Introducing ScaleGraph : An X10
Library for Billion Scale Graph Analytics
Miyuru Dayarathna
Tokyo Institute of Technology, Japan dayarathna.m.aa@m.titech.ac.jp
Charuwat Houngkaew
Tokyo Institute of Technology, Japan houngkaew.c.aa@m.titech.ac.jp
Toyotaro Suzumura
Tokyo Institute of Technology/IBM Research - Tokyo, Japan suzumura@cs.titech.ac.jp
Abstract
Highly Productive Computing Systems (HPCS) and PGAS lan- guages are considered as important ways in achieving the exascale computational capabilities. Most of the current large graph pro- cessing applications are custom developed using non-HPCS/PGAS techniques such as MPI, MapReduce. This paper introduces Scale- Graph, an X10 library targeting billion scale graph analysis scenar- ios. Compared to non-PGAS alternatives, ScaleGraph defines con- crete, simple abstractions for representing massive graphs. We have designed ScaleGraph from ground up considering graph structural property analysis, graph clustering and community detection. We describe the design of the library and provide some initial perfor- mance evaluation results of the library using a twitter graph with 1.47 billion edges.
Categories and Subject Descriptors D.2.11 [Software Architec- tures]: Data abstraction, Languages
General Terms Design, Performance, Languages, Algorithms, Standardization
Keywords X10, PGAS, HPCS, large graph analytics, reusable libraries, programming techniques, distributed computing
1. Introduction
Recently numerous applications in a wide variety of domains have started producing massive graphs with billions of vertices/edges. Increasingly such large graph data are found in the form of social networks, web link graphs, Internet topology graphs, etc. Mining these graphs to find deep insights require middleware and software libraries that could harness the full potential of large scale comput- ing infrastructures such as super computers. Most of these middle- ware/libraries has been developed using C/C++/Java programming languages following programming models such as MPI, MapRe- duce, and Bulk Synchronous Message Passing.
Developing techniques to manage and reduce software com- plexity of system software is an utmost challenge that needs to be addressed, when we scale from petascale to exascale systems. Use of PGAS languages such as UPC, X10, and Chapel are con- sidered as an avenue for achieving Highly Productive Computing
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee.
X10 Workshop 2012 June 14, 2012, Beijing, China. Copyright c 2012 ACM [to be supplied]. . . $10.00
Systems. PGAS languages provide an easy means of programming distributed-memory machines. While there have been comprehen- sive libraries developed in other programming languages for large graph analysis, such support is rare in current PGAS implementa- tions. APIs for exposing fine grain/dynamic parallelism has become an important aspect in achieving exascale computing systems. X10 is a new object-oriented language designed to support productive programming of multi-core and multi-node computers. Compared to its peer PGAS languages such as UPC, the main focus of X10 is improvement of HPC programmer productivity. X10 is driven by the motto “Performance and Productivity at Scale” which clearly resembles the aforementioned fact. Since X10 is a new language for HPC community, we believe a lot of support in terms of com- prehensive application libraries need to be developed to support the language to achieve it’s productivity goals. The object oriented na- ture of X10 makes it possible for modeling such extensible class libraries [36].
Considering this important requirement we have started imple- menting an X10 graph processing library that supports billion scale graph processing tasks. Our ultimate goal is to create a compre- hensive X10 Graph processing library with support for significant amount of graph algorithms including algorithms for calculating graph structural properties, clustering, community detection, pat- tern matching, etc. The library is intended for graphs with billions of vertices. In our library, a graph is represented by a concrete ab- straction called “Graph” and we model different graph categories such as graphs with vertex/edge attributes (i.e., attributed graphs), graphs without vertices/edges (i.e., plain graphs) by implement- ing the Graph interface. Our graph representation model is scal- able based on the number of “Places” available for the application. In the current version of the library we have implemented degree distribution and betweenness centrality calculation algorithms. We compare performance of calculating Betweenness Centrality (BC) of our library against X10 BC implementation and report the per- formance results. The contribution of this paper is the establishment of the baseline architecture of ScaleGraph library.
The paper is organized as follows. Related work of the paper are described in the Section 2. We provide an overview of the X10 language under the Section 3. The design of the library is described in the Section 4. Next we provide implementation details under the Section 5. The evaluation is described in Section 6. We provide a discussion and list the limitation of the library under the Section 7. The paper is concluded in Section 8.
2. Related Work
Construction of graph processing libraries with support for variety of graph algorithms has been a widely studied area. One of the fa- mous examples for such graph libraries is igraph [15]. It has been
heavily used by complex network analysis community. Igraph has support for classic graph theory problems such as Minimum Span- ning Trees, and Network Flow. Core of the igraph has been written in C. There are two extensions for igraph, one in R and another in Python. Lee et al. created Generic Graph Component Library (GGCL) [31] which is a library built on C++ STL. Graph algo- rithms on GGCL do not depend on the data structures on which they operate. Stanford Network Analysis Package (SNAP) [32] is a general purpose network analysis and graph mining library de- veloped by Leskovec et al.. Current version of SNAP (version 2011-13-31) supports maximum 250 million vertices and 2 bil- lion edges [32]. The library calculates structural properties, gen- erates regular and random graphs. Similar to ScaleGraph, SNAP supports attributes on nodes and edges and has been used to an- alyze large graphs with millions of nodes and billions of edges. However compared to ScaleGraph, one of the major limitation of all the above mentioned libraries is that they are made to run on workstations, hence even at maximum scale only some of them can analyze graphs with few billion edges.
Boost Graph Library (BGL) is a C++ STL library for graph processing [20][6]. Part of the BGL is a generic graph interface that allows access to the graph’s structure while hiding the details of the implementation. A parallel version of the library (PBGL) [21] has been developed using MPI. However if the user is not well versed in use of C++ and STL, the learning curve of the BGL becomes very steep [30]. Hence BGL and PBGL might not be an acceptable solution for application programmers at large. Note that by using the term “Application Programmer” we represent not only high-end parallel application programmers but also application programmers on next generation systems such as SMP-on-a-chip and tightly coupled Blade servers [27]. ParGraph [24] is a generic parallel graph library which is comparable to PBGL. ParGraph is written in C++ and it has similar syntax to PBGL. Different from BGL, PBGL, and ParGraph; ScaleGraph requires less amount of code for specifying a graph computation requiring lesser programming effort. In contrast to ScaleGraph; BGL, and PBGL do not support vertex and edge attributes.
Standard Template Adaptive Parallel Library (STAPL) [2] is a generic library with similar functionality to Boost. STAPL targets scientific and Numerical applications, also intended for exploiting parallelism for graph algorithms. However like Boost libraries, STAPL does not define broadly applicable abstractions for graphs [40].
JUNG (Java Universal Network/Graph) is a comprehensive open-source graph library [43][39]. It supports variety of repre- sentations of graphs such as directed and undirected graphs, multi- modal graphs, hypergraphs and graphs with parallel edges (i.e., multi-edges). Since JUNG has been developed using Java, it of- fers the interoperability with rich third party libraries written in Java. Current distribution of JUNG includes a number of graph al- gorithms related to data mining and social network analysis [43]. Current version of JUNG does not support distributed implementa- tion of algorithms which is a limitation in applying it to distributed graph processing scenarios.
Combinatorial BLAS is a high-performance software library written in C++/MPI for graph analysis and data mining [10]. Knowledge Discovery Toolkit (KDT) which is a Python graph analysis package has been introduced recently utilizing Combi- natorial BLAS as the underlying graph processing infrastructure [33]. Compared to them, our library is completely written in X10 which is a PGAS language aimed for productive programming on multi-core, multi-node systems.
While there has been large scale graph algorithm implementa- tion on main stream parallel architectures such as distributed mem- ory machines; there are some other studies focusing on specific ma-
chine architectures which are currently less popular. Examples in- clude the works by Madduri et al. [34], Bader et al. [4][18], and Berry et al. (Multi Threaded Graph Library) [7]; which describe the ability of using massively multithreaded machines to implement graph algorithms. While distributed memory application develop- ers focus on maximization of locality to minimize interprocess communication, program developers for massively multithreaded machines having large shared memory (e.g., Cray MTA-2) do not focus on locality or data exchange [35]. Some of the works of this domain (E.g., Multi Threaded Graph Library) have been extended to commodity processors yet with lesser performance [5]. Different from them, in our work we concentrate on productivity of specify- ing graph computations in distributed settings while maintaining scalability aspects in commodity machines ranging from developer laptops to super computers.
There have been prior work on specifying graph computations on X10. Cong et al. worked on creating fast implementations of irregular graph problems on X10 [14][13]. They also worked on creating an X10 Work Stealing framework (XWS) with the aim of solving the problem of present software systems not support irregu- lar parallelism well. However both these works do not focus on cre- ating a Graph API with well-defined abstractions for representing graphs. In this paper we emphasize creation of such library since we believe this will support X10 application developers to directly use the support provided by the library for graph computations.
While our work is creating a large graph analysis library on the domain of PGAS languages, Pregel [35] is a computational model for analyzing large graphs with billions of vertices and trillions of edges. Pregel focuses on building a scalable and fault tolerant platform with an API that is flexible in expressing arbitrary graph algorithms using vertex centric computations. Similar to PBGL, Pregel’s C++ API requires more programming effort compared to ScaleGraph’s API which is also targeted for users outside the HPC domain.
Kulkarni et al. describe that concurrency should be packaged, when possible, within syntactic constructs that makes it easy for programmer to express what might be done in parallel, and for the compiler and runtime system to determine what should be done in parallel [28]. ScaleGraph follows the same concept and tries to introduce well defined abstractions for massive graph analysis scenarios.
3. X10 - An Overview
We provide an overview of X10 and briefly describe the lan- guage constructs which have been used to develop ScaleGraph below. More information on X10 language syntax is available from X10 language specification [25] and from X10 web site http://x10-lang.org.
X10 is an experimental PGAS (Partitioned Global Address Space) [44] language currently being developed by IBM Research in collaboration with academic partners [26][12]. The project started in 2004, and tries to address the need for providing a pro- gramming model that can with stand architectural challenges posed by multiple cores, hardware accelerators, cluster, and supercomput- ers. The main role of X10 is to simplify the programming model in such a way that it leads to increase in programming productivity for future systems [27] such as Extreme Scale computing systems [17]. X10 has been developed from the beginning with the motivation of supporting hundreds of thousands of application programmers and scientists with providing ease of writing HPC code [12]. Previ- ous programming models use two separate levels of abstraction for shared-memory thread-level parallelism (e.g., pthreads, Java threads, OpenMP) and distributed-memory communication (e.g., JMS, RMI, MPI) which results in considerable complexity when trying to create programs that follow both the approaches [1]. X10
addresses this problem by introducing the notion of Places. Every activity in X10 runs in a place which is collection of non-migrating mutable data objects and the activities (similar to threads) that operate on the data [1]. Therefore the notion of Places includes both shared-memory thread level parallelism as well as distributed- memory communication which makes the life of the programmer easier. Supporting both concurrency and distribution has been the first class concerns of the programming language’s design [22]. X10 is available freely under opensource license.
X10 is a strongly typed, object-oriented language which em- phasizes static type-checking and static expression of program in- variants. The choice of static expression supports the motivation of improving programmer productivity and performance. X10 stan- dard libraries are designed to support applications to extend and customized their functionality which is a supporting factor for X10 library developers.
The latest major release of X10 is X10 2.2 and it has been constructed via source-to-source compilation to either C++ or Java [22]. The C++/Java language specific tools are then used to compile the translated code to platform specific versions. In the case of C++ a platform C++ compiler is used to create an executable. In the case of Java, compiled class files from a Java compiler are ran on a JVM. These two methods of X10 language implementations are termed as Native X10 and Managed X10 [22]. When designing ScaleGraph we are more interested of performance rather than portability advantages provided by Java, hence current version of the ScaleGraph library has been developed targeting the Native X10. Furthermore by choosing Native X10, we get the advantage of the fact that we are able to integrate many scientific libraries which are typically available via C APIs [22].
X10 programmers can write code that get compiled and run on GPUs [16]. The Native X10 has been extended to recognize the language constructs of CUDA code and produce corresponding kernel code. Current version of our library does not use the GPU programming features available with X10.
One of the fundamental language constructs of X10 is Place. A place in X10 corresponds to a processing element with attached local storage [36]. A place can also be viewed as an address space [22]. Asynchronous activities (i.e., async) work as a single abstrac- tion for supporting a wide range of concurrency constructs such as threads, message passing, direct memory access, streaming, data prefetching [25]. Activities specify logical parallelism using struc- tured and unstructured constructs such as ateach, async, and future. Throughout its lifetime, an activity executes at the place where it got spawned and has access only to the data stored at that place. An activity may spawn new remote activities which get executed asynchronously at remote places using at. Termination detection of such spawned activities can be done using finish. Activities can be coordinated using clocks and lock free synchronization atomic.
We use distributed arrays (DistArray) in creating the graph abstractions. Every element in a distributed array is assigned to a particular place by following the array’s distribution. X10 uses an annotation system to allow the compiler to be extended to new static analyses and new transformations [25]. Annotations are created by an “@” followed by an interface type. X10 provides full interoperability with C++ and Java through @Native(lang,- code) annotation on classes, methods and blocks [36]. We use
@Native(lang,code) annotation for implementing certain C++ language specific functions which are not currently supported by X10. For example, directory listing is currently not supported by X10. As a solution, we developed an X10 class and linked it to a C++ code that does directory listing. X10 has a special struct type called GlobalRef which is a global reference to an object at one place that might be passed to a different place. We use GolbalRef as a support for coordinating activities between different places.
4. Library Design
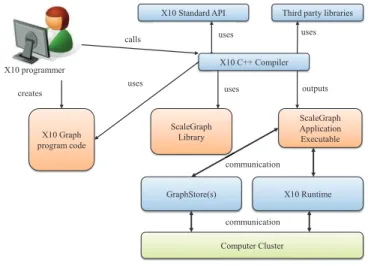
ScaleGraph library has been designed from ground-up with the aim of defining solid abstractions for billion scale graph processing. Architecture of ScaleGraph is shown in Figure 1. X10 application programmers can utilize our library to write graph applications for Native X10. ScaleGraph library depends on third party C++ libraries such as Xerces-C++ XML Parser [41].
ScaleGraph Application Executable
X10 Runtime
Computer Cluster X10 programmer
X10 Graph program code
GraphStore(s) X10 Standard API
X10 C++ Compiler
Third party libraries
ScaleGraph Library calls
uses
uses uses
outputs uses
communication
communication creates
Figure 1. ScaleGraph Architecture.
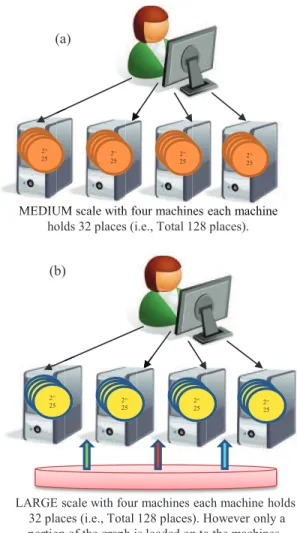
X10 applications which use ScaleGraph can be written to operate in three different scales called SMALL, MEDIUM and LARGE. The SMALL scale represents a graph application that runs on a single Place (Lets take the maximum supported graph size as 2n (n : n> 0, n ∈ N). We created this configuration to support complex network analysis community at large, who might be interested of using our library in single machine settings. If an application which uses the library in SMALL scale is run in multi- ple places, the graph will be stored in the place designated by home (i.e., Place 0).
The second configuration type is MEDIUM scale in which the number of vertices stored in one place is 2m(m : m> n, m ∈ N), however the total graph size equals to (2m∗numberof P laces). For example, when the application is developed for MEDIUM scale size with m=25 and is run on 32 places, the application can handle graphs up to 230(i.e., ≈ 1 billion) vertices (As shown in Figure 2 (a)).
The third category of applications is the LARGE scale (shown in Figure 2 (b)). This category has been created to support scenarios where the end user does not have enough compute resources to instantiate sufficient amount of places to hold billion scale graphs. This type of application scenarios will be frequent for users with small compute clusters with limited RAM or even in resource full compute clusters such as supercomputers when the processed graph need to be persisted on disks.
We have introduced such three scales of operations due to re- source availability and performance trade offs present in many graph analysis applications. While the library scales well with in- creasing numbers of machines, one cannot expect it to process a very large graph that could not be kept on a single laptop’s mem- ory. We believe the three scales of operation modes leads to a more simpler yet robust architecture of ScaleGraph.
The library has been modeled entirely using object oriented software design techniques. Current design of the library contains six main categories; graph, I/O, generators, metrics, clustering, and communities. Package structure of ScaleGraph is shown in Figure 3.
MEDIUM scale with four machines each machine holds 32 places (i.e., Total 128 places). MEDIUM
2^ 24 2^24 2^
24 2^ 25
UM scale with UM sca
2^ 24 2^24 2^
24 2^25
h four machine h four m
2^ 24 2^24 2^
24 2^25
nes each machine nes each
2^ 24 2^24 2^
24 2^25
2^ 24
LARGE scale with four machines each machine holds 32 places (i.e., Total 128 places). However only a
portion of the graph is loaded on to the machines.
2^ 24 2^24 2^
25
2^ 24 2^24 2^
24 2^25
2^ 24 2^24 2^
24 2^25
2^ 24 2^24 2^
24 2^25
(a)
(b)
Figure 2. Medium scale and Large Scale Configurations of Scale- Graph.
The graph package holds all the classes related to graph rep- resentation. All the graphs of ScaleGraph implement a single in- terface called Graph. ScaleGraph separates graph representation from rest of the algorithms. A Graph in ScaleGraph is just a data structure and it has no associated operations implementing specific analysis algorithms (E.g., degree, pagerank, centrality, etc.,). Graph algorithms are coded in separate classes. Currently we have devel- oped two types of Graph classes named PlainGraph and Attributed- Graph. The PlainGraph is used to store non-attributed graphs (i.e., Graphs without attributes for both vertices and edges) while At- tributedGraphs can store attributes on both vertices and edges.
graph graph
io
generator clustering
sort spantree
subgraph util
communities metrics org
scalegraph
isomorphism layout
Figure 3. Package structure of ScaleGraph.
val attrArray:ArrayList[Attribute] = null;
schema: AttributeSchema = new AttributeSchema(); schema.add("fname",
AttributeSchema.StringAttribute); schema.add("email_add",
AttributeSchema.StringAttribute); schema.add("age", AttributeSchema.IntAttribute);
attrArray = new ArrayList[Attribute]();
attrArray.add(new StringAttribute("fname", "Alice")); attrArray.add(new StringAttribute("email_add",
"alice@gmail.com")); v0:Vertex = new Vertex(attrArray);
attrArray = new ArrayList[Attribute]();
attrArray.add(new StringAttribute("fname", "Bob")); attrArray.add(new StringAttribute("email_add",
"bob@gmail.com")); v1:Vertex = new Vertex(attrArray);
g: AttributedGraph = AttributedGraph.make(); g.setVertexAttributeSchema(schema); g.addVertex(v0);
g.addVertex(v1);
schema: AttributeSchema = new AttributeSchema(); schema.add("title", AttributeSchema.DateAttribute); schema.add("dtime", AttributeSchema.DateAttribute); g.setEdgeAttributeSchema(schema);
attrArray = new ArrayList[Attribute]();
attrArray.add(new StringAttribute("title", "Meeting")); attrArray.add(new DateAttribute(2012,2,10)); e0: Edge = new Edge(v0,v1, attrArray);
g.addEdge(e0);
Alice
Bob
alice@gmail.com
bob@gmail.com
Figure 4. An example code for creating AttributedGraph.
We use an adjacency list representation of graph data in our Graph interface. In most of the real world graphs are sparse graphs which can be efficiently represented using an adjacency list com- pared to an adjacency matrix. While adjacency matrices provides a marginal advantage over adjacency lists for memory utilization for representing big graphs, and less time for edge insertion and deletion, it is well recognized fact that adjacency lists are better for most applications of graphs [42].
ScaleGraph contains a set of classes for reading and writing graph files located under org.scalegraph.io. All the readers im- plement Reader interface while all the writers implement Writer in- terface both of which are located on org.scalegraph.io. There are many different types of graph file formats used by complex network research community. Out of them we support some fre- quently used file formats for attributed graphs such as GML, GEXF, GraphML, CSV, GDF, and GraphViz. For non-attributed graphs we support popular formats such as edgelist, CSV, DIMACS, LGL, and Pajek. Certain file formats have more then single file reader/writer classes. An example is ScatteredEdgeListReader which reads a
Source Vertex ID Attribute
Values Edge ID
0 1
attributeNameID Map attributeIDName Map
attributeNameID Map attributeIDName Map
VertexEdge
Array of edges Array of edge attributes
i Place ID
. . .
Edge to attribute map
Vertex ID In Edge IDs
Out Edge IDs Vertex
Records
Edge ID
Destination Vertex ID Edge Records
Array of vertices Array of vertex attributes
Vertex to attribute map
0 . . . i Place ID
Vertex records Neighbor vertex IDs of A(i,j)
Array of vertex records
0 . . . i Place ID
Array of vertex records
Source vertices
Destination vertices
Neighbor vertex IDs of B(i,j)
A(i,P)
A(i,j)
A(i,0)
…
Vertex records
B(i,P)
B(i,j) B(i,0)
…
E(i,P)
E(i,j) E(i,0)
… V(i,P)
V(i,j) V(i,0)
0 . . . i Place ID
Array of unique vertices
(a) (b)
M : Total supported vertices N : Number of Places
P : Vertices per Place (P=(M/N)) i : Place ID (N > i ≥ 0) P > j ≥ 0
…
Attribute Values Vertex ID
Figure 5. Internal data representation of PlainGraph and AttributedGraph.
collection of files created by partitioning an edgelist file in small pieces.
The generators package includes a collection of graph genera- tors. We have already implemented an RMAT [11] generator and are working on other generators such as BarabasiAlbertGenerator, CitationgraphGenerator, ErdosRenyiGenerator, etc.
ScaleGraph contains a set of classes for obtaining the struc- tural properties of graphs. Current version of ScaleGraph has im- plemented BetweenessCentrality and Degree distribution calcula- tion. The planned other metrics include diameter, pagerank, den- sity, complexity, cliques, KCores, Mincut, connected component, etc. We have started working on clustering and communities pack- ages.
Currently the main interfaces of ScaleGraph include Graph, Reader and Writer interfaces which are described above.
5. Implementation
In this section we describe how the users of our library can uti- lize the library for their purposes. We focus on the main two graph representations available in our library, PlainGraph and Attributed- Graph.
5.1 Graph Representations 5.1.1 AttributedGraph
Figure 4 shows a sample code of creating an AttributedGraph to represent an email graph scenario. AttributedGraph is composed of Vertex, Edge, and Attribute objects and it has predefined schemas for vertices, and edges. Use of the term “schema” is analogous to relation schema in databases. The vertex, and edge schemas are fixed for the rest of the life cycle of the graph. Defining of such fixed schema allows us to eliminate subsequent requests to add elements with different attribute schemas. Compared to many graph libraries we described in Section 2, ScaleGraph supports both vertex and edge attributes. As can be observed from Figure 4, each Vertex and Edge of the Graph can be represented as objects which is an advantage in modeling real world scenarios. However the information of these objects are not stored as objects to avoid the performance penalties such as excessive memory use.
Internal data representation of AttributedGraph is shown in Fig- ure 5 (a). Vertex ids, and vertex attribute values are stored in two separate DistArrays which spans in all the places. A separate Ver- tex to Attribute map DistArray is created to make the link between the vertex ids and vertex attributes. A similar storage structure is
used for storing edges, their attribute values, and the mapping in- formation of edges to their attributes.
There are small HashMaps located at 0thPlace called attribu- teNameIDMap and attributeIDNameMap which map the attribute ids to their names. These two HashMaps are used during Attribute object reconstruction to identify the attribute names, since only the attribute ids are stored in the DistArray of vertex/edge attributes to reduce memory utilization. If there are N places, and M total supported vertices (i.e., maximum M vertices can be stored in the graph) each place will hold P=(M/N) vertices as marked in Fig- ures 5 (a) by V(i,0)to V(i,P ). Each Vertex/Edge in the DistArrays are represented by VertexRecord and EdgeRecord objects. Ver- texRecord object holds VertexID, a list of In Edge IDs, and Out Edge IDs. EdgeRecord object holds Edge ID, Source Vertex IDs, and Destination Vertex IDs. Such storage structure provides us fast access to vertex/edge information since the vertices/edges are in- dexed by the array index value. This design allows us to store much larger graphs in memory compared to different other approaches such as keeping the same graph data set in every place.
5.1.2 PlainGraph
An example code of use of PlainGraph for calculating the Degree distribution is shown in Figure 6 (a). Degree (i.e., Degree Central- ity) of a network represents the degree of its each vertex [37]. It is a widely used metric of graphs which we believe is a very important measure that ScaleGraph should support.
Similar to AttributedGraph, PlainGraph has its own (yet sim- pler) internal data structures to store vertices and edges (shown in Figure 5 (b)). There are three DistArrays of Long called Source Vertices, Destination Vertices, and Unique vertices. For each ver- tices A and B (A6=B), an edge A to B (A→B) adds A, and B to source vertices DistArray and B as a neighbor vertex of A. Also it adds A, and B to Destination vertices DistArray and A as a neigh- bor vertex of B. This type of storage structure enables us to ob- tain fast access to both in-neighbours and out-neighbours. The third DistArray is used for keeping the list of unique vertices. This array is relatively small compared to the Source vertices and Destina- tion vertices DistArrays. That is because Unique Vertices DistArray stores only the existing vertices of the graph while other two arrays keep additional space for adding vertices during the application’s operation (i.e., they can store up to M vertices).
//create a Reader object to load graph data from //secondary storage
var reader:ScatteredEdgeListReader = new ScatteredEdgeListReader();
var graph:PlainGraph = null;
//Load the whole graph from secondary storage //to memory
graph = reader.loadFromDir("/data/scattered_twitter");
//Create a Degree object to calculated graph degree var deg:Degree = new Degree();
//Calculate the degree distribution of the graph var result:HashMap[Long, Long] =
deg.getInOutDegree(graph);
var graph: AttributedGraph;
//Load the graph data from secondary storage graph =
GMLReader.loadFromFile("/data/power_grid.gml");
//Run the Betweeness Centrality calculation val result = BetweennessCentrality.run(graph, false);
(a)
(b)
Figure 6. An example code for obtaining graph metrics.
5.2 Graph Metrics
5.2.1 Degree Distribution Calculation
Degree distribution is one of the widely studied properties of a graph [23]. Degree of a vertex in a graph is the number of edges connected to it [38]. If one denotes degree by k, then the degree distribution can be represented by pk. Two types of degree distri- butions can be calculated for directed graphs such as world wide web graph, citation networks called in-degree and out-degree dis- tributions. In the context of a web graph, in-degree of a vertex V is the number of vertices that links to V. Out-degree of V is the num- ber vertices that V links to [38]. ScaleGraph supports calculation of both in-degree, out-degree for directed graphs. In ScaleGraph a boolean flag has been used to determine the directedness of a graph. If the flag is set to true, the graph is treated as a directed graph. 5.2.2 Betweenness Centrality
Betweenness centrality (BC) [3][19] is a graph metric which mea- sures the extent to which a vertex lies on paths between other ver- tices [37]. It is one of the most frequently employed metrics in so- cial network analysis [8]. We can define BC of a general network as follows. Let nistbe the number of geodesic paths (i.e., shortest paths) from s to t that pass through i (s,t, and i are vertices of the graph, s6=t6=i). Lets denote the total number of geodesic paths from s to t as gst. Then the BC of vertex i (i.e., xi) is given by,
xi=
X
st
nist/gst (1)
We implement a more efficient version of BC introduced by Brandes [8]. For a graph with n vertices and m edges this algo-
finish {
val distVertexList:DistArray[Long] = this.plainGraph.getVertexList();
val localVertices : Array[Long]{self.rank == 1} = distVertexList.getLocalPortion();
val numLocalVertices: Int = localVertices.size; val numThreads = Runtime.NTHREADS; val chunkSize = numLocalVertices / numThreads; val remainder = numLocalVertices % numThreads;
var startIndex: Int = 0;
for(threadId in 0..(numThreads -1 )) {
async doBfsOnPlainGraph(threadId, numThreads, localVertices); }
}
// If undirected graph divide by 2 if(this.plainGraph.isDirected() == false) { if(this.isNormalize) {
// Undirected and normalize
betweennessScore.map(betweennessScore, (a: Double) => a / (((numVertex - 1) * (numVertex - 2))) );
} else {
// Undirected only
betweennessScore.map(betweennessScore, (a: Double) => a / 2 ); }
} else {
if(this.isNormalize) { // Directed and normalize
betweennessScore.map(betweennessScore, (a: Double) => a / ((numVertex -1) * (numVertex - 2)) );
} }
Team.WORLD.allreduce(here.id, betweennessScore, 0, betweennessScore, 0, betweennessScore.size, Team.ADD); }
Figure 7. A code snippet of BC calculation on PlainGraph.
rithm require O(n+m) space. The algorithm runs in O(nm) and O(nm+n2log n) time on unweighted and weighted graphs, respec- tively [8]. Brandes algorithm uses a Breadth-first search (BFS) from each vertex to find the frontiers and all shortest paths from that source. Then it backtracks through the frontiers to update sum of importance values of each vertex [33]. However it should be noted that in the case of AttributedGraph we use Dijkstra’s algo- rithm instead of BFS in order to account for edge weights.
Calculation of Betweeneness Centrality of an AttributedGraph is shown in Figure 6 (b). We have implemented GML reader to load graphs in GML format [9] to ScaleGraph. The results from the algorithm is an Array of Pairs (i.e., Array[Pair[Vertex, Double]]). A code snippet of our BC implementation on Plain- Graph is shown in Figure 7.
6. Evaluation
We evaluate the execution performance of Degree distribution calculation and Betweenness Centrality calculation algorithms on PlainGraph. All the evaluations of ScaleGraph has been con- ducted on Tsubame 2.0 on 4 machines. Each machine has 2 Intel XeonR X5670 @2.93GHz CPUs each with 6 cores (total 12R cores per machine/24 hardware threads). Each machine has 54GB memory and 120GB SSD and were connected with a GPFS file system for data storage. Each machine runs on SUSE Linux Enter- prise Server 11 SP1. We used latest X10 release version, X10.2.2.2.
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
1 2 4 8
Elapsed Time (s) Thousands
Number of nodes
Elapsed time of BC for ScaleGraph on multiple nodes
8 12 15 16 18 20 RMAT Graph Scale
0 5 10 15 20 25 30 35 40 45
1 2 4 8
Elapsed Time (s)
Number of nodes
Elapsed time of BC for ScaleGraph on multiple nodes
8 12 15 16 RMAT Graph Scale
0 10 20 30 40 50 60 70 80 90
0 2 4 6 8 10
Elapsed Time (s)
Number of nodes
Elapsed time for X10 BC on multiple nodes
8 12 15 16 18 20
0 0.2 0.4 0.6 0.8 1 1.2 1.4
0 1 2 3 4 5 6 7 8 9
Elapsed Time (s)
Number of nodes
Elapsed time for X10 BC on multiple nodes
8 12 15 16 RMAT
Graph Scale
RMAT Graph Scale
(a) (b)
(c) (d)
Figure 8. Elapsed time for running BC on ScaleGraph and on X10 BC implementation.
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
6 8 10 12 14 16 18 20 22
Elapsed Time (s) Thousands
RMAT Graph Scale
Elapsed time of BC for Scalegraph on single place
Figure 9. Elapsed time for running Betweeness Centrality on ScaleGraph.
The X10 distribution was built to use MPI runtime and was built with maximumly optimized versions of the class libraries by pro- viding -DNO CHECKS=true -Doptimize=true squeakyclean as arguments. We set X10 STATIC THREADS environment variable to 22. This allows us to avoid test applications generating excessive amounts of threads.
We used the KAIST Twitter data set [29] which has 41.7 million user profiles which are represented as follower (A)/followee (B) relationship. The graph contains 1.47 billion edges of the form A
→B. We scattered the data file (11GB on GPFS) in to 5454 files
0 1 2 3 4 5 6 7 8 9
6 8 10 12 14 16 18 20 22
Elapsed Time (s)
RMAT Graph Scale
Elapsed time of In/Out Degree Calculation on Single Node
Figure 10. Elapsed time for calculating in/out degree of RMAT graphs.
each of size 2MB and used the ScatteredEdgeListReader class to load the scattered data files. This approach allowed us to load the graph data into the PlainGraph’s data structures faster than using the EdgeListReader class of ScaleGraph which reads only a single file. However, a drawback of this method is that, since we used Linux’s split command with specific file size (2MB), it cuts the original file exactly in 2MB size which resulted in loss of few edges from the loaded graph since we had to discard beginning/ending lines of certain small files. We hope to eliminate this problem in future versions of ScaleGraph. Furthermore we used RMAT Graphs
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16
6 8 10 12 14 16 18 20 22
Elapsed Time per Vertex (ms)
RMAT Graph Scale
Elapsed time of In/out degree calculation per vertex
Figure 11. Elapsed time for calculating in/out degree (shown in elapsed time per vertex).
[11] of scales 8, 12, 15, 16, 18, and 20 for evaluating the scalability of Degree distribution and for evaluating BC.
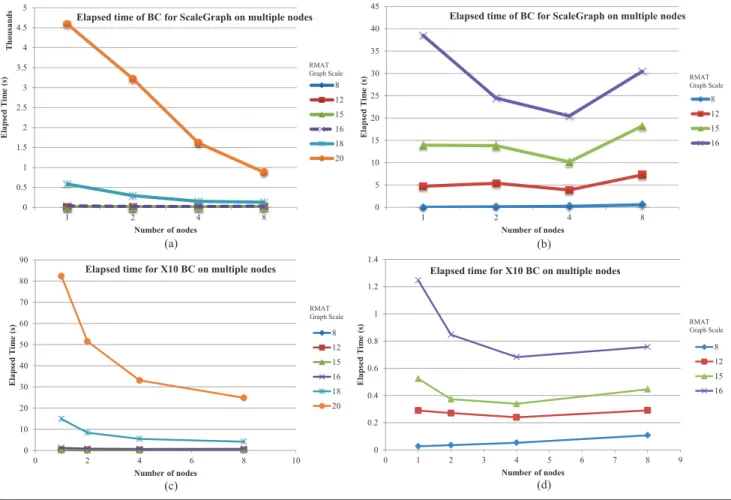
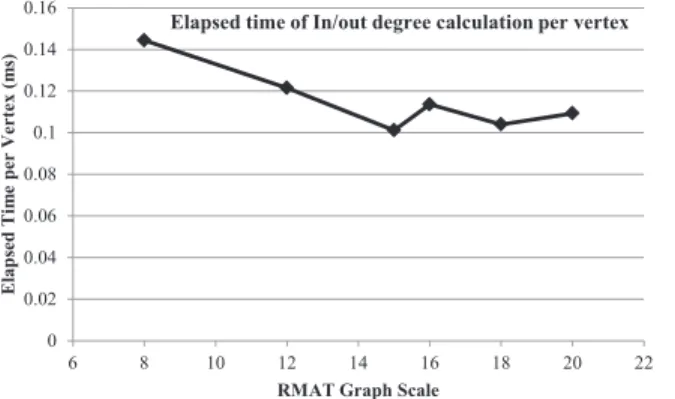
First we obtained the performance information of loading the graph, getting the vertex count, edge count and calculating the in/out degree of the Twitter data set. In three experiment runs we observed that it takes 40 minutes to load the graph on to PlainGraph structure, 81 seconds to get the vertex count and 93 seconds to get edge count. The in/out degree calculation took 1 hour and 12 minutes. Next we ran in/out degree calculation on RMAT Graphs (The results are shown in Figure 10). It should be noted that the plunge of the curve at scale 18 (39322 edges) happened due to the large number of edges compared to scale 16 (487204 edges). Furthermore we calculated the elapsed time per vertex as shown in Figure 11. For Twitter graph we observed 0.144ms elapsed time per vertex. This indicates that elapsed time per vertex remains almost the same even in the case of Twitter Graph which has 41.7 million vertices.
Finally we ran BC on ScaleGraph’s PlainGraph with the same data sets (RMAT graphs of scales 8, 12 and 16) and also on X10 BC implementation. The results are shown in Figure 8. It can be observed that X10 BC implementation out performs our current implementation of BC since we keep the graph data distributed where as X10 BC implementation maintains exact copy of the graph data in every node which makes it orders of time faster than ours. We are currently working on reducing the time it takes for calculating BC on ScaleGraph. The Figure 8 (b) and (d) have been drawn to make it more visible the curves of scales 8, 12, 15, and 16 which are not clearly visible on Figure 8 (a) and (c).
7. Discussion and Limitations
In this paper our intention was to introduce the design and some initial experiment results of ScaleGraph which is an X10 library for billion scale graph processing that is under development. Un- like most contemporary graph libraries we try to introduce con- crete abstractions for representing graph data on distributed envi- ronments while providing a simple programming interface for X10 application developer community. One of the key features that dis- tinguishes our library from others is that we create a distributed in- dex of graph data (i.e., the vertices are indexed by their vertex ID) which makes it difficult to load the graph data in different places asynchronously. Our current solution for this issue is to split the large graph in to pieces and then load them via our library.
We are currently working on improving the BC and degree calculation algorithms. Also we are working on implementing more complex graph algorithms such as graph clustering, community detection, pattern matching, etc.
8. Conclusion
This paper introduced ScaleGraph which is a X10 library for bil- lion scale graph analytics. The library has been designed ground up following the object-oriented programming constructs. We evalu- ated the performance of Betweeness Centrality and Degree distri- bution calculation on PlainGraph to observe the scalability of the library. Planned and ongoing work of the library includes improv- ing the scalability of the Graph algorithms and implementing new algorithms such as graph clustering, community detection, pattern matching, etc.
Acknowledgments
We would like to thank the anonymous reviewers of X10 Workshop 2012 for their valuable comments for improving our work.
This research was supported by the Japan Science and Technol- ogy Agency’s CREST project titled “Development of System Soft- ware Technologies for post-Peta Scale High Performance Comput- ing”.
References
[1] S. Agarwal, R. Barik, V. Sarkar, and R. K. Shyamasundar. May- happen-in-parallel analysis of x10 programs. PPoPP ’07, pages 183– 193, 2007. ISBN 978-1-59593-602-8.
[2] P. An, A. Jula, S. Rus, S. Saunders, T. Smith, G. Tanase, N. Thomas, N. Amato, and L. Rauchwerger. Stapl: an adaptive, generic parallel c++ library. In Proceedings of the 14th international conference on Languages and compilers for parallel computing, LCPC’01, pages 193–208, Berlin, Heidelberg, 2003. Springer-Verlag. ISBN 3-540- 04029-3.
[3] J. Anthonisse. The rush in a directed graph. Technical Report BN, 9/71, 1971.
[4] D. Bader, G. Cong, and J. Feo. On the architectural requirements for efficient execution of graph algorithms. In Parallel Processing, 2005. ICPP 2005. International Conference on, pages 547 – 556, june 2005. [5] B. Barrett, J. Berry, R. Murphy, and K. Wheeler. Implementing a portable multi-threaded graph library: The mtgl on qthreads. In Par- allel Distributed Processing, 2009. IPDPS 2009. IEEE International Symposium on, pages 1 –8, may 2009.
[6] D. Batenkov. Boosting productivity with the boost graph library. XRDS, 17:31–32, Mar. 2011. ISSN 1528-4972.
[7] J. Berry, B. Hendrickson, S. Kahan, and P. Konecny. Software and algorithms for graph queries on multithreaded architectures. In Paral- lel and Distributed Processing Symposium, 2007. IPDPS 2007. IEEE International, pages 1 –14, march 2007.
[8] U. Brandes. A Faster Algorithm for Betweenness Centrality. Journal of Mathematical Sociology, 25:163–177, 2001.
[9] U. Brandes, M. Eiglsperger, I. Herman, M. Himsolt, and M. Marshall. Graphml progress report structural layer proposal. In P. Mutzel, M. Jnger, and S. Leipert, editors, Graph Drawing, volume 2265 of Lecture Notes in Computer Science, pages 109–112. Springer Berlin / Heidelberg, 2002. ISBN 978-3-540-43309-5.
[10] A. Buluc¸ and J. R. Gilbert. The combinatorial blas: design, im- plementation, and applications. International Journal of High Per- formance Computing Applications, 25(4):496–509, 2011. URL http://hpc.sagepub.com/content/25/4/496.abstract. [11] D. Chakrabarti, Y. Zhan, and C. Faloutsos. R-MAT: A Recursive
Model for Graph Mining. In Fourth SIAM International Conference on Data Mining, Apr. 2004.
[12] P. Charles, C. Grothoff, V. Saraswat, C. Donawa, A. Kielstra, K. Ebcioglu, C. von Praun, and V. Sarkar. X10: an object-oriented ap- proach to non-uniform cluster computing. In Proceedings of the 20th annual ACM SIGPLAN conference on Object-oriented programming, systems, languages, and applications, OOPSLA ’05, pages 519–538, New York, NY, USA, 2005. ACM. ISBN 1-59593-031-0.
[13] G. Cong, G. Almasi, and V. Saraswat. Fast pgas connected compo- nents algorithms. PGAS ’09, pages 13:1–13:6, New York, NY, USA, 2009. ACM. ISBN 978-1-60558-836-0.
[14] G. Cong, G. Almasi, and V. Saraswat. Fast pgas implementation of distributed graph algorithms. SC ’10, pages 1–11, Washington, DC, USA, 2010. IEEE Computer Society. ISBN 978-1-4244-7559-9. [15] G. Csardi and T. Nepusz. The igraph software package for complex
network research. InterJournal, Complex Systems:1695, 2006. URL http://igraph.sf.net.
[16] D. Cunningham, R. Bordawekar, and V. Saraswat. Gpu programming in a high level language: Compiling x10 to cuda. 2011.
[17] J. Dongarra and et al. The international exascale software project roadmap. International Journal of High Performance Computing Applications, 25(1):3–60, 2011.
[18] D. Ediger, K. Jiang, J. Riedy, D. A. Bader, and C. Corley. Massive social network analysis: Mining twitter for social good. In Proceed- ings of the 2010 39th International Conference on Parallel Processing, ICPP ’10, pages 583–593, Washington, DC, USA, 2010. IEEE Com- puter Society. ISBN 978-0-7695-4156-3.
[19] L. C. Freeman. A Set of Measures of Centrality Based on Between- ness. Sociometry, 40(1):35–41, Mar. 1977.
[20] R. Garcia, J. Jarvi, A. Lumsdaine, J. G. Siek, and J. Willcock. A com- parative study of language support for generic programming. OOP- SLA ’03, pages 115–134, New York, NY, USA, 2003. ACM. ISBN 1-58113-712-5.
[21] D. Gregor and A. Lumsdaine. Lifting sequential graph algorithms for distributed-memory parallel computation. SIGPLAN Not., 40:423– 437, October 2005. ISSN 0362-1340.
[22] D. Grove, O. Tardieu, D. Cunningham, B. Herta, I. Peshansky, and V. Saraswat. A performance model for x10 applications: What’s going on under the hood? 2011.
[23] M. Hay, C. Li, G. Miklau, and D. Jensen. Accurate estimation of the degree distribution of private networks. In Data Mining, 2009. ICDM
’09. Ninth IEEE International Conference on, pages 169 –178, dec. 2009.
[24] F. Hielscher and P. Gottschling. Pargraph. URL: http://pargraph.sourceforge.net/, Jan. 2012.
[25] IBM. X10 language specification (version 2.2). Jan 2012.
[26] IBM. X10: Performance and productivity at scale. URL: http://x10-lang.org/, Jan. 2012.
[27] V. S. Kemal Ebcioglu, Vijay Saraswat. X10: Programming for hierar- chical parallelism and non-uniform data access. In 3rd International Workshop on Language Runtimes, Impact of Next Generation Proces- sor Architectures on Virtual Machine Technologies, 2004.
[28] M. Kulkarni, K. Pingali, B. Walter, G. Ramanarayanan, K. Bala, and L. P. Chew. Optimistic parallelism requires abstractions. In Proceed- ings of the 2007 ACM SIGPLAN conference on Programming lan- guage design and implementation, PLDI ’07, pages 211–222, New York, NY, USA, 2007. ACM. ISBN 978-1-59593-633-2.
[29] H. Kwak, C. Lee, H. Park, and S. Moon. What is Twitter, a social network or a news media? WWW ’10, pages 591–600, 2010. [30] J. Law. Review of ”the boost graph library: user guide and refer-
ence manual by jeremy g. siek, lie-quan lee, and andrew lumsdaine.” addison-wesley 2002. ACM SIGSOFT Software Engineering Notes, 28(2):35–36, 2003.
[31] L.-Q. Lee, J. G. Siek, and A. Lumsdaine. The generic graph compo- nent library. SIGPLAN Not., 34:399–414, October 1999. ISSN 0362- 1340.
[32] J. Leskovec. Snap: Stanford network analysis project. URL: http://snap.stanford.edu/, Jan. 2012.
[33] A. Lugowski, D. Alber, A. Buluc¸, J. Gilbert, S. Reinhardt, Y. Teng, and A. Waranis. A flexible open-source toolbox for scalable complex graph analysis. In SIAM Conference on Data Mining (SDM), 2012 (accepted).
[34] K. Madduri, B. Hendrickson, J. Berry, D. Bader, and J. Crobak. Mul- tithreaded Algorithms for Processing Massive Graphs. 2008. ISBN 978-1-58488-909-0.
[35] G. Malewicz, M. H. Austern, A. J. Bik, J. C. Dehnert, I. Horn, N. Leiser, and G. Czajkowski. Pregel: a system for large-scale graph processing. In Proceedings of the 2010 international conference on Management of data, SIGMOD ’10, pages 135–146, New York, NY, USA, 2010. ACM. ISBN 978-1-4503-0032-2.
[36] J. Milthorpe, V. Ganesh, A. Rendell, and D. Grove. X10 as a paral- lel language for scientific computation: Practice and experience. In Parallel Distributed Processing Symposium (IPDPS), 2011 IEEE In- ternational, pages 1080 –1088, may 2011.
[37] M. Newmann. Networks: An Introduction. Oxford University Press, 2010. ISBN 9780199206650.
[38] M. Newmann, A.-L. Barabasi, and D. J. Watts. The Structure and Dynamics of Networks. Princeton University Press, 2006. ISBN 978- 0-691-11356-2.
[39] J. O’Madadhain, D. Fisher, S. White, and Y. Boey. The JUNG (Java Universal Network/Graph) Frame- work. Technical report, UCI-ICS, Oct. 2003. URL http://www.datalab.uci.edu/papers/JUNG tech report.html. [40] K. Pingali, D. Nguyen, M. Kulkarni, M. Burtscher, M. A. Hassaan,
R. Kaleem, T.-H. Lee, A. Lenharth, R. Manevich, M. M´endez-Lojo, D. Prountzos, and X. Sui. The tao of parallelism in algorithms. In Proceedings of the 32nd ACM SIGPLAN conference on Programming language design and implementation, PLDI ’11, pages 12–25, New York, NY, USA, 2011. ACM. ISBN 978-1-4503-0663-8.
[41] A. X. Project. Xerces-c++ xml parser. URL: http://xerces.apache.org/xerces-c/, Jan. 2012.
[42] S. S. Skiena. The Algorithm Design Manual. Springer, 2 edition, 2008. ISBN 978-1-84800-069-8.
[43] Sourceforge. Jung - java universal network/graph framework. URL: http://jung.sourceforge.net/index.html, Jan. 2012. [44] A. Vajda. Programming Many-Core Chips. Springer-Verlag, 2011.
ISBN 978-1-4419-9738-8.