平成24年度 ミクロ計量経済学
講義ノート5 パネルデータにおける2項選択モデル
このノートでは、パネルデータの分析に使用する2項選択モデルの紹介と、その注意すべ き点を考察する。パネルデータ分析は、個人間の異質性を制御できることが利点であるが、 2項選択モデルのような非線形モデルでその利点を活かすのは、それほど自明ではない。ま た動学モデルの場合は、初期条件の定式化が必要となるが、いかにしてその定式化を行うか には議論の余地がある。
5.1 パネルデータ2項選択モデル
次のような単純な2項選択モデルを考える。
yit= 1{x′itβ + vit≥ 0} (1)
i = i, . . . , n (n → ∞); t = 1, . . . T (T は固定)とする。ここで、 vit|Xi ∼ F
|{z}
正規分布やロジット分布など
(2)
と仮定し、iについては無作為標本を仮定する。vitは時系列方向には相関があることを許容 するモデルである。
このモデルの場合、「部分的」最尤推定量を使用することができる。つまり、目的関数を l =
∑n i=1
∑T t=1
[yitlog F (x′itβ) + (1 − yit) log{1 − F (x′itβ)}] (3)
として、β = arg min lˆ を推定量とするものである。なお、vitの時系列方向での相関を無視 しているため、lは真の尤度ではないかもしれない。しかし、βˆが一致性をもつことは、比 較的容易に示すことができる。
• この方法の問題点は、一致性があっても有効性は担保できていないことがあげられる。 またより本質的な問題として、個人間の異質性をvitに含めてしまっているため、個人 間の異質性を固定した上でのxitの効果を表現できていないことがある。実際、個人 間の異質性が変量効果で表現でき、モデルが正しいとしても、推定したβの値は、変 量効果の部分を制御したxitの効果にはならない。
• なお、vitの相関を考慮するため、標準誤差の計算には、自己相関に頑健な標準誤差の 式を使用するべきである。
他にも、線形モデルを使用することもある。モデルは、
yit = x′itβ + vit (4)
である。この方法の利点は、線形モデルの手法がそのまま使え、vitが固定効果を含む場合 や、動学モデルの推定も容易であることである。しかし、線形モデルであるので、yit= 1と なる確率が0と1の間に収まらないなどの問題を起こす可能性が高い。
5.2 観測できない異質性を考慮したモデル
パネルデータ分析の利点である、個人間の異質性の制御を行うため、
yit= 1{x′itβ + µi+ vit≥ 0} (5) として、個人効果µiをモデルに含める。ここで、vit|Xiの分布は仮定しておく。
変量効果 まず、µiがXiと独立であり、その分布がわかっている変量項効果モデルを考え る。つまり、追加的なじょうけんとして、
µi|Xi ∼ N (0, σµ2) (6)
と仮定する。なお、必ずしも正規分布を仮定する必要はない。また、
vi|Xi ∼ N (0, σv2I) (7)
を仮定する。
• 識別のために、σv2= 1という標準化をする。
ここで考えているモデルは、変量効果プロビットモデルという。
この場合、一致で有効な推定が可能になる。尤度関数の導出のために、µiについて条件 づけた確率を考察する。それは、
Pr(yi|Xi, µi) =
∏T t=1
Φ(x′itβ + µi)yit(1 − Φ(x′itβ + µi))1−yit (8)
と書ける。しかし、µiの密度は、ϕ(µi/σµ)/σµと仮定したので、µiについて積分をして、 Pr(yi|Xi) =
∫ T
∏
t=1
Φ(x′itβ + µi)yit(1 − Φ(x′itβ + µi))1−yit 1 σµ
ϕ( µi σµ
)
dµi (9)
という確率の表現を得る。 つまり、尤度関数は、
l =
∑n i=1
log Pr(yi|Xi) (10)
と書ける。また最尤推定量β = arg min lˆ は有効である。
• ここでは、var(vit|xi, µi) = 1と仮定した。しかし、時点ごとに異なる分散を許容する ことができる。つまり、var(vit|xi, µi) = σ2vtと仮定する。ただし、識別のための標準 化として、σ2v1 = 1と仮定する。
Chamberlainのモデル 変量効果モデルでは、Xiとµiが独立であることが仮定されてい た。これは、経済学上の応用では、正当化しにくい仮定である。この問題を緩和するため、 Chamberlain (1980)はµiを
µi = π + Π′Xi+ ai, (11)
とモデル化することを提案した。ここで、ai(µiではない)が変量効果であると仮定する。例 えば、
ai|Xi ∼ N (0, σ2a) (12)
と仮定する。なお、πとΠは誘導形の係数と解釈し、特に経済学的な意味づけを行わない。 この場合、確率は、
Pr(yit= 1|Xi, µi) = Φ(β′xit+ µi) = Φ(β′xit+ π + Π′Xi+ ai) (13)
と書ける。つまり、
Pr(yit = 1|Xi) =
∫
Φ(β′xit+ π + Π′Xi+ ai) 1 σaϕ
( a σa
)
da (14)
であり、尤度関数は、 l =
∑n i=1
log
∫ T
∏
t=1
Φ(β′xit+ π + Π′Xi+ ai)yit{1 − Φ(β′xit+ π + Π′Xi+ ai)}(1−yit(15))
× 1 σa
ϕ( a σa
)
da (16)
となる。つまり、aは積分をとることで消している。尤度関数を最大化して、(β, π, Π, σa)を 推定する。
• 識別が可能である理由は、Xiがそれぞれのiについて同じように影響を与える一方で、 xitは時間とともに変動することである。したがって、時間を通じて変動しない回帰変 数の係数は識別できない。
• π + Π′Xiの代わりに、π + Π′x¯i を使用することもよくある。Mundlak (1978)による 提案である。推定すべき変数の数を減らすことが可能であり、またバランスのとれて いないパネルデータの場合にも有用である。
• vitの分散不均一性も考慮できる。例えば、
vi1 ∼ N (0, 1) (標準化) (17)
vi2 ∼ N (0, σ22) (18)
. . . (19)
viT ∼ N (0, σT2) (20)
と仮定する。
5.3 固定効果ロジットモデル
次に、µiについては何も仮定しない、固定効果(FE)モデルを考える。 F をvの分布として、尤度関数は
l =
∑n i=1
∑T t=1
[yitlog F (x′itβ + µi) + (1 − yit) log{1 − F (x′itβ + µi)}] (21)
を考える。しかし、一般に、この関数からµiを取り除いて推定することはできない。これ はモデルの非線形性による。
• 静学的ロジットモデルにおいては、固定効果を取り除くことができるが、それは、特殊 な状況であり、またロジットモデルでないと取り除くことはできない。Chamberlain (2010)ならびに、Magnac (2004)を参照せよ。
もし、T が固定されている状況で、(β, µ1, . . . , µn)について、lを最大化しても、一致性の ある推定量は得られない。これは、母数のうちµiの次元が無限であることから来る問題で あり、“incidental parameter problem (付随パラメーター問題)”あるいは、‘Neyman-Scott (1948)問題”と呼ばれる。
• なお、線形モデル、
yit = βxit+ µi+ vit (22)
の場合は、yitをxitに回帰しその時に各人ごとに定数項ダミーを加えると固定効果推 定量を得られる。これは一致性をもつ。しかし、µiを一致性をもって推定することは できない。
T が無限に行く状況では、固定効果推定をすることができる。これは次のノートで議論 する。
ただし、ロジットモデルの場合には、固定効果を入れたモデルの推定をすることができ る。ここでは、条件付きロジットモデル(Chamberlain (1980))を考える。
一般理論 まず、一般的な固定効果を消去する方法から議論する。 今、次のような尤度関数があるとする。
l( y
|{z}
{yi1,...,yiT}
|X, θ, {µi}ni=1). (23)
重要なポイントは、{µi}n
i=1の十分統計量(S)を得ることである。つまり、
l(y|X, S, θ, {µi}ni=1) = l(y|X, S, θ) (24) となるような統計量Sがあるとよい。
• 例えば、誤差項が正規分布に従う線形モデル、 yit= β′xit+ µi+ vit
|{z}
正規乱数
(25)
の場合は、
∑T
t=1yit = Siがµiの十分統計量となる。このモデルの場合、固定効果推 定量が、条件付き最尤推定量となる。
パネル固定効果ロジットモデル 次に、今の議論の焦点である、2項選択モデルについて考 える。次のパネル固定効果ロジットモデル、
Pr(yit= 1|Xi, µi) = e
β′xit+µi
1 + eβ′xit+µi (26)
を考察する。Tは固定と仮定する。 このモデルでは、
∑T
t=1yitがµiの十分統計量となる。
簡単化のために、T = 2の場合を考える。つまり、Si = yi1+ yi2となる。以下では、Xi とµiとに条件づけていることは省略する。次の確率を計算する。
Pr{(yi1, yi2) = (∗, ∗)|Si}. (27) もし、Si= 0あるいは、2の時は、それぞれ、(yi1, yi2) = (0, 0)あるいは、(1, 1)となる。つ まり、この時は分布は退化すし、尤度への貢献はない。
したがって、Si= 1の場合のみを考える。すると、
Pr{(yi1, yi2) = (0, 1)|Si = 1} (28)
= Pr{(yi1, yi2) = (0, 1)}
Pr{(yi1, yi2) = (0, 1), (1, 0)} (29)
=
1 1 + eβ′xi1+µi
eβ′xi2+µi 1 + eβ′xi2+µi 1
1 + eβ′xi1+µi
eβ′xi2+µi 1 + eβ′xi2+µi +
eβ′xi1+µi 1 + eβ′xi1+µi
1 1 + eβ′xi2+µi
(30)
= e
βxi2+µi
eβxi2+µi+ eβxi1+µi (31)
= e
β˙xi2
1 + eβ˙xi2 (32)
となり、µiは消える。なお ˙xi2= xi2− xi1としている。よって、条件付き対数尤度関数は、 l =
∑n i=1
[
1{(yi1, yi2) = (0, 1)} log
( eβ˙xi2 1 + eβ˙xi2
)
+ 1{(yi1, yi2) = (1, 0)} log
( 1
1 + eβ˙xi2 )]
(33)
となる。β = arg max lˆ は一致性をもつ。なお、βˆは固定効果を母数とした固定効果推定で はない。その違いについては、Abrevaya (1997)を参照せよ。
• 以上の方法では、βˆのみを得ることででき、µiについは未知のままである。βのみが わかっている状況ではどのような分析が可能であるかが、ここでの論点である。以下 で示すように、オッズ比については、βのみの知識で、分析が可能になる。オッズ比は
オッズ比=
Pr(yit= 1) Pr(yit= 0) = e
βxit+µi
(34)
である。よって、
log(オッズ比) = βxit+ µi (35)
から
∂
∂xit
log(オッズ比) = β (36)
となり、オッズ比にxitの与える影響はβで表現できることがわかる。 しかし、限界効果
∂
∂xit
Pr(yit = 1) (37)
を得ることはできない。そのためには、µiを既知とするか、µiの分布を仮定(つまり 変量効果にする)し、積分をとって消してしまうしかない。
5.4 動学的離散選択モデル
この節では、動学的なモデルを考える。具体的には、
Pr(yit= 1|xi, yi,t−1, . . . µi) = F (x′itβ + αyi,t−1+ µi) (38) のように、ラグ付き被説明変数が説明変数としてつかわれるモデルである。このようなモデ ルを考える目的は、状態依存と個人の異質性とを区別したいことである。
• α: (真の)状態依存を表現している。
• µi: 見せかけの状態依存を表現している。
このモデルを推定する際に問題となるのは、初期値のyi0をどのように取り扱うかである。 変量効果推定 まずµiを固定されているものとして扱い、そして後ほど積分をとって消すとい
う、これまで考えてきた方法を考える。まず、各個人の尤度への貢献は、f (yi0, yi1, . . . , yiT|xi, yi0, µi) = f (yi1, . . . , yiT|xi, yi0, µi)f (yi0|xi, µi)である。このうち最初の項は
f (yi1, . . . , yiT|xi, yi0, mui) (39)
= f (yiT|yi1, . . . , yi,T−1, xi, yi0, µi) × f (yi1, . . . , yi,T−1|xi, yi0, µi) (40)
=
∏T t=1
f (yit|yi0, yi1, . . . yi,t−1, xiµi) (41)
=
∏T t=1
F (x′itβ + αyi,y−1+ µi)yit × (1 − F (x′itβ + αyi,y−1+ µi))1−yit (42)
≡ A(µi) (43)
と書ける。ここで、Gをµiの分布として、単に
∫
A(µ)dG(µ), (44)
として積分を取る方法は、正当化されない可能性がある。なぜなら、初期値の分布f (yi0|xi, µi) を無視しているからである。この方法でうまくいくのは、µiとyi0が独立の時である。もし そうでないなら、最尤推定量は一致性をもたない。
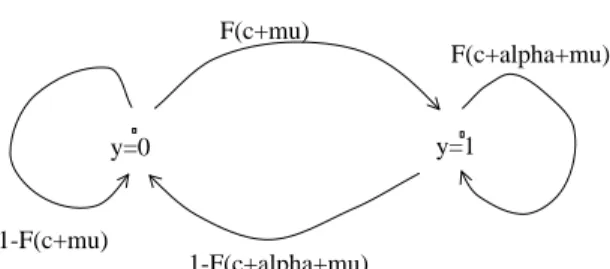
図1: マルコフ連鎖
y=0 y=1
1-F(c+mu)
1-F(c+alpha+mu)
F(c+alpha+mu) F(c+mu)
初期値の取り扱い方 したがって、初期値がµiと相関がある場合も考慮する必要がある。以 下の議論は、Heckman (1981)やHsiao (2003)を参考にしている。二つの方法を紹介する。
1. yの定常分布を使用する方法。いま、
Pr(yit= 1|yi,t−1, . . . , µi) = F (c + αyi,t−1+ µi) (45) であるとする。この時、µiを固定すると、yitはマルコフ連鎖になっている。したがっ て、その定常分布をp(c, α, µ¯ i)あるいはp¯とすると、それは、
(1 − ¯p)F (c + µi) + ¯pF (c + α + µi) = ¯p (46)
→ ¯p = F (c + µi)
1 + F (c + µi) − F (c + α + µi) (47) である。よって、
∑n i=1
log
∫
A(µ)¯p(c, α, µ)yi0(1 − ¯p(c, α, µ))1−yi0dG(µ) = l (48)
として尤度を計算する。
この方法の欠点は、共変量のxiがあった時に、どうやって定常分布を見つけるのかが 自明ではないことである。
2. Chamberlain式のやり方(Heckmanの方法である。) 次の誘導形を考える。
Pr(yi0 = 1|Xi, µi) = F (π + Π′Xi+ γµi), (49) ここで、(π, Π, γ)は誘導形の係数である。
すると、
∑n i=1
log
∫
AF (π + Πxi+ γµi)yi0(1 − F )1−yi0dG(µi) (50)
となり、尤度が計算できる。
応用例 Hyslop (1999)による女性の労働参加の研究は、動学パネルモデルの重要な応用例 である。なお、Hyslopはvitが
vit= δvi,t−1+ ηit. (51)
のようにAR(1)に従うモデルも考える。この場合、尤度関数を得るのは難しい。なぜなら、
ϵi = (ϵi1, . . . , ϵi,T)についても積分をとる必要がある。T = 4なら、数値積分も難しく、シ ミュレーション推定をする必要がある。
動学的パネルロジットモデル Chamberlain (1985)やHonore and Kyriazidou (2000)に動 学的固定効果パネルロジットモデルの推定が議論されている。
5.5 シミュレーション推定
パネルデータにおける離散選択モデルの推定にはシミュレーションが必要となることが多 い。この問題の場合には、前のノートで紹介したGHKシミュレーターが有用である。
考えるモデルは、
yit = 1{x′itβ + ϵit> 0}, (52) ϵi =
ϵi1 . . . ϵiT
∼ N (0, Ω) (53)
であり、(yit, xit)が観測される。このモデルは、Ωを適切に定義することにより、変量効果 の入ったモデルも含んでいる。ここで、Ji ≡ (yi1, . . . , yiT)かつθ = (β, Ω)と表記して、次 の確率
Pr{Ji|Xi, θ} (54)
を評価する必要がある。
いま、Jiという事象と整合的なϵitの値は、
(2yit− 1)ϵit≥ (1 − 2yit)x′itβ (55) を満たす必要がある。そこで、シミュレーションに当たっては、上の不等式を満たすような 分布からGHKシミュレーターによって加重サンプリングする。
vを(1−2yit)ϵit+(1−2yit)x′itβをt番目の要素としてもつベクトルとすると、v ∼ N (a, Σ) である。なおaはそのt番目の要素が(1 − 2yit)x′itβであるベクトルである。vは正規分布で
あり、v ≤ 0となる条件の下での加重サンプリングはGHKシミュレーターがまさにしてい
ることであるので、前回のノートの議論がそのまま成り立つ。
参考文献
[1] J. Abrevaya. The equivalence of two estimators for the fixed effects logit model. Economics Letters, 55:41–43, 1997.
[2] G. Chamberlain. Analysis of covariance with qualitative data. Review of Economic Studies, 47(1):225–238, 1980.
[3] G. Chamberlain. Heterogeneity, omitted variable bias, and duration dependence. In J. Heck- man and B. Singer, editors, Longitudinal Analysis of Labor Market Data, pages 3–38. Cam- bridge University Press, 1985.
[4] G. Chamberlain. Binary response models for panel data: Identification and information. Econometrica, 2010(1):159–168, 2010.
[5] C. Gourieroux and A. Monfort. Simulation-based inference: A survey with special reference to panel data models. Journal of Econometrics, 59:5–33, 1993.
[6] J. J. Heckman. The incidental parameters problem and the problem of initial conditions in estimating a discrete time-discrete data stochastic process and some monte carlo evidence. In C. Manski and D. McFadden, editors, Structural Analysis of Discrete Data with Econometric Applications. MIT Press, 1981.
[7] B. E. Honor´e and E. Kyriazidou. Panel data dicrete choice models with lagged dependent variables. Econometrica, 68(4):839–874, 2000.
[8] C. Hsiao. Analysis of Panel Data. Cambridge University Press, 2003.
[9] D. Hyslop. State dependence, serial correlation and heterogeneity in intertemporal labor force participation of married women. Econometrica, 67(6):1255–1294, 1999.
[10] T. Magnac. Panel binary variables and sufficiency: Generalizing conditional logit. Economet- rica, 72(6):1859–1876, 2004.
[11] Y. Mundlak. On the pooling of time series and cross section data. Econometrica, 46:69–85, 1978.
[12] J. Neyman and E. L. Scott. Consistent estimates based on partially consistent observations. Econometrica, 16:1–32, 1948.