TA session# 8
Jun Sakamoto
June 14,2016
Contents
1
Introduction of GLS 1
2
OLSE and GLSE 3
1 Introduction of GLS
The following items were suppoused about error term in OLS.
A.E[ui] = 0 B.E[u2i] = σ2< ∞ C.E[uiuj] = 0, ∀i 6= j
But we often confront the situation that above assumption dose not hold.
Example1:Heteroscedasticity
If error term has different variance, then variance-covariance matrix was represent as below.
σ2Ω =
σ12 0 · · · 0 0 σ22 . .. ... ... . .. ... 0 0 · · · 0 σ2n
Example2:First-Order Autococorrelation
If error term has firs-order autocorrelation(i.e.ut= ρut−1+ ǫt), then then variance-covariance matrix was rep- resent as below.
σ2Ω = 1−ρσ2ǫ2
1 ρ ρ2 · · · ρn−1 ρ 1 ρ · · · ρn−2 ρn−2 ρ 1 · · · ρn−3
... ... ... . .. ... ρn−1 ρn−2 ρn−3 · · · 1
OLS is not BLUE above mentioned but GLS is BLUE.
Ω is a matrix of symmetric and real number. So we can diagonalize Ω,
Ω = A′ΛA = CC′(C = A′Λ1/2) Λ is a diagonal matrix and the diagonal elements are the eigenvalue. Ais a consisting of eigen vectors.
(If you don’t understand above, please check 2nd lecture note.) Regression model is,
y= Xβ + u. Multiply C−1 on both sides of regression model.
C−1y= C−1Xβ+ C−1u ←→ y∗= X∗β+ u∗ Therefore we can get a bellow estimater.
βˆGLS= (X′Ω−1X)−1X′Ω−1y Error term of new regression model is homoscedastic.
E[uu′] = C−1E[uu′]C′−1
= C−1σΩC′−1 σ2C−1ΩC′−1
= σ2In
Property8.1
(1)E[ ˆβGLS] = β (2)V [ ˆβGLS] = σ2(X′Ω−1X)−1 Proof(1)
βˆGLS= (X′Ω−1X)−1X′Ω−1y
= (X′Ω−1X)−1X′Ω−1(Xβ + u)
= β + (X′ΩX)−1X′Ω−1u Thus, take expectation
E[ ˆβGLS] = E[β + (X′Ω−1X)−1X′Ω−1u] = β
Q.E.D
2
Proof(2)
V[ ˆβGLS] = E[((X′Ω−1X)−1X′Ω−1u)((X′Ω−1X)−1X′Ω−1u)′]
= E[(X′Ω−1X)−1X′Ω−1uu′Ω−1X(X′Ω−1X)−1]
= (X′Ω−1X)−1X′Ω−1E[uu′]Ω−1X(X′Ω−1X)−1
= (X′Ω−1X)−1X′Ω−1σ2ΩΩ−1X(X′Ω−1X)−1
= σ2(X′Ω−1X)−1X′Ω−1X(X′Ω−1X)−1
= σ2(X′Ω−1X)−1
Q.E.D Aitken Theorem
GLSE is a best linear unbiased estimator.
V[ ˆβGLS] ≤ V [b] for any linear unbiased estimator b. Proof
We can show that GLSE is BLUE like proof of the case that OLSE is BLUE because assumption is generalized by diagonalization.
Q.E.D
2 OLSE and GLSE
Property8.2
(1)OLSE is a unbiased estimator under the situation of the error term assumption does not satisfy B and C. (2)V [ ˆβGLS] ≤ V [ ˆβOLS]
Proof(1)
[ ˆβOLS] = (X′X)−1X′y
= β + (X′X)−1X′u
Above equation is also maintained under the heteroscedasticity. So we can show unbiasedness from assumption of A.
Q.E.D Proof(2)
Prop8.2 (2) is trivial because GLSE is BLUE.
V[ ˆβOLS] = E[((X′X)−1X′u)((X′X)−1X′u)′]
= E[(X′X)−1X′uu′X(X′X)−1]
= (X′X)−1X′E[uu′]X(X′X)−1
= (X′X)−1X′σ2ΩX(X′X)−1
= σ2(X′X)−1X′ΩX(X′X)−1 Thus,
V[ ˆβOLS] − V [ ˆβGLS] = σ2(X′X)−1X′ΩX(X′X)−1− σ2(X′Ω−1X)−1
= σ2((X′X)−1X′−(X′Ω−1X)−1X′Ω)Ω((X′X)−1X′−(X′Ω−1X)−1X′Ω)′
= σ2AΩA′. Ω is positive definite matrix, AΩA′ >0. Thus V [ ˆβGLS] ≤ V [ ˆβOLS]
Check variance of OLSE and GLSE.
1.We generate samples X ∼ U [0, 5] and u(u does not satisfy B or C).(t=50) 2.y is made by X and u from step1.(We assume true beta is 2)
3.We estimate ˆβ.
4. ˆβ is obtained by repeating above steps n times.
Example(1)
u1= (u1, ..., u25), ui∼ N(0, 1)
u2= (u26, ..., u50), uj∼ N(0, 25)
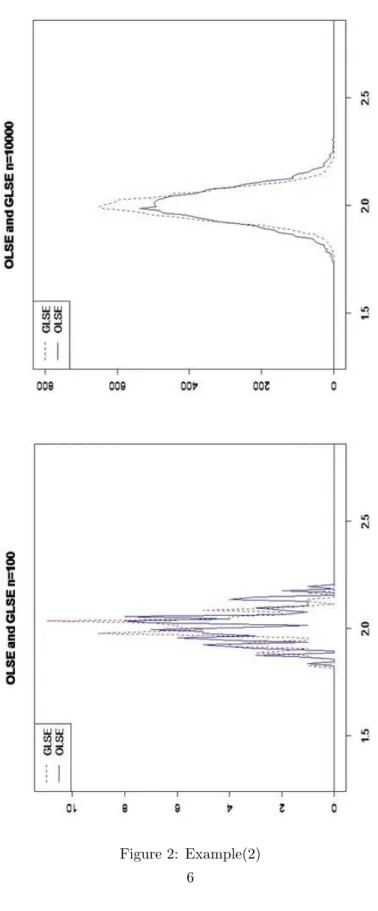
Example(2)
u1= (u1, ..., u25), ui∼ N(0, 1) u2= (u26, ..., u50), uj∼ N(0, 4)
Example(3)
ut= 0.8ut−1+ ǫt, ǫt∼ N(0, σ2t)
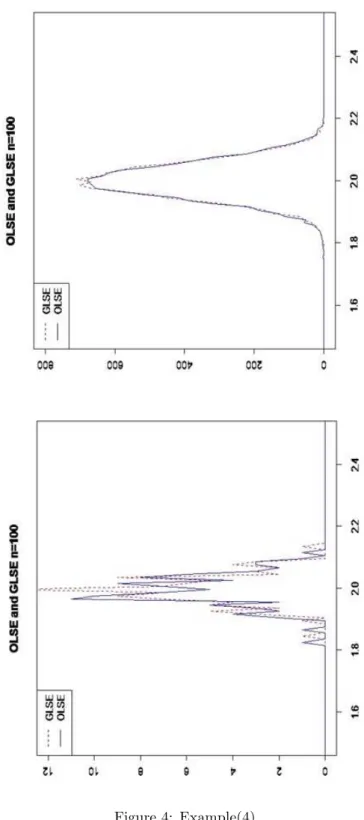
Example(4)
ut= 0.2ut−1+ ǫt, ǫt∼ N(0, σ2t)
4
Figure 2: Example(2) 6
Figure 4: Example(4)
8