線上拍賣結標價與期望獲利之預測
林俊宏
中央大學資訊工程研究所
[email protected]
張嘉惠
中央大學資訊工程研究所
[email protected]
摘要
線上拍賣是目前相當流行的商品交易方式, 龐大的商機吸引了大量的一般小型商店或個體相 繼投入網拍市場,隨著投入網拍的賣家愈來愈多, 賣家彼此之間的競爭也愈趨激烈。此時,對於賣家 而言,如何將獲利最大化就成了網拍經營中致勝的 關鍵。在本篇論文中,我們提供一個銷售建議的服 務,這個服務能在賣家刊登商品之前,預測商品的 利潤高低,藉此建議賣家是否應該以目前所使用的 銷售策略來刊登商品,避免賣家使用不適當的銷售 策略而導致利潤的損失,進而幫助賣家達到利潤最 大化的目標。我們以美國 eBay 網站做為資料的收 集對象,透過機器學習演算法來預測商品機率及結 標價,並考慮銷售策略成本來計算出商品的期望利 潤,作為銷售建議服務判斷的依據。此外,在預測 商品售出機率及結標價的議題中,我們解決預測商 品售出機率時所發生的機率值偏差問題及結標價 預測中可能發生的樣本選擇偏差問題,增加銷售建 議服務的獲利能力。最後我們比較銷售量最大化目 標、結標價最大化目標及使用銷售建議服務達到利 潤最大化目標所獲得的利潤,實驗結果顯示,我們 所提供的銷售建議服務能獲取最大的利潤,而採用 銷售量最大化目標將導致商品利潤較低,結標價最 大化目標容易導致商品無法售出。
1. 序論
近年來,電子商務隨著網路的普及而大幅成 長,尤其以 C2C 交易形式為主的線上拍賣,更是受 到一般大衆喜愛,例如 eBay、Yahoo…等大型跨國 拍賣網站。eBay 是目前全球最大的 C2C 線上拍賣 網站,到 2006 年為止,eBay 已有超過兩億兩千兩 佰萬個會員註冊,共六十萬個 eBay Store 被使用 者創立,每天有多達一億多個商品等著被拍賣 [1]。線上拍賣會吸引如此多的賣家是因為拍賣網 站突破時間與空間的限制、擁有廣大的市場、提供 二手商品銷售的管道及賣家創業的低門檻[2]。雖 然拍賣網站為賣家帶來大量的商機,但同時也意味 著眾多的個人及商家須在同一平台上激烈地競 爭,所以對於賣家而言,如何將獲得的利潤最大 化,就成了網拍經營中的致勝關鍵。
賣家要達到利潤最大化目標首先要克服追求 商品售出機率及結標價的兩難,因為賣家若想透過 設定較高的起標價或是直接購買價,則其結標價必
定也較高,但同時商品售出的機率也會隨之降低, 而且即使商品未售出,賣家仍需支付業者刊登費及 所使用相關服務之費用,還有商品未售出所造成的 損失。相反地,賣家若想藉由設定較低的起標價、 直接購買價,或是購買大量的廣告以提高商品曝光 度,此時雖然可以增加售出機率,但同時也可能獲 得較低的結標價,或是花費太多的銷售策略成本1 而壓縮獲利空間。所以賣家必須在考慮該銷售策略 成本的前提下,衡量商品售出機率與結標價兩者之 間的平衡點,追求期望利潤的最大值,才能獲得最 大利潤。然而,賣家要判斷刊登某一個商品是否能 獲利並不是一件容易的事,因為商品利潤與賣家所 使用的銷售策略息息相關,而賣家卻沒有能力預測 使用目前銷售策略的拍賣結果,這使得賣家常常還 是以不適當的銷售策略來刊登商品,造成利潤上的 損失,進而迫使賣家退而求其次,轉而追求較易達 到的銷售量最大化目標或結標價最大化目標,無法 將利潤最大化。
近年來,開始有許多研究工作應用統計和機 器學習的方法於結標價的預測[9,11,20],幫助賣 家根據預測的結標價高低,來評估使用的銷售策略 是否能獲得較高的利潤。然而,以結標價預測為基 礎的評估方式,容易導致商品無法售出。實際上, 要達到利潤最大化的目標所需要的不只是單純的 結標價或商品售出機率預測,而是包含兩者的期望 獲利預測。觀念雖然很直覺,但是到目前為止,我 們尚未發現有研究利用商品售出機率與結標價相 乘而得的獲利預測。
本篇論文不僅預測商品結標價,也預測商品 售出機率,藉以計算出商品的期望結標價,並考量 銷售策略成本,來評估賣家所使用的銷售策略(刊 登服務)的期望利潤高低,進而提供銷售建議服 務。實驗結果顯示,賣家透過我們的銷售建議服務 能得到最多的利潤,而銷售量最大化目標將導致商 品利潤較低,結標價最大化目標容易導致商品無法 售出情況。透過這樣的服務賣家可以調整自我的銷 售策略以迎合買家的需求,將有助於提高拍賣平台 交易的成功率及價格,所以這對於賣家及拍賣網站 業者來說,都會是一個有用且吸引人的服務。
1 除了刊登商品的費用外,eBay 還提供許多的付 費服務,例如賣家想設定直接購買價或拍賣底價皆需付 費,還有許多增加商品曝光率的廣告服務,例如粗體字、 加框線等都有額外的收費。
2. 相關研究
過去已有相當多的研究於拍賣的領域,研究問 題相當廣泛。在本篇論文中,我們只專注於線上拍 賣的機制,並且為協助賣家拍賣商品的相關研究。 我們將這些研究分成五類,包括決策支援系統、網 路代理人、市場調查公司分析工具、經濟學研究及 結標價預測。
決策支援系統:在管理學的領域,決策者可 藉由決策支援系統(DSS)的輔助,避免自己落入直 覺行事的陷阱。但是在線上拍賣的領域中,決策支 援系統的研究方向大多為輔助買家設定競標策略 或標的,針對網拍賣家的行銷決策支援系統相當缺 乏,而且沒有能力預測商品的拍賣結果[2],賣家 無從得知拍賣該商品能增加多少獲利。
網路代理人:在線上拍賣的領域中,包括有 官方對賣家提供的查詢歷史商品交易資訊、監控商 品競標情況及阻擋在黑名單上的競標者下標等網 路代理人服務;另外也有第三方的網路代理人,如 BidXS.com 及 McFind.com 可同時收集多個拍賣網 站的資訊,BidXS.com 還與 StrongNumbers 合作提 供商品的歷史價格變化趨勢給賣家。雖然目前這些 代理人滿足了買賣雙方的時間及資訊需求,但是它 們尚未有能力詳細地分析這些資料,只能藉由統計 過去的拍賣記錄給賣家參考。
市 場 調 查 公 司 分 析 工 具 : 目 前 也 有 terapeak[8]、HammerTap[9]兩間市場調查研究公司 與 eBay 合作,以月付 25 塊美金左右提供圖表化的 市場資訊,例如平均結標價格、商品售出成功率、 不同拍賣天數的平均結標價…等統計資訊。雖然這 些資訊對賣家在制定銷售策略時相當有用,但缺點 是僅限於單一因素對結標價和售出機率的全體統 計資料,賣家仍需考量本身的特性及商品狀況,單 純地參考該種商品的全體統計資料或模仿其它賣 家的策略將會和預期的利潤有所落差。
經濟學研究:主要研究方向在於探討拍賣機 制和買賣雙方的行為模式[15]。在賣家行為的議題 中,有部分研究工作調查在不同的賣家類型或商品 性質之下,分析賣家使用的銷售策略及其拍賣結 果。也有研究工作分析各種拍賣屬性對結標價及售 出機率的影響,以作為賣家設定銷售策略的參考。 除了上述的探索性研究之外,也有學者試圖建立計 量經濟模型,模擬買賣雙方的行為,藉此預估賣家 的獲利。僅管這些研究工作提供相當好的銷售策略 指引,但他們大多沒有模擬較詳盡的真實線上拍賣 情境及真實交易資料來預測拍賣結果,只推估各種 拍賣設定對於拍賣結果之間的關係,因此無法提供 賣家精確的獲利數字。
結標價預測:近年來相斷有許多研究工作應 用 統 計 和 機 器 學 習 的 方 法 於 結 標 價 的 預 測 [4,5,14],讓賣家預測商品的結標價,作為制定銷 售策略的參考[4]。然而,高結標價並不保證賣家 能將獲利最大化,因為商品售出機率與結標價存在 著反向關係,所以賣家在制定銷售策略時,必須同
時考慮該策略下的商品售出機率及結標價,藉由最 大化期望獲利來最大化賣家利潤。
3. 研究方法
在本節裡,我們首先簡述我們採用的資料集 及特性,接著介紹期望結標價預測的兩個模型。
3.1 研究資料
我們收集為期約二個月的美國 eBay 交易資 料,所搜集範圍為數位相機,從中選取交易筆數最 多五種的數位相機型號,共 4852 筆資料作為我們 研究的資料集,表 1 為五種數位相機的相關統計資 料。我們排除使用荷蘭式拍賣刊登的商品。除此之 外,雖然商品新舊也是影響商品售出機率及結標價 的一個重要因素,但是我們也將舊商品排除在研究 範圍之外,因為拍賣文字敘述及照片影響舊商品的 價格及售出機率甚鉅,難以從我們所收集的資訊來 預測。
我們將所搜集到的資料進行前置處理,並將 72 種屬性分類成以下 3 種。
賣家特性: 賣家類型(依販售商品個數分為商家、 頻繁賣家和個人賣家)、賣家回饋分數、正負評個 數、註冊多久、是否為 Power Seller、是否擁有 eBay Store、是否有“關於我”網頁…等。
商品特性: 商品狀況、商品配件、是否有記憶體配 件、記憶體大小、是否有保固…等。
拍賣特性: 標題、子標題、拍賣式刊登或直接購買 式刊登、拍賣始末時間、拍賣時間長久、起標價、 直接購買價、結標價、是否有保留底價、運費、付 款方式、使用的廣告服務(粗體字、加框線…等)、 是否有圖片…等。
一般而言,賣家在 eBay 銷售商品主要有兩種 方式,分別是拍賣式(AuctionList)刊登及直接購買 式(BuyItNow)刊登。兩者之間最主要的差別在於選 擇拍賣式刊登時,賣家須設定起標價。使用直接購 買式刊登時,賣家則須設定直接購買價,一旦有人 下標之後刊登隨即結束。表 2、表 3 為在我們資料 集中的拍賣式刊登與直接購買式刊登的統計資 料。由表 2 可得知,除了型號 SD550 的售出機率 較低之外,由於大多數賣家將起標價設定較低的緣 故,拍賣式刊登的商品幾乎都售出。相對地,使用 直接購買式刊登的賣家大多是職業賣家,這類賣家 通常搭配較多的相關配件於商品中,所以平均結標 價格較高。
表 1 數位相機資料集統計資料
表 2 拍賣式刊登資料集與直接購買式刊登資 料集的統計資料
在我們所收集的資料中,若商品使用拍賣式刊 登時,則直接購買價屬性為空值,反之若商品使用 直接購買式刊登,則起標價屬性為空值。從資料觀 點的角度而言,倘若我們將這兩種刊登方式的商品 資料集結合在一起,建立全部商品的預測模型,那 麼該模型將會受到這兩個重要屬性存在著大量空 值的影響。再者,對於使用直接購買式刊登的商品 而言,因為結標價即為直接購買價,所以我們無須 預測結標價。因此我們將全體資料集 D 切割成拍 賣式刊登 DA與直接購買式刊登 DB 兩種子資料
集,屬性集合 x 也隨之分成相對應的 xA及 xB二種,
再依此兩子資料集分別建立預測模型。
3.2. 期望結標價的預估
機率理論中的期望值能表達隨機變數的期望 結果值,若我們將商品是否售出視為一個隨機變數 s,結標價視為隨機變數 y,隨機變數 x 則代表該 商品的所有屬性,即包含賣家特性、物品特性及拍 賣特性。另外定義當 y=y0 時,代表商品未售出
(s=0),因此 P(y=y0|x)=P(s=0|x)。
對於以直接購買型式刊登的商品而言,其期 望結標價可以由商品售出機率乘以商品售出時的 結標價 y1來計算。
)
| 1 ( )
| 0 ( 0 )
|
(y xB Ps xB y1 Ps xB
E (1)
對於以拍賣型式刊登的商品而言,我們可以 有兩種做法,其一是延續直接購買式的做法,先估 計銷售與否的機率 P(s=0|x),再估計結標價 y1,並
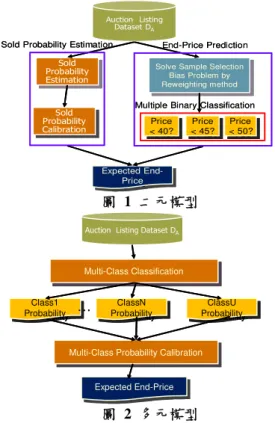
以公式(2)來計算期望結標價(圖 1),我們稱之為 二元模型(Two Class Estimation)。
)
| ( )
| ( 0 )
|
(y xA P y0 xA y1 P y1 xA
E (2)
另外一種做法則是把原本為連續數值的結標 價離散化成多個離散區間來表示,即將 y 視為一離 散隨機變數,再用一個多元分類器來做為 y 值的估 計,同時以區間的歸屬強度來做為機率(圖 2), 我們稱之為多元模型(Multi-Class Estimation)。
n
i
i
i P y x
y mean x
y E
1
)
| ( ) ( )
|
( A A (3)
二元模型這種分別預測商品售出機率及結標 價 來 計 算 期 望 值 的 作 法 , 相 同 於 Zadrozny 與 Elkan[16]在 2001 年使用 KDD-Cup98 資料集,預
測捐獻者捐獻的機率及金額來計算期望捐獻金 額,並判斷若期望捐獻金額大於行銷成本則進行行 銷,否則不對其行銷。Zadrozny 與 Elkan 同時也指 出在預測捐獻機率可能會因演算法的偏見而造成 機率值有所偏見,更重要的問題則是在預測捐獻金 額的時候,也可能會因訓練資料集與測試資料集的 分 布 不 一 致 而 產 生 樣 本 選 擇 偏 差 問 題 (Sample Selection Bias) ,導致預測值與真實結果有所偏 差。為了解決上述兩個問題,Zadrozny 與 Elkan 使 用之前所提出 smoothing c4.5 及 binning naïve bayes 來 得 到 準 確 的 機 率 值 [17] , 並 使 用 Heckman’s procedure 來矯正樣本選擇偏差,再以 multiple linear regression 預測捐獻金額。在經過矯正上述兩個問 題之後,實驗證實所獲得的利潤總和較高。由上述 可知,若我們使用二元模型預測期望結標價,我們 必須建立兩個預測模型,並解決預測機率偏差及樣 本選擇偏差問題。
相對於二元模型分別預測商品售出機率及結 標價的作法,多元分類模型則是直接預測期望結標 價,此作法的優點在於它不會發生樣本選擇偏差問 題,而且只須建立一個預測模型。但缺點在於多元 分類模型須同時分辨商品是否售出及售出時可能 的結標價區間,而且如果結標價範圍較大且分布鬆 散,會導致每個類別的資料量較少進而影響預測準 確度。
Auction Listing Dataset DA
Price
< 40? Price
< 40? < 45?Price Price
< 45? < 50?Price Price
< 50? Multiple Binary Classification Sold
Probability Calibration
Sold Probability Calibration Sold Probability Estimation
Sold Probability Estimation
Solve Sample Selection Bias Problem by Reweighting method Solve Sample Selection
Bias Problem by Reweighting method
Expected End- Price Expected End-
Price
Sold Probability Estimation End-Price Prediction Auction Listing
Dataset DA
Price
< 40? Price
< 40? < 45?Price Price
< 45? < 50?Price Price
< 50? Price
< 40? Price
< 40? < 45?Price Price
< 45? < 50?Price Price
< 50? Multiple Binary Classification Sold
Probability Calibration
Sold Probability Calibration Sold Probability Estimation
Sold Probability Estimation
Solve Sample Selection Bias Problem by Reweighting method Solve Sample Selection
Bias Problem by Reweighting method
Expected End- Price Expected End-
Price
Sold Probability Estimation End-Price Prediction
圖 1 二元模型
Class1 Probability
Class1
Probability ProbabilityClassN ClassN
Probability ProbabilityClassU ClassU Probability Auction Listing Dataset DA
Expected End-Price Expected End-Price Multi-Class Classification Multi-Class Classification
Multi-Class Probability Calibration Multi-Class Probability Calibration
…
Class1 Probability
Class1
Probability ProbabilityClassN ClassN
Probability ProbabilityClassU ClassU Probability Class1
Probability Class1
Probability ProbabilityClassN ClassN
Probability ProbabilityClassU ClassU Probability Auction Listing Dataset DA
Expected End-Price Expected End-Price Multi-Class Classification Multi-Class Classification
Multi-Class Probability Calibration Multi-Class Probability Calibration
…
圖 2 多元模型
4. 售出機率的預估及多元模型機率調校
估計商品賣出與否我們可以任一種 Binary Classification 來訓練其模型。在本篇論文中,我們 使用 SVM(Support Vector Machine)作為我們的分 類器。SVM 是近年來相當流行的分類演算法,並
普遍使用於解決各種分類問題。不過由於計算商品 期望結標價時,需要有準確的機率,因此我們必須 做適當的調校才可以將分類器所提供的類別歸屬 度轉成機率。在本篇論文中,我們使用 Platt Scaling 來得到真實的機率值。Platt Scaling 假設 SVM 的分 數值 f(x)與真實機率的對應關係如下面式子(4)所 示
) exp(
1 ) 1
| 1
(y f Af B
P (4)
其中參數 A 和 B 可以使用 Gradient Descent 找出使 得式子(5)的值最小:
) exp(
1 where 1
) 1 log( ) 1 ( ) log( argmin
,
B p Af
p y
p y
i i
i
i i
i i B
A
(5)
然而,Platt Scaling 只適用於二元分類問題, 也就是對於直接購買型式刊登的商品或是二元模 型的售出機率調校有用。但是若我們使用多元模型 方 法 來 預 測 期 望 結 標 價 時 , 我 們 必 須 得 到 P(s=1,y|xA)機率值。針對多元分類問題的機率值校 正議題,Zadrozny 和 Elkan[11]提出一個三個步驟 的解決方法。先把多元分類問題轉成多個二元分類 問題,然後把每一個二元分類器的機率值組合成多 元分類問題的機率值。至於如何將多個二元分類器 所得到的機率組合成多元分類的機率值,我們使用 Hastie 和 Tibshirani 提出的 Pairwise Coupling[6]方 法,對於每兩種類別 i,j 的組合訓練一個分類器 (All-Pairs),並以式子(6)計算機率值 rij(x)。
i i
j i
i ij
x p
x p x p
x x p
X j C i C i C P x r
1 ) ( where
) ( ) (
) ) (
,
| ( )
( (6)
再 藉 由 尋 找
p ˆ
ij 使 得 預 估 機 率 值μ ˆ
ij 與 rij(x) 的 Kullback-Leibler(KL)距離能最小
j
i ij
ij ij
ij ij ij
ij r r r r
n p
l μ 1 μ
log 1 ) 1 ( log )
( (7)
Hastie 和 Tibshirani 證明了
μ ˆ
ij與 rij(x)之間的 Kullback-Leibler 距離會隨著反覆地尋找p ˆ
ij而遞減 至收斂,尋找p ˆ
ij的演算法如下:
k
1 i
ˆ / Pˆ Pˆ . 3
ˆ the recompute ˆand
the e renormaliz ˆ ,
ˆ
: e convergenc until
K,1,...) 1,2,..., (i Repeat 2.
ˆ ing correspond ˆ and
for the guess some Start with 1. Algorithm.
i
ij i
i
j ij ij
i
j ij ij
i i
ij i
p n p
r n p p
p
μ μ
μ
5.二元模型之結標價預估及樣本選擇偏差
不同於 Zadrozny 與 Elkan 使用線性廻歸做結標 價的估計,本篇論文使用 Ghani 及 Simmons[4]提 出的多個二元分類器(Multiple Binary Classification) 預測方法於二元模型的結標價預測工作中。多個二 元分類器的做法是先把結標價切割成多個相同大 小的離散區間,對於每一個價格切割點,建立一個
二元分類器來預測該商品的結標價是否大於此價 格 切 割 點 , 並 產 生 三 個 欄 位 的 預 測 結 果 (Price, Prediction, Confidence),最後根據這些二元分類器 的結果,將商品的結標價預測為判定為“真”的分類 器中的最高價格。例如有三個二元分類器預測的結 果為(40, 1, 0.9), (45, 1, 0.85), (50,-1,0.8),此時我們 將該商品的結標價預測為區間 45~50,並取其區間 中位數 47.5 作為預測的結標價格。多個二元分類 器相對於多元分類器的優點在於每一個二元分類 器都能使用全部的資料集作為訓練資料,這對於交 易數量不多的商品幫助特別大。
不過由於二元模型中估計結標價時僅採用已 售出的商品做為價格的預測的訓練資料,因此產生 樣本選擇偏差的問題。樣本選擇偏差問題以往在計 量經濟學受到相當的重視,統計領域也有所研究 [3,10]。對於在樣本選擇偏差情況下的連續值預測 問題,經濟學家 Heckman[7]在 1979 年提出兩階段 的程序預測來解決,但該方法的限制為只能使用線 性迴歸方法做預測。除了計量經濟學及統計的相關 研究之外,近年來也有數篇機器學習領域的論文專 注於此議題上[12,13,20],其研究問題偏向於離散 值的分類預測。大多數的研究將樣本選擇偏差的情 況分成以下四種情況:
Complete Independent: 布林資料選擇變數 s 獨立 於屬性 x 和類別 y。即 P(s|x,y) = P(s) 。
Feature Bias: 布林資料選擇變數 s 相依於屬性 x, 且在屬性 x 的情況下與類別 y 獨立。即 P(x)≠ P(x|s=1)且 P(s|x,y) = P(s|x) 。
Class Bias: 布林資料選擇變數 s 相依於類別 y,且 在類別 y 的情況下與屬性 x 獨立。即 P(y)≠P(y|s=1) 且 P(s|x,y) = P(s|y) 。
Complete Bias: 布林資料選擇變數 s 同時相依於 屬性 x 和類別 y。 即 P(s|x,y) = P(s|x,y) 。
在我們的研究工作中,商品售出與否可視為布 林資料選擇變數 s,類別 y 則是結標價轉成離散屬 性分類問題後的結標價區間,屬性 x 包括賣家特 性、商品特性及拍賣特性。在結標價格預測時,由 於所使用的資料皆為售出商品(s=1),因此會有樣 本選擇偏差的問題存在。因為我們只擁有(x,s=0) 和(x,s=1,y=yj)兩 種 資 料 集, 而 沒有 (x,s=0,y)的 資 訊,預測結標價工作將屬於最複雜的 complete bias。然而在 complete bias 的情況下,理論上我們 將無法進行預測,如下面式子 8 所示,因為我們缺 乏(x,s=0,y)的資訊,而且 s 同時與 x、y 有關係,所 以我們無法將 P(y|s=1)簡化為 P(y),將 P(x|y=yj,s=1) 簡化為 P(x|y=yj),所以目前解決 complete bias 的方 法都需要做更進一步的假設。
) (
) 1
| ( ) 1 ,
| (
) (
) ( )
| ) (
| (
x P
s y y P s y y x p
x P
y y P y y x x p y y P
j j
j j
j
(8)
相對於矯正 complete bias 的困難,矯正 feature bias 就顯得簡單許多,Zadrozny[20]假設資料選擇
變數 s 不改變 decision boundary,也就是假設 P(y|x)=P(y|x,s=1)。如式子 9 所示,基於 decision boundary 不變的假設,我們可把原本 complete bias 的問題簡化成 feature bias,降低樣本選擇偏差問題 的複雜度。但當我們在假設 decision boundary 不變 的 同 時 , 我 們 其 實 也 隱 含 著 p(s=1|x)>0 或 p(x,s=1)>0 的假設,而且 P(y|x,s=1)若要能正確地逼 近 P(y|x)的值,則必須存在不少的樣本數目[13]。
)
| 1 ) (
( ) 1 , (
) , (
) 1 ( ) (
) , ( ) 1 (
) 1 , (
) , (
1) ) P(s
| ( ) 1
| (
) , (
1) 1) P(s
s x,
| 1)P(y s
| P(x
) , (
) 1 ( ) 1
| , ) ( ,
| 1 (
x s x P
P s x P
y x P
s P x P
y x P s
P s x P
y x x P y P s x P
y x P y x P
s P s x y y P x s P
(9)
我們假設同一種商品在擁有相同的屬性值 x 之下,不管商品售出與否,商品的價值不會改變, 進而假設結標價不變,即 P(y|x)=P(y|x,s=1)。如此 可簡化至 feature bias 問題。此外,我們也將結標 價離散化,將結標價連續值預測工作轉成分類問 題,以適用 Zadrozny 所提出的 reweighting 方法 [20] 來矯正樣本選擇偏差,同時也適用於 Ghani 及 Simmons 所提出的 multiple binary classification 方 法來預測結標價,提高預測的準確度。
Zadrozny 的 reweighting 方法概念為先矯正資 料的分布情況,然後再應用任一種分類演算法去學 習矯正過後的資料,以獲得正確的結果。Zadrozny 使用下面式子 13 來矯正原本偏差的資料分布 D 至
Dˆ
)
| 1 (
) , , ) ( 1 ( ) , , ˆ(
x s P
s y x s D
P s y x
D (10)
我們可視 Dˆ 中的每一筆資料 Dˆ (x, y, s)為原本偏 差的資料分布 D 中的每一筆資料 D(x, y, s)擁有權 重值 P(s=1)/P(s=1|x)。Zadrozny 並證明了在 feature bias 的情況下,用上面的式子矯正原本偏差的資料 分布後,即使使用偏差(s=1)的資料集學習,其分 類器 h 的學習結果 loss function l(h(x),y)相等於在 無偏差的資料集學習的結果。
從 附有權重 值的資料 集中學 習的作法 上, Zadrozny 使 用 他先 前提出的 方法 Costing[19]。 Costing 根據其權重值,使用 rejection sampling 的 方式來獲得新的資料集 S',然後再從 S'學習得出結 果 hi。因為 S'是以 rejection sampling 的方式獲得, 所以 S' 的資料集大小會小於原本資料集 S,如此 在學習時可降低其計算時間。也因為學習的計算量 降低,所以 Zadrozny 主張可重複學習多次以得到 更好的效果, 又不會增加太多的計算時間。
t
i i
i
C
x h x
h S' A h
Z
S S'
t i
t S A
S (x,y,c)
1 ( ))
sign( ) ( Output 2.
) ( Let (b)
) max ( c/Z. y probabilit
accpetance with
from sample rejection (a)
do to 1 For 1.
) Count , Set Sample , (Learner Costing
: Algorithm
如此一來,即使我們只使用售出的拍賣式刊登 商品作為訓練資料集,我們仍可先透過矯正樣本選 擇偏差得到正確分布的資料集,再使用多個二元分 類器來預測結標價,得到較正確的結果。
6. 實驗
我們收集了五種數位相機,共 4852 筆拍賣資 料。對於每一種相機型號,隨機取出 70%作為訓練 資料,剩下 30%為測試資料,重複五次得到五份訓 練及測試資料集,而每項實驗結果我們將取這五份 資料集的結果平均值。實驗可分成三個部分,第一 部分為預測商品售出的準確度,並探討商品售出機 率與拍賣屬性之間的關係。第二個實驗為使用多個 二元分類器預測結標價的準確度,並比較有無矯正 樣本選擇偏差的預測結果。第三個實驗為比較賣家 使用預測的銷售機率、結標價、及期望結標價做為 銷售建議參考的效能比較。
6.1 預估售出機率的結果
我們使用 SVM 作為預測商品售出與否的分 類器。表 3 為分類的準確率。在直接購買式刊登資 料集中,分類準確率比拍賣式刊登來得低,因為有 些商品即使是擁有相同的拍賣屬性,其拍賣結果還 是會有所不同。較低的商品起標價較易售出是顯而 易見的,這種低起標價策略佔了我們資料集的絕大 多數比例,此時我們對其預測的售出機率值幾乎都 達 90%以上。
表 3 售出預測準確率
為了要了解賣家所使用的高起標價策略與我 們所預測的商品售出機率之間的關係,我們從拍賣 式刊登測試集中,取出起標價高於相似價值商品平 均結標價的資料集合,分析若賣家想設定高起標價 來保證其商品結標價高於相似價值商品的平均結 標價時,會得到怎樣的拍賣結果。圖 3 為 SD600
在拍賣式刊登測試集中2,各預測機率區間下的五 種屬性的統計資料。其中 difference 代表在該預測 機率區間的資料集中,每一個商品的起標價與該相 似價值商品的平均結標價之差值的平均值,換句話 說,若平均差距的值愈大,則代表在該機率區間之 下的商品,其起標價愈高於同價值商品平均結標 價。Feedback Score 代表該機率區間下的賣家的平 均信用評等分數,Sample Size 代表該機率區間下 的資料個數,KitsAmount 代表該機率區間下的平 均配件個數,Precision 則是代表對該機率區間下的 預 測 準 確 度 。 我 們 再 將 Difference 、 Feedback Score、Sample Size 及 KitsAmount 的值正規化至 0~1 區間,代表該機率區間下的值佔總和的多少比 例。
我們可從圖 3 看出 SVM 對高起標價商品預測 的售出機率多偏向於 0 或 1,造成這種極端的結果 取決於 Feedback Score(信用評等)及 KitsAmount
(相機配件個數)的大小。我們對此現象的解釋為 較高信用評等的賣家,較易取得買家的信任,即使 採用高起標價的策略,還是能吸引買家下標;相反 地,若賣家本身的信用評等分數不夠高,則買家會 對此商品有所疑慮。除此之外,相機所搭配的配件 個數愈多則更能吸引買家購買。由此可見,即使使 用相同的銷售策略,不同的賣家或商品狀況可能導 致拍賣結果有所不同,所以單純地模仿他人的銷售 策略是很難複製出相同的商品利潤。
圖 3 在 SD600 拍賣式刊登測試集中,每一個售出 機率區間下價差、評等,配件個數的統計值
圖 4 在 SD600 直接購買式刊登測試集中,每一個 售出機率區間下價差的統計值
圖 5 在 SD600 直接購買式刊登測試集中,每一個 售出機率區間下賣家評等、配件個數等的統計值
2 由於空間的限制,我們僅呈現 SD600 型的結果。
同樣地,為了要了解賣家所使用的直接購買 價策略與我們所預測的商品售出機率之間的關 係,在直接購買式刊登的測試集中,我們也對於每 一預測機率區間的資料集,計算每一個商品的直接 購買價與該相似價值商品的平均結標價之差值的 平均值。若平均差距的值為正,則代表賣家所設定 的直接購買價高於同價值商品平均結標價,若其值 為負,則代表賣家直接購買價低於相似價值商品平 均結標價。我們可由圖 4 可以看出直接購買價與 商品售出機率呈現強烈的負向關係,而圖 5 中的 Feedback Score 及 KitsAmount 在各預測機率區間 並無明顯的差別,這表示若賣家使用直接購買式刊 登商品,要特別注意直接購買價大小的設定。
由上述分析可知,賣家在使用高起標價或高 直接購買價策略時,也應該考慮商品售出的機率, 賣家可透過我們所預測的商品售出機率,衡量所採 用的銷售策略是否符合本身的經營目標,避免不必 要的損失。除此之外,在使用 SVM 預測商品售出 機率時,我們必須做機率矯正的動作,否則在我們 的測試集中,我們所得到的機率值皆等於 0 或 1, 此時就無法得知售出機率與銷售策略之間的關係。
6.2 預估結標價的結果
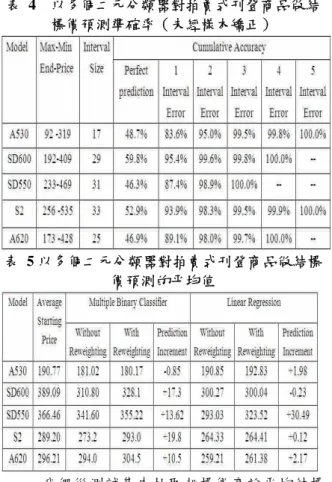
在結標價預測的實驗中,我們抽取訓練資料集 中售出的商品作為預測結標價的訓練資料集,使用 多個二元分類器方法預測結標價。多個二元分類器 須將結標價切割成相同大小的多個區間,在此我們 先移除最大及最小的結標價格,再以平均結標價的 10%作為區間大小來切割多個區間,並在每一個價 格切割點使用 SVM 作為二元分類器,來預測商品 的結標價是否大於此價格。在我們所收集的資料集 中,影響結標價的因素主要在於相機配件的多寡及 記憶體的大小,在眾多配件可供搭配的情況下,造 成即使是同一種數位相機,其價格的差異仍然相當 大,增加結標價預測的困難。表 4 為多個二元分類 器的預測結果,雖然單純預測的準確率並不高,但 至少誤差範圍在一個區間內的比例將近 90%。
由於只選取商品售出的資料作為訓練資料集 將可能產生樣本選擇偏差問題,導致我們將低估因 高起標價而導致售出機率較低的商品結標價。因此 我們使 用 Zadrozny 的 reweighting 方 法來矯正 feature bias。因為在假設 feature bias 的時候,我們 也必須假設 p(x,s=1)>0,即要確保訓練資料集中的 售出商品子資料集必須包含所有訓練資料集中的 屬性空間,且在每一屬性空間下的資料量必須足 夠,所以我們只選取屬性值在售出子資料集 p(x|s=1) 與 全 體 資 料 集 p(x) 分 布 差 異 最 大 的 起 標 價 及 Feedback Score 兩個屬性來預測 p(s=1|x),並進行 售出商品資料集的矯正。我們對於每一相機型號的 五份訓練資料,根據 reweighting 的方法計算出每 一筆資料被選取的權重,使用 rejection sampling 的 方式產生 10 份子資料集,然後以 SVM 建立預測 模型,並以 10 次預測的平均值作為最後的預測值。
表 4 以多個二元分類器對拍賣式刊登商品做結 標價預測準確率(未經樣本矯正)
表 5 以多個二元分類器對拍賣式刊登商品做結標 價預測的平均值
我們從測試集中抽取起標價高於平均結標 價且未售出的商品,比較有無矯正的結標價預測 值。如表 5 所示,當我們使用多個二元分類器預測 結標價時,矯正後的平均預測值大多皆高於未矯正 的預測值,使得預測值更接近於其平均起標價,即 更能接近於商品的真實結標價。同樣地,我們也比 較利用線性廻歸在資料矯正前後的預測值,相對於 多個二元分類器的結果,發現只有對 SD550 測試 集能明顯提高結標價預測值,我們推測其原因為 SD550 資料集擁有較多未售出的商品,所以對以平 均最小化誤差平方的線性迴歸影響較大。表 6 為資 料經過矯正後的多個二元分類器的準確率,我們可 看出資料矯正過後的準確率與未矯正差不多,所以 我們相信透過矯正樣本選擇偏差的動作,我們不僅 可對售出的商品維持相同程度的準確率,又能對未 售出的資料做更精確的預測。
表 6 經樣本矯正後以多個二元分類器對拍賣式刊 登做結標價預測的準確率
6.3 以期望獲利為考量的銷售建議效能 如序論所言,商品售出機率及結標價之間有著 負向關係,因此單純以售出機率或結標價做為考量 的銷售建議可能無法得到較高的利潤。在本篇論文 裡我們提出三種判斷準則,分別對照賣家的不同經 營目標,比較三者所能帶給賣家的利潤。
第一種方法是以銷售機率為考量,當所預測的 商品售出機率大於五成時即建議賣家刊登廣告,因 此相當於以銷售量最大化為目標。第二種方法則是 以結標價為考量,則必須有一個比較標地,如此才 能在預測的結標價大過標地時再建議賣家進行商 品的刊登。在此我們基於比較賣家在拍賣平台上的 獲利差異,做為判斷準則。我們籍由拍賣網站的記 錄得知賣家使用 eBay 所提供的付費服務來輔助拍 賣的進行。這些服務費用的總和代表著賣家花了多 少金錢在 eBay 平台上進行拍賣,所以我們只須得 知商品的結標價 y(x)及其在拍賣平台上銷售某個 商 品 所 付 出 的 成 本 sc(x) , 即 能 比 較 利 潤 高 低 profix(x)=y(x)-sc(x)。以此為出發點為考量,我們 可以在商品利潤大於其他相似商品的平均利潤 時,建議賣家進行商品的刊登。
不過上述的考其實仍有欠周詳,在本篇論文中 我們進一步地以 cost-sensitive learning 的概念結合 售出機率[16],並根據 Cost matrix 來調整對賣家的 建議,以達到整體的最低的花費,幫助我們做最適 當而不是最準確的決策。表 7 為我們所定義的 Cost Matrix,我們建議賣家刊登商品的時機,不僅是考 慮商品售出利潤大於相似價值商品的平均利潤,同 時也考量商品未售出時賣家所蒙受的銷售損失 sc(x)及其他額外的損失 uc。
綜合上述,以售出機率,結標價及期望結標價 三種考量方式建議賣家刊登的判斷準則分別如下:
銷售量最大化目標:當商品的預測售出機率大於百 分之五十,我們即建議賣家刊登。
P(s=1|x) > P(s=0|x)
結標價最大化目標:當商品的預測結標價格大於相 似價值商品的平均結標價時,即建議刊登。
y(x)-sc(x)> AvgY-AvgSC
利潤最大化目標:考慮商品售出機率及結標價,還 有銷售策略的成本,計算出商品的期望利潤。
) )(
| 0 (
)] ( )
( [ )
| 1 (
sc uc X S P
x avgprofit x
profit X
S P
表 7 Cost Matrix
圖 4 及圖 5 為在直接購買式刊登測試集及拍 賣式刊登測試集中,三種建議賣家是否進行銷售的
策略所獲得的平均商品利潤。其中 SellAll 為比較 基準,代表賣家未尋求任何銷售建議直接刊登所有 的商品;SaleAmount Maximization 則是以銷售量最 大化為目標;EndPrice Maximization 代表以結標價 最大化為目標;最後 Profit Maximization 則是以期 望利潤最大化為目標。
我們發現在拍賣式刊登測試集中,使用結標 價最大化目標獲得的利潤較銷售量最大化目標為 高。但在直接購買式刊登測試集中,以直接購買價 大於相似價值商品的平均結標價作為結標價最大 化目標,其利潤則與銷售量最大化目標所獲得的利 潤差不多。然而在直接購買式刊登資料集中,結標 價與售出機率的負向關係相當明顯,採取結標價最 大化目標須承受較多商品未售出的損失,而且若賣 家本身對於商品未售出的損失較大時,結標價最大 化目標的利潤甚至低於銷售量最大化目標。
相較於前面兩種經營目標,利潤最大化目標 獲得的利潤都是最高,因在考慮銷售策略成本的情 況下,能同時兼顧商品售出機率及結標價,確保商 品能夠賣出又能獲取較高的利潤。當未售出損失 uc 增加時,平均利潤皆會增加,這代表使用利潤 最大化目標更能避免商品未售出的損失。
我們同時也可以從圖 7 中比較在拍賣式刊登 測試集中,使用二元模型及多元模型兩種預測方式 所獲得的平均利潤。我們可以看到在矯正商品售出 機率之後,所得到的利潤較高,相同的結果也出現 在圖 4 的直接購買式刊登測試集中。在多元模型 中,經過機率矯正的利潤增加更是明顯,可見在多 個分類類別的情況下,機率偏差的問題較為嚴重, 更有矯正的必要。
圖 7 在直接購買式刊登測試集中,各種經營目標 所獲得的平均商品利潤
圖 8 拍賣式刊登測試集中,以利潤最大化為目 標,分別使用二元模型及多元模型預測所得的平均
利潤
另外從圖 8 我們也可看出矯正樣本選擇偏 差之後,所獲得的平均利潤皆較未矯正來得高。雖 然平均來說,增加的利潤相當有限,但若我們觀察 未售出商品比例最高的 SD550 型號所矯正後的結 果,如表 8 所示,SD550 在矯正之後所得到的利潤 增加量相當多,這是因為對於較多未售出商品的資 料集而言,矯正樣本選擇偏差問題更能避免我們低 估商品的結標價,將高結標價的商品判斷成低結標 價的商品。
相較於二元模型,我們提出的多元模型方法 能獲得更高利潤,不過若僅使用多元模型預測的結 標價來判斷是否大於相似價值商品的平均利潤(賣 出),那麼得到的利潤將小於二元模型。然而,這 個結果牽涉到二元模型售出機率及結標價的預測 準確度,而且結標價的範圍也影響多元模型的效 能,所以我們無法斷定多元模型是否能在所有情況 之下皆優於二元模型。
表 8 使用 reweighting 矯正樣本選擇偏差問題之 後,各種策略下的平均利潤增加量
7. 結論與未來的改進方向
在本篇論文中,我們預測商品售出機率及結 標價,並考慮銷售策略成本,計算出商品的期望利 潤,藉此提供一個新的銷售建議服務。這個服務能 判斷賣家所使用的銷售策略,其利潤是否高於全體 賣家的平均利潤,如此可避免賣家制定不適當的策 略,造成不必要的損失,進而幫助賣家達到利潤最 大化目標。
對於預測機率值偏差問題,我們使用 Platt Scaling 來矯正 SVM 的機率值。透過機率值的矯 正,賣家可以得知真實且準確的商品售出機率,而 非得到非 0 即 1 的機率值。此外,我們也分析銷售 策略與售出機率之間的關係,我們發現當賣家使用 高起標價的策略時,售出機率將與本身信用評等及 相機配件個數有關,說明了單純地模仿他人的銷售 策略不一定能得到相同的結果。若賣家採取高直接 購買價策略時,我們發現如果直接購買價設定的愈 高,那麼售出機率則愈低。在此我們建議賣家在追 求最高結標價的同時,也應注意商品售出機率,避 免商品無法售出的損失。
在結標價預測的議題當中,以往提出的預測 方法都假設商品已售出,只能針對售出的商品做精 確的預測。然而,我們發現如果沒有考慮樣本選擇 偏差問題,將導致我們傾向低估未售出商品的結標 價。在此我們使用 Zadrozny 的 reweighting 方法來
解決樣本選擇偏差問題,從實驗結果可看出,我們 能對未售出的商品做更準確的預測。
使用銷售建議服務達到利潤最大化獲得的利 潤,我們提供的建議服務因為能同時考慮商品售出 機率及結標價,所以得到最多的利潤。我們也發現 Multi-Class Estimation 經過機率值矯正、Two-Class Estimation 經過機率值及樣本選擇偏差矯正後,獲 得的利潤都較未矯正前來得高,代表準確的售出機 率及結標價預測是銷售建議服務不可缺少的。除此 之外,我們也更進一步比較兩種預測期望結標價的 方法,我們發現 Multi-Class Estimation 的獲利能力 比 Two-Class Estimation 來得高,然而,我們認為 這兩種方法的優劣,與該商品的結標價大小範圍及 售出機率、結標價預測的準確度有關。
未來研究方向,我們認為賣家不僅只想預測 商品的拍賣結果,更希望能提供最大利潤的銷售策 略。在最大利潤的銷售策略議題中,我們認為將高 利潤商品資料集中,學習關聯規則是一個不錯的解 決方法。此外,文字描述對拍賣結果存在著重大的 影響,自動擷取商品的重要關鍵字或是句子做為預 測屬性可以當未來研究方向,並提供賣家作為撰寫 商品描述的參考。另外 商品的拍賣屬性及拍賣結 果有可能會隨著時間而改變,例如 3C 商品。可將 拍賣資料視為時間序列資料,使用 Stream Mining 的技術解決屬性值分布會隨著時間而改變的問題。
參考文獻
[1] Ayer, M., Brunk, H., Ewing, G., Reid, W., & Silverman, E. “An empirical distribution function for sampling with incomplete information”. Annals of Mathematical Statistics, 1955, pp. 641–647.
[2] D.G. Gregg and S. Walczak, “Auction advisor: an agent-based online auction decision Support System”, Decision Support Systems, Vol. 41, Issue 2, 2006, pp. 449–471.
[3] Feelders, A. J. “An overview of model based reject inference for credit scoring”. Technical report, Utrecht University, Institute for Information and Computing Sciences, (unpublished).
[4] Ghani, R. and Simmons, H. “Predicting the end-price of online auctions”. In the
Proceedings of the International Workshop on Data Mining and Adaptive Modelling Methods for Economics and Management, Pisa, Italy, 2004.
[5] Heijst, D. van, Potharst, R., Wezel, M. van.
“A Support System for Predicting eBay End Prices”, Decision Support System, Vol. 44, Issue 4, March 2008, pp. 970-982.
[6] Hastie and R. Tibshirani. “Classification by pairwise coupling”. The Annals of Statistics, Vol. 26, No. 2, 1998, pp. 451-471.
[7] Heckman, J. “Sample selection bias as a specification error.Econometrica”, 47, 1979,
pp. 153–161
[8] http://www.terapeak.com/ [9] http://www.hammertap.com/
[10] Little, R. J. A. and Rubin, D. B. Statistical analysis with missing data. John Wiley & Sons, Inc., New York, NY, USA, second edition, 1986.
[11] Platt, J. “Probabilistic outputs for support vector machines and comparison to regularized likelihood methods”. Advances in Large Margin Classifiers, 1999, pp. 61–74.
[12] Smith, A. and Elkan, C. “A bayesian network framework for reject inference. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining”, 2004, pp. 286–295.
[13] W. Fan, and I. Davidson, “On Sample Selection Bias and Its Efficient Correction via Model Averaging and Unlabeled Examples”. In Proceedings of the SIAM International
Conference on Data Mining, 2007, pp. 320-331.
[14] Wang, S., Jank, W., and Shmueli, G.
“Forecasting eBay’s online auction price using functional data analysis”, Journal of Business and Economic Statistics, 2006.
[15] Wood, C.A. “Current and future insights from online auctions: A research framework of selected articles in online auctions”, Handbook on Electronic Commerce, M. Shaw, R. Blanning, T. Strader and A.B. Whinston (eds.), Springer-Verlag, 2004, pp. 130-141.
[16] Zadrozny, B and Elkan, C. “Learning and making decisions when costs and probabilities are both unknown”. In Proceedings of the Seventh ACM International Conference on Knowledge Discovery and Data Mining (SIGKDD), 2001, pp. 204-213.
[17] Zadrozny, B. and Elkan, C. “Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers”. In Proceedings of the Eighteenth International Conference on Machine Learning, pages 609-616. Morgan Kaufmann Publishers, Inc., 2001.
[18] Zadrozny, B. and Elkan, C. “Transforming classifier scores into accurate multiclass probability estimates”. SIGKDD, 2002, pp. 204-213.
[19] Zadrozny, B., Langford, J. and Abe, N.
“Cost-Sensitive learning by cost-proportionate example weighting”. Proceedings of the Third IEEE International Conference on Data Mining. 2003, pp.435-442.
[20] Zadrozny, B. “Learning and evaluating classifiers under sample selection bias”. In Proceedings of the 21th International Conference on Machine Learning, Vol. 69, 2004, pp.144-151.