles, Borraetal.(2015)usedlanguageagnosticprogrammingto develop a tool they calledContropedia. It assignscontroversyscores toevery Wiki link. Thesescores are thenpresented graphicallyasacontroversydashboardshowingboththeWikilinkscoreanditsassociatedtimelineofedits.
2.5. Credibility and controversy
WiththeadventofWeb2.0,onlineevaluationhadbecomeanimportantfeatureinmanyapplicationsinvolving informa-tion.InordertoassessthecredibilityofinformationontheWeb,anumberofevaluationsystemsweredevelopedandmuch researchhadbeendevotedtothedesignofcredibilityassessmentsystems. Ka̧kol,Jankowski-Lorek,Abramczuk,Wierzbicki, andCatasta(2013)studiedtheinfluenceofsubjectivityandbiasincredibilityratingsandfoundtheir presencetobeakey design issueinWeb credibility systems.Theconcept ofcontroversy hasbeenstudied withrespect toevaluationsystems asan important influencingfactor forimprovingoverall credibility. The existence ofsubjectivity andmutualdependency betweenreviewerbiasandobjectcontroversyisbroadlyrecognised.Lauwetal.developedareinforcement-basedmodelto quantifybiasandcontroversywithinanevaluationsystem(Lauw,Lim,&Wang,2006;2008).
2.6. Controversy in Web search
Ennals, Trushkowsky,andAgosta (2010b)developed aDispute Finder browserextension that finds andhighlights text snippets that correspond with knowndisputes. A databaseof knowndisputes ismanually maintained and a textual en-tailment algorithm is used to find snippets that correspond with a known dispute. Initially, the authors populated the databasefromwebsiteslike PolitifactandSnopes,andsubsequentlythey developeda methodforidentifyingdisputes on the Internet based onsome Englishtext patternsfound to be typical in thesedisputes (Ennals, Byler, Agosta, & Rosario, 2010a). Kawahara, Inui, andKurohashi (2010) focused on the recognition andbird’s eye view presentation of contradic-toryandcontrastiverelationshipsbetweenstatementsrelatedtoatopic(searchquery)andthoseexpressedonWebpages (search engineresults). Theirmethod isbased on predicate-argument language structures inJapanese, butis believedto be adaptable to other languages. Finding contradictions through the sentiments expressed by viewerswas attempted by
Tsytsarau,Palpanas,andDenecke(2010).Theirmethodrequiredthetopicinquestiontohaveanumberofonlinereviews oropinions,fromwhicha sentimentcouldfirstbe aggregatedandthen usedtoidentifyacontroversy.Dori-Hacohen and Allan classifiedcontroversiesonInternet pages,basedon theirsimilarity toWikipediaarticlesknown tobe controversial. Initially,the authorsbasedtheir classificationson a manuallyannotated setofarticles (Dori-Hacohen & Allan,2013), but thenthey generalizedtheir methodforautomaticclassification(Dori-Hacohen&Allan, 2015).Theauthors’recentresearch (Dori-Hacohen,Jensen,&Allan,2016)proposedanewstackedmodelandacorresponding methodofclassificationof con-troversial pagesby creatingsubnetworks oftopically relatedpages.Theyachievedimprovement inAUC ofthedeveloped classifierwhencomparedwiththeclassifierbasedonasubnetworkofrandompages,thusprovingthatcontroversyexists intopical neighborhoods. JangandAllan(2016) addressedtheunavailabilityofedithistoryforsome pages bysmoothing fromthe scoresof theneighborswith moreestablished edithistory,which helpedthem improvethebinarycontroversy classification. Jang,Foley,Dori-Hacohen,andAllan(2016)investigatedtheprobabilityofcontroversyinadocumentand de-velopedalanguagemodelforcontroversy. Yamamoto(2012)developedaWebquerysupportsystembycollectingdisputed sentencesrelatedtosearchqueriesandthenprovidingtheuserwithsome ofthemosttypicalandrelevantdisputed sen-tencestoenhanceusers’awarenessofsuspiciousstatements.Despitetheseadvances,moreproblemsarise withrespectto controversialqueries andcontroversialresultsifourgoal istoprovide assistanceto search engineusers.As describedby
vs.popularbeliefs,theneedformoraljudgmentwhenfacedwithseveralpossiblecorrectanswers,andtheculturaland so-cialsettingsofthepersonseekinginformation.GoingfurtherbeyondcontroversydetectionDori-Hacohenproposedresearch onautomaticstancedetection(Dori-Hacohen,2015).
3. Formalmodelofcontroversy
3.1. Formal model of controversy
Manyresearchershavestudiedcontroversybut, surprisingly,noformalcomputational modelfordetectingcontent con-troversyhasyetbeenproposedorwidelyaccepted.Themain reasonforthisistheissue’scomplexitycausedby multiple aspectsoftheproblems.Diversemethods,heuristicsandalgorithmsfordetectingcontroversyproposedinrecentyears ap-pliedtodifferenttypesofobjects(startingfromsentencesandendingwithproductsorvideoclips).However,itisdifficult tocreateacomprehensivetheoreticalframeworkforthem.Ontheotherhandsuchamodeliscrucialforthedevelopment andevaluationofalgorithmsfordetectingcontroversy.Inthissectionweoutlinethemodelanddiscusspotentialdifficulties inusingittoshapeandpredictcontroversies.
The formal model of controversy proposed in this section cannot be calculated per se without adding content- and community-dependentmethods of calculating(or estimating) empirical distributionof communityopinions about evalu-atingsubjectandselectingtheappropriatemetricformeasuringdisagreement(itmightbeassimpleasLeik’sordinal con-sensusorascomplexasapplicationofclusteringandearthmoverdistanceproposedby Rafalak,Deja,Wierzbicki,Nielek,& Kakol,2016).Itisalsoworthtonoticethatproposedmodelisuniversalandcanbeappliedtoanytypeofobjectsandtheir features– e.g.controversyaboutthetrustworthinessofwebpagesorthetasteoficecream.
The Merriam-WebsterDictionary defines controversyas an “argument that involves many people who strongly disagree about something: strong disagreement about something among a large group of people”.From thisdefinition,we canextract thetwobuildingblocksofcontroversy:alargegroupofpeopleandtheopinionsorevaluationstheyexpress.Ifwecombine thesetwoaspects withthe factthat controversymustbeaboutsomething (e.g.,text,event, orpicture)we obtaina triad composedoftheobject,agroupofpeople,andtheir opinionaboutthegivenobject.Separately,neitheragroupofpeople (community)noranobjectissufficienttogeneratecontroversy.Formally,controversycanbedefinedasafunctionofthree variables:
f
(
ob,com,Eobcom
)
→{
uncontrov
ersial,controv
ersial}
, (1)where
O –set of objects
ob ∈O –single object of controversy (e.g., web page, picture, opinion, etc.), C –set of communities,
com ∈C –community, E ob
com –empirical distribution of opinions given by members of community comfor object ob.
Object ob iscontroversialforagivencommunity com onlyifthereisstrongdisagreement initsevaluation E ob com.
Inter-rater agreementmeasures (e.g., Fleiss’kappa or intra-class correlationcoefficient) ordispersion measures of results(e.g., standard deviation) are typically used to assess agreement but are not suitable for use with a Likert-type ordinal scale (Jamiesonetal.,2004).ItistypicallyusedtoevaluateobjectsontheWeb.Historically,thefirstmeasuretailoredtodealwith ordinalscaleswastheLeiksordinalconsensus,introducedin1966by Leik(1966).Othermetricswereproposedby Tastleand Wierman(2007) and Van der Eijk (2001). Yet another approach is to measure the distancebetween the distribution of opinion E ob
com andthereferencedistributiontoidentifyacontroversialclass(e.g.,u-shapeddistribution).Theearthmover’s
distanceandtheBhattacharyyadistanceare twoofmanypossiblemetricsfordiscretedistributions. Althoughcontroversy mayvaryinintensity,forsimplicityweassume thata proposed functionreturnsonlyone oftwo values– eitheragiven object ob iscontroversialornot– butthesameapproachmaybeusedforfunctionsincorporatingmoreshadesofgray.
Eq.(1)canbesimplifiedbyremoving objects ob and com fromthefunction,becauseinourcalculationweonlyusethe object ob evaluationsandnottheobjectorcommunitythemselves.Asaresultweobtainthefollowing:
f
(
Eobcom
)
→{
uncontrov
ersial,controv
ersial}
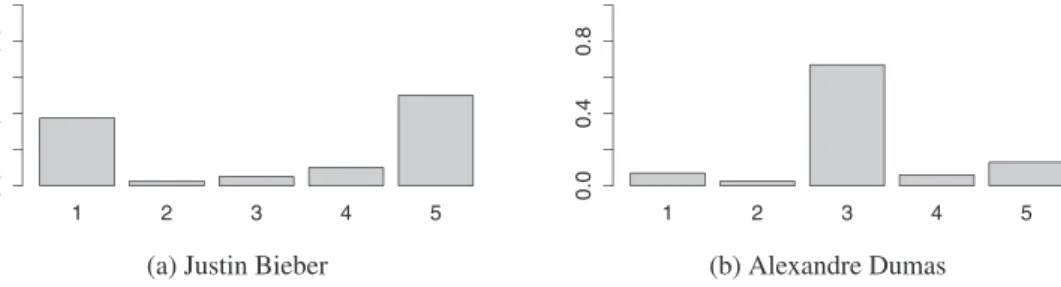
. (2)Followingtheabovedefinitions,itbecomesclearthatthecontroversycannotbeanalyzedwithoutregardtothe commu-nity.Oneconsequenceofthisisthatvariouscommunitiesmayhavedifferentcontroversiesonthesameobject.InWikipedia, anobviousexampleofthesedisjunctivecommunitiescanbeseeninitsdifferentlanguageversions.Anexampleofhowthe controversyononetopicchangesacrossWikipedialanguageversionsisdescribedinthe Section5. Fig.1depictstwoactual examplesofevaluationdistributions fordifferentarticles intheEnglish Wikipedia.Fromthesegraphs, wesee thatJustin Bieberseemstobe,atleastfortheWikipediacommunity,muchmorecontroversialthanAlexandreDumas.
3.2. Meta approaches for estimating object controversy
Fig. 1. DistributionsofvotesontrustworthyratingobtainedviaArticleFeedbackToolfortwoarticles.
somedataismissingandmustbe compensatedforinsomeway.Belowwe presentthreetypicalreal-worldscenariosand a brief analysis of the potential sources oferrors. We note that there is one more important aspect of computer-based controversy. Bothinthe model we presentin Section 3 andinour discussion below,we assume that neither theobject nor thecommunity changesover time. Web pages evolve,people change their opinions,andcommunities grow. Eachof theseprocesses maystronglyinfluence thecalculation results of Eq.(1)andimpose yetother limitations oncontroversy predictionmethods.
3.2.1. Estimation by similarity to other objects
In thisscenario, we have high-qualitydata regarding the controversyabout object ob a fora community com i butno
informationaboutobject ob b’sevaluation, forwhichwe wanttoestimate thecontroversy. So,we cantryto measurethe
similarity between objects ob a and ob b and, ifwe find them to be very similar, we can assume that the results ofthe
controversyfunctiondefinedin Eq.(1)willbe thesameforboth.Themainproblemhereisthat calculatingthesimilarity betweenrealobjects can bedone in manydifferentwaysandwe donot knowa prioriwhichof thesemethodsis most accurateinapproximatingthecontroversyfunctionvalues.
Ourattempts to apply this approachto texts by usingtf-idf formeasuring the similarity oftexts, however, exceptin some rare cases,were not successful. Thisisnot surprisingif youconsider that thepresence ofeven asingle wordina lengthy text mightsparkcontroversy.Forother typesofobjects,such aspictures orvideo,thisissuebecomesevenmore challenging.
3.2.2. Estimation of distribution and community
Acommonapproachtostudyingcontroversyinthecomputersciencesistoaskpeopletolabelwhetheragivenobjectis controversialandthentousetheselabelsforfurtherstudy(e.g.,applyingmachine-learningalgorithmsandbuildingmodels (Dori-Hacohen&Allan,2013;Dori-Hacohenetal., 2015)).Researchers,beingawarethat controversyisan inherentlyfuzzy concept,collectmanyevaluationsforeachobjectandthencalculatetheinter-raterreliability.Whenpeopleareaskedabout thecontroversyofagivenobject,theyhavetojudgetheobjectandestimatetwoadditionalvariablesrequiredtocalculate
Eq. (1): com and E ob
com. People tend to overestimate the popularity of their own opinion in a community andfollowing availability heuristic think of themselves as a typical communitymember. Bothof these potential errorsources may be somewhatcontrolledbygatheringanswersfrommanypeopleinsteadoffromasingleindividual,butasyetitisunknown whetherthisismoreeffectivethancollectingsubjectiveevaluationsaboutanobject.
3.2.3. Bias sources
There are quitea few serviceson theInternet on whichpeople can rateobjects,including movies,books, restaurants andothers. Eventhe English Wikipediahada mechanism forratingarticles (see Section 4.1). In that casewe knowthe community and the object,and we have evaluations of that object.Therefore in theory we should be able to precisely calculatethecontroversyfunction(Eq.(1)).Inrealityitisnotthatsimple.
OfthemillionsofWikipediareaders,onlyatinyfractionevaluateagivenarticle.Moreover,thissmallsamplemightnot berepresentativeofthewholecommunitysinceitisself-selected.Peopletendtoevaluateobjectsthatinspiretheirintense emotions (either positive ornegative). Therefore,the opinions of thesilent majority are usually not well representedin collected evaluations. Rafalak etal. (2016) found the distributions ofevaluations to have relatively robust samplingbias withrespecttosocio-demographicvariables.Theover-representationofaparticularpointofviewinoursamplemightalso beduetointentionalmanipulation– evenasmallminorityofwell-organizeduserscanstronglyinfluencethedistribution ofevaluations.
4. Datasets
Fig. 2. ArticleFeedbackToolv4.
Fig. 3. Histogramofratingscores(0–5)oftrustworthydimensionperclass.
4.1. Article Feedback Tool
Article FeedbackTool (AFT) – a Wikimediasurvey forarticle feedback– engaged readers inthe assessmentof article quality.AFTwasusedonWikipediainfiveversionsandwasrecentlydiscontinued.Inourresearch,we useAFTv4,which allowedreadersoftheEnglishWikipediatoratearticlesonfouraspects,regardingwhetherthey wereperceived asbeing trustworthy,objective, complete,and well-written. Users were presentedwith a survey (Fig. 2) atthe endof every arti-cleandcould submittheir ratingsforeach dimension ona starscaleof 0to 5.Inthisresearch, we consideredonly the
t rust worthy dimensionofAFTv4 inorderto createuniversal controversydetectionclassifiersthat canbe applied without directlyasking usersaboutthe objectivityofthe text.Ouroriginal AFTv4 datadump containedover11 M articleratings basedon5.6 Mdifferentrevisionsofmorethan1.5 MdistinctarticlescollectedbetweenJuly2011andJuly2012.
4.2. Articles dataset
TheprimarysourceofWikipediaarticlestaggedascontroversialisalistcomposedbyWikipediaadministrators.Forthe EnglishWikipedia,this“listofcontroversialissues” (theofficiallisttitle)contains963articles,lessthan0.04%ofallarticles. Thisverysmallnumberofcontroversialarticlesmayindicatethatonlyafractionofarticlesiscorrectlytagged(anexample ofone decidedly controversialarticle that is not onthe listis givenin Section 5). Acareful examinationof the listalso revealsthat manyofthesearticlesare no longercontroversial(althoughthey were controversialinthe pastandmaybe soagaininthe future).We testedmanyalternativewaysforcollecting a listofcontroversialarticles (includinga dataset sharedby Dori-Hacohen& Allan,2013),butdecided tocontinuetousealistcomposedbythe Wikipedians,asitwasthe easiestto replicateforother researchersand, atthesametime,represented theclosestexampleofthe widercommunity understandingofcontroversy.
Fromatotal numberof963controversialarticles,we chose219that hadatleastthreeevaluationsintheAFTdataset. Since theapplication ofmachine learningtechniques requiresboth positive andnegative examples (preferablyinsimilar quantities),wealsorandomlyselectednon-controversialarticlesinawaythatmaintainedthesamedistributionoflength(in characters)inbothclasses.Thefinaldatasetthuscontainedrecordsof438articles,bothcontroversialandnon-controversial.
Fig. 4. Histogramofnumberofratingsperarticle.
4.3. Sections dataset
Todeterminewhetheritispossibletoautomaticallyidentifycontroversialissueswithinanarticle,werandomlyselected 512sectionsfromthetalkpages ofcontroversialarticlesandmanuallyannotatedthem,usingbinaryvalues(1for contro-versialand0fornon-controversial).Surprisingly,only19.5%ofthesectionsturnedouttobecontroversial.
5. DetectingcontroversyofWikipediaarticles
Tomanagetheeditingofcontroversialarticles,Wikipediahasestablisheda setofrules.Althoughtheserulescanvary amongdifferentlanguageversions,inprincipletheyarebasedonlimitingthenumberofuserswhoareauthorizedtoedit. Ononehand,restrainingtheeditingofcontroversialarticlesreduceseditwars,butontheotherhanditslowsthe publica-tionofqualitycontent.Earlydetectionofcontroversymayhelptolimitthecostandimpactofeditwars andincreasethe reliabilityofWikipediaarticles.OnWikipedia,atopicthatiscontroversialinonelanguageversionmaynotbecontroversial inanother. One exampleofthisis anarticle aboutthehistoric bombingeventof thePolish townof Wielunby the Ger-manLuftwaffeattheoutbreakofWWII.ThecontroversybetweensomePolishandGermanhistorianscanonlybefoundin theEnglishWikipedia.AmuchlongerarticlecoveringthiseventexistsonthePolishWikipedia,whichisnotcharacterized by anycontroversy, whilethereisno sucharticleatall ontheGermanWikipedia.Thisexamplefits ourformalmodel of controversyandreflectsthedependencyofcontroversyonthecommunity.
Below, we present three classifiers for the detection of controversy on Wikipedia. We are proposing the first two (Sections5.1and 5.2), whereas weare using theother one (Section 5.3.1), whichwasintroduced by Kittur etal.(2007), asabaselineforcomparison.
5.1. AFT-based controversy detection
Forevery articleinour datasetwe computedthefrequencyofeach offiveavailable AFTratings, theLeik’sdispersion measure (Leik, 1966), andthe total number ofratings. We used the resultsas features in a machine learningalgorithm (Random Forest).We foundthemostimportantfeaturestobe thenumberof1-starratings,thenumberof2-starratings, andthetotalnumberofratings.
5.2. Emotion polarity-based controversy detection
Table 1
PerformancecomparisoninAFTdataset.
AFT EP Kittur Combined F-measure 80.37% 69.05% 81.48% 84.10%
PrecisionControversial 79.96% 67.66% 79.77% 83.14%
PrecisionNon-controversial 80.78% 70.78% 83.42% 85.11%
ROC-AUC 0.88 0.73 0.89 0.91
5.3. Baseline
Ascomparativebaselineforouralgorithms,weusedthemethodproposedby Kitturetal.(2007).Inaddition,we deter-minedwhethercombiningornotthesemethodwithouralgorithmsincreaseditsperformance.
5.3.1. Meta information
Kitturetal.proposedthemetaclassifier(Kittur etal.,2007),whichweusedasone baselineforourstudy.Ithadbeen comparedwithfiveother classifiersinaprevious study(Rad&Barbosa,2012).Wechose thismethodbecauseofitsgood performanceandtheeasinessofdatasetconstruction.Basedonastatisticalanalysisoftherevisionhistoriesforarticlesand theirtalkpages,wefoundsevenfeaturesoutof30tobethemostimportant:
• numberofrevisionsofthediscussionpage
• numberofminoreditsofthediscussionpage
• numberofuniqueeditorsofthediscussionpage • numberofrevisionsofthearticle
• numberofuniqueeditorsofthearticle
• numberofrevisionsofthediscussionpagebyanonymouseditors • numberofrevisionsofthearticlebyanonymouseditors
Basedontheabove,wetrainedaclassifiertodistinguishbetweencontroversialandnon-controversialarticles.
5.4. Performance of classifiers
Thebaselineclassifierweusedtoevaluatetheperformanceofourproposedclassifiersisdescribedin Section5.3.1above. Weusedtherandomforest(Dori-Hacohen&Allan,2015)implementationinRformachinelearning.Duetothestochasticity ofthisalgorithm,weran thelearningprocess foreach model50timeswithdifferentseedvaluesandthenwe calculated theaverageoftheconfusionmatrix.
5.5. Detecting controversial articles
Table 1summarizes the performance of the algorithms we describe in this section. The algorithm proposed by
Kitturetal.(2007)yieldsthebestresultsbutitsoveralladvantageoverourAFTalgorithmisnegligible(slightlymorethan 1%fortheF-measure(accuracy)and0.01forthereceiveroperatingcharacteristic-areaunderthecurve(ROC-AUC)).TheEP methodperformssubstantiallyworse(F-measureof69.05%).TheCombinedmethod(Kittur,AFTandsentiment)worksbest forourdatasetandreached85.11%precisionfornon-controversialarticles.Thus wecanclaimthattheAFT-basedmethod, whichfollowsourformalmodelofcontroversyperformsapproximatelyasgoodasKittur’sbaselinemethod.
Formany applications,the misclassification cost is not symmetric, i.e., identifying a truly non-controversialarticle as controversialislesscostlythan doingthe opposite. Fig. 5showstheROCforall thetestedalgorithms. The AUCpeaksat 0.91forthealgorithmthatcombinesthemethodsdescribedinthispaper,buttheyarealsoquitehighfortheKitturandAFT algorithms(0.88and0.89,respectively).Again,thedifferencebetweentheKitturandAFTalgorithmsisveryslight,butwe canobserveaninterestingdifferenceintheshapesoftheROCcurvesforthesealgorithms.AFTworksbetterforlowerfalse positiveratiosandKittursurpassesAFTathigherfalsepositiveratios.Thismayexplainwhycombiningthesetwomethods improvestheperformance.Ingeneral, thesteep riseintheROCfunctionsforall thealgorithms (exceptemotionpolarity) indicates that by acceptingslightly morefalse positives, for whichmisclassification is not costly, almost all controversial articlescanbedetected.
5.6. Classification performance based on emotion polarity
Fig. 5. ROCofclassifiersinarticledataset.
Fig. 6. ROCofsectionsclassifier.
Fig. 7. F-measurebyratioofcontroversialsections.
Tousethesectionsclassifier forfurtherclassification,wechose acut-off valueforwhichits recallinthecontroversial class was79% andits F-measure was68.6%. Fig. 7 showsclassification performancesbased onthe ratio ofpre-classified sections.Wecanseethatweobtainedthebestcontroversyclassificationforarticleshavingaratioofcontroversialsections of26%ormore.
WecanalsousetheclassifierbasedontheEPofsectionsforclassifyingthecontroversyofentirepages.However,ifwe compareperformancedatafrom Fig.7withthosefrom Table1,we canseethatthe directuseofsentimentmeasures on entiretalkpagesis moreefficientdespite thedilutioneffectdescribedabove.We can usethisclassifierto locate contro-versialtopics inthearticle’s talkpage.Bydoing so,we can better determinethe“essence” of theparticular controversy, becausemanycontroversialarticlesconsistlargelyofconsensustext,whichhasbeenstrippedofcontroversy.UsingourEP classifier,wecanidentifyandlocateotherwiseinvisiblecontroversyinthetalkpage.
ThenoveltyofourapproachistheincreasedgranularityofcontroversydetectioninWikipedia,suchastheonewithan AUCashighas0.80andwithoutanyavailablemetadata.Wecannowdetectcontroversialissuesinarticlesatthesections levelofthediscussionpage.
6. ControversialcategoriesinWikipedia
HavingdescribedourapproachfordetectingcontroversyinWikipedia,inthissectionwe explainhowtodetect contro-versialWikipediacategories.
TheWikipediacategorysystemisadirectedcyclicgraph,inwhicharticlesandcategoriesarenodesanddirectededges indicatetheparent-childrelationship.Everycategoryorarticlecanbeachildofmanyothercategoriesandcanhavemany subcategories.ThemainWikipediacategoryis Content ,whichhassevensubcategories.Currentlythereareover1.5 M sub-categoriesin Wikipedia.A categorymay consist ofboth articles andsubordinate categories.Leaf categories inthe graph consistofonlyarticles.
Whilewehaveagoodmodelfordeterminingifasinglearticleiscontroversial,we needtoaggregate microscoresand determine thecontroversy of each node (i.e., category)in the Wikipedia category graph,which will make it possible to detectnewandpotentiallycontroversialarticles.Foreachcategory,wetakeallitsdirectlysubordinatearticlesandcalculate ameanpredictioncontroversyscore.Thiswebcontentcontroversydetectionsystemwaspresentedby Jankowski-Lorekand Zieli´nski(2015).
6.1. Dataset
Currently,theEnglishWikipediaconsistsofroughly5 M articles.Wecomputedalltherequiredfeatures andusedthe modeldescribedintheprevioussectiontodeterminethecontroversyscoreandthisscore’sconfidencelevelforeacharticle. Forfurtherresearch,thisdatasetispubliclyavailableandcanbedownloadedfromthefigshare.comwebsite.1
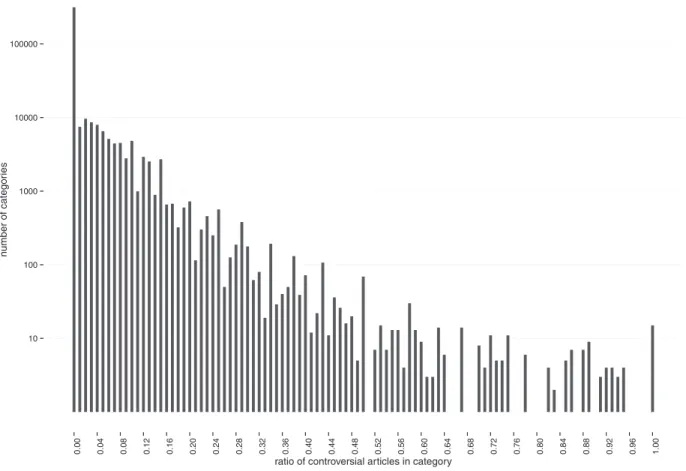
Fig. 8. Histogramofratioofcontroversialarticlesincategories.
Only0.5%(23,103)ofarticlesareclassifiedascontroversial.Weconsiderthistobeaplausibleresult,astheofficiallistof controversialWikipediaarticlescontainsjust963entriesandinthediscussion pagesweidentified 2153entriesusingthe controversialarticletemplate.Thislistisnotoftenupdatedanddefinitivelydoesnotcontainallthecontroversialtopicsand articles.Foreacharticle,weretrievedallthecategoriestowhichitisassigned.Asdescribedabove,anarticlecanbelongto severalcategoriesanddifferentlevelsoftheWikipediacategorygraph.Mostarticleshavefewerthan20assignedcategories butsome havemorethan 200.Thereare 354,940categorieswithonly oneortwo pagesassigned.We willdiscardthose categoriesinfuturestudiesasitisnotmeaningfultoaggregatesuchasmallnumberofarticlespercategory.
6.2. Controversy of Wikipedia categories
Fig.8showsthenumberofcategorieswithagivenpercentageofcontroversialarticles.Thetrendindistributionisnearly exponential forratios smaller than 0.5. Above 0.5, i.e., where the number of controversial articles is greater than non-controversial ones, the distributionis irregular witha notable peak at 15categories witha ratio equalto 1.0. This peak correspondstocategoriescontainingonlycontroversialarticles.Only346categorieshave50%ormorecontroversialarticles. Itisreasonabletotreatthesecategoriesascontroversial.
Fig.9showsahistogramofmeanconfidencelevelofcontroversyinWikipediacategories.Forcategorieswiththemean confidencelevellowerthan0.5thetrendofthedistributionofthehistogramisnearlylogarithmic.Thistrendismoresteady thanin Fig.8.Thereare514categoriesthathavethemeanconfidencelevelofcontroversyof0.5orhigher.Itconfirmsthat thevastmajorityofWikipediacontentisnon-controversialandtheprobabilityoffindingarandomcontroversialwikipedia categoryislow.Thismeansthatingeneral,Wikipediashouldbeconsideredasnotcontroversial.
Therightsidesofbothhistogramsin Figs.8and 9(forvaluesonx-axisbetween0.5and1.0)looklessregularinterms ofthedistributiontrend.Thismaybeattributabletoamuchlowertotalnumberofcategoriesintheseintervals,preventing anycleartrendfromappearing.
Fig. 9. Histogramofmeanconfidencelevelofcontroversyincategories.
Table 2
Top20controversialcategories.
Rank Category MeanConfidence #ofArticles
1 G8nations 0.9978125 8
2 G7nations 0.9975 7
3 G20nations 0.952368421 19
4 Hindustani-speakingcountriesandterritories 0.935833333 3 5 NUTS1statisticalregionsoftheUnitedKingdom 0.905 3 6 PeoplebannedfromenteringChina 0.888333333 3 7 Federalconstitutionalrepublics 0.8875 9 8 Slaviccountriesandterritories 0.883076923 13 9 PeopleoftheAmericanEnlightenment 0.87375 6 10 NearEasterncountries 0.873333333 9 11 WarsinvolvingQatar 0.861666667 3 12 MemberstatesoftheUnionfortheMediterranean 0.860064103 39 13 MemberstatesofNATO 0.855535714 28 14 MemberstatesoftheSouthAsianAssociationforRegionalCooperation 0.85375 8 15 MiddleEasterncountries 0.842916667 18
16 Mormonism 0.841666667 3
17 NortheastAsiancountries 0.8325 7 18 MemberstatesoftheCouncilofEurope 0.828928571 14 19 Democratic-RepublicanPartyPresidentsoftheUnitedStates 0.828125 4 20 WesternAsiancountries 0.827368421 19
6.2.1. Empirical validation
Basedonthereal-worldunderstandingthat sometopicsare generallyknowntobe controversial,e.g., politics,religion, racism,tonameafew,wemanuallytestedthelistsofcontroversialandnon-controversialcategories.
Fig. 10. Percentageofcorrectlyclassifiedcontroversialandnon-controversialarticlesincorrespondencewiththechosenthresholdvalue.
controversialcategoriesbased onmean confidence,we verified82% asbeingcontroversial.Out of100 randomlyselected non-controversialcategories,only5%were infactcontroversialtopics(falsenegatives).Thisvalidationresultconfirmsthat wecanusethemeanconfidencelevelofthecontroversyofarticlestofindcontroversialcategories.
6.2.2. Cross validation
Forthe second validation,we randomly split ourdatasetinto trainingandtest subsetsat aratio of0.7. We usedthe trainingsubsettocalculatethecontroversylevelofcategoriesbasedontheratioofcontroversialtonon-controversialarticles andthemeancontroversy confidencelevel.Then weused thesecategoriesto determinewhicharticles inthetest subset werecontroversial,basedontheaveragelevelofconfidenceofallthecategoriestowhichtheywereassigned.Inthetesting dataset,therewere1,399,303articles,6926ofwhichwereoriginallyclassifiedascontroversial.
Fig.10showsthepercentageofcorrectlyclassifiedcontroversialandnon-controversialarticlesinrelationtothechosen thresholdvalue. An articlewas assignedasbeingcontroversialif themean confidencecontroversy levelof itscategories exceededthisthreshold.
Wecanseethatthepercentageofcorrectlyclassifiedcontroversialarticlesrapidlyincreasesuponloweringthethreshold valuetobelow0.2andforvaluesupto0.06,whereasthepercentageofcorrectlyclassifiednon-controversialarticlesholds steadyuntil0.12andthenbeginstoslightlydecreaseandthendropsrapidlyafterreachingthe0.05thresholdvalue.Based ontheseresults,wechose0.06asthebestthresholdvalue,withwhichwe candetect92% ofallcontroversialarticlesand produceonly10.3% offalsepositives. Theresultsofoursecond validationalsoconfirmedthatwe canusethemeanlevel ofconfidence inthe controversyofarticles toidentify controversialcategories,although inorderto correctlydetect new controversialarticleswemustchooseanappropriatethresholdvalue.
7. ControversyofWebqueries
thefirstresultpage(Pass,Chowdhury,&Torgeson,2006).Incaseofcontroversy,anearlywarningshouldbeissuedbefore anylinkisfollowed,becausemanyusersneverreturntotheSERPoncetheyhavefollowedaresultlink.
User’s search intent isreflectedinthe search query .Themappingofthesearchintentintothesearchqueryisoutsideof thiswork.Inthisresearch,wefocusonthesearchqueryanditsrelationtoknowncontroversies.
A search query will be referred to as controversial when it is related to a topic that is known to be controversial .In our approach,werepresentthistopicbyaWikipediacategory.Asdescribedin Section6,wehaveassignedacontroversyscore toeverycategory,basedonthecalculationofthemeanscoreofthecontroversyclassifier(see Section5.3.1)forallarticles belongingtoa givencategory. Weshallnowcomputeasimilarityfunctionofaqueryandacategory, anduseathreshold todeterminewhetherthequeryisrelatedtothecategory.
7.1. Queries dataset
Today’ssearch-engineproviders consider adatabaseofsearch terms tobe a veryvaluable andprivacy-sensitiveasset. Probablyforthesereasons,theonlylargerscaledatasetofsearchenginequerylogsfreelyavailableforresearchpurposesis theAOLdatasetcollectedduring2006andextensivelydescribedby Passetal.(2006). This collection consists of 21 million web queries, 10M of which are unique .Thequerylogswerecollectedfrom 650kUS-basedusersoverathree-monthperiod. Thisdataset has served as basefor manyresearchers since its publishing in 2006 to recentyears (e.g., Shokouhi, 2013; Whiting& Jose,2014). However, ourresearch doesnot particularlydepend onthisspecific dataset.In fact,we could use otherquerylogswithourmethodonequalterms,i.e.,asasourceofrealusers’queries.
7.2. Similarity function
Next,we needafunctionforcalculatingthesimilaritybetweenaqueryandaWikipediacategory,whichwe defineas describedbelow.Firstweconcatenatethetextsofall articlesbelongingtothecategoryandfindkeywordsusingthetf-idf vectorsin thecorpus of all Wikipediaarticles. Then, we matchthe top-N keywords against the words inthe queryand calculatetheaggregatedtf-idfvaluesfor M matchingwordsand N keywords,respectively.
QSim
(
q,c)
=M i=1Qi
N i=1Ci
(3)
Q i...tf-idfvalueof i-th matchingwordofquery q C i...tf-idfvalueoftop-i-th keywordofcategory c M ≤N
Q Simtakesvaluesfromtherange[0,1].Avalueof0meansthereisnosimilarity,while1indicates perfect similarity.A scoreof1canbeobtainedonlyifall N keywordsinthecategoryarepresentinthequery.Becausemostqueriesareshorter thanfour words,fourisa good value for N .Higher numbers for N arealso good,buttheFormula (3)resultwillyield a smallernumber.Sinceweusethisnumberforranking,theexactvalueof N doesnotreallymatter.
Whenauserentersa queryinnaturallanguage,thenumberofmeaningfulwordsinthequerycan easilyexceedfour. Insuchcases,morethan N keywords shouldbeusedinthesimilarityformula. Ifthematchofthetop N keywords isnot
perfect ,thenwe canextendtheoutlooktoadditionaltop-L keywords.Ifthenumberofadditionalmatchingkeywords is K
thentheirtf-idfvaluesaresummedto R :
R= K
i=1
Qi (4)
Then
QSim
(
q,c)
=M i=1Qi+R
N i=1Ci+R
(5)
InFormula (5),keywords1..N are mandatory ,i.e., theabsenceofa mandatory keywordinthequerydecreasesthe sim-ilarityscore,and keywords N +1..L are optional ,i.e., the presenceof an optional keyword inthe queryincreasesthe score obtainedbyusingonlythe mandatory keywords.Therangeofthefunction Q Simis[0,1].
7.3. Early warning algorithm
Havingdefinedthe Q Sim functionin Section7.2,wecannowmeasurethe similarityofanysearchtermtoanyconcept
representedbyaWikipediacategory,e.g.,foreveryquerywecancalculateitssimilarityscoresforallcategories.However,as wealreadyknowthecontroversyscoreforeach Wikipediacategory,andwearelookingonlyforcontroversy,forpractical reasonswe limit this taskto categorieswith acontroversy score exceeding some arbitrarythreshold value. Wedefine a controversysub-scoreonthelevelquery-categorybythefollowingformula:
Fig. 11. QContscorefortop1000controversialqueries.
Foreveryquery,wecanhaveasmany Sub Contscoresaswehavecategoriesexceedingthethresholdvalue.Again,because
we are looking only forcontroversy, we consider only those pairs (query, category) for which their Q Sim exceeds some
arbitrarythreshold.Asa result,we canhave0to j Sub Cont scores foreach query.Then, wecan introducethecontroversy
scoreofaqueryasfollows:
QCont
(
q)
=(
1 −α
)
·max(
SubCont(
q,ci))
+α
· j
i=1
(
SubCont(
q,ci))
. (7)Bymanipulatingthevalueofparameter
α
between0.0and1.0,wecanbalancetheimpactofthehighestmatchagainstthe aggregatedvalueofallmatchesforagivenquery.Wecalculated Q Cont scorefortop1000controversialqueriesandranked thembythedecreasingscores,i.e.,thehighest
score first. Fig. 11showsthe distribution of Q Cont scoreby the decreasing rankforthe top 1000controversial queries.A
rapidfallof Q Cont scorecanbeobservedonthelogarithmicy-axiswiththedecreasingrankonx-axis.Thisindicatesthata
binaryclassificationbyacut-off valueof Q Cont mayperformquitewell.
7.4. Empirical validation
Wehavemanuallyvalidatedthetop-ranked resultsofthe Early Warning Algorithm fortheexistenceofcontroversy.The validation wasperformedby fiveannotators who were askedtoevaluate controversyof topicsthat they associated with the query,using their ownknowledge regarding thesetopics.Annotators wereasked tolook atthetopics fromthe per-spectiveoftheir communities(annotatorswerePolish,butfluentintheEnglishlanguage andfamiliarwithcontemporary globalculture).Ifannotatorshadnoknowledgeregardingtopicsassociatedwiththequery,theywereallowedtouseGoogle searches.
Annotators assigneda binaryevaluation ofquery controversy. Ifcontroversy wasdiscovered, they were also askedto brieflyjustifytheirevaluationbydescribingthetopicthatwasrelatedtothequeryandcausedlotsofcontroversy.Thefinal decisionregardingaquery’sassociationwithcontroversialtopicswasmadebasedonmajoritydecisionoffiveannotators.
Table3 liststhequeries andtherelatedtopicsthatwere thereasonfortheevaluationofthequeryascontroversial. Sig-nificantly,withinthetop25highest-rankedqueriesusingtheproposedcontroversyranking,theannotatorsfoundonlytwo falsepositives(truepositiverateof92%).Allremainingquerieswereevaluatedascontroversial.
Ontheotherendoftherankedresultlistthereare queriesthatareleastlikelytorefertocontroversy.Within25such queriesshownin Table4onlythreefalsenegativeswerefound(truenegativerateof88%).Someoftheexamplesofthetop 25queries relatedtocontroversialtopicsclearlyillustratethe potentialofan “earlywarning” about controversy. Consider the query“selena” (position 8inthe controversyranking). A superficial Google search (lookingjustatthetop 10 search results) allows theuser to find informationabout the pop-starSelena Gomez.2 However, without diggingdeeper in the
Table 3
Topcontroversialqueriesfoundindataset.
Query Controversy Notes
1 puertorico YES migrationrelatedissuesinUSA 2 continentalairlines YES pastairplanecrashes
3 harrypotter YES occultandsatanicsubtextsinnovelforchildren 4 vietnamwar YES strongUS-Americanoppositionagainstthewar
5 abortion YES moralissuebroughtuponpoliticalagendainmanycountries 6 thomasjefferson YES relationshipofUSpresidentwithhismixed-raceslaveSallyHemings 7 fidelcastro YES popularchampionorcrueldictator
8 selena YES disrespectfulphotoinmosque
9 microsoftwindows YES monopolistbusinesspractices,securityissues 10 rushlimbaugh YES anti-immigrationstatements
11 korea YES KoreanhistorytextbookinSouthKorea,int’lcriticismofNorthKoreanpolitics 12 billclinton YES Lewinskyscandal
13 popejohnpaulii YES lackofresponsetoabuseofchildreninchurch 14 startrek NO Notcontroversial.Sexualityinoriginal“StarTrek” series. 15 sierraleone YES Ebolalockdownpolicy
16 osamabinladen YES deathconspiracytheories 17 hillaryclinton YES privateuseofgovernmentalemail 18 mormons YES bookofMormonorigins,polygamy 19 mariogames YES occult,animalcruelty,transgenderism 20 nigger YES racistinsult
21 ameliaearhart YES deathconspiracytheories
22 airlineflights NO Notcontroversial.Relationshiptoterrorism. 23 victoriabeckham YES Useofskinnymodelsinfashionshows
24 haileselassie YES dictatorandreligiousleaderoverthrownbyMarxistcoup 25 spaceshuttlechallenger YES CriticismoftheSpaceShuttleprograminUS
Table 4
Exampleleastcontroversialqueriesindataset.
Query Controversy Notes
1 b-box NO babyessentialsmanufacturer 2 boxesandmore NO packagingproductssupplier 3 howtobox NO
4 republicancandidates NO 5 whereispoitiers NO 6 whatismanga NO 7 nixonelection YES 8 donatecomputer NO 9 yankees NO 10 3mcorp NO 11 centercity NO 12 developmentofthebrain NO 13 whattodoinaflood NO
14 smokinganditseffects YES Smokingofmarihuana 15 whatisba NO
16 avocadowhatisinit NO
17 starsymbols YES Occult,politicalcontroversies 18 morethancoffee NO cafechain
19 j.a.c.redford NO 20 artandmusic NO 21 concretehowto NO 22 howtopaintfurniture NO 23 messinaitaly NO
24 cityofpeace YES Jerusalem,Baghdad,Auschwitz 25 wildstallions NO
Googlesearch results,orusingthequery“selena mosque”,theuserwouldnot learn abouta controversyaboutSelenain Muslimcountries(referringtoallegedlyinappropriatebehaviorinamosque).
Anotherexampleisthequery“mariogames” (position19inthecontroversyranking).Again,theGoogle top10search resultswillnot revealinformationaboutcontroversy.However, thequery“mariogamescruel” canretrieveaWebpageof the“mariowiki”3 thatcontainsalistofcontroversiesrelatedtothegame,includingconcerns aboutanimalcruelty, trans-genderismandtheoccult. Oneofthe falsepositivesinthe top25is thequery“StarTrek”.Interestingly,it seemsthat in the1960s and1970s, whenthe original “StarTrek” series wasrunning,it mayhave generatedsignificant controversy in
Fig. 12. TPRofbinaryclassificationbycut-off value.
theUnitedStatesbecauseofreferencesorsuggestionsofhomosexuality,polyamorousrelationshipsetc.4Itseemsthatsince then thiscontroversyhadbeenreduced, butits tracesstillremain ontheWebandWikipedia.Therelationbetween con-troversyandtimeisaninterestingissuethatweplantoinvestigatemoreinthefuture.Likealmosteverything,controversy tootendstofluctuateandcanoccurovercertainperiodsonly.Theproposedapproachmainlydetectscontroversiesexisting currentlyorintherecentpast.
Someofthefalsenegativesinthebottom25ofthequerylistdemonstratedifficultiesofautomaticcontroversy evalua-tion.Forexample,thequery“starsymbols” wasclassifiedasnon-controversial.However,starsymbolsincludethe“Starof David” (symbolofIsraelwhichsometimesappearsinanti-semiticcontroversies)andthepentagram(usedinoccult).Such culturalknowledgeisdifficulttoteachtoan algorithm.Anotherfalsenegative,thequery“smokinganditseffects” can re-fertotobacco(in thiscontext,itmaynolongerbecontroversial),butitcanalsorefertomarijuana.Thealgorithmcannot simply guessthis association,andthe wording ofthe querywas apparently understoodby the algorithm asreferring to smokingoftobacco.
Havingranked the top 1000 results(see Fig.11) we now need a cut-off value forthe binaryclassification: if Q Cont>
cut-off,thenthequeryisclassifiedcontroversial,otherwiseit isclassifiednot controversial.Inordertochoosethecut-off value wefirsthadtoestimatetheperformance ofsuchaclassification,forwhichwehadtousehumanannotationagain. Wedividedthetop250rankedqueriesin10bins,25querieseach.Eachbinspreadsoveradecreasingrangeof Q Cont.The
controversyforeach querywasmanually annotatedinbins 1,2,5,6,7,8 and10.Then wecalculated TruePositiveRate (TPR)foreachoftheannotatedbinsandpresenteditgraphicallyin Fig.12.Thisplotletsusestimatethatwithanexample cut-off valueof Q Contscoreof25weobtainTPRof0.7.Thepositionofthesameexamplecut-off pointisalsoshownonthe
rankingplot,see Fig.11.
7.5. Robustness to manipulation
One concernabouttheproposed approachrelatesto adversarialmanipulationof controversycomputation.It could be possiblethatsomeentitiestrytoimpacttheresultstoeithermakecertainWikipediaarticlesseemlesscontroversialor,in contrast,to“render” thenon-controversialonessuchthat theybecome controversial.However, thiswouldrequire manip-ulatingdataonseverallevels.Inparticular,notonlytheperceptionsoftrustworthinessgivenbyWikipediavisitorsshould be impactedbutalsothe sentimentlevels ofWikipediatalk pages,whichrecord communicationbetweenthe editors, as well asthe numbers ofedits,revisions, unique editors, etc. Thisis ratherdifficult, especially, consideringthat Wikipedia categoriesmay containlarge numberof individual pages.To summarize, theuseof severalindependent variablesby the controversyclassifiers,aswell astheaggregationofarticlecontroversyscoresintocategoriesmakes ourmethodquite ro-busttoadversarialmanipulation.
8. Conclusionsandfuturework
Detectingcontroversyisachallengethatreachesfarbeyondnaturallanguageprocessingalgorithmsandrelatedresearch. It requires a holistic approachand differenttools drawn fromWeb science andsocial informatics. The resultspresented heredemonstrate that ourformal model,introduced in Section 3, correctlyidentifies potential problems associated with predictingcontroversy. The proposed formal model ofcontroversy might also be usefulas a basis forfurther study and introducesacommondenominatorforusebyverydifferentresearchperspectives.
Wikipediaarticlesprovideagoodstartingpointforlearningaboutcontroversyduetothevastamountofmeta informa-tionthat canbeusedforpredictingandexplainingsourcesofdisagreement.Asshownin Table1in Section5,combining
ourmethodwithpreviously proposedapproachesbooststheF-measure to84.10%andconstitutesa goodbasisforfurther research.WeusedthepredictedcontroversyofWikipediaarticlestocalculatethelistofthemostcontroversialcategories. Thislistmightbeusefulfortheselectionoftopicsformorecarefulmonitoring.ThisisasubjectimportanttotheWikipedia community,becauseWikipediaaimstorealizeaneutralpointofviewandexcludesexcessivecontroversialviews.
In Section7,weshowedthatevaluatingcontroversyofWikipediacontentmayalsobeusedforidentifyingcontroversial queriesinsearchengines.Wetestedourproposedalgorithmonrealqueriessubmittedbypeople.Ourmanuallyconducted validationshowsthatitworksquite wellformostcontroversialquerieswhile notraisingtoomanyfalse alarms.We em-phasizethat aquerywithacontroversywarningshouldnotbeconsidered asnegativeorharmful,butratherthewarning shouldbeseenasausefulrecommendationforuserstobecarefulwhenstudyinganysearchresults.Moreover,becauseof theheavypersonalization andthefilterbubbleeffecton searchresults,aparticularusermightonlyretrieveone pointof view,soacontroversywarningindicatesthatsomeimportantinformationmaybelackinginthesearchresults.
Controversiesareinevitable.Therefore,furtherresearchoncontroversyontheInternetisneededtobetterunderstandits dynamics.Newalgorithmsfordetectingandmitigatingcontroversieswilldefinitelybedevelopedintheforeseeablefuture. Inourfuturework,we plantoverifywhethertheuseofcontentandmetainformationfromQ&Awebsitesmighthelpto identifycontroversywithrespectto rapidlychangingtopicsortopicsthatare beyondthecoverage ofWikipedia.Wealso plantoincludetimeandcommunitydynamicsinourformalmodelofcontroversy.
Theremainderofthissectiondiscusses thelimitationsofourstudy,possiblesocialramifications ofalertingWeb users toquerycontroversy,andfuturework.
8.1. Study limitations
Ourstudyfollowsanempiricalresearchmethodology.Inthissection,we describethelimitationsofourresearch meth-ods,andpossiblewaysofaddressingthem.
8.1.1. AOL Query Log
AOL Query Log was published in 2006, hence, it might seem outdated. We have utilized AOL Query Log due to its availabilityandrelativelylargesize.Tothebestofourknowledge,nootherpubliclyavailabledatasetofWebsearchqueries hasa similar size (about 10 million unique queries).While the set of queries is over 10 years old andthe Web search behaviorofusersmayhavechangedsincethen,ourestimations ofcontroversyoftopicsrelatedtothe querieshavebeen performedonthecurrentversionsofWikipediaarticles. Similarly,the evaluationdescribedin Section7.4wasperformed undercurrentcircumstances (i.e.,asifthequerieswereissuedcurrently).Hence,thereisnoproblemoftimedifferenceor thelackofsynchronizationbetweentheknowledgebaseusedforcomputingtheresultsandthetimeofevaluation.
8.1.2. Web users vs. Wikipedia users
OurresearchhasmadetheassumptionthatcontroversyevaluationbasedonWikipediawillbeusefulforallWebusers. Thisisthesameasassumingthat thecommunityofWikipediauserswillprovideausefulcontroversyevaluationforthe communityofallWebusers.Evenifwe restrictthesecommunities bylanguage(English-languageWikipediaand English-languageWeb),theremaybeWebuserswhodonotuseWikipedia.However,accordingtoarecentstudy,5despiteadropin GooglesearchrankingsofWikipediapages,over50%ofsearchquerieshaveaWikipediapageinthetop10ofGooglesearch results.Wikipediahasabout18billionviewspermonth6(ascomparedtoabout100billionGooglesearchesmonthly).The numberofusersishardertoestimate,butthenumberofuniquedevicesthataccesstheEnglish-languageWikipediadaily isabout60million.7 Thesestatisticsshowthat whilethecommunityofWikipediausersissmallerthanthecommunityof allWebusers(fortheEnglishlanguage),itshouldbesufficientlylargetobetreatedasalargesample(atleastontheorder oftensofmillionsinsize).Nevertheless,littleisknownaboutthecommunityofWebusersthatdoesnotuseWikipedia, andmoreresearchofthissubjectisrequired.
WhatismoresignificantisthataccordingtoWikipediapolicy,Wikipediaonlyexcludescontentthatisnotencyclopedic. Wikipedia is adding 20,000 new articles each month. It reacts very quickly to current newsworthy events, such as the deathofMichaelJacksonortheFukushima catastrophe.Forthesereasons,itislikelythat controversiesthatoccur inthe communityofWebuserswilleventually(rathersoonerthanlater)bereflectedintheWikipedia.
8.1.3. Cultural biases
Naturally,culture andbackground ofa person impacts theway inwhich sheor hejudgesandperceives controversy. ConformistsocietiessuchasJapanesesocietymayhavedifferentattitudeandpropensitythanindividualisticsocietiessuch astheUSAtowards evaluating andmeasuringcontroversy. Theproposed method canbe adapted todifferentcultures by utilizingdifferentlanguage versionsof Wikipedia(e.g.,Japanese Wikipedia). Webelieve that thiscould partially mitigate theproblemofculturalimpactandbias.
5 https://www.stonetemple.com/google-still-loves-wikipedia-more-than-its-own-properties/ , September 23, 2015. 6http://www.pewresearch.org/fact-tank/2016/01/14/wikipedia-at-15/ .